
Stack Overflow 标签引擎 – 第 3 部分
5.00/5 (2投票s)
Stack overflow 标签引擎 - 第 3 部分
这是关于构建 Stack Overflow 标签引擎的迷你系列文章的第三部分。如果您还没有阅读 第一部分 或 第二部分,我建议您先阅读它们。
复杂布尔查询
Stack Overflow 标签引擎最强大的功能之一是它允许您对多个标签执行复杂的布尔查询,例如:
一种实现此功能的简单方法是编写如下代码,它利用 HashSet 来让我们高效地查找特定问题是否应被包含或排除。
var result = new List<Question>(pageSize);
var andHashSet = new HastSet<int>(queryInfo[tag2]);
foreach (var id in queryInfo[tag1])
{
if (result.Count >= pageSize)
break;
baseQueryCounter++;
if (questions[id].Tags.Any(t => tagsToExclude.Contains(t)))
{
excludedCounter++;
}
else if (andHashSet.Remove(item))
{
if (itemsSkipped >= skip)
result.Add(questions[item]);
else
itemsSkipped++;
}
}
主要问题是我们必须扫描 tag1 的所有 id,直到获得足够的匹配项,即 foreach (var id in queryInfo[tag1])。此外,我们还必须将 tag2 的所有 id 加载到 HashSet 中,以便我们可以检查匹配项。因此,当跳过的问题越来越多时,此方法会花费更长的时间,即对于较大的 skip 值或如果 tagsToExclude(即“忽略的标签”)数量很大,请参见 第二部分获取更多信息。
位图
那么我们能做得更好吗?是的,有一种相当成熟的机制可以处理这类查询,称为 位图索引。要使用它们,您必须预先计算一个索引,其中每个位都设置为 1 以指示匹配,否则设置为 0。在我们的场景中,这看起来像:
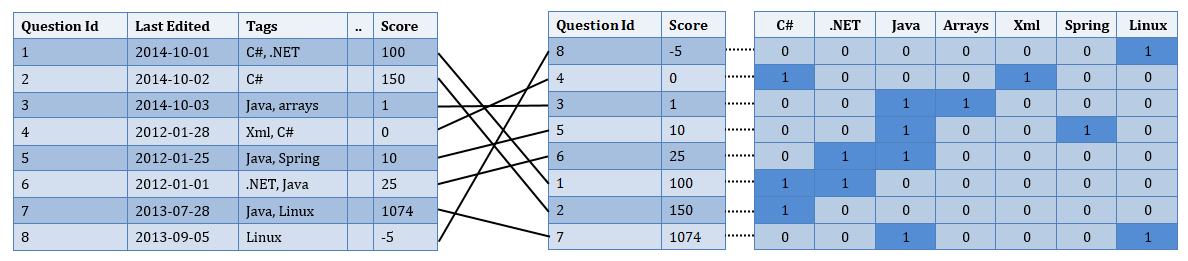
然后,只需对位(一次一个 byte)执行相关的按位运算即可,例如,如果您想获取带有 C# AND Java 标签的问题,则执行以下操作:
for (int i = 0; i < numBits / 8; i++)
{
result[i] = bitSetCSharp[i] & bitSetJava[i];
}
主要缺点是我们必须为每个排序顺序(LastActivityDate、CreationDate、Score、ViewCount、AnswerCount)为每个标签(C#、.NET、Java 等)创建位图索引,因此我们很快就会占用大量内存。2014 年 9 月的 Stack Overflow 数据集包含近 800 万个问题,因此以每字节 8 个问题计算,单个位图需要 976KB 或 0.95MB。加起来就是惊人的 **149GB**(0.95MB * 32,000 个标签 * 5 种排序顺序)。
压缩位图
幸运的是,有一种方法可以使用某种形式的 游程长度编码 来大量压缩位图。为此,我使用了出色的 EWAH 库 的 C# 版本。该库基于 Daniel Lemire 等人发表的论文 Sorting improves word-aligned bitmap indexes 中进行的研究。通过使用 EWAH,它还有一个额外的好处,那就是您无需解压缩位图即可执行按位运算。它们可以就地执行(有关如何执行此操作的示例,请参见 此提交,其中我向现有库添加了一个单独的就地 AndNot 函数)。
但是,如果您不想阅读 研究论文,下面的图显示了位图如何压缩成具有 1 个或多个位集的 64 位 字,以及重复的零或一的运行。因此,31 0x00 表示 31 个 64 位字(所有位都设置为 0)已编码为一个值,而不是 31 个单独的 字。
0 0x00
1 words
[ 0]= 17, 2 bits set ->
{0000000000000000000000000000000000000000000000000000000000010001}
31 0x00
1 words
[ 0]= 2199023255552, 1 bits set ->
{0000000000000000000000100000000000000000000000000000000000000000}
18 0x01
1 words
[ 0]= 64, 1 bits set ->
{0000000000000000000000000000000000000000000000000000000001000000}
48 0x01
3 words
[ 0]= 1048576, 1 bits set ->
{0000000000000000000000000000000000000000000100000000000000000000}
[ 1]= 9007199254740992, 1 bits set ->
{0000000000100000000000000000000000000000000000000000000000000000}
[ 2]= 9007199304740992, 13 bits set ->
{0000000000100000000000000000000000000010111110101111000010000000}
131 0x00
1 words
[ 0]= 536870912, 1 bits set ->
{0000000000000000000000000000000000100000000000000000000000000000}
....
为了说明可以实现的节省空间的效果,下表显示了具有不同数量设置位(1)的压缩位图的大小(以字节为单位)(作为比较,未压缩的位图为 1,000,000 字节或 0.95MB)。
| 设置的位数 | 大小(字节) |
| 1 | 24 |
| 10 | 168 |
| 25 | 408 |
| 50 | 808 |
| 100 | 1,608 |
| 200 | 3,208 |
| 400 | 6,408 |
| 800 | 12,808 |
| 1,600 | 25,608 |
| 32,000 | 512,008 |
| 64,000 | 1,000,008 |
| 128,000 | 1,000,008 |
正如您所见,直到我们超过 64,000 位(精确地说,是 62,016 位)时,我们才达到常规位图的大小。注意:在这些测试中,我将位设置在 800 万个可能位范围内的均匀分布。压缩也取决于设置了哪些位,因此这是最坏情况。位聚集在一起的程度越高(在同一个 byte 中),压缩效果越好。
因此,对于整个 Stack Overflow 数据集中的 32,000 个标签,位图压缩到惊人的 **1.17GB**,而未压缩的则为 149GB!
结果
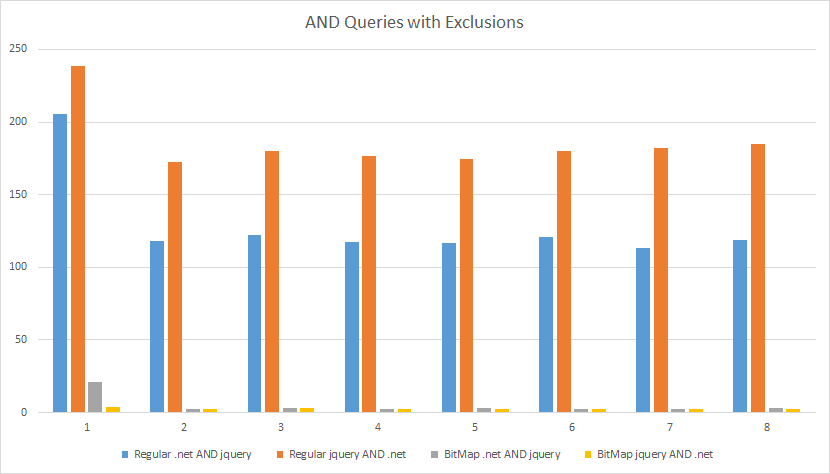
但是,与使用 HashSets 的简单查询(请参见上面的代码)相比,对压缩位图的查询是否实际更快?是的,它们确实更快,在某些情况下,差异非常显著。
正如您下面所看到的,对于 AND NOT 查询,它们要快得多,特别是与简单/常规代码需要超过 150 毫秒且压缩位图代码需要大约 5 毫秒的最坏情况相比(x 轴是排除/跳过的问次数,y 轴是时间(毫秒))。
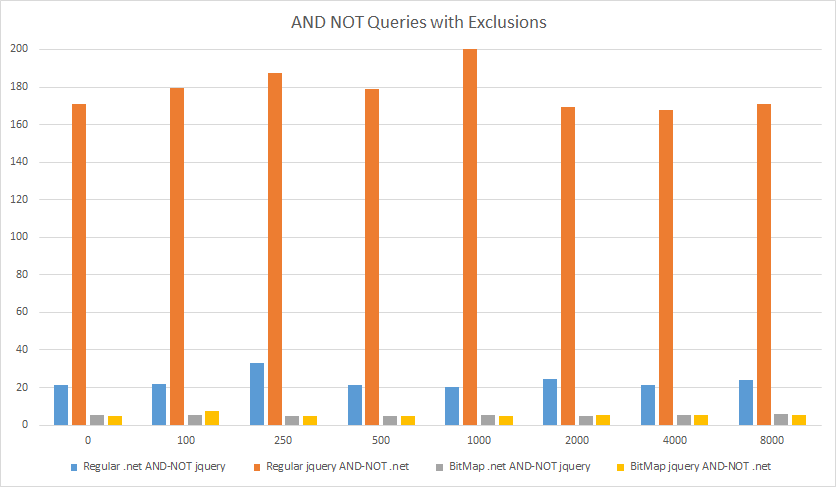
作为参考,有 194,384 个问题标记为 .NET,528,490 个问题标记为 jquery。
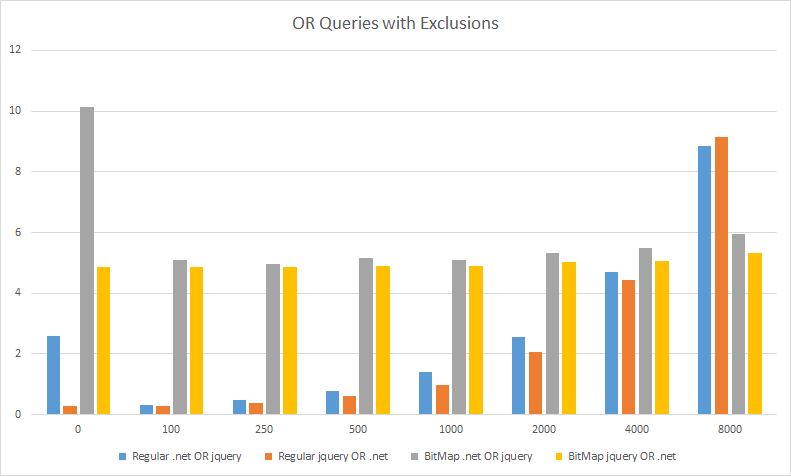
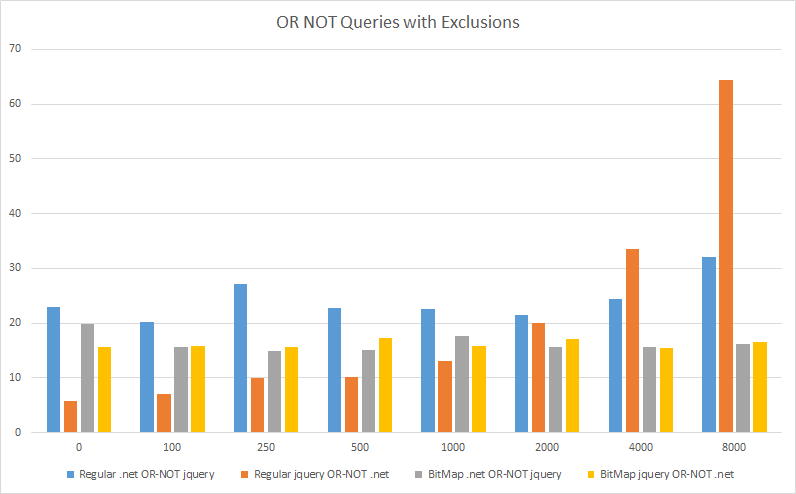
为了确保我公平,我应该指出,压缩位图查询对于 OR 查询来说速度较慢,如下所示。但请注意刻度,它们花费大约 5 毫秒,而常规查询花费大约 1-2 毫秒,因此压缩位图查询仍然很快!压缩位图查询的好处是,无论我们跳过多少问题,它们花费的时间都相同,而常规查询会随着排除/跳过的问次数的增加而变慢。
如果您有兴趣,所有查询类型的結果都可在此处获得。
{kind=link}
{kind=link}
延伸阅读
- 位图
- 实际应用
未来文章
但仍有更多内容需要实现。在未来的文章中,我希望涵盖以下内容:
- 目前,我的实现与垃圾回收器配合得不好,并且会产生大量分配。我将尝试重现 Stack Overflow 在与 .NET GC 斗争后遵循的“无分配”规则。

去年十月,我们遇到了一种情况,大量精心构造的请求导致我们的 Tag Engine 服务器(这是一个我们内部用来高效关联问题和标签的应用程序)资源利用率过高。
文章 Stack Overflow 标签引擎 – 第三部分 最初发表在我的博客 性能即特性! 上