
面向.Net和AngularJS开发者的Hadoop
5.00/5 (20投票s)
使用面向Microsoft的技术(C#、SSIS、SQL Server、Excel等)查询Hadoop。
下载 C# Hadoop Visual Studio 13 解决方案
引言
我想向Microsoft开发者展示,Hadoop和.Net是能够很好地协同工作的技术组合。通过演示如何设置、配置Hadoop集群、导入数据(从RDBMS、平面文件等)、使用Hive以及通过REST API查询数据,最终在您的.Net/AngularJS应用程序中显示结果数据集——所有这些都从Microsoft开发者的角度出发。
我们计划从Oracle和SQL Server导入表。然后在Hortonworks Ambari Dashboard(Hive)中进行查询,在一个应用程序中对来自不同数据源的两个表进行连接。
我计划演示Hadoop与以下技术/应用程序的交互:
- C# 控制台
- C# REST 服务
- AngularJS
- SSIS
- SQL Server 链接服务器
- Excel
- 在 Visual Studio IDE 中查询 Hadoop
背景
“从四节点到数据未来……”
早在2003年,Google就投资并发明了构成今天广为人知的Hadoop的基础框架。他们首先面对的是处理数十亿次搜索和索引数百万个网页的问题。当找不到满足他们需求的任何大规模、分布式、可伸缩的计算平台时,他们便着手创建了自己的平台。
Doug Cutting(来自Yahoo)受到Google白皮书的启发,决定创建一个名为“Hadoop”的开源项目。Yahoo进一步为该项目做出了贡献,并在为企业应用程序开发Hadoop方面发挥了关键作用。自那时以来,Facebook、Linkedin、ebay、Hortonworks、Cloudera等许多公司都为Hadoop项目做出了贡献。
这个名字本身来源于Doug儿子的玩具大象——Hadoop,“……容易记住,也容易在Google上搜索到……”
术语
Hadoop
是一个免费的、基于Java的编程框架,支持在分布式计算环境中处理大规模数据集。它是Apache软件基金会赞助的Apache项目的一部分。
Sqoop
Apache Sqoop(发音同scoop)是一个旨在高效地批量传输Apache Hadoop与结构化数据存储(如关系数据库)之间数据的工具。Sqoop有助于在Hadoop与其他数据库之间移动数据,并且可以并行传输数据以提高性能。
Hive
Apache Hive是一个构建在Hadoop之上的数据仓库基础设施,用于提供数据汇总、查询和分析。虽然最初由Facebook开发,但Apache Hive现在已被多家公司使用和开发。
Hadoop 安全
简而言之,安全层是构建在Linux LDAP之上的。当一个RDBMS表被导入Hadoop时,它以平面文件格式(如CSV)存在,因此它位于一个文件夹中。安全主要围绕着限制对这些文件夹的访问。
MapReduce
Hadoop MapReduce是一个软件框架,用于在商品硬件的计算集群上分布式处理大规模数据集。它是Apache Hadoop项目的一个子项目。该框架负责任务调度、监控和重新执行任何失败的任务。
Map/Reduce的主要目标是将输入数据集分割成独立的块,这些块以完全并行的方式进行处理。Hadoop MapReduce框架对map的输出进行排序,然后将其作为reduce任务的输入。通常,作业的输入和输出都存储在文件系统中。
必备组件
下载并安装以下应用程序(如果您已安装完整版,请使用该版本)。
- VM Workstation Player
- Hortonworks Data Platform (HDP) Sandbox for VM (8.7GB)
- Putty(用于执行Linux命令的工具——Hortonwork的仪表板中也有执行Linux命令的应用程序)
- Oracle Express(您需要一个免费的Oracle账户,并在安装时记下SYSTEM密码)
- Oracle SQL Developer 4.1.2(类似于SSMS)
安装完Oracle Express后,您应该可以在开始菜单中找到相应的条目。

打开SQL Developer并连接到您的Oracle Express(使用安装时为SYSTEM用户输入的密码)。

打开Oracle脚本(顶部附件)并执行它(点击绿色的播放按钮)。这将创建一个新的Oracle用户并安装一个数据库,其中包含我们稍后要导入Hadoop的演示表。
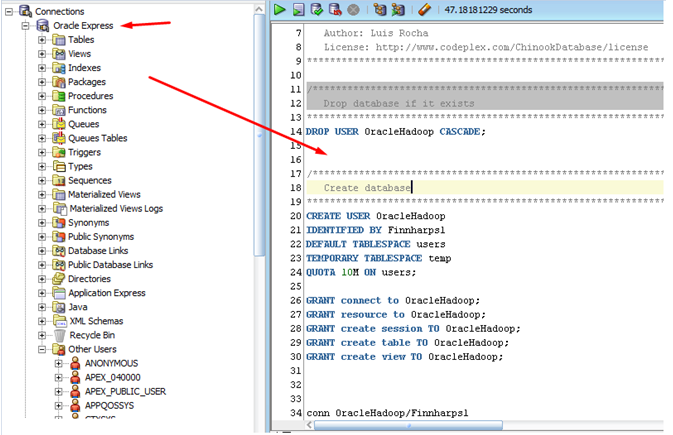

脚本完成后,创建一个新的连接来测试所有配置是否正确——以OracleHadoop/Finnharps1登录。这些是您将在Hadoop Sqoop中用于导入Artist表的凭据。


安装完成后,记下您的系统管理员(sa)密码,打开附带的SQL Server脚本,并通过点击绿色的播放按钮执行它。

这将创建与您之前为Oracle Express创建的相同数据库。这样做的目的是我们从Oracle导入一个表,从SQL Server导入一个表,然后在Hadoop中创建一个Hive查询来连接这两个表。
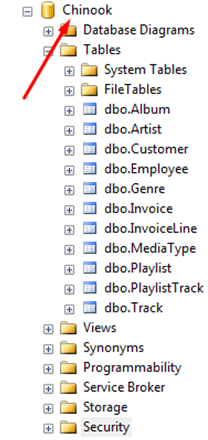
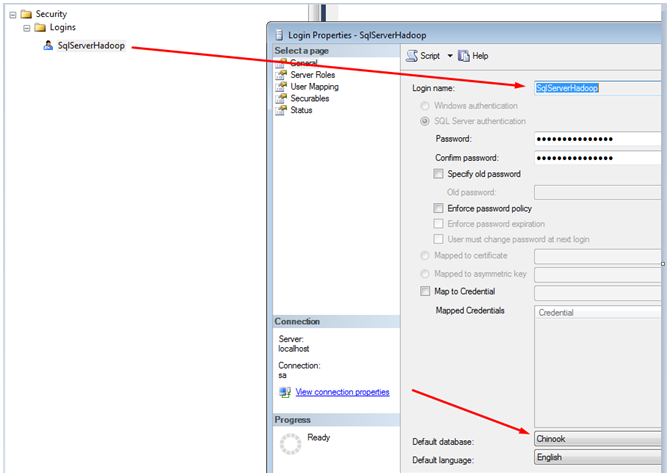
现在,我们将创建一个新的SQL Server用户,因为我们正在使用Oracle,所以最好为两个数据库服务器都设置一个独特的用户名。创建一个名为SQLServerHadoop的新SQL登录,密码为Finnharps1。
注意:您必须使用强密码,否则Hadoop Sqoop将无法连接到我们的数据库。
创建您的SQL Server用户

以下是使用SQL脚本创建的、具有相同表结构的SQL Server和Oracle数据库。

VM 设置
安装VM Player。下载完VM Sandbox后,您可以启动VM Player并运行您之前下载的Hortonworks sandbox。







当VM加载Sandbox时,您将看到如下所示的脚本信息;
VM最终启动后,记下IP地址(我的地址是192.168.181.129)。

按<Alt + F5>键进入VM,然后输入默认的VM登录名和密码(root/hadoop)。您可能会被提示更改密码。请记下您的新密码。
启动Putty并输入VM的IP地址。

Microsoft JDBC Driver 设置
在Putty中,复制以下命令以查看您在VM中的位置
pwd

然后输入命令列出目录内容和子路径。您会注意到我已经下载了Microsoft JDBC驱动程序(红色的.tar文件)。
ls -la
注意:蓝色的文本是文件夹。

让我们下载Microsoft JDBC驱动程序,解压并将jdbc.jar文件复制到Sqoop的lib文件夹中。
注意:要获取Sqoop目录路径——在Putty中输入以下命令:
ls -la /usr/bin/sqoop

在Putty中(一次输入一个)输入以下命令:
cd /usr/local/ curl -L 'http://download.microsoft.com/download/0/2/A/02AAE597-3865-456C-AE7F-613F99F850A8/sqljdbc_4.0.2206.100_enu.tar.gz' | tar xz cp sqljdbc_4.0/enu/sqljdbc4.jar /usr/hdp/current/sqoop-client/lib/

准备SQL Server环境
执行以下SQL语句,以确定是否需要更改“共享内存”传输配置。
注意:如果您正在从该SQL Server实例中的存储过程执行SSIS包;在完成本教程时,您需要撤销更改。
SELECT
CONNECTIONPROPERTY('net_transport') AS net_transport,
CONNECTIONPROPERTY('protocol_type') AS protocol_type,
CONNECTIONPROPERTY('auth_scheme') AS auth_scheme,
CONNECTIONPROPERTY('local_net_address') AS local_net_address,
CONNECTIONPROPERTY('local_tcp_port') AS local_tcp_port,
CONNECTIONPROPERTY('client_net_address') AS client_net_address

如果代码返回的net_transport是共享内存(如上所示),您将需要进入SQL Server Configuration Manager,禁用共享内存,确保TCP/IP已启用,并重启SQL Server服务。

再次运行SQL语句,您应该会看到下面的配置属性——记下SQL Server的IP地址和端口,因为Hadoop的Sqoop在导入SQL Server表数据时将使用这些信息。

列出用户可用的数据库
注意:密码是明文,仅用于测试目的。
注意:SQL Server密码必须符合强密码规则,否则Linux/Hadoop将抛出模糊的错误消息。
通过在putty中运行以下命令(一次一个)为Root账户授予向HDFS写入的权限:
sudo -u hdfs hadoop fs -mkdir /user/root sudo -u hdfs hadoop fs -chown root:root /user/root
然后在Putty中输入以下命令以列出Hadoop可以为该用户导入的可用数据库(请勿使用localhost作为IP地址,因为这会指向VM的本地服务器,我们寻找的是您桌面/服务器上的SQL Server)。
sqoop list-databases --connect jdbc:sqlserver://192.168.1.100:1433 --username SqlServerHadoop --password Finnharps1

将Artist表从SQL Server导入Hadoop;
sqoop import --connect "jdbc:sqlserver://192.168.1.100:1433;database=Chinook;username=SqlServerHadoop;password=Finnharps1" --table Artist --hive-import -- --schema dbo

在导入过程中,您将看到显示的信息。使用<Ctrl> + PageUp/PageDown查看详细信息。

最后,将显示有关导入表的信息。

如果列出目录内容,您现在会看到导入表的Java文件。

我跳到前面来向您展示如何在Hortonwork的Hive应用程序中查看新导入的表。

Oracle Driver 设置
我们将以与导入SQL Server驱动程序相同的方式导入Oracle驱动程序。
导航到usr文件夹:cd /usr/
wget https://afirs.googlecode.com/files/ojdbc6.jar
在Putty中,导航到/usr/文件夹并列出内容,以查看导入的jar文件。

现在,让我们使用以下命令将其复制到Sqoop目录中:
cp ojdbc6.jar /usr/hdp/current/sqoop-client/lib/

列出Oracle数据库
以SYS用户登录SQL Developer并为OracleHadoop用户运行以下脚本:
GRANT DBA TO ORACLEHADOOP;
grant CREATE SESSION, ALTER SESSION, CREATE DATABASE LINK,
CREATE MATERIALIZED VIEW, CREATE PROCEDURE, CREATE PUBLIC SYNONYM,
CREATE ROLE, CREATE SEQUENCE, CREATE SYNONYM, CREATE TABLE,
CREATE TRIGGER, CREATE TYPE, CREATE VIEW, UNLIMITED TABLESPACE
to ORACLEHADOOP ;

我们可以通过在Putty中执行以下命令来列出Hadoop可以看到的Oracle数据库;
sqoop list-databases --connect jdbc:oracle:thin:@192.168.1.100:1521/xe --username ORACLEHADOOP --password Finnharps1

现在,将Album数据库表导入Hadoop:
sqoop import --connect jdbc:oracle:thin:@192.168.1.100:1521/xe --username ORACLEHADOOP --password Finnharps1 --table ALBUM --hive-import

注意:即使对于小型数据转储,这个过程也可能非常耗时!
列出usr目录的内容,以查看新导入的ARTISTS(java)文件。

查看Java文件
输入以下命令,以打开VI编辑器并查看新导入的Album表相关的(ORM)java类:
vi ALBUM.java

登录Ambari浏览器仪表板
在浏览器中输入VM的IP地址,即可路由到Hortonworks仪表板页面(在提示时使用凭据admin/admin)。从这里,我们将能够导航到Hive查询编辑器,并对新导入的表执行一些SQL语句。
注意:即使表最初存在于RDBMS中,在Hadoop中它们的格式更类似于CSV文件(逗号分隔)。

使用Hive查询Hadoop的Schema表
点击菜单框,然后从下拉列表中选择Hive。

您将看到页面左侧的数据库浏览器,它将显示default数据库中现有的表。

只需在编辑器中输入SQL语句,然后点击(绿色)执行按钮,即可在下方看到渲染结果;

表Schema
如果点击表链接,它将展开以显示表的字段结构。

ODBC 设置(SQL Server、Tableau、Excel等使用)
使用以下Microsoft链接下载Hive ODBC驱动程序(x32或x64)并进行安装。
SQL Server 连接到 Hadoop 服务器 - 设置
创建一个“系统DSN”,并设置以下属性——输入您的Hadoop VM IP地址,然后点击测试按钮以确保连接有效。在高级选项中,请务必将String大小配置为8000,因为这会在从Hadoop检索(n)varchar数据时导致错误。



在SQL Server中,通过执行以下命令创建一个新的Linked Server条目(请注意datasrc属性指向我们新创建的DSN)。
EXEC master.dbo.sp_addlinkedserver @server = N'HiveFinnharps',
@srvproduct=N'HIVE', @provider=N'MSDASQL',
@datasrc=N'Microsost C# Hadoop',
@provstr=N'Provider=MSDASQL.1;Persist Security Info=True;User ID=root; Password=finnharps;'
下图显示了SQL属性如何在我们的Linked Server条目中进行映射;

为了帮助您找到数据库、schema和表路径,右键单击表,然后依次选择Select To -> Clipboard。

执行以下(内部连接)语句,以查看Artist和Album表中的数据。

快速C#控制台查询Hadoop示例
下面的Visual Studio部分概述了一个更好的例子——但这里是一个关于如何连接到Hadoop、执行查询并处理其结果的快速参考。
static void Main(string[] args)
{
var conn = new OdbcConnection
{
ConnectionString = "Dsn=Microsost C# Hadoop;Uid=root;Pwd=finnharps;"
};
try
{
conn.Open();
var adp = new OdbcDataAdapter("Select * from Artist limit 100", conn);
var ds = new DataSet();
adp.Fill(ds);
foreach (var table in ds.Tables)
{
var dataTable = table as DataTable;
if (dataTable == null) continue;
var dataRows = dataTable.Rows;
if (dataRows == null) continue;
System.Console.WriteLine("Records found " + dataTable.Rows.Count);
foreach (var row in dataRows)
{
var dataRow = row as DataRow;
if (dataRow == null) continue;
System.Console.WriteLine(dataRow[0].ToString() + " " + dataRow[1].ToString());
}
}
}
catch (Exception ex)
{
System.Console.WriteLine(ex.Message);
}
finally
{
conn.Close();
}
}

Office(Excel\Access)查询Hadoop
如果您的Office版本是32位——请务必安装Microsoft Hive ODBC (32)。为您的Excel版本(32或64)创建一个新的系统DSN条目——我们将使用它来连接到Hadoop。使用下面的图像来关联DSN与您的连接。


系统将提示您输入root密码。然后会出现一个表/字段选择对话框,供您选择要导入Excel的字段。


然后,您将有机会过滤数据(就像任何其他类型的ODBC导入一样)。最后,查询对话框将处理您的请求,并将数据正常插入Excel。

从Excel工作表中导入的Hadoop数据。

各种Visual Studio项目查询Hadoop
要运行以下项目,Hortonworks VM必须正在运行。下面是我将演示的四个项目:
- Angularjs
- 控制台
- 数据访问层(因为Entity Framework无法与ODBC连接一起使用,所以我设计了一个DAL来执行SQL操作)
- Rest服务

数据访问层
下面是几个执行Hadoop表SQL查询的方法。DAL方法都使用ODBC连接来查询数据库,然后进行简单的执行并将结果返回。此DAL由控制台应用程序、AngularJS应用程序和REST服务使用。
public ActionResults ExecuteSqlStatement(string sqlStatement)
{
using (conn = new OdbcConnection("Dsn=Microsost C# Hadoop;Uid=root;Pwd=finnharps;")) // retrieve password from encrypted ConnectionString section of Web.Config!!!
{
using (var command = new OdbcCommand(sqlStatement, conn))
{
try
{
conn.Open();
using (var reader = command.ExecuteReader())
{
actionResult.ResultTable.Load(reader);
}
}
catch (OdbcException ex)
{
actionResult.ActionStatus = false;
actionResult.ErrorException = ex;
throw;
}
}
}
return actionResult;
}
public ActionResults RetrieveTop10Albumns()
{
using (conn = new OdbcConnection("Dsn=Microsost C# Hadoop;Uid=root;Pwd=finnharps;")) // retrieve password from encrypted ConnectionString section of Web.Config!!!
{
using (var command = new OdbcCommand(@"SELECT * FROM album LIMIT 100;", conn))
{
try
{
conn.Open();
using (var reader = command.ExecuteReader())
{
actionResult.ResultTable.Load(reader);
}
}
catch (OdbcException ex)
{
actionResult.ActionStatus = false;
actionResult.ErrorException = ex;
throw;
}
}
}
return actionResult;
}
控制台
控制台应用程序通过引用DAL程序集来执行其SQL请求。DAL代码将在下一节中进行解释。
static void Main(string[] args)
{
try
{
// initialise objects
dal = new HadoopDataAccessLayer();
result = new ActionResults();
// Top 10 albums
result = dal.RetrieveTop10Albumns();
foreach (DataRow row in result.ResultTable.Rows) // Loop over the rows.
{
System.Console.WriteLine("--- Row ---"); // Print separator.
foreach (var item in row.ItemArray) // Loop over the items.
{
System.Console.Write("Item: ");
System.Console.WriteLine(item);
}
}
// Top 10 artists & albums
result = dal.RetrieveTop10ArtistAndAlbum();
foreach (DataRow row in result.ResultTable.Rows) // Loop over the rows.
{
System.Console.WriteLine("--- Row ---"); // Print separator.
foreach (var item in row.ItemArray) // Loop over the items.
{
System.Console.Write("Item: ");
System.Console.WriteLine(item);
}
}
// Top 10 artists
result = dal.RetrieveTop10Artists();
foreach (DataRow row in result.ResultTable.Rows) // Loop over the rows.
{
System.Console.WriteLine("--- Row ---"); // Print separator.
foreach (var item in row.ItemArray) // Loop over the items.
{
System.Console.Write("Item: ");
System.Console.WriteLine(item);
}
}
System.Console.WriteLine("Hit <Enter> to close window.")
System.Console.ReadLine();
}
catch (Exception ex)
{
System.Console.WriteLine(ex.Message);
System.Console.ReadLine();
}
}
REST
REST服务也引用DAL程序集,并通过调用公共接口方法ExecuteSqlStatement,并将SQL语句从AngularJS客户端传递进来。生成的类被转换为JSON并传递回调用客户端。
[HttpGet]
[Route("api/GenericSql")]
public HttpResponseMessage Get(string SqlStatement)
{
try
{
result = dal.ExecuteSqlStatement(SqlStatement);
JSONresult = JsonConvert.SerializeObject(result);
var response = Request.CreateResponse(HttpStatusCode.OK);
response.Content = new StringContent(JSONresult, System.Text.Encoding.UTF8, "application/json");
return response;
}
catch (Exception ex)
{
var response = Request.CreateResponse(HttpStatusCode.BadRequest);
JSONresult = JsonConvert.SerializeObject(ex);
response.Content = new StringContent(JSONresult, System.Text.Encoding.UTF8, "application/json");
return response;
}
}
在IIS中部署的REST服务
下面是在IIS中部署的REST服务——然后由AngularJS调用。

在浏览器中测试服务方法
在浏览器中输入以下URL,以查看Artists表的JSON结果;
https:///Hadoop/api/Artists

在浏览器中输入以下URL,以查看Album表的JSON结果;
https:///Hadoop/api/Albums

在SoapUI中测试
下图显示了如何执行Artist控制器(GET)方法,并显示其JSON结果(就像我们在浏览器中所做的那样,只是格式更好)。

AngularJS
下面的屏幕截图展示了AngularJS to Hadoop应用程序的用户界面。该界面允许用户从一个丝带风格菜单中选择,并将结果显示在静态网格中。

当您点击一个丝带按钮时,会调用相应的REST服务方法,该方法又会调用相应的DAL方法,并启动与Hadoop的SQL进程(会渲染一个busybox告知用户处理过程)。

下面的网格显示了来自Hadoop的结果。

AngularJS调用REST方法过滤Hadoop;

HTML
下面的(Ribbonbar)片段是标准的(SPA)AngularJS语法,使用Controllers、Directives、Routing、Services和Expressions。带有(生成的)HTML页面注入到主页面(MVC)中。
<div id="testRibbon" class="officebar" ng-controller="ribbonController">
<ul>
<li class="current">
<a href="#" rel="home">Hadoop</a>
<ul>
<li>
<span>Albums</span>
<div class="button" ng-click="buttonClick('Top10Albums');">
<a href="#/Results" rel="table"><img src="Content/ribbon/images/cover32.png" alt="" />Top 10</a>
</div>
</li>
.
.
.
<!--Inject views into ui-view-->
<div id="content" ui-view="main"></div>
控制器
Controller片段处理页面事件并调用相应的服务方法,该服务方法又调用REST服务,REST服务引用DAL,从而可以与Hadoop通信。
$scope.buttonClick = function (value) {
$log.debug('Enter buttonClick');
blockUI.start(); // block UI
if (value == 'GenericSQL') {
$scope.$parent.ResultTitle = 'Generic SQL'
if ($scope.genericSQL == '') {
alert('Please enter a Hadoop SQL statement!');
return;
}
// call respective service
ribbonService.getGenericSQL($scope.genericSQL) // pass back the promise and handle in controller (service is only a pass through\shared logic between ctrls)
.then(function (results) {
$scope.$parent.Data = results.data.ResultTable // update the parent scope as you have nested controllers in view
},
function (results) {
blockUI.stop(); // unblock UI
alert("Failed Hadoop data request" + results); // log error
});
}
else if (value == 'FilteredArtist') {
$scope.$parent.ResultTitle = 'Filtered Artists'
if ($scope.filterArtist == '') {
alert('Please enter an artist to filer by!');
return;
}
// call respective service
ribbonService.getFilteredArtist($scope.filterArtist) // pass back the promise and handle in controller (service is only a pass through\shared logic between ctrls)
.then(function (results) {
$scope.$parent.Data = results.data.ResultTable // update the parent scope as you have nested controllers in view
},
function (results) {
blockUI.stop(); // unblock UI
alert("Failed Hadoop data request" + results); // log error
});
}
服务
以下是两个Service方法——请注意指向我们已部署的Hadoop REST服务的URL——因此与Hadoop通信非常简单。
this.getGenericSQL = function (sqlStatement) {
return $http({
method: 'GET',
withCredentials: true,
data: 'json',
url: 'https:///Hadoop/api/GenericSql?sqlStatement=' + sqlStatement
});
};
this.getFilteredArtist = function (filteredArtist) {
return $http({
method: 'GET',
withCredentials: true,
data: 'json',
url: 'https:///Hadoop/api/Artists/FilteredArtistAlbum?filter=' + filteredArtist
});
};
SSIS(使用32位ODBC DSN)
一旦我们知道如何创建ODBC DSN,我们就可以基本上使用Microsoft产品来与Hadoop通信。下面的屏幕截图演示了如何设置SSIS以从Hadoop导出(源)数据,并导出(目标)到Excel工作表。以下是一个Visual Studio SSIS项目。




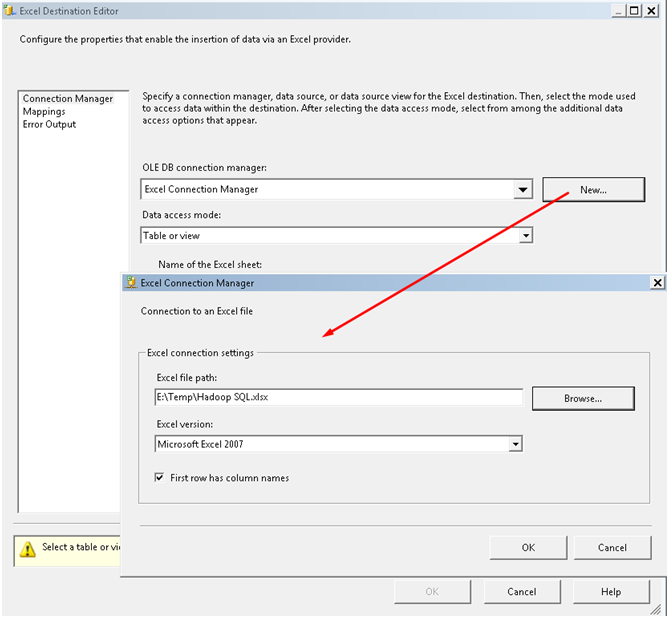

添加一个数据转换以转换不匹配的数据类型(从Oracle导入SQL Server的开发人员会将此转换步骤视为正常过程)。

SSIS包执行后,Excel(目标)工作表。

在Visual Studio中查询Hadoop
我们也可以使用Visual Studio来查询Hadoop,而无需将Hadoop服务器链接到SQL Server。通过添加新的连接并像往常一样使用ODBC DSN。

像处理其他RDBMS系统一样执行SQL查询。

要获取连接字符串——选择Hive服务器的属性。
