
词法分析触手可及。
4.56/5 (5投票s)
使用 Quex 生成词法分析器
引言
本文演示了一种构建词法分析器的简单方法。它围绕一个名为 Quex 的词法分析器生成器展开。最初,我是在一次火车旅行中作为“随便看看”的活动开始开发这个工具的;在过去十年左右的时间里,它成为了一种爱好。Quex 源于让事情比其他可用工具更舒适、更容易、更快速的愿望。如今,其显著特点包括:
- 生成直接编码的引擎,而不是表驱动的。
- 可定制的行号和列号计数。
- Unicode 和其他编码支持。
- 基于缩进的词法分析(如 Python 所做)。
- 可以通过继承关联的模式。
- 用于文件包含支持的包含堆栈。
- 许多事件处理程序用于精细控制。
- 路径和模板压缩以减少代码大小。
- ... 并附带许多示例供您使用。
在以下各节中,一个极简示例将初步介绍该工具的使用方法。此外,还将详细介绍三个功能。首先,讨论如何轻松访问行号和列号信息。其次,介绍了处理基于缩进的作用域(如 Python 中)的机制。第三,展示了如何使用转换器分析任意字符编码的字符流。
背景
词法分析代表文本自动解释的第一阶段。也就是说,它检测“意义的原子块”并将它们打包成所谓的“标记”。
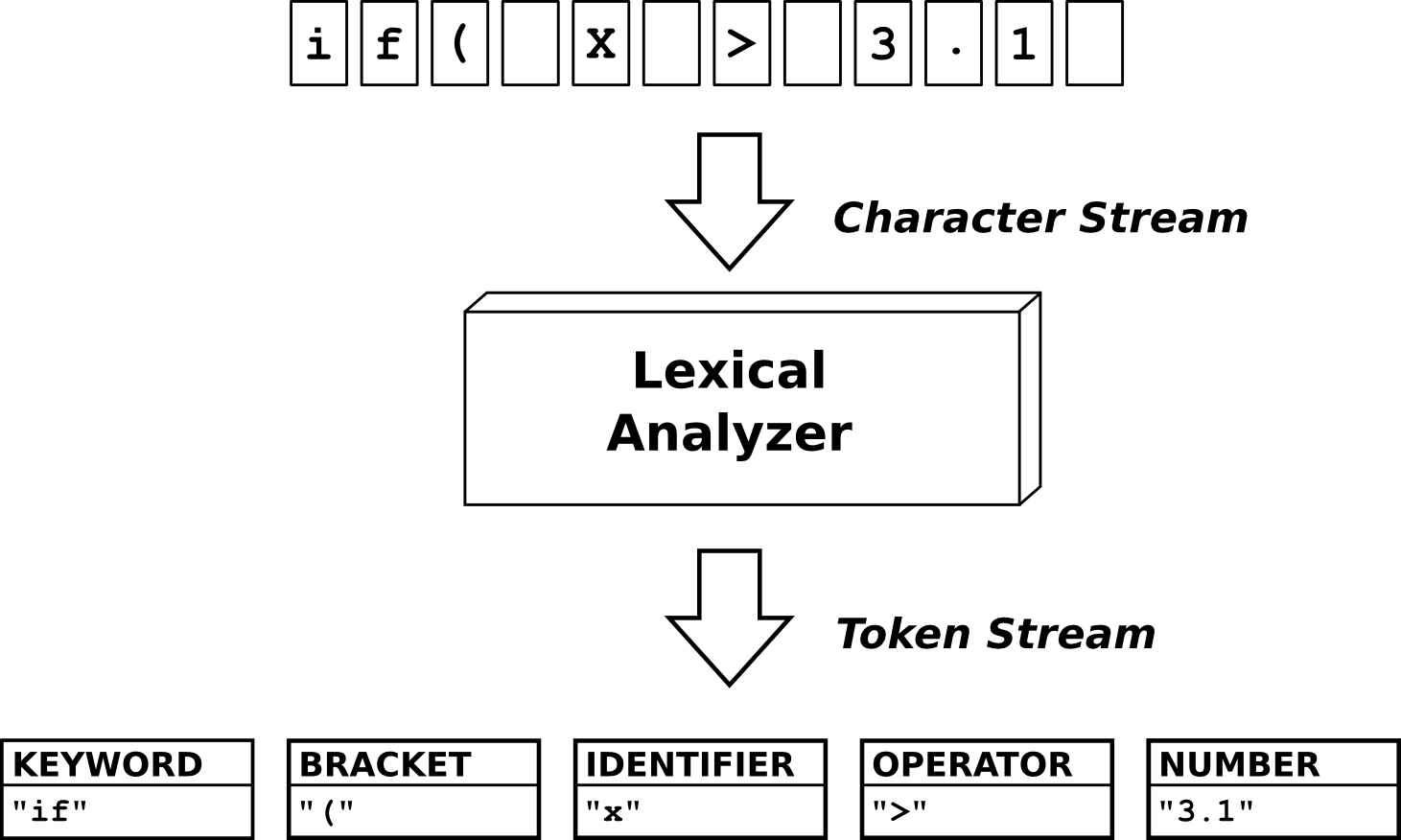
通过模式匹配来检测意义的原子块。在 Quex 中,模式以 正则表达式 的形式描述,这种形式因 lex 和 flex 而普及。例如,这些模式说明“整数”由数字的集合组成,“标识符”由字母的集合组成,某些关键字可能被定义为特定的字符序列,例如 while 或 if。一个检测数字和标识符的极简示例介绍了如何使用 Quex 的初步印象。它传达了理解以下各节所需的足够知识。然而,有关进一步阅读,可以查阅丰富的 在线文档,或 Quex 随附的手册页“quex.1”。
要尝试以下内容,必须安装 Quex,它适用于 Linux、Windows、BSD、MacOS、Solaris 以及任何安装了 Python2.7 的系统(实际上,Python2.7 是 Quex 的主要依赖项)。假设 quex 应用程序的目录在您的系统 PATH 中,并且环境变量 QUEX_PATH 设置为 Quex 的安装目录。
命令行指令在 Unix 系统上无缝运行。在 Windows 机器上,字符串 $QUEX_PATH 必须替换为 %QUEX_PATH%,并且相对路径 ./ 必须替换为空。
极简示例
词法分析器的行为通过模式-动作对来指定。每当传入的字符序列匹配某个模式时,就执行特定的动作。通常,让这个动作产生一个标记是个好主意。因此,词法分析器将字符流转换为标记流。下面显示了一个在检测到数字或标识符时产生标记的分析器。
mode PRIMER : <skip: [ \t\n]> {
[0-9]+ => QUEX_TKN_INTEGER(Lexeme);
[_a-zA-Z]+ => QUEX_TKN_IDENTIFIER(Lexeme);
}
mode 关键字开启一个模式定义。任何分析器动作都在一个模式中发生。skip 标签让分析器忽略任何空白字符。花括号内的“pattern => action”对定义了哪些匹配会触发哪些标记。将上述代码片段保存到文件“minimalist.qx”中,Quex 就可以生成一个词法分析器。在命令行中,可以输入
> quex -i minimalist.qx -o EasyLexer
这将生成一个词法分析器引擎“EasyLexer”及其所有相关文件,即
EasyLexer分析器的头文件。EasyLexer-configuration包含配置参数。EasyLexer.cpp分析器的实现。EasyLexer-token分析器的标记类文件。EasyLexer-token_ids标记标识符的定义。
现在,需要一些驱动代码来初始化分析器并遍历标记。也就是说,必须构造 EasyLexer 类的一个对象,并指示它从文件中读取。要重复启动分析循环,必须调用成员函数 receive()。
#include "EasyLexer"
#include <iostream>
int main(int argc, char** argv)
{
using namespace std;
quex::Token* token_p = 0x0;
quex::EasyLexer qlex(argc == 1 ? "example.txt" : argv[1]);
do {
qlex.receive(&token_p);
cout << string(*token_p) << endl;
} while( token_p->type_id() != QUEX_TKN_TERMINATION );
return 0;
}
标准 cout 的输出是用户可能对标记执行操作的占位符。最终,通过接收到带有 QUEX_TKN_TERMINATION 的标记来检测标记流的结束。将此片段保存到文件“lexer.cpp”中,就可以构建一个完整的词法分析器应用程序,例如使用 GNU 的 C++ 编译器
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o ./lexer
现在,lexer 需要一些输入来处理。如下所示的示例文本文件“minimalist.txt”中的一些数字和标识符即可。
4711 hello world
运行词法分析器,使用
> ./lexer minimalist.txt
最终在标准输出上显示词法分析结果为
INTEGER '4711'
IDENTIFIER 'hello'
IDENTIFIER 'world'
<TERMINATION> ''
最后几段带领您从分析器规范、驱动实现和编译到分析数据显示的整个过程。如果这激发了您的兴趣,那么以下各节就是为您准备的。它们展示了获取行号信息用于错误和警告输出是多么容易。它解释了如何使用基于缩进的作用域功能生成像 Python 这样优美的语言。对于生活在 ASCII 世界之外的人们,最后一节详细阐述了任意字符编码的词法分析。
行号计数
当解释器在需要修复的输入上阻塞时,最好精确地指出错误发生的位置。为此,至少需要跟踪行号,可能还需要跟踪列号。跟踪行号和列号可能具有挑战性,在计算时间方面成本高昂,并会给词法分析器描述增加视觉噪音。因此,Quex 隐式地完成这项工作是一件好事。命令行标志 "--no-column-counting" 禁用列号计数,"--no-line-counting" 禁用行号计数。默认情况下,两者都启用。
Quex 知道用于通信分析结果的标记类。它使用标记来存储行号和列号。因此,一旦收到标记,就可以直接从标记中读取行号和列号。在标准输出之前向代码片段添加以下行将向词法分析器的输出添加行号和列号信息。
...
cout << "(" << token_p->line_number() << ", "
cout << token_p->column_number() << ") \t";
cout << string(*token_p) << endl;
...
这是跟踪列号和行号所需的全部内容。但是,对于自定义计数,提供了模式标签 counter。这可能很有用,例如,在使用排版系统时,其中“m”的水平宽度与“i”不同。
mode PRIMER :
<counter: [\t] => grid 8;
[i] => space 2;
[m] => space 5;
>
{
...
}
上述示例指定制表符使列号跳到八个列单位的网格上。一个“i”被计为两个单位,一个“m”被计为五个单位。
基于缩进的词法分析
Python 编程语言完美地展示了如何通过所谓的 Off-Side Rule 减少代码中的视觉噪音。也就是说,缩进限制了语句块,不需要括号。用基于花括号的语法编写的代码片段可能如下所示。
for x = 0 to N { // OPEN_BRACKET
for y = x to M { // OPEN_BRACKET
if array(x, y) == 0 // OPEN_BRACKET
return true;
} // CLOSE_BRACKET
} // CLOSE_BRACKET
} // CLOSE_BRACKET
return false;
其中 OPEN_BRACKET 和 CLOSE_BRACKET 作为对 { 和 } 的反应发送。它们划分语句块。相同的功能可以通过基于缩进的作用域语言实现,如下所示。
for x = 0 to N
for y = x to M // INDENT
if array(x, y) == 0 // INDENT
return true; // INDENT
return false; // 3x DEDENT
在这里,语句块由 INDENT 和 DEDENT 标记分隔,因为它们是作为对缩进宽度变化的反应而发送的。前者的句法内容与后者等效。但显然,后者更简洁。Quex 支持此类语言的开发。用 indentation 标签定义的模式配备了一个单元,该单元生成以下标记:
- 当出现缩进大于前一行的行时,生成
INDENT。它隐式地为任何后续的更大缩进内容打开一个“块”。 - 当出现与前一行缩进相同的行时,生成
NODENT。 - 对于每个以比当前行更高缩进开头的块,生成
DEDENT。这些块被关闭。
一个名为“indentation.qx”的文件,其内容如下,将促使 Quex 生成一个基于缩进的词法分析器。
mode PRIMER :
<indentation: /* Use defaults */ >
<skip: [ \t]>
{
[0-9]+ => QUEX_TKN_INTEGER(Lexeme);
[_a-zA-Z]+ => QUEX_TKN_IDENTIFIER(Lexeme);
}
生成的引擎可以像以前一样使用相同的驱动代码运行。因此,生成词法分析器并编译... ...
> quex -i indentation.qx -o EasyLexer
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o i-lexer
生成应用程序 i-lexer。当输入示例文件“indentation.txt”时,如下所示:
4711
hello
beautiful
world
它会在标准输出上产生以下分析结果
INTEGER '4711'
<INDENT> ''
IDENTIFIER 'hello'
<INDENT> ''
IDENTIFIER 'beautiful'
<DEDENT> ''
<DEDENT> ''
IDENTIFIER 'world'
<NODENT> ''
<TERMINATION> ''
Unicode 和编解码器转换器
文本仅用 ASCII 编码的时代早已过去。然而,许多编程语言仍然以这种编解码器为中心。如果能将“¬”和“≠”等数学运算符,或者“π”和“ρ”等希腊字母作为编程语言的一部分,那不是很好吗?这可以通过将转换器插入 Quex 生成的分析器来实现。Quex 提供了 ICU 和 IConv 转换器库的接口。Unicode 的最小示例可以指定为:
mode PRIMER :
<skip: [ \t\n]> {
\G{Nd}+ => QUEX_TKN_INTEGER(Lexeme);
\P{ID_Start}\P{ID_Continue}* => QUEX_TKN_IDENTIFIER(Lexeme);
}
上面的例子也展示了如何访问和使用 Unicode 属性在正则表达式中。\P{White_Space} 匹配 Unicode 字符集中任何被认为是空白字符的字符。\G{Nd} 匹配通用类别“数字”中的任何字符。\P{ID_Start} 和 \P{ID_Continue} 访问可用作标识符起始字符和标识符后续字符的字符集。有关 Unicode 属性模式的更多信息,请参阅 Unicode 技术报告 #23。
对于转换器,调用 Quex 需要一些额外的参数。通过“--iconv”或“--icu”指定转换器库。为了捕获所有 Unicode 字符,缓冲区的元素宽度最好选择为四个字节,即应提供“-b 4”。假设我们要使用 IConv 库,我们指示 Quex 通过以下方式生成分析器:
> quex -i converter.qx -o EasyLexer -b 4 --iconv
剩下的就是稍微修改一下驱动代码。一个额外的参数告诉转换器它需要从哪个编解码器进行转换;让它成为 UTF8。
...
quex::EasyLexer qlex(argc == 1 ? "example.txt" : argv[1], "UTF8");
...
在某些系统上,必须将“-liconv”添加到链接器行(如果它不在 g++ 的默认参数中),以便它拉入 IConv 库(ICU 链接器标志可以通过 icu-config --ldflags 访问)。编译指令变为:
> g++ -I. -I$QUEX_PATH lexer.cpp EasyLexer.cpp -o c-lexer -liconv
生成的词法分析器 c-lexer 现在能够匹配来自任何字符集的数字和标识符。考虑一个名为“converter.txt”的示例文件,其内容如下:
١٤١٥٩ १४१५९ ๑๔๑๕๙ 大 schoen ยิ่งใหญ่
运行 ./c-lexer converter.txt 会获取该输入并提供结果
INTEGER '١٤١٥٩'
INTEGER '१४१५९'
INTEGER '๑๔๑๕๙'
IDENTIFIER '大'
IDENTIFIER 'schoen'
IDENTIFIER 'ยิ่งใหญ่'
<TERMINATION> ''
上面的例子使用 UTF8 作为输入编解码器。但是,可以指定 ICU 或 IConv 处理的任何编解码器。分析器的编解码器由传递给分析器构造函数的最后一个参数控制。例如,传递“UTF16”会自动让完全相同的分析器在“UTF16”编码的文件上运行。因此,可以动态修改输入编解码器,而无需重新生成分析器本身。
摘要
本文展示了使用 Quex 可以多么轻松地实现词法分析中的复杂功能。只需几行代码即可指定一个词法分析器。调用 Quex 即可生成所需的源代码。一个小的 C++ 程序与生成的引擎交互并接收字符流中找到的标记。本文展示了如何访问行号和列号信息,如何实现基于缩进的作用域语言,以及如何处理任意字符编码的字符流。
历史
2015 年 12 月:首次提交。