CodeProject.AI 服务器网格
我们处理 AI 相关任务时面临的核心问题之一是计算能力。通常越大越好,但如果您不过度使用,较低配置的机器也可以应对。但是,当意外负载出现,您的小型机器开始吱嘎作响时会发生什么?您真正想要的是一个系统,让您能够将 AI 任务卸载到其他服务器,如果您有闲置的服务器可以承担工作。
这就是 Mesh 发挥作用的地方。
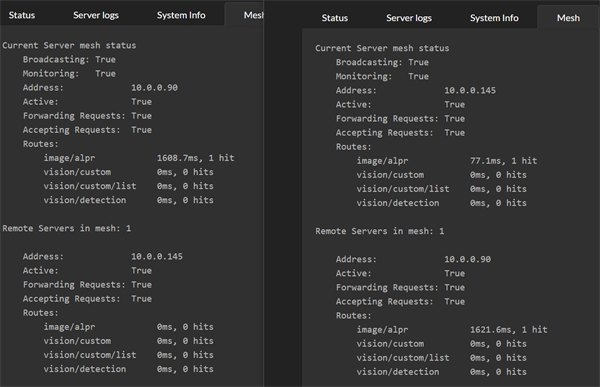
在这里,我们看到两台机器,每台都安装了 CodeProject.AI Server,并且都启用了新的 Mesh 功能。
每台服务器都会处理自己的请求,但同时也了解 Mesh 中的其他服务器,并且如果认为另一台服务器可以做得更好,就会将请求发送给其他服务器。为了确定另一台服务器是否能做得更好,每台服务器都会尝试其他服务器并查看效果。从那时起,接收请求的服务器将要么自行处理请求,要么在其他服务器能更快地完成时将其传递给另一台服务器。
在上图中,服务器 .145 处理了两个 ALPR 请求。第一个请求它自己处理,响应时间为 77 毫秒。第二个请求它传递给了远程的 .90 服务器,该服务器记录的响应时间为 1621 毫秒。由于响应时间过高,远程服务器将不会再收到任何请求。
经过(可配置的)一段时间后,远程服务器的响应时间会“衰减”。较旧的请求计时将被丢弃,“有效”响应时间会重新回到 0。
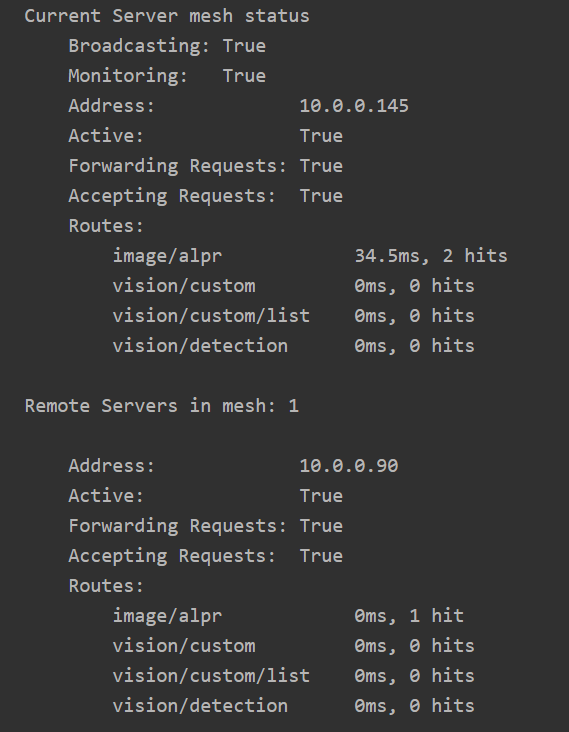
注意到 .90 服务器上,ALPR 的响应时间现在为 0。
现在想象一下黑色星期五,停车场安全系统在早上 6 点突然出现问题。当前服务器接收到大量请求,无法跟上。当前服务器的有效响应时间增加 10 倍,接近 800 毫秒,因此它开始将请求卸载到另一台服务器。
另一台服务器已经预热,并且 16 秒的推理时间已不复存在。远程服务器运行着不错的 GPU,即使在高负载下,其本地响应时间也约为 80 毫秒。
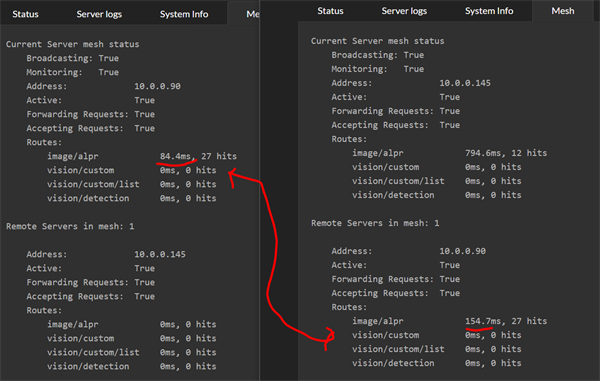
现在我们在当前服务器的 Mesh 摘要选项卡中看到,远程服务器处理了大部分 AI 操作,有效响应时间为 154 毫秒。在远程服务器上,我们看到它报告的有效响应时间为 84 毫秒,但请记住,远程服务器的计时不包括网络往返或重新打包初始 AI 请求所涉及的工作。
Mesh 处理是完全可选的,仪表板可以轻松地将其打开和关闭。无需任何配置。所有服务器都会自我发现 Mesh,注册和注销自己,并且已内置负载均衡。
安装
无需设置。即插即用。
好的,关于设置。
Mesh 设置位于服务器根文件夹中的 appsettings.json 文件下 MeshOptions 分支中。最基本的是 Mesh 是否已启用,此设置在仪表板的 **Mesh** 选项卡中公开。
EnableBroadcasting 和 MonitorNetwork
其他设置包括 EnableBroadcasting,它设置本地服务器是否会向本地网络广播其可用性;以及 MonitorNetwork,它设置服务器是否会花费 CPU 周期监视其他服务器。Mesh 功能不依赖于监视或广播,因此这些标志允许服务器查看网络上发生的情况,而不会广播潜在敏感信息。
AcceptForwardedRequests 和 AllowRequestForwarding
这两个设置决定了服务器是否接受来自 Mesh 中另一台服务器的请求,以及它是否会向 Mesh 中的其他服务器发送请求。这些设置允许服务器为其他服务器提供支持,而不会给其他服务器增加负担,反之亦然,可以使用 Mesh 来获得支持,而不会允许其他服务器增加自身负载。
一个例子是 Raspberry Pi 和 Macbook Pro。Pi 可能将 AcceptForwardedRequests 设置为 false,将 AllowRequestForwarding 设置为 true;而 Mac 可能将 AcceptForwardedRequests 设置为 true,将 AllowRequestForwarding 设置为 false。这可以在需要时为 Pi 提供帮助,而无需担心 Mac 发送不必要的负载。
路由和模块
Mesh 中的每台服务器可能安装了不同的模块,或者在给定模块中安装了不同的模型。服务器还可能运行不同的硬件、操作系统,或者连接到不同的外围设备,例如 Coral 等外部 AI 加速器。
某些模块在其处理过程中也会本地持久化数据,因此对不同服务器的调用可能会产生不同的响应。例如,人脸识别会将注册的面孔存储在本地数据库中,因此,一个调用一台服务器注册面孔,然后调用另一台服务器识别面孔的请求可能会失败,如果另一台服务器也未注册该面孔。
考虑到这一点,每个模块中的每个路由都可以标记为 MeshEnabled。如果为 true,服务器将向 Mesh 公开此路由(例如 /v1/vision/face/detect)。如果 MeshEnabled 为 false(例如 /v1/vision/face/register),则该路由将不供其他服务器使用。
MeshEnabled 在每个模块的 modulesettings.json 文件中,在该文件的 Routes 分支下设置。
Docker
已知服务器:解决网络问题
CodeProject.AI Server 在 Docker 容器内运行,但有一个注意事项:服务器用于宣布其参与 Mesh 的广播可能无法穿过网络层和子网到达其他服务器。这意味着 CodeProject.AI 服务器的 Docker 实例可能对正在寻找 Mesh 参与者的其他服务器不可见。
为了解决这个问题,请编辑希望使用 Docker 实例的每台服务器的 CodeProject.AI 服务器根目录下的 appsettings.json 文件,并编辑 MeshOptions.KnownMeshHostnames 集合。
例如,我们在车库里有一台名为 PC-GARAGE 的电脑。它在 Docker 中运行 CodeProject.AI Server。我们有另一台服务器想使用 PC-GARAGE,因此在那台服务器上,我们编辑 appsettings.json 文件,将其包含在内:
确保启用 UDP 流量
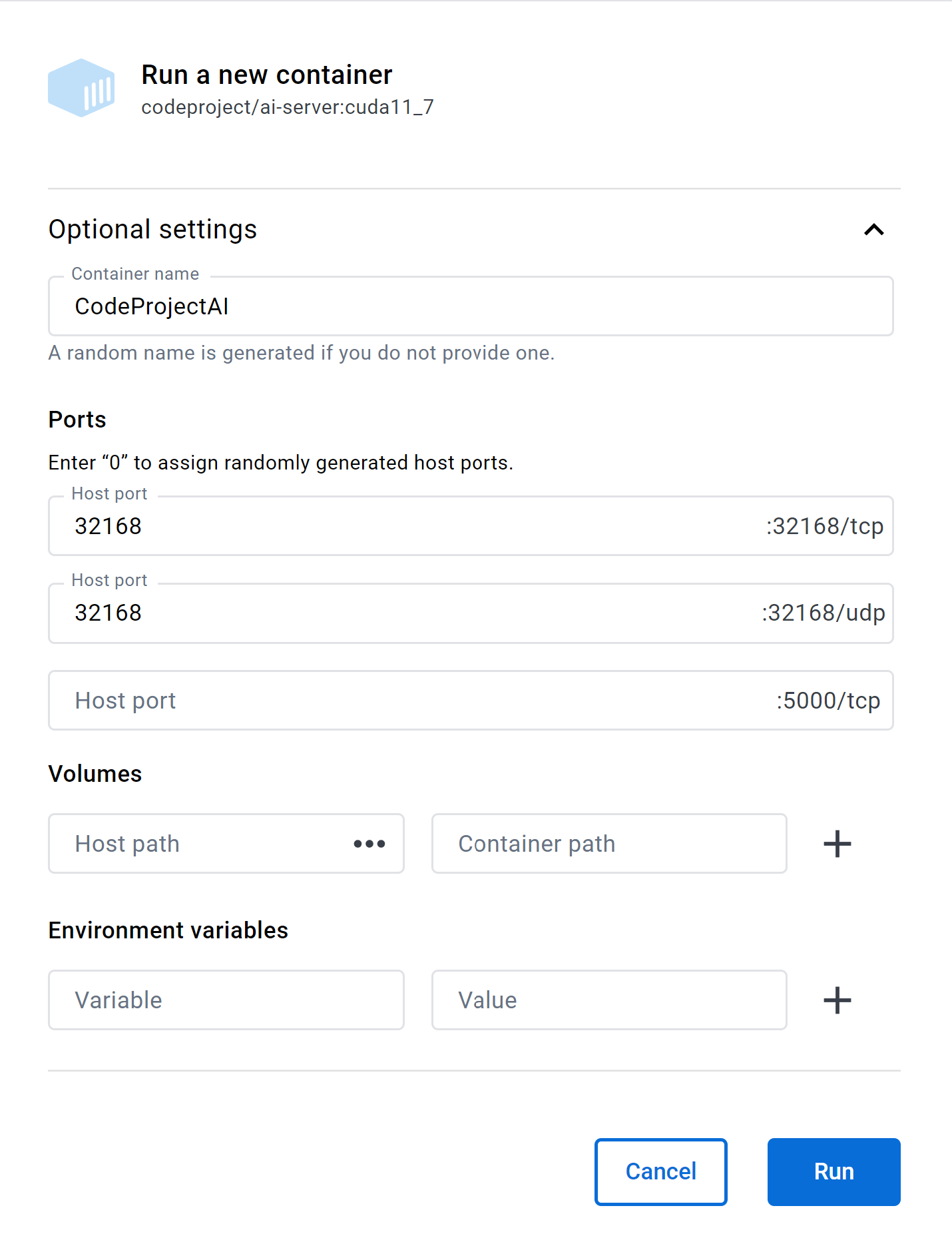
要启用广播和广播的监视,您需要确保 UDP 端口 32168 已由 Docker 容器公开。
如果您是通过命令行启动,则需要在命令行中添加 -p 32168:32168/udp 以打开映射 UDP 端口,该端口使服务器能够广播其 Mesh 状态。
如果您运行的是 Linux on Arm,请使用 codeproject/ai-server:arm64 而不是 codeproject/ai-server
如果使用 Docker Desktop 启动,则 Mesh 支持所需的唯一额外操作是填写 32168/udp 端口文本框。