
C++ 和微控制器:使用和测试
5.00/5 (8投票s)
我使用 C++ 与微控制器的经验
引言
从历史上看,微控制器开发的主要语言是 C 语言。许多大型项目都是用 C 语言编写的。但时代在进步。嵌入式系统的现代开发工具已经支持 C++。然而,这种方法仍然相当罕见。不久前,我尝试在我的下一个项目中使用 C++。我将在本文中讨论这次经验。
我大部分的微控制器工作都是用 C 语言编写的。首先是客户要求,然后就成了一种习惯。同时,当我为 Windows 编写应用程序时,我使用 C++ 和 C#。
关于 C 和 C++ 之间的选择问题,我已经很久没有遇到过了。即使是 Keil MDK 发布了支持 C++ 的新版本,也没有让我感到困惑。如果你看一下 Keil 的演示项目,你会发现所有东西都是用 C 语言编写的。C++ 示例被放在一个单独的文件夹中,就像一个 Blinky 项目。CMSIS、LPCOpen 也都是用 C 语言编写的。如果“所有”人都使用 C 语言,那么这其中一定有原因。
NET Micro Framework 改变了这种局面。如果有人不知道,它是一个 .NET 的实现,允许在 Visual Studio 中用 C# 为微控制器编写应用程序。有关它的更多信息可以在这些文章中找到。
.NET Micro Framework 是用 C++ 编写的。受此启发,我决定尝试用 C++ 创建另一个项目。我必须说,我没有找到支持 C++ 的明确论据,但这种方法有一些有趣且有用的地方。
C 和 C++ 项目有什么区别?
C 和 C++ 的主要区别之一是 C++ 是一种面向对象的语言。众所周知的封装、多态和继承在这里司空见惯。C 是一种过程式语言。只有函数和过程,而模块(一对 _*.h* + _*.c*_)用于代码的逻辑分组。但是,如果你看一下 C 在微控制器中的使用方式,我们可以看到常见的面向对象方法。
让我们看看 Keil 的 MCB1000 示例中 LED 的代码(_Keil_v5\ARM\ Boards\Keil\MCB1000\MCB11C14\CAN_Demo_)
LED.h:
#ifndef __LED_H
#define __LED_H
/* LED Definitions */
#define LED_NUM 8 /* Number of user LEDs */
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:
#include "LPC11xx.h" /* LPC11xx definitions */
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
/*----------------------------------------------------------------------------
initialize LED Pins
*----------------------------------------------------------------------------*/
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6); /* enable clock for GPIO */
/* configure GPIO as output */
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
/*----------------------------------------------------------------------------
Function that turns on requested LED
*----------------------------------------------------------------------------*/
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
/*----------------------------------------------------------------------------
Function that turns off requested LED
*----------------------------------------------------------------------------*/
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
/*----------------------------------------------------------------------------
Output value to LEDs
*----------------------------------------------------------------------------*/
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
如果你仔细观察,你可以与面向对象编程进行类比。LED 是一个对象,它有一个 `public` 常量、构造函数、三个 `public` 方法和一个 `private` 字段。
class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED(); //Аналог LED_init
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
即使代码是用 C 语言编写的,它也使用了面向对象编程范式。_*.c*_ 文件是一个对象,它允许在 _*.h*_ 文件中描述的 `public` 方法的实现中使用封装机制。但没有继承和多态。
我看到的大多数项目中的代码都是用相同的风格编写的。如果您正在使用 OOP 方法,为什么不使用完全支持它的语言呢?如果您想将语言从 C 更改为 C++,您只需要更改语法,而不是设计原则。
考虑另一个例子。假设我们有一个设备,它使用通过 I2C 连接的温度传感器。但是设备有一个新的修订版,现在相同的传感器连接到 SPI。该怎么办?您应该支持设备的第一个和第二个修订版,这意味着代码应该足够灵活,以适应这些变化。在 C 语言中,您可以使用 `#define` 预定义,以免编写两个几乎相同的文件。例如:
#ifdef REV1
#include "i2c.h"
#endif
#ifdef REV2
#include "spi.h"
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
等等。在 C++ 中,您可以更优雅地解决这个问题。创建接口
class ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
以及两种实现
class Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
然后,您可以根据修订版本使用特定的实现。
class TemperatureGetter
{
private:
ITemperature* _temperature;
public:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
C 和 C++ 代码之间的区别似乎不是很大。面向对象版本看起来甚至更笨重。但它允许您做出更灵活的解决方案。
当您使用 C 时,您有两种主要解决方案:
- 使用如上所示的 `#define`。此选项不是很好,因为它“模糊”了模块的职责。结果是它负责多个项目版本。当这些文件的数量增加时,支持它们变得相当困难。
- 像在 C++ 中一样制作两个模块。在这种解决方案中,“模糊”不会发生,但这些模块的使用会更复杂。由于它们没有统一的接口,所以每对方法的使用都应该包含在 `#ifdef` 中。这会降低代码的可读性和可维护性。当分离的位置提高到更高的抽象级别时,代码将更加笨重。因此,需要为每个模块的函数考虑另一个名称,以便它们不重叠,这也可能导致代码可读性的恶化。
多态性的使用带来了美好的结果。一方面,每个类都解决了清晰的原子问题,另一方面,代码没有被污染。
在这两种情况下,仍然需要根据板卡修订版分支代码,但多态性的使用使得在程序的层之间移动分支位置更容易,并最大限度地减少了 `#ifdef` 的使用。
多态性的使用使得更容易实现一个更有趣的解决方案。
假设有一个新的修订版,它包含两个温度传感器。
同样的代码,只需最少的改动,就可以在运行时通过使用 `Init(&temperature)` 方法选择 SPI 或 I2C 实现。
这个例子非常简单,但在一个真实的项目中,我使用了相同的方法来实现基于两种不同物理数据接口的相同协议。这使得在设备设置中选择接口变得容易。
然而,尽管有上述所有事实,C 和 C++ 的使用差异并不是很大。C++ 的优点,与 OOP 相关,并没有那么明显,属于个人偏好范畴。但是,在微控制器中使用 C++ 存在一些严重问题。
使用 C++ 有何危险?
C 和 C++ 之间的第二个重要区别是内存使用方式。C 在很大程度上是静态的。所有函数和过程都有固定的地址,堆只在必要时才使用。C++ 是一种更动态的语言。通常,它涉及积极地使用内存分配和释放。这是 C++ 的一个巨大危险。微控制器资源非常少,因此控制它们非常重要。对 RAM 的不加控制使用会导致其中存储的数据损坏。许多开发人员都遇到过此类问题。
如果仔细查看上面的示例,可以注意到这些类没有构造函数和析构函数。这是因为它们从未动态创建。
使用动态内存(即使使用 `new` 关键字)总是会导致调用 `malloc` 函数,该函数从堆中分配所需数量的字节。即使您已经考虑周全并会仔细监控内存使用,您也可能会遇到内存碎片化的问题。
堆可以表示为一个数组。例如,堆中有 20 字节。

每次内存分配都会导致检查所有内存(从左到右或从右到左 - 这不重要),以查找是否存在预定数量的空闲字节。此外,这些字节必须全部连续位于一起。
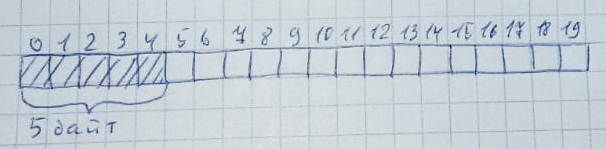
当内存不再需要时,它会恢复到原始状态。
很容易发生这样一种情况,即存在足够多的可用字节,但它们不按顺序排列。假设分配了 10 个区域,每个区域 2 字节。
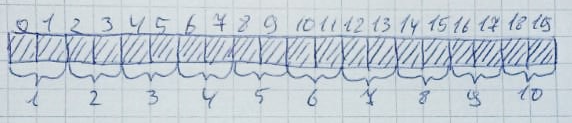
然后 2、4、6、8、10 区将被释放。
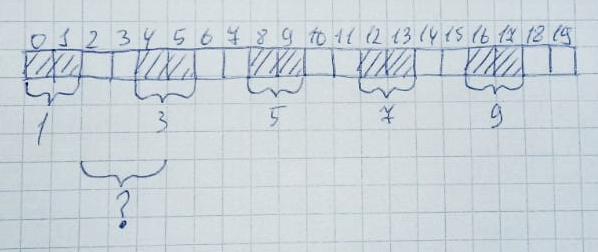
形式上,堆的一半(10 字节)仍然是空闲的。但是,您无法分配大小为 3 字节的内存,因为没有 3 个连续的空闲单元格数组。这称为内存碎片化。
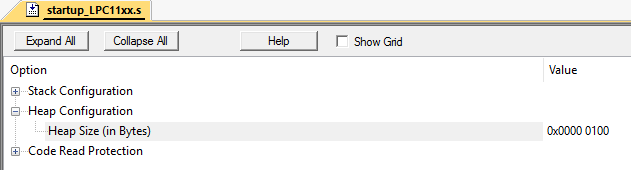
这种情况很容易伪造。我在 Keil mVision 的 LPC11C24 上做了这个。
让我们将堆大小设置为 256 字节。
假设我们有两个类。
#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
正如您所看到的,`bar` 类将比 `foo` 类占用更多的内存。
让我们用 14 个 `bar` 类的副本填充堆。然后,无法为 `foo` 类分配内存。
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
但是,如果只创建 7 个 `bar` 类的副本,`foo` 类也可以创建。
int main(void)
{
foo *f;
bar *b[14];
//b[0] = new bar();
b[1] = new bar();
//b[2] = new bar();
b[3] = new bar();
//b[4] = new bar();
b[5] = new bar();
//b[6] = new bar();
b[7] = new bar();
//b[8] = new bar();
b[9] = new bar();
//b[10] = new bar();
b[11] = new bar();
//b[12] = new bar();
b[13] = new bar();
f = new foo();
}
然而,如果你首先创建 14 个 `bar` 类的副本,然后删除 0、2、4、6、8、10 和 12 号副本,那么由于堆的碎片化,为 `foo` 类分配内存将无法完成。
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
事实证明,完整的 C++ 无法完全使用,这是一个显著的缺点。从架构角度来看,C++ 优于 C,但优势不大。因此,转向 C++ 并不会带来任何显著的益处。但它也不会带来任何大的负面影响。因此,由于差异很小,语言选择将仅仅是开发人员的个人偏好。
但是对于我自己来说,我发现在使用 C++ 方面有一个显著的优点。事实是,如果方法得当,微控制器的 C++ 代码可以很容易地在 Visual Studio 中通过单元测试进行覆盖。
C++ 的一个巨大优势是能够使用 Visual Studio。
对于我来说,微控制器代码测试一直是一项艰巨的任务。代码通过各种方式进行测试,但是创建一套完整的自动化测试系统总是需要巨大的成本,因为它需要创建特殊的硬件并为其编写特殊的固件。特别是当我们谈论由数百个设备组成的 IoT 分布式系统时。
当我开始编写 C++ 项目时,我想尝试将代码插入 Visual Studio,并仅使用 Keil mVision 进行调试。首先,Visual Studio 有一个非常强大且易于使用的代码编辑器。其次,Keil mVision 没有与版本控制系统友好的集成,但 Visual Studio 已经将一切自动化了。第三,我曾希望有机会通过单元测试覆盖部分代码,这些测试在 Visual Studio 中也得到了很好的支持。第四,这是新版本的 Resharper C++——Visual Studio 的 C++ 代码扩展,它可以帮助您遵循代码风格并避免许多潜在的错误。
在 Visual Studio 中创建项目并将其连接到版本控制系统不会引起任何问题。但是使用单元测试就不那么容易了。
与硬件分离的类(例如,协议解析器)可以很容易地测试。但我想要更多。在我的项目中,我使用 Keil 的头文件来操作外设。例如,`LPC11C24` 的 _LPC11xx.h_。这些文件根据 CMSIS 标准描述所有寄存器。特定寄存器的定义通过 `#define` 完成。
#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
事实证明,如果重写寄存器定义并进行一些存根,使用外设的代码可以在 Visual Studio 中很好地编译。此外,如果你创建一个 `static` 类并将其字段指定为寄存器地址,你将获得一个完整的微控制器仿真器,它允许你测试外设代码。
#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
然后这样做
#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
这样就可以在 Visual Studio 中以最少的改动编译和测试微控制器的整个项目代码。
我写了 300 多个测试,涵盖了纯硬件方面和抽象于硬件的代码。提前发现大约 20 个严重错误,由于项目规模,如果没有自动化测试,这些错误将不容易检测到。
摘要
在微控制器开发中是否使用 C++ 是一个复杂的问题。上面我已经说明,一方面,完全支持 OOP 的架构优势并不大,另一方面,堆的使用限制是一个相当大的问题。考虑到这些方面,C 和 C++ 在微控制器开发中的差异并不大。因此,它们之间的选择只能由开发人员的个人偏好来决定。
然而,我发现使用 C++ 有一个很大的优点——使用 Visual Studio。这可以显著提高开发的可靠性,因为它能够与版本控制系统配合使用,利用单元测试(包括外设测试)以及 Visual Studio 的其他优势。
历史
- 2016 年 2 月 29 日:初始版本