
健壮的 C++:操作方面
性能良好的服务器
引言
在我撰写的关于 健壮服务核心 (RSC) 的文章中,文章中展示的代码比下载版本有所简化。这样做的原因是完整版本包含与文章主题无关的内容。那它们为什么在那里呢?
答案是,尽管 RSC 可以用作多种应用程序的框架,但其中一种是大型嵌入式系统,例如服务器。这些类型的系统必须在部署的每个站点进行配置。为了提供高可用性,它们必须告知操作员问题,允许他们采取纠正措施,并提供调试信息,以便开发人员能够查明并修复进入发布的软件故障。本文涵盖了用于这些目的的功能。具体来说,它将讨论:
这些内容在许多其他文章中并不重要,但在本文中却是重点。其中大多数实际上是面向切面编程中的切面。但 RSC 是用 C++ 编写的,因此试图合并它们的出现而不是仅仅将它们散布在代码中只会增加开销并造成难以理解的混乱。
本文使用 对象池 来提供上述功能如何使用的示例。如果您还没有阅读过关于对象池的文章,快速浏览一下会帮助您理解本文内容。如果您是第一次阅读关于 RSC 的文章,请花几分钟时间阅读这篇 序言。
配置参数
配置参数是自定义软件加载的主要方式。每个配置参数在系统开始初始化后不久从 配置文件 读取。文件的格式很简单。以斜杠 (/) 开头的行被视为注释并被忽略。否则,系统为文件中的每一行创建一个 CfgTuple 实例。每行包含两个字符串:参数的名称(其键)和它的值。
随着系统继续初始化,其子系统创建 CfgParm 的子类,其中包含以下数据成员:
- 与参数关联的
CfgTuple(tuple_):通过参数的键找到。 - 一个字符串 (
default_),如果在配置文件中未指定,则设置参数的值。 - 一个字符串 (
expl_),解释参数的用途。 - 更改系统运行时参数值所需的重新启动级别 (
level_)。
如果新创建的 CfgParm 的 CfgTuple 未找到,则使用其默认值创建一个实例。当配置文件未包含该参数的键值条目时会发生这种情况。
CfgParm::CfgParm(c_string key, c_string def, c_string expl) :
tuple_(nullptr),
default_(def),
expl_(expl),
level_(RestartNone)
{
auto reg = Singleton<CfgParmRegistry>::Instance();
tuple_ = reg->FindTuple(key);
if(tuple_ == nullptr)
{
tuple_ = new CfgTuple(key, default_);
reg->BindTuple(*tuple_);
}
}
创建 CfgParm 后,必须立即将其注册到单例 CfgParmRegistry,以便可以从其 CfgTuple 设置其值。
void CfgParmRegistry::BindParm(CfgParm& parm)
{
auto key0 = strLower(parm.Key());
// Register parameters by key, in alphabetical order.
//
CfgParm* prev = nullptr;
for(auto next = parmq_.First(); next != nullptr; parmq_.Next(next))
{
auto key1 = strLower(next->Key());
if(key0 < key1) break;
prev = next;
}
parmq_.Insert(prev, parm);
parm.SetFromTuple();
}
设置值是一个两步过程:将其设置为参数的下一个值,然后使其成为当前值。这两个步骤是分开的,因为有时新值只能预加载,然后系统必须重新启动才能应用它。(重启是对系统的部分重新初始化,如 健壮 C++:初始化和重启 中所述。)
bool CfgParm::SetFromTuple()
{
auto input = tuple_->Input();
if(SetNext(input))
{
SetCurr();
return true;
}
SetNext(default_); // input was invalid
SetCurr();
return false;
}
CfgParm 实际上是一个虚拟类,可以对其进行子类化以支持不同类型的参数。
CfgBoolParm支持布尔参数。CfgFlagParm支持std::bitset中的一个位。CfgIntParm支持整数参数。CfgStrParm支持std::string参数。
命令行界面命令
CLI 提供了 >cfgparms 命令来访问配置参数。

列出所有配置参数及其值。

本节的其余部分将使用对象池大小的配置参数来说明如何创建和使用其中一个参数。
创建用于对象池大小的 CfgTuple
配置文件中的条目之一是:
NumOfMsgBuffers 2
这定义了 MsgBuffer 池的大小(2K),该池为在线程间消息传递期间使用的对象提供块。当在系统初始化期间早期调用 CfgParmRegistry::LoadTuples 时,它会在遇到上述条目时创建一个 CfgTuple。其键是 "NumOfMsgBuffers",其值是 "2"。
创建用于对象池大小的 CfgParm
在初始化期间稍晚一些,NbModule::Startup 中的以下行创建了 MsgBuffer 池:
Singleton<MsgBufferPool>::Instance()->Startup(level);
每个对象池都是一个单例,其构造函数调用基类 ObjectPool 构造函数,后者又创建池的 ObjectPoolSizeCfg。这就是定义池大小的参数;它继承自 CfgIntParm。顺序如下,省略了未参与创建参数的代码:
MsgBufferPool::MsgBufferPool() :
ObjectPool(MsgBufferObjPoolId, MemDynamic, BlockSize, "MsgBuffers") { }
ObjectPool::ObjectPool
(ObjectPoolId pid, MemoryType mem, size_t size, const string& name) :
name_(name.c_str()),
key_("NumOf" + name_),
targSegmentsCfg_(nullptr)
{
targSegmentsCfg_.reset(new ObjectPoolSizeCfg(this));
Singleton<CfgParmRegistry>::Instance()->BindParm(*targSegmentsCfg_);
}
ObjectPoolSizeCfg::ObjectPoolSizeCfg(ObjectPool* pool) :
CfgIntParm(pool->key_.c_str(), "1", 0,
ObjectPool::MaxSegments, "number of segments of 1K objects") { }
CfgIntParm::CfgIntParm(c_string key, c_string def, word min, word max,
c_string expl) : CfgParm(key, def, expl) { }
当 ObjectPool 构造函数调用 CfgParmRegistry::BindParm 时,通过查找与其键关联的 CfgTuple 来设置参数的值。当 MsgBufferPool 单例的 Startup 函数最终被调用(它从其基类继承该函数)时,会分配池的初始块集。
void ObjectPool::Startup(RestartLevel level)
{
AllocBlocks();
}
而 AllocBlocks 创建由池的配置参数指定的块数。
增加对象池的大小
对象池的大小可以通过 CLI 命令 >cfgparms set 在运行时增加,该命令后面跟着一个键和值。
nb>cfgparms set NumOfMsgBuffers 4
这会导致调用以下内容:
void ObjectPoolSizeCfg::SetCurr()
{
CfgIntParm::SetCurr();
// If the pool contains no blocks, it is currently being constructed,
// so do nothing. But if it already contains blocks, expand its size
// to the new value.
//
if(pool_->currSegments_ > 0)
{
pool_->AllocBlocks();
}
}
减小对象池的大小
上面的 CLI 命令也用于减小对象池的大小。
nb>cfgparms set NumOfMsgBuffers 3
这再次导致调用 ObjectPoolSizeCfg::SetCurr。但是,当这次调用 AllocBlocks 时,什么也没发生。原因是对象池中的块是分段分配的,并且所有段都可能包含正在使用的块。因此,尽管缩小的尺寸已被记录,但它要等到重启释放所有现有块并重新分配它们才会生效。
命令行参数
尽管配置文件的读取发生在系统初始化非常早的阶段,但在某些情况下,在发生这种情况之前就需要一个可自定义的值。尽管这些情况很少见,但必须通过命令行参数来支持。
目前,RSC 唯一的命令行参数是定义保护堆大小的参数。该堆用于创建在系统运行时将被写入保护的对象。其中一些对象在读取配置文件之前创建,因此必须在此时间创建保护堆。因此,此堆的大小可以通过命令行参数进行自定义。
当进入 main 时,RSC 会将每个命令行参数保存在内存中,并立即对其进行写保护。这可以保护其值,并在需要时进行查找。请参阅 main.cpp 和 MainArgs.h。
统计
性能统计信息可以洞察系统的内部行为。这使得管理员可以:
- 验证系统是否按预期运行。
- 监控系统的吞吐量。
- 计算系统的峰值容量。
- 确定在峰值容量下运行时所需的资源数量。
- 发现意外行为。
单个性能统计信息的基类定义在 Statistics.h 中。
Statistic是所有统计信息的虚拟基类。它包含几个原子整数,用于支持该统计信息。Counter支持在事件发生时递增的统计信息。Accumulator支持在事件发生时将正值加到其中的统计信息。HighWatermark支持跟踪某个事物观察到的最高值的统计信息。LowWatermark支持跟踪某个事物观察到的最低值的统计信息。
创建统计信息时,会将其添加到全局 StatisticsRegistry。由于系统包含大量统计信息,因此每个统计信息还会被添加到 StatisticsGroup 中,其目的是一起显示相关统计信息。创建这些组之一时,也会将其添加到全局 StatisticsRegistry。
系统中的所有统计信息都报告在一个日志中,该日志默认每 15 分钟出现一次。在系统重启前也会生成一份报告。在进行此报告后,每个统计信息都会合并到一个“总体”值中,保存到“上一个”值中,最后清零,为下一个报告间隔做准备。因此,对于每个统计信息,可以看到以下值:
curr:其在当前报告间隔中到目前为止的值。prev:其在上一个报告间隔中的最终值。all:其跨所有报告间隔的总体值。
为了说明统计信息的使用,让我们回到对象池。每个池提供以下统计信息:
- 可用的最少块的
LowWatermark。 - 成功分配次数的
Counter。 - 释放次数的
Counter。 - 分配不成功次数(无可用块)的
Counter。 - 由审计恢复的被回收块数的
Counter。 - 池大小自动扩展次数的
Counter。 - 构造对象后,块中剩余的未使用字节数的
LowWatermark。
顺带一提,我记得有人告诉我提供内部可验证的统计信息是个错误!例如,如果有三个统计信息 A=B+C 应该始终成立,那么一个晦涩的错误可能会偶尔导致此恒等式不完全成立。这会让一些客户感到不安,并导致一个被夸大的重要性 bug 报告。
命令行界面命令
CLI 提供了 >stats 命令来访问统计信息。

列出所有统计信息组。

现在来看对象池统计信息。

没什么好看的。这是因为,默认情况下,报告是“简短”的,在这种情况下,仍处于初始状态的统计信息不会显示。系统刚刚初始化,因此只有一些 MsgBuffers(用于线程间通信)已被使用。但是,如果我们运行 POTS 呼叫的流量生成器来对系统进行一段时间的负载测试,我们可以看到更多的情况发生了。

创建统计信息
每个 Statistic 子类定义一个 typedef,该 typedef 使用 std::unique_ptr 包装统计信息。通过将一组相关统计信息定义为类的成员,然后将该类作为使用这些统计信息的类的成员来分配。
基类 Statistic 继承自 Dynamic,Dynamic 使用一个在大多数系统 重启(部分重新初始化)期间被释放的堆。因此,统计信息是动态分配的,因为大多数使用它们的类在释放其统计信息的重启中得以幸存。在这样的重启的关闭阶段,类必须将管理统计信息的指针置为 null。在启动阶段,它必须重新分配它们。这是与管理对象池统计信息相关的代码:
typedef std::unique_ptr<Counter> CounterPtr;
typedef std::unique_ptr<LowWaterMark> LowWatermarkPtr;
// Statistics for each object pool.
//
class ObjectPoolStats : public Dynamic
{
public:
ObjectPoolStats();
LowWatermarkPtr lowCount_;
CounterPtr allocCount_;
CounterPtr freeCount_;
CounterPtr failCount_;
CounterPtr auditCount_;
CounterPtr expansions_;
LowWatermarkPtr lowExcess_;
};
ObjectPoolStats::ObjectPoolStats()
{
lowCount_.reset(new LowWatermark("fewest remaining blocks"));
allocCount_.reset(new Counter("successful allocations"));
freeCount_.reset(new Counter("deallocations"));
failCount_.reset(new Counter("unsuccessful allocations"));
auditCount_.reset(new Counter("blocks recovered by audit"));
expansions_.reset(new Counter("number of times pool was expanded"));
lowExcess_.reset(new LowWatermark("size of block minus largest object"));
}
ObjectPool::ObjectPool(...) // lots of code deleted
{
stats_.reset(new ObjectPoolStats);
}
void ObjectPool::Shutdown(RestartLevel level)
{
// An object pool resides in protected memory. If the restart will free
// it, do nothing. If the restart will free the statistics, nullify the
// unique_ptr that manages them.
//
if(Restart::ClearsMemory(MemType())) return;
FunctionGuard guard(Guard_MemUnprotect);
Restart::Release(stats_);
}
void ObjectPool::Startup(RestartLevel level)
{
// If we don't have any statistics, they were freed during a restart, so
// reallocate them.
//
FunctionGuard guard(Guard_MemUnprotect);
if(stats_ == nullptr) stats_.reset(new ObjectPoolStats);
}
更新统计信息
每个 Statistic 子类提供一个用于更新其值的函数。
Counter::Incr()Accumulator::Add(size_t count)LowWatermark::Update(size_t count)HighWatermark::Update(size_t count)
因此,当对象池分配一个块时,更新关联的统计信息就像:
stats_->allocCount_->Incr();
日志
日志是系统提供状态更新的主要方式。有些日志突出了操作员可能能够修复的问题,而另一些则仅仅是信息性的。还有 软件日志,对操作员来说毫无意义,但有助于开发人员调试。
一个大型系统可以生成多种类型的日志,因此对其进行分类很有帮助。日志组包含与特定子系统相关的所有日志。例如,对象池有自己的日志组。RSC 的日志子系统定义了 LogGroup 类,每个实例注册一个简短的字符串来标识该组中的日志(例如,对象池相关日志的 OBJ)。
每个日志也按生成它的情况进行分类。无论它属于哪个组,它都使用 LogType 定义的枚举器之一来标识:
TroubleLog突出显示可能需要操作员干预才能解决的问题(100-199)。ThresholdLog表示已达到或超过某个级别(200-299)。StateLog报告状态更改或后台活动的进度(300-399)。PeriodicLog以固定间隔报告信息(例如,统计信息)(400-499)。InfoLog报告不需要干预的事件(500-699)。MiscLog是不属于上述类别的日志(700-899)。DebugLog被转发给开发人员以帮助调试(900-999)。
整数范围意味着,例如,给定日志组中的每个故障日志都使用 100-199 范围内的整数来唯一标识自己。日志的系统范围标识符通过在日志标识符后面加上其组来后缀。例如,OBJ200 必须是对象池的阈值日志;实际上,它是在池中可用块的数量低于定义阈值时生成的日志。
CLI 命令
CLI 提供了 >logs 命令来访问日志。

列出所有日志组,对象池定义的日志,然后查看其中一个日志的含义。

一些其他的日志命令在测试或日志洪泛期间使用。
count仅显示到目前为止生成的日志总数。suppress停止生成指定组中的所有日志。throttle只生成指定日志的第 n 次出现。
为了检查测试期间是否没有发生日志,脚本会使用 count 来比较测试前后报告的日志数量。如果某些日志在测试期间可能发生也可能不发生,throttle 或 suppress 将阻止其出现。后两个命令还用于在系统遇到日志洪泛时减少日志数量。
日志被放入日志缓冲区,直到写入日志文件,并在每次重启期间创建一个新的日志缓冲区。其余的日志命令管理日志缓冲区。
buffers指示哪些日志缓冲区包含日志;它还可以显示它们。write将缓冲区的待处理日志流式传输到其日志文件。free解除分配日志缓冲区。
日志会随着重启而保留,以便它们可以帮助调试系统启动的重启。尽管系统会尝试在重启期间将所有待处理日志写入日志文件,但这并非总是能成功。上述命令用于将待处理日志写入磁盘并释放任何不再需要的日志缓冲区。
定义日志
日志必须属于一个日志组,因此后者必须先创建。以下是定义对象池日志组及其各种日志的代码。
enum LogType
{
TroubleLog = 100, // 100-199: fault; intervention may be possible
ThresholdLog = 200, // 200-299: level reached or exceeded
StateLog = 300, // 300-399: state change or progress update
PeriodicLog = 400, // 400-499: automatic report
InfoLog = 500, // 500-699: no intervention required
MiscLog = 700, // 700-899: other types of logs
DebugLog = 900 // 900-999: to help debug software
};
constexpr LogId ObjPoolExpansionFailed = TroubleLog;
constexpr LogId ObjPoolBlocksInUse = ThresholdLog;
constexpr LogId ObjPoolExpanded = StateLog;
constexpr LogId ObjPoolQueueCorrupt = DebugLog;
constexpr LogId ObjPoolQueueCount = DebugLog + 1;
constexpr LogId ObjPoolBlockRecovered = DebugLog + 2;
constexpr LogId ObjPoolBlocksRecovered = DebugLog + 3;
fixed_string ObjPoolLogGroup = "OBJ";
auto group = new LogGroup(ObjPoolLogGroup, "Object Pools");
new Log(group, ObjPoolExpansionFailed, "Object pool expansion failed");
new Log(group, ObjPoolBlocksInUse, "Object pool blocks in use");
new Log(group, ObjPoolExpanded, "Object pool size expanded");
new Log(group, ObjPoolQueueCorrupt, "Object pool queue corrupt");
new Log(group, ObjPoolQueueCount, "Object pool queue count incorrect");
new Log(group, ObjPoolBlockRecovered, "Object pool block recovered");
new Log(group, ObjPoolBlocksRecovered, "Object pool blocks recovered");
LogGroup 构造函数将组注册到全局 LogGroupRegistry,而 Log 构造函数将日志注册到其 LogGroup。
生成日志
Log::Create 和 Log::Submit 函数用于在运行时生成日志。Create 分配并返回一个由 std::unique_ptr 包装的 std::ostringstream。这允许在提交日志之前添加日志特定的信息。Create 的参数如上面的代码所示,即标识日志组的字符串,后跟日志在其组内的标识符。
auto log = Log::Create(ObjPoolLogGroup, ObjPoolExpanded);
if(log != nullptr)
{
*log << Log::Tab << "pool=" << name_;
*log << " new segments=" << currSegments_;
Log::Submit(log);
}
每条日志都以 Create 插入的标准标题开始。标题包含日志的标识符、时间、系统名称以及自上次重启以来日志的序列号(第 12 条日志)。因此,上面的日志如下所示:

告警
当生成日志时,它还具有更新告警的能力。当操作员干预可能解决日志所强调的问题时,会触发告警。告警将保持活动状态,直到被清除,这发生在问题不再存在时。只有故障和阈值日志可以设置告警,但任何类型的日志都可以清除告警。
每个告警都有一个严重性级别:严重、主要、次要或关闭。清除告警的日志看起来像常规日志。但如果告警处于开启状态,则一个或多个星号会出现在标准日志标题之前,以指定告警的严重性:*** 表示严重,** 表示主要,* 表示次要告警。
CLI 命令
CLI 提供了 >alarms 命令来访问告警。
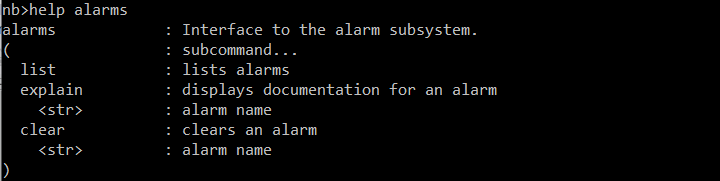
如果我们列出系统中的所有告警,会显示每个告警的状态,因此查找星号会告诉我们是否有告警处于活动状态。explain 命令提供有关告警的更多信息。

还有一个 clear 命令,用于在系统未能清除告警时重置告警。
定义告警
ObjectPool 构造函数调用 EnsureAlarm。
void ObjectPool::EnsureAlarm()
{
// If the high usage alarm is not registered, create it.
//
auto reg = Singleton<AlarmRegistry>::Instance();
auto alarmName = "OBJPOOL" + std::to_string(Pid());
alarm_ = reg->Find(alarmName);
if(alarm_ == nullptr)
{
auto alarmExpl = "High percentage of in-use " + name_;
FunctionGuard guard(Guard_ImmUnprotect);
alarm_ = new Alarm(alarmName.c_str(), alarmExpl.c_str(), 30);
}
}
由于告警是日志子系统的扩展,因此告警会随着重启而保留。但对象池不会,这就是为什么 EnsureAlarm 在创建告警之前会检查告警是否已存在。
要创建告警,必须提供其名称和简要说明,以及延迟(此处为 30 秒)。延迟用于滞后。告警的严重性可以立即增加,但直到延迟间隔过去后才会降低。没有这个延迟,快速变化的情况可能会导致日志洪泛。
触发告警
对象池通过调用以下方法来更新其告警:
void ObjectPool::UpdateAlarm()
{
// The alarm level is determined by the number of available blocks
// compared to the total number of blocks allocated:
// o critical: less than 1/32nd available
// o major: less than 1/16th available
// o minor: less than 1/8th available
// o none: more than 1/8th available
//
dyn_->delta_ = 0;
auto status = NoAlarm;
if(dyn_->availCount_ <= (dyn_->totalCount_ >> 5))
status = CriticalAlarm;
else if(dyn_->availCount_ <= (dyn_->totalCount_ >> 4))
status = MajorAlarm;
else if(dyn_->availCount_ <= (dyn_->totalCount_ >> 3))
status = MinorAlarm;
auto log = alarm_->Create(ObjPoolLogGroup, ObjPoolBlocksInUse, status);
if(log != nullptr) Log::Submit(log);
}
这类似于生成日志,但它使用 Alarm::Create 而不是 Log::Create,并且还提供告警的严重性级别。
每次从其池分配一个块或将其返回到其池时调用上述函数都会增加相当大的开销。因此,池维护一个运行计数(delta_),并且仅当可用块的数量净增加或减少 50 时才调用该函数。另请注意,Alarm::Create 返回 nullptr,除非应该实际生成日志(即,当告警的严重性发生变化且滞后延迟(如果适用)已过)。
当告警出现时,它看起来像一个常规日志,但前面有一个或多个星号。

跟踪工具
跟踪工具通过将各种类型的事件记录在缓冲区中来支持调试,该缓冲区的内容可以在停止跟踪后转储。RSC 的跟踪工具使用通用框架,以便来自所有启用工具的事件出现在一个集成的转储中,该转储按事件发生的时间顺序排列。
要在实时系统中使用跟踪工具,必须提供过滤器以显著减少要记录的事件数量。这可以防止系统减速到其响应时间变得不可接受的程度,也可以防止跟踪缓冲区很快被与正在调试的问题无关的事件填满。
当启用了对象池的跟踪工具时,它会在池的块被以下操作时记录一个事件:
- 分配
- 释放
- 认领(以防止其被对象池审计回收)
- 回收
RSC 还提供了许多其他跟踪工具。有关更多详细信息,请参阅 调试实时系统。
历史
- 2020 年 11 月 11 日:扩展统计信息部分;添加日志和告警部分。
- 2020 年 10 月 28 日:初始版本。