
使用Elasticsearch和C#实现CRUD应用程序的入门教程 - 第二部分
4.93/5 (12投票s)
Elasticsearch和C#集成。
引言
在第一部分中,我们学习了如何设置、配置和运行一系列 Elastic 语句。现在,是时候将其转换成一个功能完备的 C# CRUD 应用程序了。让我们开始吧。
创建一个演示应用程序
第一步,创建一个新的 Windows Form 解决方案。你可以在这里下载,它看起来是这样的:

其中高亮显示的引用是red最重要的,你可以通过 NuGet 获取它们。正如名称所示,NEST 和 Elasticsearch 的 DLL 是 Elasticsearch 的 .NET 抽象层。
在我写这篇文章的时候,官方文档明显已经过时了。不管怎样,你可以在这里访问它:http://nest.azurewebsites.net/。
全部蓝色区域是我组织项目的方式。这很标准:BLL 代表业务规则层(Business Rules),DAL 代表数据访问层(Data Access Layer),DTO 包含实体(Entities),而 View 则存放我们的 Windows Form。
通过 NEST 连接 Elastic
按照我所展示的抽象结构,我们的数据访问层非常简单:
namespace Elastic_CRUD.DAL
{
/// Elastic client
public class EsClient
{
/// URI
private const string ES_URI = "https://:9200";
/// Elastic settings
private ConnectionSettings _settings;
/// Current instantiated client
public ElasticClient Current { get; set; }
/// Constructor
public EsClient()
{
var node = new Uri(ES_URI);
_settings = new ConnectionSettings(node);
_settings.SetDefaultIndex(DTO.Constants.DEFAULT_INDEX);
_settings.MapDefaultTypeNames(m => m.Add(typeof(DTO.Customer),
DTO.Constants.DEFAULT_INDEX_TYPE));
Current = new ElasticClient(_settings);
Current.Map(m => m.MapFromAttributes());
}
}
}
名为 “Current” 的属性是对 Elastic REST 客户端的抽象。所有的 CRUD 命令都将通过它来完成。另一个重要的部分是 “Settings”,我将所有的配置键都集中在一个简单的类中:
/// System constant values
public static class Constants
{
/// Elastic index name
public const string DEFAULT_INDEX = "crud_sample";
/// Elastic type of a given index
public const string DEFAULT_INDEX_TYPE = "Customer_Info";
/// Basic date format
public const string BASIC_DATE = "yyyyMMdd";
}
如你所见,所有名称都指向我们在本文第一部分创建的存储。
第 1 组(索引、更新和删除)
我们将把之前学到的 Elastic 语句在这个 WinForm 应用程序中复现出来。为了组织好它,我为每一组功能设置了一个选项卡,总共有五个:

如你所见,第一个选项卡将负责添加、更新和删除客户。因此,客户实体是一个非常重要的部分,它必须使用 NEST 的装饰器(decoration)进行正确映射,如下所示:
/// Customer entity
[ElasticType(Name = "Customer_Info")]
public class Customer
{
/// _id field
[ElasticProperty(Name="_id", NumericType = NumberType.Long)]
public int Id { get; set; }
/// name field
[ElasticProperty(Name = "name", Index = FieldIndexOption.NotAnalyzed)]
public string Name { get; set; }
/// age field
[ElasticProperty(Name = "age", NumericType = NumberType.Integer)]
public int Age { get; set; }
/// birthday field
[ElasticProperty(Name = "birthday", Type = FieldType.Date, DateFormat = "basic_date")]
public string Birthday { get; set; }
/// haschildren field
[ElasticProperty(Name = "hasChildren")]
public bool HasChildren { get; set; }
/// enrollmentFee field
[ElasticProperty(Name = "enrollmentFee", NumericType = NumberType.Double)]
public double EnrollmentFee { get; set; }
/// opnion field
[ElasticProperty(Name = "opinion", Index = FieldIndexOption.NotAnalyzed)]
public string Opinion { get; set; }
}
现在我们已经有了 REST 连接和完全映射好的客户实体,是时候编写一些逻辑了。添加或更新一条记录应该使用几乎相同的逻辑。Elastic 非常智能,它能通过检查给定 ID 是否存在来决定是新建记录还是更新记录。
/// Inserting or Updating a doc
public bool Index(DTO.Customer customer)
{
var response = _EsClientDAL.Current.Index
(customer, c => c.Type(DTO.Constants.DEFAULT_INDEX_TYPE));
if (response.Created == false && response.ServerError != null)
throw new Exception(response.ServerError.Error);
else
return true;
}
API 中负责这个功能的方法叫做 “Index()”,因为将文档保存到 Lucene 存储中,正确的术语是“索引”(indexing)。
请注意,我们正在使用我们的常量索引类型(“Customer_Info”),以便告知 NEST 客户将被添加/更新到哪里。粗略地说,这个索引类型就是我们在 Elastic 世界中的“表”。
在使用 NEST 时,另一个常见的特性是 lambda 表达式,几乎所有的 NEST API 方法都通过它来工作。如今,使用 lambda 早已不是什么新鲜事,但它并不像常规的 C# 语法那样直观。
如果在阅读过程中,你觉得语法令人困惑,我强烈建议你在 Code Project 社区里快速搜索一下,那里有很多关于如何使用 Lambda 的教程。
删除是最简单的一个:
/// Deleting a row
public bool Delete(string id)
{
return _EsClientDAL.Current
.Delete(new Nest.DeleteRequest(DTO.Constants.DEFAULT_INDEX,
DTO.Constants.DEFAULT_INDEX_TYPE,
id.Trim())).Found;
}
与 “Index()” 方法非常相似,但这里只需要提供客户的 ID。当然,还要调用 “Delete()” 方法。
第 2 组(标准查询)
正如我之前提到的,Elastic 在查询方面功能非常强大,因此不可能在这里涵盖所有高级查询。但是,在尝试了下面的示例之后,你将能够理解其基础知识,从而在以后开始编写自己的用例。
第二个选项卡包含三个查询:

- 通过 ID 搜索:它基本上使用一个有效的 ID,并且只考虑这个 ID:
/// Querying by ID public List QueryById(string id) { QueryContainer queryById = new TermQuery() { Field = "_id", Value = id.Trim() }; var hits = _EsClientDAL.Current .Search(s => s.Query(q => q.MatchAll() && queryById)) .Hits; List typedList = hits.Select(hit => ConvertHitToCustumer(hit)).ToList(); return typedList; } /// Anonymous method to translate from a Hit to our customer DTO private DTO.Customer ConvertHitToCustumer(IHit hit) { Func<IHit<DTO.Customer=>, DTO.Customer=> func = (x) => { hit.Source.Id = Convert.ToInt32(hit.Id); return hit.Source; }; return func.Invoke(hit); }让我们慢慢来分析。
首先,需要创建一个 NEST
QueryContainer对象,指定我们想要用作搜索条件的字段。在本例中,是客户 ID。这个查询对象将作为参数传递给
Search()方法,以获取 Hits(从 Elastic 返回的结果集)。最后一步是通过
ConvertHitToCustomer方法将 Hits 转换成我们熟悉的Customer实体。我本可以将所有这些都放在一个方法里完成,但我决定将其拆分。原因是为了向大家展示,你们有很多选项来组织代码,而不仅仅是把所有东西都塞进一个难以阅读的 Lambda 语句中。
- 使用所有字段进行查询,并用 “
AND” 运算符组合它们:/// Querying by all fields with 'AND' operator public List QueryByAllFieldsUsingAnd(DTO.Customer costumer) { IQueryContainer query = CreateSimpleQueryUsingAnd(costumer); var hits = _EsClientDAL.Current .Search(s => s.Query(query)) .Hits; List typedList = hits.Select(hit => ConvertHitToCustumer(hit)).ToList(); return typedList; } /// Create a query using all fields with 'AND' operator private IQueryContainer CreateSimpleQueryUsingAnd(DTO.Customer customer) { QueryContainer queryContainer = null; queryContainer &= new TermQuery() { Field = "_id", Value = customer.Id }; queryContainer &= new TermQuery() { Field = "name", Value = customer.Name }; queryContainer &= new TermQuery() { Field = "age", Value = customer.Age }; queryContainer &= new TermQuery() { Field = "birthday", Value = customer.Birthday }; queryContainer &= new TermQuery() { Field = "hasChildren", Value= customer.HasChildren }; queryContainer &= new TermQuery() { Field = "enrollmentFee", Value=customer.EnrollmentFee }; return queryContainer; }与通过 ID 搜索的思路相同,但现在我们的查询对象是由
CreateSimpleQueryUsingAnd方法创建的。它接收一个客户实体,并将其转换为一个 NESTQueryContainer对象。
请注意,我们正在使用 NEST 的自定义运算符“&=”来连接所有字段,它代表了 “AND”。 - 这与上一个例子类似,但使用
OR “|=”运算符来组合字段。/// Querying by all fields with 'OR' operator public List QueryByAllFieldsUsingOr(DTO.Customer costumer) { IQueryContainer query = CreateSimpleQueryUsingOr(costumer); var hits = _EsClientDAL.Current .Search(s => s.Query(query)) .Hits; List typedList = hits.Select(hit => ConvertHitToCustumer(hit)).ToList(); return typedList; } /// Create a query using all fields with 'AND' operator private IQueryContainer CreateSimpleQueryUsingOr(DTO.Customer customer) { QueryContainer queryContainer = null; queryContainer |= new TermQuery() { Field = "_id", Value = customer.Id }; queryContainer |= new TermQuery() { Field = "name", Value = customer.Name }; queryContainer |= new TermQuery() { Field = "age", Value = customer.Age }; queryContainer |= new TermQuery() { Field = "birthday", Value = customer.Birthday }; queryContainer |= new TermQuery() { Field = "hasChildren", Value = customer.HasChildren }; queryContainer |= new TermQuery() { Field = "enrollmentFee", Value = customer.EnrollmentFee }; return queryContainer; }
第 3 组(组合查询)
第三个选项卡展示了如何使用 bool 查询来组合筛选器。这里可用的子句有 “must”、“must not” 和 “should”。虽然初看起来可能有些奇怪,但这与其他数据库的用法相差不远:
- must:子句(查询)必须出现在匹配的文档中。
- must_not:子句(查询)不得出现在匹配的文档中。
- should:子句(查询)应该出现在匹配的文档中。在一个没有 “
must” 子句的布尔查询中,必须有一个或多个should子句匹配文档。可以使用minimum_should_match参数设置需要匹配的should子句的最小数量。
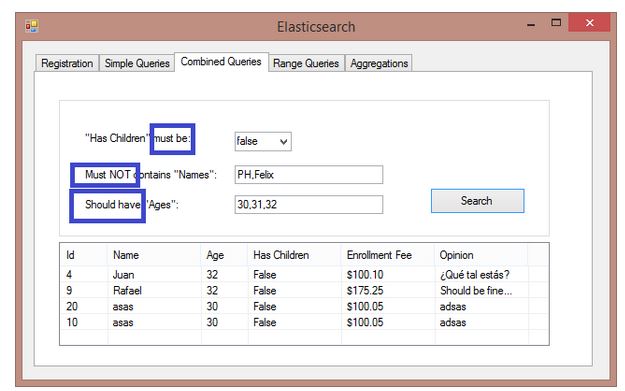
将其转换到我们的 C# 应用程序中,我们会得到:
/// Querying combining fields
public List QueryUsingCombinations(DTO.CombinedFilter filter)
{
//Build Elastic "Should" filtering object for "Ages":
FilterContainer[] agesFiltering = new FilterContainer[filter.Ages.Count];
for (int i = 0; i < filter.Ages.Count; i++)
{
FilterDescriptor clause = new FilterDescriptor();
agesFiltering[i] = clause.Term("age", int.Parse(filter.Ages[i]));
}
//Build Elastic "Must Not" filtering object for "Names":
FilterContainer[] nameFiltering = new FilterContainer[filter.Names.Count];
for (int i = 0; i < filter.Names.Count; i++)
{
FilterDescriptor clause = new FilterDescriptor();
nameFiltering[i] = clause.Term("name", filter.Names[i]);
}
//Run the combined query:
var hits = _EsClientDAL.Current.Search(s => s
.Query(q => q
.Filtered(fq => fq
.Query(qq => qq.MatchAll())
.Filter(ff => ff
.Bool(b => b
.Must(m1 => m1.Term
("hasChildren", filter.HasChildren))
.MustNot(nameFiltering)
.Should(agesFiltering)
)
)
)
)
).Hits;
//Translate the hits and return the list
List typedList = hits.Select(hit ==> ConvertHitToCustumer(hit)).ToList();
return typedList;
}
在这里,你可以看到第一个循环为给定的“ages”创建了 “should” 筛选器集合,而下一个循环则为提供的“names”构建了 “must not” 子句列表。
“must” 子句将只应用于 “hasChildren” 字段,所以这里不需要集合。
当所有的筛选器对象都填充好后,只需将它们全部作为参数传递给 lambda Search() 方法即可。
第 4 组(范围查询)
在第四个选项卡中,我们将讨论范围查询(与 SQL 中的 'between'、'greater than'、'less than' 等运算符的思路完全相同)。
为了重现这个功能,我们将组合两个范围查询,高亮部分如下:

我们的 BLL 有一个方法来构建并运行这个查询:
/// Querying using ranges
public List QueryUsingRanges(DTO.RangeFilter filter)
{
FilterContainer[] ranges = new FilterContainer[2];
//Build Elastic range filtering object for "Enrollment Fee":
FilterDescriptor clause1 = new FilterDescriptor();
ranges[0] = clause1.Range(r => r.OnField(f =>
f.EnrollmentFee).Greater(filter.EnrollmentFeeStart)
.Lower(filter.EnrollmentFeeEnd));
//Build Elastic range filtering object for "Birthday":
FilterDescriptor clause2 = new FilterDescriptor();
ranges[1] = clause2.Range(r => r.OnField(f => f.Birthday)
.Greater(filter.Birthday.ToString
(DTO.Constants.BASIC_DATE)));
//Run the combined query:
var hits = _EsClientDAL.Current
.Search(s => s
.Query(q => q
.Filtered(fq => fq
.Query(qq => qq.MatchAll())
.Filter(ff => ff
.Bool(b => b
.Must(ranges)
)
)
)
)
).Hits;
//Translate the hits and return the list
List typedList = hits.Select(hit => ConvertHitToCustumer(hit)).ToList();
return typedList;
}
详细来说,这个方法将创建一个包含两个项目的 FilterContainer 对象:
第一个包含 “EnrollmentFee” 的范围,对其应用 “Great”(大于)和 “Lower”(小于)运算符。第二个将覆盖大于用户为 “Birthday” 字段提供的任何值。
请注意,我们需要坚持使用自这个存储创建以来就使用的日期格式(参见第一篇文章)。
一切就绪后,只需将其作为参数发送给 Search() 方法即可。
第 5 组(聚合)
最后,第五个选项卡展示了(在我看来)最酷的功能——聚合。
正如我在上一篇文章中所述,这个功能对于量化数据并理解其意义特别有用。

第一个组合框包含了所有可用的字段,第二个则包含了聚合选项。为简单起见,我在这里展示了最流行的几种聚合方式:
Sum
private void ExecuteSumAggregation
(DTO.Aggregations filter, Dictionary list, string agg_nickname)
{
var response = _EsClientDAL.Current
.Search(s => s
.Aggregations(a => a
.Sum(agg_nickname, st => st
.Field(filter.Field)
)
)
);
list.Add(filter.Field + " Sum", response.Aggs.Sum(agg_nickname).Value.Value);
}
Average
private void ExecuteAvgAggregation
(DTO.Aggregations filter, Dictionary list, string agg_nickname)
{
var response = _EsClientDAL.Current
.Search(s => s
.Aggregations(a => a
.Average(agg_nickname, st => st
.Field(filter.Field)
)
)
);
list.Add(filter.Field + " Average", response.Aggs.Average(agg_nickname).Value.Value);
Count
private void ExecuteCountAggregation
(DTO.Aggregations filter, Dictionary list, string agg_nickname)
{
var response = _EsClientDAL.Current
.Search(s => s
.Aggregations(a => a
.Terms(agg_nickname, st => st
.Field(filter.Field)
.Size(int.MaxValue)
.ExecutionHint
(TermsAggregationExecutionHint.GlobalOrdinals)
)
)
);
foreach (var item in response.Aggs.Terms(agg_nickname).Items)
{
list.Add(item.Key, item.DocCount);
}
}
最小值/最大值
private void ExecuteMaxAggregation
(DTO.Aggregations filter, Dictionary list, string agg_nickname)
{
var response = _EsClientDAL.Current
.Search(s => s
.Aggregations(a => a
.Max(agg_nickname,
st => st //Replace ‘.Max’ for ‘.Min’ to get
//the min value
.Field(filter.Field)
)
)
);
list.Add(filter.Field + " Max", response.Aggs.Sum(agg_nickname).Value.Value);
}
结论
由于大多数开发人员习惯于关系型数据库,使用非关系型存储可能会很有挑战性,甚至感到奇怪。至少,对我来说是这样。
我曾在多个项目中与大多数知名的关系型数据库打过交道,它们的概念和标准已经深深烙印在我的脑海中。
所以,接触这种新兴的存储技术正在改变我的观念,我猜想,世界各地的其他 IT 专业人士也正在经历同样的事情。
随着时间的推移,你可能会意识到它确实为设计解决方案开辟了广阔的前景。
希望你们喜欢这篇文章!
祝好!
历史
- 2015年9月28日:初始版本