
CYQ.Data 从入门到放弃 ORM 系列:开篇:自动化框架编程思想
这是 cyq.data ORM 的一篇介绍文章。
引言
这是 cyq.data ORM 的一篇介绍文章,这也是我的第一篇博文。
背景
随着 CYQ.Data 开始免费回来使用,发现用户的情绪更加激动,为了保持这种持续性的兴奋,所以萌生了开源的想法。
同时,这个框架已经经历了 5--6 年的持续进化,之前发布的早期教程已经太落后了,包括使用方法,以及相关的介绍都容易引起误导。
为此,我打算再次写一个系列来介绍最新版本,让大家从传统的 ORM 框架编程,过渡到自动化编程的类型思考(自创词)。
所以:这个新的系列名称是:CYQ.Data 从入门到放弃 ORM 系列
CYQ.Data 是什么?
1:它是一个 ORM 框架。
2:它是一个数据层组件。
3:它是一套工具库。
让我们看一张图

从上面的图可以看出,它不仅仅是一个 ORM,还附带了不少功能。
因此
写日志:你再也不需要:Log4net.dll
操作 Json:你再也不需要 newtonjson.dll
分布式缓存:你再也不需要 Memcached.ClientLibrary.dll
目前的框架只有 340K,后续版本不会在乱加东西,体积还会更小。
传统 ORM 的发展过程:
看一个千篇一律的发展趋势

搜索国内的 .NET 开源系统:ORM,大概有 110 个,在 CodeProject 中发现的 .NET 系统:有 ORM,数量大概 530 个。
看了很多之后,很容易发现,ORM 的市场都是大同小异,唯一的区别
那就是,自定义的查询语法,每个人都在自己的招牌下玩,并且一定要玩出花样,要跟别人家的不一样,显出自己的优越感。
同时,如此广泛的查询语法糖,没有多大意义,并且也浪费了很多开发者的时间,因为学习成本就是看一本书或者系列入门到精通。
综合看来,有没有能逃出这个俗套的,那是有木有!说明 ORM 做的都是套路,创新是需要艺术细胞的。
曾经,我也有一个非常简单的传统 ORM 叫 XQData
我在 2009 年制作的,现在还躺在硬盘上,就随意分享出来,给没有太多朋友用的开源 ORM 入门指南。
XQData 源码(SVN 下载)地址:http://code.taobao.org/svn/cyqopen/trunk/XQData
CYQ.Data 自动化框架的思想
CYQ.Data 在早期版本(具体不说是多早),和传统的砖头式 ORM 相比,除了杂七杂八,看起来有点波澜,鼓励和关注的价值之外,并没有感觉在哪里牛逼。
随着自动化框架思想的形成,经过几年的改进,现在和实体类型的 ORM 之间的差距已经不在同一个级别了。
以实体类型 ORM 的方式写代码:实体继承自 CYQ.Data.Orm.OrmBase
using (Users u = new Users())
{
u.Name = "cyqdata";
u.TypeID = Request["typeid"];
//....
u.Insert();
}
看起来很简单是不是?没错,但是过于死板,写起来不够智能化,就是完美的一对耦合。
我为什么推荐使用 MAction?因为它具有自动化框架的思想
请看下面的代码
using (MAction action = new MAction(TableNames.Users))
{
action.Insert(true);//This intermediate is no single assignment process
}
和看到的代码相比,它的优势在于
1:代码量少,并且没有中间的赋值过程;
2:不依赖数据库字段和属性:无论你修改前台界面,还是修改数据库,后台代码都不需要调整;
如果增加操作和事务切换表,这次拥有两个优点
1:实体 ORM:只能使用一次分布式事务,包含一个片段,一个链接不能重用。
2:MAction:可以是你本地事务,可以是你重用的链接。
上面的 MAction 代码,有一个依赖 TableNames.Users 表,如果变成参数,你将找不到相同的天空
using (MAction action = new MAction(ParameterTableName))
{
action.Insert(true);
}
所以这两行代码,你发现完全解耦和数据库和界面。
在这里你会发现,它是一个实体类型 ORM 框架和不是一个层级
1:因为它真正的解耦了数据层和 UI 层。
2:因为它基于自动化编程框架的思想,已经不再是赋值的一个过程。
看到这里,再回过头来看 ASP.NET Aries AjaxBase 框架的开源,你就知道为什么后台总是这么一点代码就能处理任何自动化的表和数据了
下面的方法只需要前台只需要传递一个表名(+对应数据)

如果进一步,表名配置在数据库中的 Url 菜单字段,那么就形成一个自动化的页面
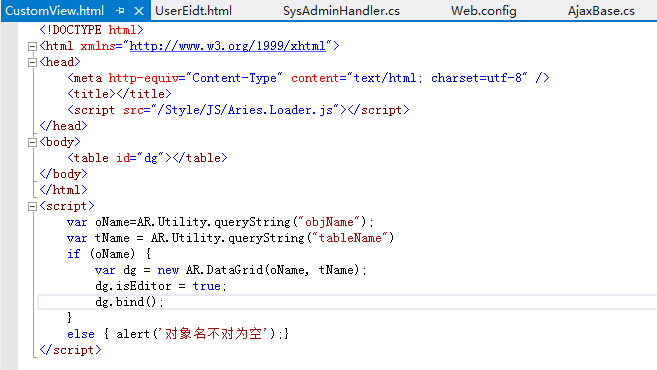
这些自动化框架编程思想的自动化,ORM 实体是不可能有的,只能充当小角色,实体 ORM 接口生成一大堆代码敲一大堆代码。
看一个 API 接口设计:
假设有一个 App 项目,Android 和 IOS,他们都需要调用 Back API,这时候,你如何设计?
不能动,等着 App Manager 产品,接口原型确定了,然后和 App 接口需要的元素,以及开发 App 的开发工程师谈,然后写一个方法来请求?
毕竟,你要知道读什么表,查询什么数据,这样你只能被动的?每个增加页面或者功能,你都得回去写一堆业务逻辑代码,然后进行 FBI?
累,是不是?
直接看这个框架,你的设计过程将变得多么简单,优雅,抽象思维
接口核心代码
using (MAction action = new MAction(tableName))
{
action.Select(pageIndex, pageSize,where).ToJson();
}
接下来,你要设计的是
1:App 客户端好请求参数格式:{key: 'xx', pageindex: 1, pagesize: 10, wherekey: 'xxxx'}
2:映射表名到数据库(Key, Value),App 只需传递 Key 时请求的名称
3:根据实际业务,构好条件。
几个这样的通用接口设计,给 app 开发者,你就会看到好处
1:可以减少很多沟通成本。
2:API 设计的通用性,减少代码量,配置化,维护简单。
3:一开始就可以动手,不需要等到 App 出来原型的手。
4:就算有表,长成什么样,后期都可以根据数据库配置提前。
5:实现之后,对于公司改变业务,改变项目,也可以用,因为你的设计和具体业务是解耦的。
试想一下,换做实体 ORM,你是不是得提前有一个数据库,生成一堆硬编码,然后继续 New 具体的实例,思维的局限性只能局限于具体的业务。
框架的抽象思维和条件推导的智能
看一张图

常用的数据表 CRUD 操作,从图中可以看出,最终框架抽象出两个核心参数
表 + where 条件
我曾经也思考过语法糖,是否要将 Where 这块设计成:.... .Select(...) Where(...) Having(...) GroupBy(...) OrderBy(.. .) ...
最后还是坚持住初心的
1:开发者没有学习成本。
2:保持框架年轻化的创意。
3:具备自动化框架的思想。
语法糖的劣势
1:框架本身设计复杂,增加的异化程度。
2:用户学习成本,增加的使用复杂度。
3:不适合自动扩展:设计已经固化,无法根据某些条件和 Key 表动态构建查询!只适合具体的业务,不适合自动化编程。
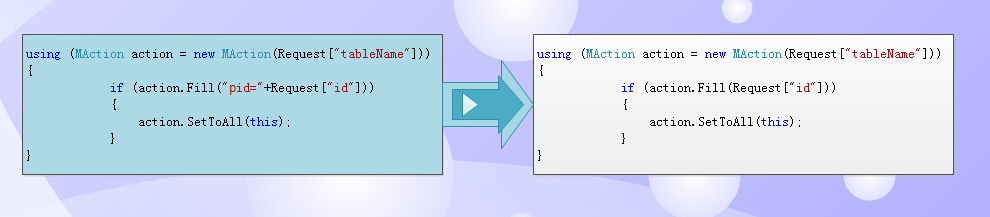
通过智能推导去除(因为不同的表主键不一样),智能生成推导,让程序员传过去的是主要关心的值,而不是关注任何一个具体命名的主键的参数名。
如果值是 “1,2,3” 这种逗号分隔的多值,框架会自动推导转换成 IN (1,2,3) 条件。
看两段代码:左边还是比较完整的 Where 条件,右边是推导类型的智能编程。
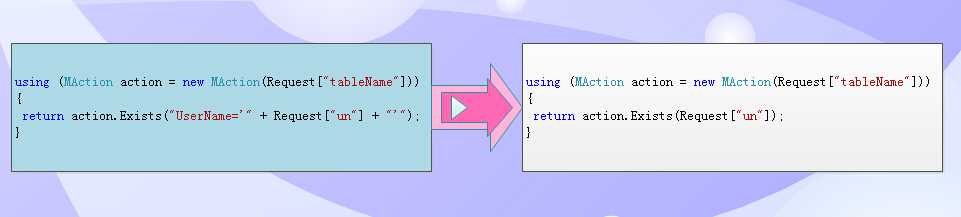
注意:传统的值一样,但是我们想要的是 UserName,不是主键,系统能推导出来?
这时候系统会根据值的类型,主键,唯一键的等效类型进行综合分析,该值应该用于构建主键还是唯一键的 where 。
(PS:唯一键的推导昨天才完成功能,所以只有最新版本才有。)
因为框架的智能推导功能,屏蔽了字段的差异,所以用户只需要关心传统的值。它也让你体会到了自动化框架编程思想的重要功能。
自动化批量编程
看一张图:DataTable:它和各种类型数据之间直接进行批量转换
 DataTable 是核心之一,框架有专门介绍它的文章。
DataTable 是核心之一,框架有专门介绍它的文章。
当然,Table 构建,经常是基于行,所以看一张图:MDataRow(它是一个核心的单行数据)
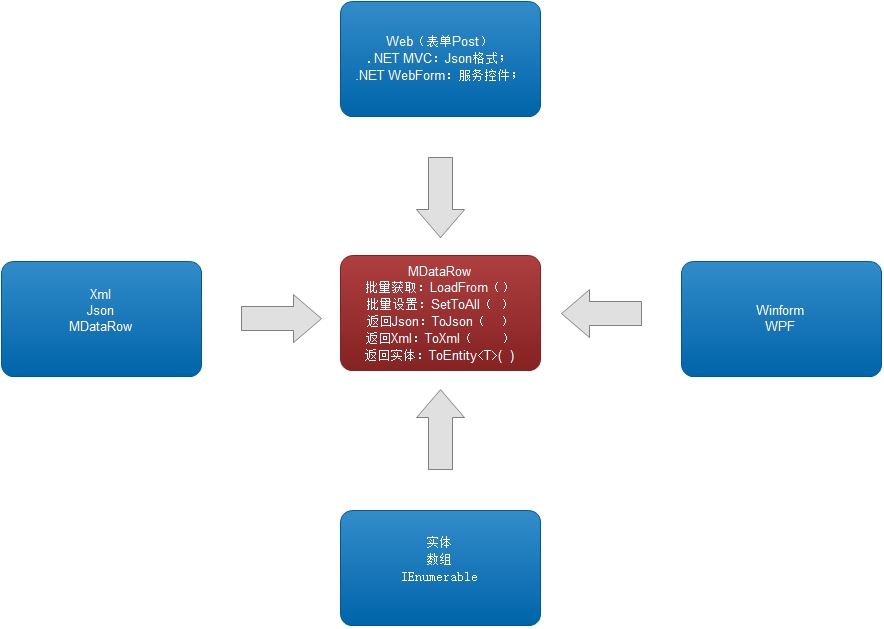 正是因为 DataRow 打开了单行批量数据的来来往往,所以才造就了 MDataTable 的多行批量处理。
正是因为 DataRow 打开了单行批量数据的来来往往,所以才造就了 MDataTable 的多行批量处理。
其实 MDataRow 是实现核心的层,但是它比较低调。
总结
当你使用编程框架的时候,你就会发现更关心的是:数据的流向,以及如何去构建抽象系统的配置参数。
在大部分编程时间里,除了具体的字段含义需要特别关注之外,大部分都是基于自动化编程思想,数据流思想。
早期的系列:没有这种编程思想,必然导致看了每篇介绍后都会有一种一种格格不入的感觉。
现在的系统:自动化框架编程思想,也是深受客户忠诚度喜爱的原因,特别是免费之后。
当然,这个系列后续会有重写教程,教程和源码都会同步到SVN,敬请期待。
PS:如果你想尝试使用它,你可以在 nuget 上搜索 cyqdata。