
MFC 序列化的全部内容
描述了 MFC 序列化机制的所有方面
目录
- 背景
- 什么是序列化
- 它是如何工作的
- 注意事项
- 为什么我不能多次调用 ar.GetObjectSchema()?
- 序列化基类和派生类
- 第一种解决方案:在派生类中完成所有序列化
- 第二种解决方案:将架构弹回 CArchive 中
- 第三种解决方案:考虑使用“不要调用我们,我们会调用您”设计模式来重构 Serialize 函数
- 第四种解决方案:将基类架构存储为类的第一个成员
- 序列化纯基类
- 使用文档/视图进行序列化
- 不使用文档/视图进行序列化
- 序列化普通旧数据类型
- 序列化 CArray 模板集合
- 序列化到进程内存以及从进程内存序列化
- 序列化到共享进程内存以及从共享进程内存序列化
- 序列化到套接字以及从套接字序列化
- 序列化任意字节流
- 序列化 Windows SDK 数据结构
- 序列化 STL 集合
- 序列化 STL 数据类型
- 序列化扁平 C 风格数组
- 序列化枚举类型
- CObject 派生类的序列化版本控制
- 非 CObject 类的序列化版本控制
- 注意事项
- 使用代码
- 历史
引言
数据结构的世界是广阔的。当我们需将这些巨大的数据块写入磁盘、内存或套接字,或者从中读取时,MFC 序列化是每个程序员工具箱中的强大工具。
背景
序列化自 MFC(微软基础类库)首次推出以来就是其一部分,但我感觉它从未得到应有的重视,因为它在很大程度上是未被充分文档化的。演示序列化的 SDK 示例非常有限,仅涵盖了普通旧数据和 CObject 派生类及集合的序列化。然而,通过适当的扩展,我们可以序列化任何存在的数据结构、STL 集合、用户定义的集合、任何集合(包括扁平 C 风格数组)。毫无疑问,这是将分层数据存储到磁盘、内存或套接字以及从中检索数据的最强大、最高效、最快捷的方式。MFC 序列化支持对磁盘、内存和套接字的读写。写入内存对于进程间通信(如剪贴板剪切/复制/粘贴操作)非常有用,而写入套接字则在与远程机器进行网络通信时非常有用。本文将介绍使用 MFC 提供的类的普通 MFC 序列化,如何序列化 STL 集合,如何序列化普通的 Windows SDK 数据结构,如何序列化 C 风格数组,如何序列化到进程和共享内存,以及如何序列化到套接字和从套接字序列化。此外,我还将演示如何在有或没有文档/视图架构的情况下(例如在控制台应用程序和 TCP/IP 服务器中)使用 MFC 序列化。
什么是序列化
MSDN 文档给出了最好的描述
序列化是将对象转换为字节流以便存储对象或将其传输到内存、数据库或文件的过程。其主要目的是保存对象的状态,以便在需要时能够重新创建它。相反的过程称为反序列化。
MFC 序列化实现了二进制和文本序列化。二进制通过移位运算符(<<、>>)和 WriteObject / ReadObject 函数处理。文本序列化通过 ReadString / WriteString 函数处理。
MFC 序列化提供了对 C++ CObject 派生类的带版本控制的序列化。通过适当的扩展,它也可以为非 CObject 派生类提供序列化。然而,在这些情况下,版本控制需要手动处理。
它是如何工作的
MFC 序列化的核心是 CArchive 对象。CArchive 没有基类,它与 CFile 和 CFile 的派生类(如 CSocketFile、CSharedFile 或 CMemFile)紧密耦合工作。CArchive 内部封装了一个字节数组,该数组根据需要动态增长,并写入或读取自 CFile 或 CFile 派生对象。
CFile– 提供到磁盘或从磁盘的序列化CMemFile– 提供到进程内存或从进程内存的序列化CSharedFile– 提供到或从其他进程可访问的进程共享内存的序列化CSocketFile– 为网络通信提供到CSocket或从CSocket的序列化- 你还可以通过命名管道、RPC 和其他 Windows 进程间通信机制进行序列化
CArchive 提供了普通旧数据和带版本控制的 C++ CObject 派生类的序列化。要使一个 CObject 类可序列化,你只需要添加一个宏
// In the class declaration DECLARE_SERIAL(CRoot) // In the class implementation IMPLEMENT_SERIAL(CRoot, CObject, VERSIONABLE_SCHEMA | 1)
这两个宏会向你的类中添加全局提取运算符 >>(它调用 CArchive::ReadObject)、静态函数 CreateObject 和 CRuntimeClass 成员变量。CRuntimeClass 结构体有一个 m_lpszClassName 成员,它存储了你类名的文本表示。CRuntimeClass 还有一个 m_wSchema,它保存了你类的版本信息。
这些宏在内部展开为以下代码
//
// DECLARE_SERIAL(CRoot) expands to
//
public:
static CRuntimeClass classCRoot;
virtual CRuntimeClass* GetRuntimeClass() const;
static CObject* PASCAL CreateObject();
AFX_API friend CArchive& AFXAPI operator >> (CArchive& ar, CRoot* &pOb);
//
// IMLEMENT_SERIAL(CRoot, CObject, VERSIONABLE_SCHEMA | 1) expands to
//
CObject* PASCAL CRoot::CreateObject()
{
return new CRoot;
}
extern AFX_CLASSINIT _init_CRoot;
AFX_CLASSINIT _init_CRoot (RUNTIME_CLASS(CRoot));
CArchive& AFXAPI operator >> (CArchive& ar, CRoot * &pOb)
{
pOb = (CRoot *)ar.ReadObject(RUNTIME_CLASS(CRoot));
return ar;
}
AFX_COMDAT CRuntimeClass CRoot::classCRoot =
{
"CRoot", // Name of the class
sizeof(class CRoot), // size
VERSIONABLE_SCHEMA | 1, // schema
CRoot::CreateObject, // pointer to CreateObject function used to intantiate object
RUNTIME_CLASS(CObject), // Base class runtime information
NULL, // linked list of the next class always NULL
&_init_CRoot // pointer to AFX_CLASSINIT structure
};
CRuntimeClass* CRoot::GetRuntimeClass() const
{
return RUNTIME_CLASS(CRoot);
}
这里没有插入运算符 <<,因为 CArchive 通过在全局命名空间中声明的基类指针来存储 CObject 派生类。
CArchive& AFXAPI operator<<(CArchive& ar, const CObject* pOb);
普通旧数据的处理相当直接。这里是一个读写 float 数据类型的例子
//
// Storing
//
CArchive& CArchive::operator<<(float f)
{
if(!IsStoring())
AfxThrowArchiveException(CArchiveException::readOnly,m_strFileName);
if (m_lpBufCur + sizeof(float) > m_lpBufMax)
Flush();
*(UNALIGNED float*)m_lpBufCur = f; // Write float into the byte array
m_lpBufCur += sizeof(float); // Increment buffer pointer by the size of the float
return *this;
}
以下代码是 float 数据类型的加载代码
//
// Loading
//
CArchive& CArchive::operator>>(float& f)
{
if(!IsLoading())
AfxThrowArchiveException(CArchiveException::writeOnly,m_strFileName);
if (m_lpBufCur + sizeof(float) > m_lpBufMax)
FillBuffer(UINT(sizeof(float) - (m_lpBufMax - m_lpBufCur)));
f = *(UNALIGNED float*)m_lpBufCur; // Assign byte array to float size of the float
m_lpBufCur += sizeof(float); // Increment buffer pointer by the size of the float
return *this;
}
读写 CObject 派生类要复杂一些。这将在下一节中介绍。
注意事项
因为所有数据都存储在一个连续的字节缓冲区中,所以必须以与存储时完全相同的顺序读取。否则,在加载过程中将抛出 CArchiveException 异常。
为什么我不能多次调用 ar.GetObjectSchema()?
简而言之,你不能在每次加载对象时多次调用 GetObjectSchema,原因如下。
//
// GetObjectSchema
//
UINT CArchive::GetObjectSchema()
{
UINT nResult = m_nObjectSchema;
m_nObjectSchema = (UINT)-1; // can only be called once per Serialize
return nResult;
}
至于为什么会这样?我最好的猜测是历史遗留问题。成员变量 CArchive::m_nObjectSchema 与 CRuntimeClass::m_wSchema 非常不同,因为 CArchive 对象架构是从文件中读取的,该文件可能包含许多具有不同架构的对象。它保存的是当前正在从文件中读取的对象的架构。想一想,当你反序列化一个对象时,例如在下面的例子中(假设 m_nObjectSchema 保持不变)
void CMyClass::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
// omitted storing code …
}
else
{
// Loading
UINT nSchema = ar.GetObjectSchema();
switch(nSchema)
{
case 1:
ar >> m_pObject1; // Version schema 10. Serialize may call GetObjectSchema
ar >> m_pObject2; // Version schema 1. Serialize may call GetObjectSchema
ar >> m_pObject3; // Version schema 2. Serialize may call GetObjectSchema
ar >> m_pObject4; // Version schema 15. Serialize may call GetObjectSchema
}
}
// For whatever reason
if(ar.IsLoading())
{
UINT nSchema = ar.GetObjectSchema(); // schema of this class?
}
}
在上面的例子中,当你完成加载代码部分时,对象架构已经被改变了 4 次。我猜想,为了消除这种微妙的错误行为,MFC 框架决定从源头上杜绝,而不是让程序员为他们宝贵的数据被破坏而抓耳挠腮。
GetObjectSchema 每次加载对象只能被调用一次,因为框架在每次调用 CArchive::GetObjectSchema 后会强制将其重置为 (UINT)-1。
即使在今天的 MFC 库中,上面的例子也是万无一失的。来自 CArchive::ReadObject 的代码清单有以下代码
//
// CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested)
//
//... omitted code
TRY
{
// allocate a new object based on the class just acquired
pOb = pClassRef->CreateObject();
//... omitted code
// Serialize the object with the schema number set in the archive
UINT nSchemaSave = m_nObjectSchema; // Save current schema
m_nObjectSchema = nSchema; // put new schema into the CArchive::m_nObjectSchema
pOb->Serialize(*this); // Call virtual Serialize
m_nObjectSchema = nSchemaSave; // Pop the saved schema back
}
如你所见,它将当前的 m_nObjectSchema 保存到 nSchemaSave 中。将当前对象的架构赋给 m_nObjectSchema。调用 Serialize。将保存的架构弹回到 m_nObjectSchema 中。因此,对象架构永远不会出错。
序列化基类和派生类
在 MFC 中,有四种方法可以解决派生类和基类的序列化问题。
但首先,让我们看看这个微妙的问题。在 16 位 MFC 实现的时代,磁盘空间和 RAM 一样是宝贵的商品。因此,无论你的类层次结构中有多少个派生类,它们的对象架构都将始终等于最终子类的架构,并且只会被写入一次!
//
//
//
class CBase : public CObject
{
DECLARE_SERIAL(CBase)
public:
int m_i;
float m_f;
double m_d;
virtual void Serialize(CArchive& ar);
};
class CDerived : public CBase
{
DECLARE_SERIAL(CDerived)
public:
long m_l;
unsigned short m_us;
long long m_ll;
virtual void Serialize(CArchive& ar);
};
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number. Never written to the file!
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no! nSchema = 2
switch (nSchema)
{
case 1:
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2) // actual schema that is written to the file
void CDerived::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no! nSchema = (UINT)-1 because of 2<sup>nd</sup> call to GetObjectSchema
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
这是为什么呢?快速查看二进制文件转储会发现,对于 CSerializableDerived 类,架构只写入一次,并且它总是等于实例化的对象架构。在这种情况下,它等于 CSerializableDerived 类的架构,即使基类架构等于其他值。

跟踪到 CArchive::WriteObject 会发现这段代码
// // void CArchive::WriteObject(const CObject* pOb) // // … omitted code // write class of object first CRuntimeClass* pClassRef = pOb->GetRuntimeClass(); // Contains m_wSchema of the CSerializableDerived which = 2 WriteClass(pClassRef); // … omitted code
跟踪到 CArchive::WriteClass,框架首先写入一个等于 0xFFFF 的 WORD 值 wNewClassTag。然后它调用 CRuntimeClass::Store 函数
// // void CArchive::WriteClass(const CRuntimeClass* pClassRef) // // … omitted code // store new class *this << wNewClassTag; // New class tag = 0xFFFF pClassRef->Store(*this); // … omitted code
CRuntimeClass::Store 函数获取类名的长度,并写入对象架构,然后是类名的长度和类名本身。这就是为什么对于最派生的类,对象架构只写入一次的问题的答案。
//
//
//
void CRuntimeClass::Store(CArchive& ar) const
// stores a runtime class description
{
WORD nLen = (WORD)AtlStrLen(m_lpszClassName); // Get the length of the class name
ar << (WORD)m_wSchema << nLen; // Write schema followed by length of the class name into the file. Written only once!!!
ar.Write(m_lpszClassName, nLen*sizeof(char)); // Write class name into the file
}
在 CRuntimeClass 信息被写入文件后,框架最终调用我们对象的虚函数 Serialize
// // void CArchive::WriteObject(const CObject* pOb) // // … omitted code // cause the object to serialize itself ((CObject*)pOb)->Serialize(*this); // … omitted code
在对象加载期间发生的情况正好相反。首先调用提取运算符。此运算符由 IMPLEMENT_SERIAL 宏提供。
//
// Global extraction operator call provided by the IMPLEMENT_SERIAL macro
//
CArchive& AFXAPI operator >> (CArchive& ar, CSerializableDerived* &pOb)
{
pOb = (CSerializableDerived*)ar.ReadObject(RUNTIME_CLASS(CSerializableDerived));
return ar;
}
跟踪到 CArchive::ReadObject,我们会发现以下代码
// // CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested) // // ... omitted code // attempt to load next stream as CRuntimeClass UINT nSchema; DWORD obTag; CRuntimeClass* pClassRef = ReadClass(pClassRefRequested, &nSchema, &obTag); // ... omitted code
CArchive::ReadClass 函数首先读取对象标签
//
// CRuntimeClass* CArchive::ReadClass(const CRuntimeClass* pClassRefRequested,
// UINT* pSchema, DWORD* pObTag)
//
// ... omitted code
// read object tag - if prefixed by wBigObjectTag then DWORD tag follows
DWORD obTag;
WORD wTag;
*this >> wTag; // Read the object tag
if (wTag == wBigObjectTag)
*this >> obTag;
else
obTag = ((wTag & wClassTag) << 16) | (wTag & ~wClassTag);
// ... omitted code
CRuntimeClass* pClassRef;
UINT nSchema;
if (wTag == wNewClassTag)
{
// defined as follows
// #define wNewClassTag ((WORD)0xFFFF) // special tag indicating new CRuntimeClass
// new object follows a new class id
if ((pClassRef = CRuntimeClass::Load(*this, &nSchema)) == NULL) // Read CRuntimeClass information from the file
AfxThrowArchiveException(CArchiveException::badClass, m_strFileName);
// ... omitted code
}
// ... omitted code
以下是 CRuntimeClass::Load 函数的清单。请注意,类名不能超过 64 个字符。如果类名的长度大于或等于 64 个字符,或者 CArchive::Read 未能从文件中读取类名,则函数返回 NULL。如果类名成功从文件中读取,szClassName 将在 nLen 长度值处以 NULL 结尾,并在 CRuntimeClass::FromName 中进行查找
//
//
//
CRuntimeClass* PASCAL CRuntimeClass::Load(CArchive& ar, UINT* pwSchemaNum)
// loads a runtime class description
{
if(pwSchemaNum == NULL)
{
return NULL;
}
WORD nLen;
char szClassName[64];
WORD wTemp;
ar >> wTemp; *pwSchemaNum = wTemp; // Read the schema
ar >> nLen; // Read the length of the class name
// load the class name
if (nLen >= _countof(szClassName) ||
ar.Read(szClassName, nLen*sizeof(char)) != nLen*sizeof(char))
{
return NULL;
}
szClassName[nLen] = '\0';
// match the string against an actual CRuntimeClass
CRuntimeClass* pClass = FromName(szClassName);
if (pClass == NULL)
{
// not found, trace a warning for diagnostic purposes
TRACE(traceAppMsg, 0, "Warning: Cannot load %hs from archive. Class not defined.\n",
szClassName);
}
return pClass;
}
CRuntimeClass::FromName 只是遍历 AFX_MODULE_STATE::m_classList 并按名称进行比较。如果找到该类,则返回 CRuntimeClass 指针。AFX_MODULE_STATE CRuntimeClass 的发现是另一个值得单独写一篇文章的课题。但足以说明的是,这个特性是在 RTTI(运行时类型信息)编译器支持之前实现的,它允许在关闭 RTTI 编译器开关的情况下对 MFC 类进行运行时类型发现。事实上,Visual C++ 6.0 的默认设置就是关闭 RTTI 开关。
//
//
//
CRuntimeClass* PASCAL CRuntimeClass::FromName(LPCSTR lpszClassName)
{
CRuntimeClass* pClass=NULL;
ENSURE(lpszClassName);
// search app specific classes
AFX_MODULE_STATE* pModuleState = AfxGetModuleState();
AfxLockGlobals(CRIT_RUNTIMECLASSLIST);
for (pClass = pModuleState->m_classList; pClass != NULL;
pClass = pClass->m_pNextClass)
{
if (lstrcmpA(lpszClassName, pClass->m_lpszClassName) == 0)
{
AfxUnlockGlobals(CRIT_RUNTIMECLASSLIST);
return pClass;
}
}
AfxUnlockGlobals(CRIT_RUNTIMECLASSLIST);
#ifdef _AFXDLL
// search classes in shared DLLs
AfxLockGlobals(CRIT_DYNLINKLIST);
for (CDynLinkLibrary* pDLL = pModuleState->m_libraryList; pDLL != NULL;
pDLL = pDLL->m_pNextDLL)
{
for (pClass = pDLL->m_classList; pClass != NULL;
pClass = pClass->m_pNextClass)
{
if (lstrcmpA(lpszClassName, pClass->m_lpszClassName) == 0)
{
AfxUnlockGlobals(CRIT_DYNLINKLIST);
return pClass;
}
}
}
AfxUnlockGlobals(CRIT_DYNLINKLIST);
#endif
return NULL; // not found
}
回到 CArchive::ReadClass,它返回 CRuntimeClass、pSchema 和 pObTag 指针。
//
//
//CRuntimeClass* CArchive::ReadClass(const CRuntimeClass* pClassRefRequested,
// UINT* pSchema, DWORD* pObTag)
//... omitted code
// store nSchema for later examination
if (pSchema != NULL)
*pSchema = nSchema;
else
m_nObjectSchema = nSchema;
// store obTag for later examination
if (pObTag != NULL)
*pObTag = obTag;
// return the resulting CRuntimeClass*
return pClassRef;
在成功获取 CRuntimeClass 指针后,框架调用由 DECLARE_SERIAL 和 IMPLEMENT_SERIAL 宏提供的 CreateObject。
- 将当前的
CArchive::m_nObjectScema存储到nSchemaSave中 - 将当前
CRuntimeClass的架构赋给CArchive::m_nObjectSchema - 调用虚函数 Serialize
- 将
nSchemaSave弹回到CArchive::m_nObjectSchema中
//
// CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested)
//
//... omitted code
TRY
{
// allocate a new object based on the class just acquired
pOb = pClassRef->CreateObject();
//... omitted code
// Serialize the object with the schema number set in the archive
UINT nSchemaSave = m_nObjectSchema; // Save current schema
m_nObjectSchema = nSchema; // put new schema into the CArchive::m_nObjectSchema
pOb->Serialize(*this); // Call virtual Serialize
m_nObjectSchema = nSchemaSave; // Pop the saved schema back
ASSERT_VALID(pOb);
}
所以现在你知道为什么你的类只有一个架构,无论你的类层次结构中有多少个类。
我们如何解决这个问题?有四种方法可以解决。有些方法比其他方法更优雅。让我们来看看所有这些方法。当然,这只适用于你必须在所有类中维护版本的情况。最简单的方法是不对任何东西进行版本控制,但在现实生活中,如果你的应用程序预期寿命以十年计,那么从一开始就维护版本控制是绝对必要的。
第一种解决方案:在派生类中完成所有序列化
这不是一个优雅的解决方案,但它行之有效,并且消除了所有意外。对于我们上面的例子,代码将如下所示
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived::Serialize(CArchive& ar)
{
// Do not call base class
// CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
// serialize base members
ar << m_i;
ar << m_f;
ar << m_d;
// serialize this class members
ar << m_l;
ar << m_us;
ar << m_ll;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2:
// deserialize base members
ar >> m_i;
ar >> m_f;
ar >> m_d;
// deserialize this class members
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
这个解决方案不是很漂亮。如果你的基类有太多成员,你的 Serialize 函数可能会变得非常庞大。
第二种解决方案:将架构弹回 CArchive 中
这个解决方案稍微优雅一些,但是当架构发生变化时,你仍然需要在所有基类中增加架构版本号。
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no, nSchema = 2
switch (nSchema)
{
case 1:
case 2: // THIS IS REQUIRED!!!
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
// Pop the schema back into the CArchive for derived class to use
ar.SetObjectSchema(nSchema);
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived::Serialize(CArchive& ar)
{
// Call base class
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
第三种解决方案:考虑使用“不要调用我们,我们会调用您”设计模式来重构 Serialize 函数
添加 private virtual function SerializeImpl(CArchive& ar, UINT nSchema) 将消除多次调用 CArchive::GetObjectSchema 的需要。
//
//
//
class CBase : public CObject
{
DECLARE_SERIAL(CBase)
public:
int m_i;
float m_f;
double m_d;
virtual void Serialize(CArchive& ar);
private:
virtual void SerializeImpl(CArchive& ar, UINT nSchema);
};
class CDerived : public CBase
{
DECLARE_SERIAL(CDerived)
public:
long m_l;
unsigned short m_us;
long long m_ll;
private:
virtual void SerializeImpl(CArchive& ar, UINT nSchema);
};
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
// CDerived::SerializeImpl version will be called
SerializeImpl(ar, (UINT)-1);
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2: // THIS IS STILL REQUIRED!!!
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
// CDerived::SerializeImpl version will be called
SerializeImpl(ar, nSchema);
}
}
void CBase::SerializImpl(CArchive& ar, UINT nSchema)
{
// Not implemented
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
// Eliminates calling to ar.GetObjectSchema() alltogether
void CDerived::SerializImpl(CArchive& ar, UINT nSchema)
{
// call base if you have more than 2 parent classes
// so the parent’s class serialization routine utilized
CBase::SerializImpl(ar, nShema);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
这在某种程度上更为优雅,但当架构发生变化时,仍然需要我们在所有基类中增加版本号。
接下来是最优雅的解决方案。
第四种解决方案:将基类架构存储为类的第一个成员
现在,这个解决方案解决了 MFC 序列化机制的缺点。你可以通过成员变量静态的 classCBase::m_wSchema 访问你的基类架构,在我们的例子中是这样。
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Not so useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
// store the classCBase.m_wSchema; Added by the DECLARE_SERIAL macro and populated by the IMPLEMENT_SERIAL macro
// as the very 1st member
WORD wSchema = (WORD)classCBase.m_wSchema; // Strips VERSIONABLE_SCHEMA and Equals 1 as declared above
ar << wSchema;
ar << m_i;
ar << m_f;
ar << m_d;
}
else
{ // loading code
// Do not call CArchive::GetObjectSchema!
//UINT nSchema = ar.GetObjectSchema();
// Read base object schema
WORD wSchema = 0;
ar >> wSchema;
switch (wSchema) // Equals 1
{
case 1:
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived:: Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema(); // equals 2
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
这是最优雅的解决方案,因为它让你无需维护基类,代价是每个父类在文件中增加一个 `sizeof(WORD)` 的大小。
序列化纯基类
假设你有一个带有纯虚函数的 CObject 派生类。
//
// CObject derived class with pure virtual functions
//
class CPureBase : public CObject
{
DECLARE_SERIAL(CPureBase)
public:
CPureBase();
virtual ~CPureBase();
virtual void Serialize(CArchive& ar);
virtual CString CanSerialize() const = 0;
virtual CString GetObjectSchema() const = 0;
virtual CString GetObjectRunTimeName() const = 0;
};
在正常情况下,这是行不通的,因为 IMPLEMENT_SERIAL 宏会向你的代码中添加以下函数
//
// Function added by IMPLEMENT_SERIAL macro
//
CObject* PASCAL CPureBase::CreateObject()
{
return new CPureBase; // Compiler error! Cannot instantiate class due to pure virtual functions
}
为了解决这个问题,我们需要创建我们自己版本的 IMPLEMENT_SERIAL 宏,让它从 CreateObject 函数返回 nullptr。
//
// Helper macro for Pure base serializable classes
// Removes instancing of the new class in CreateObject()
#define IMPLEMENT_SERIAL_PURE_BASE(class_name, base_class_name, wSchema)\
CObject* PASCAL class_name::CreateObject() \
{ return nullptr; } \
extern AFX_CLASSINIT _init_##class_name; \
_IMPLEMENT_RUNTIMECLASS(class_name, base_class_name, wSchema, \
class_name::CreateObject, &_init_##class_name) \
AFX_CLASSINIT _init_##class_name(RUNTIME_CLASS(class_name)); \
CArchive& AFXAPI operator>>(CArchive& ar, class_name* &pOb) \
{ pOb = (class_name*) ar.ReadObject(RUNTIME_CLASS(class_name)); \
return ar; }
现在你可以声明你的纯基类是可序列化的了。
//
// This code compiles
//
IMPLEMENT_SERIAL_PURE_BASE(CPureBase, CObject, VERSIONABLE_SCHEMA | 1)
// CPureBase
CPureBase::CPureBase()
{
}
CPureBase::~CPureBase()
{
}
// CPureBase member functions
void CPureBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
}
else
{ // loading code
}
}
使用文档/视图进行序列化
这种类型的序列化在 MFC 文献中被提及最多。如果你的应用程序具有文档视图架构,序列化已经是 CDocument 派生类的一部分。Serialize 的重写提供了必要的代码。典型的代码结构如下所示
void CSerializeDemoDoc::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
// Storing
ar << m_pRoot;
}
else
{
// Loading
ar >> m_pRoot;
}
}
不使用文档/视图进行序列化
要在没有文档/视图的情况下进行序列化,比如说在控制台应用程序中,你需要添加以下代码来写入文件
//
// Writing to the file
//
CFile file; // Create CFile object
// Open CFile object
if (!file.Open(_T("Test.my_ext"), CFile::modeCreate | CFile::modeReadWrite | CFile::shareExclusive))
return false;
// Create CArchive object pass a pointer to CFile and , CArchive::store enumeration
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// write your value
ar << val;
// Close CArchive object
ar.Close();
// Close CFile object
file.Close();
要在没有文档/视图的情况下反序列化或读取,请使用以下代码
//
// Reading from a file
//
CFile file;
if (!file.Open(_T("Test.my_ext"), CFile::modeRead | CFile::shareExclusive))
return false;
CArchive ar(&file, CArchive::load);
ar >> val;
ar.Close();
file.Close();
只需几行代码,你就驾驭了 CArchive 对象的强大功能。
序列化普通旧数据类型
CArchive 提供了以下插入和提取运算符来处理普通旧数据的存储和检索。
//
// CArchive operators
//
// insertion operations
CArchive& operator<<(BYTE by);
CArchive& operator<<(WORD w);
CArchive& operator<<(LONG l);
CArchive& operator<<(DWORD dw);
CArchive& operator<<(float f);
CArchive& operator<<(double d);
CArchive& operator<<(LONGLONG dwdw);
CArchive& operator<<(ULONGLONG dwdw);
CArchive& operator<<(int i);
CArchive& operator<<(short w);
CArchive& operator<<(char ch);
#ifdef _NATIVE_WCHAR_T_DEFINED
CArchive& operator<<(wchar_t ch);
#endif
CArchive& operator<<(unsigned u);
template < typename BaseType , bool t_bMFCDLL>
CArchive& operator<<(const ATL::CSimpleStringT<BaseType, t_bMFCDLL>& str);
template< typename BaseType, class StringTraits >
CArchive& operator<<(const ATL::CStringT<BaseType, StringTraits>& str);
template < typename BaseType , bool t_bMFCDLL>
CArchive& operator>>(ATL::CSimpleStringT<BaseType, t_bMFCDLL>& str);
template< typename BaseType, class StringTraits >
CArchive& operator>>(ATL::CStringT<BaseType, StringTraits>& str);
CArchive& operator<<(bool b);
// extraction operations
CArchive& operator>>(BYTE& by);
CArchive& operator>>(WORD& w);
CArchive& operator>>(DWORD& dw);
CArchive& operator>>(LONG& l);
CArchive& operator>>(float& f);
CArchive& operator>>(double& d);
CArchive& operator>>(LONGLONG& dwdw);
CArchive& operator>>(ULONGLONG& dwdw);
CArchive& operator>>(int& i);
CArchive& operator>>(short& w);
CArchive& operator>>(char& ch);
#ifdef _NATIVE_WCHAR_T_DEFINED
CArchive& operator>>(wchar_t& ch);
#endif
CArchive& operator>>(unsigned& u);
CArchive& operator>>(bool& b);
...
如果你需要序列化未在 CArchive 对象中声明的数据类型,你需要编写自己的实现。稍后当我介绍序列化 Windows SDK 结构时,我们会再讨论这个问题。
序列化 CArray 模板集合
MFC 为其几乎所有的集合提供了序列化支持,为了序列化 MFC 集合,你所需要做的就是调用集合版本的 Serialize(CArchive& ar)。CArray 有所不同,因为它是一个模板,并且模板类型事先未知。而且该类型可能派生自 CObject,也可能没有。CArray::Serialize 函数的默认实现如下所示。它所做的只是在写入操作期间写入 CArray 的大小,在读取操作期间从磁盘读取 CArray 的大小并调整 CArray 的大小。然后它会友好地将调用转发给 SerializeElements<TYPE>() 函数。
//
// Serialize function forwards call to the SerializeElements<TYPE>()
//
template<class TYPE, class ARG_TYPE>
void CArray<TYPE, ARG_TYPE>::Serialize(CArchive& ar)
{
ASSERT_VALID(this);
CObject::Serialize(ar);
if (ar.IsStoring())
{
// Just writes the collection size
ar.WriteCount(m_nSize);
}
else
{
// Just reads the collection size and resizes the CArray
DWORD_PTR nOldSize = ar.ReadCount();
SetSize(nOldSize, -1);
}
SerializeElements<TYPE>(ar, m_pData, m_nSize);
}
用户必须为正在存储或从归档中检索的类型提供 SerializeElements<TYPE>() 的适当实现。以下清单演示了 CAge 类的 SerializeElements<TYPE> 实现。有关实现细节,请参阅 SerializeDemo 项目。
//
//
//
class CAge : public CObject
{
DECLARE_SERIAL(CAge)
public:
CAge();
CAge(int nAge);
virtual ~CAge();
virtual void Serialize(CArchive& ar);
UINT m_nAge;
};
// CArray serialization helper specialized for the CAge class
template<> inline void AFXAPI SerializeElements(CArchive& ar, CAge** pAge, INT_PTR nCount)
{
for (INT_PTR i = 0; i < nCount; i++, pAge++)
{
if (ar.IsStoring())
{
ar << *pAge; // Calls CArchive::WriteObject
}
else
{
CAge* p = nullptr;
ar >> p; // Calls CArchive::ReadObject
*pAge = p;
}
}
}
序列化到进程内存以及从进程内存序列化
通过 CMemFile 支持与内存之间的序列化。CMemFile 不需要文件名。
// // Write to the memory // CMemFile file; CArchive ar(&file, CArchive::store); ar << val; ar.Close();
从内存中序列化的方式如下
// // Read from the memory // CMemFile file; // CByteArray aBytes declared and populated elsewhere file.Attach(m_aBytes.GetData(), m_aBytes.GetSize()); CArchive ar(&file, CArchive::load); ar >> val; ar.Close();
序列化到共享进程内存以及从共享进程内存序列化
通过 CSharedFile 支持与内存之间的序列化。如果你想将序列化的对象传输到剪贴板,以便粘贴到应用程序的另一个实例中,或者传递给另一个应用程序,这将非常有用。
//
// Write to the shared memory to do a clipboard copy operation
//
UINT m_nClipboardFormat = RegisterClipboardFormat(_T("MY_APP_DATA"));
CSharedFile file(GMEM_MOVEABLE | GMEM_SHARE | GMEM_ZEROINIT);
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// CView derived class
GetDocument()->Serialize(ar);
EmptyClipboard();
SetClipboardData(m_nClipboardFormat, file.Detach());
CloseClipboard();
ar.Close();
file.Close();
从共享内存序列化,从剪贴板粘贴操作
//
// Read from the shared memory clipboard paste
//
UINT m_nClipboardFormat = RegisterClipboardFormat(_T("MY_APP_DATA"));
if (!OpenClipboard())
return;
CSharedFile file(GMEM_MOVEABLE | GMEM_SHARE | GMEM_ZEROINIT);
HGLOBAL hMem = GetClipboardData(m_nClipboardFormat);
if (hMem == nullptr)
{
CloseClipboard();
return;
}
file.SetHandle(hMem);
CArchive ar(&file, CArchive::load);
// CView derived class
GetDocument()->DeleteContents();
GetDocument()->Serialize(ar);
CloseClipboard();
ar.Close();
file.Close();
序列化到套接字以及从套接字序列化
与套接字之间的序列化是通过 CSocketFile 类完成的。只有当 CSocket 的类型为 SOCK_STREAM 时,你才能将 CArchive 序列化到 CSocket 中。这个主题比 MSDN 文档中描述的要复杂一些。官方文档描述了你可以使用 CSocketFile 对 CSocket 进行读写。这对于写操作是正确的,但对于读操作则不一定正确。如果你传输的数据大小只有几个字节,那么是的,你可以使用 CSocketFile 来接收数据。但是,如果你的数据大小是兆字节级别(或任何大于读取缓冲区的大小),那么你很可能会分几次读取来接收数据,你将不得不先将所有数据累积到 CByteArray 结构中,只有在所有数据都接收完毕后,你才能将其附加到 CMemFile 而不是 CSocketFile 并进行反序列化。尝试从 CSocketFile 读取部分数据通常会导致 CArchiveException。
//
// Write to the socket. In this case using CSocketFile is fine
//
CSocket sock;
if (!sock.Create()) // Defaults to the SOCK_STREAM
return;
// Assuming there is a server running on the local host port 1011
if (!sock.Connect(_T("127.0.0.1"), 1011))
return;
CSocketFile file(&sock);
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// Write value to the socket
ar << m_pRoot;
ar.Close();
file.Close();
sock.Close();
从套接字进行序列化要复杂一些。我给出了类的完整清单,以演示如何正确地从套接字读取大的二进制数据集。有关完整的源代码清单,请参阅示例项目 SerializeTcpServer。
//
// Read from the socket. In this case using CSocketFile will not work
// if the transmitted data is greater that the receiving buffer size
//
// CSocket derived class declaration
class CSockThread;
// CRecvSocket command target
class CRecvSocket : public CSocket
{
public:
CRecvSocket();
virtual ~CRecvSocket();
virtual void OnReceive(int nErrorCode);
CSockThread* m_pThread; // Parent thread to ensure our server handles multiple connections simultaneously
CByteArray m_aBytes; // Array of received bytes
private:
DWORD m_dwReads; // Number of reads
void Display(CRoot* pRoot);
};
// Implementation
#define INCOMING_BUFFER_SIZE 65536
// CRecvSocket
CRecvSocket::CRecvSocket(): m_pThread(nullptr)
, m_dwReads(0)
{
}
CRecvSocket::~CRecvSocket()
{
}
// CRecvSocket member functions
void CRecvSocket::OnReceive(int nErrorCode)
{
// yield 10 msec
Sleep(10);
// Our reading buffer
BYTE btBuffer[INCOMING_BUFFER_SIZE] = { 0 };
// Read from the socket size of our buffer size or less
int nRead = Receive(btBuffer, INCOMING_BUFFER_SIZE);
switch (nRead)
{
case 0:
// No data - Quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
break;
case SOCKET_ERROR:
if (GetLastError() != WSAEWOULDBLOCK)
{
// Socket error - Quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
}
break;
default:
// Increment read counter
m_dwReads++;
// Read into the byte array
CByteArray aBytes;
// Resize our byte array to the size of the received data
aBytes.SetSize(nRead);
// Copy received data into the CByteArray
CopyMemory(aBytes.GetData(), btBuffer, nRead);
// Append received data to m_aBytes member
m_aBytes.Append(aBytes);
DWORD dwReceived = 0;
// Look ahead for more incoming data
if (IOCtl(FIONREAD, &dwReceived))
{
// No more incoming data
if (dwReceived == 0)
{
// We have received all of the incoming data
// Instead of CSocketFile use CMemFile
CMemFile file;
file.Attach(m_aBytes.GetData(), m_aBytes.GetSize());
CArchive ar(&file, CArchive::load);
CRoot* pRoot = nullptr;
TRY
{
ar >> pRoot;
}
CATCH(CArchiveException, e)
{
std::cout << "Error reading data " << std::endl;
}
END_CATCH
if (pRoot)
{
// Use our de serialized CRoot class
Display(pRoot);
delete pRoot;
}
ar.Close();
file.Close();
// finally quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
}
}
}
CSocket::OnReceive(nErrorCode);
}
在当今的应用程序中,你很少会在一次 OnReceive 调用中接收到所有的二进制或文本数据传输。因此,你需要将所有数据累积到一个字节数组中。只有这样,你才能通过将累积的 CByteArray 附加到 CMemFile 来成功地反序列化它。上面的例子调用 IOCtl(FIONREAD, &dwReceived) 来确定是否有更多的数据正在传入。经验法则是:因为我们的读取缓冲区等于 65536 字节,任何传输大于读取缓冲区的数据都会导致不止一次的读取。
CSockThread* m_pThread; 的实现在示例项目 SerializeTcpServer 中提供。
序列化任意字节流
任意字节流基本上是任何你不知道或不关心其内部结构的二进制文件。一个例子是,你想在你的类数据中存储 JPEG 图像或 mpeg 4 电影文件,而不需要任何关于底层数据结构的知识。你可以在以后反序列化它,并用适当的应用程序使用它。MFC 序列化允许你轻松地存储这些数据。
在下面的代码中,我们将存储四张 JPEG 图片的字节流
//
// Declare class to hold an array of JPEG images
//
class CMyPicture : public CObject
{
DECLARE_SERIAL(CMyPicture)
public:
CMyPicture();
virtual ~CMyPicture();
virtual void Serialize(CArchive& ar);
CString GetHeader() const;
CString m_strName; // Original image file name
CString m_strNewName; // New image file
CByteArray m_bytes; // Image binary data array
};
typedef CTypedPtrArray<CObArray, CMyPicture*> CMyPictureArray;
以下是该类的主体清单
//
// Class to store JPEG images
//
IMPLEMENT_SERIAL(CMyPicture, CObject, VERSIONABLE_SCHEMA | 1)
// CMyPicture
CMyPicture::CMyPicture()
{
}
CMyPicture::~CMyPicture()
{
}
// CMyPicture member functions
void CMyPicture::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
ar << m_strName;
ar << m_strNewName;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_strName;
ar >> m_strNewName;
break;
}
}
// Serialize arbitrary byte stream into or from the file
m_bytes.Serialize(ar);
}
要用 JPEG 图像数据填充这样一个类,你只需要做以下事情
//
// CMyPictureArray m_aPictures declared in the class header as a member
//
m_aPictures.Add(InitPicture("Water lilies.jpg", "Water lilies Output.jpg"));
m_aPictures.Add(InitPicture("Blue hills.jpg", "Blue hills Output.jpg"));
m_aPictures.Add(InitPicture("Sunset.jpg", "Sunset Output.jpg"));
m_aPictures.Add(InitPicture("Winter.jpg", "Winter Output.jpg"));
UpdateAllViews(nullptr, HINT_GENERATED_DATA);
SetModifiedFlag();
}
// Read binary stream from an unknown file
std::vector<BYTE> CSerializeDemoDoc::ReadBinaryFile(const char* filename)
{
std::basic_ifstream<BYTE> file(filename, std::ios::binary);
return std::vector<BYTE>((std::istreambuf_iterator<BYTE>(file)), std::istreambuf_iterator<BYTE>());
}
CMyPicture* CSerializeDemoDoc::InitPicture(const char* sFileName, const char* sOutFileName)
{
std::vector<BYTE> vJPG = ReadBinaryFile(sFileName);
CMyPicture* pPicture = new CMyPicture;
pPicture->m_strName = sFileName;
pPicture->m_strNewName = sOutFileName;
pPicture->m_bytes.SetSize(vJPG.size());
CopyMemory(pPicture->m_bytes.GetData(), (void*)&vJPG[0], vJPG.size() * sizeof(BYTE));
return pPicture;
}
// Writes JPEG images back to the hard drive
void CSerializeDemoDoc::OnTestdataWriteimagedatatodisk()
{
for (INT_PTR i = 0; i < m_pRoot->m_aPictures.GetSize(); i++)
{
CMyPicture* pPic = m_pRoot->m_aPictures.GetAt(i);
std::ofstream fout(pPic->m_strNewName, std::ios::out | std::ios::binary);
fout.write((char*)pPic->m_bytes.GetData(), pPic->m_bytes.GetSize());
fout.close();
}
AfxMessageBox(_T("Finished writing images back to disk"), MB_ICONINFORMATION);
}
序列化 Windows SDK 数据结构
CArchive 类不提供 Windows SDK 结构的序列化。然而,为这种序列化添加支持几乎是毫不费力的。以下代码演示了如何序列化 LOGFONT SDK 结构。
//
// LOGFONT SDK structure serialization code
//
// LOGFONT write
inline CArchive& AFXAPI operator <<(CArchive& ar, const LOGFONT& lf)
{
CString strFace(lf.lfFaceName);
ar << lf.lfHeight;
ar << lf.lfWidth;
ar << lf.lfEscapement;
ar << lf.lfOrientation;
ar << lf.lfWeight;
ar << lf.lfItalic;
ar << lf.lfUnderline;
ar << lf.lfStrikeOut;
ar << lf.lfCharSet;
ar << lf.lfOutPrecision;
ar << lf.lfClipPrecision;
ar << lf.lfQuality;
ar << lf.lfPitchAndFamily;
ar << strFace;
return ar;
}
// LOGFONT read
inline CArchive& AFXAPI operator >> (CArchive& ar, LOGFONT& lf)
{
CString strFace;
ar >> lf.lfHeight;
ar >> lf.lfWidth;
ar >> lf.lfEscapement;
ar >> lf.lfOrientation;
ar >> lf.lfWeight;
ar >> lf.lfItalic;
ar >> lf.lfUnderline;
ar >> lf.lfStrikeOut;
ar >> lf.lfCharSet;
ar >> lf.lfOutPrecision;
ar >> lf.lfClipPrecision;
ar >> lf.lfQuality;
ar >> lf.lfPitchAndFamily;
ar >> strFace;
_tcscpy_s(lf.lfFaceName, strFace);
return ar;
}
在你定义了 LOGFONT 的提取和插入运算符之后,你只需要执行以下代码片段。
//
// Serialize LOGFONT structure m_lf
//
void CRoot::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
ar << m_lf; // Write LOGFONT
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_lf; // Read LOGFONT
break;
}
}
}
接下来的代码片段序列化了 WINDOWPLACEMENT SDK 结构
//
// Serializing WINDOWPLACEMENT
//
// WINDOWPLACEMENT write
inline CArchive& AFXAPI operator <<(CArchive& ar, const WINDOWPLACEMENT& val)
{
ar << val.flags;
ar << val.length;
ar << val.ptMaxPosition.x;
ar << val.ptMaxPosition.y;
ar << val.ptMinPosition.x;
ar << val.ptMinPosition.y;
ar << val.rcNormalPosition.bottom;
ar << val.rcNormalPosition.left;
ar << val.rcNormalPosition.right;
ar << val.rcNormalPosition.top;
ar << val.showCmd;
return ar;
}
// WINDOWPLACEMENT read
inline CArchive& AFXAPI operator >> (CArchive& ar, WINDOWPLACEMENT& val)
{
ar >> val.flags;
ar >> val.length;
ar >> val.ptMaxPosition.x;
ar >> val.ptMaxPosition.y;
ar >> val.ptMinPosition.x;
ar >> val.ptMinPosition.y;
ar >> val.rcNormalPosition.bottom;
ar >> val.rcNormalPosition.left;
ar >> val.rcNormalPosition.right;
ar >> val.rcNormalPosition.top;
ar >> val.showCmd;
return ar;
}
然后,读写 WINDOWPLACEMENT 结构就变得像这样简单了
//
// Reading and writing WINDOWPLACEMENT structure
//
void CRoot::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
ar << m_wp; // Write WINDOWPLACEMENT struct
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_wp; // Read WINDOWPLACEMENT struct
break;
}
}
}
序列化 STL 集合
STL 集合的序列化就像 SDK 数据结构的序列化一样简单。让我们为流行的 STL 集合定义插入和提取运算符。要序列化 std::vector<int>,我们需要以下定义
//
// STL vector<int> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::vector<int>& val)
{
// first store the size of the vector
ar << (int)val.size();
for each (int k in val)
{
ar << k; // store each int into the file
}
return ar;
}
要将 STL vector 读回到 std::vector<int> 中,我们执行以下操作
//
// STL vector<int> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::vector<int>& val)
{
int nSize;
ar >> nSize; // read the vector size
val.resize(nSize); // resize vector to the read size
for (size_t i = 0; i < (size_t)nSize; i++)
{
ar >> val[i]; // retrieve values
}
return ar;
}
std::map<char, int> 集合的序列化。首先,我们存储 map 的大小。因为 std::map<char, int> 的底层元素是 std::pair<char, int>,所以我们存储 pair 的第一个和第二个成员。
//
// std::map<char, int> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::map<char, int>& val)
{
ar << (int)val.size();
for each (std::pair<char, int> k in val)
{
ar << k.first;
ar << k.second;
}
return ar;
}
std::map<char, int> 的读取代码如下。
//
// std::map<char, int> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::map<char, int>& val)
{
int nSize;
ar >> nSize;
for (size_t i = 0; i < (size_t)nSize; i++)
{
std::pair<char, int> k;
ar >> k.first;
ar >> k.second;
val.insert(k);
}
return ar;
}
STL 固定大小 std::array<int, 3> 的序列化。
//
// STL std::array<int, 3> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::array<int, 3>& val)
{
for each (int k in val)
{
ar << k;
}
return ar;
}
std::array<int, 3> 读取运算符。
//
// STL std::array<int, 3> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::array<int, 3>& val)
{
for (size_t i = 0; i < (size_t)val.size(); i++)
{
ar >> val[i];
}
return ar;
}
std::set<std::string> 集合的序列化。
//
// STL std::set<std::string> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::set<std::string>& val)
{
ar << (int)val.size(); // write the size first
for each (std::string k in val)
{
ar << CStringA(k.c_str());
}
return ar;
}
std::set<std::string> 集合的读取代码。
//
// STL std::set<std::string> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::set<std::string>& val)
{
int nSize;
ar >> nSize;
for (size_t i = 0; i < (size_t)nSize; i++)
{
CStringA str;
ar >> str;
val.insert(std::string(str));
}
return ar;
}
序列化 STL 数据类型
STL 类型的序列化就像 SDK 数据结构的序列化一样简单。首先,我们需要一个提取和插入运算符的定义。要序列化或反序列化 std::string,我们需要添加以下运算符
//
// STL std::string write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::string& val)
{
ar << CStringA(k.c_str()); // because std::string is ANSI we can pass it as a constructor to the CStringA class
return ar;
}
反序列化 std::string
//
// STL std::string read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::string& val)
{
CStringA str;
ar >> str;
val = str;
return ar;
}
关于 STL 数据和容器的序列化实现,我就讲到这里。当你看到一个 STL 集合和一个 STL 类型被序列化时,你就看到了全部。我将把序列化 std::pair、std::tuple、std::unordered_map 等作为练习留给读者。
序列化扁平 C 风格数组
要序列化扁平 C 数组,你将遵循与序列化集合相同的过程。但是因为扁平 C 风格数组的大小是已知的,所以没有必要在文件中存储其大小。
//
// Write float val[3]
//
inline CArchive& AFXAPI operator <<(CArchive& ar, float val[3])
{
for(int i = 0; i < 3; i++)
{
ar << val[i];
}
return ar;
}
读取扁平 C 风格数组。
//
// read float val[3]
//
inline CArchive& AFXAPI operator >> (CArchive& ar, float val[3])
{
for (size_t i = 0; i < 3; i++)
{
ar >> val[i];
}
return ar;
}
序列化枚举类型
要序列化枚举,你实际上只需要一个提取运算符,因为在插入时,枚举会隐式转换为 int。但是,为枚举同时提供插入和提取运算符会得到一个更清晰的解决方案,并可能消除未来讨厌的意外。
//
// Enumeration that we want to serialize
//
enum EMyTestEnum
{
ENUM_0,
ENUM_1,
};
写入枚举代码。
//
// Write enumeration EMyTestEnum
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const EMyTestEnum& val)
{
int iTemp = val;
ar << iTemp;
return ar;
}
读取枚举代码。
//
// Read enumeration EMyTestEnum
//
inline CArchive& AFXAPI operator >> (CArchive& ar, EMyTestEnum& val)
{
int iTmp = 0;
ar >> iTmp;
val = (EMyTestEnum)iTmp;
return ar;
}
CObject 派生类的序列化版本控制
这是一个相当有趣的话题,CObject 派生的版本控制可以通过两种方式完成。让我们假设我们有一个类,其版本随着核心应用程序中新功能的实现而不断演变。
//
// Any source code blocks look like this
//
class CMyObject : public CObject
{
DECLARE_SERIAL(CMyObject)
public:
CMyObject();
virtual ~CMyObject();
virtual void Serialize(CArchive& ar);
// Version 1 data
float m_f;
double m_d;
// Version 2 data
COLORREF m_backColor;
COLORREF m_foreColor;
// Version 3 data
CString m_strDescription;
// Version 4 data
CString m_strNotes;
};
要序列化这样一个对象,并且仍然能够读取版本 1、2 和 3 的旧文件,我们可以通过以下方式实现。
//
// Version 4 object
//
IMPLEMENT_SERIAL(CMyObject, CObject, VERSIONABLE_SCHEMA | 4)
void CMyObject::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
ar << m_f;
ar << m_d;
ar << m_backColor;
ar << m_foreColor;
ar << m_strDescription;
ar << m_strNotes;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_f;
ar >> m_d;
break;
case 2:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
break;
case 3:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
ar >> m_strDescription;
break;
case 4:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
ar >> m_strDescription;
ar >> m_strNotes;
break;
}
}
}
这种方法虽然清晰明了,但充其量是乏味的。有很多重复的代码。另一种方法是反向加载这些数据,让 switch case 语句穿透到正确版本的文件。
//
// Version 4 object
//
IMPLEMENT_SERIAL(CMyObject, CObject, VERSIONABLE_SCHEMA | 4)
void CMyObject::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
// Add new features to the top rather than bottom
ar << m_strNotes; // Version 4
ar << m_strDescription; // Version 3
ar << m_backColor; // Version 2
ar << m_foreColor; // Version 2
ar << m_f; // Version 1
ar << m_d; // Version 1
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
// Reverse case statements. New version goes on top without break statement
// to let it simply fall through all the versions
case 4:
ar >> m_strNotes; // fall through to version 3
case 3:
ar >> m_strDescription; // fall through to version 2
case 2:
ar >> m_backColor;
ar >> m_foreColor; // fall through to version 1
case 1:
ar >> m_f;
ar >> m_d;
break; // finally break from version 1
}
}
}
这是一个更清晰的版本控制解决方案,消除了所有重复的代码。
非 CObject 类的序列化版本控制
要序列化非 CObject 派生类,我们只需遵循与 Windows SDK 结构相同的规则。
//
// Non CObject class
//
class CMyObject
{
public:
CMyObject();
virtual ~CMyObject();
static const short VERSION = 1;
float m_f;
double m_d;
};
将版本号作为第一个成员写入。然后在读取时,根据文件内部的版本,你可以通过与加载的版本相对应的适当读取过程来处理它。
//
// Serializing CMyObject
//
// CMyObject write
inline CArchive& AFXAPI operator <<(CArchive& ar, const CMyObject & val)
{
ar << val.VERSION; // Write the current version of the class as very first item
ar << val.m_f;
ar << val.m_d;
return ar;
}
// CMyObject read
inline CArchive& AFXAPI operator >> (CArchive& ar, CMyObject & val)
{
short nVersion = 0;
ar >> nVersion;
switch(nVersion)
{
case 1:
ar >> val.m_f;
ar >> val.m_d;
break;
}
return ar;
}
注意事项
永远不要序列化 WIN32 和 WIN64 typedefs!如果你将应用程序升级到 64 位,并尝试读取由 32 位版本应用程序创建的文件,而该文件恰好序列化了 WIN32/64 typedefs(例如 DWORD_PTR),那么它将惨败。因为 DWORD_PTR 在 32 位架构上是 4 字节长,在 WIN64 上是 8 字节长,所以将 4 字节读入 8 字节或反之,将导致 CArchiveException,并且它将使你的文件对于另一个位对齐版本的应用程序无用。只序列化硬性已知的类型。如果必须使用 64 位整数,则在 32 位和 64 位版本的应用程序中都明确地将其序列化为 __int64。如果你正在序列化 SDK 结构,这一点尤其需要关注。你需要仔细检查结构声明,如果可能存在 WIN32/64 typedefs,如果你正在构建 32 位应用程序并计划将来将其升级到 64 位,则明确地将它们转换为最大尺寸。
坚持使用 UNICODE 或 ANSI,句号。如果由于某种原因你必须同时维护应用程序的 ANSI 和 UNICODE 版本,那么请专门序列化 CStringA 或 CStringW,以便另一个版本可以读取该文件。可以说,像 "hello" 这样的字符串在 ANSI 字符串中将存储为 5 个字节长,但对于 UNICODE 版本则为 10 个字节长。
静态链接到 MFC 以消除对 MFCXX.DLL 或任何其他第三方库的运行时依赖。假设在第三方 DLL 的新版本中 sizeof(WhateverClass) 发生了变化,而你的应用程序动态链接到它并对其进行序列化,那么你的应用程序将无法读取文件。安全总比后悔好。所以如果你无法控制第三方库的代码,那么就静态链接到它。提前一点规划会大有裨益。
使用代码
我提供了 SerializeDemo 解决方案项目,该项目演示了本文中描述的所有方面。该解决方案包含 4 个子项目
SerializeData– 存放所有项目使用的数据结构和运算符SerializeDemo– MFC 文档/视图应用程序SerializeTcpServer– 一个在本地主机"127.0.0.1"端口1011上运行的控制台服务器应用程序。如果端口 1011 在你的机器上已被占用,你可能需要更改端口号。SerializeDemo 应用程序可以连接到此服务器以传输序列化数据SerializationWithoutDocView– 演示在没有文档/视图架构的情况下使用CArchive的控制台应用程序

SerializeDemo 应用程序运行中。
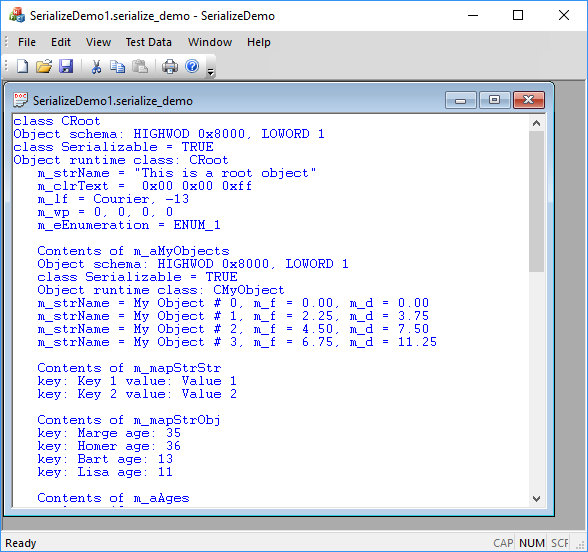
尝试使用以下菜单命令来操作此应用程序。

尝试使用“编辑-复制”并粘贴到 SerializeDemo 应用程序的新实例中。
序列化 TCP 服务器运行中。

SerializeDemo 应用程序将序列化数据发送到服务器。服务器打印接收到的二进制数据。

历史
2017 年 3 月 16 日,原文。
2018 年 9 月 28 日。修正了一些拼写错误
2019 年 1 月 9 日。由于文章很长,添加了目录