
机器学习入门
4.50/5 (6投票s)
机器学习的宏观概览
什么是机器学习?
“机器学习是一个研究领域,它赋予计算机学习的能力,而无需显式编程。” - Arthur Smauel。
我们可以将机器学习视为一种自动化预测或建模任务的方法。例如,考虑一个电子邮件垃圾邮件过滤器系统,程序员不必手动查看电子邮件并制定垃圾邮件规则。我们可以使用机器学习算法,并向其输入数据(电子邮件),它将自动发现足够强大的规则来区分垃圾邮件。
机器学习如今已广泛应用于各种应用中,例如电子邮件中的垃圾邮件检测或电影推荐系统,这些系统会根据您的观看历史推荐您可能喜欢的电影。机器学习的优点和强大之处在于它会随着数据的增加而学习,因此我们提供的数据越多,它就越强大。.
机器学习的类型
机器学习有三种不同的类型:监督学习、无监督学习和强化学习。
监督学习
监督学习的目标是从标记的训练数据中学习一个模型,该模型使我们能够对未来数据进行预测。为了使监督机器学习有效,我们需要向算法提供两样东西:输入数据以及我们对其的了解(标签)。
前面提到的垃圾邮件过滤器示例是一个很好的监督学习例子;我们有一堆电子邮件(数据),并且我们知道每封电子邮件是垃圾邮件还是非垃圾邮件(标签)。

监督学习可分为两个子类别
1. 分类:用于根据过去的观察来预测类别或类标签,即我们有一个离散变量,您想将其区分为离散的分类结果。例如,在电子邮件垃圾邮件过滤器系统中,输出是离散的“垃圾邮件”或“非垃圾邮件”。
2. 回归:用于预测连续结果。例如,确定房屋价格及其受房屋房间数量的影响。输入数据是房屋的特征(房间数量、位置、面积(平方英尺)等),输出是价格(连续结果)。
无监督学习
无监督学习的目标是发现未标记数据中隐藏的结构或模式,它可以分为两个子类别
1. 聚类:用于将信息组织成有意义的簇(子组),而无需预先了解它们的含义。例如,下图显示了如何使用聚类来根据特征组织未标记的数据成组。

2. 降维(压缩):用于将高维数据减小到低维数据。更清楚地说,考虑这个例子。望远镜有 TB 级的数据,并非所有数据都可以存储,因此我们可以使用降维来提取这些数据中最具信息量的特征进行存储。降维也是可视化数据的良好选择,因为如果您有高维数据,可以将其压缩到 2D 或 3D 以方便绘制和可视化。
强化学习
强化学习的目标是开发一个系统,该系统可以根据与动态环境的交互来改进其性能,并且存在作为奖励的延迟反馈。即,强化学习是通过延迟奖励来学习的。棋类游戏是强化学习的一个经典例子,计算机决定一系列走法,奖励是游戏结束时的“赢”或“输”。
您可能会认为这类似于监督学习,其中奖励基本上是数据的标签,但核心区别在于这种反馈/奖励不是真相,而是衡量为实现特定目标而采取的行动有多好。
数据预处理
数据的质量以及其中包含的有用信息量对算法的学习效果有很大影响。因此,在使用数据集之前对其进行预处理非常重要。最常见的预处理步骤是删除缺失值, 将分类数据转换为适合机器学习算法的形状和特征缩放.
缺失数据
有时数据集中的样本会缺少一些值,我们希望在将它们传递给机器学习算法之前处理这些缺失值。我们可以遵循多种策略
1. 删除带有缺失值的样本:这种方法最方便,但我们最终可能会删除过多的样本,从而丢失可能有助于机器学习算法的宝贵信息。
2. 插补缺失值:与其删除整个样本,不如使用插值来估计缺失值。例如,我们可以用该列的平均值替换缺失值。
分类数据
一般来说,特征可以是数值型的(例如,价格、长度、宽度等)或分类型的(例如,颜色、大小等)。分类特征进一步分为标称和有序特征。
有序特征可以排序。例如,大小(小、中、大),我们可以按大小顺序排列大 > 中 > 小。而标称特征没有顺序,例如,颜色,说红色比蓝色大没有意义。
大多数机器学习算法都要求您将分类特征转换为数值。一种解决方案是为每个值分配一个从零开始的不同数字。 (例如 小à 0, 中à 1, 大à 2)
这对有序特征很有效,但可能对标称特征(例如,蓝色à 0, 白色à 1, 黄色à 2)造成问题,因为即使颜色没有顺序,学习算法也会假设白色大于蓝色,黄色大于白色,这是不正确的。
为了解决这个问题,我们可以使用独热编码,即为标称特征的每个唯一值创建一个新特征。

在上面的例子中,我们将color特征转换为三个新特征红色, 绿色, 蓝色并使用二进制值来表示颜色。例如,具有“红色”颜色的样本现在编码为(红=1,绿=0,蓝=0)
特征缩放
假设我们有包含两个特征的数据,一个特征的范围是 1 到 10,另一个特征的范围是 1 到 1000。如果算法使用距离作为其工作的一部分,或者它试图最小化均方误差,那么可以肯定地认为该算法将花费大部分时间专注于特征 2。
为了解决这个问题,我们将使用标准化,即将不同的特征缩放到相同的尺度。我们将特征缩放到 [0, 1] 的范围

 i 是一个特定样本,
i 是一个特定样本, 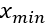 是特征中的最小值,
是特征中的最小值,  是最大值。
是最大值。
另一种方法是标准化
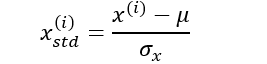
其中,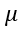 是该特征所有样本的平均值,
是该特征所有样本的平均值,  是该特征的标准差。
是该特征的标准差。
下表显示了标准化和归一化对样本输入数据的处理结果
训练数据 vs 测试数据
我们通常将输入数据分为学习数据集和测试数据集。然后,我们对学习数据集运行机器学习算法以生成预测模型。稍后,我们使用测试数据集来评估我们的模型。
重要的是,测试数据应与用于训练的数据分开,否则我们将算是作弊,因为例如,生成的模型可能会记住数据,因此如果测试数据也是训练数据的一部分,那么我们对模型的评估分数将高于实际分数。
数据通常被分割为 75% 的训练数据和 25% 的测试数据,或 2/3 的训练数据和 1/3 的测试数据。需要注意的是训练集越小,算法发现规则的难度就越大。
此外,在分割数据时,您需要保持类别比例和总体统计数据,否则某些类别在训练数据集中将代表不足,而在测试数据集中代表过多。
例如,您可能有 100 个样本,总共有 80 个样本被标记为 A 类,其余 20 个样本被标记为 B 类。您需要确保在分割数据时保持这种表示。
避免此问题并确保所有类别都在训练和测试数据集中都有代表的一种方法是分层。它是重新排列数据的过程,以确保每个数据集都能很好地代表整体。在我们之前的例子中(80/20 个样本),最好排列数据,使得在每个数据集中,每个类别都占两个类别的约 80:20 的比例。
交叉验证
构建机器学习模型时的关键步骤是估计模型在模型未见过的数据上的性能。我们希望确保模型能够很好地泛化到新的、未见过的数据。
在一种情况下,机器学习算法具有不同的参数,我们希望调整这些参数以达到最佳性能。(注意:机器学习算法的参数称为超参数)。另一种情况是,有时我们想尝试不同的算法并选择性能最佳的算法。以下是一些使用的技术。
留出法
我们只需将数据分成训练集和测试集。我们使用训练集训练算法以生成模型。为了评估不同的算法,我们使用测试数据来评估每种算法。
但是,如果我们在一选算法过程中反复使用相同的测试数据集,那么测试数据现在就成了训练数据的一部分。因此,当我们使用测试数据进行最终评估时,生成的模型会偏向测试数据,并且性能分数会偏高。
留出验证
与之前一样,我们将数据分成训练集和测试集。然后,将训练数据进一步分成训练集和验证集。
训练数据用于训练不同的模型。然后,使用验证数据计算每个模型的性能,并选择最佳模型。最后,该模型用于测试集以评估性能。下图说明了这一想法。

但是,由于我们多次使用验证集,留出验证对数据分区方式敏感,这就是 K 折交叉验证试图解决的问题。
K 折交叉验证
最初,我们将数据分成训练集和测试集。此外,训练数据集被分成 K 个块。
假设我们将使用 5 折交叉验证,训练数据集被分成 5 个块,训练阶段将进行 5 次迭代。在每次迭代中,我们使用一个块作为验证数据集,其余的块组合在一起形成训练数据集。
这与留出验证非常相似,只是在每次迭代中,验证数据都不同,这消除了偏差。每次迭代都会生成一个分数,最终分数是所有迭代的平均分数。与之前一样,我们选择最佳模型,并使用测试数据进行最终性能评估。
结论
在本文中,我试图从宏观角度介绍机器学习。我特意避免讨论任何具体的机器学习算法,因为这需要大量的篇幅。如果您对机器学习感兴趣,我建议您查阅“进一步阅读”部分的一些资料。
延伸阅读
1. 机器学习:一门由斯坦福大学副教授 Andrew Ng 主讲的 Coursera 课程。该课程广泛介绍了机器学习、数据挖掘和统计模式识别。
2. 使用 scikit-learn 进行机器学习 [第一部分,第二部分]:关于使用 scikit-learn 进行机器学习的初学者/中级教程。
3. Python 机器学习:Sebastian Raschka 著。本书讨论了机器学习的基础知识以及如何使用 Python 在实际应用中利用这些知识。