
通过 ReadyRoll 和 Entity Framework Code First Migrations 将数据库部署控制权交还
0/5 (0投票)
在本文中,我将向您展示如何继续使用 EF Code First 来建模您的数据库,同时使用 ReadyRoll 来实际部署 T-SQL 更改脚本,并克服 Code First 方法的挑战。
引言
数据库更改管理通常被视为拖慢部署速度的一个因素。这可能是 Entity Framework (EF) 在开发社区中如此受欢迎的原因。它在本地建模和部署数据库更改时提供了直接的工作流程。还可以通过 Code First 的 Fluent API 来编写迁移,并使用 C# 编写,这使得更改的编写体验比直接使用 T-SQL 操作数据库更加熟悉。然而,当团队中使用 EF Code First 迁移方法并且您想要分支或合并代码,或者协调比该方法所能支持的更复杂的架构更改时,可能会出现一些困难。对于这些限制中的一些,存在变通方法,而另一些则无法解决,仅仅因为 Code First 的本质就是如此。例如,它不支持 Entity Framework 模型之外的对象,例如数据库视图或函数(这些对象必须单独部署)。
这就是我认为一款使用平台原生语言 Transact-SQL 的工具可以提供帮助的地方。这也是我最初开发ReadyRoll的原因——正是为了解决开发人员在想要按时完成数据库更改,同时又想以正确的方式完成,而不是采取“快速修复”时面临的挑战。
在本文中,我将向您展示如何继续使用 EF Code First 来建模您的数据库,同时使用 ReadyRoll 来实际部署 T-SQL 更改脚本,并克服 Code First 方法的挑战。
为什么要进行数据库迁移?
首先,让我们来解决一下为什么要做数据库迁移来进行更改管理的问题。
背景介绍——我在金融服务行业工作多年,担任发布工程师,负责公司所有业务应用程序的部署。发布过程中最艰苦的部分无疑是发布过程中的数据库部分。数据库更改是手工编码的,脚本是手动部署的。在发布时有时会出错——脚本可能会丢失或部署顺序错误。数据库比较工具的出现改善了这种情况,因为它们消除了手工编写所有更改的需要,但我仍然需要做很多幕后工作来确保脚本按正确的顺序运行。
当我开始使用迁移框架时,我突然能够看到并控制我们想要执行的确切更改以及它们的顺序。我们开发了单个 T-SQL 脚本的更改,将它们添加到源代码管理中,并且每个脚本都有一个预定义的编号,这意味着它将按照我们预先指定的顺序按数字顺序执行。许多开发团队喜欢迁移方法进行数据库更改,正是因为从一开始就对其进行这样的监督。在部署时不应该有任何意外。
为什么要使用 ReadyRoll?
当我最初开始开发 ReadyRoll 作为一种迁移工具时,我知道迁移方法对我们的团队来说是正确的,但我们遇到了现有框架的限制。我们无法按预期的方式分支和合并更改,并且这些工具中的持续集成和自动化部署支持通常严重不足。我们还发现自己花费大量时间手工编写代码,当需要跨环境部署到数百个数据库时,这有点令人望而生畏。
因此,我开始将 ReadyRoll 创建为一个用于 SQL Server 数据库更改的、驱动迁移的混合工具。混合部署风格意味着通常的迁移模型方法适用(每个更改脚本都按预定义的数字顺序针对目标数据库执行),但 ReadyRoll 还包含一组使用基于状态的更改管理方法的功能。这些功能包括使用数据库差异引擎生成 T-SQL 脚本以及跟踪单个数据库对象更改历史记录的能力。
从动手开发的角度来看,我们的团队在 Visual Studio 中工作得很愉快,但也有一些团队成员更喜欢先在 SQL Server Management Studio (SSMS) 中编写数据库更改。因此,我将 ReadyRoll 设计为 Visual Studio 的一个扩展,并在需要时具有从 SSMS 导入更改的灵活性。
然而,这种数据库优先的开发工作流程并不适合所有人。如果您发现代码优先工作流程更自然,那么 ReadyRoll 可以为您提供一种方法,它结合了 Entity Framework Code First 迁移的最佳部分,并将其与迁移混合方法的灵活性相结合。
将现有的 Entity Framework 项目改编为基于 T-SQL 迁移的项目
为了将基于 T-SQL 迁移的方法与 ReadyRoll 集成到现有的 Entity Framework 项目中,让我们看一个简单的例子。我们将使用 Microsoft 自己的 Entity Framework Code First 示例项目(Contoso University),如下面的图 1 所示。

需要经过一系列步骤来创建一个空的 ReadyRoll 数据库项目,然后将我们的新项目指向与启用 Entity Framework 的项目相同的数据库。您可以在在线文档中详细了解这些步骤。
完成这些步骤后,我们需要为项目创建基线,这是一个从当前架构模型状态生成的脚本,它为所有将来的迁移设定了起点。这意味着基线最终应反映生产环境中架构模型的状态。
我们通过打开程序包管理器控制台窗口并执行以下命令来创建基线脚本:
Update-Database -Script -Source $InitialDatabase
这意味着 Entity Framework 会生成所有现有迁移的 T-SQL。该脚本还会自动添加到新的 ReadyRoll 数据库项目中。$InitialDatabase 参数会导致 Entity Framework 生成一个脚本,该脚本应能在所有目标环境中运行,而无论是否正在创建新数据库(如本例所示),或者在 Test 或 Production 等上游环境中是否已部署了部分或全部迁移。
现在我们已经在 ReadyRoll 数据库项目中有了脚本,我们可以在本地 SQL Server 实例上执行它。基线脚本已创建。
现在我们可以设置 ReadyRoll 来控制数据库部署。这意味着启用自动迁移(AutomaticMigrationsEnabled=true),如图 2 所示。我们仍然会生成迁移,但它们将是 T-SQL 格式,而不是 Fluent(C# 迁移类)格式。

(请注意,如果您更愿意使用 Fluent API 来编写更改,但使用 T-SQL 来部署到您的 Test 和 Production 环境,您也可以设置 AutomaticMigrationsEnabled=false。)
进行数据库模型更改——如何“向上”迁移
当您想要进行数据库模型更改时,您实际上不必放弃 Code First 提供的任何智能功能,即可将 T-SQL 作为您选择的部署语言。您可以像往常一样编写您的更改,然后执行以下命令来生成新的 T-SQL 更改脚本:
Update-Database -Script
此脚本与我们创建基线时的脚本不同,它假定目标数据库中已存在某种状态。这意味着脚本将仅包含模型中最近的更改。您可以在在线文档中详细了解更改的示例(修改 LastName 和 FirstName 属性的长度为 255)。下面的图 3,取自该示例,显示了一个由 ReadyRoll 生成的更改脚本:

此时,我们可以选择在部署前是否对脚本中的迁移逻辑进行进一步编辑。对于属性长度更改这种情况很简单,因此我们可以直接部署更改脚本,无需更多工作。
然而,其他更改需要仔细考虑以防止数据丢失。例如,如果我们合并列(例如,如果 FirstName 和 LastName 合并为一个名为 Fullname 的列),Entity Framework 将其脚本化为 CREATE COLUMN / DROP COLUMN 语句集。为了防止我们的数据因删除列而丢失,我们需要编辑迁移脚本以创建新列,然后合并并将数据复制到新列,最后删除旧列。

编辑生成的脚本可能需要一些时间,但最好是更有控制地进行,而不是冒着不知不觉中删除列及其所有数据的风险。直接使用 T-SQL 而不是通过抽象层工作的好处在于,我们可以将执行数据迁移的所有逻辑包含在生成的代码旁边。这些代码将在构建时由 T-SQL 解析器进行验证,然后再将其部署到数据库。所有语句都将在事务中一起执行,从而确保整个部署是原子的。
我们还可以选择是否让这些更改通过验证阶段,从而为我们的部署过程带来更多控制。这意味着针对 ReadyRoll 维护的影子数据库(从您的项目脚本自动创建)执行 T-SQL 更改脚本。验证阶段可以发现的错误类型包括缺少依赖项(例如,用户没有相关的登录名)、旧对象中的无效代码和语法错误。如果脚本在验证阶段失败,ReadyRoll 会提供错误详细信息并提供修复脚本的选项。
部署后,我们还可以使用 ReadyRoll 的 DBSync 工具来检查部署是否按预期进行。下面的图 5 显示了一个示例,其中原始/沙盒和目标数据库在数据库中的 Person 对象更改为增加 LastName 和 FirstName 属性的长度后都已同步。

由于 ReadyRoll 项目(显示在左侧)和沙盒数据库(显示在右侧)与我们打算进行的更改同步,因此我们知道部署已成功。
回滚模型更改——如何“向下”迁移
如果我们在部署数据库模型更改后决定要撤销该迁移,我们可以使用 ReadyRoll 来回滚特定的更改,而无需从头开始重新部署数据库(从而保留数据库中的数据)。
如果我们首先从项目中删除要回滚的迁移,然后就可以使用 ReadyRoll 的 DBSync 工具将数据库重新同步到修订后的项目模型。这可以通过在工具窗口中单击“刷新”按钮来完成,它将显示项目和沙盒数据库之间的对象差异。我们还可以以并排视图查看单个对象差异,项目模型版本在左侧,沙盒数据库版本在右侧。下面的图 6 显示了一个示例。

我们可以选择要回滚的对象并丢弃更改。这会将沙盒数据库与项目源同步,通过生成一个一次性脚本并将其应用于沙盒数据库。为此,ReadyRoll 使用其 DBSync 工具(该工具基于行业领先的架构比较工具 Redgate SQL Compare 的引擎构建),并为您节省了编写所有 SQL 代码的麻烦。
最后一步是确保 Entity Framework 与连接的数据库保持同步。这也可以通过 ReadyRoll 的 DBSync 工具来完成,通过跟踪 __MigrationHistory 表中的数据,包括表数据和回滚选定的对象,如下面的图 7 所示。

进一步的数据库更改管理技术
本文到目前为止介绍了如何将 ReadyRoll 与 Entity Framework 结合使用来设置基线以及向上或向下迁移更改。您还可以使用 ReadyRoll 来支持您的数据库更改管理流程,包括:
如何概览您的数据库资产
ReadyRoll 提供了一个选项,让我们可以在项目资产中包含一个*离线架构模型*,这意味着我们可以获得数据库对象级更改的只读视图。这是 ReadyRoll 通过使用 DBSync 工具提供的混合功能之一,借鉴了基于状态的数据库更改模型。离线架构模型允许我们在项目本身内审核表、架构、用户和类型等数据库对象的更改。这使得跟踪这些对象随时间推移的更改成为可能,例如使用源代码管理的*批注*命令。每当我们从沙盒数据库导入更改时,DBSync 工具都会根据正在导入的架构更改更新离线模型。它对于审计以及在开发进一步更改之前评估数据库的更高层结构非常有用。
下面的图 8 显示了离线模型如何按类型在子文件夹中存储数据库对象,使用它们的完全限定名,例如 *dbo\Tables\Person.sql*。

处理代码对象时如何节省时间
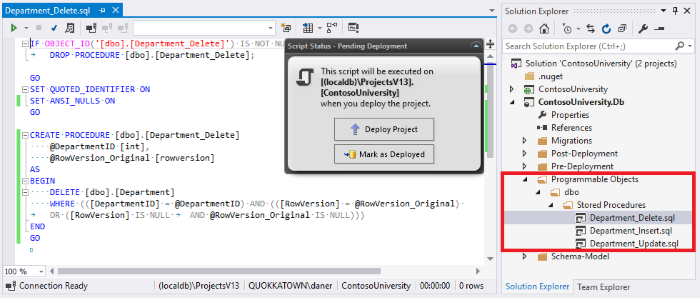
如果我们定期对代码对象(如存储过程、触发器或视图)进行更改,ReadyRoll 的*可编程对象*可以为我们节省时间。通过将所有支持的对象提取到幂等脚本文件中(例如,*dbo\Stored Procedures\Department_Update.sql*),我们可以通过简单地编辑现有文件来重用脚本。这意味着我们可以多次部署相同的对象,而无需每次都添加数字迁移脚本。不仅将每个数据库对象作为单独的文件进行源代码管理更加容易,而且在团队中有开发人员同时更改这些对象时,我们还可以更轻松地进行分支、合并和批注。
下面的图 9 显示了 ReadyRoll 的可编程对象结构,每个对象都有一个可访问的脚本。
项目日益增长时如何进行导航
我们中的许多人在数据库随着时间的推移而充斥着数百甚至数千个来自不同版本的脚本的环境中工作。对于那些正在考虑将迁移作为数据库更改管理方法的人来说,想到这堆不断增长的脚本有时可能会令人望而生畏。ReadyRoll 中的*语义版本控制*使管理这种情况和规划发布更加容易。
它将我们的迁移分隔到具有语义版本号的离散子文件夹中,因此我们可以将迁移分组到逻辑组中。例如,如果我们按版本分支,语义版本控制意味着每个版本分支都会获得一个唯一的引用号。我们可以使用此唯一引用号作为版本号的一部分(例如,1.2.0-RL125)在源代码管理中查找该版本。如果我们每次分支出新版本的代码时都创建一个新的 semver 文件夹,我们还可以减少数据库部署中发生冲突的可能性。这是因为语义版本控制确保编号在新分支时重置,或者当多个并发分支合并到一个分支时重置。如果允许版本编号在没有语义版本控制的情况下在分支和合并之间继续,脚本针对目标数据库的部署顺序可能与源代码管理中脚本的顺序不一致。这可能导致意外的部署问题,或者最坏的情况下,导致数据丢失。
如何纠正数据库漂移
本质上,基于迁移的数据库更改模型在开发点就引入了数据库更改的控制和监督。当开发和添加到源代码管理时,单个更改会被捕获在多个小型脚本中。然后按照预定义的顺序应用这些迁移脚本。但是,团队需要意识到,迁移*仅*对编写它的数据库版本有效。
在部署任何数据库迁移之前,我们应该检查源数据库和目标数据库是否处于迁移所期望的版本。如果目标数据库已进行了“热修复”或“进程外”更改,导致目标数据库版本“漂移”,则迁移脚本可能会对目标数据库产生意外的后果。例如,它可能会悄无声息地、意外地撤销为修复服务器上的严重问题而进行的更改。
因此,在部署之前检查数据库漂移是一种重要的风险缓解技术。一种方法是执行架构比较,以检查目标数据库是否与已知状态匹配。一些开发人员使用事件通知和 SQL 跟踪等技术。也有专门用于在漂移发生时提醒团队的工具,例如 DLM Dashboard(Redgate 的免费工具)。
ReadyRoll 也可以作为持续集成过程的一部分,通过在构建时使用其 DBSync 工具在源数据库和目标数据库之间执行架构比较来帮助您管理架构漂移。此过程会生成漂移报告和漂移校正脚本。报告详细说明了已从源代码控制基线漂移的对象。该脚本(如果执行)会将目标数据库与源代码控制重新同步,并撤销直接对目标数据库所做的更改。可以实现一个设置,以确保我们在部署校正脚本之前有机会对其进行审查。这是一个手动步骤,但在检测到漂移的情况下,这是一个重要的步骤。当然,如果团队严格遵循相同的开发和部署流程并将更改签入源代码管理,则不太可能发生漂移——但即使是最有纪律的团队也仍然容易受到意外事件的影响。
摘要
我根据手动数据库部署的痛点进行实际开发的经验开发了 ReadyRoll。它无法消除我们在按下发布按钮时自然会有的那一丝停顿,但它确实使这种体验的紧张程度大大降低。
它让您从开发之初就能够控制更改,支持更复杂的更改,并能够在部署前测试更改。
它还为更乐于使用应用程序代码的开发人员改善了使用 T-SQL 的体验。正如我们的客户之一,FlexiGroup 的高级 .NET 开发人员 Damian Haynes 所说:“一旦您向所有开发人员展示了导入表更改甚至查找数据的简便方法,他们都会成为 T-SQL 脚本作者。”
我已将本文中详细介绍的完整项目包含在一个压缩文件夹中——ContosoUniversity.PlusReadyRoll.zip。它包含 ASP.NET/Entity Framework 项目和 ReadyRoll 数据库项目。要一起使用这两个项目,您需要下载 ReadyRoll。Redgate 网站上提供免费的 28 天试用版。