
通用高级 PDF 数据列表报告工具
在 C# 中为分组或非分组数据列表创建 PDF 报告,具有许多自定义选项和配置(提供 .NET Framework 4.6.1 和 .NET Core 3.1 的源代码)
引言
许多商业应用程序需要将数据列表导出为 PDF 文件。由于 PDF 组件是物理呈现在文档页面上的,因此获取 PDF 格式数据列表的最佳实践是借助 PDF 渲染工具直接生成 PDF 数据列表报告。Uzi Granot 与开发者社区分享了他出色且轻量级的 PDF 渲染基础类库 PdfFileWriter。通过使用这个库,并对内部代码进行少量调整(以及针对 .NET Core 的更新),我构建了 PdfDataReport 工具,用于从 C# 数据列表(无论是否进行记录分组)创建 PDF 报告。它的通用性在于,创建任何新报告或更新任何现有报告,只需在报告描述符中添加或更新与数据源模型类匹配的 XML 节点,然后使用数据列表和报告描述符作为参数调用相应方法即可。该工具的所有主要功能都将在示例应用程序中进行演示,并在本文中进行讨论。
构建和运行示例项目
.NET Core 3.1 的下载源代码 PdfDataReport.NetCore 只能使用 Visual Studio 2019 版本 16.4 或更高版本打开。.NET Framework 4.6.1 的示例应用程序 PdfDataReport.Net4 可以在 Visual Studio 2017(需安装 .NET Framework 4.6.1)或 2019 中打开。该解决方案包含四个项目。

-
PdfDataReport: PDF 数据列表报告处理器。这是本文和代码讨论的主要焦点。 -
PdfDataReport.Test: 简单的 WPF 程序,模拟PdfDataReport工具的使用者,用于测试数据报告的生成。 -
PdfDataReport.Test.Model: 包含示例应用程序的数据模型类。PdfDataReport工具本身不直接使用任何数据模型类。数据列表的基类型List<T>是动态传入的。 -
PdfFileWriter: PDF 渲染器类库(版本 1.26.0)。为了满足 PDF 数据列表的需求,我对 PdfDocument.cs、PdfTable.cs、PdfTableCell.cs 和 TextBox.cs 类文件进行了一些修改。PdfFileWriter库内部的代码更改不是本文的重点。如果感兴趣,读者可以在这些文件中搜索标记为 “SW:” 的行以了解详情。
如果你的本地计算机上安装了所需的 Visual Studio 和框架库,那么你应该可以毫无依赖问题地重新生成解决方案。请确保 PdfDataReport.Test 是启动项目,并且你的计算机上存在默认的 PDF 显示应用程序(通常是 Adobe Reader)。对于 .NET Core 3.1 的示例应用程序,如果你没有使用默认的 Adobe Reader DC 安装,你可能需要在 app.config 文件的 PdfReaderExe 值中指定 PDF 阅读器的可执行文件路径(详见最后一节 “.NET Core 3.1 相关变更”)。
然后你可以按 F5 以调试模式运行应用程序,以显示演示页面。

演示页面上的每个链接都会调用 PdfDataReport.ReportBuilder 类中的这个方法来构建 PDF 字节数组,并从中派生出 PDF 数据报告文件。
Byte[] pdfBytes = builder.GetPdfBytes(List<T> dataList, string xmlDescriptor);
第一个参数是一个泛型列表对象,作为数据源。PdfDataReport.Test 项目包含一个测试数据源类文件 TestData.cs,用于生成所需数量的数据记录以供演示。如果列表是按某个对象属性(即数据字段)进行分组的,那么该数据列表需要先按该属性排序。第二个参数是一个 XML 字符串,用于定义报告模式(在本文中称为“描述符”——详见下一节)。
尝试点击演示页面上的第一个链接,按订单状态分组的产品订单。PDF 生成过程开始运行,生成产品订单活动报告,然后显示生成的 PDF 页面。

描述符
XML 描述符文档定义了报告的结构、组件和数据字段属性。这是使报告工具具有通用性的关键部分。XML 文档文件可以放置在 PdfDataReport 进程可以访问的任何位置。可以在文档中添加一个 report 节点,用于从特定数据源生成报告。以下是示例描述符文件 report_desc_sm.xml 中用于产品订单活动报告的典型 report 节点块。
<report id="SMStore302" model="ProductOrders">
<view>
<general>
<title>Product Order Activity</title>
<subtitle></subtitle>
<group>OrderStatus</group>
<grouptitle>Order Status: {propertyvalue}</grouptitle>
</general>
<columns>
<col name="OrderId" display="Order Number" datatype="integer"/>
<col name="OrderDate" display="Order Date" datatype="datetime" />
<col name="OrderStatus" display="Order Status" group="true" datatype="string" />
<col name="CustomerId" datatype="integer" visible="false" />
<col name="CustomerName" display="Customer" datatype="string" nowrap="true" />
<col name="NumberOfItems" display="Number of Items"
datatype="integer" total="true" alignment="right" />
<col name="OrderAmount" display="Amount ($)" datatype="currency" total="true" />
<col name="ShippedDate" display="Shipped Date"
datatype="datetime" default-value="-" />
</columns>
</view>
</report>
在上述结构中,view 节点下有两个节节点,general 和 columns。general 节点包含报告标题和数据分组信息的描述符项。在 columns 节点下,每个 col 节点定义了该列在报告显示中的属性和值。在报告生成过程的初始阶段,描述符项和值将被传输到这些编程数据缓存中:
- 来自
general节点的各个元素的局部变量 - 用于非分组列的 L
ist<ColumnInfo> colInfoList - 用于分组依据列的
groupColumnInfo对象
调用 ReportBuiler.GetColumnInfo 方法来解析 XML 节点,以填充 List<ColumnInfo> colInfoList 和 groupColumnInfo 对象。
private List<ColumnInfo> GetColumnInfo(XmlDocument xmlDoc, ref ColumnInfo groupColumnInfo)
{
var nodeList = xmlDoc.SelectNodes("/report/view/columns/col");
var colInfoList = new List<ColumnInfo>();
ColumnInfo colInfo = default(ColumnInfo);
var idx = 0;
//Check if the list contains only one grouped column.
//Multiple grouped-column list will be treated as non-grouped data.
var isOneGroup = false;
foreach (XmlNode node in nodeList)
{
if (Util.GetNodeValue(node, "@group", "false") == "true")
{
if (isOneGroup)
{
isOneGroup = false;
break;
}
else
{
isOneGroup = true;
}
}
}
foreach (XmlNode node in nodeList)
{
//Invisible is auto excluded.
var isVisible = bool.Parse(Util.GetNodeValue(node, "@visible", "false"));
//Include needed columns.
if (isVisible)
{
colInfo = new ColumnInfo();
var colNameNode = node.Attributes["name"];
if (colNameNode == null)
{
throw new Exception("Column (" + idx.ToString() + ")
name from XML is missing.");
}
else
{
colInfo.ColumnName = colNameNode.InnerText;
}
colInfo.DisplayName = Util.GetNodeValue(node, "@display");
colInfo.DataType = Util.GetNodeValue(node, "@datatype", "string");
colInfo.IsGrouped = bool.Parse(Util.GetNodeValue(node, "@group", "false")) ||
colInfo.ColumnName.ToLower() == groupByColumn;
colInfo.IsTotaled = bool.Parse(Util.GetNodeValue(node, "@total", "false"));
colInfo.IsAveraged = bool.Parse(Util.GetNodeValue(node, "@average", "false"));
colInfo. DefaultValue = Util.GetNodeValue(node, "@default-value");
var align = node.Attributes["alignment"];
if (align == null)
{
//Default alignments based on type.
switch (colInfo.DataType.ToLower())
{
case "string":
colInfo.Alignment = "left";
break;
case "currency":
colInfo.Alignment = "right";
break;
case "percent":
colInfo.Alignment = "right";
break;
case "integer":
colInfo.Alignment = "right";
break;
case "datetime":
colInfo.Alignment = "center";
break;
default:
colInfo.Alignment = "left";
break;
}
}
else
{
colInfo.Alignment = align.InnerText.ToLower();
}
if (isOneGroup && colInfo.IsGrouped)
{
//If it's one group list.
groupColumnInfo = colInfo;
}
else
{
//Non-grouped data list or the list having more than one group column.
colInfoList.Add(colInfo);
}
}
idx++;
}
return colInfoList;
}
XML 节点解析器还会为检索到的 col 节点的任何 XML 属性设置一个默认值,但 name 属性除外。因此,理论上,在向描述符文件添加任何新的 col 节点时,只需要 name 属性和其 string 数据类型。此外,col 节点具有 default-value 属性,我们可以用它来指定当传入的数据值为 0(对于数值类型)、null 或空时,列中应显示的任何期望值。
设置列宽
所有数据列的宽度值都需要为创建 PDF 表格而明确定义。PdfDataReport 工具支持手动或自动设置列宽。描述符中 col 节点的 fixed-width 属性如果存在任何正值,将覆盖该列的默认自动宽度设置。在这种情况下,任何宽度超过固定列宽的文本都将在该列中换行。下面的 XML 行示例会将 Customer 列的宽度设置为 1.8 英寸(度量单位在报告配置文件中设置 - 详见示例 App.config 文件中的 UnitOfMeasure 键)。
<col name="CustomerName" display="Customer" datatype="string" fixed-width="1.8" />
大多数 PDF 数据列表使用自动列宽,如产品订单活动报告所示。设置自动列宽需要首先计算列主体的总数据字符宽度,并取该列所有数据行的最大值。在处理每条数据记录的循环中,检测列主体最大宽度的代码如下:
currentTextWidth = bodyFont.TextWidth(BODY_FONT_SIZE, dataString.Trim());
if (textWidthForTotalCol > currentTextWidth)
currentTextWidth = textWidthForTotalCol;
if (currentTextWidth > textWidth)
textWidth = currentTextWidth;
然后,该过程计算列标题显示中最长单词的宽度,并从最大总主体字符宽度和最长标题显示单词宽度中选择较大的数值。
var wordWidth = 0d;
var headerFontSizeForCalculation = HEADER_FONT_BOLD ?
HEADER_FONT_SIZE * BOLD_SIZE_FACTOR : HEADER_FONT_SIZE;
List<string> dspWords = colInfoList[idx].DisplayName.Split(' ').ToList();
foreach (var dspWord in dspWords)
{
//Check for some symbol column such as checkbox or star.
currentTextWidth = headerFont.TextWidth(headerFontSizeForCalculation,
dspWord == "" ? "*" : dspWord);
if (currentTextWidth > wordWidth)
wordWidth = currentTextWidth;
}
if (wordWidth > textWidth)
{
textWidth = wordWidth;
}
计算出的所有列的宽度数据被缓存到 List<double> columnWidths 中,该列表将被转换为数组,用于调用 PdfFileWriter.rptTable.SetColumnWidth 方法。
rptTable.SetColumnWidth(columnWidths.ToArray());
自动选择纸张大小
可打印的 PDF 文档受限于特定大小或类型的纸张。对于数据列表报告,页面的宽度取决于总列宽。PdfDataReport 工具可以通过计算页面内容宽度(总列宽加上左右边距)来自动选择纸张大小或方向,其依据是以下事实和规则:
-
需要从配置文件的
PaperSizeList键中提供预定义的纸张尺寸列表。示例应用程序默认设置了 8.5x11、8.5x14、11x17 和 12x18 英寸的纸张尺寸。这些大多是美国常用的纸张尺寸。 -
如果页面内容宽度不超过第一种纸张尺寸(示例应用程序中为 8.5x11)的纵向宽度,则会选择该纸张的纵向方向。否则,将使用第一种纸张尺寸的横向方向。
-
如果第一种纸张的横向尺寸不适合,后续所有选择都将是横向方向,并增加纸张尺寸,例如横向的 8.5x14、11x17 等。
-
如果页面内容宽度超过了配置列表中预定义的最大横向纸张宽度,那么报告将使用计算出的实际页面宽度和最后一种预定义页面尺寸的纸张高度进行显示。
以下代码行显示了实现细节。
//Automatic paper size and orientation selections.
var pageSizeOptionArray = PAGE_SIZE_OPTIONS.Split(',');
var pageSizeOptionList0 = new List<SizeD>();
foreach (var elem in pageSizeOptionArray)
{
var elemArray = elem.Split('x');
var item = new SizeD()
{
//Set landscape orientations in data array by default.
Height = double.Parse(elemArray[0].Trim()),
Width = double.Parse(elemArray[1].Trim())
};
pageSizeOptionList0.Add(item);
}
//Sort it in case input list is not in sequence of small to large size width.
var pageSizeOptionList = pageSizeOptionList0.OrderBy(o => o.Width).ToList();
//Now add portrait orientation for the first item.
pageSizeOptionList.Insert(0, new SizeD()
{
Width = pageSizeOptionList[0].Height,
Height = pageSizeOptionList[0].Width
});
//Pick up minimum page size based on maximum total column width plus margins
//and then update page size.
var leftMargin = MAXIMUM_LEFT_MARGIN;
var rightMargin = MAXIMUM_RIGHT_MARGIN;
var sizeMatched = false;
var totalColummWidth = columnWidths.Sum();
foreach (var item in pageSizeOptionList)
{
//Left and right margins are dynamically set between minimum and maximum values.
var spaceForMargins = item.Width - totalColummWidth;
if (spaceForMargins > MINIMUM_WIDTH_MARGIN * 2)
{
document.PageSize.Width = item.Width * document.ScaleFactor;
document.PageSize.Height = item.Height * document.ScaleFactor;
sizeMatched = true;
//If space smaller than max config values,
//set remaining space proportionally for left/right margins.
if (spaceForMargins < (leftMargin + rightMargin))
{
leftMargin = spaceForMargins * leftMargin/(leftMargin + rightMargin);
rightMargin = spaceForMargins - leftMargin;
}
break;
}
}
if (!sizeMatched)
{
leftMargin = MINIMUM_WIDTH_MARGIN;
rightMargin = leftMargin;
document.PageSize.Width = (totalColummWidth + leftMargin + rightMargin) *
document.ScaleFactor;
//Use height of the last pre-defined page size.
document.PageSize.Height = pageSizeOptionList[(pageSizeOptionList.Count - 1)].Height;
}
当点击示例应用程序演示页面上的“自动选择纸张大小或方向”链接时,页面会以横向信纸尺寸(11x8.5)显示,因为页面内容宽度大于纵向方向(8.5x11)的纸张尺寸。

列对齐
使用默认的 PdfFileWriter.PdfTable 设置,页面上的列以两端对齐的方式呈现,即左右边距都对齐,多余的空间分布在列内。这是通过微调每列的宽度,使总列宽等于表格宽度来实现的。PdfDataReport 工具也可以使用左对齐方式,即页面内容仅与左边距对齐,剩余的空白区域向右边距延伸。之前所有的 PDF 页面截图都显示了左对齐方式,这是通过添加一个占据所有剩余空白空间的虚拟列来实现的。
//If not uisng justify page-wide layout, all remaining space needs to be a dummy column.
if (!JUSTIFY_PAGEWIDE)
{
var dummyColWidth = rptTable.TableArea.Right - columnWidths.Sum();
columnWidths.Add(dummyColWidth);
colInfoList.Add(new ColumnInfo() { ColumnName = "Dummy", ActualWidth = dummyColWidth });
}
可以在报告配置文件中设置 JUSTIFY_PAGEWIDE 标志值。对于使用 PdfDataReport 工具创建的报告,如果该标志或其值不存在,则列默认左对齐。将该标志设置为 true 将使列在页面内容宽度内两端对齐。当点击示例应用程序演示页面上的“使显示列与页面同宽”链接时,测试自动页面选择报告将展示两端对齐的布局。

分组数据显示与分页
PdfDataReport 工具可以显示分组的数据行和聚合数据项,如第一张产品订单活动报告的截图所示。为了保持报告内容清晰易读,该工具只支持按一个字段对数据列表进行分组。这应该能满足大多数业务数据报告的需求。
为了在 PDF 数据报告中正确显示分组的数据记录,一些设计考虑和实现方法非常重要,如下所述:
-
C# 列表数据源在附加到
builder.GetPdfBytes方法的List<T> dataList参数之前,必须已经按分组字段/属性排好序。这样PdfDataReport工具才能处理各个分组的页眉、正文和页脚行。object prevValue = default(object); object currValue = default(object); foreach (var item in dataList) { currValue = item.GetType().GetProperty (groupColumnInfo.ColumnName).GetValue(item, null); //Start new group. if (!currValue.Equals(prevValue)) { //Footer row for last processed group (except first time). if (prevValue != null) { //Draw footer row for previous group here... } //Draw header row for current group here... prevValue = currValue; } //Draw body rows for current group here... } -
在处理循环中,添加分组依据列本身的操作将被跳过,因为该列在根据 XML 描述符填充
colInfoList时被排除在外。因此,不会显示分组依据列。取而代之的是,分组依据列的数据值以及可能的自定义静态文本将显示在组标题上。XML 描述符中的general/group-title节点定义了自定义静态文本和数据占位符。如果group-title节点及其值存在,该值将覆盖默认的文本和格式。//Set overwriting group title. groupTitle = Util.GetNodeValue(objXMLDescriptor, "/report/view/general/group-title"); . . . //Header row for current group. rptTable.Cell[0].Value = groupColumnInfo.DisplayName + " = " + currValue.ToString(); if (!string.IsNullOrEmpty(groupTitle)) { rptTable.Cell[0].Value = groupTitle.Replace("{propertyvalue}", currValue.ToString()); }; -
如果在 XML 描述符中指定了任何总计或平均值,以及该组的总记录数,都需要显示在组页脚上。详细的代码逻辑在
ReportBuilder.DrawGroupFooter方法中,但这里有一个如何绘制包含总计列的组页脚行的示例。//Group total row if (hasTotal) { //This label at least occupies width space of first two columns //that shouldn't be totalled columns. rptTable.Cell[0].Value = " Group Total"; foreach (var colTotalIndex in colTotalIndexList) { rptTable.Cell[colTotalIndex].Value = colInfoList[colTotalIndex].GroupTotal; } rptTable.DrawRow(); } -
当列表数据源中有任何总计或平均列时,应在第一个总计或平均列的起始位置之前为“组总计”或“组平均”标签留出足够的宽度空间。通常,任何总计或平均列都应放在前两三列之后,以保证总计或平均数值的正确显示。

-
自动分页需要在组与组之间以及报告的最后一行数据之后平滑地发生。为了遵循格式良好的数据列表文档的通用规则,特别是对于物理呈现的 PDF 数据列表文档,
PdfDataReport工具绝不会在下一页没有数据行的情况下分页。换句话说,下一页应该至少以特定组或整个报告的一行数据开始。这个规则避免了在页面上只显示页眉和页脚的情况。实现这个规则的代码逻辑有点复杂。但基本上,该工具在处理数据组中的最后一行时会计算剩余空间。如果空间不足以容纳该数据行加上组页脚行,页面将立即分页,将最后的数据行移到下一页。对于整个数据列表的最后一行,计算的空间余量包括报告页脚行。代码的主要部分在
DrawGroupBreak方法中。请参阅注释,了解代码行如何操作分页,并在分页点添加续页消息显示。private bool DrawGroupBreak(PdfTable rptTable, bool lastGroupItem = false, bool lastDataItem = false) { //Exclude condition where there is only entire row on page. if (rptTable.RowTopPosition == rptTable.TableArea.Top - rptTable.Borders.TopBorder.HalfWidth) return false; var room = 0d; var bottomLimit = rptTable.TableArea.Bottom + rptTable.Borders.BottomBorder.HalfWidth; //If remaining space is not enough for // 2 rows: for mid-group-row. // 3 rows: for last-group-row (with total/average). // 4 rows: for last-group-row (with total and average). // 6 rows: for last-group/report-row and report footer (with total only). if (lastGroupItem) { if (lastDataItem) { room = rptTable.RowTopPosition - rptTable.RowHeight * 6; } else { //For last-group-row scenario. if (hasTotal && hasAverage) room = rptTable.RowTopPosition - rptTable.RowHeight * 4; else if (hasTotal || hasAverage) room = rptTable.RowTopPosition - rptTable.RowHeight * 3; } } else { //For mid-group-row scenario. room = rptTable.RowTopPosition - rptTable.RowHeight * 2; } if (room < bottomLimit) { //Draw line. var pY = rptTable.RowTopPosition; // rptTable.BorderYPos // [rptTable.BorderYPos.Count - 1]; rptTable.Contents.DrawLine(rptTable.BorderLeftPos, pY, rptTable.BorderRightPos, pY, rptTable.Borders.CellHorBorder); //Draw message. var temp = ""; if (lastGroupItem) temp = "(A group record continues on next page...)"; else temp = "(Group records continue on next page...)"; //Backup style. var cellStyle = new PdfTableStyle(); cellStyle.Copy(rptTable.Cell[0].Style); //Set value and styles, and then draw continue row. rptTable.Cell[0].Value = temp; rptTable.Cell[0].Style.Font = bodyFontItalic; rptTable.Cell[0].Style.Alignment = ContentAlignment.BottomLeft; rptTable.DrawRow(); //Set style back rptTable.Cell[0].Style.Copy(cellStyle); return true; } return false; }
当点击示例应用程序演示页面上的“按订单状态分组的产品订单(组末分页)”链接时,将显示产品订单活动报告,其页面会在一个组的最后一行之前分页。
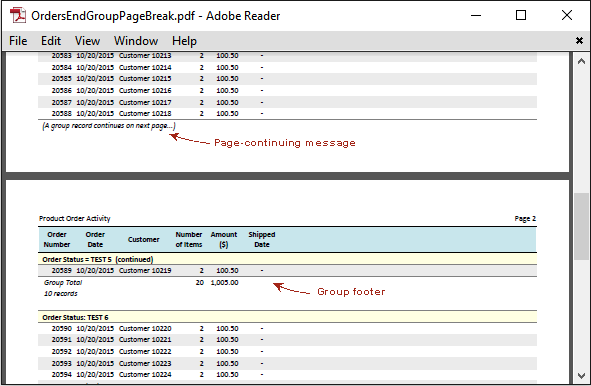
点击演示页面上的下一个链接,“按订单状态分组的产品订单(报告末尾分页)”,将显示在整个数据列表的最后一行之前分页的示例。在这种情况下,最后一页 PDF 上会有最后一行数据、组页脚行和报告页脚行。

设置背景和边框线颜色
PdfDataReport 工具为列标题、组标题、交替行、列标题和页脚线以及组标题和页脚线提供了有限但最可能被使用的预定义背景和边框颜色选择。如果这些颜色设置的任何配置项或其值不存在,报告生成过程将始终使用默认设置。你可以从报告配置文件中轻松更改这些颜色设置。你甚至可以通过以下步骤将任何新的颜色设置添加到工具中以满足你的需求:
-
通过在
PdfDataReport.ReportBuilder类中搜索selColor变量,你可以找到编写现有颜色选择项的代码位置。例如,组标题背景颜色的代码如下://Group header background color. Color selColor; switch (GROUP_HEADER_BK_COLOR) { case "FaintLightYellow": selColor = Color.FromArgb(255, 255, 238); break; case "VeryLightYellow": selColor = Color.FromArgb(255, 255, 226); break; case "LightYellow": selColor = Color.FromArgb(255, 255, 214); break; case "FaintLightGray": selColor = Color.FromArgb(230, 230, 230); break; case "VeryLightGray": selColor = Color.FromArgb(220, 220, 220); break; case "LightGray": selColor = Color.FromArgb(207, 210, 210); break; default: //VeryLightYellow selColor = Color.FromArgb(255, 255, 226); break; } DrawBackgroundColor(rptTable, selColor, rptTable.BorderLeftPos, cell.ClientBottom, rptTable.BorderRightPos - rptTable.BorderLeftPos, rptTable.RowHeight); -
将你自己的颜色项作为一个新的
case添加到switch块中。 -
在你的配置文件中的
appSettings部分找到相应的键。例如,组标题背景颜色的键如下:<!--Available GroupHeaderBackgroudColor settings: "FaintLightYellow", "VeryLightYellow" (default), "LightYellow", "FaintLightGray", "VeryLightGray", "LightGray"--> <add key="GroupHeaderBackgroudColor" value=""/> -
用你新颜色设置的
字符串表示来更新该值。
在您自己的项目中使用 PdfDataReport 工具
要将 Visual Studio 的 PdfDataReport 项目整合到您的开发环境中,请遵循以下步骤:
-
将 PdfDataReport 和 PdfFileWriter 项目的物理文件夹复制到您的解决方案根文件夹。然后在 Visual Studio 中打开您的解决方案,并将这两个项目作为现有项目添加到您的解决方案中。
-
从您的执行项目/程序集(调用 PDF 报告生成过程的项目)中设置对
PdfDataReport项目的引用。 -
创建您的 PDF 报告描述符文件,其中包含生成的数据列表报告的定义。将该文件放置到您的执行项目/程序集可以访问的位置。您可以使用执行项目/程序集的配置文件使描述符文件路径可配置。
-
如果您不想使用默认值,请在您的执行项目/程序集配置文件中为报告格式和样式设置添加或更新任何键和值。有关详细信息,请参阅
PdfDataReport.Test项目中的 App.config 文件。 -
在您的执行项目/程序集中,使用
dataList和xmlDescriptor参数调用ReportBuilder.GetPdfBytes方法。然后,您可以使用返回的 PDF 字节数组创建 PDF 文件,或直接在 HTTP 响应中将其传递给 Web 客户端,以便在浏览器上自动打开 PDF 报告。
.NET Core 3.1 相关变更
自从 .NET Core 3.0 发布以来,将示例应用程序及其库从 .NET Framework 4.x 移植到 .NET Core 成为可能。我曾尝试使用其他第三方库工具将应用程序升级到 .NET Core 2.2,但并未完全成功。.NET Core 3.1 还修复了使用 Windows 桌面库时的一些问题。PdfDataReport 库项目没有代码变更。升级的工作主要与 PdfFileWriter 库有关,以及对 PdfDataReport.Test 演示项目的一点点修改。
PdfFileWriter 项目
虽然 PdfDataReport 工具没有使用诸如图表、条形码、媒体等选项,但我仍然希望保持原始的 PdfFileWrite 库的完整性,将其所有可用功能都升级到 .NET Core 版本。不过,我没有测试那些在示例应用程序中未使用的功能。
以下是执行升级任务的步骤:
-
使用 Visual Studio 2019(版本 16.4 或更高)创建 .NET Core 3.1 库项目。
-
将所有类 *.cs 文件从现有的
PdfFileWriter项目复制到新的 .NET Core 项目中。 -
手动更新 PdfFileWriter.csproj 文件,使其看起来像这样(注意粗体显示的更新或添加的行):
<Project Sdk="Microsoft.NET.Sdk.WindowsDesktop"> <PropertyGroup> <TargetFramework>netcoreapp3.1</TargetFramework> <UseWindowsForms>true</UseWindowsForms> <UseWPF>true</UseWPF> </PropertyGroup> </Project> -
从 NuGet 包管理器中添加对
System.Drawing.Common(v4.7.0) 和System.Windows.Forms.DataVisualization(v1.0.0-prerelease 19218.1) 的引用。 -
删除 Bitmap.cs 文件,因为新的
System.Drawing命名空间提供了内置的Bitmap类。否则,你会得到转换错误。 -
保存、重启并重新生成解决方案。
PdfDataReport.Test 项目
.NET Core 3.1 代码上唯一的问题是调用 System.Diagnostics.Process 来用阅读器程序打开 PDF 文件的代码行。
当直接将 PDF 文档文件名传递给 ProcessStartInfo 对象时,该代码行在 .NET Framework 4.6.1 中可以正常工作。在下面的代码中,fileName 是文档文件名。代码将初始化在 Windows 系统中为该文件扩展名设置的默认应用程序。
//Start default PDF reader and display the file content.
Process Proc = new Process();
Proc.StartInfo = new ProcessStartInfo(fileName);
Proc.Start();
在 .NET Core 中,这样的代码行会产生错误“The specified executable is not a valid application for this OS platform”(指定的可执行文件不是此操作系统平台的有效应用程序)。参数 fileName 被视作可执行文件名而不是文档文件名。当分别将可执行文件名和文档文件名赋给 ProcessStartInfo 对象的属性时,它就可以工作了。在示例应用程序中,可配置项用于可执行文件名,其默认值设置为 Adobe Reader DC 安装的默认位置。
//Start default PDF reader and display the file content.
Process Proc = new Process();
var pdfReaderExe = ConfigurationManager.AppSettings["PdfReaderExe"] ??
@"C:\Program Files (x86)\Adobe\Acrobat Reader DC\Reader\AcroRd32.exe";
Proc.StartInfo = new ProcessStartInfo()
{
FileName = pdfReaderExe,
Arguments = fileName
};
Proc.Start();
您可以通过编辑 app.config 文件中的行来更改 PDF 阅读器工具或使用任何其他版本的 Adobe Reader。
<add key="PdfReaderExe" value="{your PDF Reader executable path}"/>
历史
- 2016年1月28日
- 使用 .NET Framework 4.0 的原始帖子
- 2020年2月10日
- 将示例应用程序升级到 .NET Core 3.1。相应地编辑或添加了一些章节的描述。
- 旧的 .NET Framework 源代码文件也更新到了 .NET Framework 4.6.1。