
通用警报处理程序 - 多线程的实际示例
4.95/5 (37投票s)
在本文的示例的帮助下,我试图解释一个实际的多线程应用程序设计。微软CLR Profiler工具已被用来深入了解正在发生的事情。重点放在通用模块的开发,因为它最大化了代码重用。
引言
最近,我一直在开发许多设备监控应用程序,在这些应用程序中我需要一个类似警报处理程序的模块。经过几次迭代,我得出了这个设计,并将在本文中与您分享。本文强调两个重要点;即多线程和构建可重用模块。
在计算机系统中,进程被认为是独立的单元。这是由操作系统管理的,以保护一个应用程序不受另一个应用程序的影响。两个进程通信的唯一途径是操作系统提供的进程间通信(IPC)机制。线程被定义为轻量级进程。多线程通过共享内存提供了一种并发的替代方法。但它仍然不是免费的;我们需要保护它们免受损坏并避免死锁。因此,多线程程序的开发和调试很困难。
在本文中,我将向您展示一个多线程的实际示例,以及如何对应用程序进行性能分析以获得更好的洞察。生活中最重要的范式之一是“眼见为实”。为了在这里遵循这一点,我将使用微软的免费工具CLR Profiler。我相信本文提供的讨论将有助于初学者理解多线程的复杂性,并在他们未来的项目中提供帮助。
本文的第二个方面是强调创建可重用模块。代码库的重用一直是任何软件项目的主要动机之一。为了重用代码,模块必须以特定的方式设计并加以特别关注。例如,以日志记录实用程序为例。众所周知,在每个应用程序中,日志记录实用程序都是我们应用程序基础设施的一部分。因此,我们必须设计日志记录模块并定义API,以便它可以在多个应用程序中重用,最好是不做任何更改。您将看到,我在本文中也使用了类似的日志记录模块(这是从Jeffrey Varszegi的NSpring Logging Library for .NET中提取的简化版本)。正如Marc Clifton在A Look At What's Wrong With Objects中所述,这里的想法是尽可能地在特定项目中增加“应用程序通用”组件。理想情况下,应该尝试扩展项目中的应用程序通用组件,以便在特定项目中实现最大的代码重用,如下面的图所示。

关于需求的简要说明
在我们的应用程序中,我们经常需要处理警报,并通过不同的渠道将消息传递给指定为目标响应者的相关人员,即负责管理设备(可能是远程地方,如工厂区域、住宅区或医院大楼等)的工程师。根据应用程序中维护的响应者数据库,警报通过不同的通知渠道传达给目标响应者。
在此上下文中,一些通知渠道的例子是
- SMS
- 电子邮件
- 控制台
- 警报器
- 大喇叭等。
在本文中,我将展示如何实现这样一个AlertHandler模块。我将使用.NET C#进行实现。AlertHandler处理所有应用程序生成的警报。然后,这些警报将作为消息通过电子邮件、短信发送,并通过警报器、大喇叭发出声音——警报还会以弹出对话框的形式出现在监控控制台上。
警报处理程序架构

设计方法
当警报消息到达时,警报可能需要传递到多个渠道。在构建此模块时,我首先设计一个名为AlertManager的协调器,它接收传入的警报并将其分派到适当的渠道。为了避免硬编码的“switch..case”分派逻辑,我将使用责任链设计模式。简单来说,AlertManager拥有一个包含所有已注册渠道处理程序的List,当接收到警报消息时,它会将消息传递给List中的每个处理程序。根据渠道类型,只有指定的处理程序会处理警报,其余的将忽略警报消息。
为了最大限度地减少与应用程序其他部分的耦合,同时在非阻塞异步模式下工作,并在处理过程中不丢失任何警报事件,我将假设警报在alertQueue中接收。然后,根据消息中指定的渠道,将它们从队列分派到适当的消息处理程序。在这个客户端-服务器设计中,我将使用发布/订阅设计模式。客户端,即渠道处理程序(如短信、控制台和电子邮件),可能会向AlertManager协调器注册它们处理警报的兴趣。然后,每个渠道处理程序都可以以自己的特定方式处理消息。
当应用程序初始化时,我们将只实例化一个AlertManager实例,但根据特定应用程序的配置渠道,我们将实例化不同的短信、控制台和电子邮件渠道处理程序。这些通常是通过从执行程序集(在此例中为AlertHandler.exe)中的基类型(在此例中为Handler)派生的类型,并使用基于.NET反射的动态工厂来实例化的。如果同一警报消息需要发送到多个渠道,那么alertQueue中将有多个消息条目,每个条目对应一个特定的渠道。
通过这种方法,您可以看到AlertManager无需提前了解响应者选择了哪个通信渠道,因此将来可以添加新的通信渠道而无需更改AlertManager的代码。
下图显示了AlertHandler模块中重要类的类图。

AlertManager提供了一种称为注册的机制。当短信、控制台和电子邮件渠道处理程序被构造和初始化时,它们作为启动过程的一部分向AlertManager注册自己,这样AlertManager就知道如何在新的警报消息到达时通知渠道处理程序对象。现在,当AlertManager接收到一个新的警报消息时,它会将alertMsg对象传递给所有已注册的处理程序,让它们有机会进行处理。如前所述,由于我实现了责任链模式,只有指定的渠道处理程序会根据警报消息中存在的渠道信息来处理新消息。以下几行说明了AlertManager类,它也实现了IDisposable接口。
AlertManager 类
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading;
namespace AlertHandler
{
public class AlertMsgContext
{
// Type defining information passed to receivers of the event
public AlertMsgContext(String from, String to, String subject,
String body, Common.AlertChannels channel)
{
this.from = from;
this.to = to;
this.subject = subject;
this.body = body;
this.channel = channel;
}
public readonly String from, to, subject, body;
public readonly Common.AlertChannels channel;
}
/// <summary>
/// The mediator in handling alert messages
/// </summary>
public class AlertManager : IDisposable
{
public AlertManager()
{
// Construct an instance of the AlertManager
}
/// <summary>
/// A dedicated thread is created to dequeue
/// </summary>
public void Initialize()
{
alertQueue = new Queue<alertmessage>(Common.startPoolSize);
handlers = new List<handler>();
nodeAdd = new ManualResetEvent(false);
alertDispatcher = new Thread(new ThreadStart(DequeueMsg));
alertDispatcher.Start();
}
public void EnqueueMsg(AlertMessage alertMessage)
{
alertQueue.Enqueue(alertMessage);
lock (eventLocker)
{
nodeAdd.Set();
}
}
/// <summary>
/// Method responsible for notifying registered handlers
/// </summary>
private void OnAlertMsg(AlertMsgContext context)
{
// Has any object registered interest with our event?
foreach (Handler ah in handlers)
{
if (ah.HandleMsg(context))
{
break; // break the loop as it is handled
}
}
}
/// <summary>
/// First construct an object to hold the information I want
/// and pass to the receivers of this notification
/// </summary>
private void TriggerAlertEvent(String from, String to,
String subject, String body,
Common.AlertChannels channel)
{
AlertMsgContext context =
new AlertMsgContext(from, to, subject, body, channel);
OnAlertMsg(context);
}
/// <summary>
/// This method is called when an alert has been dequeued
/// </summary>
private void HandleMessage(AlertMessage alertMessage)
{
TriggerAlertEvent(alertMessage.recipient, alertMessage.backupRecipient,
"Controller ID - " + alertMessage.controllerID + " " +
"Device ID - " + alertMessage.deviceID + " "
+ alertMessage.category.ToString(), alertMessage.detailedMessage,
alertMessage.channel);
}
private void DequeueMsg()
{
bool empty = false;
AlertMessage alertMessage = null;
while (nodeAdd.WaitOne())
{
while (alertQueue.Count > 0)
{
alertMessage = alertQueue.Dequeue(ref empty);
if (alertMessage == default(AlertMessage))
{
return;
}
else
{
HandleMessage(alertMessage);
}
}
lock (eventLocker)
{
//to handle the scenario, let's say de-queue thread consumed all
//messages and about to reset the event. Before that another message
//dropped in and locked the object. Now de-queue thread is waiting for
//lock. Particular enqueue thread now adds a message, sets the event
//and releases the lock. Now de-queue thread will get the lock and if
//we would not have checked the alertQueue.Count it would have reset
//the event and now we will fail to process the newly added message, until
//another message is added.
if (0 == alertQueue.Count)
{
nodeAdd.Reset();
}
}
}
}
public void Register(Handler ah)
{
handlers.Add(ah);
}
public void UnRegister(Handler ah)
{
handlers.Remove(ah);
}
private void ClearHandlers()
{
for (int i = 0; i < handlers.Count; i++)
{
handlers[i].Dispose();
}
handlers.Clear();
handlers = null;
}
private void ClearQueue()
{
alertQueue.Clear();
alertQueue = null;
}
/// <summary>
/// Implementing IDisposable pattern
/// </summary>
protected virtual void Dispose(bool disposing)
{
if(!disposed && disposing)
{
alertDispatcher.Abort();
ClearHandlers();
ClearQueue();
nodeAdd.Close();
disposed = true;
}
}
public void Dispose()
{
Dispose(true);
// This object will be cleaned up by the Dispose method.
// Therefore, we call GC.SupressFinalize to
// take this object off the finalization queue
// and prevent finalization code for this object
// from executing a second time.
GC.SuppressFinalize(this);
}
#region Declarations
private Queue<alertmessage> alertQueue = null;
private List<handler> handlers = null;
private Thread alertDispatcher = null;
private ManualResetEvent nodeAdd = null;
private readonly object eventLocker = new object();
private bool disposed = false;
#endregion
}
}
您可以看到,在AlertManager中,我们定义了一个名为OnAlertMsg的方法,负责通知已注册的处理程序警报事件。当新的警报从alertQueue中被AlertManager中的专用线程出列(即读取)时,就会调用OnAlertMsg方法。该方法接收一个已初始化的AlertMsgContext对象,其中包含有关事件的附加信息。在AlertManager的线程回调方法DequeueMsg中,警报会在警报提取循环中从alertQueue中清空,并通过HandleMessage调用OnAlertMsg。
Handler 抽象类
对于不同的渠道处理程序,我们首先定义一个abstract类Handler,每个处理程序类型都应该实现它。Handler中的第一个方法是Register,它将特定的渠道处理程序注册到AlertManager,表明对alertMessage感兴趣。这对于不同的处理程序是相同的,因此它保留在基类Handler中。Handler中的第二个方法是HandleMsg,它负责实际处理警报消息,并且根据渠道类型而不同,因此它是virtual的。此方法负责渠道特定的警报消息渲染以及任何通信协议处理。第三个方法是UnRegister,它简单地取消注册,从而从AlertManager的已注册处理程序List中删除条目。Handler类还实现了IDisposable接口。
using System;
using System.Collections.Generic;
using System.Text;
namespace AlertHandler
{
/// <summary>
/// Disposable abstract base class for all channel handlers
/// </summary>
public abstract class Handler : IDisposable
{
public void Register()
{
// after instantiation register with Alert Manager.
aManager = App.GetAM();
aManager.Register(this);
}
public virtual bool HandleMsg(AlertMsgContext context)
{
return false;
}
/// <summary>
/// Unregister myself with AlertManager
/// </summary>
public void UnRegister()
{
aManager.UnRegister(this);
}
/// <summary>
/// Implementing IDisposable pattern
/// </summary>
protected virtual void Dispose(bool disposing)
{
if (!disposed && disposing)
{
aManager = null;
disposed = true;
}
}
public void Dispose()
{
Dispose(true);
// This object will be cleaned up by the Dispose method.
// Therefore, we call GC.SupressFinalize to
// take this object off the finalization queue
// and prevent finalization code for this object
// from executing a second time.
GC.SuppressFinalize(this);
}
#region Declarations
private AlertManager aManager = null;
private bool disposed = false;
#endregion
}
}
SMS 类
下面列出了一个已实现的SMS示例渠道处理程序类
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading;
namespace AlertHandler
{
class SMS : Handler
{
public SMS()
{
// Construct an instance of the SMSMsgEventHandler
}
/// <summary>
/// This is the method that the AlertManager will call to
/// notify the SMS object that a new message has arrived
/// Implementing Chain of Responsibility pattern
/// </summary>
public override bool HandleMsg(AlertMsgContext context)
{
bool result = false;
if (context.channel == Common.AlertChannels.SMS)
// I will work only if it is for me
{
result = true;
if (ThreadPool.QueueUserWorkItem(new WaitCallback(SendMessage), context))
{
Console.WriteLine("Queued the work for ThreadPool request in SMS...");
}
else
{
Console.WriteLine("Unable to queue ThreadPool request in SMS...");
}
}
return result;
}
/// <summary>
/// Wrapper method for use with thread pool.
/// 'arguments' identifies the additional event information
/// that the AlertManager wants to give us.
/// </summary>
private void SendMessage(object arguments)
{
// Normally, the code here would SMS the Alert message like using
// pagegate third party software
// This test implementation displays the info on the console and also logs for audit
AlertMsgContext messageArguments = arguments as AlertMsgContext;
Console.WriteLine("SMS message:");
Console.WriteLine(
" To: {0}\n From: {1}\n Subject: {2}\n Body: {3}\n",
messageArguments.from, messageArguments.to, messageArguments.subject,
messageArguments.body);
App.FileLog("SMS message:", messageArguments.from + " " + messageArguments.to
+ " " + messageArguments.subject + " " + messageArguments.body);
}
}
}
当应用程序初始化时,它会首先构造一个AlertManager对象。与AlertManager一起,渠道处理程序也根据应用程序配置进行构造。在启动过程中,渠道处理程序将向AlertManager注册,这本质上意味着它们的引用会被添加到AlertManager维护的容器列表中。当SMS警报消息到达时,在出列后,AlertManager会调用其自身的OnAlertMsg,并将消息传递给每个已注册的处理程序。每个渠道处理程序将验证队列中的警报数据结构中存在的渠道类型,只有SMS处理程序才会处理此警报消息。
处理程序的HandleMsg有一个参数,该参数是对AlertMsgContext对象的引用。此对象包含对特定渠道处理程序有用的附加信息。从AlertMsgContext对象中,SMS处理程序可以访问与AlertMsg相关的以下信息:
controllerIDdeviceIDcategorydetailedMessage和recipient
在实际的SMS实现中,这些信息将使用recipient字段作为SMS发送到接收者的手机。在本示例代码中,为了说明起见,这些信息仅显示在控制台窗口中。
注意:请注意,这里我们使用了.NET的System.Threading命名空间中的ThreadPool类。线程池是为了提高效率而设计的,特别是当线程任务的执行时间与操作系统启动和销毁线程的时间相当时。如果您查看此类,您会发现所有成员都是static的,并且没有public构造函数。这是因为每个进程只有一个线程池,我们无法创建新的线程池。
详细数据结构
public enum AlertChannels
{
Console = 1,
Email,
SMS,
Siren,
Unknown
}
public enum ExceptionType
{
Fire = 1,
Leakage,
NoFuel,
HighVoltage,
HighPressure,
HighTemparature,
NoWater,
LowVoltage,
LowPressure,
HighCurrent,
LowCurrent,
SinglePhase,
FailedToStart,
CommunicationFailed,
Unknown
}
}
警报是根据ExceptionType、设备类型(包括Tele-Controller、Water Pump、Diesel-Generator、Air-Conditioner、Halogen-Lights和Fans等)以及它们在监控区域中的战略位置而生成的基于规则的动作的一部分。
public class AlertMessage
{
public String controllerID = null;
//Static IP address of the Telecontroller
public String deviceID = null;
//MacID of the device
public Common.ExceptionType category;
//this is the ExceptionType
public String detailedMessage = null;
//IDs will get translated with shortnames so that they become human
//readable
public Common.AlertChannels channel;
//based on this, the message will be dispatched to specific channel
//handler by the Alert manager
public String recipient = null;
//user ID of the responder
public String backupRecipient = null;
//backup user ID usually the supervisor of the responder
}
应用程序生成的警报由设备监控线程插入队列,AlertManager的专用线程将其出列并调用其自身的HandleMessage – 然后根据渠道类型,相应的渠道处理程序将发送警报。AlertManager还可以在分派警报给已注册渠道之前记录警报。渠道处理程序自身会记录任何异常——例如,在电子邮件发送失败的情况下。
重要概念
发布/订阅设计模式
在基于发布/订阅设计模式(也称为观察者模式)的系统中,订阅者注册他们对事件或事件模式的兴趣,并异步接收由发布者生成的事件通知。在我们的示例中,发布者是生成警报的各种设备监控线程,订阅者是发送警报给适当响应者的特定渠道处理程序。使用此模式,我们实现了各种解耦(参见发布/订阅的多种面孔),以实现可测试和可维护的代码。解耦还通过允许参与者独立运行来强制实现抽象层面的可伸缩性。即这里的解耦是:
空间解耦:发布者不持有订阅者的引用;它们也不知道有多少订阅者参与了交互。同样,订阅者也不持有发布者的引用;它们也不知道有多少发布者参与了交互。
时间解耦:通过消息队列的添加,发布者和订阅者不必同时参与交互。
同步解耦:消息的生产和消费不会发生在发布者和订阅者的主要控制流中,因此也不会以阻塞的方式发生。所以发布者和订阅者独立工作。
责任链设计模式
我们在AlertManager和已注册渠道处理程序之间的交互中使用了此模式。当警报消息从alertQueue中出列时,我们使用此模式来避免AlertManager和渠道处理程序之间的耦合,让一个以上的处理程序有机会验证消息。换句话说,我们将订阅者对象链式连接起来,并将消息沿着链传递,直到某个对象处理它。因此,AlertManager无需知道将哪个警报消息传递给哪个渠道处理程序。渠道处理程序根据AlertMessage数据结构中的字段(渠道类型)自行决定是否处理该消息。这是开放/封闭原则的一个例子。通过在责任链(已注册警报处理程序列表)中添加处理程序,可以在不修改AlertManager代码的情况下改变系统的行为。
动态工厂设计模式
工厂模式将对象构造与代码的其余部分分离。然而,它仍然存在耦合,尽管这种耦合局限于工厂类。如果我们使用.NET反射在工厂模式中,那么我们就可以克服这些依赖关系,这些依赖关系被称为“switch..case”形式的硬编码耦合,就像在具体工厂模式中那样。HandlerFactory类利用了动态工厂的这一概念。以下是HandlerFactory类和TypeExtractor类实现的源代码列表。
HandlerFactory 类
using System;
using System.Collections.Generic;
using System.Reflection;
namespace AlertHandler
{
/// <summary>
/// Dynamic Factory to create a handler instance
/// </summary>
public class HandlerFactory
{
/// <summary>
/// Usage - Object instance = App.CreateInstance(classType);
/// </summary>
public Handler CreateHandler(Type classType)
{
Handler ah = null;
if (classType != null)
{
// Create an instance of an object.
try
{
ah = Activator.CreateInstance(classType) as Handler;
}
catch (Exception e)
{
App.FileLog("<HandlerFactory><CreateHandlerFromTypes>",
"Error creating object instance of type: " +
classType.ToString() + " " + e.Message);
}
}
return ah;
}
}
}
TypeExtractor 类
using System;
using System.Collections.Generic;
using System.Reflection;
namespace AlertHandler
{
/// <summary>
/// Helper class to Dynamic Factory to create a handler instance
/// </summary>
public class TypeExtractor
{
public static List<Type> GetAllHandlerTypes()
{
List<Type> chnlTypes = null;
Type[] typeArray = null;
try
{
Assembly assembly = Assembly.GetExecutingAssembly();
typeArray = assembly.GetTypes();
chnlTypes = new List<Type>();
foreach (Type type in typeArray)
{
if (type.BaseType.Equals(assembly.GetType
("AlertHandler.Handler", true)))
{
chnlTypes.Add(type);
}
}
}
catch (Exception e)
{
App.FileLog("<TypeExtractor><GetAllHandlerTypes>",
"Error getting Handler types, " + e.Message);
}
return chnlTypes;
}
}
}
对象池
我们都知道,在.NET中,已释放的对象由.NET框架进行垃圾回收。我们不必担心我们是否在代码中使用了精确的new() – delete()对。这很好,但我们仍然需要承担垃圾回收的成本。因此,当我们反复使用同一类型的对象时,对象池技术允许我们重用已释放的对象,从而避免垃圾回收(GC)开销。在此实现中,对象被池化到一个链表数据结构中,该数据结构使用无锁算法实现。下面的代码演示了用于将对象获取和添加到池中的无锁链表操作 - (从… Managed I/O Completion Ports (IOCP) - Part 2 by P.Adityanand)中提取并泛型化)。
现在停下来讨论一下为什么使用无锁结构?这是因为当我们的应用程序在多处理器环境中运行时(这在当今的PC硬件中很普遍),如果我们使用锁来保护多个线程之间的共享内存,可能会由于锁竞争而降低性能。我们这里使用的共享内存池是一个单向链表数据结构,带有头部和尾部指针。
无锁算法的工作方式如下:
- 节点仅在链表的最后一个节点之后使用尾部指针添加。
- 节点始终使用头部指针从链表开头移除。
- 为了获得各种指针的一致值,我们依赖于一系列读取操作,这些操作会重新检查早期值以确保它们未更改(请参阅非阻塞链表的实用实现)。
在此实现中,我们使用了比较并交换(CAS),这是多线程应用程序上下文中一个非常熟悉的术语。在.NET中,它在System.Threading命名空间中的Interlocked.CompareExchange方法中实现。它允许我们在单个原子线程安全操作中比较两个值,并将其中一个值更新为新值。
注意:原子操作意味着该操作不能与其他线程操作交错。
using System;
using System.Threading;
using System.Reflection;
namespace AlertHandler
{
/// <summary>
/// Defines a factory interface to be implemented by classes
/// that creates new poolable objects
/// </summary>
public abstract class PoolableObjectFactory<T>
{
/// <summary>
/// Create a new instance of a poolable object
/// </summary>
/// <returns>Instance of user defined PoolableObject derived
/// type</returns>
public abstract PoolableObject<T> CreatePoolableObject();
}
/// <summary>
/// Poolable object type. One can define new poolable types by deriving
/// from this class.
/// </summary>
public class PoolableObject<T>
{
/// <summary>
/// Default constructor. Poolable types need to have a no-argument
/// constructor for the poolable object factory to easily create
/// new poolable objects when required.
/// </summary>
public PoolableObject()
{
Initialize();
}
/// <summary>
/// Called when a poolable object is being returned from the pool
/// to caller.
/// </summary>
public virtual void Initialize()
{
LinkedObject = null;
}
/// <summary>
/// Called when a poolable object is being returned back to the pool.
/// </summary>
public virtual void UnInitialize()
{
LinkedObject = null;
}
internal PoolableObject<T> LinkedObject;
}
/// <summary>
/// Lock Free ObjectPool
/// </summary>
public class ObjectPool<T>
{
/// <summary>
/// Creates a new instance of ObjectPool
/// </summary>
/// <param name="pof">Factory class to be used by ObjectPool to
/// create new poolable object instance when required.</param>
public ObjectPool(PoolableObjectFactory<T> pof, bool bCreateObjects)
{
_pof = pof;
_bCreateObjects = bCreateObjects;
Init(0);
}
/// <summary>
/// Creates a new instance of ObjectPool with n-number of pre-created
/// objects in the pool.
/// </summary>
/// <param name="pof">Factory class to be used by ObjectPool to
/// create new poolable object instance when required.</param>
/// <param name="objectCount">Numberof objects to pre-create</param>
public ObjectPool(PoolableObjectFactory<T> pof,
bool bCreateObjects, long objectCount)
{
_pof = pof;
_bCreateObjects = bCreateObjects;
Init(objectCount);
}
/// <summary>
/// Add the poolable object to the object pool. The object is
/// uninitialized before adding it to the pool.
/// </summary>
/// <param name="newNode">PoolableObject instance</param>
public void AddToPool(PoolableObject<T> newNode)
{
newNode.UnInitialize();
PoolableObject<T> tempTail = null;
PoolableObject<T> tempTailNext = null;
do
{
tempTail = _tail;
tempTailNext = tempTail.LinkedObject
as PoolableObject<T>;
if (tempTail == _tail)
{
if (tempTailNext == null)
{
// If the tail node we are referring to is really the last
// node in the queue (i.e. its next node is null), then
// try to point its next node to our new node
// We have used Compare and Swap (CAS) which is a very familiar term
// in the context of multi-threaded applications. It allows us to
// compare two values, and update one of them with a new value, all in
// a single atomic thread-safe operation.
if (Interlocked.CompareExchange
<poolableobject<t>>(ref tempTail.LinkedObject,
newNode, tempTailNext)
== tempTailNext)
{
break;
}
}
else
{
// This condition occurs when we have failed to update
// the tail's next node. And the next time we try to update
// the next node, the next node is pointing to a new node
// updated by other thread. But the other thread has not yet
// re-pointed the tail to its new node.
// So we try to re-point to the tail node to the next node of the
// current tail
Interlocked.CompareExchange<poolableobject<t>>
(ref _tail, tempTailNext, tempTail);
}
}
} while (true);
// If we were able to successfully change the next node of the current
// tail node to point to our new node, then re-point the tail node also
// to our new node
Interlocked.CompareExchange<poolableobject<t>>(ref _tail, newNode, tempTail);
Interlocked.Increment(ref _count);
}
/// <summary>
/// Returns an existing object from the pool or creates a
/// new object if the pool is empty. If an existing object is being
/// returned it is initialized before returned to the caller.
/// </summary>
/// <returns>PoolableObject instance</returns>
public PoolableObject<T> GetObject()
{
bool empty = false;
PoolableObject<T> tempTail = null;
PoolableObject<T> tempHead = null;
PoolableObject<T> tempHeadNext = null;
do
{
tempHead = _head;
tempTail = _tail;
tempHeadNext = tempHead.LinkedObject
as PoolableObject<T>;
if (tempHead == _head)
{
// There may not be any elements in the queue
if (tempHead == tempTail)
{
if (tempHeadNext == null)
{
// If the queue is really empty come out of dequeue operation
empty = true;
break;
}
else
{
// Some other thread could be in the middle of the
// enqueue operation. it could have changed the next node of the tail
// to point to the new node. So let us advance the tail node to point
// to the next node of the current tail
Interlocked.CompareExchange
<poolableobject<t>>
(ref _tail, tempHeadNext, tempTail);
}
}
else
{
// Move head one element down.
// If succeeded Try to get the data from head and
// break out of the loop.
if (Interlocked.CompareExchange
<poolableobject<t>>
(ref _head, tempHeadNext, tempHead) == tempHead)
{
break;
}
}
}
} while (true);
if (empty == false)
{
Interlocked.Decrement(ref _count);
tempHead.Initialize();
}
else
{
if (_bCreateObjects == true)
{
tempHead = _pof.CreatePoolableObject();
}
}
return tempHead;
}
/// <summary>
/// Removes all the poolable objects from the pool.
/// </summary>
public void Clear()
{
Clear(0);
}
/// <summary>
/// Removes all the poolable objects from the pool. And fills the pool
/// with n-number of pre-created objects
/// </summary>
public void Clear(long objectCount)
{
_count = 0;
Init(objectCount);
}
/// <summary>
/// Count of poolable objects in the pool
/// </summary>
public long Count
{
get
{
return _count;
}
}
private void Init(long objectCount)
{
_head = _tail = _pof.CreatePoolableObject();
if (objectCount > 0)
{
for(int count=1; count<=objectCount; count++)
{
AddToPool(_pof.CreatePoolableObject());
}
}
}
#region Declarations
private PoolableObject<T> _head = null;
private PoolableObject<T> _tail = null;
private long _count = 0;
private bool _bCreateObjects = false;
private PoolableObjectFactory<T> _pof = null;
#endregion
}
}
无锁队列
使用与对象池相同的无锁算法,我们实现了Queue。我们这里使用的Queue基于.NET泛型,因为我们在应用程序的其他部分需要不同消息结构的队列(从而重用了Queue类)。请注意,一旦节点使用头部指针从Queue中出列,它就会被添加到池中以供将来重用。
此实现的其余部分与P.Adityanand的Managed I/O Completion Ports (IOCP) - Part 2中给出的相同。
using System;
using System.Threading;
namespace AlertHandler
{
/// <summary>
/// Factory class to create new instances of the Node type
/// </summary>
class NodePoolFactory<T> : PoolableObjectFactory<T>
{
/// <summary>
/// Creates a new instance of poolable Node type
/// </summary>
/// <returns>New poolable Node object</returns>
public override PoolableObject<T> CreatePoolableObject()
{
return new Node<T>();
}
}
/// <summary>
/// Internal class used by all other data structures
/// </summary>
class Node<T> : PoolableObject<T>
{
public Node()
{
Init(default(T));
}
public Node(T data)
{
Init(data);
}
public override void Initialize()
{
Init(default(T));
}
private void Init(T data)
{
Data = data;
NextNode = null;
}
public T Data;
public Node<T> NextNode;
}
/// <summary>
/// Lock Free Queue
/// </summary>
public class Queue<T>
{
/// <summary>
/// Creates a new instance of Lock-Free Queue
/// </summary>
public Queue()
{
Init(0);
}
/// <summary>
/// Creates a new instance of Lock-Free Queue with n-number of
/// pre-created nodes to hold objects queued on to this instance.
/// </summary>
public Queue(int nodeCount)
{
Init(nodeCount);
}
public void Enqueue(T data)
{
Node<T> tempTail = null;
Node<T> tempTailNext = null;
Node<T> newNode = _nodePool.GetObject()
as Node<T>; //new Node(data);
newNode.Data = data;
do
{
tempTail = _tail;
tempTailNext = tempTail.NextNode as Node<T>;
if (tempTail == _tail)
{
if (tempTailNext == null)
{
// If the tail node we are referring to is really the last
// node in the queue (i.e. its next node is null), then
// try to point its next node to our new node
// CAS will compare the object reference value pointed to by the first
// parameter, with that of the comparand, which is the third parameter,
// and will make the first variable point to the object specified in
// the second parameter.
if (Interlocked.CompareExchange
<node<t>>(ref tempTail.NextNode,
newNode, tempTailNext) == tempTailNext)
break;
}
else
{
// This condition occurs when we have failed to update
// the tail's next node. And the next time we try to update
// the next node, the next node is pointing to a new node
// updated by other thread. But the other thread has not yet
// re-pointed the tail to its new node.
// So we try to re-point to the tail node to the next node of the
// current tail
//
Interlocked.CompareExchange<node<t>>
(ref _tail, tempTailNext, tempTail);
}
}
} while (true);
// If we were able to successfully change the next node of the current
// tail node to point to our new node, then re-point the tail node also
// to our new node
//
Interlocked.CompareExchange<node<t>>(ref _tail, newNode, tempTail);
Interlocked.Increment(ref _count);
}
public T Dequeue(ref bool empty)
{
T data = default(T);
Node<T> tempTail = null;
Node<T> tempHead = null;
Node<T> tempHeadNext = null;
do
{
tempHead = _head;
tempTail = _tail;
tempHeadNext = tempHead.NextNode;
if (tempHead == _head)
{
// There may not be any
// elements in the queue
//
if (tempHead == tempTail)
{
if (tempHeadNext == null)
{
// If the queue is really empty come out of dequeue operation
empty = true;
return default(T);
}
else
{
// Some other thread could be in the middle of the
// enqueue operation. it could have changed the next node of the tail
// to point to the new node.
// So let us advance the tail node to point to the next node of the
// current tail
Interlocked.CompareExchange
<node<t>>(ref _tail, tempHeadNext, tempTail);
}
}
else
{
// Move head one element down.
// If succeeded Try to get the data from head and
// break out of the loop.
//
if (Interlocked.CompareExchange
<node<t>>(ref _head, tempHeadNext, tempHead) == tempHead)
{
data = tempHeadNext.Data;
break;
}
}
}
} while (true);
Interlocked.Decrement(ref _count);
tempHead.Data = default(T);
_nodePool.AddToPool(tempHead);
return data;
}
public void Clear()
{
Init(_count);
}
//public void Clear(int nodeCount)
//{
// Init(nodeCount);
//}
public long Count
{
get
{
return Interlocked.Read(ref _count);
}
}
private void Init(long nodeCount)
{
_count = 0;
if (_nodePool != null)
{
_nodePool.Clear(nodeCount);
}
else
{
_nodePool = new ObjectPool<T>(new NodePoolFactory<T>(), true, nodeCount);
_head = _tail = _nodePool.GetObject() as Node<T>;
}
}
#region Declarations
private Node<T> _head;
private Node<T> _tail;
private long _count = 0;
private ObjectPool<T> _nodePool = null;
#endregion
}
}
性能分析和深入了解
测试和调试多线程应用程序是一项重要工作。如前所述,除非经过验证,否则您无法相信任何事情。在本节中,我们将简要了解如何对多线程应用程序进行性能分析,以更深入地了解其运行细节。
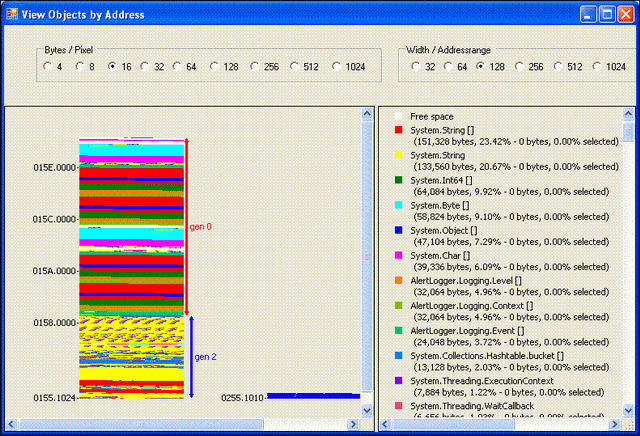
在上一篇文章中,我使用了微软的Fiddler工具来了解ASP.NET应用程序中的网络流量。在这里,我将使用CLR-Profiler工具来查看多线程应用程序中正在发生的事情。使用方法和各种解释在从下载站点提供的“CLRProfiler.doc”中给出。如何使用CLR Profiler文档也是快速掌握其用法的好资料。使用此工具,我们可以找到诸如堆分配和去分配统计信息、GC需要多长时间来释放分配的堆内存、应用程序中谁调用了谁(作为调用堆栈)等问题的答案。
以下是在具有Intel Pentium Dual CPU、T2390 @ 1.86 GHz、1.99 GB RAM和.NET Framework 2.0配置的笔记本电脑上测试的AlertHandler的重要屏幕截图。






结论
为了防止共享内存损坏,多线程编程中的同步锁总是伴随着代价。我们需要非常小心,以避免死锁以及由于缺乏同步而导致的损坏。随着PC硬件中多核CPU的出现,这些锁的争用会降低应用程序的整体性能。由于死锁和争用等问题,设计可伸缩的锁策略非常困难。
在本文中,我使用了经过验证的无锁算法来实现队列,并且仅对设置或重置ManualRestEvent对象等简短任务使用锁。Keir Fraser和Tim Harris在他们的论文《Concurrent Programming Without Locks》中描述了通过使用无锁算法实现高吞吐量。请参考这篇论文。
此外,本文还展示了各种正在使用的设计模式,这些模式可以减少软件组件之间的耦合,并生成可测试和可维护的代码,从而使其可重用。我们都知道代码重用可以提高生产力和代码质量。然而,正如本文所述,需要进行一些准备才能重用代码库,这并非免费。很多时候,由于时间限制,在项目执行周期中无法关注这方面。关注这一点的最佳时机是在项目结束时,当我们希望收集刚刚完成项目的各种质量和生产力指标时。通过一些迭代,如果我们能在项目结束时管理好一些可重用模块,这对于整个团队来说将是一项额外的成就,并为未来的客户增加了质量价值。
最后,我使用了一个免费的性能分析工具来分析多线程应用程序,并展示了通过运行示例应用程序AlertHandler并使用该工具的各种选项截取的屏幕截图。这些视图帮助我们理解该应用程序的运行方式以及如何提高性能。对象是如何分配和垃圾回收的,以及是否存在内存泄漏。
与所有软件项目一样,这种设计方法并不是解决此特定问题的唯一方法。可能有其他设计方法,特别是我想提到使用.NET事件和委托作为这里使用的发布/订阅设计模式的替代方案。然而,我想使用一个单一的专用调度线程,因为这种方法为我们提供了一种查看队列以进行测试和调试的方式。
我将非常感谢您的反馈评论。祝您编码和实验愉快!
参考文献
- Marc Clifton 的《A Look At What's Wrong With Objects》
- Marius Marais 的《Who cares about Domain Rules》
- Patrick Th. Eugster、Pascal A. Felber、Rachid Guerraoui、Anne-Marie Kermarrec 的《The Many Faces of Publish/Subscribe》
- Jeremy D. Miller 的《Using the Chain of Responsibility Pattern》
- Romi Kovacs 的《Creating Dynamic Factories in .NET Using Reflection》
- P.Adityanand 的《Managed I/O Completion Ports (IOCP) - Part 2》
- Timothy L. Harris (剑桥大学计算机实验室) 的《A Pragmatic Implementation of Non-Blocking Linked-Lists》
- Maged M. Michael、Michael L. Scott (罗切斯特大学计算机科学系) 的《Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms》
- Keir Fraser 和 Tim Harris 的《Concurrent Programming Without Locks》
- Vance Morrison 的《What every Dev must know about multi-threaded Apps》
- Sacha Barber 的《Beginners Guide To Threading In .NET Part 1 of n》
- Ajay Vijayvargiya 的《The Practical Guide to Multithreading Part 1》
- David Carmona 的《Programming the Thread Pool in the .NET Framework》
- Shameem Akhter 和 Jason Roberts 的《Multi-threaded Debugging Techniques》
- Jeffrey Varszegi 的《Logging Library for .NET》
- 微软的CLR Profiler工具
- 如何使用CLR Profiler
致谢
我必须感谢我以前的同事Parashar Satpute先生,他帮助我实现了AlertHandler模块的最终版本。他提供了许多见解、解释和本文中使用的实现技术,我发现它们非常有用。没有他的帮助,我认为我无法完成这篇文章。
历史
- 初稿提交于 2010年8月17日
- 2010年8月18日进行了小的文本修改