
使用 Intel® Data Analytics Acceleration Library 优化线性回归方法
本文介绍了称为线性回归的常见回归分析类型,以及 Intel® 数据分析加速库 (Intel® DAAL) 如何在配备 Intel® Xeon® 处理器的系统上运行以优化此算法。
公司如何预测其在未来广告上的花费以增加销售额? 同样,公司应该在未来的培训计划上花费多少才能提高生产力?
在这两种情况下,这些公司都依赖于变量之间的历史关系,例如,前者是销售价值与广告支出之间的关系,以预测未来结果。
这是可以使用机器学习1 最佳解决的典型回归问题。
本文介绍了称为线性回归2 的常见回归分析类型,以及 Intel® 数据分析加速库 (Intel® DAAL) 3 如何在配备 Intel® Xeon® 处理器的系统上运行以优化此算法。
什么是线性回归?
线性回归 (LR) 是最基本的回归类型,用于预测分析。 LR 显示变量之间的线性关系以及一个变量如何受一个或多个变量影响。 受其他变量影响的变量称为因变量、响应变量或结果变量,其他变量称为自变量、解释变量或预测变量。
为了使用 LR 分析,我们需要检查 LR 是否适用于此数据集。 为此,我们需要观察数据的分布情况。 让我们看下面的两张图


在图 1 中,我们可以将一条直线拟合到数据点上;然而,在图 2 的数据点上却没有办法做到这一点。 只有曲线(非线性)可以拟合图 2 中的数据点。 因此,线性回归分析可以在图 1 的数据集上进行,但在图 2 的数据集上则不能。
根据自变量的数量,LR 分为两种类型:简单线性回归 (SLR) 和多元线性回归 (MLR)。
当只有一个自变量时,LR 称为 SLR,而 MLR 有一个以上的自变量。
一个因变量和一个自变量的最简单方程形式定义为
y = Ax + B (1)
其中
y:因变量
x:自变量
A:回归系数或直线的斜率
B:常数
问题是如何找到最佳拟合线,使得因变量 (y) 的观测值与预测值之间的差异最小。 换句话说,找到方程 (1) 中的 A 和 B,使得 |yobserved – ypredicted| 最小。
找到最佳拟合线的任务可以使用最小二乘法4 来完成。 它通过最小化从每个数据点到直线的垂直差(观测值和预测值之间的差异)的平方和来计算最佳拟合线。 垂直差也称为残差。
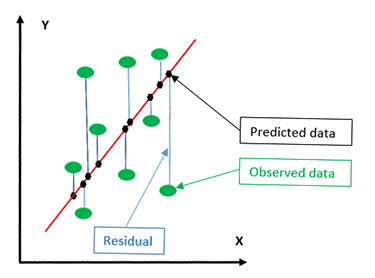
从图 3 中可以看出,绿点代表实际数据点。 黑点显示了数据点在回归线(红线)上的垂直(非垂直)投影。 黑点也称为预测数据。 实际数据和预测数据之间的垂直差称为残差。
线性回归的应用
可以很好地利用线性回归的一些应用
- 预测未来销售额。
- 分析产品销售的市场营销效果和定价。
- 评估金融服务或保险领域的风险。
- 在汽车中研究发动机性能的测试数据。
线性回归的优缺点
LR 的一些优点和缺点
- 优点
- 当自变量和因变量之间的关系几乎是线性的时候,结果是最优的。
- 缺点
- LR 对异常值非常敏感。
- 它不恰当地用于模拟非线性关系。
- 线性回归仅限于预测数值输出。
Intel® 数据分析加速库
Intel DAAL 是一个由许多基本构建块组成的库,这些构建块针对数据分析和机器学习进行了优化。 这些基本构建块针对最新的 Intel® 处理器的最新功能进行了高度优化。 LR 是 Intel DAAL 提供的预测算法之一。 在本文中,我们使用 Intel DAAL 的 Python* API 来构建一个基本的 LR 预测器。 要安装 DAAL,请遵循 如何在 Linux 中安装 Intel DAAL 的 Python 版本*5 中的说明。
在 Intel 数据分析加速库中使用线性回归算法
本节将介绍如何使用 Intel DAAL 在 Python*6 中调用线性回归方法。
参考部分提供了指向可用于测试应用程序的免费数据集的链接7。
执行以下步骤从 Intel DAAL 调用算法
- 使用 from 和 import 命令导入必要的包。
- 通过发出命令导入 Numpy
import numpy as np
- 通过发出以下命令导入 Intel DAAL 数值表
from daal.data_management import HomogenNumericTable
- 导入必要的函数到数值表中以存储数据
from daal.data_management import ( DataSourceIface, FileDataSource, HomogenNumericTable, MergeNumericTable, NumericTableIface)
- 使用以下命令导入 LR 算法
from daal.algorithms.linear_regression import training, prediction
- 通过发出命令导入 Numpy
- 如果数据输入来自 .csv 文件,则初始化文件数据源
trainDataSet = FileDataSource( trainDatasetFileName, DataSourceIface.notAllocateNumericTable, DataSourceIface.doDictionaryFromContext ) - 为训练数据和因变量创建数值表
trainInput = HomogenNumericTable(nIndependentVar, 0, NumericTableIface.notAllocate) trainDependentVariables = HomogenNumericTable(nDependentVariables, 0, NumericTableIface.notAllocate) mergedData = MergedNumericTable(trainData, trainDependentVariables)
- 加载输入数据
trainDataSet.loadDataBlock(mergedData)
- 创建一个函数来训练模型。
- 首先使用以下命令创建一个算法对象来训练模型
algorithm = training.Batch_Float64NormEqDense()
注意:此算法使用正规方程来解决线性最小二乘问题。 DAAL 还支持 QR 分解/因子分解。 - 使用以下命令将训练数据集和因变量传递给算法
algorithm.input.set(training.data, trainInput) algorithm.input.set(training.dependentVariables, trainDependentVariables)
其中
algorithm:如上一步 a 中定义的算法对象。 train
Input:训练数据。 trainDependent
Variables:训练因变量 - 使用以下命令训练模型
trainResult = algorithm.compute()
其中
algorithm:如上一步 a 中定义的算法对象。
- 首先使用以下命令创建一个算法对象来训练模型
- 创建一个函数来测试模型。
- 与上述第 2、3 和 4 步类似,我们需要创建用于测试的测试数据集
i。testDataSet = FileDataSource( testDatasetFileName, DataSourceIface.doAllocateNumericTable, DataSourceIface.doDictionaryFromContext )
ii。testInput = HomogenNumericTable(nIndependentVar, 0, NumericTableIface.notAllocate) testTruthValues = HomogenNumericTable(nDependentVariables, 0, NumericTableIface.notAllocate) mergedData = MergedNumericTable(testDataSet, testTruthValues)
iii。testDataSet.loadDataBlock(mergedData)
- 使用以下命令创建一个算法对象来测试/预测模型
algorithm = prediction.Batch()
- 使用以下命令将测试数据和训练模型传递给模型
algorithm.input.setTable(prediction.data, testInput) algorithm.input.setModel(prediction.model, trainResult.get(training.model))
其中
algorithm:如上一步 a 中定义的算法对象。
testInput:测试数据。 - 使用以下命令测试/预测模型
Prediction = algorithm.compute()
- 与上述第 2、3 和 4 步类似,我们需要创建用于测试的测试数据集
结论
线性回归是一种非常常见的预测算法。 Intel DAAL 优化了线性回归算法。 通过使用 Intel DAAL,开发人员可以利用未来几代 Intel Xeon 处理器的最新功能,而无需修改他们的应用程序。 他们只需要将应用程序链接到最新版本的 Intel DAAL。