
Sql Server In Clause 具有多个文字值时的性能行为
4.50/5 (2投票s)
本文讨论了文字值之间的性能差异。
引言
我将开始我的第一篇文章,关于带有常量字面值的 in 子句,我们将探讨优化器的行为变化。它如何处理和内部处理带有常量字面值的这个条件。以及子查询还有哪些替代方案。了解查询优化器的默认行为是件好事,这样您就可以充分利用它,并可能(以更好的方式)影响优化器,使其通过不同的访问路径,并以不同的方式处理查询,从而为查询带来更好的执行计划,即使没有索引,也不要误解我,索引是好的,但有些列您并不希望都建立索引。
在开始这篇文章之前,我们应该记住 SQL Server 是一种声明性语言,查询引擎不会直接执行提交给它的 SQL 查询。粗略地说,当查询提交给 SQL Server 时,它会解析查询并检查语义,然后创建一个等效的逻辑树来匹配提供的查询,然后逻辑树会经过多个优化阶段以获得一个“足够好”的查询计划。
查询优化器是一个出色的软件,其主要目标是以尽可能短的时间生成一个好的执行计划。在大多数情况下,查询优化器会创建多个替代的物理执行计划,并选择总成本最低的那个计划。
我确信所有使用 SQL 的人都会使用 "in" 作为多个 "or" 的替代简写,以避免重复的条件。SQL 语言中有 "in" 子句是件好事,想想如果我们需要为同一个列写 100 次多个 "or" 子句会有多么困难。
In 条件在数据库中非常常见,用于传递多个谓词,因为重复多个 or 用于同一列看起来相当冗长,因此有 in 子句形式的简写可用。
例如
Where id = 1 or id=2 or id = 3 可以写成 where id in (1,2,3)
下面快速回顾
子查询匹配 test_expression 则返回 True,否则返回 False。如果子查询包含空值,则根据会话/数据库的 ansi null 设置可能会返回意外结果。如果存在冗余数据,则从子查询中删除。如果 in 子句中提供了大量值(数千个),可能会消耗资源并返回错误 8623 或 8632。进一步阅读此处。
回到主题
下面我创建了一个随机表,其中包含一些随机数据,用于测试 in 子句与字面值的行为。据我所知,没有人触及过这个话题,不知道原因,所以最好开始吧 :)
以下是填充测试数据的可测试脚本
CREATE TABLE DBO.TestTable (
ID INT IDENTITY(1, 1) NOT NULL
,IDvarchar AS Cast(ID AS VARCHAR(50)) PERSISTED NOT NULL
,intcolumn INT
,NAME VARCHAR(50) NOT NULL
,Age INT NOT NULL
,Randomvalue BIGINT
);
INSERT INTO TestTable (
intcolumn
,NAME
,AGE
)
SELECT s1.number
,'Some Random Data..'
,s1.number % 10 + 25
FROM master.dbo.spt_values s1
CROSS JOIN master.dbo.spt_values s2;
UPDATE TestTable
SET Randomvalue = Cast(rand(checksum(newid())) * ID AS INT);
ALTER TABLE TestTable
ALTER COLUMN Randomvalue INT NOT NULL;
UPDATE STATISTICS TestTable WITH fullscan;
在开始之前,有几点需要考虑
- 该表是堆表
- 上面没有有用的索引
- 查找列包含唯一的整数值
- 字面值存在于表中
- QO 限制为使用 1 个线程(并行性禁用)
- 执行计划是非平凡的。
为了衡量性能差异,我创建了一个脚本,它会针对提供的常量字面值进行循环运行,并计算执行这些值所花费的总时间,然后将结果放入一个临时表中。结果被分配给一个局部变量,只是为了限制将数据发送到 SSMS 网格。
例如
——第一个查询将执行为
Select @ID=ID , @IDVARCHAR=IDvarchar ,@INTCLOUMN=intcolumn, @NAME=Name ,@AGE=Age ,@RANDOMVALUE=Randomvalue
from TestTable
where id in
(
3279615
)
——第二个查询将执行为
Select @ID=ID , @IDVARCHAR=IDvarchar ,@INTCLOUMN=intcolumn, @NAME=Name ,@AGE=Age ,@RANDOMVALUE=Randomvalue from TestTable
where id in
(
3279615, 2619534\
)
——第三个查询将执行为
@ID=ID , @IDVARCHAR=IDvarchar ,@INTCLOUMN=intcolumn, @NAME=Name ,@AGE=Age ,@RANDOMVALUE=Randomvalue from TestTable
where id in
(
3279615, 2619534, 2932146
)
依此类推……直到 99 个值
脚本
Create Table #counter (variablecount INT , Duration INT
)
DECLARE @values NVARCHAR(max)
SELECT @values = (
'3279615, 2619534, 2932146, 4953386, 2818224, 5244141, 2321234, 4670287, 3600354, 4307158, 4668756, 4049137, 3037542, 4483522, 3660501, 4426646, 3110987, 2709820, 2818736, 4875826, 2029820, 5467223, 2316672, 2080036, 3781872, 5120161, 4231500, 2885329, 2186636, 4273746, 4469182, 4682959, 3905551, 3206172, 2911743, 4275209, 3789552, 2341547, 2943986, 5229815, 2867115, 2402580, 2943328, 3125357, 4816147, 4219152, 3825625, 3221610, 5052178, 4742174, 2182772, 4934910, 5196299, 3803372, 5041037, 4261499, 5266382, 3667876, 3467411, 2574704, 3941358, 3785855, 4258958, 4565076, 5274231, 3203938, 5329843, 4438383, 2312628, 3248408, 3743514, 4552594, 4109833, 4388393, 5064054, 2054373, 3715411, 3761234, 5470921, 5197951, 4356672, 3309015, 3767928, 2372922, 3858804, 3617027, 3247204, 2105261, 2846260, 3053944, 4398447, 3246406, 4326008, 2506261, 5404760, 2410146, 3578365, 2753024, 3164078, 4087679'
)
DECLARE @dynamicsql NVARCHAR(max)
DECLARE @loop INT
,@LoopCount INT
SET @loop = 7
SET @LoopCount = 1
WHILE (@loop < 997)
BEGIN
SET @dynamicsql = 'declare @Beforeexecutiontime datetime
declare @Aeforeexecutiontime datetime
declare @ID int
declare @IDvarchar varchar(50)
declare @INTCLOUMN int
declare @Name varchar(50)
declare @Age int
declare @Randomvalue bigint
Set @Beforeexecutiontime=getdate()
Select @ID=ID , @IDVARCHAR=IDvarchar ,@INTCLOUMN=intcolumn, @NAME=Name ,@AGE=Age ,@RANDOMVALUE=Randomvalue from TestTable
where id in
(' + Convert(NVARCHAR(max), left(@values, @loop)) + ')
option (MAXDOP 1)
SET @Aeforeexecutiontime =getdate()
INSERT INTO #counter
select ' + Convert(NVARCHAR(10), @LoopCount) + ',datediff (MS ,@Beforeexecutiontime ,@Aeforeexecutiontime)
'
EXEC (@dynamicsql)
SET @loop = @loop + 10
SET @LoopCount = @LoopCount + 1
SET @dynamicsql = ''
END
SELECT *
FROM #counter
ORDER BY variablecount
我的系统上的结果
Microsoft SQL Server 2014 – 12.0.2000.8 (X64) (Build 7601: Service Pack 1)

Microsoft SQL Server 2012 – 11.0.2100.60 (Intel X86) (Build 7601: Service Pack 1)
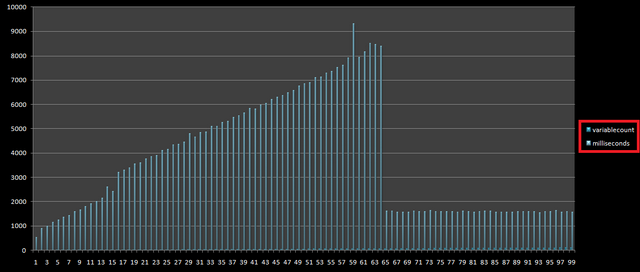
Microsoft SQL Server 2008 R2 (RTM) – 10.50.1600.1 (X64) (Build 7601: Service Pack 1)

Microsoft SQL Server 2005 - 9.00.3042.00 (Intel X86) (Build 7601: Service Pack 1)

请注意,当字面值计数达到 16 时,执行时间的变化,然后当它达到 65 及以上时,又有所改进,为什么?为什么处理在达到 65 时又变快了?对于任何经历过这些结果的人来说,都会得出结论,这不应该发生,因为如果 SQL Server 查询优化器能够针对 65 个或更多的字面值加快处理速度,那么它也应该能够对 10 到 64 行进行处理,不是吗?
您系统的结果是什么?
原因
您可能已经知道 SQL Server 是一种声明性语言,我们只是向 SQL 引擎提交了一个 SQL 语句,现在由 SQL Server 决定如何在内部执行它。
这一部分只专注于解释计划中突然发生的变化导致查询运行更快的原因。那么让我们看看查询优化器如何处理 2 个值的多个谓词。为了更清晰地理解,我将使用统计 IO和执行计划。
SET STATISTICS IO ON
SELECT *
FROM testtable
WHERE id IN (
3279615
,2619534
)
OPTION (MAXDOP 1)
我的系统上的结果是
表 'TestTable'。扫描次数 1,逻辑读取 37168
即使对于 2 个不同的值,扫描次数也只有“1”,这表明该表只针对两个字面值扫描了一次,当然,这是扫描多个值的更好选择,尤其是在表上没有支持索引的情况下。在这种情况下,我的假想伪代码如下所示

现在看一下“执行计划”选项卡,上面查询的执行计划显示

将光标放在表扫描迭代器上,底部显示 in 子句值已被 SQL Server 转换为多个 or。这完全适用于 15 个不同的字面值。那么现在我们来看看使用第 16 个字面值时会发生什么。
--16th literal value
SET STATISTICS IO ON
SELECT *
FROM testable
WHERE id IN (
3279615,2619534,2932146,4953386,2818224,5244141
,2321234,4670287,3600354,4307158,4668756,4049137
,3037542,4483522,3660501,3110987
)
OPTION (MAXDOP 1)
消息选项卡上的统计 IO 输出显示:“表 'TestTable'。扫描次数 1,逻辑读取 37618。”因此扫描次数仍然是“1”,统计信息没有揭示太多信息。现在让我们检查上面查询的执行计划。

有一个额外的筛选器迭代器,将光标放在迭代器上,它显示
根据谓词限制行集。如果它根据谓词限制行,那么这个过程之前是如何发生的?筛选实际上之前也在发生,但是筛选谓词与表扫描迭代器结合在一起,以避免单独的筛选计划运算符并减少在筛选和扫描运算符之间传递行的成本,而这里限制是 15 个不同的字面值。现在我们可以看到两个迭代器是相互独立的,如果您查看 BOL 中关于筛选谓词的解释,您会得到如下内容:

然而,在许多情况下,您也会看到筛选谓词。例如:having 子句,带有 case 语句的 where 子句以及非表筛选等。因此,在 16 个不同的字面值之后,它改变了物理访问数据的方式。因此,性能略有差异。现在让我们看看在 65 个不同的字面值之后会发生什么,因为它扩展得很好。
-- 65 Literal Values
SET STATISTICS TIME ON
SELECT *
FROM testtable
WHERE id IN (
3125357 , 3164078, 3203938, 3206172, 3221610, 3246406, 3247204, 3248408,
3309015, 5266382, 5274231, 3467411, 5329843, 3578365, 3600354, 2312628,
2316672, 2321234, 4219152, 4231500, 4258958, 4261499, 4273746, 4275209,
4326008, 4356672, 4388393, 4398447, 4426646, 4438383, 4469182, 4483522,
4552594, 4565076, 5404760, 5467223, 5470921, 2341547, 2372922, 2402580,
4668756, 4670287, 4682959, 2410146, 2506261, 2574704, 2619534, 2709820,
2753024, 2818224, 2818736, 2029820, 2846260, 2867115, 2885329, 2054373,
2080036, 2932146, 2105261, 2943328, 2943986, 3279615, 4307158,3617027,
2911743
)
OPTION (MAXDOP 1)
GO

从语义上讲,我们没有改变语句中的任何内容,统计 IO 没有揭示太多,但执行计划却揭示了。现在内部处理已经完全改变,并且在计划选择中引入了一个带有常量扫描迭代器的右半连接,因此执行时间减少了,现在查询优化器将字面值视为一个值的集合作为常量扫描迭代器,然后将测试表连接到 ID 列上。常量扫描将所有字面值保存在内存中,对字面值进行哈希处理并探测测试表的 ID。然而,哈希匹配在这里是一种高效的方法,但与之前的过滤相比,它会消耗一些内存。在我的系统上,处理此哈希连接需要额外的 1888 KB 内存授权,您可以使用 DMV `sys.dm_exec_query_memory_grants` 或将光标放在实际/后执行计划中最左侧的 select 迭代器上来检查正在执行的查询的内存授权。您可能知道 SQL Server 使用规则来实现物理实现,这里它使用“ConstGetToConstScan”来启用常量扫描迭代器。
在 SQL Server 2012 及更高版本中,在哈希匹配连接上,SQL Server 会应用残余谓词。

Expr1003 是整数类型字面常量值的列名,我没想到会这样,因为我们的字面值集合中既没有数据类型不匹配,也没有空值。由于其行为(探测残余)在 SQL Server 的早期版本中不存在,直到您在字面值集合中添加显式不匹配的数据类型,那么在字面值上存在残余谓词必然有一个坚实的原因。
最后一部分
我相信,即使在本文中途,您也已经知道如何通过表变量或临时表来修复这种行为。由于上述查询并不复杂,选择迭代器接收到的最终数据的估计值在这里并不重要,所以我选择表变量,无论是使用跟踪标志 2453 (请阅读知识库文章获取更多信息)还是语句级重新编译。
但如果我的查询更复杂,我可能会使用临时表,只是为了避免陷入计划回归,因为临时表更有效地使用直方图值。所以让我们继续,在临时变量中插入 64 个常量字面值,看看它是如何工作的。
DECLARE @LitralCollection AS TABLE (LValue INT NOT NULL)
-- 64 Literal Values
INSERT INTO @LitralCollection
Select 3125357 Union ALL Select 3164078 Union ALL Select 3203938 Union ALL
Select 3206172 Union ALL Select 3221610 Union ALL Select 3246406 Union ALL
Select 3247204 Union ALL Select 3248408 Union ALL Select 3279615 Union ALL
Select 3309015 Union ALL Select 5266382 Union ALL Select 5274231 Union ALL
Select 3467411 Union ALL Select 5329843 Union ALL Select 3578365 Union ALL
Select 3600354 Union ALL Select 2312628 Union ALL Select 2316672 Union ALL
Select 2321234 Union ALL Select 4219152 Union ALL Select 4231500 Union ALL
Select 4258958 Union ALL Select 4261499 Union ALL Select 4273746 Union ALL
Select 4275209 Union ALL Select 4307158 Union ALL Select 4326008 Union ALL
Select 4356672 Union ALL Select 4388393 Union ALL Select 4398447 Union ALL
Select 4426646 Union ALL Select 4438383 Union ALL Select 4469182 Union ALL
Select 4483522 Union ALL Select 4552594 Union ALL Select 4565076 Union ALL
Select 2372922 Union ALL Select 2402580 Union ALL Select 3617027 Union ALL
Select 4682959 Union ALL Select 2410146 Union ALL Select 2506261 Union ALL
Select 2709820 Union ALL Select 2753024 Union ALL Select 2818224 Union ALL
Select 2846260 Union ALL Select 2867115 Union ALL Select 2885329 Union ALL
Select 2080036 Union ALL Select 2932146 Union ALL Select 2105261 Union ALL
Select 5404760 Union ALL Select 5467223 Union ALL Select 5470921 Union ALL
Select 2341547 Union ALL Select 4668756 Union ALL Select 4670287 Union ALL
Select 2574704 Union ALL Select 2619534 Union ALL Select 2818736 Union ALL
Select 2029820 Union ALL Select 2054373 Union ALL Select 2911743 Union ALL
Select 2943328
SELECT *
FROM testtable
WHERE id IN (
SELECT Lvalue
FROM @LitralCollection
)
OPTION (MAXDOP 1,Recompile)

耗时 = 1291 毫秒。
与 64 个字面值相比,不使用临时变量
-- 64 Literal Values
SELECT *
FROM testtable
WHERE id IN (
3125357 , 3164078 , 3203938 , 3206172 , 3221610 , 3246406 , 3247204 , 3248408 , 3279615 ,
3309015 , 5266382 , 5274231 , 3467411 , 5329843 , 3578365 , 3600354 , 2312628 , 2316672 ,
2321234 , 4219152 , 4231500 , 4258958 , 4261499 , 4273746 , 4275209 , 4307158 , 4326008 ,
4356672 , 4388393 , 4398447 , 4426646 , 4438383 , 4469182 , 4483522 , 4552594 , 4565076 ,
5404760 , 5467223 , 5470921 , 2341547 , 2372922 , 2402580 , 3617027 , 4668756 , 4670287 ,
4682959 , 2410146 , 2506261 , 2574704 , 2619534 , 2709820 , 2753024 , 2818224 , 2818736 ,
2029820 , 2846260 , 2867115 , 2885329 , 2054373 , 2911743 , 2080036 , 2932146 , 2105261 ,
2943328
)
OPTION (MAXDOP 1)

耗时 = 6147 毫秒。
您是否注意到在执行计划中,当将所有字面值提供给临时变量时,查询优化器将值集合创建为常量扫描迭代器,并将所有行一次性地填充到临时变量中,因此与其将其填充到临时变量中,不如直接在查询中使用该集合。
SELECT *
FROM testtable
WHERE id IN (
Select 3125357 Union ALL Select 3164078 Union ALL Select 3203938 Union ALL
Select 3206172 Union ALL Select 3221610 Union ALL Select 3246406 Union ALL
Select 3247204 Union ALL Select 3248408 Union ALL Select 3279615 Union ALL
Select 3309015 Union ALL Select 5266382 Union ALL Select 5274231 Union ALL
Select 3467411 Union ALL Select 5329843 Union ALL Select 3578365 Union ALL
Select 3600354 Union ALL Select 2312628 Union ALL Select 2316672 Union ALL
Select 2321234 Union ALL Select 4219152 Union ALL Select 4231500 Union ALL
Select 4258958 Union ALL Select 4261499 Union ALL Select 4273746 Union ALL
Select 4275209 Union ALL Select 4307158 Union ALL Select 4326008 Union ALL
Select 4356672 Union ALL Select 4388393 Union ALL Select 4398447 Union ALL
Select 4426646 Union ALL Select 4438383 Union ALL Select 4469182 Union ALL
Select 4483522 Union ALL Select 4552594 Union ALL Select 4565076 Union ALL
Select 2372922 Union ALL Select 2402580 Union ALL Select 3617027 Union ALL
Select 4682959 Union ALL Select 2410146 Union ALL Select 2506261 Union ALL
Select 2709820 Union ALL Select 2753024 Union ALL Select 2818224 Union ALL
Select 2846260 Union ALL Select 2867115 Union ALL Select 2885329 Union ALL
Select 2080036 Union ALL Select 2932146 Union ALL Select 2105261 Union ALL
Select 5404760 Union ALL Select 5467223 Union ALL Select 5470921 Union ALL
Select 2341547 Union ALL Select 4668756 Union ALL Select 4670287 Union ALL
Select 2574704 Union ALL Select 2619534 Union ALL Select 2818736 Union ALL
Select 2029820 Union ALL Select 2054373 Union ALL Select 2911743 Union ALL
Select 2943328
)
OPTION (MAXDOP 1)

耗时 = 1162 毫秒。
现在查询优化器最终的执行计划选择已经改变,正如你所看到的
在上面的执行计划中,内部侧是一个常量扫描(内存中所有字面值的集合),通过哈希匹配作为物理连接迭代器连接 Testtable。有趣的是,在探测侧有一个额外的筛选谓词( [TEST1].[dbo].[TestTable].[ID]>=(2029820) AND [TEST1].[dbo].[TestTable].[ID]<=(5470921) )。
2029820 和 5470921 是常量字面值集合中存在的最小值和最大值。因此,探测侧只向哈希匹配连接传递 250 MB 的数据,而之前是 478 MB 的数据。这种转换并不总是奏效,特别是当字面值集合的最大值和最小值范围很广,或者在并行计划中位图下推到探测表时。
摘要
在这篇文章中,我只关注了在没有支持索引的表上,in 子句与字面值的行为。我展示了在第 16 个和第 65 个字面值之后执行时间如何变化,以及当这些情况困扰您时如何处理。但如果您有支持索引,则无需担心这种情况,自己检查一下很有趣 ;)