
基于 Intel Edison 的生物识别锁, 带有云语音和面部生物识别的 IoT 安全锁
4.95/5 (16投票s)
从拆箱到原型,一份完整的C#和Node.js英特尔爱迪生产品开发指南,包含一个实时云生物识别物联网项目
"一个多模态生物识别系统,结合云端语音生物识别和面部生物识别,其中PC应用采用C#编写,面部和语音生物识别物联网应用采用Node.js编写,通过MqTT和Dropbox的存储即服务进行通信,以提供一个基于英特尔爱迪生的生物识别安全储物柜。"

- 下载 BiometricLocker-NodeJsIoT_App.zip - 13 KB
- 下载 myFirstProject.zip - 8.7 KB
- C# 语音生物识别 面部生物识别 Dropbox MqTT PC 物联网应用 - 28 MB
目录
A 部分:让我们学习
1. 背景
2. 英特尔爱迪生入门
2.1 设置您的开发环境
2.2 加载操作系统 - 将 Linux Yocto 镜像烧录到爱迪生
2.3 配置英特尔爱迪生
2.4 远程登录
2.4.1 通过 SSH 使用爱迪生
2.4.2 文件传输
2.5 解决 WiFi 问题
3. 设置开发环境
3.1 板载 LED 开关
3.2 LED 闪烁,物联网的“Hello World”
3.3 为爱迪生板供电
3.4 英特尔 XDK 入门
4. 使用 Node.js 和 Grove 组件的嵌入式和物联网工作流程
4.1 小项目 1:根据按钮按下状态开关 LED
4.2 小项目 2:使用 MqTT 进行远程控制
4.2.1 MqTT
4.2.2 在英特尔爱迪生中使用 MqTT
4.3 小项目 3:根据室内光线控制灯光强度
4.3.1 在英特尔爱迪生中使用 LCD
4.3.2 使用 LDR
4.3.3 PWM - 根据 LDR 值控制灯光强度
4.3.4 舵机控制
5. 在英特尔爱迪生中设置音频和摄像头
5.1 使用英特尔爱迪生设置网络摄像头
5.2 设置音频
B 部分:让我们制作
6. 系统设计
6.1 系统架构
6.2 制造
6.3 使用 Knurld 进行语音识别
6.3.1 理解语音识别
6.3.2 Knurld API 和服务
6.3.3 Knurld 处理流程
6.4 使用微软认知服务(牛津人工智能)进行面部验证
6.4.1 理解面部识别和多生物识别
6.4.2 微软认知服务 - 人脸 API
6.5 Dropbox - 应用与生物识别端点之间的桥梁
7. 编码 - 为储物柜开发软件套件
7.1 PC 应用
7.1.1 设置和注册
7.1.2 语音注册
7.1.3 面部注册
7.1.4 在 C# 中调用云服务的通用方法
7.2 物联网设备应用
8. 结论
A 部分:让我们学习
1. 背景
除了常见的“到2020年数十亿设备互联,万亿美元经济”之外,另一个经常与物联网联系在一起的说法是“安全是一个挑战”。如何创建更安全的框架以在设备与云之间以及边缘设备之间建立更安全的通信,是物联网研究和开发领域之一。当我开始规划本教程的物联网项目时,我想研究物联网的安全方面。我最初的计划是研究各种加密级别并围绕此编写教程。但后来我意识到,没有坚实用例的教程对读者来说用处不大。我还想在最终产品的背景下审查物联网生态系统提供的安全上下文。所以,我开始思考一个可以展示安全方面的产品。收银箱通常被小企业用来存放日常交易的资金。我们许多人也在家里有储物柜。我们把必需品和贵重物品放在储物柜里。传统上,储物柜通过钥匙保护,而钥匙很容易伪造。一些尖端的储物柜还提供基于指纹验证的系统。基于生物识别的用户认证被认为是这种锁更复杂的安全扩展。因此,我认为生物识别安全将是一个非常适合构建高度安全系统的系统。
毋庸置疑,这些系统在离线环境中工作,并且是相当独立的系统。所以我想“如果有一个能在物联网生态系统上运行的安全储物柜,那岂不是很好吗?”
现在,这个想法不仅仅是因为我想围绕物联网和云开发一个安全的系统,它相对于传统系统还有一定的优势。首先是解决方案的可扩展性。例如,让我们考虑一个银行储物柜系统。不同的账户持有人有各自的储物柜。假设银行实施了一个离线解决方案,随着客户群的增长,系统将面临严重的可扩展性问题。现在让我们假设银行想要开设更多的分支机构。在每个分支机构中,持有储物柜的用户都必须手动注册。如果客户更改地点,他通常需要释放当前的储物柜并在新地点申请一个新的。这对银行来说是一个繁琐的过程。因此,可扩展性和移动性成为离线生物识别解决方案的核心问题。另一个重要问题是生物识别系统本身的安全问题。确保生物特征数据库在本地服务器中是安全的也具有挑战性。有一整套服务和解决方案用于确保本地存储中的数据安全。
现在,设想一下,如果我们能将解决方案带到核心而非停留在边缘会怎样?核心,或者现在通常所说的云,是一个极其可扩展的基础设施,天生就具备高可靠性、安全性和计算能力。现在想象一下,如果我们将刚才讨论的银行储物柜生物识别解决方案在云端实现,银行就不必担心记录的本地安全、系统维护、客户的可扩展性或移动性。他们可以专注于自己的业务,而安全性和可扩展性将由云端负责。这正是这个名为“生物识别储物柜”项目的动力。
云还提供其他优势。例如,银行可以轻松提供基于移动设备的验证系统。因此,为储物柜收集的用户生物特征可以轻松扩展到其他核心银行服务。例如,用户可以使用其生物特征访问其网上银行。银行可以将服务扩展到ATM机。它们甚至可以扩展到移动银行。移动设备现在是个人甚至一些企业应用程序最受欢迎的平台,因此服务在云端变得更加重要,以便它们可以跨不同设备和服务区域进行扩展。
因此,从物联网生态系统的角度以及可扩展的企业安全系统来看,基于云的生物识别储物柜是一个很好的产品。
但还有另一方面需要一些思考。哪种生物特征?虹膜、指纹、人脸、声音、掌纹是一些流行的生物特征选择。但哪种既经济又可扩展呢?人脸立即浮现在我们脑海中。为什么?因为它不需要额外的硬件。手机有摄像头,平板电脑有摄像头,笔记本电脑也有摄像头。但是,生物识别系统通常容易受到攻击。例如,人脸生物识别系统很容易通过在摄像头前展示用户的高清照片来欺骗。活体检测系统就是为了应对这种威胁而开发的,它会动态要求用户做出一些面部表情,比如微笑或眨眼。如果用户能做到,他就会被认为是活的,并且其人脸将被验证。然而,不幸的是,由于这种检测需要后续帧,许多商业人脸生物识别提供商未能提供开箱即用的解决方案。还有其他验证用户的方法吗?当然是声音。如果要求用户以随机顺序说出某些短语,那么他就会被认为是活的。这进一步增强了系统的安全性。但最好的部分是,像人脸一样,即使这个系统也不需要特殊的硬件,因为平板电脑、手机和笔记本电脑都有麦克风,可以用来录制用户的声音。
因此,一个结合面部和语音生物识别的基于云的生物识别系统将是理想的移动、可扩展和可靠的安全(更精确地说,是认证)系统,将是安全系统最明显的选择。
只有对连接“事物”和客户端都进行充分思考,才能构建高效的物联网生态系统。因此,我们提出了一种新颖的“基于云的人脸和语音生物识别安全储物柜”。然而,本教程的重点将围绕在边缘物联网设备中实现这些技术(因为最终储物柜是一个事物,而且该事物必须是安全的)。
最后一个也是最重要的问题是“哪种设备?”树莓派?Beagle Bone?Arduino Yun?在概念上花费了大量时间之后,我很快就决定选择英特尔爱迪生。为什么?
因为,相信我,与英特尔爱迪生相比,没有任何东西能让你的物联网原型设计更容易,你将在本教程的过程中学习并承认这一点。顺便说一句(你完全可以忽略这一点),我是一名英特尔软件创新者,我对英特尔技术情有独钟。而且,英特尔非常慷慨地免费提供了整套硬件套件(耶!!!秘密揭晓)。但是,即使你没有免费获得它,并且需要为此花钱,我也建议你这样做。因为英特尔爱迪生和Grove套件的组合真的能让一个10岁的孩子也掌握物联网技能。
文章组织结构
当我解决了我想处理的问题领域后,下一个摆在我面前的显而易见的问题是,我想通过本教程涵盖什么。
一个更简单的选择是为一些入门指南提供外部链接,并将本文的重点放在核心概念上。但后来我想,如果我从零开始创建一个产品,为什么不构建一个完整堆栈的教程呢?从概念化到设计和原型制作?因此,我决定不将本文限制为仅限于我们的生物识别储物柜的代码或硬件解释,而是决定指导一个完全没有接触过物联网生态系统的新手(或女孩!!!无性别歧视!)去鼓励、帮助、指导和指导开发一个商业级的物联网产品。
如果您已经是物联网领域的行家,或者是Arduino DIY爱好者,并且对“事物”有所了解,您可以直接跳到介绍安全性的部分。如果您是安全专业人士,并且想了解您的技能如何在物联网中使用,您可以跳过安全主题,重点关注物联网方面。无论您是专业人士、业余爱好者,还是只是好奇的读者,您都会从本文中找到有趣的学习内容。如果您找到了,请留下评论。准备好了吗?太棒了,那我们开始吧。但是,在此之前,一个普遍的警告:- 这将是一篇篇幅巨大的文章,因此建议您收藏,确保您的咖啡或啤酒储备(无论您喜欢什么)能支撑到阅读结束。
如果您已经是活跃的开发者、DIY爱好者或黑客,请跳过下一段;绝对的初学者建议阅读本节的脚注。
一些针对初学者的快速入门链接
由于物联网包含框架、协议、连接、云、集线器、总线、设备、标准等等,因此建议您遵循一些物联网基础教程和文章。如果您以前从未接触过硬件,我建议您先购买一块Arduino UNO板,亲自动手进行一些基本的硬件黑客和编程,然后再开始本教程。这里有几个快速链接可能有助于您加速物联网学习。
2. Arduino 硬件平台的完整初学者指南(DIY 适用)
第2章:英特尔爱迪生入门
在本章中,我们将学习如何设置设备、烧录操作系统镜像、将设备连接到互联网、分配 IP 地址以及一些解决爱迪生 WiFi 问题的方法。本章专门针对那些刚拿到爱迪生开发板的用户。那些已经设置好开发板的用户可以直接跳转到第 3 章。
2.1 设置您的开发环境
本项目是一个多编程语言、多架构、多硬件、多协议栈的项目,因此需要多种工具和技术。建议您获取所有必要的工具并安装它们,以启动本项目的制作。
硬件
- 带有 Arduino 扩展板的英特尔爱迪生。(亚马逊链接)
- 英特尔爱迪生电源适配器(我将在适当的时候揭示其重要性)
- 一个兼容 UVC 的 USB 网络摄像头(带麦克风的摄像头将是理想选择)[UVC 兼容摄像头供应商列表]
- 一个蓝牙麦克风(本教程中我们不使用它。所以如果你已经有一个摄像头和蓝牙麦克风,那没关系。我只是分享一些配置蓝牙麦克风的链接。但是,请注意单独的麦克风和摄像头会有性能问题)
- 英特尔爱迪生 Grove 套件(亚马逊链接)
- 一个 Grove 兼容的舵机(如果您的 Grove 套件不包含的话)。
- 爱迪生 USB 驱动
- 7-zip 用于解压 Yocto 镜像
- PuTTY 通过 SSH 或串口连接到开发板
- WinScp 或FileZilla,用于方便地在爱迪生开发板之间传输文件
- Visual Studio 2015 Community 版。(我使用 VS2012)。用于开发我们的 C# 客户端。
- 英特尔爱迪生 Yocto 构建镜像
- 英特尔 XDK 物联网版
- Bonjour 来自苹果,用于自动发现物联网设备
- 手机上的MyMqTT应用程序
您还需要设置许多其他工具,但目前阶段并非必需。您正在开始使用英特尔爱迪生和物联网,因此至少需要这些工具。但最重要的是,您需要一个良好的互联网连接(毕竟是万物互联)。
2.2 加载操作系统——将Linux Yocto镜像烧录到爱迪生
有大量的教程(这里有一个英特尔官方教程 -> 将固件烧录到您的英特尔爱迪生开发板 - Windows)介绍了爱迪生的入门指南。因此我本可以轻松跳过这一部分。然而,为了保持本文的连贯性并涵盖使用爱迪生开发物联网产品的完整端到端过程,我将在本文中介绍固件烧录部分。
如果您刚拿到全新的爱迪生开发板,可以按照图 2.1 中的步骤进行拆箱并准备您的爱迪生开发板。

在开始烧录之前,您必须为开发板通电。 请参见图 2.2,了解爱迪生开发板上每个端口和开关的功能。

如上图所示,第一个 micro USB 端口(电源选择开关之后那个)用于烧录固件到爱迪生,也用于通过 USB 为开发板供电。因此,对于烧录,只需将一根 USB 线连接到此端口即可进行烧录。连接方式如图 2.3 所示。

我们将使用一个名为 dfu-util(设备固件升级工具)的实用程序。请访问官方 dfu-util(http://dfu-util.sourceforge.net/)Source forge 页面,然后从发布文件夹下载 Windows exe(http://dfu-util.sourceforge.net/releases/dfu-util-0.8-binaries/win32-mingw32)。
此工具又依赖于另一个工具 libusb,可以从 df-utils 的同一个 Source forge 发布目录下载(http://dfu-util.sourceforge.net/releases/dfu-util-0.8-binaries/win32-mingw32/libusb-1.0.dll)。
下载 Yocto zip 文件后(文件名通常为 iot-devkit-prof-dev-image-Edison-20160xxx.zip),右键单击 -> 7-zip -> 提取文件,选择一个文件夹进行提取。
这里有一个显而易见的问题:为什么我们需要单独的 zip/unzip 软件包,而不能使用 WinRar 甚至 Windows 内置的解压工具呢?原因是 Linux 发行版中有些文件嵌套非常深,其绝对路径非常长。Windows 的解压工具无法处理如此长的文件路径。因此我们需要 7-Zip。如果您不使用 7-Zip,您的安装很可能无法成功完成。一旦文件夹解压完毕,将 df-utils.exe 和 lib-usb.dll 复制到这个解压后的文件夹中。
您的文件夹应该类似于下图 2.4。

图 2.4 解压后的 Yocto 目录视图,包含 df-util 和 libusb
您需要做的就是插入两根线缆,确保爱迪生开发板的电源开关拨向 USB(别担心,我们将在另一个部分讨论开发板供电问题)。您可以查看下图以确认连接是否正确。
找到并双击 FlashAll.bat,它应该会提示您重启,如下所示。

您可以通过按下开发板上的重置按钮(参见图 2.2)来重启爱迪生。
如果一切顺利,安装将完成,flashall 命令窗口将关闭。
现在是时候连接第二个 micro USB 的串口了,如果你在烧录时没有连接的话。将你的串口连接到最后一个 micro usb 端口(图 2.2)。
现在,当您右键单击“我的电脑”(或 Windows 7 中的“我的计算机”)并选择“属性”->“设备管理器”时,在“LPT 端口”下您将看到一个新条目,如图 2.6 所示。

因此,现在您的爱迪生开发板已通过串口连接到电脑。是时候测试开发板是否启动了。
打开 PuTTY。选择“Serial”单选按钮而非默认的“SSH”,并确保将波特率设置为 115200。爱迪生开发板不支持 9600 或 19200 的波特率,如果您之前使用过 Arduino,可能已经习惯了这些波特率。 输入您的串口号并点击“Open”。

图 2.7:使用 PuTTY 通过 USB 串口连接到爱迪生开发板
您将看到您的爱迪生开发板正在启动,如下图 2.8 所示。

启动后,爱迪生会提示您输入用户名,即 root。密码尚未配置。因此,一旦您输入 root,您将看到 root@edison# 提示符,如下图 2.9 所示。从现在开始,我们将此提示符称为爱迪生 shell。

瞧。您刚刚完成了第一步——即设置您的开发板。为自己欢呼吧,您做得非常棒。休息一下。当您回来时,我们将开始下一个重要的步骤,即配置开发板。
2.3 配置英特尔爱迪生
在真正开始使用爱迪生进行编码之前,还有几件事要做。首先要注意的是,爱迪生是一款物联网设备。物联网设备需要通过许多安全和非安全的网关在本地和全球范围内交换消息。因此,为开发板设置一个唯一的名称和密码是使一切正常运行非常重要的一步。这非常简单。您可以使用爱迪生 shell 中的单个命令来配置和设置开发板。
configure_Edison --setup
首先,它会提示您输入密码,如图 2.10 所示

接下来,它会提示您为设备输入一个唯一的名称。如果您在网络中连接了许多爱迪生设备(这是许多家庭自动化和工业应用的基本要求),那么 DNS 需要一种方法来解析设备的 IP 地址。建议您为设备指定一个唯一的名称,以避免 DNS-IP 冲突或 DNS 解析错误。下图显示了设备名称设置。

设备名称设置完成后,它会提示您输入密码。输入密码。如果您在生产环境中,建议创建一个强密码。
现在它会询问您是否要设置 WiFi。只需键入 y 并回车。
它会向您显示WiFi网络列表,您必须选择要连接的网络,当它要求确认时,输入y,然后输入您的WiFi密码。

如果一切顺利,您将看到一个动态 IP 地址分配给您的设备。这当然是与您的本地网络对应的本地 IP 地址。
现在通过 ping google.com 测试您的互联网连接。如果您看到 ping 中数据包交换成功,则表示您的互联网已连接,您几乎可以开始使用您的开发板了。
(使用 ctrl+c)停止 ping。

这是您使用英特尔爱迪生开始物联网所需的最优设置。在本教程中,我们需要设置其他几项,如网络摄像头、音频、蓝牙等。我们将在本阶段跳过这些设置,并在使用它们之前适当涵盖它们。
顺便说一句,如果您已经达到了这一点,那么您到目前为止做得非常棒。
注意(对初学者很重要)
当您第二次通过 PuTTY 的串口登录时,点击“打开”按钮后,您会看到一个空白控制台。 别担心,只需按回车键,您就会进入登录 shell。
2.4 远程登录
设置好设备后,我们首先需要做的就是测试是否能够远程登录到我们的爱迪生开发板。在大多数情况下,我们将把物联网应用部署为独立实体设备。这应该不需要任何笔记本电脑连接进行编码和调试。 我们将在这里探讨两种不同的技术:第一种是 SSH,它是迄今为止开发出的最重要的工具之一(特别是对于物联网),第二种是通过 WinScp 进行远程文件传输。文件传输对于备份代码、从设备中提取传感器日志、存储配置文件非常重要。
2.4.1 通过 SSH 使用爱迪生
安全外壳(Secure Shell)或通常称为SSH,让您即使设备未连接到笔记本电脑也能登录设备。SSH 还让您可以从任何操作系统使用爱迪生。一旦爱迪生配置了 IP 地址并连接到您的本地网络,您就可以使用以下命令从 Unix shell 或 Mac 通过 SSH 连接到设备。它会提示您输入密码。输入爱迪生密码。您将登录到爱迪生并可以操作设备。
ssh root@<Edison_ip_address>
由于我的重点是 Windows 环境,我将使用 PuTTY 进行远程登录(您也可以在 Linux 或 Mac 上使用 PuTTY)。

如果您使用的是 PuTTY,在选择默认 SSH 单选按钮后,在 IP 地址文本框中输入 Edison_ip_address,如上图 2.14 所示,然后点击打开。
由于 SSH 建立安全通信,PuTTY 会与您的开发板交换证书。因此,当您第一次使用 PuTTY 通过 SSH 连接到特定设备时,它会显示一个包含交换证书的安全警告。只需接受即可。它会提示您输入 root 用户。

请注意,SSH 不需要串行通信。因此,您可以拔掉最后一根 micro USB 线缆(串行端口线缆,如图 2.2所示),然后测试 SSH 命令。
爱迪生的一大优点是它支持多会话。 因此,您可以同时从不同的 PC 通过 SSH 登录到同一块开发板。您也可以在同一台 PC 上使用两个 PuTTY 窗口:一个用于 SSH,另一个用于串口。
下图 2.16 展示了我如何通过两种不同的会话登录到我的爱迪生设备,一种使用串口,另一种使用 SSH。

所以,如果你是团队负责人或高级人员,并且你的一个队友在代码上卡住了,你总是可以通过 SSH 登录他的机器并访问他当前代码的副本 :)。多个开发者也可以同时在不同的项目上使用爱迪生(!未经测试)
2.4.2 文件传输
在使用物联网设备时,很多时候您需要交换文件,例如:下载日志文件、上传配置文件等。因此,建议在此阶段设置一个文件传输工具。尽管这对于当前项目来说并非必不可少,但在处理音频和视频时您可能需要它。
文件传输工具有很多。FileZilla 是一个非常流行的工具。如果您使用 FileZilla,可以通过 SFTP 登录到您的开发板,如图 2.17 所示。

别忘了将默认端口 80 更改为 22。一旦登录到设备,您将在右侧看到您的爱迪生根文件夹,左侧是您的工作目录,如图 2.18 所示。

您可以通过将文件从电脑本地目录拖放到爱迪生来传输文件。WinScp 只支持 SFTP,因此对初学者来说稍微简单一些。下图 2.19 显示了 WinScp 的截图。

我个人更喜欢使用 WinScp,但您可以使用任何您觉得方便的工具。您可以将一些文件传输到爱迪生,在 shell 中使用 ls 命令查看传输是否成功。这本来应该是第 2 章的结尾,但我想涵盖另一个重要主题,它作为解决 WiFi 问题的一种技巧。您在这里不必遵循此子主题,但浏览一下此主题将让您了解爱迪生 WiFi 可能面临的问题类型以及如何解决这些问题。
2.5 解决 WiFi 问题
很多时候,如果您的 WiFi 不可靠或信号强度弱,爱迪生将无法正确连接。因此,即使设备已分配 IP 地址,设备也会拒绝通过 SSH 连接。如果您遇到此类连接问题,请通过串行模式登录,然后测试 ping google.com。如果您看到设备无法 ping 通 Google(它会发出命令响应“bad address google not found”),则需要再次手动重新配置爱迪生(如果您的 WiFi 正常工作)。第一步,您可以从串行 PuTTY 生成 reboot 命令,登录后再次测试 ping。如果设备仍然无法连接,请在 shell 中生成
configure_Edison --WiFi
请再次按照WiFi 设置步骤操作,然后您应该能够再次通过爱迪生访问设备。
重新配置WiFi的问题之一是,爱迪生将WiFi配置存储在文件/etc/wpa_supplicant/wpa_supplicant.conf中。
每次您重新配置时,您的设置都会添加到此文件中(即使您输入相同的网络和密码)。如果文件变得太大,或者内部写入操作损坏,那么在 configure_Edison --WiFi 之后您将看到错误,可能是未显示 SSID,或连接 global_iframe 失败,如图 2.20 所示。

如果您遇到上述任何错误,请不要担心。这里有一个解决问题的方法。
- 删除配置文件。
-
rm /etc/wpa_supplicant/wpa_supplicant.conf
- 使用 vi 命令创建一个新的配置文件
-
vi /etc/wpa_supplicant/wpa_supplicant.conf
- 复制并右键单击 vi 编辑器以粘贴以下配置模板的内容
-
ctrl_interface=/var/run/wpa_supplicant ctrl_interface_group=0 update_config=1 fast_reauth=1 device_name=Edison manufacturer=Intel model_name=Edison network={ ssid="YOURSSID" scan_ssid=1 key_mgmt=NONE auth_alg=OPEN wep_key0=f0039faded348299992344be23 } - ESC :wq 保存并退出 vi 编辑器。
- 重启
现在再次进入Wifi setup阶段,您应该没问题了 :)。请注意,重新配置后,您的 IP 地址可能会更改。请检查并记下 IP 地址。
注意:如果您无法通过右键单击粘贴到 vi 编辑器中,请单击 shell 顶部以调出“更改设置”,并确保按照下图设置了属性。
好的,这标志着第二章的结束。以下是我们第二章中学到的内容总结:
章节总结:我们学到了什么
- 拆箱爱迪生
- 将 Yocto 镜像烧录到爱迪生
- 从 PC 到爱迪生设置串口通信
- 通过 PuTTY 和 SSH 登录爱迪生开发板
- 使用 WinSCP 或 FileZilla 将文件传输到爱迪生
- 最后,解决爱迪生常见 WiFi 问题的变通方法。
3. 设置开发环境
在本章中,我们将学习如何设置开发环境,执行一些基本的 Node.js 程序,理解电源和硬件组件。
爱迪生支持多种编程语言。Python、Arduino C 和 Node.js 是其中的一些平台。我喜欢 Node.js,因为它语言简洁,有大量的库可用,并且爱迪生开箱即用支持它。因此,如果您按照第 2 章中介绍的步骤设置了开发板,则不需要任何其他配置。您可以开始编码了 :)
在本章中,我们的重点将是理解如何用 Node.js 编写简单的代码。最好您能遵循一些优秀的 Node.js 在线教程。
我特别建议初学者阅读这篇Tutorial Point Node.js 教程,它提供在线执行选项。因此,您可以在学习的同时尝试代码。
然而,在本教程的过程中,我们将涵盖 Node.js 与物联网相关的重点方面。
我们将使用英特尔 XDK 物联网版来编写、调试、运行和部署代码。但是,在切换到英特尔 XDK 之前,我们将在 vi 编辑器中执行我们的第一个简单 Node.js 程序,以检查一切是否设置完美。
一旦我们完成了第一个程序(将打开板载 LED)的测试,我们将讨论以不同方式为爱迪生供电。然后我们将学习如何将不同的硬件组件与爱迪生一起使用。这是本章的议程
- 通过 vi 编辑器的 Node.js 代码使板载 LED 亮起
- 了解英特尔爱迪生的供电选项
- 英特尔 XDK 入门
- Grove 扩展板连接
- 准备英特尔 XDK 物联网版进行编码和调试
准备好了吗?让我们开始“制作”吧
3.1 板载 LED 开关
爱迪生开箱即用支持 Node.js。因此,您可以直接通过 vi 编辑器开始编码。在您的 PuTTY 爱迪生 Shell 中输入 first.vi。按下 insert 或 'i' 键,然后输入以下列表。
var mraa=require('mraa')
var ledPin=new mraa.Gpio(13);
ledPin.dir(mraa.DIR_OUT);
ledPin.write(1);
按 escape,然后 :wq,回车保存并退出。
要执行脚本,请键入
node first.js
看你的板子。板载 LED,连接到引脚 13,现在将亮起,如下图 3.1 所示。

太棒了!您正在路上。现在,通过更改程序关闭这个 LED !!!
好的,回到这个程序的作用!
mraa 是 Libmraa 的 node.js 包装器,而 Libmraa 是用 C++ 编写的库,用于访问运行 Unix 的嵌入式和物联网设备的硬件端口。
英特尔爱迪生 Arduino 扩展板拥有与 Arduino 相同的数字和模拟引脚。如果您不了解执行器和传感器,建议您阅读本教程开头我分享的 Arduino 文章链接。
板载 LED 就像 Arduino 一样连接到引脚 13。这些引脚是双输入输出(DIP)类型。所以我们首先声明一个名为 mraa 的 mraa 库对象。现在我们通过将名为 ledPin 的变量声明为 mraa.Gpio() 类型的新实例来访问引脚 13。由于这些引脚可以用作输入或输出(但请记住在任何时刻只能作为一种类型),我们需要通过 mraa.DIR_OUT 或 mraa.DIR_IN 来指定引脚类型。由于我们想控制 LED,LED 需要是一个输出设备。因此我们选择方向为 DIR_OUT。最后使用 write 函数写入 1 或 0,分别导致灯泡开启和关闭。
由于 JavaScript 是一种脚本语言,我们不需要为程序定义入口点。程序从第一条指令开始执行。
然而,您可以观察到一件事,当您执行程序的那一刻,LED 会亮起,然后您的 shell 提示符会返回。这意味着程序已执行完毕。根据定义,微控制器或嵌入式微处理器应该在一个无限循环中运行,一遍又一遍地重复相同的指令集,并带有时间延迟(回忆 Arduino 的 void loop() 函数)。因此,为了让我们的程序也做同样的事情,我们将为 node.js 创建我们自己的 loop() 函数,并将我们基本的 LED 开关程序扩展为 LED 闪烁,这被认为是嵌入式系统和物联网的“Hello World”。
3.2 LED 闪烁,物联网的“Hello World”
在 node.js 中,我们可以使用 setTimeout() 函数在预定义的时间段后异步调用一个函数。以下是一个 loop() 的通用结构,它每 1000 毫秒调用自身一次。
function loop()
{
//your code goes here
setTimeout(loop,1000); // recurssion in every 1000ms
}
您可以在此函数中编写您的主要逻辑,然后从脚本中简单地调用此函数。下面是 blink.js 代码,通过修改 first.js 和上述循环模板开发而来。
//listing blink.js
var mraa=require('mraa')
var ledPin=new mraa.Gpio(13);
ledPin.dir(mraa.DIR_OUT);
var ledState=0;
loop();
function loop()
{
if(ledState==1)
{
ledState=0;
}
else
{
ledState=1;
}
ledPin.write(ledState);
setTimeout(loop,1000);
//ledPin.write(1);
}
我们简单地引入了一个名为 ledState 的变量,并在每次调用循环时反转其值。一个显而易见的问题可能是为什么不使用布尔变量呢?因为,write() 期望其参数为整数类型。所以我们使用数字。执行此代码,您将看到板载 LED 每 1 秒闪烁一次。
你能修改这个程序,让LED亮5秒,灭1秒吗?自己试试看。
如果你的 LED 正在闪烁,你现在就可以开始使用硬件了。我们将从 Grove shield 开始。但是,在我们使用 Grove shield 之前,我将介绍另一个子主题,即开发板的供电。在阅读过程中,你将了解到理解电源和可用于爱迪生的不同电源选项及其用例的重要性。
3.3 为爱迪生板供电
你可能会想到的一个显而易见的问题是“为什么在这里才介绍这个话题?它应该在开头就出现。毕竟,供电是最基本的事情之一”。
嗯,一旦我们有了新玩具,我们想先玩它。我们想打开它,了解它的基本功能。然后我们才开始探索它的特性。当您开始使用物联网组件时,LED 闪烁是最重要的信心助推器之一。所以,我涵盖了基本知识,帮助您达到这个阶段,并稍微理解硬件和程序结构。一旦您达到这个阶段,您就拥有了一个可以进行实验的现成工作板。
图 3.2 所示表格展示了不同的供电选项、如何连接到爱迪生、它们的额定值和使用案例。

通常我所有的非摄像头英特尔爱迪生项目都使用移动电源,因为其移动性、良好的电流额定值和易用性。我建议您不要使用 USB 为爱迪生供电,因为它电流输出非常差。所以,如果您使用笔记本电脑为爱迪生供电,当同时使用多个组件时,请准备好频繁重启和崩溃。此外,摄像头也无法在 USB 供电的开发板上工作。
对于使用 12v 电机、继电器和摄像头的机器人项目,建议使用 12v 电池。这里需要注意的重要事项是,许多此类电池具有高电流额定值,如 5A 或 7A。请务必检查额定值,并选择最大电流为 1.2A 至 1.5A 的电池。
上述表格将作为您的爱迪生参考清单,并帮助您根据需求选择电源。
在您开始使用爱迪生进行严肃的物联网工作之前,还有一个设置。
3.4 在爱迪生上使用 Grove 套件
“时间就是金钱。”
在进行原型设计时,您希望您的模型尽快准备好以进行概念验证。想象一下如果复制粘贴从未被发明?我们中有多少人仍然会是一名高效的程序员?代码复用使得软件原型设计极其快速和高效。 但硬件却并非总是如此。您需要连接线路,测试电压,电源,进行各种连接,然后发现有些东西不工作。您重新打开连接。面包板是临时连接的选择之一,但说实话,您永远无法在面包板上构建原型并将其呈现在投资者面前。它们看起来不整洁,而且连接线总有松动的可能性。 尽管 Arduino 通过提供硬件原型设计最基本的需求,使得连接相对简单,但您仍然需要连接外部组件。
由 Seeed Studio 出品的 Grove 套件是让硬件原型设计变得简单的一大飞跃。它让您能够快速制作出优秀的原型,而无需过多担心连接问题。
那么,让我们从 Grove 套件开始吧。
我们打开 Grove 套件包装。您可以看到槽位中放置了几个组件。我更喜欢用标记笔标记它们,以便在完成某些实验后能将组件放回原位。这就是 Grove 套件的样子。

我建议您标记插槽,以便您始终能跟踪您的组件。当您打开并取出 LCD 后,您会在其下方找到底座扩展板,如图 3.4 所示。
现在取出图 3.4 (a) 所示的 Grove 底座扩展板,并将其安装在爱迪生开发板顶部,如图 3.4 (b) 所示。确保底座扩展板正确地插入槽中。

3.5 连接硬件组件到基座扩展板
图 3.5 解释了如何将 Grove 组件连接到基座扩展板。逻辑非常简单。将传感器连接到模拟端口,数字开关或输出(如继电器和 LED)连接到数字端口。如果要使用 PWM 进行速度控制或强度控制,请使用 D5 或 D6,它们是 PWM 端口。LCD 或加速度计必须连接到 I2C 端口。

但是,连接线在哪里呢?拿起你装有组件的白色槽盒,你会看到连接线。只需取出线缆,一端连接到组件,另一端连接到基座扩展板端口,按照图 3.5中的表格进行连接。
对于那些仍然找不到连接线并感到困惑的人,请参考图 3.6

线缆只能以一种方式连接,所以您不必担心接错。但如果您真的想知道“无困惑连接”的诀窍?
黑线连接到端口的“GND”标记侧。 (见上图)
在上图中,我将蜂鸣器连接到D4。如果你也连接相同的,你可以通过在blinking.js中将引脚号从13改为4来轻松测试它。
如果你回顾一下我在这篇教程开头提到的Arduino 教程,并将我在搭建每个电路时所付出的努力与你所构建的电路进行比较,你就会意识到 Seed 的 Grove 套件所带来的革命性变化!
好的,现在您已经烧录了 Yocto,配置了 Wifi,测试了 LED 闪烁,连接了 Grove 套件并进行了测试。现在是时候开始使用开发板进行严肃的编码和原型设计了。
3.6 英特尔 XDK 入门
您已经在 vi 编辑器中开发了一个简单的程序。所以,一个显而易见的问题可能是“为什么我们需要另一个软件?”。嗯,vi 编辑器非常适合入门,但对于大型实时项目来说并不理想,因为它没有代码搜索、模块维护、智能感知以及其他干净编码所需的最低要求。
另一个可能出现在你脑海中的问题是,为什么我们不早点设置它?因为英特尔爱迪生需要 WiFi 才能连接到你的设备。一旦 WiFi 设置完成,你肯定想测试你的开发板是否正常工作。对吧?
一旦你完成了上述所有步骤,你已经是一名自信的物联网初学者了。所以让我们完成从初级到中级的旅程。
在启动英特尔 XDK 之前,请确保您已安装Bonjour,如软件要求部分所述。XDK 使用它来发现您的爱迪生。
当您首次运行 XDK 时,它会要求您注册一个英特尔账户。注册后,请使用您的账户登录。
在底部点击文本为“-select a device-”的组合框。如果您的设备在网络中正常运行,XDK 将自动检测到该设备并将其显示在列表中,如图 3.7 所示。

如果您是第一次连接设备,它会提示您输入默认用户 root 的密码。输入密码后,您将收到“您的设备已连接”的提示。
点击顶部项目选项卡,然后选择底部的“创建新项目”,如图 3.8 所示。

现在选择物联网 Node.js 项目。XDK 预装了大量的现成项目,供您快速学习物联网编码。但是,我并不是这些模板的忠实粉丝。所以,我更喜欢为您提供一个全新的空白项目,让您从最基础的开始,然后在其上不断添加您的设备和代码。
因此,选择空白模板,如图 3.9 所示
![]()
给项目命名(如果希望新项目位于不同于默认的目录,请更改项目位置)。
项目创建后,您就可以开始将 Node.js 代码写入默认的 main.js 文件中。XDK 会为您提供提示,在您编辑代码时进行编译,高亮显示语法,并支持更多功能!

在 vi 编辑器中运行了您的前两个基本程序后,您会立刻爱上英特尔 XDK。我保证!
编写您的代码,然后使用上传和运行按钮将代码上传到您的开发板并运行代码,如图 3.11 所示。

图 3.11:在 XDK 中上传并运行 Node.js 代码
XDK 是爱迪生的一款完整工具。您可以通过编辑器底部的选项卡,使用串口和 SSH 两种方式登录您的设备并使用命令,就像您在 PuTTy 中操作一样。
在 XDK 中尝试您的前两个程序(first.js 和 blinking.js)。再也不想回到 vi 了 :D
试试看
- 尝试通过 XDK 的 SSH 登录爱迪生并执行 ls 命令
- 拿一个 LED 和一个蜂鸣器,连接到两个不同的端口,尝试让它们交替闪烁,即 LED 亮 <=> 蜂鸣器灭
至此,本章结束。让我们回顾一下本章学到的内容
章节总结
- 如何编写简单的 Node.js 程序
- 板载 LED 的开关和闪烁
- 如何为我们的爱迪生开发板供电
- 如何在爱迪生上使用 Grove 套件
- 如何使用英特尔 XDK 编写更高效的代码
下一章将致力于让您成为一名更好的物联网程序员。我们将连接不同的组件并实现一些重要的逻辑。我们将理解硬件-Node.js-互联网-Node.js-硬件的工作流程。
干杯!!!恭喜您成功完成本章并设置好开发环境。
4. 使用 Node.js 和 Grove 组件的嵌入式和物联网工作流程
在本章中,我们将通过 Node.js 实现一些简单的用例项目。我们将学习如何使用 npm 安装外部库,如何设计嵌入式工作流程,如何规划电路和编码,以及如何通过物联网特定协议(远程控制)进行通信。 我们将利用在此处获得的知识来创建最终原型。这里的简单小型项目是我们的最终项目(实际上是许多物联网项目)的基本构建块。
这将非常有趣。让我们开始吧。
4.1 小项目 1:根据按钮按下状态开关 LED
您需要将一个按钮和一个 LED 连接到 Grove 扩展板上。当您按下按钮时,LED 应该亮起,并保持亮起状态,直到您再次按下按钮。当您再次按下按钮时,LED 应该关闭。
我们先来搭建电路。
按钮本质上是一个开关(一种传感器)。那么我们应该把它连接到哪个端口呢?是模拟端口还是数字端口?嗯,从技术上讲,你可以把按钮连接到模拟或数字端口。但是按钮只有两种状态:开和关。我们使用模拟端口连接那些值会变化的传感器。所以,这里我们将按钮连接到数字端口。LED 就像我们知道的那样连接到数字端口。
你能按照图 4.1 中给出的表格搭建电路吗?(我非常自信你能做到)。

您上次指定电子电路为表格是什么时候????
这就是 Grove 和爱迪生让你的开发变得如此简单。我还想澄清一下为什么我特意选择 D5 连接 LED!在稍后阶段,我想根据光线强度来控制 LED 的亮度。回忆一下第 2 章,强度或速度控制是通过 PWM 实现的,而引脚 D5 和 D6 是 Grove 中仅有的 PWM 端口(参见图 3.5)。
尽管我非常自信您已正确连接组件,但我仍为您提供电路快照,以防您想验证!

现在让我们看看编码。您能尝试为上述逻辑编写代码吗?
我敢肯定你写出了这样的东西
//listing: wrongLedSwitch.js
var mraa=require('mraa')
var ledPin=new mraa.Gpio(5);
ledPin.dir(mraa.DIR_OUT);
var buttonPin=new mraa.Gpio(4);
buttonPin.dir(mraa.DIR_IN);
loop();
function loop()
{
ledPin.write(buttonPin.read());
setTimeout(loop,1000);
}
就像 read() 是一个返回输入端口值的方法一样。由于我们考虑的是 Gpio,它是一个数字端口,所以值要么是 1 要么是 0。因此,您正在尝试根据按钮的状态来控制 LED 的状态。
问题出在哪里?您肯定已经注意到,当您按下按钮时,LED 会亮起,但当您松开按钮时,它也会熄灭。但我们不希望这样,对吧?一旦松开,它应该保持亮着,直到我们再次按下按钮。然后 LED 应该熄灭。
因此,从逻辑上讲,当按钮状态为 1 且 LED 状态为 0 时,LED 状态变为 1。当按钮状态为 1 且 LED 状态为 1 时,LED 状态应变为 0。注意,我们需要一个状态变量来适当地实现该逻辑。
此外,您可能已经观察到按下按钮后状态变化存在延迟。这是由于循环中的高延迟造成的。100ms 是循环的标准延迟。因此,您需要将延迟更改为 100ms。与此同时,您还需要引入一个状态变量。
所以我们修改代码如下
如您所见,我们不是处理按钮的状态,而是处理转换。每当按钮状态从 0 变为 1 时,我们都会触发操作。
任何导致输出端口状态改变的事件都称为触发器。 在许多物联网生态系统中,您会听到“触发器”这个词。触发器可以是硬件触发器,如本例所示,也可以是逻辑触发器,如(高温值或低光强度)。物联网中的触发器可以在本地或云端实现。
// --> copy this code in main.js in your project
var mraa=require('mraa')
var ledPin=new mraa.Gpio(5);
ledPin.dir(mraa.DIR_OUT);
var buttonPin=new mraa.Gpio(4);
buttonPin.dir(mraa.DIR_IN);
var ledState=0;
var btnState=0;
loop();
function loop()
{
var b=buttonPin.read();
if(b==1 && ledState==0 && btnState==0)
{
ledState=1;
ledPin.write(1);
btnState=1;
}
else if(b==1 && ledState==1 && btnState==0)
{
ledPin.write(0);
btnState=1;
ledState=0;
}
if(b==0)
{
btnState=0;
}
setTimeout(loop,100);
}
现在您可以看到,每当我们按下按钮,LED 就会亮起,并保持亮起,直到我们再次按下按钮,如动画图 4.3 所示。

完成了第一个迷你项目后,让我们学习一些物联网知识。在下一个迷你项目中,我们将结合此处使用的开关,实现相同 LED 的远程控制。
4.2 小项目 2:使用 MqTT 进行远程控制
4.2.1 MqTT

MqTT(图 4.4)是一种简单的发布-订阅协议,在我看来,它是物联网领域发生过的最好的事情之一。
一个全球性的 MqTT 代理允许客户端程序在服务器中创建一个主题(类似于队列)。客户端程序可以在任何设备上运行,包括但不限于手机、平板电脑、笔记本电脑、PC,当然还有物联网设备。我们称运行 MqTT 客户端的实体为节点(与 node.js 节点无关)。各种编程语言和堆栈中都有大量的 MqTT 开源客户端库。
因此,一个节点可以将二进制数据(称为消息)发布到任何主题中。主题可以分层嵌套。例如,我们可以创建一个主题为 rupam,然后是 rupam/home,然后是 rupam/home/sensors 和 rupam/home/control,然后是 rupam/home/control/locks 和 rupam/home/control/devices。
订阅“rupam”的节点将收到在“rupam”、“rupam/home”或“rupam/home/devices”等主题中发布的所有消息。
许多节点可以订阅一个或多个主题。每当一个节点在任何主题中发布数据时,所有订阅了该特定主题的节点都将异步地从代理接收消息。
此外,消息可以分为两种类型:持久性消息和非持久性消息。持久性消息即使在推送到订阅节点后也会被代理保留,而非持久性消息将被清除。
因此,一个想要使用 MqTT 服务的程序需要连接到代理,订阅主题,并向主题发布消息。
在我们当前的工作背景下,我们只需从 Android 手机发布消息,并在英特尔爱迪生上编写一个 Node.js 程序来订阅该主题。每当通过代理收到消息时,就进行分析并做出决策。
重要资源
这里有两个免费的代理供您订阅,免费享受基于物联网的消息传递!!!!!
- iot.eclipse.org
- test.mosquitto.org
4.2.2 在英特尔爱迪生中使用 MqTT
MqTT 未包含在核心 Node.js 软件包中。因此,爱迪生开箱即不支持它。然而,好消息是,就像其他 Node.js 环境一样,在爱迪生中安装新的 Node.js 软件包也简单易行。

图 4.5:使用 npm 在爱迪生中安装外部 Node.js 软件包
只需使用 XDK 的 SSH 选项卡登录爱迪生。在 shell 中输入
npm install mqtt
就是这样。软件包将被安装。现在您可以玩转 MqTT 了。因此,从我们的代码中,我们需要连接到一个代理(我们这里将使用 iot.eclipse.org),订阅一个主题(比如说 rupam/control),在消息到达事件处理程序中,分析消息。如果消息是 ON,打开 LED;如果 OFF,关闭 LED。我们还希望保留我们基于开关的控制。所以我们将修改上一节的ledSwitching.js列表并添加 MqTT 功能。
这是 MqTT 部分
//////// MqTT Integration/////////
var mqtt = require('mqtt');
var client = mqtt.connect('mqtt://iot.eclipse.org');
client.subscribe('rupam/control/#')
client.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString()
console.log(payload);
payload = payload.replace(/(\r\n|\n|\r)/gm,"");
if(payload=='ON')
{
ledState=1;
ledPin.write(1);
}
if(payload=='OFF')
{
ledState=0;
ledPin.write(0);
}
cb();
}
/////////////////////////////////
我们创建一个名为 mqtt 的 mqtt 客户端,连接到代理并订阅一个名为 rupam/control 的通道。在 handleMessage() 事件处理程序中,我们将消息转换为字符串,删除多余的空白字符并检查消息文本。我们根据消息实现切换决策。
请注意,我们创建了一个名为 cb() 的函数,它代表回调,更重要的是,我们再次从 handle message 中调用了 cb()。这是一个非常重要的语句。如果您忘记从 handleMessage() 中再次调用 cb(),那么您将只收到一条消息 :) 剩下的消息将不会触发 handleMessage() 函数,因为客户端已经从中退出了。通过再次调用回调,我们确保客户端在处理完第一条消息后自动再次进入监听模式。
重要的是,不要在您的循环中实现这段代码。 因为,如果您这样做,它会为每个循环实例创建客户端实例,从而销毁前一个实例。因此,您将永远收不到消息,因为甚至在消息到达之前,监听客户端就已经被重新初始化了。
将其放回我们的 ledSwitching.js 中,这是最终代码
var mraa=require('mraa')
var ledPin=new mraa.Gpio(5);
ledPin.dir(mraa.DIR_OUT);
var buttonPin=new mraa.Gpio(4);
buttonPin.dir(mraa.DIR_IN);
var ledState=0;
var btnState=0;
//////// MqTT Integration/////////
var mqtt = require('mqtt');
var client = mqtt.connect('mqtt://iot.eclipse.org');
client.subscribe('rupam/control/#')
client.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString()
console.log(payload);
payload = payload.replace(/(\r\n|\n|\r)/gm,"");
if(payload=='ON')
{
ledState=1;
ledPin.write(1);
}
if(payload=='OFF')
{
ledState=0;
ledPin.write(0);
}
cb();
}
/////////////////////////////////
loop();
function loop()
{
var b=buttonPin.read();
if(b==1 && ledState==0 && btnState==0)
{
ledState=1;
ledPin.write(1);
btnState=1;
}
else if(b==1 && ledState==1 && btnState==0)
{
ledPin.write(0);
btnState=1;
ledState=0;
}
if(b==0)
{
btnState=0;
}
setTimeout(loop,100);
}
我们希望通过手机发送 ON 和 OFF 消息来控制 LED。同样,您可以使用Eclipse Paho 库实现一个简单的 MqTT Android 客户端。
但是,我们并不是真的专注于 Android。因此,与其纯粹为了测试而编写一个 App,不如使用 Google Play 中现有的 MqTT 客户端 App!
我特别喜欢并使用MyMqtt 应用程序进行测试。
打开 App,进入设置,连接到 iot.eclipse.org,保留其他默认设置。现在进入发布部分,在主题中写入 rupam.control [ 重要:发布时不要加 # ]。 现在发送 ON 或 OFF,即可看到您的 LED 亮起和熄灭。
结果见图 4.6

哇!您刚刚在爱迪生上完成了您的第一个“真正的物联网”程序,并远程控制了一个 LED。为什么现在不尝试使用“LED ON”、“LED OFF”、“BUZZ ON”、“BUZZ OFF”等命令来控制 LED 和蜂鸣器呢?
您完全可以使用小写作为命令,但我更喜欢大写命令来区分它们与普通文本。
至此,我们的迷你项目2结束,我们学到了如何远程控制组件以及客户端之间的通信协议。
在我们的下一个迷你项目中,也是我们学习项目中的最后一个,我们将根据房间光线强度控制 LED 亮度,并在 LCD 上显示详细信息。因此,作为学习体验的一部分,我们将在下一个迷你项目中学习 PWM 和 LCD 这两个主要内容。
4.3 小项目 3:根据室内光线控制灯光强度
在这个小项目中,我们将连接一个 LCD 来显示房间光线强度,并根据房间光线改变 LED 的强度以及 LCD 的背景颜色。我们将保留之前部分开发的切换逻辑。因此,在这个小项目结束时,您将能够切换 LED,同时控制其强度。您还将学习 LCD。
您需要在这里添加两个额外的组件:LCD和光传感器。您可以根据图3.5来连接电路吗?
4.3.1 在英特尔爱迪生中使用 LCD
我们将把一个LCD连接到任何一个I2C端口(程序将自动检测端口)。我们首先进行一些基本的LCD编码。然后,我们将在4.3.2中实现PWM,然后在4.3.3中将它们组合成一个实体。

LCD的编码也相当简单。Grove提供的LCD实际上是一个RGB背光2x16 LCD。这意味着您可以在两行中打印消息,并更改LCD的背景颜色。
让我们创建一个简单的LCD“Hi Codeproject”程序
// lcd.js
//// LCD part///////////
var LCD = require('jsupm_i2clcd');
var myLCD = new LCD.Jhd1313m1(6, 0x3E, 0x62);
myLCD.setColor(255,0,0);
myLCD.setCursor(0,0)
myLCD.write('Hi Codeproject')
myLCD.setCursor(1,0)
myLCD.write('Intel Edison')
////////////////////////
jsupm_i2clcd 是一个开箱即用的 UPM i2c LCD 库,所以不需要重新安装。我不知道 Jhd1313m1(6, 0x3E, 0x62); 是什么,但它似乎是 LCD 初始化所必需的 :(
代码的其余部分很简单。首先使用 setColor(r,g,b) 函数设置背景颜色。使用 setCursor(row,col) 设置光标位置。首先我们在第0行(即第一行)打印“hi codeproject”,然后将光标设置到第二行(row=1)并打印“Intel Edison”。
结果如下所示

我们现在将连接一个光传感器(也称为LDR或光敏电阻)。请查看下一节了解LDR的工作原理。
4.3.2 使用 LDR
我必须在这个阶段说明,我们不会在我们的项目中使用LDR。所以,我曾经想跳过这个话题。然而,为了让您的学习曲线更完整,我还是添加了这一节。本节的目的纯粹是为了让您了解传感器的工作原理,与我们的项目无关。(所以,如果您只对我们的生物识别储物柜感兴趣,可以跳过这一节。对于初学者来说,这很重要)。但是,我们将在这里介绍一些LCD的最佳实践。所以,如果您跳过这一节,您将会错过一些东西!
由于LDR是一个传感器,我们将把它连接到四个可用模拟端口中的任何一个:A0-A3(请参阅图3.5)
让我们在这里将LDR与A0连接。您所要做的就是将ldrPin声明为new mraa.Aio(0)。在循环中,将传感器值读入一个变量并在LCD上显示。
我们将在循环内部使用 write()、setCursor(row,col) 和 setColor(r,g,b),并在顶部进行初始化。
让我们通过添加传感器处理和lcd.js来修改ledSwitchingMqtt.js
var mraa=require('mraa')
var ledPin=new mraa.Gpio(5);
ledPin.dir(mraa.DIR_OUT);
var buttonPin=new mraa.Gpio(4);
buttonPin.dir(mraa.DIR_IN);
var ledState=0;
var btnState=0;
// LDR Part//////////////
var ldrPin=new mraa.Aio(0);
// no need for initializing dir for Aio as Aio pins are only input type
//// LCD part///////////
var LCD = require('jsupm_i2clcd');
var myLCD = new LCD.Jhd1313m1(6, 0x3E, 0x62);
myLCD.setColor(255,0,0);
myLCD.setCursor(0,0)
myLCD.write('Hi Codeproject')
myLCD.setCursor(1,0)
//myLCD.write('Intel Edison')
// we will use second line to print light value
////////////////////////
//////// MqTT Integration/////////
var mqtt = require('mqtt');
var client = mqtt.connect('mqtt://iot.eclipse.org');
client.subscribe('rupam/control/#')
client.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString()
console.log(payload);
payload = payload.replace(/(\r\n|\n|\r)/gm,"");
if(payload=='ON')
{
ledState=1;
ledPin.write(1);
}
if(payload=='OFF')
{
ledState=0;
ledPin.write(0);
}
cb();
}
/////////////////////////////////
loop();
function loop()
{
var b=buttonPin.read();
// LDR part/////////
myLCD.setCursor(1,0);
var ldrVal=ldrPin.read();
// convert the value into percentage
var pc=ldrVal*100.0/1024.0;
pc=Math.floor(pc * 100) / 100;
myLCD.write('Light='+pc+' %')
/////////////////////
if(b==1 && ledState==0 && btnState==0)
{
ledState=1;
ledPin.write(1);
btnState=1;
}
else if(b==1 && ledState==1 && btnState==0)
{
ledPin.write(0);
btnState=1;
ledState=0;
}
if(b==0)
{
btnState=0;
}
setTimeout(loop,100);
}
让我们分析LDR部分
// LDR part/////////
myLCD.setCursor(1,0);
var ldrVal=ldrPin.read();
// convert the value into percentage
var pc=ldrVal*100.0/1024.0;
pc=Math.floor(pc * 100) / 100;
myLCD.write('Light='+pc+' %')
/////////////////////
Arduino 兼容设备中的模拟端口内部连接到 10 位 A2D 转换器。因此,模拟引脚上的 read() 函数返回传感器值的 10 位数字等效值。最大值为 1024。读取光强度后,我们将其转换为百分比。Math.floor() 用于将数字仅转换为两位小数。
尝试注释掉这一行来运行示例。
注意,我们每次在循环中都调用 myLCD.setCursor()。因为默认情况下,光标位置会放置在最后一个字符串的末尾。
尝试注释掉 setCursor() 调用来运行示例。
电路和显示屏如下图所示

所以,在本节中我们学习了
- 如何有效利用LCD每行16个字符来高效显示信息
- 如何使用传感器(特别是LDR)并在LCD上显示其值
在下一节中,我们将学习如何根据光照值控制LED亮度。
4.3.3 PWM - 根据LDR值控制光照强度
读者心中自然而然冒出的第一个问题是:“光照强度与储物柜有什么关系?”嗯,实际上没有直接关系。但是,我们将在项目中使用舵机来控制锁(稍后会介绍)。舵机控制基于PWM。尽管我们将使用一个库进行电机控制,它不会直接暴露PWM低级调用,但了解如何使用PWM始终是好的,这样您将来就可以根据原始PWM调用编写自己的舵机控制逻辑。
在当前教程的背景下,本节还有助于通过本地开关以及使用MqTT从远程执行开关和PWM控制。
一些PWM基础知识可以在我的Arduino基础教程的PWM部分中找到。所以,我们将跳过理论部分,只从该教程中提取一个简单的摘要。
脉冲宽度调制(PWM)是一种通过改变脉冲的占空比来控制负载(如电机/灯等)电流的方法。占空比为70%的PWM信号意味着连接到相关引脚的电机将以其最大速度的70%旋转。
这是代码
var mraa=require('mraa')
/*---------- Uncomment for Plain Switching *****/
//var ledPin=new mraa.Gpio(5);
//ledPin.dir(mraa.DIR_OUT);
/*---------- Uncomment for Plain Switching *****/
//---- PWM---------//
var ledPin=new mraa.Pwm(5);
ledPin.enable(true);
//---------------------//
var buttonPin=new mraa.Gpio(4);
buttonPin.dir(mraa.DIR_IN);
var ledState=0;
var btnState=0;
// LDR Part//////////////
var ldrPin=new mraa.Aio(0);
// no need for initializing dir for Aio as Aio pins are only input type
//// LCD part///////////
var LCD = require('jsupm_i2clcd');
var myLCD = new LCD.Jhd1313m1(6, 0x3E, 0x62);
myLCD.setColor(0,255,0);
myLCD.setCursor(0,0)
myLCD.write('Hi Codeproject')
myLCD.setCursor(1,0)
//myLCD.write('Intel Edison')
// we will use second line to print light value
////////////////////////
//////// MqTT Integration/////////
var mqtt = require('mqtt');
var client = mqtt.connect('mqtt://iot.eclipse.org');
client.subscribe('rupam/control/#')
client.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString()
console.log(payload);
payload = payload.replace(/(\r\n|\n|\r)/gm,"");
if(payload=='ON')
{
on();
}
if(payload=='OFF')
{
off();
}
cb();
}
/////////////////////////////////
loop();
var desiredLight=1;
function on()
{
ledState=1;
//------ Uncomment for plain switching///////
//ledPin.write(1);
//-------------------------------//
// PWM---------//
console.log(desiredLight);
ledPin.write(desiredLight);
/////////////////
/////////////////
}
function off()
{
ledState=0;
// For pwm only////////
ledPin.write(0);
}
var t=0;
function loop()
{
t++;
var b=buttonPin.read();
// LDR part/////////
myLCD.setCursor(1,0);
var ldrVal=ldrPin.read();
// convert the value into percentage
var pc=ldrVal*100.0/1024.0;
pc=Math.floor(pc * 100) / 100;
myLCD.write('Light='+pc+' %')
desiredLight=(100-pc)/300;
if(ledState==1)
{
// if light is on adjust intensity every 5 sec
if(t>=50)
{
ledPin.write(desiredLight);
t=0;
}
}
/////////////////////
if(b==1 && ledState==0 && btnState==0)
{
on();
btnState=1;
}
else if(b==1 && ledState==1 && btnState==0)
{
off();
btnState=1;
}
if(b==0)
{
btnState=0;
}
setTimeout(loop,100);
}
请注意,对于PWM,我们将 ledPin 声明为 mraa.pwm(5)。调用 enable(true) 将激活PWM模式。
//---- PWM---------// var ledPin=new mraa.Pwm(5); ledPin.enable(true); //---------------------//
另请注意,我们已将开关逻辑分离为 on() 和 off() 函数。write(0) 可关闭普通数字引脚和PWM模式下的逻辑。
有趣的是,在 on() 函数中,我们使用了 write(desiredLight) 而不是用于普通切换的 write(1)。
desiredLight 是一个全局变量,其值在 loop() 函数中计算光照百分比后立即改变。pwmPin.write(duty_cycle_in_decimal) 要求您以小数形式指定所需的占空比(例如:77% 占空比为 .77,63% 占空比为 .63,依此类推)。因此,我们通过用 100 减去光照百分比 pc,然后除以 100 进行百分比到小数的转换,从而计算出 desiredLight。
因此,如果室内光线为80%,我们将只以20%的强度点亮LED,所以desiredLight将为0.2。
另外,请注意,当灯亮时,我们实际上每隔5秒钟就会改变一次亮度值。
执行此程序。您会看到什么?
您会注意到一切运行正常,只是在关闭后,LED并没有完全熄灭。它以非常微弱的亮度发光,如图4.10所示。

这是因为在PWM中会发送一个信号脉冲来保持PWM引脚的活跃。没有任何脉冲的脉冲宽度不能为零,因此灯从未真正熄灭。
但是,别担心。这个问题可以通过在 off() 函数中 write(0) **之后** 调用 enable(false),以及在 on() 函数中 write(desiredLight) **之前** 调用 enable(true) 来解决。如果您更改顺序会怎样?如果在 write(0) 之前调用 enable(false),则 PWM 占空比 0 将永远不会被写入,并且 LED 将根本不会熄灭。
因此,我们的开和关功能现在修改如下。
function on()
{
ledState=1;
//------ Uncomment for plain switching///////
//ledPin.write(1);
//-------------------------------//
// PWM---------//
console.log(desiredLight);
ledPin.enable(true);
ledPin.write(desiredLight);
/////////////////
/////////////////
}
function off()
{
ledState=0;
// For pwm only////////
ledPin.write(0);
ledPin.enable(false);
/////////////
}
当您从on()函数启用PWM时,您不能在声明时执行此操作。我不知道为什么,多次启用PWM会无法写入百分比值:(
//---- PWM---------//
var ledPin=new mraa.Pwm(5);
//ledPin.enable(true); don't call it here--> enable it from on function
//---------------------//
4.3.4 舵机控制
我之前曾计划将舵机控制单独作为一个小节,并在我们的物联网设备应用程序中直接解释。但是,我妻子建议舵机可能在许多其他项目(如机器人技术)中都会用到。因此,创建一个使用Intel Edison的舵机基本工作原理会很有用。如您所知,我们男人常常对女士的建议没有抵抗力。所以,这是我妻子强烈要求的一个小节。
本质上,您需要将舵机连接到PWM端口,例如D5/D6,就像您控制LED亮度时所做的那样。
我们需要两个npm库来操作舵机:johney-5 和 edison-io。johney-5 在许多平台(包括R-Pi)的机器人DIY中特别受欢迎。使用 Node.js 的 require 函数将它们添加到您的代码中。
var five = require("johnny-five");
var Edison = require("edison-io");
我们这里要尝试做的是将舵机连接到D5,将按钮连接到D4(是的,把那个LED取下来放回您的Grove盒子)。当我们按下按钮一次时,舵机应该顺时针移动(一次),然后再次按下按钮时,它应该逆时针移动90度回到其原来的位置。
因此,本质上我们将控制舵机位置的角度。假设当前位置为0',另一个位置为90'。让我们定义一个全局变量angle来跟踪当前值。
初始角度为0。
var angle=0;
让我们定义一个名为sw(switch的缩写)的变量来定义按钮状态。
var mraa=require('mraa');
var sw=new mraa.Gpio(4);
sw.dir(mraa.DIR_IN);
让我们初始化johney-5并将舵机角度设置为0。
var board = new five.Board({
io: new Edison()
});
var servo = new five.Servo({
pin:5
});
servo.to(0);
servo.to(ANGLE) 可用于将舵机的角度设置为 ANGLE。角度需要以度为单位指定。因此,90度,45度是有效的舵机角度。
从现在开始,这非常简单。您已经从“用按钮控制LED”示例中了解了开关逻辑。现在您所要做的就是用 servo.to(90) 替换 ledPin.write(1),用 servo.to(0) 替换 ledPin.write(0)。您还需要用 angle=90 替换 ledState=1,用 angle=0 替换 ledState=0。在比较逻辑中,不再与 ledState 比较,而是与 angle 比较。
function loop()
{
var b=sw.read();
if(b==1 && angle==0 && btnState==0)
{
angle=90;
servo.to(90);
btnState=1;
}
else if(b==1 && ledState==1 && btnState==0)
{
servo.to(0);
btnState=1;
angle=0;
}
if(b==0)
{
btnState=0;
}
setTimeout(loop,100);
}
我不是告诉您使用Node.js和Intel Edison真的很简单吗?我没有添加任何此实验的快照,因为我现在相信您不需要为此实验提供插图。
至此,我们的Intel Edison基础硬件学习过程就结束了。还有很多东西可以学习,比如加速度计、振动传感器等,这些内容无法在本篇文章中涵盖。
我包含了这一部分,是为了让Edison的初学者熟悉编码,以便我们开始项目时,您能感到舒适并能自己执行这些步骤。
在开始下一章之前,让我们回顾一下本章所学到的知识,下一章我们将配置网络摄像头和音频作为项目不可或缺的一部分。
章节总结:我们学到了什么
- 如何在Node.js中实现输入输出嵌入式程序逻辑
- 如何使用Grove连接器和Grove扩展板轻松设计硬件
- 设计过程
- 作为学习的一部分,我们进行了三个实时的迷你项目
- 我们学习了MqTT,一种简单通用的物联网消息交换协议
- 我们使用手机远程控制了LED
- 我们学习了如何高效使用LCD
- PWM的使用以及PWM在开关和强度控制中的应用
- 如何从XDK ssh在Edison中安装npm来安装外部Node.js库。
您可以从以下链接下载三个迷你项目的所有代码,作为一个独立的Intel XDK项目。(它包含package.json,会自动安装所有依赖项,如MqTT。因此,一旦您将此项目导入到XDK中,您就不必担心单独安装npm了)。
5. 在英特尔爱迪生中设置音频和摄像头
最后,在掌握了Intel Edison的基础知识并完成了三个增强信心的项目之后,您现在已经准备好跳跃前进,使用Intel Edison进行一些非硬件媒体相关的操作。正如项目名称所示,我们将在项目中使用两种模式:人脸和语音。人脸识别需要您从网络摄像头捕获图像,语音验证需要从输入音频设备捕获语音。因此,第一步是配置它们。
不幸的是,目前还没有即插即用的方法。摄像头和语音都需要先配置好才能使用。
我将语音和摄像头配置作为一个单独的章节,并将其从核心项目开发章节中抽象出来,以作为一种资源呈现。如果您自己的想法涉及使用摄像头或语音,或两者都使用,那么您可以将本章作为设置的参考。
本章将包含两个子主题
- 使用Intel Edison配置网络摄像头
- 使用Intel Edison配置音频
让我们开始配置摄像头。在此之前,您可能需要仔细查看我们的硬件要求部分,以了解需要哪种摄像头。不兼容UVC的摄像头将无法与Edison配合使用。
另请注意,网络摄像头必须通过Edison的主机USB端口连接到Edison。因此,Edison必须为摄像头供电。因此,设备必须有12V电源。请参阅图3.2了解更多详细信息。我建议您**坚持使用Edison官方12V电源**,以便在Edison中使用音频和视频。
5.1 使用英特尔爱迪生设置网络摄像头
我正在使用Creative Sensz3d摄像头,因为它是我在Intel感知计算挑战赛期间获得的(免费!),而且它有一个很好的麦克风阵列,可以捕捉高质量的音频。您可以使用任何兼容UVC的带麦克风的摄像头。
如果您使用过Linux,大多数发行版都有很好的“sudo apt-get install”之类的东西,这使得在Linux平台上生活变得轻松。然而,Yocto开箱即用并没有这样的包管理器。但幸运的是,Alex为Edison创建了一个名为opkg的令人惊叹的包管理器,它非官方地成为Intel Edison的官方包管理器。对于完整的5.1节,请使用SSH通过PuTTY登录到Edison。(因为a)您需要互联网连接,b)您需要打开多个shell来安装和验证)。
步骤1:驱动程序检查
网络摄像头需要网络摄像头驱动程序。首先,通过以下命令检查是否已安装uvc摄像头驱动程序
find /lib/modules/* -name 'uvc'
如果它显示已安装的驱动程序,如下图所示,那么您就完成了。

步骤2:Opkg更新
首先更新opkg。
vi /etc/opkg/base-feeds.conf
并在配置文件中添加以下几行
src/gz all http://repo.opkg.net/edison/repo/all src/gz edison http://repo.opkg.net/edison/repo/edison src/gz core2-32 http://repo.opkg.net/edison/repo/core2-32
按Esc :wq保存并退出编辑器
现在
opkg update
步骤4:驱动程序安装(如果步骤1失败,即未安装驱动程序)
现在使用opkg下载并安装uvc驱动程序
opkg install kernel-module-uvcvideo
安装uvc驱动程序后,您可能需要重新启动Edison板。
步骤5:网络摄像头检测
插入摄像头并**重新启动**设备(摄像头驱动程序仅在启动时加载。因此,要么连接摄像头并启动,要么如果设备已经启动,则使用重新启动)。
现在输入以下命令。
lsmod | grep uvc
如果结果显示uvc模块,则说明您的相机已被检测到并且其驱动程序已由Edison加载。
当安装并插入网络摄像头时,Edison会在/dev中创建一个节点。因此,使用以下命令检查是否创建了video0节点。
ls -l /dev/video0
此完整阶段的结果如图5.2所示

步骤6:安装fswebcam以便从摄像头拍照
opkg install fswebcam
步骤7:用Edison拍摄您的漂亮照片
fswebcam test.png
通过网络摄像头拍摄的照片将以test.png格式存储在根文件夹中。从WinScp下载test.png。
你看到了什么?
一张不那么好的模糊图像?那是因为fswebcam在摄像头准备好之前就查询了设备。所以要捕捉10帧才能得到高质量的照片。
fswebcam --frame 10 good-img.png

图5.3 通过Intel Edison上的网络摄像头捕捉图像
恭喜您成功地让网络摄像头与Edison配合工作。这是您将迈向巨大飞跃的又一小步。
5.2 设置音频
在许多应用程序中,您可能需要流式传输音频。对于这类应用程序,蓝牙音频设备至关重要。我们在这里使用音频输入来捕获人的声音。因此,我将专注于本节的音频输入配置,并省略音频输出和流式传输部分。我们的摄像头有麦克风。第一步是检测此麦克风,然后将其设置为默认音频输入设备,最后设置音频音量、采样率等配置。
我建议您下载并阅读这份官方的Intel Edison音频设置指南。
Intel Edison开箱即用提供了一个名为arecord的工具。您只需对其进行配置。
步骤1:检测您的录音设备
在PuTTY中输入以下命令
arecord -l
它应该显示所有设备的列表,如图5.4所示

识别并标记与您的设备关联的卡号。在我的情况下是卡2。
步骤2:将您的音频输入设备设置为默认捕获设备
检测到音频设备后,下一步是将arecor的默认音频设置为此设备。
vi .asoundrc
并输入以下内容
pcm. !default
{
type hw
card 2
device 0
}
Esc :wq 保存并退出。就这样,您的录音属性已设置完毕。
步骤3 录制音频
设置好默认录音设备后,终于到了录制音频的时候了。使用arecord的命令行工具录制音频
arecord -f cd test.wav
-f cd 强制arecord使用CD质量(44khz)进行录制。
它将开始录制。要停止录制,只需使用ctrl+c。您可以使用WinSCP再次下载录制的文件进行分析。
我说的“codeproject是一个很棒的网站,我喜欢codeproject”的结果可以在图5.5中看到

5.5 通过arecord命令行录音工具生成的wav文件结果
如果您想知道用于显示波形图的软件是什么,那就是Audacity,它是一款用于创建和编辑声音的绝佳工具。
步骤4:配置音频属性(可选)
语音验证需要清晰的音频。语音幅度必须良好。默认的音频属性可能并非总是理想的。如果您的音质不佳,可以通过生成命令调出命令行图形音频属性设置工具
alsamixer
显示实用程序后,按F6选择声卡,如图5.6所示

现在使用键盘上的上下箭头键来设置录音设备的理想增益。

就这样。您现在可以在您的物联网设备中录制音频并更改音频设置了。
至此,我们的Intel Edison培训系列就结束了。是时候进入下一部分,设计和创建我们的项目了。
但在结束之前,像其他章节一样,让我们回顾一下本章所学到的知识
- opkg更新和使用opkg安装内核和驱动程序模块
- 设置网络摄像头
- 通过Edison中的网络摄像头拍照
- 配置音频设备
- 通过音频设备录制音频
- 设置录音属性。
有了这些,我们现在准备好创建我们的生物识别储物柜。在本文的第二部分,我们将详细介绍我们原型机的制作。为您的努力和完成Intel Edison物联网生态系统的学习而欢呼吧。
B部分:动手制作
6. 系统设计
在本章中,我们将主要关注导致我们产品的各种问题。我们将讨论设计、项目的整体流程以及原型的创建。我们还将讨论人脸识别和语音验证以及这两个过程的工作流程。让我们首先了解项目的架构,我将在下一节中详细阐述。
6.1 系统架构

我们的储物柜由Intel Edison供电。这里的储物柜本质上是一个带有锁定机制的盒子。我们将使用舵机作为锁。储物柜将有一个LCD用于向用户显示当前过程和任何其他指示。按钮用于打开和关闭锁。关闭锁不需要身份验证,但打开锁需要用户身份验证。
储物柜还应配备一个与Intel Edison USB主机端口连接的摄像头+麦克风组合。
现在,我们需要一个基于客户端GUI的注册表单,用户可以在其中输入基本信息,如用户名、文本密码和任何其他信息。由于Edison没有键盘和GUI支持,这一部分需要在不同的边缘设备(如手机或PC)上执行。我们通常将此类应用程序称为移动领域的“伴侣应用程序”。对于这个特定的原型,我们将使用我最喜欢的C#开发PC应用程序。
客户端PC应用程序负责用户注册过程。我们还将在这里使用文本转语音,并使用PC的扬声器生成指令。目前,这将是单用户/基于PC的应用程序。
客户端应用程序将在云端创建用户帐户。我们将使用Knurld的用户管理系统注册用户帐户。Knurld的详细工作流程将在稍后作为单独的子节进行解释。
注册时,PC应用程序会要求用户说出特定的语音短语。用户的语音样本将被收集并存储在云端,语音特征将被提取并与Knurld一起存储,用于特定的注册用户。
注册期间,PC应用程序还将捕捉用户的面部,并将其注册到Microsoft的Oxford AI Apis,这是Microsoft认知服务的一部分。
人脸识别API在人脸注册后返回一个用户ID。这个人脸用户ID和语音用户ID通过MqTT发送到储物柜设备。
当用户按下储物柜上的按钮时,Intel Edison首先捕获用户的照片并将其存储在云端,然后将照片链接和人脸用户ID发送给Oxford AI进行验证。如果人脸验证成功,系统会要求用户说出一些给定的示例短语。这些短语将作为音频文件录制并存储在云端。语音注册ID和此验证音频链接将发送给Knurld进行验证。如果验证成功,则解锁。一旦用户再次点击按钮,锁将关闭。
重要提示
由于大多数基于云的生物识别服务提供商都接受样本特征的链接,因此我们还需要使用存储即服务,因为并非所有服务提供商都提供存储服务。因此,我们将使用**Dropbox** APIs进行存储服务。录制的音频和捕获的照片将存储在DropBox中,并获取其链接。注册和验证服务将把这些链接传递给相应的端点。
因此,除了拥有Microsoft和Knurld的账户外,我们还需要一个Dropbox账户。我们将在本章的后面部分,作为独立的子节,深入了解这些服务及其端点。
所以,让我们开始制作我们的储物柜。
在这个阶段,我还想与您分享项目服务结构。整个储物柜需要PC App和Locker向Dropbox、Oxford AI和Knurld发出并接收多个API调用。因此,在专注于我们的编码策略之前,理解整个过程非常重要。图6.2提供了完整的调用-服务-API端点结构。

这张图足以向您解释我们需要为我们的项目构建的复杂API调用结构。对于那些更习惯于算法而非图表的人,这里有算法供您参考。
PcApp ->user : username,password ? user -> PcApp : username,password,gender PcApp -> Knurld : user exists?, AppModel alt exists PcApp -> user : change credential else Success Knurld -> PcApp : UserId PcApp -> user : registration success PcApp -> Knurld : enroll voice, UserID, AppModel Knurld -> PcApp : Phrases, RegistrationID PcApp -> user : Speak phrases user -> PcApp : Recorded audio( audio.wav) PcApp -> Dropbox : store audio.wav Dropbox -> PcApp : Done PcApp -> Dropbox : give link of audio.wav Dropbox -> PcApp : Audio_url PcApp -> Knurld : Analyze( AppModel, Audio_Url, RegistrationID) Knurld -> PcApp : timing.json PcApp -> Knurld : Enroll(AudioUrl, phrases_with_timing.json,registrationId, UserID,AppModel) Knurld -> PcApp : Enroll Message alt Success PcApp -> user : Voice enrolled PcApp -> Locker : AppModel, UserID Locker -> Locker : Store AppModel,UserID PcApp -> user : Photo capture user -> PcApp : phto through camera photo.jpg PcApp -> Dropbox : Store phto.jpg Dropbox -> PcApp : photo.jpg stored PcApp -> Dropbox : give link of photo.jpg Dropbox -> PcApp : photo_url PcApp -> OxfordAI : faceDetect(photo_url) OxfordAI -> PcApp : faceID PcApp -> Locker : store faceId Locker -> Locker :faceId stored else fail PcApp -> user: Enrollment failed end end user -> Locker : Open Lock Locker -> user : "smile please" Locker-> Locker : Capture photo as photo.jpg Locker -> user : photo captured Locker -> Dropbox : store photo.jpg Dropbox -> Locker : photo.jpg stored Locker -> Dropbox: give url of photo.jpg Dropbox -> Locker : Photo_Url Locker -> OxfordAI : Verify ( faceId,Photo_url) alt success Locker -> user : "face verified" Locker -> Knurld : Verify(userId, AppModel) Knurld -> Locker : VerificationId, Phrases Locker -> user : "Speak phrases" Locker -> Locker : Record audio as audio.was Locker -> user : Audio recorded Locker -> Dropbox : Store audio.wav Dropbox -> Locker : Audio.wav stored Locker -> Dropbox : give url of audio.wav Dropbox -> Locker: Audio_url Locker -> Knurld : Analyze(AppModel,verificationID,Audio_url) Knurld -> Locker : timing.json Locker -> Knurld : verify(phrases_with_timing.json, AppModel,UserId, VerificationID) Knurld -> Locker : Verification result alt Success Locker -> user : "User Authenticated" Locker -> Locker : LOCK_OPEN else Locker -> user : "failed" Locker -> Locker : BUZZER end end
当我们深入了解Dropbox、Knurld和Oxford AI的详细信息时,我们将回到这个参考结构。
详细的流程结构已经阐述完毕,让我们先制作储物柜,然后再回到软件部分。
6.2 制造
我们首先需要一个盒子作为储物柜。如果您可以使用3D打印机,非常欢迎您设计一个漂亮的盒子并进行3D打印。不幸的是,我没有这样的设备。所以我使用了一个纸板箱,它基本上装载了我最近在Intel软件创新者会议上收到的纪念品。
图6.3 显示了储物柜盒子的原型。

连接细节如图6.4所示

现在,一旦您将组件连接到Grove Shield和Edison,我们就需要将组件固定到这个盒子上,以获得一个完整的独立盒子。
首先,您需要放置Edison板。标记Edison板支架的位置,如图6.5所示,钻孔或使用螺丝打孔。最后,将Edison板及其支架推入图6.5所示的四个孔中。

将其余组件粘贴在板上,如图6.6所示

最后完成时,我们的储物柜看起来像图6.7和6.8所示。


您可以看到,我们将舵机安装在侧面,以保持锁处于关闭状态。至此,我们完成了储物柜的制作。如果您成功地模拟了制作过程,请为自己欢呼。因为,您已经从一个新手成长为一名拥有模型原型的物联网专业人士,走过了漫长的道路。
现在我们将深入研究使用Knurld的语音识别系统。
6.3 使用 Knurld 进行语音识别
6.3.1 理解语音识别
尽管Knurld是一家基于云的语音验证服务提供商,您并不真正需要理解语音生物识别过程的细节,但对该系统有一个基本了解,以便有效使用它,总是好的。让我们了解一个基本的语音生物识别系统,以便我们更有效地使用Knurld的服务。
生物识别系统一般分为两个阶段:注册和验证。注册类似于我们日常生活中常见的移动和网络应用程序中的用户注册过程。在此阶段,系统会收集用户详细信息。注册还包括一个额外的实体,即用户的生物识别样本。对于语音生物识别,它是用户的语音样本;对于人脸生物识别,它是用户的人脸照片。
语音生物识别系统通常有两种类型:**文本相关**系统和**文本无关**系统。文本相关系统要求用户说出与注册时相同的短语集。另一方面,文本无关系统独立于用户所说的内容,它依赖于用户语音的固有特性,如音高。
文本无关系统并非真正可扩展,因为它极难创建一套独特的特征来区分不同用户。
文本相关系统可进一步分为两种类型:**封闭集**与**开放集**系统。封闭集系统要求用户从选定的列表中说出短语,而开放集系统则允许用户选择他们想要说出的词语集。
在开放集系统中,由于用户可以自由选择任何单词,并且每个单词都有不同的音素,因此为识别每个用户独立建模特征是极其困难的。因此,最近封闭集系统被广泛接受。
语音认证方案可进一步分为两种类型:**验证**和**识别**。识别过程是指系统中不提供参考样本进行匹配。系统必须将测试样本的特征与所有注册用户的特征进行匹配,以找出哪个用户的声音是相同的。该系统主要用于法医领域,主要用作生物识别搜索工具。识别系统的一个例子(人脸而非语音)是Facebook的人脸搜索技术,只要您上传一些照片,它就会提示您照片中存在的用户。
Knurld是一个基于**封闭集、语音验证**的语音生物识别系统。
任何生物识别系统的核心是**特征提取**过程。特征是对生物识别特征(如虹膜、人脸、语音、指纹)的高级描述符。不同的生物识别系统采用不同的算法将特征表示为特征向量。在语音生物识别中,最常见的特征是**倒谱特征**。任何生物识别系统在特征提取之前都会采用**预处理**步骤。语音生物识别最重要的两个预处理步骤是:**静音去除**和**降噪**。语音样本首先进行**低通滤波**以去除噪声。然后使用**时域分割**技术分离语音短语。
从中提取倒谱特征并存储在数据库中或用于匹配。
语音验证系统又可分为**基于模型**或**基于特征**。基于特征的系统是将用户的短语特征向量与参考特征向量进行比较。然而,在基于模型的系统中,验证时会为用户在参考中创建随机顺序的短语。用户需要以完全相同的顺序说出短语。系统不仅检查每个短语的特征,还检查短语是否以给定顺序说出。这种方法声称可以消除通过预录音进行伪造的可能性,因为用户在验证阶段不会知道呈现给他的是什么短语顺序。
Knurld 采用了基于模型的系统。
尽管公司声称拥有最先进的预处理阶段来消除最常见的噪音,但请允许我告诉您,如果您想拥有一个高效的语音生物识别系统,高质量的音频捕获是无可替代的。
所以,我们需要学习用户注册、语音分析、语音注册、语音验证与Knurld。
6.3.2 Knurld API 和服务
步骤1:注册并获取开发者ID
您需要先通过此注册链接在Knurld注册一个开发者账号。成功注册Knurld后,您将收到一封来自公司的电子邮件,其中包含您的开发者ID和oAuth令牌,如下所示。

您需要妥善保管并复制到一些文件中。
步骤2:获取客户端ID和客户端密钥
注册为开发者后,登录开发者主页。在那里您会找到一个“我的API”链接。点击“我的API”后,您会看到一个“Knurld.io高级语音技术API”的超链接。点击该链接,您将看到您的客户端ID和客户端密钥。

图6.10 获取Knurld的client_id和client_secret
因此,您需要开发者ID、客户端ID、客户端密钥来使用Knurld开发端到端的基于语音的认证。
步骤3:授权:获取oAuth令牌
您需要将 client_id 和 client_secret 传递给 Knurld 的 oAuth 端点,以获取 oAuth 访问令牌。 oAuth 令牌和 developer_id 将用于调用其他 API。
您可以访问Knurld的交互式开发者资源,无需编写任何代码即可测试API。迁移到授权部分,输入您在步骤2中获取的client_id和client_secret。
您也可以在交互部分看到API端点详细信息,如下所示
curl -X POST "https://api.knurld.io/oauth/client_credential/accesstoken?grant_type=client_credentials" \
-H "Content-Type: application/x-www-form-urlencoded" \
-d "client_id=$CLIENT_ID" \
-d "client_secret=$CLIENT_SECRET"因此,您可以从任何编程语言中获取一个httpClient(几乎所有语言都有其httpClient),向该端点创建一个POST请求,指定内容类型,并将client_id和client_secret作为参数。
下图6.11显示了API调用的HTTP 200结果和获得的访问令牌。

图6.11 Knurld授权:从client_id和client_secret获取访问令牌
如6.3.1节所述,Knurld是一种封闭集、基于模型、语音验证的语音生物识别系统。因此,您需要使用Knurld支持的短语列表中的至少三个短语来设置一个应用程序模型。要创建应用程序模型,请再次进入交互式API浏览器中的应用程序模型部分。
这是curl请求
curl -X POST "https://api.knurld.io/v1/app-models" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AUTH_TOKEN" \
-H "Developer-Id: Bearer: $DEVELOPER_ID" \
-d ‘{“vocabulary”:[“$PHRASE1”, “$PHRASE2”, “$PHRASE3”],"verificationLength":$VERIFICATION_LENGTH}’以下是交互式演示中对Api的调用

非常非常重要
开发者ID(您通过Gmail获得的)必须在bearer后面加上冒号(Bearer:),而访问令牌(您通过调用授权端点并通过client_id和client_secret获得的)必须以(Bearer )即Bearer SPACE(此处无冒号)指定。如果您忽略了这一点,您将无法从这里开始进行任何API调用。
保存App模型,即“https://...”,保存到某个文件中作为您的App模型。您的所有注册和验证都将基于此模型。请注意我们用于创建App模型的短语:它们是:London、paris和Circle。您可以从Knurld允许的单词中选择任何单词集,如上所述。
步骤5:从交互式网站测试所有功能
登录Knurld的在线基于JavaScript的完整流程演示。

图6.13:实时演示网站显示我们在步骤4中创建的应用程序模型
您可以探索演示站点中的所有选项,以熟悉API和流程。
6.3.3 Knurld 处理流程
我们已经从6.3.2节中学习了一些编码策略。我们已经了解了授权和创建应用程序模型的过程。创建消费者也类似。但是验证和注册过程需要详细的理解,因为它们不是单个API调用,而是一组需要按顺序调用并通过将一个输出链接到另一个输出的API。
注册是一个多步骤过程,这里分步骤解释
步骤1 创建注册
让我们分析一下curl API调用
curl -X POST 'https://api.knurld.io/v1/enrollments' \
-H "Authorization: Bearer $AUTH_TOKEN" \
-H "Developer-Id: Bearer: $DEV_TOKEN" \
-d '{ "consumer": "https://api.knurld.io/v1/consumers/$CONSUMER_ID", \
"application": "https://api.knurld.io/v1/app-models/$APPLICATION_ID" }'您需要将 Bearer oAuth token 和 Bearer: Developer-Id 作为请求头,向端点 https://api.knurld.io/v1/enrollments 发送 POST 请求。
Content-type 必须设置为 application/json
在请求的数据字段中,您需要传入一个JSON数据,其中包含您创建消费者时获得的消费者URL。它将返回一个**enrollment_url和instructions**作为JSON对象。在instructions中,提到了短语以及用户需要说出的次数。响应将包含完整的URL,例如/v1/enrollments/xyz。
其中 xyz 是注册任务 ID。保存此 URL。这需要在步骤 4 中调用。
{
"href": "https://api.knurld.io/v1/enrollments/jdjfkjdskjfweo10280948921"
}步骤2:提交分析
尽管 API 参考中的第二步是填充注册,但如果您观察我们将在步骤 3 中介绍的 API,您会发现该调用需要一个包含“phrase”、“Start”、“Stop”的 payload 字段。这个 payload 是什么?
基本上,这是一个指定您音频中哪个单词在哪个时间实例开始,在哪个时间实例结束的payload。您如何获取它?为此,您需要调用分析。
分析支持两种类型:多部分表单数据和通过URL的端点分析。由于最终验证和注册不支持多部分表单数据,只接受URL,因此我们将只使用URL。
curl -X POST “https://api.knurld.io/v1/endpointAnalysis/url” \
-H "Authorization: $AUTH_TOKEN" \
-H "Developer-Id: $DEVELOPER_ID" \
-H "Content-Type: application/json" \
-d '{ "audioUrl":<URL_TO_FILE>, "words":<int>}'
在调用注册分析时,“words”将为9,因为所有三个短语都将由用户各说三次。audioUrl是存储音频的可下载远程位置。
因此,您需要从麦克风录制音频,将其保存为wav文件(目前只支持.wav格式),上传到云存储服务,获取URL,然后将其传递给分析服务。
这正是我们PC应用程序和物联网设备应用程序都需要与**Dropbox**集成的原因。
Knurld的问题在于,它不会从这个调用返回短语及其时间位置。它只返回一个任务名称。
{
"taskName": "f25b31b1ab3d2400cada5dead8c7b256",
"taskStatus": "started"
}您现在需要调用获取分析端点才能最终获取短语
步骤3:获取分析
curl -X GET “https://api.knurld.io/v1/endpointAnalysis/$TASK_NAME” \
-H "Authorization: $AUTH_TOKEN" \
-H "Developer-Id: $DEVELOPER_ID"
在endPointAnalysis中,您可以看到一个名为`$TASK_NAME`的变量,您需要在此处传入您从“提交分析”步骤中获得的`taskName`值。
这将返回一个JSON对象,如下所示。
{
"taskName": "f25b31b1ab3d2400cada5dead8c7b256",
"taskStatus": "completed",
"intervals": [
{
"start": 2576,
"stop": 3360
},
{
"start": 3856,
"stop": 4512
},
{
"start": 5040,
"stop": 5568
}
]
}对于注册,将有9个这样的数组元素;对于验证,将有3个元素。
请仔细观察,这个JSON数组只给出短语的开始和停止间隔,而不是短语本身。但是下一步,也就是提交注册的分析结果,需要一个包含短语、开始和停止元素的数组。因此,在这一步中,您必须获取结果,解析它们,追加短语,创建一个新的JSON数组,然后将其传递到下一步。
步骤4:填充注册
curl -X POST "https://api.knurld.io/v1/enrollments/$ENROLLMENT_ID" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $AUTH_TOKEN" \
-H "Developer-Id: Bearer: $DEVELOPER_ID" \
-d ‘{\"enrollment.wav\":\"$AUDIO_URL",\"intervals\":[ \
{\"phrase\":\"$WORD\",\"start\":value,\"stop\":value},\
{\"phrase\":\"$WORD\",\"start\":value,\"stop\":value}, \
{\"phrase\":\"$WORD\",\"start\":value,\"stop\":value}]}’
在此阶段,您需要调用在步骤1中获取的注册端点URL,通过发送在步骤3中创建的payload。请注意,虽然分析只返回开始和停止时间,但此payload也要求提供短语。因此,我们讨论了解析和创建新的JSON对象。
步骤5:获取注册状态
提交工资单并不能真正确保您的注册成功。可能有许多原因,例如错误的短语顺序等,都可能导致注册失败。因此,作为最后一步,您必须调用获取注册状态以了解您的注册是否成功!
curl -X GET “https://api.knurld.io/v1/enrollments/$ENROLLMENT_ID” \
-H "Authorization: Bearer $AUTH_TOKEN" \
-H "Developer-Id: Bearer: $DEV_TOKEN"成功或失败可以从响应的“status”字段进行分析。
验证过程与注册流程相同。您只需将端点URL中的“**enrollments**”替换为“**verifications**”即可。
至此,我们结束了对语音识别的理解,特别是对Knurld语音识别服务的理解。这将帮助您理解代码模型。您可以通过手动录制音频,手动将其保存到Dropbox,然后将URL传递给分析步骤来手动测试每个API端点。
在下一节中,我们将学习人脸识别步骤,并深入了解微软的认知服务。
6.4 使用微软认知服务(Oxford AI)进行人脸验证
6.4.1 理解面部识别和多生物识别
在我们学习基于云的人脸识别工作原理之前,让我们先讨论一下人脸识别系统一般是如何工作的。
人脸识别系统就像语音生物识别系统一样,是一个两步过程:注册和验证。每个步骤都有两个主要步骤:**预处理**和**特征提取**。语音识别中的预处理包括降噪和静音去除,而人脸识别中的预处理是**人脸检测**过程。
人脸检测是指在图像中定位人脸区域并将其从图像中分割出来。人脸特征提取又可分为两种类型:**人脸定位**或**全局特征提取**。在人脸定位过程中,会提取眼睛、鼻子、嘴唇、额头、下巴、脸颊,并从这些部位分离出特征。人脸定位引出了另一个令人兴奋的领域,即情感分析。局部人脸特征用于检测人脸的性别、年龄和其他方面。
全局或局部特征可以转换为一个名为**模板**的字符串。人脸验证过程可以是**基于模型**的匹配,也可以是基于模板匹配的。
我建议您阅读并使用这篇非常棒的多面部识别的codeproject文章,以了解人脸识别的工作原理。
您一开始可能有的问题之一是,为什么我们需要多生物识别?为什么单单人脸识别不够?
嗯,您可以从塞尔吉奥文章的封面照片中找到部分答案,其中您可以看到系统也识别了塞尔吉奥手中照片中孩子的脸。因此,人脸识别系统可能会被通过展示用户的照片来欺骗,并且始终存在安全风险。一些人脸识别服务提供商正在将“活体检测”作为人脸识别过程的核心服务之一,但它尚未标准化。
另一方面,语音识别系统可以通过模仿声音来欺骗。因此,这两种生物识别技术都各有优缺点,同时具有低成本硬件实现的优势。通过将人脸与语音结合,您首先确保活体检测自动集成。因为在与Knurld进行的语音识别中,您被要求按照随机生成的顺序说出短语,并且该顺序的会话过期时间非常有限。只有人类才能在如此有限的会话中做出响应。通过将人脸与语音结合,您克服了模仿声音的问题。因此,理论上和原则上,多模态人脸-语音生物识别提供了更好的安全性。
现在,我们来看看微软的认知服务,了解人脸识别是如何工作的。
6.4.2 微软认知服务 - 人脸 API
与Knurld一样,MCS也提供用户管理和人脸识别服务。但我们将使用Knurld的账户管理来实现我们的用例。因此,我们将关于MCS的讨论仅限于人脸识别和人脸API。
一个常见的问题是,为什么只有微软?还有其他人脸API吗?是的,现在有许多公司提供基于云的人脸API,例如face++。
事实上,如果你探索了face++网站,然后回到MCS,你很可能会问“谁抄袭了谁”?作为一名开发者,我将这个问题留给版权专家,并从用户体验的角度来思考。
让我向您保证,在探索了大量人脸识别和面部表情分析服务后,我发现MCS是最稳定、延迟最低,最重要的是**摄像头、姿态、强度无关**。
为什么摄像头和强度独立如此重要?因为,显然我们的注册将通过笔记本电脑完成,那里的摄像头将与您将用于Intel Edison的物联网摄像头不同。储物柜可能不会放在家里“光线最充足”的地方(我不知道有人把储物柜放在阳台)。但是,用户可能在光线充足的办公室或客厅使用笔记本电脑。所以对我来说,摄像头和光线(技术上有时称为**亮度独立**)识别服务至关重要。
下图6.14可以很好地说明我想表达的意思。
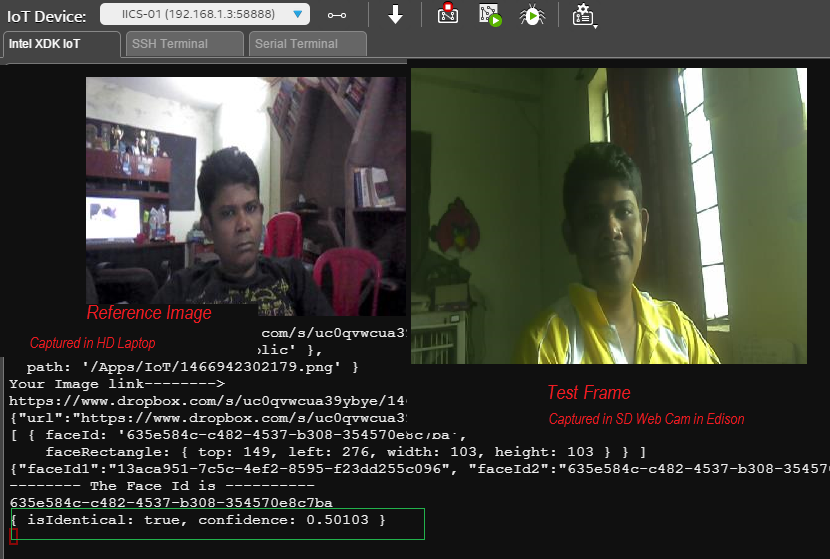
图6.14:微软认知人脸API的光线、姿态和摄像头独立人脸识别
测试帧是在我们构建的储物柜的一次实时测试中捕获的。您可以清楚地看到这里人脸识别系统的质量。此外,微软人脸API的延迟(即算法的响应时间)在我测试的一些服务中是最低的。许多服务在此摄像头独立功能上失败了。因此,我们将优先选择微软的认知服务。
您可以将自己的照片上传到Dropbox,并在主页上直接测试检测服务。
重要提示:Dropbox链接有dl=0扩展名,这意味着API无法处理它们。因此,无论是knurld还是人脸API,您都需要将dropbox url从dl=0更改为dl=1。[我们将在代码中处理这个问题!]
这是人脸API对我与挚爱妻子的合影的分析。

API返回一个易于解析的JSON对象。
2 faces detected
JSON:
[
{
"faceId": "d4dfe717-796c-43d7-985f-21f2c9ac9fca",
"faceRectangle": {
"width": 189,
"height": 189,
"left": 356,
"top": 174
},
},
"faceAttributes": {
"age": 33.5,
"gender": "female",
"headPose": {
"roll": 3.1,
"yaw": -16.8,
"pitch": 0
},
"smile": 0.975,
"facialHair": {
"moustache": 0,
"beard": 0,
"sideburns": 0
},
"glasses": "NoGlasses"
}
},
{
"faceId": "89477e90-cbbc-4aac-b9fc-6340d365e6ed",
"faceRectangle": {
"width": 176,
"height": 176,
"left": 207,
"top": 138
},
"faceLandmarks": {
}
},
"faceAttributes": {
"age": 39,
"gender": "male",
"headPose": {
"roll": 15.3,
"yaw": -6.7,
"pitch": 0
},
"smile": 1,
"facialHair": {
"moustache": 0,
"beard": 0,
"sideburns": 0
},
"glasses": "NoGlasses"
}
}
]
我已删除呈现人脸中每个地标点起点和终点的 facelandmarks 属性。
因此,该服务提供了多重人脸检测,每个面部都带有属性。性别、微笑分析和头部姿态可以与人脸识别结合使用,以提供更好的识别服务。例如,您可以使用微笑和姿态通过应用程序实现活体检测。您可以随机询问用户“向左侧倾斜脸部并微笑”。如果分析返回左侧姿态(从旋转、俯仰、偏航),则用户正在动态响应程序,并被认为是活体对象。
然而,这个项目并没有实现人脸活体检测,因为语音为我们做了这件事。
有趣的是,您会发现您使用人脸API分析的每张人脸都会获得一个唯一的ID。注册时提供的人脸ID(由我们的程序逻辑处理)和验证时分析测试人脸生成的人脸ID可以提供给faceVerification API以获取匹配结果。
MCS人脸API最酷的地方在于,您无需创建任何账户,也无需任何麻烦,即可测试我们的两个测试用例。
在同一个主页上,您也可以测试验证过程!
一旦对算法的稳健性有信心,只需创建一个免费账户。您可以从OxfordAI的API测试控制台探索所有服务。
在我们的案例中,我们将只使用两个API:人脸检测和人脸验证。注册将由逻辑处理。当您在PC应用程序的“注册”期间提交人脸时,它将返回一个人脸ID。我们将此ID保存在文件中,并通过MqTT发送到Edison。Edison会将此ID保存在文件中。
当在验证期间拍摄用户照片时,Edison将首先将其提交进行检测。将返回一个新的ID。此验证人脸ID和存储的注册时人脸ID将发送到验证服务,该服务将返回一个相似度度量。根据您的应用程序的灵敏度,您可以设置一个阈值来接受或拒绝验证照片。
所以,创建您的账户并在控制台测试API。这将为您在实施之前提供极大的信心。
由于Knurld和MCS都需要远程URL,我们将使用Dropbox作为桥梁和存储即服务,来存储我们的音频和照片,并将它们传递到各自的端点。在下一节中,我们将快速向您介绍此项目所需的Dropbox API。
6.5 Dropbox - 应用与生物识别端点之间的桥梁
我想你们大多数人已经有一个Dropbox账户了。如果没有,就创建一个吧。它是一个很酷的云存储服务提供商。
现在,我们有兴趣访问一些Dropbox API。所以请前往Dropbox开发者页面,点击oAuth,然后点击token/revoke。
点击“获取令牌”以获取令牌。您将看到访问令牌,如图6.16所示。

这就是您开发应用程序所需要的一切。
我们对访问两个API感兴趣:上传和获取共享链接。
对于上传,我们将在PC应用程序中使用C#库,在设备应用程序中使用Node.js。上传时,您需要指定您的文件夹。/表示根文件夹。/Photos表示您Dropbox中的Photos文件夹。
无论您在上传时指定哪个文件夹,获取共享链接时都需要传递相同的文件夹。
curl -X POST https://content.dropboxapi.com/2/sharing/get_shared_link_file \ --header 'Authorization: Bearer <My access token>' \ --header 'Dropbox-API-Arg: {"url":""}'
通过程序中的HTTP客户端进行的API调用将返回特定文件的远程URL。在程序中,您需要将dl=0更改为dl=1,并在进行人脸识别和语音识别时将其传递给相应的端点。
嗯,这就是您创建生物识别储物柜所需的所有背景信息。您现在已经准备好做您在codeproject中最擅长的事情了,那就是编码。
但在我们跳到教程中最喜欢的部分之前,让我们再次回顾一下本章所学到的知识。
章节总结
- Knurld API结构、流程和工作原理。
- 如何测试API。
- 微软人脸API结构和调用
- Dropbox API。
- 您创建了一个Dropbox开发者账户,Knurld开发者账户,并订阅了微软认知服务的人脸API。您从MCS API控制台获得了访问令牌。
- 我们学习了人脸和语音识别的一些基本原理,以及为什么多模态生物识别更安全。
- 我们对API测试有了普遍的理解,并学习了如何以平台无关的方式调用API端点。
最后,经过数小时的学习、账户创建、API测试、制作,是时候将所有这些整合到一个集成的物联网应用程序中了。让我们进入编码部分,我相信这将是本文中最容易理解的部分!
7. 编码 - 为储物柜开发软件套件
您已经知道,我们的整体软件套件将在两台不同的机器(和设备)上运行两个不同的应用程序。
PC应用程序执行以下操作
- 使用Knurld创建用户账户
- 用户语音注册。
- 用户人脸注册
- 与Edison设备建立MqTT桥接。使用Text2Speech说出设备发来的消息。
- 语音注册后向设备应用程序发送消费者ID
- 将人脸注册期间获取的人脸ID发送到设备应用程序
设备应用程序则将在Intel XDK中使用Node.js开发。它需要执行以下操作
- 它应该能够与PC应用程序交换MqTT消息
- 将faceID和ConsumerID存储在文件中
- 等待用户按下按钮
- 当用户按下储物柜按钮时,如果状态为“打开储物柜”,则初始化人脸验证过程。
- 如果人脸验证成功,则启动语音验证。
- 如果语音验证成功,则通过控制舵机打开储物柜。
您可以再次参考参考序列图,更仔细地查看详细的流程序列。
考虑到这些要点,让我们转向PC应用程序的设计和开发。
7.1 PC 应用

PC应用程序将使用Windows Form应用程序开发。欢迎您设计一个WPF版本。设置应用程序必须不断扫描设备,并在设备可用时连接到设备。我们的设备应用程序会定期发送“Hello”MqTT消息。因此,此应用程序订阅MqTT通道。当它收到Hello消息时,它会显示一条消息“已连接到设备”。
7.1.1 设置和注册
我们使用M2MQTT客户端库进行MqTT的发布和订阅。下载DLL并将其添加为项目引用。它需要.net framework 4.0及以上版本。因此,您的项目目标必须>4.0。
BackgroundWorker bwStart = new BackgroundWorker();
public static MqttClient mc = null;
public static string topic = "rupam/Locker";
string broker = "iot.eclipse.org";
System.Speech.Synthesis.SpeechSynthesizer speaker = new System.Speech.Synthesis.SpeechSynthesizer();
我们声明了一个名为 mc 的 MqTT 客户端。我们定义了一个名为 "rupam/Locker" 的通道用于消息交换。
我们声明了一个 BackgroundWorker bwStart 来在后台启动与 iot.eclipse.org 的连接。
工作线程在 Form_Load() 事件中运行
bwStart.DoWork += bwStart_DoWork;
bwStart.RunWorkerCompleted += bwStart_RunWorkerCompleted;
bwStart.WorkerSupportsCancellation = true;
bwStart.RunWorkerAsync();
在 DoWork 中,我们初始化与代理的连接。
void bwStart_DoWork(object sender, DoWorkEventArgs e)
{
mc = new MqttClient(broker);
mc.Connect("RUPAM");
//throw new NotImplementedException();
}
在 RunWorkerCompleted() 中,我们订阅 MqTT 消息。
void bwStart_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
mc.Subscribe(new string[] { topic }, new byte[] { (byte)0 });
mc.MqttMsgPublishReceived += mc_MqttMsgPublishReceived;
tssLabel.Text = "Connected to IoT Hub";
}
您可以观察到,我们订阅主题是在添加消息接收事件处理程序之前。mc_MqttMsgPublishedReceived 是设备和PC应用程序之间的桥梁。消息以二进制形式接收,首先转换为文本。
void mc_MqttMsgPublishReceived(object sender, uPLibrary.Networking.M2Mqtt.Messages.MqttMsgPublishEventArgs e)
{
this.Invoke((MethodInvoker)delegate
{
if (e.Message[1] == (byte)0)
{
// listBox1.Items.Add(GetString(e.Message));
}
else
{
try
{
string command = "";
for (int i = 0; i < e.Message.Length; i++)
{
// command = command + ('A' + ((int)e.Message[i] - 64));
command = command + ((char)('A' + ((int)e.Message[i] - 65))).ToString();
}
//MessageBox.Show(command);
if (command.Contains("Connected") )
{
if (labConnection.Text.Contains("Not"))
{
labConnection.Text = "Locker Connected";
speaker.Rate = -1;
speaker.Speak(command);
mc.Publish(topic,GetBytesForEdison("Connected to App"));
}
}
else
{
speaker.Rate = -1;
speaker.Speak(command);
}
}
catch
{
}
}
});
}
最初,labConnection文本被设置为“未连接”。设备定期发送一个名为“Connected Cashbox”的MqTT消息。此函数检查“Connected”一词。当它收到消息时,它会检查设备是否已连接,如果没有,则更改labConnection的文本并触发语音。
如果我们不使用它并在每次收到“Hello”消息时触发语音,那么每隔2-5秒,设置应用程序就会说出“Connected”。我们通过从数字中减去65并将其添加到字符“A”来将二进制消息转换为ASCII。
如果命令不包含“Connected”这个词,那么它就是来自设备的日志消息,所以,无论内容如何,我们都在else部分把它说出来。
点击“账户设置”按钮会弹出第二个表单,即frmPassword。表单的运行时如图7.2所示。

该表单通过检查 /AppData/Roaming/IntegratedIdeas/IoTBiometric/consumer.txt 中是否存在文件条目来检查用户是否已注册。如果不存在,则告知用户需要注册。同时,该应用程序会检测PC用户名并将其放入用户名字段,以进一步简化注册。
此表单还包含两个图片框:较大的图片框渲染摄像头捕获的帧,较小的图片框渲染分割后的人脸。帧渲染和分割部分改编自我们曾在人脸识别部分引用的Sergio的Multi face recognitoon教程。我们使用EmguCV进行帧捕获和局部人脸检测。
表单中提供了人脸检测,以便用户在注册前就知道人脸检测在本地工作正常。
在 Form_Load 方法中,我们初始化摄像头并向 Application.Idle 添加一个名为 FrameGrabber 的事件处理程序,用于从摄像头捕获帧。
#region initialize face
try
{
face = new HaarCascade("haarcascade_frontalface_default.xml");
grabber = new Capture(0);
grabber.QueryFrame();
//Initialize the FrameGraber event
Application.Idle += new EventHandler(FrameGrabber);
}
catch
{
MessageBox.Show("can not start camera","Error",MessageBoxButtons.OK,MessageBoxIcon.Error);
}
#endregion
其中 face 和 grabber 的声明如下
#region face related declarations
Image<Bgr, Byte> currentFrame;
public Capture grabber;
HaarCascade face;
#endregion
在FrameGrabber方法中,我们检测人脸,将其分割并显示在小人脸缩略图框中。
void FrameGrabber(object sender, EventArgs e)
{
currentFrame = grabber.QueryFrame().Resize(320, 240, Emgu.CV.CvEnum.INTER.CV_INTER_CUBIC);
picMain.BackgroundImage = new System.Drawing.Bitmap(currentFrame.Bitmap, picMain.Size);
gray = currentFrame.Convert<Gray, Byte>();
//Face Detector
MCvAvgComp[][] facesDetected = gray.DetectHaarCascade(
face,
1.2,
10,
Emgu.CV.CvEnum.HAAR_DETECTION_TYPE.DO_CANNY_PRUNING,
new System.Drawing.Size(20, 20));
//Action for each element detected
foreach (MCvAvgComp f in facesDetected[0])
{
t = t + 1;
var imFace = currentFrame.Copy(f.rect).Resize(picFace.Width, picFace.Height, Emgu.CV.CvEnum.INTER.CV_INTER_CUBIC);
picFace.Image = imFace.Bitmap;
}
// Calling FaceSdk.
}
这种方法在硅谷术语中是“受塞尔吉奥项目启发”,但在普通英语中,它被称为“无耻抄袭”该项目:)
如果用户账户未注册,点击注册按钮将触发Knurld的用户注册。由于HttpCalls都是阻塞的,我们希望它们作为后台进程执行。我们需要告诉与Knurld调用关联的backgroundWorker应该调用哪个操作。我们通过一个名为KnurldOperations的枚举来完成。
public enum KnurldOperations { AUTHORIZE, REGISTER, CHANGE_PASSWORD, INIT_ENROLLMENT, SUBMIT_ANALYSIS, ENROLL, INIT_RECOGNITION, RECOGNIZE, AUTHENTICATE,NONE,INIT_VERIFICATION, ENROLLMENT_INSTRUCTIONS,DROPBOX_UPLOAD, DROPBOX_SHARE,GET_ANALYSIS,VERIFICATION_INSTRUCTIONS,VERIFY,VERIFICATION_STATUS};
因此,在注册期间,我们将操作类型设置为 REGISTER,并为 bw 调用 RunWorkerAsyn()。
if (btnOK.Text.Equals("Register"))
{
timHttpProgress.Enabled = true;
toolStripProgressBar1.Value = 0;
Operation = KnurldOperations.REGISTER;
bw.RunWorkerAsync();
tssMessage.Text = "Registration in Progress";
}
我创建了一个文档齐全的类KnurldHelper,用于抽象对Knurld API的调用。
让我们首先看一下KnurldHelper类的RegisterUser方法,然后再看bw的DoWork。
#region Registration and User/consumer related Apis
/// <summary>
/// This method registers a user and return the user specific URL called Consumer.
/// There is no validation at the server side. So you must handle the validation in your code
/// For instance check for blank username or password and so on.
/// </summary>
/// <param name="username">Unique username</param>
/// <param name="password">password of any length/format/alpha numeric</param>
/// <param name="gender">Gender M or F</param>
/// <returns>consumer if registration is successfull else return error</returns>
public static string RegisterUser(string username, string password,string gender)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.knurld.io/v1/consumers");
request.Headers.Add("Authorization", "Bearer " + AccessToken);
request.Headers.Add("Developer-Id", "Bearer: " + DeveloperId);
request.Method = "POST";
request.ContentType = "application/json";
// adding paremeters
string s = "{\"username\":\"" + username + "\",\"gender\":\"" + gender + "\",\"password\":\"" + password + "\"}";
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
var consumer = result["href"].ToString();
return consumer;
}
catch (WebException we)
{
string responseError = new StreamReader(we.Response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseError);
string s = "";
if (result.ToString().Contains("fault"))
{
s = "Error :-" + result["fault"]["faultstring"] + "\n" + result["fault"]["detail"]["errorcode"].ToString();
}
else if (result.ToString().Contains("message"))
{
s = s + "Error :- " + result["message"];
}
else
{
s = result["ErrorCode"] + "\n" + result["Error"];
}
return s;
}
}
将此方法的实现与 Knurld 的 API 端点进行比较。
我们创建一个 HttpWebRequest 对象并调用API端点。我们将AccessToke(在frmMain加载时通过调用 FetchAccessToken() 获取)放入请求头中。AccessToke和DeveloperID(用户需要提供)作为请求头参数提供。我们构建一个JSON兼容的Payload字符串,其中包含username、gender和password字段。此字符串 s 或 postData 将转换为字节格式,通过调用 Encoding.ASCII.GetBytes(postData) 作为请求的Payload发送。
请注意,HttpWebRequest 存在于 System.Web dll 中,**该 dll 不适用于客户端配置文件框架。因此,在选择 .Net 框架时,请不要选择 4.0 客户端配置文件。**
请记住,创建消费者后,它会在响应的 href 字段中返回一个完整的URL。因此,我们解析响应并将其作为结果返回。
我们还处理WebException。如果payload不是正确的JSON格式,API端点将返回“fault string”消息。对于所有其他情况,它将返回包含HTTP错误和错误描述的JSON错误字符串。我们希望我们的方法调用者能够区分有效响应和错误。因此,我们在返回错误消息之前,在其前面加上一个简单的“Error:-”字符串。调用方(RunWorkerCompleted)在收到响应后将检查返回字符串中是否存在“Error:-”字符串块。如果找到该字符串块,则会向用户显示适当的错误消息。
让我们看看我们的 FetchAccessToken() 方法。请记住,我们之前在Knurld API部分讨论过如何从Knurld的API浏览器调用此方法。将该部分的curl请求与下面的实现进行比较。
#region Authorization
/// <summary>
/// This method is called first to set the access token to the app
/// This automatically takes ClientId and ClientSecret from the publice class members
/// </summary>
public static string FetchAccessToken()
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.knurld.io/oauth/client_credential/accesstoken?grant_type=client_credentials");
var postData = "client_id="+ClientId;//94CtiIKAyjhZAvJhT4X6RJIOxXY80hAw
postData += "&client_secret="+ClientSecret;
var data = Encoding.ASCII.GetBytes(postData);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = data.Length;
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
AccessToken = result["access_token"];
return AccessToken;
}
catch (WebException we)
{
string s = DecodeException(we);
return s;
}
}
#endregion
DecodeException() 是一个简单实现 RegisterUser 方法中 WebException 处理部分的方法,这样对于每个 API 调用,在 WebException 处理部分,您只需调用此方法即可将异常解析为字符串。
我们根据 Knurld API 端点文档将 request.Method 更改为 "POST" 或 "GET"。由于每个端点调用都会返回不同的 JSON 字符串,我们将响应捕获到一个名为 response 的动态数据类型中。然后根据 API 参考,我们解析并提取我们感兴趣的字段。
KnurldHelper通过调用InitAll()方法进行初始化。
/// <summary>
/// This method MUST BE CALLED prior to using any other methods of this class. This sets up the sdk
/// </summary>
/// <param name="ClientId">Your ClientID</param>
/// <param name="ClientSecret">Your Client Secret</param>
/// <param name="DeveloperId">Without "Bearer:" keyword</param>
/// <param name="Company">Company name</param>
/// <param name="Product">App name. This sdk creates a directory: \Users\Username\AppData\Roaming\CompanyName\ProductName and puts all resources there</param>
public static void InitAll(string ClientId,string ClientSecret,string DeveloperId,string Company, string Product)
{
KnurldHelper.ClientId = ClientId;
KnurldHelper.ClientSecret = ClientSecret;
KnurldHelper.DeveloperId = DeveloperId;
KnurldHelper.CompanyName = Company;
KnurldHelper.ProductName = Product;
Path = Environment.GetFolderPath(Environment.SpecialFolder.ApplicationData) + "\\" + CompanyName + "\\" + ProductName + "\\";
}
请注意,此方法要求用户提供公司名称和应用程序名称作为参数。我们在 C:\Users\
要获取这些文件,需要使用助手的 Path 属性,它将存储目录从用户那里抽象出来。由于 InitAll() 初始化了路径所需的所有字段,因此您的程序不必担心为项目创建和管理应用程序目录。
public static string Path
{
set
{
path = value;
if (!Directory.Exists(path))
{
Directory.CreateDirectory(path);
}
}
get
{
path = Environment.GetFolderPath(Environment.SpecialFolder.ApplicationData) + "\\" + CompanyName + "\\" + ProductName + "\\";
return path;
}
}
了解了KnurldHelper方法的工作原理后,让我们回到调用部分。回想一下,我们根据KnurlOperation类型变量Operation的值在bw_DoWork()方法中调用这些方法,Operation的值由我们的GUI在调用bw.RunWorkerAsync()之前设置。让我们看看DoWork方法。
void bw_DoWork(object sender, DoWorkEventArgs e)
{
switch (Operation)
{
case KnurldOperations.REGISTER:
string gender="M";
if(radioButton2.Checked)
{
gender="F";
}
result = Knurld.KnurldHelper.RegisterUser(txtUname.Text, txtNewPwd.Text, gender);
break;
case KnurldOperations.AUTHENTICATE:
result = Knurld.KnurldHelper.Authenticate(txtUname.Text, txtOldPwd.Text);
break;
case KnurldOperations.CHANGE_PASSWORD:
result = Knurld.KnurldHelper.ChangePassword(File.ReadAllText(frmMain.Path + "consumer.txt"), txtNewPwd.Text);
break;
}
//throw new NotImplementedException();
}
当我们获得结果(无论是异常还是有效的http响应)时,我们可能需要根据结果访问GUI组件。因此,结果字符串被声明为全局变量。一旦获得结果,就会调用RunWorkerCompleted()部分,我们在这里实现决策逻辑。
让我们看看 RunWorkerCompleted() 方法的 REGISTER 部分。
switch (Operation)
{
case KnurldOperations.REGISTER:
toolStripProgressBar1.Value = 0;
timHttpProgress.Enabled = false;
if (result.Contains("Error"))
{
MessageBox.Show(result, "Registration Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
txtUname.Focus();
tssMessage.Text = "Registration Failed";
}
else
{
MessageBox.Show(txtUname.Text+" is registered", "Registration Suuccessful", MessageBoxButtons.OK, MessageBoxIcon.Information);
File.WriteAllText(frmMain.Path + "Consumer.txt", result);
File.WriteAllText(frmMain.Path + "User.txt", txtUname.Text);
tssMessage.Text = txtUname.Text + " is registered now";
grpVoice.Visible = true;
}
break;
//...... other cases here...... We are only checking Register method.
}
您可以清楚地看到,我们已将错误处理逻辑与HTTP 200情况分开。上述代码的else部分是有效响应。当RegisterUser()方法返回消费者URL时,该URL将写入指定路径。
你可能会问一个简单的问题。为什么不使用Async?嗯,我对Async方法不太熟悉,也没有效率编写它们。你可以自由地将这些方法导入到基于Async的风格中。
您可能还会问,为什么是文件数据库?我们可以使用SQLLite吗?当然可以。因为我们不需要在这里存储太多数据(请记住我们的数据在云端),而且在开发代码时,我必须处理在日志中转储大量原始响应,所以我更喜欢文件数据库,在那里我可以转储响应,用文本编辑器打开,分析并同时开发代码。
注册成功后,frmPassword 中的“注册语音”按钮变得可见。注册结果见图 7.3。

如果您想知道为什么是 John(或者 John 是谁)而不是 Rupam,我已经创建了 Rupam 的几种变体,并且在收到“用户已存在”消息后,没有耐心更改名称。所以 John(一个我想到的随机名字!!!)
注册后,应用程序会检查应用程序路径中的 enrollment.txt,但由于未注册语音而未找到。因此它会弹出一个消息并保持按钮处于活动状态。点击此按钮
7.1.2 语音注册(录入)
语音注册需要执行以下任务
- 通过传递 AppModel 初始化验证,
- 解析响应并提取指令
- 向用户读出指令
- 录制用户语音
- 保存录制的音频
- 将音频上传到 Dropbox
- 获取 Dropbox 链接
- 将 URL 中的 dl=0 更改为 dl=1
- 提交音频进行分析
- 一旦获得开始和结束间隔的 JSON 分析数组,就获取它并附加短语
- 将其发送到注册函数
- 持续轮询 GetEnrollment 状态,直到 API 终点返回初始化。
- 一旦状态成功,将消费者 URL 返回到我们的设备。
- 此外,由于注册和验证都取决于音频录制质量,我们需要确保音频质量刚好适合录制。
由于步骤繁多,语音注册(除了录音)大约需要 15-30 秒,我们会在 frmVoice 表单中提供有关各个标签的所有信息,并随着进程的逐个完成,用勾号符号更改这些标签的文本。
我们来看看图 7.4 中的 frmVoice 表单

frmVoice 加载的那一刻,accessToken 会再次获取,因为 Knurld accessToken 的生命周期极短。我们不希望在应用程序完成之前 accessToken 过期。一旦获得访问令牌,就会初始化注册。我们获得一个 URL 和一组指令,这些指令显示在顶部。
回想一下,为了使注册正常工作,程序需要将 AppModel 传递到 JSON 数据字段中。回想一下,我们在 Knurld API 部分通过 API Explorer 创建了一个 AppModel。
在 Form_Load() 方法中,我们获取存储在路径中 App.txt 中的 AppModel。如果 App.txt 不在路径中,它将从当前目录复制(由于我将调试模式设置为 Debug,它将从 Debug\App.txt 复制到 Path\App.txt。因此,如果您想用您创建的 AppModel 更改 AppModel,请复制文本并替换 Debug 文件夹中 App.txt 的内容)。
Operation = KnurldOperations.INIT_ENROLLMENT;
try
{
KnurldHelper.App = File.ReadAllText(frmMain.Path + "App.txt");
}
catch
{
File.Copy(".\\App.txt", frmMain.Path + "App.txt");
KnurldHelper.App = File.ReadAllText(frmMain.Path + "App.txt");
}
// Start the background process...
bw = new BackgroundWorker();
bw.DoWork += bw_DoWork;
bw.WorkerReportsProgress = true;
bw.WorkerSupportsCancellation = true;
timer1.Enabled = true;
bw.RunWorkerCompleted += bw_RunWorkerCompleted;
bw.RunWorkerAsync();
此外,在获取 AppModel 之后,我们立即启动后台进程。由于 Operation 设置为 INIT_ENROLLMENT,它将调用 KnurldHelper 类的 StartEnrollment()。
void bw_DoWork(object sender, DoWorkEventArgs e)
{
switch (Operation)
{
case KnurldOperations.INIT_ENROLLMENT:
result = Knurld.KnurldHelper.StartEnrollment(File.ReadAllText(frmMain.Path + "Consumer.txt"));
break;
// other cases will be discussed later
}
}
注意,StartEnrollment() 方法需要 consumerID(或 URL)作为参数,因为它必须调用 /v1/enrollments/consumerID 作为端点。在用户注册成功后,消费者 URL 或 consumerID 已保存在 Path 中的 Consumer.txt 文件中。
让我们来看看 StartEnrollment() 方法,现在理解它应该不难。
#region Enrollment related APIs
/// <summary>
/// Starts a Voice Enrollment process for a registered user
///
/// <param name="userHref">The url of the username.
/// 1. Call GetAllConsumers(). var cons=GetAllConsumers()
/// 2. the method gets App Id from Property Knurld.App. Make sure it is set by calling LoadMyApp()
/// 3. Fetch url of the user. var url=ConsumerUrlFromUsername(cons,userName);
/// 4. var enrollmentUrl=StartEnrollment(url);
/// </param>
/// /// <returns>Enrollment URL, required for a) Processing Audio=> Submitting Audio, Enroll</returns>
/// </summary>
public static string StartEnrollment(string userHref)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.knurld.io/v1/enrollments");
request.Headers.Add("Authorization", "Bearer " + AccessToken);
request.Headers.Add("Developer-Id", "Bearer: " + DeveloperId);
request.Method = "POST";
request.ContentType = "application/json";
// adding paremeters
string s = "{\"consumer\":\"" + userHref + "\",\"application\":\"" + App + "\"}";
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
string enrollmentJob = result["href"].ToString();
return enrollmentJob;
}
catch(WebException we)
{
string s = DecodeException(we);
return s;
}
}
如您所见,我们正在将 userHref 或消费者 ID 和 AppModel 作为请求参数发送,并获得一个响应,其中包含一个名为 enrollmentJob 的当前注册过程 ID。在提交作业订单时需要此作业,该订单应包含分析结果。分析需要用户按照说明录制的音频文件。
为了录制音频,我们创建了一个名为 SoundRecorder.cs 的类,它使用 Windows 本机方法进行音频录制。
您可以在任何 Windows 窗体或 WPF 应用程序中使用此类别进行音频录制。
namespace Knurld
{
public class MySoundRecorder
{
[DllImport("winmm.dll")]
private static extern int mciSendString(string MciComando, string MciRetorno, int MciRetornoLeng, int CallBack);
public static bool isPaused = false;
string musica = "";
public static void Start()
{
mciSendString("open new type waveaudio alias Som", null, 0, 0);
var WaveBitsPerSample = 16;
var WaveChannels = 2;
var WaveSamplesPerSec = 44000;
var WaveBytesPerSec = WaveBitsPerSample * WaveChannels * WaveSamplesPerSec / 8;
var WaveAlignment = WaveBitsPerSample * WaveChannels / 8;
string command = "set Som time format ms";
command += " bitspersample " + WaveBitsPerSample;
command += " channels " + WaveChannels;
command += " samplespersec " + WaveSamplesPerSec;
command += " bytespersec " + WaveBytesPerSec;
command += " alignment " + WaveAlignment;
mciSendString(command, null, 0, 0);
mciSendString("record Som", null, 0, 0);
}
public static void Pause()
{
mciSendString("pause Som", null, 0, 0);
}
public static void UnPause()
{
mciSendString("record Som", null, 0, 0);
}
public static void StopAndSave(string fname)
{
mciSendString("pause Som", null, 0, 0);
if (File.Exists(fname))
{
File.Delete(fname);
System.Threading.Thread.Sleep(200);
}
mciSendString("save Som " + fname, null, 0, 0);
mciSendString("close Som", null, 0, 0);
}
}
}
我们观察到采样率设置为 44kHz,因为我们的设备 arecord 仅以 44kHz 录制音频(CD 质量)。我们希望注册和验证音频格式相同。
SoundRecorder.Start() 和 SoundRecorder.Stop("c:\users\Rupam\AppData\Roaming\IntegratedIdeas\IoTBiometric\abc.wav") 是录制开始和停止的对应调用。
请注意,我们正在路径中录制音频。
一个问题是,我们不知道录制属性,例如音量或当前增益(以 dB 为单位)。不幸的是,原生的 SoundRecorder 类不会向 UI 发送任何响应。因此,在 UI 中您得不到任何关于信号变化的提示。
我们创建了一个简单的技巧来显示您录制时音频电平的变化。
我们获取一个 Microsoft SpeechRecognizer 对象,将其设置为听写模式,然后从其事件处理程序中获取信号电平。
private System.Speech.Recognition.SpeechRecognitionEngine speech = new System.Speech.Recognition.SpeechRecognitionEngine();
在 Form_Load() 方法中,我们将其初始化如下
// -- Set the speech synthesizer to use the default audio input device
speech.SetInputToDefaultAudioDevice();
// -- Tell the speech synthesizer to recognize plain speech, not commands.
speech.LoadGrammar(new System.Speech.Recognition.DictationGrammar());
// -- Start recognizing
speech.RecognizeAsync(System.Speech.Recognition.RecognizeMode.Multiple);
通过设置 RecognizeMode.Multiple,我们确保语音对象持续监听音频。
由于所有短语都是不同的英语单词,当您说出它们时,它们将被识别。我们不需要处理已识别的单词,但是当您在 AudioLevelUpdated 事件处理程序中说话时,我们会获得音频电平。
private void speech_AudioLevelUpdated(object sender, System.Speech.Recognition.AudioLevelUpdatedEventArgs e)
{
try
{
pgAudioLevel.Value = e.AudioLevel;
}
catch
{
}
//throw new NotImplementedException();
}
Knurld 和甚至 Microsoft 的 API 的问题之一是,如果您提交相同的 URL 进行验证或注册,端点会拒绝它们。
这意味着,即使我已在一个现有文件名(例如:my.wav)中录制了全新的音频并将其重新上传到 Dropbox,当您与 API 端点共享该链接时,它也会生成错误。这仅仅意味着每个文件名(无论是音频还是图像)都必须是唯一的。
因此,当用户在录制语音后点击“停止”按钮时,我们会根据当前日期和时间生成一个新文件并将其保存在 Path 中。然后我们将操作设置为 DROPBOX_UPLOAD,这会启动 Dropbox 文件上传方法。
if (Mode.Equals("Enrollment"))
{
string n = string.Format("{0:yyyy_MM_dd_hh_mm_ss_tt}", DateTime.Now);
audioFileName = user + "_" + n + "_"+count+"enrollment.wav";
count++;
MySoundRecorder.StopAndSave(frmMain.Path + audioFileName);
tssMessage.Text = "Audio Saved. Uploading to DropBox";
Operation = KnurldOperations.DROPBOX_UPLOAD;
toolStripProgressBar1.Value = 0;
timer1.Enabled = true;
bw.RunWorkerAsync();
}
为了将文件上传到 Dropbox,我们使用 Nemiro.oAuth 类库,这使得上传变得非常容易。
case KnurldOperations.DROPBOX_UPLOAD:
OAuthUtility.PutAsync
(
"https://api-content.dropbox.com/1/files_put/auto/",
new HttpParameterCollection
{
{"access_token", dropboxAccessToken},
{"path","/"},
{"overwrite", "true"},
{"autorename","true"},
{File.OpenRead(frmMain.Path+audioFileName)}
},
callback: Upload_Result
);
break;
路径中的“/”表示音频将保存到您的 Dropbox 根目录。
在 Upload_Result 回调中,我们检查调用的 HTTP 状态。如果状态为 200,则表示文件已成功上传。上传后,我们调用 AudioSharePath() 方法来共享刚刚上传的文件的链接。
private void Upload_Result(RequestResult result)
{
if (this.InvokeRequired)
{
this.Invoke(new Action<RequestResult>(Upload_Result), result);
return;
}
if (result.StatusCode == 200)
{
tssMessage.Text="File Uploaded. Getting Link";
AudioSharepath(audioFileName);
}
else
{
if (result["error"].HasValue)
{
MessageBox.Show(result["error"].ToString(), "Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
else
{
MessageBox.Show(result.ToString(), "Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
AudioSharePath() 必须共享文件的链接,获取链接,将末尾的 dl=0 更改为 dl=1,就像我们之前讨论过的那样,并开始分析过程。回想一下,分析端点必须分析给定的音频并返回一个包含短语开始和结束间隔数组的 JSON 对象。
public void AudioSharepath(string fname)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.dropboxapi.com/2/sharing/create_shared_link");
request.Headers.Add("Authorization", "Bearer " + dropboxAccessToken);
request.Method = "POST";
request.ContentType = "application/json";
string s = "{\"path\":\"" + "/" + fname + "\"}";
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
string url = result["url"].ToString().Replace("dl=0", "dl=1");
labCloud.Text = "\u221A Cloud Storage";
dropboxUrl = url;
//// Once File is Uploaded, submit the url for Analysis///////////////
tssMessage.Text = url;
File.Delete(fname);
toolStripProgressBar1.Value = 0;
timer1.Enabled = true;
tssMessage.Text = "Starting Analysis";
Operation = KnurldOperations.SUBMIT_ANALYSIS;
bw.RunWorkerAsync();
/////////////////////////////////////////////////////////////
}
catch (WebException we)
{
string s= KnurldHelper.DecodeException(we);
MessageBox.Show(s, "Analysis Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
我们从 bw.DoWork 调用 SubmitAudioForAnalysis。
if (Mode.Equals("Enrollment"))
{
result = KnurldHelper.SubmitAudioFileUrlForAnalysis(dropboxUrl,9);
}
分析端点需要 wordCount 作为请求参数之一。
回想一下,对于注册,所有三个短语都必须重复三次。因此,我们传递 9 作为参数。该方法返回一个名为 taskName 字段中的 analysisUrl。它还会返回一个状态,值为“initialized”。程序必须轮询 GetAnalysisStatus 端点,直到它返回状态值“completed”(或 HTTP 错误)。
让我们看看 RunWorkerCompleted() 方法中 GET_ANALYSIS 的处理,其中分析结果可用。
case KnurldOperations.GET_ANALYSIS:
bw.CancelAsync();
if(result.Equals("Processing"))
{
// Keep Polling the GetAnalysisStatus end point till the status is processing
System.Threading.Thread.Sleep(100);
timer1.Enabled = true;
Operation = KnurldOperations.GET_ANALYSIS;
bw.RunWorkerAsync();
return;
}
else if (result.Contains("Error"))
{
MessageBox.Show(result, "Analysis Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
intervals = result;
if (Mode.Equals("Enrollment"))
{
tssMessage.Text = "Analysis Successful. Enrolling";
}
else
{
tssMessage.Text = "Analysis Successful. Verifying";
}
labAudioAnalysis.Text = "\u221A AudioAnalyzed";
//MessageBox.Show(result);
toolStripProgressBar1.Value = 0;
timer1.Enabled = true;
if(Mode.Equals("Enrollment"))
Operation = KnurldOperations.ENROLL;
else
Operation = KnurldOperations.VERIFY;
bw.RunWorkerAsync();
break;
一旦状态完成,我们将结果分配给一个名为 intervals 的局部变量。最后,我们将操作设置为 ENROLL,它调用 KnurldHelper.Enroll() 方法。
注册方法将词汇表中的短语附加,每个重复三次并创建一个有效负载。dropboxUrl 和此有效负载提交用于注册。
public static string Enroll(string enrollmentJob,string intervals,List<string>vocab,string dropboxUrl)
{
try
{
// var responseString = HttpUploadEnrollmentFile(enrollmentJob, fname, "filename", "audio/wav", new NameValueCollection());
var request = (HttpWebRequest)WebRequest.Create(enrollmentJob);
request.Headers.Add("Authorization", "Bearer " + AccessToken);
request.Headers.Add("Developer-Id", "Bearer: " + DeveloperId);
request.Method = "POST";
request.ContentType = "application/json";
// adding paremeters
//listBox1.Items[0].ToString(), listBox1.Items[1].ToString(), listBox1.Items[2].ToString()
string s = "{\"enrollment.wav\":\"" + dropboxUrl + "\" ,\"intervals\":[";
JArray interval = JArray.Parse(intervals);
int n = 0;
for (int i = 0; i < interval.Count - 1 && i < 8; i++)
{
string s1 = "{\"phrase\":\"" + vocab[i / 3] + "\",\"start\":" + interval[i]["start"] + ",\"stop\":" + interval[i]["stop"] + "} ,";
s = s + s1;
n++;
}
int last = (n - 1) / 3;
if (last >= 3)
{
last = 2;
}
string s2 = "{\"phrase\":\"" + vocab[last] + "\",\"start\":" + interval[interval.Count - 1]["start"] + ",\"stop\":" + interval[interval.Count - 1]["stop"] + "}] }";
s = s + s2;
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
string enrollmentUrl = result["href"].ToString();
return enrollmentUrl;
}
catch (WebException we)
{
string s = DecodeException(we);
return s;
}
catch (IndexOutOfRangeException ie)
{
return "Error :- Phrases were not extracted properly in Audio.\nRecord Again";
}
catch (ArgumentOutOfRangeException aoe)
{
return "Error :- Not all the phrases were extracted. Please try again";
}
}
在处理操作 ENROLL 的 RunWorkerAsync() 部分,一旦注册成功,我们将注册 URL 写入 Path/enrollment.txt,并通过 MqTT 发送带有 : 分隔符的 "consumerUrl" 字符串,当我们的设备(储物柜)收到时,该字符串会更新到设备存储中。该 URL 用于设备验证。
case KnurldOperations.ENROLL:
if (!result.Contains("Error"))
{
Operation = KnurldOperations.NONE;
timer1.Enabled = false;
toolStripProgressBar1.Value = 0;
string enrollmentStatus = result;
tssMessage.Text = "Enrolled";
labComplete.Text = "\u221A Completed";
File.WriteAllText(frmMain.Path + "enrollment.txt", enrollmentUrl);
MessageBox.Show("Enrollment Suucessful");
frmMain.mc.Publish(frmMain.topic,frmMain.GetBytesForEdison("consumerUrl#"+File.ReadAllText(frmMain.Path+"consumer.txt")));
btnDoneCancel.Text = "Done";
btnDoneCancel.Image = Image.FromFile("Ok.png");
}
else
{
MessageBox.Show(result, "Enrollment failed", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
break;
这就是我们的 frmVoice 和注册过程的结束。建议您在分析代码时保持 CURL 请求打开。KnurldHelper 是 KnurldAPI 调用的一个包装器。您可以将该类与 SoundRecorder 和 Dropbox 方法一起使用,以将语音识别服务与任何应用程序集成。
注册用户语音后,我们现在将重点转向人脸 API。人脸 API 相对简单,只有四个总体调用:检测、照片上传、链接共享和验证。验证在设备端实现。所以你实际上只使用了三个 API 调用。在这三个调用中,你已经为两个 Dropbox 调用开发了方法。因此,在 PC 应用程序中使用人脸 API 实际上是通过调用 faceDetection 端点并获取 faceID,然后将该 ID 传递给我们的设备。
自动调整录音音量
即使实施了 Knurld API 相当复杂的流程,您在注册和验证过程中仍可能遇到一些问题。这些问题大多源于不正确的录音音量和增益水平。因此,在这个项目中,我实现了一个自动调整录音音量的逻辑。
经过几个小时的反复试验,我发现 70% 的录音音量最适合 Knurld 服务,此时增益必须为 0 dB。设置正确的音频电平绝不能留给最终用户。从用户体验的角度来看,这绝不是一个好主意。因此,我们需要一些方法来连接主音量服务并从应用程序程序中进行调整。回想一下,我们已经破解了 Speechrecognization 的 AudioLevelUpdated() 事件处理程序来获取当前音频电平。我们现在需要做的就是将所需值与主录音音量挂钩。
我们使用 Naudio,一个低级音频 DSP 助手来完成此任务。
#region Naudio
try
{
//Instantiate an Enumerator to find audio devices
NAudio.CoreAudioApi.MMDeviceEnumerator MMDE = new NAudio.CoreAudioApi.MMDeviceEnumerator();
//Get all the devices, no matter what condition or status
NAudio.CoreAudioApi.MMDeviceCollection DevCol = MMDE.EnumerateAudioEndPoints(NAudio.CoreAudioApi.DataFlow.All, NAudio.CoreAudioApi.DeviceState.All);
//Loop through all devices
foreach (NAudio.CoreAudioApi.MMDevice dev in DevCol)
{
try
{
if (dev.DataFlow.Equals(NAudio.CoreAudioApi.DataFlow.Capture))
{
//Get its audio volume
System.Diagnostics.Debug.Print("Volume of " + dev.FriendlyName + " is " + dev.AudioEndpointVolume.MasterVolumeLevel.ToString());
Slider1.Value=(int)(dev.AudioEndpointVolume.MasterVolumeLevelScalar*100);
}
}
catch (Exception ex)
{
//Do something with exception when an audio endpoint could not be muted
System.Diagnostics.Debug.Print(dev.FriendlyName + " could not be muted");
}
}
}
catch (Exception ex)
{
//When something happend that prevent us to iterate through the devices
System.Diagnostics.Debug.Print("Could not enumerate devices due to an excepion: " + ex.Message);
}
#endregion
NAudio.CoreAudioApi.MMDeviceEnumerator 提供了所有已安装音频设备的枚举。我们遍历设备并分析设备的 DataFlow 字段。录音设备的类型将是 NAudio.CoreAudioApi.DataFlow.Capture。因此,我们将 AudioEndpointVolume.MasterVolumeLevelScalar 值与我们表单中的 Slider1 挂钩。由于 PC 音量以百分比显示,而 Naudio 设备以分数返回音量,因此我们将音量乘以 100 以获得百分比。
现在我们只需从 AudioLevelUpdated() 事件处理程序更改此音量。
当峰值电平超过 70 时,我们需要降低它;当峰值电平低于 30-40 时,我们需要提高它。
private void speech_AudioLevelUpdated(object sender, System.Speech.Recognition.AudioLevelUpdatedEventArgs e)
{
try
{
pgAudioLevel.Value = e.AudioLevel;
// -- If the volume is over 70% loud, knock the slider down a bit
// which will in turn drop the record level
if ((e.AudioLevel > 70))
{
Slider1.Value -= 8;
}
// -- Keep track of the peak level for this sentence.
if ((e.AudioLevel > peakLevel))
{
peakLevel = e.AudioLevel;
}
}
catch
{
}
//throw new NotImplementedException();
}
peakLevel 在 Recognized 方法中更新。
private void speech_SpeechRecognized(object sender, System.Speech.Recognition.SpeechRecognizedEventArgs e)
{
if ((peakLevel < 20))
{
if(Slider1.Value+15<100)
Slider1.Value += 15;
}
// -- Reset the peak level
peakLevel = 0;
//throw new NotImplementedException();
}
所以,每当 Windows SpeechRecognizer 检测到音频时,你都在设置滑块值以优化录音音量。
现在你所要做的就是从你的滑块值更改事件处理程序中,将新值分配给音频捕获设备的主音量。
void Slider1_ValueChanged(object sender, EventArgs e)
{
//Instantiate an Enumerator to find audio devices
NAudio.CoreAudioApi.MMDeviceEnumerator MMDE = new NAudio.CoreAudioApi.MMDeviceEnumerator();
//Get all the devices, no matter what condition or status
NAudio.CoreAudioApi.MMDeviceCollection DevCol = MMDE.EnumerateAudioEndPoints(NAudio.CoreAudioApi.DataFlow.All, NAudio.CoreAudioApi.DeviceState.All);
//Loop through all devices
foreach (NAudio.CoreAudioApi.MMDevice dev in DevCol)
{
try
{
if (dev.DataFlow.Equals(NAudio.CoreAudioApi.DataFlow.Capture))
{
//Get its audio volume
System.Diagnostics.Debug.Print("Volume of " + dev.FriendlyName + " is " + dev.AudioEndpointVolume.MasterVolumeLevel.ToString());
dev.AudioEndpointVolume.MasterVolumeLevelScalar = (float)Slider1.Value/100.0f;
System.Diagnostics.Debug.Print(dev.AudioEndpointVolume.MasterVolumeLevel.ToString());
}
}
catch (Exception ex)
{
//Do something with exception when an audio endpoint could not be muted
System.Diagnostics.Debug.Print(dev.FriendlyName + " could not be muted");
}
}
}
就是这样!
现在您的用户可以使用语音生物识别系统,而无需担心录音音量、电平、音频。该系统成为即插即用的生物识别系统,将优化调整音频属性以产生最佳的语音识别结果。

回想一下,在我们的 frmMain 中有一个名为 ProcessFrame 的事件,它获取实时摄像头输入,检测人脸并将其显示在图片框中。当您点击“注册人脸”时,图像会放入 frmFace 的图片框中。在此表单中,当您点击“注册”按钮时,将进行人脸注册。
正如我们之前提到的,人脸注册在此处纯粹是象征性的。我们所做的基本上是调用 MCS 人脸 API 的人脸检测端点。它返回一个 ID(参见上图中的红色矩形标记)。我们将此 ID 本地保存并发送到设备,设备将其作为参考人脸存储。
逻辑是 -> 存储照片 -> 上传到 DropBox -> 获取链接 -> 调用人脸检测服务 -> 保存人脸 ID。
private void button1_Click(object sender, EventArgs e)
{
//1. Save the image Locally
imagePath=Knurld.KnurldHelper.Path + name + "_" + mode + ".jpg";
picMainImage.Image.Save(imagePath, System.Drawing.Imaging.ImageFormat.Jpeg);
//2. Upload that to Dropbox
UploadImageInDropbox();
//3. After image is uploaded, get a link and from that method call face detection
}
UploadImageInDropbox() 的功能与我们用于 Knurld 的功能类似。将其编写为单独方法的逻辑是为了隔离音频和图像上传的逻辑。两种结果的回调方法会导致不同的操作集。
public void UploadImageInDropbox()
{
// Extract filename from path;
string[] parts = imagePath.Split(new char[] { '\\' });
imagePathAbsolute = parts[parts.Length - 1];
// Dropbox path
dropBoxPath = "/Apps/IoT/";
OAuthUtility.PutAsync
(
"https://api-content.dropbox.com/1/files_put/auto/",
new HttpParameterCollection
{
{"access_token", dropboxAccessToken},
{"path",dropBoxPath+imagePathAbsolute},
{"overwrite", "true"},
{"autorename","true"},
{File.OpenRead(imagePath)}
},
callback: Upload_Result
);
我在我的 Dropbox 根目录中创建了一个名为 Apps 的新文件夹,并在其中创建了另一个名为 IoT 的文件夹。我正在将图像放入 IoT 文件夹中。您可以随意将图像放入根目录或任何其他 Dropbox 文件夹中。
从 upload_Result 中,我们调用另一个名为 ImageSharepath 的方法,在该方法中,上传的文件被共享,其链接被获取,末尾的 dl=0 被替换为 dl=1,并且调用人脸检测 API。
if (result.StatusCode == 200)
{
tssMessage.Text = "File Uploaded. Getting Link";
ImageSharepath(imagePathAbsolute);
}
让我们完整地看看 ImageSharepath 方法。
public void ImageSharepath(string fname)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.dropboxapi.com/2/sharing/create_shared_link");
request.Headers.Add("Authorization", "Bearer " + dropboxAccessToken);
request.Method = "POST";
request.ContentType = "application/json";
string s = "{\"path\":\"" + dropBoxPath + fname + "\"}";
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
string url = result["url"].ToString().Replace("dl=0", "dl=1");
//labCloud.Text = "\u221A Cloud Storage";
dropboxUrl = url;
//// Once File is Uploaded, submit the url for Analysis///////////////
tssMessage.Text = url;
//File.Delete(fname);
toolStripProgressBar1.Value = 0;
/////////////Now Submit for Face Detection////////////////////////////////////////////////
result = OxfordApiHelper.FaceDetection(dropboxUrl, ocpKey);
System.Drawing.Bitmap bmp = Bitmap.FromFile(imagePath) as System.Drawing.Bitmap;
using (Graphics g = Graphics.FromImage(bmp))
{
for (int i = 0; i < result.Count; i++)
{
int left=(int)result[i]["faceRectangle"]["left"];
int top=result[i]["faceRectangle"]["top"];
int width = (int)result[i]["faceRectangle"]["width"];
int height=(int)result[i]["faceRectangle"]["height"];
Rectangle rect = new Rectangle(left, top, width, height );
g.DrawRectangle(new Pen(new SolidBrush(Color.Green), 2), rect);
labInfo.Text = result[i]["faceId"];
string gender = result[i]["faceAttributes"]["gender"];
g.DrawString(gender, new Font("Tahoma", 7), new SolidBrush(Color.White), rect.X, rect.Y - 15);
}
}
picMainImage.Image = bmp;
/////////////////// Face Registration//////////////////////
if (mode.Equals("Enrollment"))
{
File.WriteAllText(KnurldHelper.Path + "faceId.txt", labInfo.Text);
frmMain.mc.Publish(frmMain.topic,frmMain.GetBytesForEdison("faceId#"+labInfo.Text));
MessageBox.Show(name + "'s face enrolled");
}
/////////////////////////////////////////////////////////////
////////////////// Face Verification/////////////////////
else
{
try
{
var faceId1 = File.ReadAllText(KnurldHelper.Path + "faceId.txt");
var faceId2 = labInfo.Text;
dynamic res = OxfordApiHelper.FaceVerification(faceId1, faceId2, ocpKey);
string isIdentical=res["isIdentical"];
double confidence = (double)res["confidence"];
if (isIdentical == "True" && confidence > .5)
{
MessageBox.Show("verified",confidence.ToString());
}
else
{
MessageBox.Show("Not Verified",confidence.ToString());
}
}
catch(WebException we)
{
}
// compare this ID with Existing ID in verification
}
}
/////////////////////////////////////////////////////
catch (WebException we)
{
string s = KnurldHelper.DecodeException(we);
MessageBox.Show(s, "Analysis Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
就像 KnurldHelper 一样,我为访问 OxfordAIApis 编写了另一个 Helper 类,名为 OxfordApiHelper。
它的 FaceDetection() 方法使用照片的 dropboxUrl 和 API 密钥调用。该助手有两个方法:FaceDetection() 和 FaceVerification()。尽管我们的 Locker 项目不需要在 PCApp 中进行验证,但我添加了它以提供完整的人脸验证功能。您还可以通过提供您第一次调用 FaceDetection() 时获得的人脸 ID 以及第二次调用相同(第二次调用是验证调用)的人脸 ID 来测试验证是否有效。
让我们仔细看看注册过程。当获得人脸检测响应时,我们将其存储在一个文件中并发送到设备。这就是我们作为注册过程需要做的全部。
if (mode.Equals("Enrollment"))
{ File.WriteAllText(KnurldHelper.Path + "faceId.txt", labInfo.Text); // Saving locally
frmMain.mc.Publish(frmMain.topic,frmMain.GetBytesForEdison("faceId#"+labInfo.Text)); // to -> Locker device
MessageBox.Show(name + "'s face enrolled");
}
我们先看看 FaceDetection() 方法。
public static dynamic FaceDetection(string dropboxUrl,string ocpKey)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.projectoxford.ai/face/v1.0/detect?returnFaceId=true&returnFaceLandmarks=true&returnFaceAttributes=age,gender,smile");
var postData = "{\"url\":\"" + dropboxUrl+"\"}";//94CtiIKAyjhZAvJhT4X6RJIOxXY80hAw
var data = Encoding.ASCII.GetBytes(postData);
request.Method = "POST";
request.ContentType = "application/json";
request.ContentLength = data.Length;
request.Headers.Add("Ocp-Apim-Subscription-Key", ocpKey);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JArray.Parse(responseString);
return result;
}
catch (WebException we)
{
throw we;
}
}
现在,理解这个方法的逻辑对你来说应该不再困难了。你已经知道如何调用 API 端点。只需将端点用作请求 URL,就像我们使用 https://api.projectoxford.ai/face/v1.0/detect?returnFaceId=true 一样。
然后您提及请求类型,在这种情况下是 POST。
几乎所有 API 的有效载荷都是 JSON。将共享图片链接放入 JSON 格式并将其转换为二进制数据。将 API 密钥放入请求头并调用端点。将响应消耗到动态变量中,然后解析结果 JSON 对象(或数组)以提取字段。
然后我们解析并提取 faceID 字段,并将其存储在由 KnurldHelper 的 Path 属性指定的目录中。
我们再来看看验证方法,了解人脸验证的逻辑。这将使人脸验证在设备上的实现变得更简单。
API 端点接收两个 faceID 进行验证。faceId1 是参考 ID,faceId2 是测试 ID。
public static dynamic FaceVerification(string faceId1, string faceId2,string ocpKey)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.projectoxford.ai/face/v1.0/verify");
var postData = "{\"faceId1\":\"" + faceId1 + "\",\n\"faceId2\":\""+faceId2+"\"}";//94CtiIKAyjhZAvJhT4X6RJIOxXY80hAw
var data = Encoding.ASCII.GetBytes(postData);
request.Method = "POST";
request.ContentType = "application/json";
request.ContentLength = data.Length;
request.Headers.Add("Ocp-Apim-Subscription-Key", ocpKey);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
return result;
}
catch (WebException we)
{
throw we;
}
}
}
让我们再次回顾 ImageSharepath,看看结果是如何处理的。
try
{
var faceId1 = File.ReadAllText(KnurldHelper.Path + "faceId.txt");
var faceId2 = labInfo.Text;
dynamic res = OxfordApiHelper.FaceVerification(faceId1, faceId2, ocpKey);
string isIdentical=res["isIdentical"];
double confidence = (double)res["confidence"];
if (isIdentical == "True" && confidence > .5)
{
MessageBox.Show("verified",confidence.ToString());
}
else
{
MessageBox.Show("Not Verified",confidence.ToString());
}
}
catch(WebException we)
{
}
我们需要分析 faceVerification 端点的 JSON 响应中的两个字段:IsIdentical 和 confidence。confidence 是相似度百分比,isIdentical 显示 OxfordAI 是否认为这两张照片相似。
我经过类似人脸测试后,使用了 0.5 的阈值。欢迎您根据应用程序的安全敏感性使用自己的阈值。
7.1.4 在 C# 中调用云服务的通用方法
本节不属于我撰写的实际文章。但阅读 C# PC 应用程序部分后,我想,也许我犯了一个错误,没有在开始编写代码之前详细阐述调用云服务的通用设计策略。所以,我正在添加这一节。这将像一个模板,您可以直接使用它来访问任何类型的云服务。
- 步骤 1 注册和 API 密钥:当您向云服务提供商注册时,它将实质上为您提供一个访问 API 的密钥。我们称之为 KEY。在许多服务中,它是一对客户端 ID 和客户端密钥。
- 步骤 2 oAuth:通常,每个云服务提供商都提供一组 API 服务。这些服务中的每一个都需要一个访问令牌。访问令牌是一个长编码字符串,其中嵌入了所有权限和作用域以及一个私钥。访问云服务提供商 API 的第二步是生成访问令牌。一些服务提供商允许直接从其网站的 API 资源管理器生成访问令牌(例如 Dropbox),一些服务提供商不需要显式访问令牌,它们是从提供的 API 密钥内部生成的(例如 OxfordAI API),一些服务提供商需要显式访问令牌才能访问其服务(例如 Knurld)。在这些情况下,服务提供商提供一个用于生成访问令牌的 URL,这可以通过编程方式完成。
- 一些服务提供商需要用户明确授权某些功能(例如 Facebook 或 Google)。在这种情况下,URL 通常会将用户带到一个网页,其中显示了应用程序正在请求的一组权限。这种访问令牌的生成必须通过应用程序中的嵌入式 Web 客户端(例如 .net 中的 WebBrowser 控件)执行。当用户接受服务并授予权限时,URL 会重定向到一个空白页面,其中访问令牌本身嵌入在 URL 中。您可以使用 Navigated 事件处理程序读取 URL 数据并解析访问令牌。
- 步骤 3 调用 API:每个 API 都将具有以下通用结构 https://<服务提供商域名>/vn/endpoint。其中 vn 是 API 版本,目前通常是 v1 或 v2。端点类似于您从程序中调用的 Web 方法或远程函数。每个云服务提供商都将拥有其 API 文档,其中将指定 curl 请求格式(例如,参见 Knurld 创建应用程序模型的 curl)。API 调用的通用结构如下所示。
Content-Type: 在大多数情况下是 application/json。其他类型由 API 文档指定。
URL: URL 是上面提到的完整端点 URL 结构,例如 https://abc.com/v1/foo
表单参数或 URL 参数:这些是您多年来一直使用的传统表单数据。它们需要通过在 URL 后面加一个 ?,然后是参数名称,然后是 =,然后是值来指定。多个参数用 & 分隔。例如
https://abc.com/v1/foo?username=rupam&password=rupam
方法:它们主要有两种类型:POST 和 GET
头部:这些是要添加到请求头部中的字段。这通常在 curl API 调用中使用 -H 选项指定。
有效载荷:几乎大多数云服务提供商的 API 都使用 JSON 结构。有效载荷通常在 curl 请求模式中用 -d(或 data)指定。其通用结构是:{"Name":"Value","Age":23,"Degrees":[ {"year":1996, "Course":"SSLC","Marks":96},{"year":1998,"Course":"PUC","Marks":78}]}
注意使用 " (双引号) 。 JSON 要求字段名称和字符串或日期值用双引号括起来。因此,在 C# 编程时,您必须使用正确的转义序列。
例如
string payload="{\"Name\":\"Value\",\"Age\":23,\"Degrees\":[ {\"year\":1996, \"Course\":\"SSLC\",\"Marks\":96},{\"year\":1998,\"Course\":\"PUC\",\"Marks\":78}]}"
创建有效载荷或数据字符串后,建议将其打印到文件或控制台,将文本复制到 在线 JSON 解析器 中以验证您的 JSON。在 C# 中,此数据需要转换为二进制值。
响应:API 调用的 HttpResponse 将返回一个数字。如果调用成功,它将是 HTTP 200。否则,响应将包含一个错误号,如 401/500 等,以及一个也为 JSON 格式的错误响应。这些异常最好由 WebException 类处理。通用 Exception 类无法捕获这些异常。API 调用通常返回一个有效的 JSON 字符串作为响应。您可以将结果捕获到动态变量中,然后解析 JSON 格式。
我再次发布我们的 KnurlHelper 方法,您可以将其作为参考方法来调用几乎所有云服务;
#region Registration and User/consumer related Apis
/// <summary>
/// This method registers a user and return the user specific URL called Consumer.
/// There is no validation at the server side. So you must handle the validation in your code
/// For instance check for blank username or password and so on.
/// </summary>
/// <param name="username">Unique username</param>
/// <param name="password">password of any length/format/alpha numeric</param>
/// <param name="gender">Gender M or F</param>
/// <returns>consumer if registration is successfull else return error</returns>
public static string RegisterUser(string username, string password,string gender)
{
try
{
var request = (HttpWebRequest)WebRequest.Create("https://api.knurld.io/v1/consumers");
request.Headers.Add("Authorization", "Bearer " + AccessToken);
request.Headers.Add("Developer-Id", "Bearer: " + DeveloperId);
request.Method = "POST";
request.ContentType = "application/json";
// adding paremeters
string s = "{\"username\":\"" + username + "\",\"gender\":\"" + gender + "\",\"password\":\"" + password + "\"}";
var postData = s;
var data = Encoding.ASCII.GetBytes(postData);
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
dynamic response = (HttpWebResponse)request.GetResponse();
var responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseString);
var consumer = result["href"].ToString();
return consumer;
}
catch (WebException we)
{
string responseError = new StreamReader(we.Response.GetResponseStream()).ReadToEnd();
dynamic result = JObject.Parse(responseError);
string s = "";
if (result.ToString().Contains("fault"))
{
s = "Error :-" + result["fault"]["faultstring"] + "\n" + result["fault"]["detail"]["errorcode"].ToString();
}
else if (result.ToString().Contains("message"))
{
s = s + "Error :- " + result["message"];
}
else
{
s = result["ErrorCode"] + "\n" + result["Error"];
}
return s;
}
}
我希望这个新增的部分能为您(尤其是初学者)理解和使用来自不同服务提供商的不同 API 提供指导。
章节总结
好了,我们的 PC APP 就到此结束了。现在让我们回顾一下您在 C# 中构建的 PC APP 具有哪些功能。
- KnurldHelper 用于抽象 Knurld 的语音生物识别 API 调用
- OxforApiHelper 用于 OxforAiApi 的人脸检测和人脸验证
- Dropbox 文件上传和文件共享
- 自动设置音频音量以实现最佳语音识别性能
- 基于 Emgu CV 的本地人脸检测,以指导用户是否正确识别摄像头中的人脸
- 基于 Knurld 的用户账户管理器
- MqTT 协议栈用于建立 PC 应用与设备应用之间的通信。
您可以从这里下载 C# PC 应用程序:C# 语音人脸生物识别 MqTT 储物柜
接下来,我们将进入开发的最后一个阶段,我们将使用 Intel XDK IoT 版本中的 Node.js 构建 IoT 设备应用程序。设备应用程序的作用是实现语音和人脸验证,并在两次验证都成功时触发伺服电机控制的储物柜。
7.2 物联网设备应用
我们终于进入了本教程/文章/项目(您想怎么称呼它都行)的最后阶段。在本教程的过程中,您已经学习了如何设置硬件、设置开发环境,并对一些迷你项目有了信心。然后您分析了设计。了解了生物识别系统的一般原理,特别是语音和人脸生物识别。您了解了云服务以及 Knurld 和 Microsoft 分别如何提供基于云的语音和人脸生物识别。您还学习了如何创建一个有效的 PC 设置应用程序来控制用户管理。
然而,这一切都归结到设备。如果计划中的设备运行不佳,那么一切努力都将付诸东流。然而,多亏了像 Intel XDK 这样出色的 IoT IDE,现在构建设备应用程序变得相当简单。我们已经在我们的迷你项目中学习了一些基本的 Node.js IoT 编码,适用于 Intel Edison。但是,在设备中集成实时云服务通常非常困难。
我们直接进入编码环节。
我们初始化硬件变量:sw、servo 和 LCD,并将舵机复位到 0'。
var five = require("johnny-five");
var Edison = require("edison-io");
var LCD = require('jsupm_i2clcd');
var myLCD = new LCD.Jhd1313m1(6, 0x3E, 0x62);
var fs = require('fs');
var faceId='';
var faceId1='';
var mraa=require('mraa');
var sw=new mraa.Gpio(4);
//var consumerUrl="https://api.knurld.io/v1/consumers/ecd1003f382e5a3f544d2f1dcf790d4e"
var consumerUrl='';
sw.dir(mraa.DIR_IN);
var board = new five.Board({
io: new Edison()
});
var servo = new five.Servo({
pin:5
});
servo.to(0);
myLCD.setCursor(0,0);
myLCD.setColor(255,0,0);
myLCD.write("BiometricCashBox");
myLCD.setCursor(1,0);
myLCD.write('CLOSE');
var angle=0;/// Lock closed<---------
设备应用-PC 应用通过 MqTT 进行消息交换
回想一下,PC 应用程序通过监听设备应用程序周期性的“hello”消息来连接设备。还记得 PC 应用程序配置的消息是“Connected XYZ”吗?因此,设备每 5 秒生成一次“Connected CahBox”消息到 MqTT 通道,PC 应用程序订阅了该通道。
PC 应用程序向设备应用程序发送两个信息:consumerUrl(当用户注册时)和人脸注册后的人脸 ID。这些值需要由设备应用程序保存在文件系统中。
///////////////===================MqTT Setup==========================================
var mqtt = require('mqtt');
var mqttClient = mqtt.connect('mqtt://iot.eclipse.org');
mqttClient.subscribe('rupam/CashBox/#')
var topic='rupam/CashBox';
mqttClient.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString();
console.log('Mqtt==>'+payload);
if(payload.indexOf('hello')>-1)//PC's hello message
{
hello();
}
if(payload.indexOf('faceId')>-1)
{
var arr=payload.split('#');
faceId=arr[1];
faceId1=faceId;
/// write back into file////////////////
fs.writeFile("/home/root/faceId.txt", faceId, function(err) {
if(err)
{
return console.log(err);
}
console.log("faceID:"+ faceId1+" is saved");
});
////////////////////////////////
}
if(payload.indexOf('consumerUrl')>-1)
{
var arr=payload.split('#');
consumerUrl=arr[1];
/// write back into file////////////////
fs.writeFile("/home/root/consumerUrl.txt", consumerUrl, function(err) {
if(err)
{
return console.log(err);
}
console.log("consumerUrl:"+ consumerUrl+" is saved");
});
////////////////////////////////
}
cb()
}
setTimeout(hello,5000);
function hello()
{
mqttClient.publish(topic,'Connected Cashbox')
//setTimeout(hello,1000);
}
///////===========================================================
BoxOpen 和 BoxClose
我们定义了两个方法:BoxOpen() 和 BoxClose(),用于打开和关闭储物柜。BoxClose() 相当直接。当函数被调用时,我们通过检查舵机角度来检查箱子是否已经关闭。如果角度是 90',这意味着储物柜已经关闭。否则,我们调用 servo.to(90) 来关闭箱子。
然而,储物柜的开启受生物识别安全保护。回想一下,我们需要先在设备中验证人脸。注意,当调用 BoxOpen() 函数时,我们调用另一个名为 faceModule 的方法。但我们设置了 3 秒的延迟,这是必要的,以便 PC 应用程序处理 MqTT 消息并合成语音指令。
function BoxClose()
{
if(angle!=90)
{
mqttClient.publish(topic,'Box closed');
console.log('Switch Released')
angle=90; //Door Close
servo.to(90);
myLCD.setCursor(1,0);
myLCD.setColor(0,255,0);
myLCD.write('CLOSE');
}
}
function BoxOpen()
{
if(angle!=0)
{
mqttClient.publish(topic,'Box open initiated');
mqttClient.publish(topic,'Please smile. Your Photo will be captured in 2 seconds')
setTimeout(faceModule,3000);
console.log('Switch Pressed')
myLCD.setColor(220,20,0);
myLCD.setCursor(1,0);
myLCD.write("SW Pressed")
angle=0;// Door Open
/*
angle=0;// Door Open
servo.to(0);
myLCD.setCursor(1,0);
myLCD.setColor(255,0,0);
myLCD.write('OPEN');
*/
}
}
人脸验证
现在让我们看看 faceModule 是如何工作的
//========================Face Methods=============================================
var dropboxAccessToken='<my dropbox access token>';
var ocpKey = '<my oxford ai subscription key>';
var childProcess = require('child_process');
//--------------------------------------------------------------
function faceModule()
{
/// First check if the customer's face is registered or not... if not prompt to register////home/root/faceId.txt///////////
fs.readFile('/home/root/faceId.txt', 'utf8', function (err,data) {
if (err)
{
myLCD.setCursor(1,0);
myLCD.write('No face regstrd')
mqttClient.publish(topic,'Please register your face first')
angle=90;// face database not preset
return console.log(err);
}
console.log('faceId='+data);
faceId=data;
faceId1=faceId;
});
//////////////////////////////////////////////////////////////////////////////////////
if(faceId1.length>2)
{
myLCD.setColor(200,40,0);
myLCD.setCursor(1,0);
myLCD.write("Photo Capturing")
var imageName = (new Date).getTime() + ".png";
childProcess.exec('fswebcam -F 30 ' + '/home/root/'+imageName, function(error, stdout, stderr)
{
myLCD.setColor(180,60,0);
myLCD.setCursor(1,0);
myLCD.write("Photo Taken")
mqttClient.publish(topic,"Photo Capture Completed. Uploading to Cloud")
upload(imageName);
if(error!=null)
{
console.log('stdout: ' + stdout);
}
else{
console.log('Error'+stderr);
}
});
}
}
- 步骤 1 从文件系统读取 faceId:如果出错,通知没有注册人脸。否则,记录 faceId 并将其存储在一个名为
faceId1的变量中(根据 OxfordAI API,faceId1 是注册 ID)。
fs.readFile('/home/root/faceId.txt', 'utf8', function (err,data) {
if (err)
{
myLCD.setCursor(1,0);
myLCD.write('No face regstrd')
mqttClient.publish(topic,'Please register your face first')
angle=90;// face database not preset
return console.log(err);
}
console.log('faceId='+data);
faceId=data;
faceId1=faceId;
});
- 步骤 2 创建用于捕获的图像名称:通过根据当前时间创建动态字符串,生成将由相机捕获的照片文件名。
var imageName = (new Date).getTime() + ".png";
- 步骤 3 捕获用户照片:这一部分需要稍微详细说明。回想一下 Edison 的摄像头照片捕获部分,我们可以通过在命令行调用
fswebcam来拍摄快照。在同一部分中,我们讨论了捕获单个帧效率低下,您需要捕获更多帧才能获得高质量图片。还记得吗?但问题是,那是命令行,而我们现在在 Node.js 中。那么如何捕获照片呢?别担心。Node.js 的 child_process npm 模块让您能够从 Node.js 程序中调用任何 Unix 系统调用。现在,捕获照片就像调用child_process.exec()使用fswebcam一样简单。
childProcess.exec('fswebcam -F 30 ' + '/home/root/'+imageName, function(error, stdout, stderr)
- 步骤 4:上传到云端:照片捕获后,通过调用
upload()函数并传入保存在imageName变量中的捕获图像的绝对路径,将照片上传到云端。同时生成 MqTT 消息。
mqttClient.publish(topic,"Photo Capture Completed. Uploading to Cloud")
upload(imageName);
Dropbox 上传必须将文件上传到 Dropbox 目录,然后共享文件链接。链接的 dl=0 必须更改为 dl=1,并且应该将其用于人脸检测终点。
我们使用一个名为 dropbox-upload 的 npm 模块将文件上传到 Dropbox /Apps/IoT 文件夹。不幸的是,这个模块只执行文件上传,不支持其他 Dropbox API。其他 Dropbox npm 模块支持不同的 API,但不包括文件上传。所以我们需要两个不同的模块来上传和共享链接。我们使用 npm 模块 dropbox 来共享文件的链接。
结果被捕获到一个名为 link 的变量中。我们将 dl=0 替换为 dl=1,并将最终的照片远程 URL 存储为 dropboxUrl。
/////////////////////// Dropbox Uploading/////////
function upload(fname)
{
var uploadFile = require('dropbox-upload');
console.log('Uploading '+fname +' to /Apps')
uploadFile('/home/root/'+fname,'/Apps/IoT',dropboxAccessToken,function()
{
console.log('uploaded-----------------');
myLCD.setColor(160,80,0);
myLCD.setCursor(1,0);
myLCD.write("Photo Uploaded")
//////////////// Generating photo Link///////////////////////////////
console.log('sharing........ /Apps/IoT/'+fname);
var Dropbox = require('dropbox');
var dbx = new Dropbox({ accessToken: dropboxAccessToken });
dbx.sharingCreateSharedLink({path: '/Apps/IoT/'+fname})
.then(function(response)
{
console.log(response);
var link=response["url"].toString().replace("dl=0","dl=1");
console.log('Your Image link-------->\n'+link);
/// resetting angle////////////
angle=90;
///////////////////////////////
dropboxUrl=link;
///////////// Once File is uploaded go for analysis
faceDetection(dropboxUrl);
}
)
}
);
}
- 步骤 5 使用 faceDetection 模块检测人脸:上传完成后,imageName 的 Dropbox usrl 在 dropboxUrl 变量中可用,它被传递给 faceDetection 模块以获取 faceId2,然后用于验证。faceDetection 函数使用另一个流行的 Node.js npm 模块 restler。restler 有助于使 REST API 调用更容易。观察实现。它类似于 通用 API 调用部分 和 C# 实现。观察对 url 端点 https://api.projectoxford.ai/face/v1.0/detect 的调用。Ocp 密钥或订阅密钥作为头部传递。Content-type 设置为 application/json。当 faceDetection 结果可用时,调用 .on('complete',function(data)) 内联函数,其中 data 是人脸检测端点返回的 JSON 响应。由于 OxfordAI 的人脸检测是一个多面部检测系统,faceId 和属性作为数组返回。在我们的储物柜案例中,它是一个单用户系统。所以我们通过访问 data[0] 获取第一个检测到的人脸。faceId 存储检测到的人脸 ID,需要与存储的人脸 ID 进行验证。
function faceDetection(dropboxUrl)
{
var rest = require('restler');
payload='{"url":"'+ dropboxUrl+'"}';
console.log(payload+' inside faceDetection')
rest.post('https://api.projectoxford.ai/face/v1.0/detect',
{
headers: {
'Ocp-Apim-Subscription-Key': ocpKey ,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data) {
try{
console.log(data);
faceId=data[0]['faceId'];
console.log('-------- The Face Id is ----------\n'+faceId)
mqttClient.publish(topic,'Your face detected. Verifying now.')
faceVerify(faceId);
myLCD.setColor(140,100,0);
myLCD.setCursor(1,0);
myLCD.write("face detected")
}
catch(error)
{
console.log(error);
mqttClient.publish(topic,'Sorry! your face was not detected in image. Look steady in front of camera and press switch to retry')
myLCD.setColor(255,00,0);
myLCD.setCursor(1,0);
myLCD.write("face nt detected")
}
});
}
步骤 6 人脸验证:从 faceDetection 函数获得的人脸 ID 被发送到 faceVerify 函数,该函数将该值作为 faceId2 消耗。然后它调用 OxfordAI API 的 faceVerify 端点以获取 confidence 和 isSimilar。如果 confidence > .5 并且 isSimilar 为 true,我们就验证用户。同样,端点使用 restler 调用。
//////////////////// Face Recognition//////////////
function faceVerify(faceId2)
{
// var faceId1='13aca951-7c5c-4ef2-8595-f23dd255c096' // This is static, needs a dynamic way to send to Edison App
var rest = require('restler');
payload='{"faceId1":"'+ faceId1+'", "faceId2":"'+faceId2+'"}';
console.log(payload+' inside faceVerify')
rest.post('https://api.projectoxford.ai/face/v1.0/verify',
{
headers: {
'Ocp-Apim-Subscription-Key': ocpKey ,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data) {
console.log(data);
try{
var confidence=data['confidence'];
var isIdentical=data['isIdentical'];
console.log(confidence+.5);
console.log(isIdentical);
if(confidence>.5 )//&& confidence>.5
{
console.log('Face verified with confidence '+(confidence));
myLCD.setColor(100,160,0);
myLCD.setCursor(1,0);
myLCD.write("face Verified")
mqttClient.publish(topic,'Congrats! Your face is verified.. Now voice verification will begin')
///////////////////////////////// Now voice verification Should Start////////////////////////
voiceModule();
////////////////////////////////////////////////////////////////////////////////
}
else
{
mqttClient.publish(topic,'Sorry! Your face is not verified. Press switch again to retry')
}
}
catch(Error)
{
mqttClient.publish(topic,'Sorry! verification process failed. Press switch again to retry')
}
//faceId=data[0]['faceId'];
//console.log('-------- The Face Id is ----------\n'+faceId)
});
}
人脸验证成功后,它会调用 voiceModule(),这是语音识别的实现。
语音识别
我们首先需要初始化语音识别所需的所有变量。
var appId="https://api.knurld.io/v1/app-models/ecd1003f382e5a3f544d2f1dcf77a185";
var devid='Bearer: <my dev id>';
var clientId='<my client id>';
var clientSecret='<my client secret>'
var access_token='';
var verificationUrl='';
var rest = require('restler');
var dropboxUrl='';
var intervals=null;
var phrases=null;
var Sound = require('node-arecord');
var aname=(new Date()).getTime() + ".wav";
var fname= '/home/root/'+aname;
var sound = new Sound({
debug: true, // Show stdout
destination_folder: '/home/root/',
filename: fname,
alsa_format: 'cd',
alsa_device: 'plughw:2,0'
});
- 步骤 1 语音验证初始化:您是如何在设置 Intel Edison 音频后录制您的第一个音频的?使用命令行和 arecord。还记得吗?那么我们将如何执行语音录制?您的直接回答会是“使用 child_process.exec()”对吧?不完全是。因为还记得当我们用 arecord 测试音频录制时,我们实际上必须使用 ctrl+c 来停止录制。这意味着命令需要硬件中断才能关闭。这在 Node.js 中很难实现。因此,我们使用另一个 npm 模块 node-arecord。使用 node-arecord,您必须指定要执行录制的时间总长。为了使 arecord 工作,您需要指定声卡和采样率。请注意 alsa_device 分配为 plughw:2,0。这是因为在设置音频时,我们检测到的硬件卡是 2,设备 ID 是 0。还记得我们为 arecord 使用了 CD 质量吗?
- 步骤 2 授权应用程序并获取访问令牌:首先我们查找 consumerUrl。如果文件系统中没有,则表示尚未注册语音。如果 consumerUrl 存在,则表示已注册语音。我们首先调用 https://api.knurld.io/oauth/client_credential/accesstoken 端点以获取访问令牌。
function voiceModule()
{
//////////////// Check for ConsumerUrl.txt, if not exists give message and return else load consumerUrl///////////////////////
fs.readFile('/home/root/consumerUrl.txt', 'utf8', function (err,data) {
if (err)
{
myLCD.setCursor(1,0);
myLCD.write('Voice nt Enrld')
mqttClient.publish(topic,'Voice not registered. Register voice')
angle=90;// face database not preset
return console.log(err);
}
consumerUrl=data;
console.log('consumerUrl='+consumerUrl);
});
if(consumerUrl.length>2)
{
////////////////////////////////////////////////////////////////////////////////////
mqttClient.publish(topic,' Validating voice app');
//////////////////// Step1 fetch Access Token//////////////////////////////////////////////////
rest.post('https://api.knurld.io/oauth/client_credential/accesstoken?grant_type=client_credentials', {
data: {
'client_id': '<my client id>',
'client_secret': '<my client secret>'
}
}).on('complete', function(data) {
//console.log(data);
console.log('-------------');
console.log(data.access_token+"\n"+data['developer.email']);
access_token=data.access_token.toString();
////////////////// Initialize a Verification/////////////////////////
payload='{"consumer":"'+ consumerUrl+'" ,"application": "'+ appId+'"}';
rest.post('https://api.knurld.io/v1/verifications', {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data) {
verificationUrl=data["href"];
console.log('Verification URL=====>'+verificationUrl);
/////////// After Verification URl retrive verificationStatus which will return phrases////////////////
///////////////// Get Verification Status//////////////////////////////////////////////////////////
rest.get(verificationUrl, {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
}).on('complete', function(data) {
// here fetch instructions
// console.log(data);
phrases=data["instructions"]["data"]["phrases"];
/////////////////////////////CHKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK//////////////////////////////////////////////////////////////////
var msg=data["instructions"]["directions"]+ " the phrases are:";
console.log("Phrases Are.......................");
for(var i=0;i<phrases.length;i++)
{
console.log(phrases[i])
msg=msg+phrases[i]+",";
}
console.log(msg);
mqttClient.publish(topic,msg);
myLCD.setColor(60,180,0);
myLCD.setCursor(1,0);
myLCD.write("Record Voice")
setTimeout(speak,15000);
////////////////////////////CHKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK////////////////////////////////////////////////////////////////////////////
});
});
/////////////////////////Initialize verification ends here/////////////////////////////////////////////
});
- 步骤 3 初始化验证:请记住,Knurld 采用基于模型的验证过程。它随机提供用户必须说出的短语顺序。因此,您需要获取这些必须说出的短语集。一旦访问令牌可用,就会调用验证端点。
.on('complete', function(data) {
verificationUrl=data["href"];
console.log('Verification URL=====>'+verificationUrl);
/////////// After Verification URl retrive verificationStatus which will return phrases////////////////
///////////////// Get Verification Status//////////////////////////////////////////////////////////
rest.get(verificationUrl, {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
一旦初始化验证结果可用,短语就会被提取并通过 MqTT 发布,然后发送到 PC APP 并由语音合成器说出。
由于指令较长,语音合成器需要一些时间才能说出(估计约 12 秒),因此我们设定了 15 秒的录制前超时。使用 setTimeout 函数,调用 speak 函数。
- 步骤 4 音频录制:node-arecord 对象使得录制变得相当容易。它只需要一个调用。
function speak()
{
sound.record();
/////////////////////// Recording Stop
setTimeout(uploadAudio,10000);
}
我们录制音频 10 秒钟。
重要提示:我们创建的应用程序模型包含短语“purple”、“circle”、“maroon”,无论您说出的顺序如何(请记住,验证时您只需说一次,不像注册时每个单词都需要重复 3 次),或者说话的人是谁,都不会超过 8 秒。因此我们使用了 10 秒的录音块。如果您的词汇包含“baltimore”等大词,则您的计时必须相应调整。
录音完成后,将调用 uploadAudio 函数。
- 步骤 5 将音频上传到 Dropbox:我们已经了解了 Dropbox 的上传方式,所以我就不再重复赘述代码了。
- 步骤 6 调用分析:音频文件保存后,调用分析端点。在开发 C# PC 应用程序时,我们已经看到了分析的功能,它启动了一个分析音频的过程。然后调用 GetAnalysisStatus 端点返回间隔。分析函数返回一个包含 taskname 的有效负载。我们在 2 秒后轮询 getIntervals 函数以获取录制音频中的间隔。
function analysis()
{
var payload='{"audioUrl":"'+dropboxUrl +'","words":3}';
mqttClient.publish(topic, 'Audio Uploaded.. starting analysis')
/////////////////////////////////////////////// End point Analysis//////////////////////////////
rest.post('https://api.knurld.io/v1/endpointAnalysis/url', {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data) {
console.log("------------- TASK NAME and TASK STATUS--------------");
console.log(data);
console.log("taskName:"+data["taskName"]);
var taskName=data["taskName"].toString();
console.log("taskStatus:"+data["taskStatus"]);
// after 2 seconds check for task status
setTimeout(getIntervals(taskName),2000);
});
}
- 步骤 7 获取间隔:GetAnalysisStatus 端点返回的间隔 JSON 数组只包含短语的开始和结束时间。它不包含短语本身。就像我们的 C# 应用程序一样,当获得分析结果时,我们需要附加短语。
function getIntervals(taskName)
{
rest.get('https://api.knurld.io/v1/endpointAnalysis/'+taskName, {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
}
}).on('complete', function(data)
{
mqttClient.publish(topic,'Analysis Completed.. verifying voiceprint')
console.log("------------- PAYLOAD--------------")
intervals=data["intervals"];
for(var i=0;i<intervals.length;i++)
{
intervals[i]["phrase"]=phrases[i];
}
console.log(intervals);
console.log('****************** Now Submit Verification****************')
verify(JSON.stringify(intervals));
myLCD.setColor(20,220,0);
myLCD.setCursor(1,0);
myLCD.write("Voice Analyzed")
});
- 步骤 8 验证:最后通过提交间隔数据调用验证端点。请记住,就像注册一样,验证也不会立即返回结果。相反,它会返回一个 URL。应用程序需要定期检查状态。当任务状态完成时,有效负载将包含验证状态。
function verify(intervals)
{
console.log('in verify method printing intervals.....'+intervals);
var payload='{"verification.wav":"'+dropboxUrl +'","intervals":' +intervals+'}';
console.log(payload);
rest.post(verificationUrl, {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data)
{
console.log("------------- Verification Submitted.. URL--------------\n"+data);
//verificationUrl=data["href"];
/// Check Verification status after 5 seconds
setTimeout(getVerificationStatus,5000);
});
}
我们在调用 getVerificationStatus 之前设置了 5 秒的超时。根据我的实验,这是 Knurld 服务器验证语音样本所需的最长时间。
- 步骤 9:获取验证状态并认证/拒绝用户: getVerificationStatus 是一个轮询过程。如果状态不是“completed”,该方法会再次调用自身,因为此过程可能会使设备进入无限循环,我们设置了一个计数器并在三次尝试后停止验证。如果返回的 JSON 数据包含“verified”字段为 true,则我们认证用户并打开箱子。
var count=0;
function getVerificationStatus()
{
rest.get(verificationUrl, {
headers: {
'Authorization': 'Bearer '+access_token,
'Developer-Id': devid,
'Content-Type': 'application/json'
},
data: payload
}).on('complete', function(data)
{
console.log("------------- Final RESULT--------------");
/// Check Verification status after 5 seconds
console.log(data);
if(data["status"].toString()=='initialized')
{
count++;
if(count>3)
{
count=0;
mqttClient.publish('Sorry phrases not detected. Verification failed. Press switch to start again')
}
else{
setTimeout(getVerificationStatus,5000);
}
}
else if(data["status"].toString()=='completed')
{
if(data["verified"]==true)
{
console.log(data["consumer"]["username"]+" is Verified");
////////// If verified then only open the box
mqttClient.publish(topic,data["consumer"]["username"]+" is Verified");
//////////////////////////////////////////////
myLCD.setColor(0,255,0);
myLCD.setCursor(1,0);
myLCD.write("User Verified")
servo.to(0);//<-------- Box Open
myLCD.setCursor(1,0);
myLCD.setColor(255,0,0);
myLCD.write('OPEN');
angle=0;
/////////////////////
}
else
{
mqttClient.publish(topic,'Sorry!'+["consumer"]["username"]+ ' voice not verified. Press switch again to retry')
console.log(data["consumer"]["username"]+" is NOT Verified");
myLCD.setColor(255,0,0);
myLCD.setCursor(1,0);
myLCD.write("Verification Failed detected")
}
}
console.log("------------- Final RESULT--- Subscribing Back-----------");
mqttClient.subscribe('rupam/CashBoxControl/#');
mqttClient.handleMessage=function(packet,cb)
{
var payload = packet.payload.toString();
console.log(payload);
if(payload=='close')
{
console.log('-- Closing---')
mqttClient.publish(topic,'Closing through remote command')
BoxClose();
}
}
});
}
嗯,差不多就是这样了。我们已经完成了生物识别储物柜的开发。现在轮到您来构建和测试它了。
8. 结论
我已经折腾了很长时间了。我一直在使用 Arduino,最近开始使用 Edison。随着嵌入式系统演变为物联网,新的一套标准、服务、硬件和软件也随之演变。因此,当我计划写这篇文章时,我正在思考一个具有复杂软件堆栈的解决方案,该堆栈涵盖物联网中的主要协议和问题,同时保持硬件最小化,但仍能展示物联网的强大功能。对最新趋势的研究表明,物联网安全解决方案具有广阔的范围。在开发了一系列生物识别解决方案(包括人脸、虹膜、语音)之后,它成为显而易见的选择之一。有两个问题:我可以选择一种特定的生物识别技术(人脸是我的首选)或采用服务级架构。考虑到每个人都希望在云端部署解决方案,我选择了后者。
在本文和项目的开发过程中,我探索了新技术、API、协议。整个学习体验太庞大了,无法在一篇文章中全部呈现。我已尽力提供尽可能多的细节。目的不是告诉您我是如何构建解决方案的,而是告诉您即使您也可以构建解决方案。
我希望这篇文章能让您更容易地进入物联网领域,并更自信地探索这个新时代。
学习愉快,编码愉快!!!!