
如何在 .NET 中使用 GPU
4.92/5 (67投票s)
轻松将程序提速5倍。现在可在任何GPU上运行!
更新 2021年10月6日
- 测试了新硬件:自2016年以来性能大幅提升!
NVIDIA GeForce RTX 3080
更新 2016年12月13日
- 现在可以在多个GPU和任何其他OpenCL设备上运行。请评论您演示的结果
引言
这个项目将向你展示,一个现代的酷睿i7可能是你PC中可编程硬件中最慢的部分。现代四核CPU大约有6 Gflops的计算能力,而现代GPU大约有6 Tflops的计算能力。
这个项目可以在你的GPU、CPU或两者上动态执行用C方言(OpenCL C)编写的简单程序。它们在运行时进行编译和执行。
这也将表明GPU编程并不难。事实上,你只需要一点基本的编程技能就可以完成这个项目。
如果你想跳过介绍并直接使用它,请随意下载源代码。
我需要这个吗?
你的电脑是一台非常强大的机器。仅使用CPU执行任务,你可能会浪费其约90%的潜力。
如果你有一段并发的代码并且想加速它,那么这就是适合你的项目。理想情况下,你的所有数据都适合放入一些float或其他数字数组中。
潜在的加速示例包括:
- 处理图片或视频
- 任何可以并行完成的工作
- 在GPU上进行繁重的数字运算
- 通过并行使用GPU和CPU来节省能源和时间
- 将GPU用于任何任务,并让CPU空闲执行其他操作
请记住,这个项目使用OpenCL。与Cuda不同,它可以在任何GPU(AMD、Nvidia、Intel)以及CPU上运行。因此,您编写的任何程序都可以在任何设备上使用。(甚至手机)
在NVIDIA、AMD和Intel上测试过。
以下是简单质数计算的结果
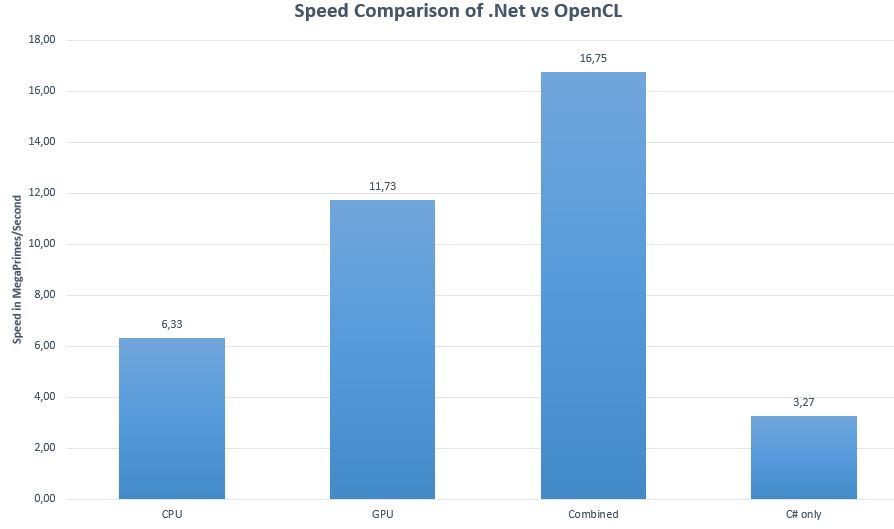
如你所见,你的程序**确实**可以大大加速。原生 C# 比你在 PC 上能获得的最快速度慢 5 倍。这甚至不是最好的情况。在纯乘加工作负载中,加速因子可以接近 500 倍。(GPU 在这个领域表现出色)。如果有很多 if 语句,CPU 有时可能会更好。
最重要的是,使用这个类为你的GPU和CPU编写程序真的非常容易。
OpenCL代码在数组上总是比C#运行得更快,并且使用这个项目真的很容易和快速。
(见下文示例)作为开发者,您的开销几乎为零。只需编写一个函数,就大功告成了。无需考虑计算设备、PInvoke、封送处理和其他问题。
如何使用?
OpenCL编程可能非常耗时。这个辅助项目将减少你的编程开销,让你能专注于核心问题。它用C#编写,但可以适应任何.NET语言,也可以适应C++。
想象一下,你想知道从2到10^8的所有质数。这是一个用C#实现的简单版本(是的,我知道有更好的算法来计算质数)。
static void IsPrimeNet(int[] message)
{
Parallel.ForEach(message, (number, state, index) =>
{
int upperlimit = (int)Math.Sqrt(number);
for(int i=2;i<=upperlimit;i++)
{
if (message[index]%i == 0) //no lock needed. every index is independent
{
message[index] = 0;
break;
}
}
});
}
现在我们把这段代码翻译成 OpenCL-C。
以下 Kernel 在**文件**中、**内联**或在**资源文件**中声明为 string。
kernel void GetIfPrime(global int* message)
{
int index = get_global_id(0);
int upperl=(int)sqrt((float)message[index]);
for(int i=2;i<=upperl;i++)
{
if(message[index]%i==0)
{
//printf("" %d / %d\n"",index,i );
message[index]=0;
return;
}
}
//printf("" % d"",index);
}
OpenCL 将你的 `kernel`(要运行的代码段)封装在一个循环中。对于简单的一维数组,你可以通过 `调用 get_global_id(0);` 获取索引。索引的上限在你调用 kernel 时传递。
欲了解更多信息,请查阅此链接。
您可以使用 `int*` 代替 `int[]`,等等。您还可以传递其他任何基本类型(`int`、`float` 等)。
你必须按照声明的顺序传递参数。你也可以在你的 `kernel` 内部调用 `printf` 以便稍后调试。你可以在 kernel 内部定义任意数量的方法。你可以在稍后通过调用 `Invoke("Name Here")` 选择入口点。
OpenCL C 与 C 相同,但不能使用指针,并且还有一些特殊的数据类型。
要获取深入信息,请查看此链接。
下面是您如何使用这个项目:
- 添加 Nuget 包
Cloo - 添加对 *OpenCLlib.dll* 的引用。
下载 OpenCLLib.zip. - 添加
using OpenCL
static void Main(string[] args)
{
int[] Primes = Enumerable.Range(2, 1000000).ToArray();
EasyCL cl = new EasyCL();
cl.Accelerator = Accelerator.Gpu; //You can also set the accelerator after loading the kernel
cl.LoadKernel(IsPrime); //Load kernel string here, (Compiles in the background)
cl.Invoke("GetIfPrime", Primes.Length, Primes); //Call Function By Name With Parameters
//Primes now contains all Prime Numbers
}
static string IsPrime
{
get
{
return @"
kernel void GetIfPrime(global int* message)
{
int index = get_global_id(0);
int upperl=(int)sqrt((float)message[index]);
for(int i=2;i<=upperl;i++)
{
if(message[index]%i==0)
{
//printf("" %d / %d\n"",index,i );
message[index]=0;
return;
}
}
//printf("" % d"",index);
}";
}
}
有了它,你可以动态编译和调用 OpenCL 内核。你也可以在加载内核后更改你的加速器(CPU、GPU)。
如果你想利用你电脑的每一分计算能力,你可以使用 `MultiCL` 类。这个类通过将你的工作分成 `N` 部分来工作。每个部分都会在可能的情况下推送到 GPU 或 CPU。这样,你就能从你的电脑中获得最大的性能。你还可以知道已经完成了多少工作,这是 `EasyCL` 无法实现的。
static void Main(string[] args)
{
int[] Primes = Enumerable.Range(2, 1000000).ToArray();
int N = 200;
MultiCL cl = new MultiCL();
cl.ProgressChangedEvent += Cl_ProgressChangedEvent1;
cl.SetKernel(IsPrime, "GetIfPrime");
cl.SetParameter(Primes);
cl.Invoke(0, Primes.Length, N);
}
private static void Cl_ProgressChangedEvent1(object sender, double e)
{
Console.WriteLine(e.ToString("0.00%"));
}
它是如何工作的?
这项工作引用了 Nuget 包 Cloo。通过 Cloo,可以从 .NET 调用 OpenCL。
它基本上隐藏了你使用 OpenCL 和 Cloo 所需了解的所有实现细节。要获取关于你的内核或设备的更多信息,请使用 OpenCL 类。
这个项目中有3个类:
EasyCL(非常轻松地调用内核)MultiCL(在**所有OpenCL设备上同时**调用内核以获得最大速度)OpenCL(调用内核并获取关于您设备的一些信息)
在内部,每次调用 Invoke 都会调用 OpenCL API 中相应的方法。
void Setargument(ComputeKernel kernel, int index, object arg)
{
if (arg == null) throw new ArgumentException("Argument " + index + " is null");
Type argtype = arg.GetType();
if (argtype.IsArray)
{
Type elementtype = argtype.GetElementType();
//ComputeBuffer<int> messageBuffer = new ComputeBuffer<int>(context,
//ComputeMemoryFlags.ReadOnly | ComputeMemoryFlags.UseHostPointer, (int[])arg);
ComputeMemory messageBuffer = (ComputeMemory)Activator.CreateInstance
(typeof(ComputeBuffer<int>), new object[]
{
context,
ComputeMemoryFlags.ReadWrite | ComputeMemoryFlags.UseHostPointer,
arg
});
kernel.SetMemoryArgument(index, messageBuffer); // set the array
}
else
{
//kernel.SetValueArgument(index, (int)arg); // set the array size
typeof(ComputeKernel).GetMethod("SetValueArgument").MakeGenericMethod(argtype).Invoke
(kernel, new object[] { index, arg });
}
}
每次你更改内核或加速器时,程序都会重新编译
为了更快的原型开发阶段,这个类还会告诉你为什么你的内核无法编译。
public void LoadKernel(string Kernel)
{
this.kernel = Kernel;
program = new ComputeProgram(context, Kernel);
try
{
program.Build(null, null, null, IntPtr.Zero); //compile
}
catch (BuildProgramFailureComputeException)
{
string message = program.GetBuildLog(platform.Devices[0]);
throw new ArgumentException(message);
}
}
非常重要的一点是,如果你的 GPU 驱动崩溃,或者内核在 3 秒以上的时间里(在 Win10 之前的机器上)使用了 100% 的 GPU,那么内核将被中止。之后你应该处置 EasyCL 对象。
//If windows Vista,7,8,8.1 you better be ready to catch:
EasyCL cl = new EasyCL();
cl.InvokeAborted += (sender,e)=> Cl_InvokeAborted(cl,e);
private void Cl_InvokeAborted(EasyCL sender, string e)
{
//your logic here
}
出于某种原因,我不知道为什么先调用一个空内核会更快,然后所有后续调用都更快。(也许是OpenCL初始化)。
缺少什么?
您无法选择是使用主机指针还是对传递给内核的 `int[]` 进行读写访问。我没有看到将数组设置为只读有任何性能提升。这似乎是一个遗留函数。
这个类是为PC编写的。通过Visual Studio/Xamarin,应该很容易将其适配到手机上。(现代智能手机的8核性能足以媲美大多数笔记本电脑。)
确保所有最新驱动程序都已安装。
http://www.nvidia.com/Download/index.aspx?lang=en-us
http://support.amd.com/en-us/download
https://software.intel.com/en-us/articles/opencl-drivers#latest_CPU_runtime
我如何提供帮助?
如果您看到这篇文章并想提供帮助,请下载演示程序。我对您的结果非常感兴趣。
我的结果
(2021年10月6日 - 时光飞逝 - 硬件越来越快!)
NVIDIA GeForce RTX 3080
单精度浮点运算能力 = 27089.95 GFlops
双精度浮点运算能力 = 567.55 GFlops
内存带宽 = 0.40 GByte/s
AMD Ryzen 9 5950X 16核处理器
单精度浮点运算能力 = 91.01 GFlops
双精度浮点运算能力 = 87.24 GFlops
内存带宽 = 1.15 GByte/s
(13.12.2016)
AMD RX480
5527.46 单精度浮点运算能力
239.78 双精度浮点运算能力
Intel(R) 酷睿(TM) i7-4790K CPU @ 4.00GHz
6.63 单精度浮点运算能力
7.33 双精度浮点运算能力
(10.09.2016)
GeForce GTX 1060 6GB
单精度浮点运算能力 = 3167.97 GFlops
双精度浮点运算能力 = 233.58 GFlops
内存带宽 = 3.55 GByte/s
Intel(R) 酷睿(TM) i7-4790K CPU @ 4.00GHz
单精度浮点运算能力 = 201.32 GFlops
双精度浮点运算能力 = 206.96 GFlops
内存带宽 = 3.10 GByte/s