
机器学习入门
4.88/5 (18投票s)
在本文以及后续关于机器学习的文章中,
目录
引言
为什么是机器学习?你为什么想了解机器学习?它对你的生活有什么影响?如果你不精通它,为什么至少需要了解机器学习的基础知识?所有这些问题的答案都非常简单。这是因为机器学习在日常生活中变得越来越重要,并且无论是自觉还是不自觉地,它已经成为我们生活的一部分,所以了解它是什么很重要。在本文以及后续关于机器学习的文章中,我们将尝试回答所有与机器学习相关的基础问题,以弄清楚机器学习是什么以及它能实现什么。
系列
我们将尝试以系列文章的形式涵盖机器学习的主题和概念,包括术语。这是第一篇文章,将侧重于可以进一步深入理解机器学习及其工作原理的宏观机器学习概念。以下是机器学习系列文章:
机器学习
那么,什么是机器学习?老实说,并没有一个大家公认的机器学习定义,但它是一个概念,并且有更多与此相关的核心概念。我们可以应用机器学习的一个重要领域是发现数据中的模式。然后,这些模式用于预测未来并做出决策。例如,在学习管理系统 (L.M.S.) 中,可以识别出学习者或读者在哪个章节、内容、图像上花费的时间最多,以及什么会引起个人的兴趣。可以应用机器学习概念来识别读者在学习内容中的每一个动作和花费的时间,从而,内容创建者将知道人们对内容的哪些领域更感兴趣,以及哪些需要改进或应该重点关注。另一个类似的例子是检测网上银行欺诈。
如果通过网上银行的资金转移持续发生欺诈,并且我们拥有完整的数据,我们就可以找出其中涉及的模式,从而识别出应用程序的漏洞或易受攻击的区域。所以,这一切都与模式以及基于这些模式预测结果和未来有关。因此,我们可以说机器学习在数据挖掘、图像处理和语言处理中起着重要作用。机器学习并不总是能提供正确的分析,或者并不总是能根据分析提供准确的结果,但它能根据历史数据提供一个预测模型来做出决策。数据越多,就能做出越以结果为导向的预测。
模式
让我们以阅读和学习为例。我们通过阅读来学习,但我们如何阅读?我们通过识别模式来阅读,我们识别字母,字母的模式来组成单词。然后,通过反复看到它,我们适应了这种模式。因此,我们学会了阅读,并最终通过阅读来学习。现在,回到我提到的网上银行欺诈,假设我们有网上银行交易的数据,我们可以创建一个预测分析模型并尝试了解未来。假设我们有五条交易记录。

如上图所示,我们有客户姓名、金额和欺诈交易的数据。
当我们查看数据并尝试识别模式时,除了得出所有以“J”开头的客户都有欺诈交易的结论外,我们并没有真正得到什么。但这并不是我们可以依赖的东西,因为这是一种模糊的预测。所以,我们识别正确模式的限制在这里是数据,或者可以说数据有限/较少。我们无法断定为什么这两笔交易很可能是欺诈性的。现在假设我们有更多的数据,如下所示。

所以,我们现在有大约 16 条交易记录,并且有更多详细信息,例如交易地点和客户年龄。如果我们仔细考虑数据并尝试找出模式,我们会发现所有欺诈交易都发生在中国,发生欺诈交易的客户年龄在 20 到 25 岁之间,并且发生欺诈的金额始终超过 20,000 美元。所以我们可以说我们在这里找到了一个模式,但是,我们能依赖这个分析并做出预测吗?我们有足够的数据进行分析吗?也许没有。我们需要越来越多的交易数据来真正根据模式预测行为。但当涉及到数百万条交易记录时,我们用肉眼(或手动)很难找到正确的模式。因此,我们需要软件来完成所有分析,机器学习就因此应运而生。
机器学习:宏观视角
从宏观上看,机器学习可以理解为如下图所示。
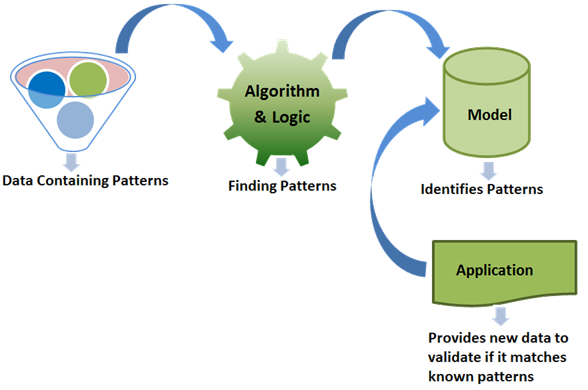
我们最初从大量包含模式的数据开始。这些数据进入机器学习逻辑和算法,以查找模式。预测模型是机器学习算法过程的结果。模型通常是识别新数据中可能模式的业务逻辑。应用程序用于向模型提供数据,以了解模型是否在新数据中识别出已知模式。在我们刚才的例子中,新数据可能是更多的交易数据。可能的模式意味着模型应该提出预测性模式来检查交易是否真的具有欺诈性。
机器学习:炒作
我们看到机器学习正在迅速发展,如今非常受欢迎。问题是为什么,对此有很多原因。首先,如果我们看看机器学习过程,我们会发现要正确地进行机器学习,我们需要输入大量数据。数据可以是结构化的或非结构化的,好消息是我们拥有这些数据。在这个大数据时代,我们不仅拥有大量数据,还拥有处理这些数据的计算能力。不仅如此,我们谈论云计算,它需要高效和隐含的机器学习算法,这些我们也拥有。所有这些在以前都不存在,但现在有了。另一个问题是,谁对机器学习感兴趣?真正关心机器学习的人是谁?总而言之,人们可以分为三类。第一类是企业主,他们总是需要解决方案来解决他们的业务需求和业务问题。例如,检查欺诈交易,检查客户转向其他提供商的可能性。机器学习通过提供更好的解决方案和准确的预测为业务增加价值。组织越大,其业务就越好、越快,因此对这些业务解决方案的需求始终存在。最好的事情是,企业主也愿意为商业解决方案付费。所以,我们看到机器学习已经超越了局限。
另一类是软件开发人员。他们关心机器学习,以便能够构建出色的应用程序来解决业务问题。如我们在机器学习模型中所见,应用程序依赖于由机器学习算法创建的预测模型来做出更好的预测。因此,软件开发人员实际上不必担心模型,或者不必真正成为模型专家,利用机器学习,他们可以构建智能应用程序,这些应用程序只是使用这些模型。
第三类人是数据科学家,他们确实需要有效且易于使用的工具。数据科学家是真正关心并深入了解统计学、机器学习工具/软件,并且真正是领域专家的人。数据科学家非常有限且昂贵,因为他们通过解决业务问题帮助企业增长,而增长业务意味着节省和赚取更多资金。因此,数据科学家本身对任何企业都具有价值,因为他们是知识、统计、问题领域和机器学习的完整组合。还有另一类人我们没有谈到,那就是制造机器学习产品和服务的供应商。
由于机器学习在很多方面都被称为预测分析,所以有提供分析的供应商,还有 SAAS、RapidMiner 等公司也参与其中。
在很多方面,机器学习是对传统数据挖掘分析的增值。这就是为什么 SAP、Oracle、Microsoft 和 IBM 等公司提供此类机器学习产品,因为他们知道这个领域涉及巨额资金,并且知道这是一个不断增长的市场的一部分。另一方面,当我们看到亚马逊、微软等公司提供云服务时,我们会发现机器学习产品已经存在其中。
R 编程
“R”是一种编程语言和环境,其魅力在于它是一种开源编程语言。以下是来自 r-project 的定义:
R 是一种用于统计计算和图形的语言和环境。它是一个 GNU 项目,与贝尔实验室(前 AT&T,现 Lucent Technologies)由 John Chambers 及其同事开发的 S 语言和环境类似。R 可以被认为是 S 的一种不同实现。有一些重要的区别,但许多为 S 编写的代码在 R 下可以 unaltered 运行。
R 提供了各种各样的统计(线性与非线性建模、经典统计检验、时间序列分析、分类、聚类……)和图形技术,并且高度可扩展。S 语言通常是统计方法研究的首选工具,而 R 为参与这项活动提供了一个开源途径。
这个定义本身就说明了这种语言,R 支持机器学习、统计计算以及更多。它包含用于解决各种机器学习问题的包。R 得到了许多商业机器学习产品的支持。R 并不孤单,Python 在这个领域也同样受欢迎,并且也包含与 R 类似的用于解决业务问题的包。
结论
为了进行智能对话并获得高水平的机器学习知识,我们理论上获得了良好的知识。我们可以说,利用机器学习,我们可以找到模式,然后创建一个模型,该模型可以识别新迭代数据中的这些模式,最后但同样重要的是,机器学习确实可以帮助任何组织实现增长。
参考文献
- R-Project
- Pluralsight 课程 - 机器学习入门