
将简单算法从原型转化为“生产级”代码的案例研究
5.00/5 (24投票s)
这是一篇比较轻量级的文章,通过一个案例研究,讨论了我们在重构原型代码(以及决定是否重构原型代码!)时应该注意的一些问题。
引言
在我忙于下一篇巨著的同时,先来点简短的内容。 :)
我最近需要写一个算法,将一系列路径填充到一个树结构中。我之所以写这个算法,是因为我当时正在指导一位需要实现这个功能但对 C#、.NET、LINQ 等还不太熟练(但他学得很快)的人。算法的复杂度足以让我想先自己解决一遍,以免显得手足无措——准备工作很重要!事实证明,这构成了一个很好的代码重构案例研究。
首先,我说的“树”不一定是指 TreeView,而可能只是像下面这个模型一样简单。
public class Node
{
public string Text { get; set; }
public List<Node> Nodes { get; protected set; }
public Node()
{
Nodes = new List<Node>();
}
}
关于 TreeView,有一些现成的实现在这里。讽刺的是,我甚至都没先想到去搜索现有的实现,而且说实话,我很高兴我没去搜,因为那个 SO 页面上的每个示例都有一个有趣的特点:它们在计算如何创建路径时,每次都会从根节点遍历树。这要么通过 Nodes.Find 方法实现,要么对于每个路径,从根节点开始迭代,直到找到一个缺失的节点。正如一位读者评论的那样:“我用了你的代码,它工作得很好,但我做了一个小小的修改,以提高在处理大量文件列表时的加载速度,因为查找操作和字符串操作通常非常慢。”
老实说,对于每个需要添加的路径都从根节点开始遍历的想法根本没能引起我的注意。相反,从一开始就很清楚这是一个递归算法。当然,“从根节点搜索”的算法都是迭代式的——不需要递归——但它们有一个显著的缺点,就是每次都要从根节点开始遍历树,并在每个层级上检查节点集合中是否存在子节点。太糟糕了!
所以,这篇文章希望能以一种有趣的方式,展示我是如何将我的实现从一个原型迭代到一个过度设计的“生产”级别的。
什么是原型?
我认为我们可以基本同意,原型就像一本书的初稿——它是代码的第一个版本,通常具有以下一个或多个特征:
- 可能效率不高。
- 可能不具备语言的惯用性——也就是说,它不一定能充分利用语言特性。
- 可能对边界情况处理不好。
- 可能没有任何契约断言或
try-catch块。 - 可能包含调试/日志语句。
- 可能属于“演进式原型”类别,这意味着代码有潜力演变成生产代码。
- 可能属于“一次性原型”类别,也就是说,一旦写完,你就会意识到可以用完全不同的方式更好地实现这个功能。
讽刺的是,这里展示的代码是“演进式”的,但最终结果与初稿完全不同,所以最初的原型最终被抛弃了!
什么是生产代码?
生产代码意味着一定的代码质量,这一点上会有很多分歧。一些指导方针可以这样陈述“它可能做了这些”:
- 处理了边界情况
- 包含一些文档
- 包含一些单元测试
- 实现了一些契约
- 实现了一些异常处理
现实地说,原型代码经常未经“生产”级别的资格审查就进入了产品。
生产代码不等于可维护代码
“生产代码”的概念经常与“可维护代码”纠缠不清,这两者需要分开。如上表所示,我概念中的“生产代码”包含了一些应该属于“可维护代码”的内容。
- 文档
- 单元测试
- 契约
- 异常处理
等等!原始列表中唯一剩下的是“处理了边界情况!”是的。甚至这一点也值得商榷。
何时代码才算生产就绪?
在我看来,这是一个更重要的问题,因为它避免了关于“质量”含义的模糊性和分歧。简单来说:
- 代码是生产就绪的,当它完成了预期的工作。
“预期工作”当然需要定义,但通常这意味着它通过了某些 QA 流程。不是单元测试,不是风格一致性,不是语言惯用正确性,不是文档。QA 流程与单元测试不同(这是另一个话题!),只要代码通过了 QA(完成了它应该做的事情,包括正确的结果、性能和异常处理等一项或多项),那么猜猜看,它就准备好投入生产了!
在这里,您的 QA“功能”流程应该是一个清晰且独立于内部代码审查的流程,而内部代码审查则关注 QA 不关注的内容。代码的其他方面都属于可维护性的范畴,以及程序员想要追求语言的惯用性(换句话说,就是“花哨”)的愿望。因此,考虑到这一点,让我们开始吧。
版本 1
算法看起来是这样的:
给定一个 string 列表,其中每个 string 代表一个以正斜杠 ('/') 分隔的路径。
- 将
string列表转换为路径组件string列表。 - 获取每个路径中第一个组件的唯一路径组件。
- 迭代路径的每个唯一组件。
- 创建子节点。
- 获取以该唯一组件作为第一个组件的路径集合。
- 填充第一个组件匹配该唯一组件并且还有其他组件的路径。
- 获取这些路径的剩余组件。
- 对我们刚刚添加的唯一子节点进行剩余部分的递归。
换句话说,如果我有这些路径:
a/b/c
a/b/d
c/d/e
我应该得到这样的树:
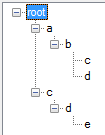
我的第一个尝试是这样的:
static void ParsePaths1(Node node, List<string> paths)
{
// Convert the list of strings into a list of path component strings:
List<string[]> splitPaths = new List<string[]>();
foreach (string str in paths)
{
splitPaths.Add(str.Split('/'));
}
// Get the distinct path components of the first component in each of the paths:
var distinctItems = splitPaths.Select(p => p.First()).Distinct();
// Iterate each of the distinct components:
foreach (string p in distinctItems)
{
// Create the child node.
Node subNode = new Node() { Text = p };
node.Nodes.Add(subNode);
// Initialize our collection of paths that match this distinct component
// as the first component in the path.
List<string> matchingFullPaths = new List<string>();
// Populate the paths whose first component matches the distinct component,
// and that have additional components.
foreach (var match in splitPaths.Where(p2 => p2.First() == p && p2.Length > 1))
{
// Get the remaining components of those paths and
// join them back up into a single string.
matchingFullPaths.Add(String.Join("/", match.Skip(1)));
}
// Recurse the remainder for the distinct subnode we just added.
ParsePaths1(subNode, matchingFullPaths);
}
}
这样做的目的是不一开始就使用过多的 LINQ,因为这会使基本算法的调试变得复杂。
这段代码存在几个问题,其中一个非常明显:
- 它相当冗长,这实际上会降低可读性。
- 存在一个集合的实例化和填充,这是完全不必要的。
- 将组件路径糟糕地重新连接成一个单一的
string!
第三个问题,即组件路径的重新连接,正是这段代码真正落入原型范畴的地方——这是我为了测试算法而采取的捷径,因为那是我的重点。
版本 2
在第二个版本中,我决定不修复最明显的问题,而是通过更好地使用 LINQ 来优化代码。这更多是一个“我首先想做什么”的决定,而不是其他。所以版本 2 是这样的:
static void ParsePaths2(Node node, List<string> paths)
{
var splitPaths = paths.Select(p => p.Split('/'));
foreach(var p2 in splitPaths.Select(p=>p.First()).Distinct())
{
Node subNode = new Node() { Text = p2 };
node.Nodes.Add(subNode);
ParsePaths2(subNode, splitPaths.Where(p3 => p3.First() == p2 && p3.Length > 1).
Select(p3 => String.Join("/", p3.Skip(1))).ToList());
}
}
代码量减少了,但出现了一个新问题:
- 由于解析器接受
List<string>,我必须将Select的结果转换为List。 - 在使用 LINQ,尤其是复杂表达式时,使用
p、p2、p3这样的变量,在试图理解 LINQ 表达式的整体情况时,并没有太大帮助。 - 我们仍然有那个糟糕的路径组件重新连接的问题。
尽管如此,版本 2 运行得很好。
版本 3
版本 3 解决了所有剩余的问题:
static void ParsePaths3(Node node, IEnumerable<IEnumerable<string>> splitPaths)
{
foreach (var distinctComponent in splitPaths.Select(path => path.First()).Distinct())
{
Node subNode = new Node() { Text = distinctComponent };
node.Nodes.Add(subNode);
ParsePaths3(subNode, splitPaths.Where
(pathComponents => pathComponents.First() == distinctComponent &&
pathComponents.Count() > 1).Select(pathComponents => pathComponents.Skip(1)));
}
}
注意我如何将解析器的签名更改为 IEnumerable<IEnumerable<string>>。这消除了糟糕的 ToList() 调用,并且通过处理“列表的列表”,也消除了 string 的重新连接。一个辅助方法让我们能够同时使用两种样式:
static void ParsePaths3(Node node, List<string> paths)
{
ParsePaths3(node, paths.Select(p => p.Split('/')));
}
版本 4 - 控制反转
版本 3 的一个让我不满意的地方是它只做一件事——填充 Node 实例的树。这很好,但之后必须有其他东西来处理这个模型,比如将其转储到控制台或填充一个实际的 TreeView。
这就是关于代码质量/可维护性的“走最后一英里”的论点最常出现的地方。版本 3 中的实现可能对需求来说已经足够好了,所有使用它的人都明白它创建了一个“模型”,然后我们可以对这个模型进行操作,以满足我们“视图”的需求。毕竟,这背后就是有些半死不活的 Model-View-Controller (MVC) 模式以及更有生命力的 Model-View-ViewModel (MVVM) 模式的概念。
对于那些确实有物理模型(如某些数据库数据)需要表示的情况,这是一种可行的方法,但坦白说,这个解析器实际上并没有创建 MVC 或 MVVM 所认为的那种“模型”。解析器实际上只是一个解析器——事实上,它甚至不应该知道或关心它正在构建什么!
引入控制反转。在版本 4 中,我们传入一个 Func,它执行所需的、外部定义的操作,并返回一个(解析器不关心是什么)对象,该对象在递归时被传入。
public static void ParsePaths4<T>(
T node,
IEnumerable<IEnumerable<string>> splitPaths,
Func<T, string, int, T> action,
int depth = 0)
{
++depth;
foreach (var p2 in splitPaths.Select(p => p.First()).Distinct())
{
T ret = action(node, p2, depth);
ParsePaths4(ret, splitPaths.Where(p3 => p3.First() == p2 &&
p3.Count() > 1).Select(p4 => p4.Skip(1)), action, depth);
}
}
为了演示,我还在这段代码中加入了一个“深度”计数器。注意方法如何变成了一个泛型方法,其中 T 取代了当前节点的类型表示,并且传入的动作也预期返回一个 T 类型的对象,这通常代表子节点。
在前面的三个版本中,我调用解析器的方式是这样的:
List<string> paths = new List<string>() { "a/b/c", "a/b/d", "c/d/e" };
Node root = new Node();
ParsePaths3(root, paths);
现在我们必须传入实现解析器想要执行的特定行为的函数。这复现了版本 1-3 的功能:
ParsePaths4(root, paths, (node, text, depth) =>
{
Node subNode = new Node() { Text = text };
node.Nodes.Add(subNode);
return subNode;
});
但因为我们现在有一个通用的解析器,它与我们如何处理路径组件的实现解耦,我们可以编写一个实现,将结果输出到控制台窗口:
ParsePaths4<object>(null, paths, (node, text, depth) =>
{
Console.WriteLine(new String(' ', depth * 2) + text);
return null;
});
这里有一个有趣的地方——因为我们实际上只做打印 string 的操作,所以我们为“根节点”传入 null,并返回 null,因为我们不关心。因此,T 的类型必须被明确指定,在这里是 object,因为 null 无法推断出类型。

这是一个填充 TreeView 控件的实现:
Program.ParsePaths4(tvDemo.Nodes, paths, (nodes, text, depth) =>
{
TreeNode childNode = new TreeNode(text);
nodes.Add(childNode);
return childNode.Nodes;
});

这对于普通程序员来说会变得有点复杂,他们可能不熟悉或不习惯 Action、Func、匿名方法等(尽管如果他们已经在使用所有那些 LINQ,他们应该比较熟悉)。但我提到这一点是因为在编码过程中,有一个点可以优雅地编写代码并考虑可维护性,但这需要一个熟练的开发者来实际维护实现,而一个更简单的实现可以被初级程序员更容易地处理,他们可能会直接复制粘贴代码来改变行为。在那里,我们看到了优雅、可维护性、可重用性和技能之间的权衡。
结论
虽然这是一篇相当轻量级的文章,但我认为它涵盖了一些我们在重构原型代码(以及决定是否重构原型代码!)时应该注意的问题。希望这个案例研究提供了一些思考的素材,或者至少是一次有趣的阅读。
我没有想到的一件事,也是 SO 上某人提供的实现中的一个点,是提供一个默认分隔符参数,可以由调用者更改。代码改进是一个永无止境的过程!
历史
- 2017年4月5日:初始版本