
使用 Python 进行 Web 抓取:第一部分
4.66/5 (16投票s)
使用 Python 3 抓取网站
引言
本文旨在通过 Python 中可用的各种库学习网络爬虫。如果您熟悉 Python,可以参考本文。这是一篇从零开始的完整指南。
注意:我坚持使用 3.x 版本,这保证了未来的可用性。
背景
对于那些从未听说过网络爬虫的人。
考虑这种情况:一个人想在 Python 的控制台/终端中打印两个数字。他/她会使用类似这样的东西
print("1 2")
那么,如果他/她想打印大约 10 个数字怎么办?嗯,他/她可以使用循环。好的,现在我们回到我们的情况,如果一个网站包含一个人的信息,而您想将其保存在 Excel 中?您会怎么做?您会复制一个人的信息,然后将他的联系方式和其他内容添加到几行中。如果信息是关于 1000 个人怎么办?嗯,您需要编写一个机器人来完成这项工作。
Python 中有很多库可供选择。我将尝试解释成为一名全能网络爬虫所需的所有重要内容。
使用库
使用默认的 urllib.request 库
Python 有自己的网络爬虫工具,对于一些高级爬取可能不那么容易,但对于基本爬取很有用。有一个名为 requests 的库,它是比这个更好的替代品,而且更稳定,所以我在这里会比在 requests 中涵盖更多内容。
好的,打开您喜欢的 Python 编辑器并导入这个库。
[code1]
import urllib.request
然后输入以下代码
# SWAMI KARUPPASWAMI THUNNAI
import urllib.request
source = urllib.request.urlopen("https://codeproject.org.cn")
print(source)
在这里,urllib.request.urlopen 获取网页。现在,当我们执行这个程序时,我们会得到类似这样的结果

让我们仔细看看这个输出。我们在一个地址上得到了一个响应对象。所以,这里我们实际上得到了一个地址。http.client.HTTPResponse 是一个类。从中,我们使用了一个对象,它返回了一个地址。所以,为了看到值,我们将使用一个指针来查看它里面实际有什么。将上面的 print 语句修改为指针,如下所示:
print(*source)
现在执行代码,您将看到类似这样的内容

您可能会问,嘿,这是什么?嗯,这是您请求的网页的 HTML 源代码。
看到这个,每个人都会产生一个常见的想法:哦,耶!我得到了 HTML 代码,现在我可以使用正则表达式来获取我想要的东西 :) 但您不应该这样做。有一个专门的解析库,我稍后会解释。
[code2]
不使用指针也可以实现同样的效果。只需将 *source 替换为 source.read()。
抓取图像
好的,那么如何用 Python 抓取图像呢?现在让我们来看一个网站,我们可以使用这个 CodeProject 网站本身,非商业用途。打开 CodeProject 的主页,您会看到他们的公司标志,右键单击他们的标志并选择查看图片,您会看到这个

好的,现在获取网址 https://codeproject.global.ssl.fastly.net/App_Themes/CodeProject/Img/logo250x135.gif
{kind=link}
注意最后的几个字母,它们表示图片的扩展名,在我们的例子中是 gif。现在我们可以将其保存到我们的磁盘。
Python 有一个名为 urllib.request 的模块,可以在 request.py 中看到,它有一个名为 urlretrieve 的成员函数,用于将文件从网络本地保存,我们将使用它来保存我们的图像。
[code 3]
# SWAMI KARUPPASWAMI THUNNAI
import urllib.request
# Syntax : urllib.request.urlretrieve(arg1,arg2)
# arg1 = web url
# arg2 = path to be saved
source = urllib.request.urlretrieve
("https://codeproject.global.ssl.fastly.net/App_Themes/CodeProject/Img/logo250x135.gif",
"our.gif")
上面的代码会将图像保存到 Python 文件所在的目录。第一个参数是 url,第二个参数是文件名。请参见代码中的语法。
urllib 的内容就到这里。我们需要转向 requests。这很重要,因为我发现它更稳定。使用 urllib 可以完成的所有操作都可以使用 requests 完成。
请求
Requests 不会随 Python 一起安装。您需要安装它。要安装此库,只需运行以下 pip 命令。
PIP 命令pip install requests
或者您可以使用从源代码安装的常规方法。这由您决定。尝试导入 requests 以检查 requests 是否已成功安装。
import requests
导入此语句时,您不应收到任何错误。
我们将尝试这段代码
[code 4]
# SWAMI KARUPPASWAMI THUNNAI
import requests
request = requests.get("https://codeproject.org.cn")
print(request)
在这里,我们将查看第 3 行(我从 1 开始计数)在该行中 request 是一个变量,requests 是一个模块,它有一个名为 get 的成员函数,我们将我们的网页链接作为参数传递给它。此代码将生成此输出
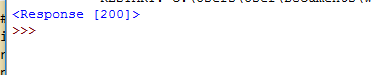
所以,这只不过是一个 http 状态码,表示成功。
[code 5]:将 print 语句中存在的变量修改为 => request.content 输出将是网页的内容,也就是 HTML 源代码。
什么是用户代理?
在网络中,当数据从源传输到目的地时,数据会被分成更小的块,称为数据包,这是互联网中数据包的一个简单定义。通常,数据包头包含有关源和目的地的信息。我们只会分析对网络爬虫有用的数据包头。
我将向您展示为什么这很重要,首先,我们将启动我们自己的服务器 并使其监听本地机器的 IP 127.0.0.1 @ 端口 1000,在这里,我们不连接到 code project,而是通过 http://127.0.0.1:1000 连接到这个服务器,您会在服务器上看到类似这样的内容

让我们仔细看看这个消息,当我们使用[code 6](这与 code 4 相同。我只是更改了目标地址)连接到服务器时,您会发现用户代理是 python-requests,以及它的版本和其他详细信息。
这个 user-agent 表明请求来自机器而不是人类,因此一些高级网站会阻止您进行爬取。我们现在该怎么办?
更改用户代理
这是我们的 code 6。
# SWAMI KARUPPASWAMI THUNNAI
import requests
request = requests.get("http://127.0.0.1:1000")
print(request.content)
我们将为上面的代码添加自定义头。
在维基百科上打开此链接以了解用户代理 https://en.wikipedia.org/wiki/User_agent,您会在那里找到一个用户代理示例,好的,我们将出于您的方便使用它。我将展示那里的示例。
维基百科示例中的用户代理Mozilla/5.0 (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Mobile/7B405
Python 的字典用于添加用户代理,键 = User-Agent ; 值 = 任何用户代理,例如我们将取上面的值。
所以我们的代码将是这样的[code 7]
agent = {'User-Agent': 'Mozilla/5.0 (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us)
AppleWebKit/531.21.10 (KHTML, like Gecko) Mobile/7B405'}
好的,现在我们可以在请求时添加这个字典来更改用户代理
request = requests.get("http://127.0.0.1:1000",
headers=agent) #see the additional argument named headers
执行后,您会看到 user-agent 从 python-requests 更改为 Mozilla Firefox,我如何相信?请看下面的截图

到目前为止我们做了什么?我们只用不同的方法获取了页面源代码,所以现在我们将收集数据,让我们开始吧!
库 3:Beautifulsoup: pip install beautifulsoup4
那么 beautiful soup 是什么?它是一个爬取库吗?实际上 beautifulsoup 是一个用于解析 HTML 的解析库。
HTML?是的,HTML,记住以上所有方法都用于获取页面源代码,也就是 HTML 源代码。
重要提示:我仅将此网站作为教育目的的示例,仅此而已。我使用此网站是因为它具有清晰的布局和分页,这对于爬取您有权访问的其他网站是最佳示例。我已警告您,如果使用不当,爬取可能会导致处罚。不要牵连我。:)
好的,让我们开始主题
重要提示
HTML 中主要用于网站爬取的基础标签
标签:(快速提示)<title> </title> => 为网页添加标题<p> </p> => 段落<a href="someLink"> </a> => 链接<h(x)> </h(x)> => 标题标签以及其他一些标签,如 div - 容器等。这毕竟不是 HTML 教程,
[如何判断我们是否处于更安全的爬取状态 - 识别网站是否不允许我们爬取]
网站的结构是这样的

我们要做的就是爬取所有粗体字(例如,图片中看到的 Royal India Restaurant)。
步骤
右键单击网站上的粗体字(Royal India Restaurant)并选择检查元素。您会看到类似这样的内容

所以我们得到了正确的 HTML 标签。看一眼 - 您会发现类似这样的内容。
<a class="class name" .... 这里 a 表示链接,正如我在快速提示中所解释的。所以粗体字是属于名为 "listing-name" 的类的链接。那么您能猜到如何获取所有粗体名称吗???
答案:爬取属于该类名的所有链接将为我们提供所有餐厅的名称。
好了,我们将编写一个脚本来首先爬取所有链接。为了获取 HTML 源代码,我将使用 requests,为了解析 HTML,我将使用 BeautifulSoup。
好的,您可能会发现这段代码会显示页面内容。
[code 9]
# SWAMI KARUPPASWAMI THUNNAI
import requests
from bs4 import BeautifulSoup
if __name__=="__main__":
req = requests.get("https://www.yellowpages.com.au/search/listings?
clue=Restaurants&locationClue=&lat=&lon=&selectedViewMode=list")
#req.content = html page source and we are using the html parser
soup = BeautifulSoup(req.content,"html.parser")
print(soup)
不,这不会显示页面源代码,输出将是这样的
引用我们重视为客户提供内容的质量,为了维持这一点,我们希望确保是真实的人在访问我们的信息。
.
.
.
<form action="/dataprotection" method="post" name="captcha">
为什么会发生这种情况?
当在线数据保护服务检测到您的计算机网络发出的请求似乎违反了我们网站的使用条款。时,就会出现此页面。
我在真实世界的爬取中告诉过您,来自 Python 的请求会被阻止。当然,我们都在违反他们的条款和条件,但这可以通过添加用户代理轻松绕过,我在[code 9]中添加了用户代理,当您运行代码时,这段代码将起作用,我们将获得页面源代码。所以我们现在发现我们违反了他们的条款和条件,我们不应该再继续爬取了。所以我在这里结束了,只是展示了网站第一页上抓取的名称!
以下是破解安全的方法 - 仅供教育目的。
现在我们的修改后的 [code 9]
# SWAMI KARUPPASWAMI THUNNAI
import requests
from bs4 import BeautifulSoup
if __name__=="__main__":
agent = {'User-Agent': 'Mozilla/5.0 (iPad; U; CPU OS 3_2_1 like Mac OS X;
en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Mobile/7B405'}
req = requests.get("https://www.yellowpages.com.au/search/listings?
clue=Restaurants&locationClue=&lat=&lon=&selectedViewMode=list",headers=agent)
#req.content = html page source and we are using the html parser
soup = BeautifulSoup(req.content,"html.parser")
for i in soup.find_all("a",class_="listing-name"):
print(i.text)
将产生这个

我在这里结束了爬取,并且网站没有再被爬取。我强烈建议您也这样做,以免影响任何人。
一个完整的爬取示例,用于熟悉爬取
目标网站:https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&ns=1
在开始爬取此网站之前,我想解释一下网站上可能看到的通用布局。一旦确定了布局,我们就可以根据它进行编码。
1. 信息在一个长页面上
如果这是我们的情况,那么我们编写一个脚本来单独爬取单个页面会更容易。
2. 分页
如果一个网站具有分页布局,该网站将有多个页面,如 page1、page2、page3 等等。
我们的示例爬取网站确实有分页布局,请遵循目标网站 https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&ns=1
然后向下滚动,您会看到类似这样的内容

这就是分页。在这种情况下,我们需要编写一个脚本来访问每个页面并爬取信息,我将在下面详细介绍如何爬取分页。
3. AJAX 旋转器
我们需要使用 selenium 来处理这类网站,我也会在后续/同一篇文章中解释如何使用 selenium。
关于上述链接的分页爬取说明:https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&ns=1
在这种情况下,我们将首先爬取所有可用的页面链接(参见上图),您会发现类似 1,2,3,...... Next> 之类的内容,所有这些都是 HTML 中的 <a> 标签链接,但不要爬取这些链接。如果您爬取这些链接,就会发生这种情况。您将获得第 1、2、3...9 页的页面链接,但无法获得后续页面的链接,因为您有Next > 链接挡住了后面的链接。
运行以下代码并查看输出[code 10]:
#Scrapes for 9 pages only
def Scrape(weblink):
r = requests.get(weblink)
soup = BeautifulSoup(r.content,"html.parser")
for i in soup.find_all("a",class_="available-number pagination-links_anchor"):
print("https://www.yelp.com"+i.get("href"))
print(i.text)
您只会得到前 9 页的输出,所以为了获取所有页面的链接,我们将要爬取下一个链接。
访问链接并检查下一个链接

所以您会发现下一个链接属于一个名为 u-decoration-none next pagination-links_anchor 的类。
爬取链接将为您提供下一个页面的链接,所以如果您爬取第 1 页,它将为您提供第 2 页的链接,如果您爬取第 2 页,然后您会得到第 3 页的链接,这有意义吗?
递归...!:)
def scrape(weblink):
r = requests.get(weblink)
soup = BeautifulSoup(r.content,"html.parser")
# Do some scraping for the current page here
for i in soup.find_all("a",class_="u-decoration-none next pagination-links_anchor"):
print("https://www.yelp.com"+i.get("href"))
scrape("https://www.yelp.com"+i.get("href"))
现在我们可以做任何我们想做的事情。
我们将以餐厅名称为例爬取所有餐厅的名称。
def scrape(weblink):
print(weblink)
r = requests.get(weblink)
soup = BeautifulSoup(r.content,"html.parser")
for i in soup.find_all("a",class_="biz-name js-analytics-click"):
print(i.text)
for i in soup.find_all("a",class_="u-decoration-none next pagination-links_anchor"):
print("https://www.yelp.com"+i.get("href"))
scrape("https://www.yelp.com"+i.get("href"))
这将产生类似这样的输出
引用https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&ns=1
Extreme Pizza
B Patisserie
Cuisine of Nepal
ABV
Southern Comfort Kitchen
Buzzworks
Frances
The Morris
Tacorea
No No Burger
August 1 Five
https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&start=10
https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&start=10
Extreme Pizza
Gary Danko
Italian Homemade Company
Nopa
Sugarfoot
Big Rec Taproom
El Farolito
Hogwash
Loló
Kebab King
Paprika
https://www.yelp.com/search?find_desc=Restaurants&find_loc=San+Francisco%2C+CA&start=20
您会发现Extreme pizza 重复出现 2 次。这只不过是酒店的赞助广告,会显示在每页的第一个位置。我们可以编写一个脚本来跳过第一个条目。条件语句可以做到。我不需要向初学者解释这一点。
使用 Burp Suite 和 Firefox Developer Edition 辅助复杂的 POST 请求
开始之前,请在此处下载 burp suite:https://portswigger.net/burp/communitydownload 并注意 burpsuite 的社区版已足够。除非您进行安全测试,否则不需要专业版。
- 首先转到 burp 并检查代理服务是否已启用。
- 打开 firefox dev edition 以在目标代理网络上进行侦听。
- 转到代理以捕获
get和post请求。
我知道遵循以上三个步骤很困难,所以我制作了一个视频,以便您更容易理解。
终极 Selenium 指南
到目前为止,我们已经使用了一些库进行了一些非常基本的爬取。现在,我们将使用 web drivers 进行完整的浏览器自动化,这将非常有趣地观看...
安装 selenium 的最佳方法是下载源代码 https://pypi.python.org/pypi/selenium
好的,安装 Selenium 后,通过导入 webdriver 来测试 selenium 的工作情况
from selenium import webdriver
如果执行此行,则不应出现任何错误。如果没有错误,那么我们将开始,从导入模块中,您会找到类似 webdriver 的东西,是的,我们将使用 webdrivers 来自动化浏览器。
好的,有很多 web drivers 可以完成相同的任务,但我只会介绍两种。
- chrome driver:用于实际爬取
- phantomjs:用于无头爬取
- 下载 chrome driver:https://sites.google.com/a/chromium.org/chromedriver/downloads
- 下载 PhantomJs:http://phantomjs.org/download.html
Chrome Driver
现在我们将看到如何使用 Chrome driver。一旦您测试了 chrome driver 已正确安装,然后执行以下操作。首先,建议将 chromedriver 放置在静态位置,例如 C:\\chromedriver.exe。这是因为您可以避免大量的内存消耗(字面意思)。我的意思是,如果您将其放在 Python 脚本附近,它就可以了,但对于单独的项目,您需要在每个地方放置 chromedriver,这会导致很多麻烦。
好的,现在看看 code 11,这段代码将打开 Google。
[CODE 11]
from selenium import webdriver
# we are going to use the Chrome Driver so we have used Chrome
browser = webdriver.Chrome("E:\\chromedriver.exe")
#Get the website
browser.get("https://www.google.com")
get 函数将获取作为参数传递的网站链接!现在我们将打开和关闭浏览器。为了关闭浏览器,我们将使用 close() 方法。
关闭浏览器的语法webdriver.close()
您会发现 webdriver 关闭的浏览器并没有关闭。这可以通过使用 browser.quit()方法完成。[code 12]
理解 ID、name 和 css_selectors
ID
id 全局属性定义了一个唯一的标识符 (ID),它在整个文档中必须是唯一的。它的目的是在链接(使用片段标识符)、脚本或样式(使用 CSS)时识别元素。
参考:MDN
在此处查看示例 ID

好的,现在我们将尝试使用 id 点击按钮!
在这里,您会找到 CANCEL 按钮。右键单击Cancel按钮并检查元素,您会看到类似这样的内容

一旦我们点击Cancel按钮,它将把我们重定向到 CodeProject 的主页,所以我们将使用 selenium 来自动化这个过程,好的,让我们开始吧![code - 13]
#SWAMI KARUPPASWAMI THUNNAI
from selenium import webdriver
if __name__=="__main__":
browser = webdriver.Chrome("E:\\chromedriver.exe")
#get the url
browser.get("https://codeproject.org.cn/Questions/ask.aspx")
#click the cancel button using id
cancel_button = browser.find_element_by_id("ctl00_ctl00_MC_AMC_PostEntry_Cancel")
cancel_button.click()
看看这一行 [cancel_button = browser.find_element_by_id("ctl00_ctl00_MC_AMC_PostEntry_Cancel")] 我们正在通过 ID 查找元素并单击它。之后,我们什么都不做,一旦按钮被点击,url 就会重定向到主页,因为我们点击了Cancel按钮。
理解 Name 标签
现在,打开Google^并开始检查搜索面板,您会发现类似这样的内容

到目前为止,我们已经打开了一个页面,点击了一个按钮,并获取了页面源代码。现在我们要填写一个输入框,所以从现在开始我们需要更多的关注,因为我们正在从基础转向高级!
导入 keys 以便发送关键字
from selenium.webdriver.common.keys import Keys
好的,我们将看一个例子,如何自动化谷歌搜索[code - 14]
# SWAMI KARUPPASWAMI THUNNAI
# CODE-14
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome("E:\\chromedriver.exe")
browser.get("https://www.google.com")
name = browser.find_element_by_name("q")
keyword = "Codeproject"
#Use send_keys to send the keywords
# NOTE: Do not use the webdriver like in here browser.send_keys("something")
# Webdriver does not have that kind of attribute
# Use the actual variable which is used to find the element
# in our case it is "name"
name.send_keys(keyword)
所以,send_keys(arg) 将关键字作为参数,并将关键字输入到输入框中。
理解 css_selectors
选择器定义了 CSS 规则集要应用于哪个元素。更多参考:https://mdn.org.cn/en-US/docs/Web/CSS/CSS_Selectors
[code 15]:这段代码将使用 css_selectors 搜索 duckduckgo
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
if __name__ == "__main__":
search_for = "apples"
website = "https://duckduckgo.com/"
browser = webdriver.Chrome()
browser.get(website)
search = browser.find_element_by_css_selector("#search_form_input_homepage")
search.send_keys(search_for+Keys.ENTER) # This will be fill apples and
# hit ENTER key automatically
获取 CSS 选择器的最简单方法是使用 Firefox Developer Edition

在接下来的系列文章中,我将更新更多关于 Selenium 的内容。
关注点
我最想传达给您的一句话是
我没有违反任何网站的规则,也没有违背任何网站的条款和条件。我要求用户明智地使用这些知识造福人类,而不是用于我不会鼓励您进行的网站剥削。
未来的文章将有更多内容。
请填写一份调查问卷。如果这篇文章成功,我会为您处理。