
使用 EPPlus 进阶 Excel
使用 EPPlus 创建具有专业外观的 Excel 文件(筛选器、图表、数据透视表)
目录
代码
演示中使用的 EPPlus 版本是 EPPlus 4.1.1。我用来验证文件有效性的 Excel 程序是 Excel 2013。这里有两点需要说明。第一点是,文章中展示的某些功能或某些技术可能不适用于以前版本的 Excel。这意味着,如果您尝试使用 Excel 2010 或更早版本打开文件,它可能会告诉您文件已损坏,无法正常打开。还有很小的可能性是它不适用于未来的 Excel 版本,但这不太可能,因为 Excel 内置了向后兼容性。第二点是,未来版本的 EPPlus 可能会实现 EPPlus 4.1.1 目前不具备的功能。本文解释了如何规避这个问题,但这在未来版本的 EPPlus 中可能就多余了。
可供下载的 Excel 文件未经 Excel 程序打开。当您运行该解决方案时,每次都会得到这些相同的 Excel 文件。因此,即使没有演示程序,您也可以用您的 Excel 程序版本来测试它们,并确保它们可以正确打开。如果不行,问题几乎肯定出在 Excel 而不是演示程序上。
数据
数据取自 AdventureWorks2014。如果您没有运行 SQL Server,也别担心。我添加了一个包含所有数据的 .csv 文件,并且演示程序默认配置为从 .csv 文件读取。您可以在演示程序中非常轻松地更改这一点。
我们将要处理的数据是来自 AdventureWorks2014 的订单详情。此 SQL 查询获取已成功完成(Sales.SalesOrderHeader.Status = 5)且由销售人员而非通过在线网站(Sales.SalesOrderHeader.OnlineOrderFlag = 0)下的订单的订单详情。订单详情包括下订单的销售人员、销售人员所在的地区、订单日期、所订购产品的详细信息,包括产品单价、订单折扣以及收取的总金额(LineTotal)。
select
TerritoryGroup = st.[Group],
TerritoryName = st.Name,
SalesPerson = pp.FirstName + ' ' + pp.LastName,
soh.OrderDate,
ProductCategory = pc.Name,
ProductSubcategory = psc.Name,
Product = p.Name,
sod.OrderQty,
sod.UnitPriceDiscount,
Discount = (sod.OrderQty * sod.UnitPrice * sod.UnitPriceDiscount),
sod.UnitPrice,
sod.LineTotal
from Sales.SalesOrderDetail sod
inner join Sales.SalesOrderHeader soh on sod.SalesOrderID = soh.SalesOrderID
inner join Sales.SalesPerson sp on soh.SalesPersonID = sp.BusinessEntityID
inner join Person.Person pp on sp.BusinessEntityID = pp.BusinessEntityID
inner join Sales.SalesTerritory st on sp.TerritoryID = st.TerritoryID
inner join Production.Product p on sod.ProductID = p.ProductID
inner join Production.ProductSubcategory psc on p.ProductSubcategoryID = psc.ProductSubcategoryID
inner join Production.ProductCategory pc on psc.ProductCategoryID = pc.ProductCategoryID
where soh.OnlineOrderFlag = 0
and soh.Status = 5
相应的 POCO 是 DataRow。
public class DataRow
{
public string TerritoryGroup { get; set; }
public string TerritoryName { get; set; }
public string SalesPerson { get; set; }
public DateTime OrderDate { get; set; }
public string ProductCategory { get; set; }
public string ProductSubcategory { get; set; }
public string Product { get; set; }
public short OrderQty { get; set; }
public decimal UnitPriceDiscount { get; set; }
public decimal Discount { get; set; }
public decimal UnitPrice { get; set; }
public decimal LineTotal { get; set; }
public int OrderYear { get { return OrderDate.Year; } }
public int OrderMonth { get { return OrderDate.Month; } }
}
分组还是不分组,这是个问题
您可以看到数据是作为原始数据或详细数据选择的。没有对它进行分组、求和或透视。这对于我们后面创建 Excel 数据透视表的例子很重要。但是,如果您打算创建的 Excel 只有静态数据(静态 = 不是 Excel 数据透视表),那么您也有机会在 SQL Server 中对数据进行操作,并返回已经处理好的结果,而不是在 .NET 端(LINQ)做同样的事情。如果是这样,我建议您总是选择在 SQL Server 中对数据进行分组和透视,因为 SQL Server 在这方面总是比 .NET 快十倍。
简单分组
AdventureWorks1_SimpleGrouping.xlsx
我们从一个简单的 Excel 开始,对原始数据进行一些直接的分组。我们不会使用 EPPlus 的任何高级功能。这个 Excel 将作为接下来所有内容的基础。每个标签页是一个不同的地区组(欧洲、北美、太平洋),对于每个地区组,我们创建一个订单收入表。行按销售人员、销售人员地区和订单年份分组。列按订单月份分组。我们最后在表格的两端添加一个总收入列和一个总收入行。

演示中的代码比这个代码片段要健壮得多。我从这个片段中省略了所有的样式和颜色设置,但它们都在演示代码中。我们从定义数字格式开始。负数按美国惯例定义,用括号括起来。后缀 "_)" 告诉 Excel 将所有数字正确地上下对齐。
// number formats
string positiveFormat = "#,##0.00_)";
string negativeFormat = "(#,##0.00)";
string zeroFormat = "-_)";
string numberFormat = positiveFormat + ";" + negativeFormat;
string fullNumberFormat = positiveFormat + ";" + negativeFormat + ";" + zeroFormat;
命名索引非常重要。这可能看起来是个微不足道的技巧,但我不会忽略它。可以理解,当您继续编码时,您会把所有的索引都记在脑子里,但随着您编写更健壮的代码,事情会变得复杂,而命名的索引在这种情况下是救命稻草。它还有一个好处,当您或其他人几个月或几年后重新审视代码时,您脑海中所有的索引都早已消失了,这能提供帮助。
// rows and columns indices
int startRowIndex = 2;
int territoryNameIndex = 2;
int salesPersonIndex = 3;
int orderYearIndex = 4;
int orderMonthFromIndex = 5;
int orderMonthToIndex = 16;
int totalIndex = 17;
第一个分组是按地区组进行的。对于每个地区组,我们创建一个新的工作表并将其添加到工作簿中。
// package
var ep = new ExcelPackage();
// workbook
var wb = ep.Workbook;
// group on territory group
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
// create new worksheet for every territory group
foreach (var territoryGroup in territoryGroups)
{
// new worksheet
var ws = wb.Worksheets.Add(territoryGroup.Key);
变量 rowIndex 保存当前行索引,当我们在当前行上完成工作后,我们会将它递增。第一行是标题行。
int rowIndex = startRowIndex;
// headers
ws.Cells[rowIndex, territoryNameIndex].Value = "Territory";
ws.Cells[rowIndex, salesPersonIndex].Value = "Salesperson";
ws.Cells[rowIndex, orderYearIndex].Value = "Order Year";
ws.Cells[rowIndex, totalIndex].Value = "Total";
// month headers
CultureInfo enUS = CultureInfo.CreateSpecificCulture("en-US");
for (int month = 1; month <= 12; month++)
{
string value = new DateTime(1900, month, 1).ToString("MMM", enUS);
ws.Cells[rowIndex, month - 1 + orderMonthFromIndex].Value = value;
}
rowIndex++;
第二个分组是按销售人员和销售人员所在地区进行的。
// group on salesperson, territory
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
// the index of the first data row, after the header row
int fromRowIndex = rowIndex;
foreach (var salesPersonGroup in salesPersonGroups)
{
第三个分组是按订单年份进行的。年份按降序排序,因为对于任何将要阅读此 Excel 文件的人来说,这是它们相关性的顺序。
// group on order year
// sort descending
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
// territory
string territoryName = salesPersonGroup.Key.TerritoryName;
ws.Cells[rowIndex, territoryNameIndex].Value = territoryName;
// salesperson
string salesperson = salesPersonGroup.Key.SalesPerson;
ws.Cells[rowIndex, salesPersonIndex].Value = salesperson;
// order year
int orderYear = orderYearGroup.Key;
ws.Cells[rowIndex, orderYearIndex].Value = orderYear;
最后的分组是按订单月份进行的。在分组之前,整行被设置为收入 0。请记住,有些月份不会出现在分组中,因为它们首先就不存在于原始数据中。对于那些月份,收入为 0。
// for all the months, set the default value to 0
// in case there is no data for this salesperson-year-month
ws.Cells[rowIndex, orderMonthFromIndex, rowIndex, orderMonthToIndex].Value = 0;
// group on order month
var orderMonthGroups = orderYearGroup.GroupBy(g => g.OrderDate.Month);
// revenues
foreach (var orderMonthGroup in orderMonthGroups)
{
// sum the line total over all the orders for this salesperson-year-month
decimal total = orderMonthGroup.Sum(d => d.LineTotal);
int orderMonth = orderMonthGroup.Key;
ws.Cells[rowIndex, orderMonth - 1 + orderMonthFromIndex].Value = total;
}
总计列是当前行从一月到十二月收入的总和。
// total column
string totalColumnAddress = ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
);
ws.Cells[rowIndex, totalIndex].Formula =
string.Format("SUM({0})", totalColumnAddress);
rowIndex++;
}
所有收入单元格的数字格式。如果收入为 0,它将显示为 "-"。
// the index of the last data row, before the total row
int toRowIndex = rowIndex - 1;
// cells format
ws.Cells[
fromRowIndex, orderMonthFromIndex,
toRowIndex, totalIndex
].Style.Numberformat.Format = fullNumberFormat; // #,##0.00_);(#,##0.00);-_)
最后一行是总计行。对于每一列,它是总计单元格上方所有数据行求和的结果。如果总收入为 0,它将显示为 0,而不是 "-"。
// total row header
ws.Cells[rowIndex, territoryNameIndex].Value = "Total";
// total row - per month
for (int columnIndex = orderMonthFromIndex; columnIndex <= totalIndex; columnIndex++)
{
string totalMonthAddress = ExcelCellBase.GetAddress(
fromRowIndex, columnIndex,
toRowIndex, columnIndex
);
ws.Cells[rowIndex, columnIndex].Formula =
string.Format("SUM({0})", totalMonthAddress);
}
// total row - all (bottom-right cell of the table)
string totalAddress = ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
);
ws.Cells[rowIndex, totalIndex].Formula =
string.Format("SUM({0})", totalAddress);
// total cells format
ws.Cells[
rowIndex, orderMonthFromIndex,
rowIndex, totalIndex
].Style.Numberformat.Format = numberFormat; // #,##0.00_);(#,##0.00)
}
}
标签页颜色
这是我用来给多个标签页上色的小技巧,通过对前一个标签页的色调进行微调。如果您有几批具有不同业务语义的标签页,并且希望通过不同的主色调来区分每个组,同时又希望每个标签页的颜色与旁边的其他标签页略有不同,这个技巧会很有用。这里的整个想法就是只选择一个起始颜色,即第一个标签页的颜色,然后让其他标签页的颜色由组中的标签页数量决定。

在演示中,主色调是蓝色,随着绿色值的增加,绿色会稀释蓝色。起始 RGB 颜色是 (0, 0, 154)。有三个地区组,它们的标签页颜色是 欧洲 (0, 0, 154)、北美 (0, 85, 187) 和 太平洋 (0, 170, 220)。
// group on territory group
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
// the starting color is (0, 0, 154)
int greenStep = 255 / territoryGroups.Count();
int blueStep = (255 - 154) / territoryGroups.Count();
int territoryGroupIndex = 0;
foreach (var territoryGroup in territoryGroups)
{
// new worksheet
var ws = wb.Worksheets.Add(territoryGroup.Key);
// tab color
int green = (territoryGroupIndex * greenStep);
int blue = (territoryGroupIndex * blueStep) + 154;
ws.TabColor = System.Drawing.Color.FromArgb(0, green, blue);
territoryGroupIndex++;
}
分类汇总
AdventureWorks2_SubTotals.xlsx
下一步是为之前的 Excel 增加分类汇总。我们将添加两种分类汇总行。第一种是每个销售人员的总计。第二种是每个地区的总计,即对每个地区的所有销售人员进行求和。

在 Excel 中进行分类汇总时,最好使用 SUBTOTAL 函数而不是 SUM 函数。SUBTOTAL 函数会忽略嵌套的分类汇总或任何其他聚合函数。它还会忽略不可见的单元格,这在我们稍后添加筛选器时会派上用场。SUBTOTAL 函数有两个参数。第一个参数是计算方法的代码。第二个是计算范围。我们需要求和方法,它的代码是 9,所以函数看起来像这样:SUBTOTAL(9, range)。这个链接 如何使用 SUBTOTAL 函数 概述了该函数,列出了所有可能的计算方法和一些例子。
接续上一个 Excel,我们稍微修改代码,为每个销售人员添加一个分类汇总行。在销售人员分组内部,我们跟踪到目前为止添加了多少行,并在销售人员循环结束时,在每个订单月份列下方添加一个 SUBTOTAL 函数。
// group on salesperson, territory
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
foreach (var salesPersonGroup in salesPersonGroups)
{
int salesPersonFromRowIndex = rowIndex;
// group on order year
// sort descending
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
// add row for each order year
rowIndex++;
}
int salesPersonToRowIndex = rowIndex - 1;
// sub total row
ws.Cells[rowIndex, territoryNameIndex].Value = salesPersonGroup.Key.TerritoryName;
ws.Cells[rowIndex, salesPersonIndex].Value = salesPersonGroup.Key.SalesPerson;
ws.Cells[rowIndex, orderYearIndex].Value = "S. Total";
// sub total for each order month
for (int columnIndex = orderMonthFromIndex; columnIndex <= orderMonthToIndex; columnIndex++)
{
using (var cells = ws.Cells[rowIndex, columnIndex])
{
string subtotalAddress = ExcelCellBase.GetAddress(
salesPersonFromRowIndex, columnIndex,
salesPersonToRowIndex, columnIndex
);
cells.Formula = string.Format("SUBTOTAL(9,{0})", subtotalAddress);
cells.Style.Numberformat.Format = numberFormat; // #,##0.00_);(#,##0.00)
}
}
rowIndex++;
}
现在我们为每个地区添加分类汇总行。一个地区可能有多个销售人员。对于这项任务,我们将使用 SUMIFS 函数。SUMIFS 函数根据条件执行求和。函数语法是 SUMIFS(求和范围, 第一个条件范围, 第一个条件, [第二个条件范围, 第二个条件, ...])。此链接 如何使用 SUMIFS 函数 中有关于该函数的概述。
我将省去 C# 代码,它在技术上与上面的代码性质相似。但让我们看看这张图片,试着理解这个函数是如何为我们工作的。所讨论的单元格是 F15。对于这个单元格,我们需要对二月份(F 列)中所有满足以下条件的收入求和:(1) 与德国地区(B 列)相关联,并且 (2) 不是分类汇总。SUMIFS 的第一个参数是求和范围 F3:F13。这个范围包括了来自德国以外地区和其他销售人员分类汇总的收入。接下来的两个参数是第一个条件及其范围。范围 B3:B13 是地区范围,条件是“Germany”。这告诉函数只考虑在范围 B3:B13 中所有单元格的值为“Germany”的行。最后的参数是第二个条件及其范围。范围 D3:D13 是订单年份和分类汇总的“S. Total”标题。条件是“<>S. Total”。这告诉函数只考虑值不为“S. Total”的行,从而有效地只选择了实际的订单年份。单元格 F15 的最终公式是 SUMIFS(F3:F13,B3:B13,"Germany",D3:D13,"<>S. Total")。

我们需要做的最后一件事是将总计行的函数从 SUM 改为 SUBTOTAL。正如我之前提到的,SUBTOTAL 会忽略其他的聚合函数,而我们需要忽略销售人员的分类汇总以得到最终结果。我们也可以采用另一种方式,即对各地区的分类汇总求和,但我更喜欢对收入源单元格进行求和。

合并单元格、自动筛选和冻结窗格
AdventureWorks3_AutoFilter_FreezePane.xlsx
现在我们已经完成了 Excel 的内容部分,我们将注意力转向其外观。Excel 需要易于阅读,所以我们将合并具有重复值的单元格。这样,Excel 就不会因细节而显得杂乱,并且会更悦目。然后,我们将添加自动筛选功能,以便任何阅读此 Excel 的人都可以根据自己的需要按值筛选行。最后,我们将添加冻结窗格,以锁定标题行和销售人员的列。

合并单元格
在销售人员和地区列下有重复的值,因为一个销售人员有多行用于订单年份和分类汇总。代码并不复杂。我们只需要找到每个销售人员的行范围,然后为销售人员和地区列合并它们。EPPlus 使合并单元格变得容易。一旦您选择了适当的单元格 ExcelRange cells = ws.Cells[...],您就可以启用 Merge 属性 cells.Merge = true。
// group on salesperson, territory
var salesPersonGroups = territoryGroup
.GroupBy(d => new { d.SalesPerson, d.TerritoryName })
.OrderBy(g => g.Key.SalesPerson);
foreach (var salesPersonGroup in salesPersonGroups)
{
int salesPersonFromRowIndex = rowIndex;
// group on order year
// sort descending
var orderYearGroups = salesPersonGroup
.GroupBy(g => g.OrderDate.Year)
.OrderByDescending(g => g.Key);
foreach (var orderYearGroup in orderYearGroups)
{
// add row for each order year
rowIndex++;
}
int salesPersonToRowIndex = rowIndex - 1;
int subTotalRowIndex = rowIndex;
// merge cells territory
using (var cells = ws.Cells[
salesPersonFromRowIndex, territoryNameIndex,
subTotalRowIndex, territoryNameIndex])
{
cells.Merge = true;
cells.Style.VerticalAlignment = ExcelVerticalAlignment.Center;
}
// merge cells salesperson
using (var cells = ws.Cells[
salesPersonFromRowIndex, salesPersonIndex,
subTotalRowIndex, salesPersonIndex])
{
cells.Merge = true;
cells.Style.VerticalAlignment = ExcelVerticalAlignment.Center;
}
rowIndex++;
}
自动筛选
要启用自动筛选,我们需要选择从左上角单元格到右下角单元格的整个表格。然后在选定的单元格上启用 AutoFilter 属性。
// rows and columns indices
int startRowIndex = 2;
int territoryNameIndex = 2;
int totalIndex = 17;
// rowIndex holds the current running row index
int toRowIndex = rowIndex;
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
autoFilterCells.AutoFilter = true;
}
冻结窗格
我们想冻结标题行和前三列:地区、销售人员和订单年份。我们需要选择一个单元格,该单元格左侧的所有列和上方的所有行都将被冻结。如果您再看一下上面的图片,我们想要的单元格是 E3,也就是销售人员 Jae Pak 在 2014 年一月份的收入。
// rows and columns indices
int startRowIndex = 2;
int orderMonthFromIndex = 5;
// ws type is ExcelWorksheet
ws.View.FreezePanes(startRowIndex + 1, orderMonthFromIndex); // E3
预选筛选器
AdventureWorks4_PreselectFilters.xlsx
我们的目标受众很可能是财务人员,他们十有八九会关注当年(2014年)和上一年(2013年)的收入。他们可能不需要看到2012年及更早年份的收入。同时,我们也不想从 Excel 中排除这些信息,以防他们偶尔需要。为此,我们希望预先选择订单年份筛选器的值。我们希望排除的值是2012年及更早的年份。如果任何阅读此 Excel 的人确实需要这些收入数字,他们可以打开筛选器并选择他们想要的。

Open XML
在许多其他未实现的功能中,EPPlus 没有提供任何预选筛选器的方法。然而,当 EPPlus 关上一扇门时,它会打开一扇窗。EPPlus 提供了对底层 Open XML 的访问权限,让您,程序员,有机会在 EPPlus 未实现的地方编辑 XML 并创建自己的实现。有人认为一些更流行和常用的 Excel 功能应该被实现,但这实际上取决于 EPPlus 的开发者。
在本文中,有很多地方我们会直接深入编写 XML。由于这是第一次,我将更详细地介绍如何做到这一点以及处理此类任务的一些策略。前提是您不了解 Open XML 语法。好吧,我也不知道,至少不是信手拈来。但作为一名经验丰富的程序员,可以期望您能在从未遇到过的 MSDN 页面中找到自己的方法,并具备理解新编程内容的良好感觉。
困难的部分是理解 XML 应该是什么样子。一旦你确定了 XML 片段,将其写入 EPPlus 就非常程序化了。为了获取 XML,我们手头有两个工具,第一个是 MSDN,第二个是你喜欢的压缩文件程序(WinZip、WinRAR、7-Zip)。MSDN 是你的首选工具,它包含了关于 Excel Open XML 的详细文档,所有内部层次结构以及一些更重要和突出 XML 类的示例。如果你正在寻找特定的 MSDN 文档但没有找到,我建议你从Worksheet 类开始,然后从那里深入研究 XML 类。另外,如果你需要,每个 MSDN 页面都会在左侧边栏列出所有的 XML 类。

让我们花点时间回顾一下什么是 .xlsx 文件。Excel 文件是一堆 XML 文本文件(.xlsx 中的“x”代表 XML),全部被打包在一个压缩的 ZIP 文件中,并且文件扩展名从 .zip 重命名为 .xlsx。你可以拿一个 Excel 文件,将扩展名重命名为 .zip,解压缩它,然后用文本编辑器阅读文件。当你需要快速了解 Excel 如何实现某个特定功能时,有时深入研究 MSDN 页面可能会很麻烦。我想为你制定一个策略来实现这个目标。
首先创建一个不带有所需功能的 Excel 文件。如果你是在 EPPlus 中生成的该文件,那么在 Excel 程序中打开它,再次保存并关闭 Excel。EPPlus 只生成 Excel 程序读取所需的最低限度的 XML。Excel 程序会保存一个更完整的 XML 以及它认为必要的其他任何内容。完成此操作后,在文件资源管理器中创建该文件的副本。在 Excel 中打开副本文件,添加所需功能,保存并关闭。现在你有两个 Excel 文件,除了一个功能外完全相同,我们想知道这种差异是如何以 XML 形式体现的。将这两个文件从 .xlsx 重命名为 .zip,并将它们都解压到单独的文件夹中。文件和文件夹的名称都非常不言自明,工作表文件位于 `xl\worksheets` 下,图表文件位于 `xl\charts` 下,数据透视表文件位于 `xl\pivotTables` 和 `xl\pivotCache` 下。你需要找到定义你的功能的那个文件。将该文件以及来自原始 Excel 的同名文件(不带功能的那个)隔离开。如果你打开它们中的任何一个,你会看到 XML 被压缩成一两行。你需要先对 XML 进行美化打印——换行和缩进——然后再继续。我通常使用两个编辑器中的一个来完成这个操作。第一个编辑器,在 Visual Studio 中打开 XML 文件,然后从工具栏进入 Edit -> Advanced -> Format Document (Ctrl+E, D)。第二个编辑器是 Notepad++。你需要事先安装 XML Tools 插件,然后从工具栏进入 Plugins -> XML Tools -> Pretty print (XML only - with line breaks)。另一种选择是通过代码美化打印所有 XML 文件。请在本文末尾的“杂项”一章中查找相关的讨论和代码示例。完成所有这些准备工作后,就可以深入研究 XML 了。通过比较这两个 XML 文件,你可以发现由 Excel 程序创建的功能是如何以 Open XML 实现的。一个文件会缺少一块 XML,而另一个则不会。那段 XML 片段就是你要找的。我认为最好的办法是使用文件比较程序(WinMerge、Beyond Compare),它会高亮显示相关的 XML。
现在我们完成了准备工作,让我们言归正传。我们知道自动筛选是在工作表中定义的,所以我们从 MSDN 页面 Worksheet class 开始,查找自动筛选。在子元素表中,我们找到了 autoFilter(自动筛选设置)。一旦我们开始编写这个 XML,你会发现 EPPlus 在我们启用 AutoFilter = true 时已经创建了 autoFilter XML 节点。

然后我们转到 MSDN 页面 AutoFilter class。在这个页面,我们查看子元素表,看看有没有什么有趣的东西。有一个 filterColumn(自动筛选列),从它的描述,即自动筛选列,看起来正是我们需要的东西。另外,在页面的顶部,对该类的单行描述中,描述指出了该元素的限定名称 x:autoFilter。限定名称包括命名空间(x),我们稍后会用到它。

我们继续浏览 MSDN 页面 FilterColumn class。限定名称是 x:filterColumn。有几个有趣的子元素引起了注意。第一个是 filters(筛选条件),第二个是 customFilters(自定义筛选)。第三个是 dynamicFilter(动态筛选)。这里的问题是选择哪一个。嗯,我们需要的是 filters(筛选条件)。知道这一点的方法是在 MSDN 上深入研究每个元素,或者看看 Excel 是如何实现它的。记住,你可以创建自己的 Excel 文件,将扩展名改为 zip,解压内容并开始阅读里面的 XML 文件。

在我们转到下一个元素之前,我们需要查看 FilterColumn class 的属性。属性 colId 指明了自动筛选器所在的列。从其描述来看,该值是从零开始的,并且非常重要,计数从自动筛选器的起点开始,而不是从工作表的起点开始。订单年份筛选器在工作表的 D 列下,但它也是自动筛选器起始的第三列。自动筛选器的第一列是工作表中的 B 列。第三列,表示为从零开始的索引,是 colId="2"。

我们部分 XML 片段看起来像这样。虽然不多,但我们正在路上。
<x:autoFilter>
<x:filterColumn colId="2">
</x:filterColumn>
</x:autoFilter>
我们转到 MSDN 页面 Filters class。限定名是 x:filters。这个元素只是单个筛选器的容器,但它有一个我们需要的属性。blank 属性指示是否启用(空白)。
![]()
如果你再看一下上面的图片,你会发现订单年份筛选器下的空白单元格属于地区分类汇总行和最终总计行。我们希望即使在筛选时也继续显示这些行。这意味着我们需要启用(空白)。所以,部分 XML 现在看起来像这样。
<x:autoFilter>
<x:filterColumn colId="2">
<x:filters blank="true">
</x:filters>
</x:filterColumn>
</x:autoFilter>
我们最后来看 MSDN 页面 Filter class。限定名是 x:filter。这个元素定义了每个单独的筛选器。筛选器的值在 val 属性中设置。

我们决定只显示当前(2014年)和上一个(2013年)订单年份以及分类汇总行。所以,我们的筛选器值是“2014”、“2013”和“S. Total”。现在最终的 XML 是这样的。
<x:autoFilter>
<x:filterColumn colId="2">
<x:filters blank="true">
<x:filter val="2014" />
<x:filter val="2013" />
<x:filter val="S. Total" />
</x:filters>
</x:filterColumn>
</x:autoFilter>
在我们开始编写我们想出的 XML 之前,我想向您展示两个扩展方法。正如它们的名字所示,AppendElement 和 AppendAttribute 分别创建 XML 节点或 XML 属性,并将其附加到它们操作的父 XML 节点上。由于我们将重复使用这些操作,最好将它们都封装在扩展方法中。
namespace System.Xml
{
public static partial class XmlExtensions
{
public static XmlElement AppendElement(this XmlNode parent, string namespace, string name)
{
var elm = parent.OwnerDocument.CreateElement(name, namespace);
parent.AppendChild(elm);
return elm;
}
public static XmlAttribute AppendAttribute(this XmlNode parent, string name, string value)
{
var att = parent.OwnerDocument.CreateAttribute(name);
att.Value = value;
parent.Attributes.Append(att);
return att;
}
}
}
我们从设置一些预定义变量开始。变量 rowIndex 是我们之前构建整个表格时定义的,此时它持有表格最后一行的索引。变量 filterColumnIndex 是我们想要操作的筛选器的索引,在本例中是订单年份筛选器。变量 filterValues 列出了选定的筛选器值。正如之前讨论的,当我们构建 XML 时,我们需要“2014”、“2013”和“S. Total”。布尔变量 blanks 表示是否选择了“(空白)”。
// rows and columns indices
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderYearIndex = 4;
int totalIndex = 17;
// rowIndex holds the current running row index
int toRowIndex = rowIndex;
// order year column D
int filterColumnIndex = orderYearIndex;
// filters: current year 2014, previous year 2013, S. Total
string[] filterValues = new string[] { "2014", "2013", "S. Total" };
// include (Blanks)
bool blanks = true;
选择整个表格并启用自动筛选。
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
// enable auto filter
autoFilterCells.AutoFilter = true;
EPPlus 的 ExcelWorksheet 类有一个 WorksheetXml 属性。这个属性是通往工作表内部 Open XML 的入口。这个 XML 描述了工作表,并且,除其他事项外,定义了工作表的自动筛选及其操作方式。
XmlDocument xdoc = autoFilterCells.Worksheet.WorksheetXml;
当我们构建 XML 时,我们看到 XML 元素有命名空间前缀 "x"。命名空间是 XML 元素限定名的一部分。我们需要注册该命名空间。大多数时候,您不必编写命名空间 URI 字面量字符串,它已经由 XmlDocument.DocumentElement.NamespaceURI 提供了。如果命名空间在命名空间管理器 XmlNamespaceManager 中不存在,您必须用命名空间前缀注册它。对于这种情况,我们用命名空间 "http://schemas.openxmlformats.org/spreadsheetml/2006/main" 注册前缀 "x"。
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
当我们之前启用自动筛选时,EPPlus 创建了 x:autoFilter XML 节点。这是我们需要编辑的 XML 节点,所以我们用 XPath 找到它。XPath 字符串简短而简单:"/x:worksheet/x:autoFilter"。
// <x:autoFilter>
var autoFilter = xdoc.SelectSingleNode("/x:worksheet/x:autoFilter", nsm);
我们添加 x:filterColumn 节点。如前所述,colId 属性是从自动筛选表的起始位置计算的,而不是从 A 列开始。
// <x:filterColumn colId="2">
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
int colId = filterColumnIndex - autoFilterCells.Start.Column;
filterColumn.AppendAttribute("colId", colId.ToString());
接下来,我们添加 x:filters 节点并启用 blank 属性。
// <x:filters blank="true">
var filters = filterColumn.AppendElement(schemaMain, "x:filters");
if (blanks)
filters.AppendAttribute("blank", "true");
最后,我们添加单个的 x:filter 节点。
// <x:filter val="filterValue" />
foreach (var filterValue in filterValues)
{
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("val", filterValue);
}
到目前为止,我们只预选了筛选器,但没有隐藏需要隐藏的行。我们必须遍历所有与任何筛选器都不匹配的行,并手动隐藏它们 ExcelWorksheet.Row(rowIndex).Hidden = true。
D 列下所有的订单年份单元格,不包括 D2 的标题单元格,以及它们的单元格值。
var filterCells = ws.Cells[
autoFilterCells.Start.Row + 1, filterColumnIndex,
autoFilterCells.End.Row, filterColumnIndex
];
var cellValues = filterCells.Select(cell => new
{
Value = (cell.Value ?? string.Empty).ToString(),
cell.Start.Row // row index
});
判断每个单元格的值是否不属于任何一个可能的筛选器。如果不是,该单元格所在的行应该被隐藏。
var hiddenRows = cellValues
.Where(c => filterValues.Contains(c.Value) == false)
.Select(c => c.Row);
如果我们包含(空白)筛选器,我们必须从隐藏行列表中移除所有具有空单元格值的行。
if (blanks)
{
hiddenRows = hiddenRows
.Except(cellValues.Where(c => string.IsNullOrEmpty(c.Value))
.Select(c => c.Row));
}
由于合并了单元格,我们必须从最后一行迭代到第一行。如果我们隐藏了合并单元格的第一行,它将隐藏该单元格中包含的所有行。
hiddenRows = hiddenRows.OrderByDescending(r => r);
隐藏不匹配任何筛选器的行。
foreach (var row in hiddenRows)
ws.Row(row).Hidden = true;
}
就是这样。这是完整的代码。
// rows and columns indices
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderYearIndex = 4;
int totalIndex = 17;
// rowIndex holds the current running row index
int toRowIndex = rowIndex;
// order year column D
int filterColumnIndex = orderYearIndex;
// filters: current year 2014, previous year 2013, S. Total
string[] filterValues = new string[] { "2014", "2013", "S. Total" };
// include (Blanks)
bool blanks = true;
using (ExcelRange autoFilterCells = ws.Cells[
startRowIndex, territoryNameIndex,
toRowIndex, totalIndex])
{
// enable auto filter
autoFilterCells.AutoFilter = true;
XmlDocument xdoc = autoFilterCells.Worksheet.WorksheetXml;
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
// <x:autoFilter>
var autoFilter = xdoc.SelectSingleNode("/x:worksheet/x:autoFilter", nsm);
// <x:filterColumn colId="2">
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
int colId = filterColumnIndex - autoFilterCells.Start.Column;
filterColumn.AppendAttribute("colId", colId.ToString());
// <x:filters blank="true">
var filters = filterColumn.AppendElement(schemaMain, "x:filters");
if (blanks)
filters.AppendAttribute("blank", "true");
// <x:filter val="filterValue" />
foreach (var filterValue in filterValues)
{
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("val", filterValue);
}
var filterCells = ws.Cells[
autoFilterCells.Start.Row + 1, filterColumnIndex,
autoFilterCells.End.Row, filterColumnIndex
];
var cellValues = filterCells.Select(cell => new
{
Value = (cell.Value ?? string.Empty).ToString(),
cell.Start.Row // row index
});
var hiddenRows = cellValues
.Where(c => filterValues.Contains(c.Value) == false)
.Select(c => c.Row);
if (blanks)
{
hiddenRows = hiddenRows
.Except(cellValues.Where(c => string.IsNullOrEmpty(c.Value))
.Select(c => c.Row));
}
hiddenRows = hiddenRows.OrderByDescending(r => r);
// hide rows
foreach (var row in hiddenRows)
ws.Row(row).Hidden = true;
}
Open XML 命名空间
之前,我们看到在向 EPPlus 写入 XML 之前,我们需要注册一个命名空间前缀。您可能会遇到无法利用 XmlDocument.DocumentElement.NamespaceURI 的情况,您需要弄清楚哪个命名空间 URI 与哪个命名空间前缀对应。没有简单的答案,除非在网上搜索或通过整个过程找出 Excel 是如何做的。但是,我想在这里列出我们将在本文中使用的三个命名空间。
Excel 的默认命名空间是 "http://schemas.openxmlformats.org/spreadsheetml/2006/main",前缀是 "x"。我们已经遇到过了。用于绘图的命名空间——颜色、透明度、大小、距离、效果,所有这些东西——是 "http://schemas.openxmlformats.org/drawingml/2006/main",它的前缀是 "a"。用于图表的命名空间是 "http://schemas.openxmlformats.org/drawingml/2006/chart",它的前缀是 "c"。
// prefix "x"
string schemaMain = "http://schemas.openxmlformats.org/spreadsheetml/2006/main";
// prefix "a"
string schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
// prefix "c"
string schemaChart = "http://schemas.openxmlformats.org/drawingml/2006/chart";
簇状柱形图
AdventureWorks5_ColumnClusteredChart.xlsx
没有一两个图表,专业的 Excel 是不完整的。在本章和下一章中,我们将添加一个柱形图和一个饼图。在您自己的工作中,您可能不需要这些确切类型的图表。然而,我们将要做的图表修改和基本工作对所有图表都是一样的。EPPlus 在图表方面有相当广泛的能力,但它并没有实现所有功能。最好的方法是尽可能多地通过 EPPlus 设置图表属性,然后通过 Open XML 进行修改。

对于每个工作表(地区组),我们希望添加一个簇状柱形图来比较不同地区在一段时间内的收入。条形图代表地区组中的各个地区,X 轴是月份,Y 轴是收入。我们为每个地区组创建一个新的工作表,然后开始构建表格。重点将放在我们处理地区总计行的时候。
// rows and columns indices
int startRowIndex = 2;
int orderMonthFromIndex = 5;
int orderMonthToIndex = 16;
// group on territory group
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
foreach (var territoryGroup in territoryGroups)
{
// new worksheet
var ws = wb.Worksheets.Add(territoryGroup.Key);
int rowIndex = startRowIndex;
/* build the table up to the territory total rows */
使用 ExcelWorksheet.Drawings.AddChart() 将图表添加到工作表。此方法的返回类型是所有图表的基类 ExcelChart,但每种类型的图表都有其自己的特殊属性,并且它们在各自的类型中实现——同样,都继承自 ExcelChart——因此将其向下转型至继承树是很重要的。在本例中,我们创建 eChartType.ColumnClustered 图表类型并将其转换为 ExcelBarChart。此类型的有趣属性是 ExcelBarChart.GapWidth,它决定了两个相邻条形之间的间隙大小。
下面的代码创建图表并设置其外观。这非常直接,但我想重点关注 Y 轴的显示单位。如果我们不设置显示单位,Excel 会将 Y 值设置为 200,000 的步长。所以,值将是 0; 200,000; 400,000; ... 1,800,000。这看起来不吸引人。通过将显示单位设置为 1000,Excel 会将每个 Y 值除以 1000,从而移除每个值的最后三个零。通过在 Y 值上添加字母“K”,我们给出了一个指示,即 Y 值实际上是 1000 的倍数。
// chart
string chartTitle = territoryGroup.Key;
ExcelBarChart chart = ws.Drawings.AddChart(
"crt" + chartTitle.Replace(" ", string.Empty),
eChartType.ColumnClustered
) as ExcelBarChart;
// size
chart.SetSize(1100, 500);
// title
chart.Title.Text = chartTitle;
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
// legend position
chart.Legend.Position = eLegendPosition.Bottom;
// Y axis
chart.YAxis.Font.Size = 9;
chart.YAxis.Border.Fill.Style = eFillStyle.NoFill;
// Y axis - display unit
chart.YAxis.DisplayUnit = 1000; // K
chart.YAxis.Format = "#,##0 K" + ";" + "(#,##0 K)";
// remove all tick marks
chart.XAxis.MajorTickMark = eAxisTickMark.None;
chart.XAxis.MinorTickMark = eAxisTickMark.None;
chart.YAxis.MajorTickMark = eAxisTickMark.None;
chart.YAxis.MinorTickMark = eAxisTickMark.None;
对于每个地区总计行,我们将其作为图表系列添加到图表中。一个系列由 X 轴和 Y 轴的范围组成。在这种情况下,X 轴是月份行(一月,二月,三月,...),Y 轴是该地区的总收入。
// group on territory
var territoryNameGroups = territoryGroup.GroupBy(d => d.TerritoryName).OrderBy(g => g.Key);
foreach (var territoryNameGroup in territoryNameGroups)
{
/* add territory total row */
// serie header (territory name)
string serieHeader = territoryNameGroup.Key;
// territory total row
string serieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
rowIndex, orderMonthFromIndex,
rowIndex, orderMonthToIndex
)
);
// months row: Jan, Feb, Mar, ...
string xSerieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
startRowIndex, orderMonthFromIndex,
startRowIndex, orderMonthToIndex
)
);
// add serie to chart
chart.Series.Add(serieAddress, xSerieAddress).Header = serieHeader;
rowIndex++;
}
将图表的位置设置在表格下方。这只有在表格完全构建完成并且我们知道表格的最后一行是什么之后才可能实现。
int toRowIndex = rowIndex - 1;
// chart position
int chartRow = toRowIndex + 3;
int chartRowOffsetPixels = 0;
int chartColumn = orderMonthFromIndex - 1;
int chartColumnOffsetPixels = 20;
chart.SetPosition(chartRow, chartRowOffsetPixels, chartColumn, chartColumnOffsetPixels);
}
图表看起来是这样的。

图表数据表
EPPlus 没有提供任何接口来启用图表数据表,所以我们将通过 Open XML 来启用它。无论图表类型如何,图表 Open XML 的入口点都是 ExcelChart.ChartXml。图表 XML 对象的命名空间是 "http://schemas.openxmlformats.org/drawingml/2006/chart",其前缀是 "c"。XML 层次结构从根部的 ChartSpace class 开始,然后是 Chart class,再然后是 PlotArea class。在 ChartSpace class 和 Chart class 下有各种属性,但本文中我们不需要它们,所以 XPath 将直接指向 c:plotArea,像这样 "/c:chartSpace/c:chart/c:plotArea"。

控制数据表的 XML 节点是 DataTable class,其限定名为 c:dTable。决定是否显示数据表键的子节点——在我们的例子中是地区名称——是 ShowKeys class,其限定名为 c:showKeys。这个 XML 节点有一个 val 属性,其可能的值为 0 表示隐藏,1 表示显示键。这是 XML。
<c:dTable>
<c:showKeys val="1">
</c:showKeys>
</c:dTable>
以及 C# 代码。该方法的 chart 参数类型为 ExcelChart,这是所有图表类型的基类,意味着这段代码不限于任何特定类型的图表。
// data table
EnableChartDataTable(chart, true);
public void EnableChartDataTable(ExcelChart chart, bool showLegendKeys)
{
var xdoc = chart.ChartXml;
var nsm = new System.Xml.XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/drawingml/2006/chart"
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var plotArea = xdoc.SelectSingleNode("/c:chartSpace/c:chart/c:plotArea", nsm);
// <c:dTable>
var dTable = plotArea.AppendElement(schemaChart, "c:dTable");
// <c:showKeys val="1">
var showKeys = dTable.AppendElement(schemaChart, "c:showKeys");
showKeys.AppendAttribute("val", (showLegendKeys ? "1" : "0"));
}
这是带有数据表的图表。
分离型三维饼图
AdventureWorks6_PieExploded3DChart.xlsx
这个三维饼图显示了每个地区在总收入中所占的百分比。正如我们处理前一个图表一样,我们将尽可能多地使用 EPPlus 来完成工作,然后通过 Open XML 对其进行修饰,为其添加一些阴影,使其具有金属质感,并使其棱角(边缘)变圆。这样图表就不会显得单调乏味。

总收入位于地区总计行的总计列(最后一列)。因为这个图表我们只需要一个数据系列,所以我们将在构建地区总计行之前和之后,分别记录其起始行索引(territoryNameFromRowIndex)和结束行索引(territoryNameToRowIndex)。
// rows and columns indices
int startRowIndex = 2;
int territoryNameIndex = 2;
int orderMonthFromIndex = 5;
int totalIndex = 17;
// group on territory group
var territoryGroups = data.GroupBy(d => d.TerritoryGroup).OrderBy(g => g.Key);
foreach (var territoryGroup in territoryGroups)
{
// new worksheet
var ws = wb.Worksheets.Add(territoryGroup.Key);
int rowIndex = startRowIndex;
/* build the table up to the territory total rows */
// group on territory
var territoryNameGroups = territoryGroup.GroupBy(d => d.TerritoryName).OrderBy(g => g.Key);
int territoryNameFromRowIndex = rowIndex;
foreach (var territoryNameGroup in territoryNameGroups)
{
/* add territory total row */
rowIndex++;
}
int toRowIndex = rowIndex - 1;
int territoryNameToRowIndex = rowIndex - 1;
现在我们添加图表并设置其外观。
// chart
ExcelPieChart chart = ws.Drawings.AddChart(
"crtRevenues",
eChartType.PieExploded3D
) as ExcelPieChart;
// size
chart.SetSize(700, 500);
// title
chart.Title.Text = "Revenues";
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
// delete legend
chart.Legend.Remove();
如前所述,这个图表只有一个数据系列,即各地区的总收入。有趣的部分是能够改变系列本身的外观。返回的 ExcelPieChartSerie 实例允许您更改数据标签的外观(内容、位置),并通过将数据成员 Explosion 设置为特定百分比来更改饼图块之间的距离。
// territories total revenues
string serieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
territoryNameFromRowIndex, totalIndex,
territoryNameToRowIndex, totalIndex
)
);
// territory names
string xSerieAddress = ExcelCellBase.GetFullAddress(
ws.Name,
ExcelCellBase.GetAddress(
territoryNameFromRowIndex, territoryNameIndex,
territoryNameToRowIndex, territoryNameIndex
)
);
// add serie to chart
ExcelPieChartSerie pieChartSerie =
chart.Series.Add(serieAddress, xSerieAddress) as ExcelPieChartSerie;
// serie appearance
pieChartSerie.DataLabel.ShowCategory = true;
pieChartSerie.DataLabel.ShowPercent = true;
pieChartSerie.DataLabel.ShowLeaderLines = true;
pieChartSerie.DataLabel.Position = eLabelPosition.OutEnd;
pieChartSerie.Explosion = 10; // percent
最后,我们将图表的位置设置在之前的簇状柱形图下方。
// chart position
int chartRow = toRowIndex + 30;
int chartRowOffsetPixels = 0;
int chartColumn = orderMonthFromIndex + 1;
int chartColumnOffsetPixels = 30;
chart.SetPosition(chartRow, chartRowOffsetPixels, chartColumn, chartColumnOffsetPixels);
}
到目前为止,图表是这个样子的。

英国度量单位 (EMU)
Open XML(特别是 DrawingML)的关键度量单位是英国度量单位(English Metric Unit),简称 EMU。EMU 定义为 1/360000 厘米。所以,1 厘米等于 360000 EMU。在这篇文章 为什么是 EMU? 和这个维基百科条目 DrawingML - Office Open XML 文件格式 中有一些非常有见地的解释,说明了为什么选择这个单位。我将尝试给出要点。EMU 与现实生活中的度量单位(厘米、英寸)相比非常小,因此允许进行整数运算(避免分数)。它可以被多个除数整除,如 2, 3, 4, 5, 6, 8, 9, 12, 18, 24, 32, 36, 72, 96,所以从非厘米和英寸的各种度量单位转换时有很多可能性。从一个度量单位转换为 EMU 时产生的任何分数都小到可以忽略不计。
对我们来说,最重要的是这段代码
int EMU_PER_CM = 360000;
int EMU_PER_INCH = 914400;
int EMU_PER_PIXEL = 9525;
int EMU_PER_POINT = 12700;
我们将使用这些常量将通过点或英寸给出的各种值转换为 EMU 值。这是这些值如何产生的数学解释。
厘米
1 EMU = 1/360000 厘米 (定义) ⇒
1 厘米 = 360000 EMU
英寸
1 英寸 = 2.54 厘米 = 2.54 * 360000 EMU = 914400 EMU
现代屏幕显示器的默认显示设置为 96 ppi。这也等于 72 dpi。在这个维基百科条目 每英寸点数 中,有关于为什么会这样的很好的解释和一些历史背景。
像素
96 ppi (每英寸像素数) ⇒
96 像素 = 1 英寸 = 914400 EMU ⇒
1 像素 = 914400 / 96 EMU = 9525 EMU
点
72 dpi (每英寸点数) ⇒
72 点 = 1 英寸 = 914400 EMU ⇒
1 点 = 914400 / 72 EMU = 12700 EMU
角度和百分比
当您在 Excel 程序中被提示输入角度或百分比时,您通常会在文本框中输入一个整数。但这些值在 Open XML 中的表示方式不同。设计 Open XML 的人的一个关键目标是,在 XML 中将数值表示为整数而不是分数。对于角度,这如何实现呢?用户当然可以输入 0 度到 360 度之间的任何数字,并具有任何他想要的精度(即分数)。解决这个问题的方法是限制角度的允许精度。在下一节中,我们将看到角度的精度是以 60000 分之一度(1/60000 度)来衡量的。这是一个权衡,角度的精度不能低于 1/60000 度,但角度可以通过乘以 60000 来表示为整数。乘法的结果表示给定角度中有多少个 1/60000 度。让我们看一些例子。
1/60000°: 1/60000 = (1/60000 * 60000) * 1/60000 = 1 * 1/60000 ⇒ XML: 1
1°: 1 = (1 * 60000) * 1/60000 = 60000 * 1/60000 ⇒ XML: 60000
5.5°: 5.5 = (5.5 * 60000) * 1/60000 = 330000 * 1/60000 ⇒ XML: 330000
360°: 360 = (360 * 60000) * 1/60000 = 21600000 * 1/60000 ⇒ XML: 21600000
请记住,您无法表示一个不能被 1/60000° 整除的角度。
(1 + 1/80000)°: 1.0000125 = (1.0000125 * 60000) * 1/60000 = 60000.75 * 1/60000
而 60000.75 不能被 60000 整除,它不是一个整数。
百分比也是如此。百分比精度以千分之一百分点(1/1000%)来衡量
1/1000%: 1/1000 = (1/1000 * 1000) * 1/1000 = 1 * 1/1000 ⇒ XML: 1
1%: 1 = (1 * 1000) * 1/1000 = 1000 * 1/1000 ⇒ XML: 1000
5.5%: 5.5 = (5.5 * 1000) * 1/1000 = 5500 * 1/1000 ⇒ XML: 5500
100%: 100 = (100 * 1000) * 1/1000 = 100000 * 1/1000 ⇒ XML: 100000
需要注意的是,这些精度在 Open XML 中并非通用。对于每个元素,您都需要查阅文档以找出元素类型的精度。在下一章中,当我们为图表添加阴影时,我们将使用类型为 ST_PERCENTAGE 的百分比元素和类型为 ST_POSITIVE_FIXED_ANGLE 的角度。前缀“ST”表示“简单类型”。
int ST_PERCENTAGE = 1000; // 1000th of a percent
int ST_POSITIVE_FIXED_ANGLE = 60000; // 60000th of a degree
图表阴影
接下来,我们在图表下方添加阴影。我认为这在 3D 饼图的基础上为图表增加了一些额外的深度。在我们开始编码之前,我们需要确定所有阴影参数的实际值。做这件事最好的地方当然是 Excel 程序。打开你目前生成的文件并编辑系列阴影。确保记下所有参数及其值。

阴影属性与图表系列相关,所以我们首先需要确定该系列。这将是整个 XML 的入口点。和前面的图表一样,我们从 PlotArea class 开始。这个类列出了各种图表类型作为子 XML 后代,除此之外,由于我们的图表是 3D 饼图,我们继续到 Pie3DChart class。阴影属性是特定于图表系列的,它们不是整个图表的全局属性(见上图),所以下一个 XML 节点是 PieChartSeries class。
我们正在寻找的 XML 节点是 ChartShapeProperties class,阴影属性将在这里,但在我们继续之前,我们需要确保从所有图表系列中选择正确的系列。在我们的例子中,我们只向图表添加了一个系列,所以没有太多选择,但我想将代码稍微概括一下,根据索引参数选择一个图表系列。其中一个子 XML 节点是 Index class。这个 XML 只是保存了系列在所有图表系列中的索引。如果参数是 serieIndex,那么从 PieChartSeries class 出发的 XPath 是 "c:ser[c:idx[@val='serieIndex']]"。通俗地说,这个 XPath 选择了一个 PieChartSeries class (c:ser),它有一个子 Index class (c:idx),该子类有一个值为 serieIndex 的属性 val (@val)。如果这些内容您看不懂,您需要复习一下 XPath。这里是 C# 代码的快速一瞥。
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
xml 节点 ChartShapeProperties class 有几个子节点,每个子节点都定义了图表的不同视觉方面,例如填充颜色、渐变、轮廓。它的子 XML 节点 EffectList class 是各种视觉效果的容器。其中一个效果是 OuterShadow class,这个类定义了图表的(外部)阴影。
如果我们看一下到目前为止的 XML,我们可以看到我们实际上使用了两个不同的命名空间。"c" 命名空间是图表命名空间,而 "a" 命名空间是模式命名空间。EffectList class 并非特定于图表,它可以在其他涉及绘图的对象中使用,这就是为什么它不存在于 "c" 图表命名空间下的原因。
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw>
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
OuterShadow class 具有 sx 和 sy 属性,它们是水平和垂直缩放因子。这些属性定义了阴影大小,在我们的例子中是 90%。百分比精度以千分之一百分点(1/1000%)来衡量,所以 XML 值为 90 * 1000 = 90000。属性 blurRad 设置阴影的模糊半径,在我们的例子中是 8 点。我们需要将此值与每点 12700 EMU 相乘,所以 XML 值为 8 * 12700 = 101600。属性 dist 设置阴影偏移的距离,在我们的例子中是 25 点。我们也需要将此值与 12700 相乘,所以 XML 值为 25 * 12700 = 317500。属性 dir 设置阴影偏移的方向,在我们的例子中是 90 度角。角度精度以 60000 分之一度(1/60000 度)来衡量,所以 XML 值为 90 * 60000 = 5400000。
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw sx="90000" sy="90000" blurRad="101600" dist="317500" dir="5400000">
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
我们仍然需要设置颜色和透明度。在 OuterShadow class 中,我们添加 RgbColorModelHex class,然后在其中添加 Alpha class。RgbColorModelHex class 设置阴影的颜色,在我们的例子中是 深橄榄色 #7F6000(红 127,绿 96,蓝 0)。val 属性是颜色的十六进制值。Alpha class 以百分比设置颜色的不透明度。alpha 值计算为 alpha = 100% - 透明度 = 100% - 70% = 30%,这就是 val 属性的值。
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:effectLst>
<a:outerShdw sx="90000" sy="90000" blurRad="101600" dist="317500" dir="5400000">
<a:srgbClr val="7F6000">
<a:alpha val="30%">
</a:alpha>
</a:srgbClr>
</a:outerShdw>
</a:effectLst>
</c:spPr>
</c:ser>
</c:pie3DChart>
XML 部分到此结束。现在是实现部分。代码以初始化一些对应于阴影参数的变量开始。您可以看到它们的值与系列阴影编辑菜单中的值相同。其余的代码与我们之前做的类似。
// the index of the serie
int serieIndex = 0;
// Color
int red = 127;
int green = 96;
int blue = 0;
// Transparency
int transparencyPer = 70;
// Size
int sizePer = 90;
// Blur
int blurPt = 8;
// Angle
int angleDgr = 90;
// Distance
int distancePt = 25;
/*************************************************/
int EMU_PER_POINT = 12700;
int ST_PERCENTAGE = 1000;
int ST_POSITIVE_FIXED_ANGLE = 60000;
/*************************************************/
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/drawingml/2006/chart"
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
if (nsm.HasNamespace("a") == false)
nsm.AddNamespace("a", schemaDrawings);
// <c:ser>
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
// <c:spPr>
var spPr = ser.SelectSingleNode("./c:spPr", nsm);
if (spPr == null)
spPr = ser.AppendElement(schemaChart, "c:spPr");
// <a:effectLst>
var effectLst = spPr.AppendElement(schemaDrawings, "a:effectLst");
// <a:outerShdw>
var outerShdw = effectLst.AppendElement(schemaDrawings, "a:outerShdw");
// <a:outerShdw sx="90000" sy="90000">
outerShdw.AppendAttribute("sx", (sizePer * ST_PERCENTAGE).ToString());
outerShdw.AppendAttribute("sy", (sizePer * ST_PERCENTAGE).ToString());
// <a:outerShdw blurRad="101600">
outerShdw.AppendAttribute("blurRad", (blurPt * EMU_PER_POINT).ToString());
// <a:outerShdw dist="317500">
outerShdw.AppendAttribute("dist", (distancePt * EMU_PER_POINT).ToString());
// <a:outerShdw dir="5400000">
outerShdw.AppendAttribute("dir", (angleDgr * ST_POSITIVE_FIXED_ANGLE).ToString());
// <a:srgbClr val="7F6000">
var srgbClr = outerShdw.AppendElement(schemaDrawings, "a:srgbClr");
srgbClr.AppendAttribute("val", string.Format("{0:X2}{1:X2}{2:X2}", red, green, blue));
// <a:alpha val="30%">
var alpha = srgbClr.AppendElement(schemaDrawings, "a:alpha");
alpha.AppendAttribute("val", (100 - transparencyPer) + "%");
这是带有阴影的图表。

图表材质和棱台
最后,我们设置图表的材质,并使其边缘更加圆润。材质将是金属,顶部和底部的棱台将被设置为 10 点的宽度和高度。

与阴影一样,这种 3D 格式针对特定系列,所有重要的东西都与 ChartShapeProperties class 中的 XML 内容有关,所以我将直接跳到那里。xml 节点 Shape3DType class 设置 3D 外观,其 prstMaterial 属性从 PresetMaterialTypeValues enumeration 中找到的预定义材质列表中设置材质。我们想要一个金属材质,所以属性值为 "metal"。
xml 节点 Shape3DType class 有两个子节点 BevelTop class 和 BevelBottom class,它们分别设置顶部和底部棱台的外观。它们都有相同的属性。w 属性设置棱台的宽度,h 属性设置棱台的高度。我们想将它们都设置为 10 点,所以 XML 值为 10 * 12700 = 127000。
<c:pie3DChart>
<c:ser>
<c:idx val="0" />
<c:spPr>
<a:sp3d prstMaterial="metal">
<a:bevelT w="127000" h="127000" />
<a:bevelB w="127000" h="127000" />
</a:sp3d>
</c:spPr>
</c:ser>
</c:pie3DChart>
和阴影一样,代码以初始化与 3D 格式参数对应的变量开始,其余部分是相同的公式化代码。
// the index of the serie
int serieIndex = 0;
// Material
string material = "metal";
// Top bevel
int topBevelWidthPt = 10;
int topBevelHeightPt = 10;
// Bottom bevel
int bottomBevelWidthPt = 10;
int bottomBevelHeightPt = 10;
/*************************************************/
int EMU_PER_POINT = 12700;
/*************************************************/
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/drawingml/2006/chart"
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var schemaDrawings = "http://schemas.openxmlformats.org/drawingml/2006/main";
if (nsm.HasNamespace("a") == false)
nsm.AddNamespace("a", schemaDrawings);
// <c:ser>
var ser = xdoc.SelectSingleNode(
"/c:chartSpace/c:chart/c:plotArea/c:pie3DChart/c:ser[c:idx[@val='" + serieIndex + "']]",
nsm
);
// <c:spPr>
var spPr = ser.SelectSingleNode("./c:spPr", nsm);
if (spPr == null)
spPr = ser.AppendElement(schemaChart, "c:spPr");
// <a:sp3d prstMaterial="metal">
var sp3d = spPr.AppendElement(schemaDrawings, "a:sp3d");
sp3d.AppendAttribute("prstMaterial", material);
// <a:bevelT w="127000" h="127000" />
var bevelT = sp3d.AppendElement(schemaDrawings, "a:bevelT");
bevelT.AppendAttribute("w", (topBevelWidthPt * EMU_PER_POINT).ToString());
bevelT.AppendAttribute("h", (topBevelHeightPt * EMU_PER_POINT).ToString());
// <a:bevelB w="127000" h="127000" />
var bevelB = sp3d.AppendElement(schemaDrawings, "a:bevelB");
bevelB.AppendAttribute("w", (bottomBevelWidthPt * EMU_PER_POINT).ToString());
bevelB.AppendAttribute("h", (bottomBevelHeightPt * EMU_PER_POINT).ToString());
这是图表的最终外观。比我们开始时好多了。
数据表
AdventureWorks7_DataTable.xlsx
这个 Excel 将为我们添加数据透视表的下一阶段做准备。在我们对数据进行任何分析之前,首先需要将其完整地上传到 Excel 中。需要注意的重要一点是,我们不会从 .NET 端对数据进行任何处理(分组、求和)。相反,数据会原封不动地加载。

假设数据有 5 万条记录,记录类型有 10 个数据成员。这些数据成员可能是 POCO 的属性,也可能是 DataTable 的列。简单的解决方案是遍历 5 万条记录,对每条记录迭代 10 次,将每个数据成员插入其 Excel 单元格,总共进行 50 万次迭代。如果您实际尝试过,您会发现这非常耗时,在任何生产环境中都是不可接受的。EPPlus 有几种方法,其唯一目的是非常快速高效地加载大量记录的数据。
// POCOs
ExcelRangeBase.LoadFromCollection<T>(IEnumerable<T> Collection)
// DataTable
ExcelRangeBase.LoadFromDataTable(DataTable Table)
// text file
ExcelRangeBase.LoadFromText(FileInfo TextFile)
// objects
ExcelRangeBase.LoadFromArrays(IEnumerable<object[]> Data)
除了快速加载数据外,如果存在标题行,这些方法还会从数据创建一个 Excel 表格并设置列筛选器。您可以从这些方法重载中选择是否需要标题行。

这段代码是关键部分。data 以 DataRow 集合的形式给出,我们之前已经从 SQL 或文件中读取过。然后,我们选择起始单元格(表的左上角),并使用 LoadFromCollection 将 data 加载到其中。我们还向 LoadFromCollection 传递了另外两个参数。参数 printHeaders 指示是否向表中添加一个包含 DataRow 属性名的标题行。参数 tableStyle 从一个固定的可能样式列表中设置表的样式。集合加载后,EPPlus 会给表起一个通用的名字,我们希望通过访问位于 ExcelWorksheet.Tables 的表集合,从中选择最后一个表,然后更改其名称来改变这个名字。
IEnumerable<DataRow> data;
bool printHeaders = true;
var tableStyle = OfficeOpenXml.Table.TableStyles.Medium2;
using (ExcelRangeBase range = ws.Cells[2, 2]
.LoadFromCollection<DataRow>(data, printHeaders, tableStyle)) { }
// data table
OfficeOpenXml.Table.ExcelTable tblData = ws.Tables[ws.Tables.Count - 1];
tblData.Name = "tblData";
这是带有所有样式的完整代码。请记住,标题行将填充 DataRow 属性的名称,而它们没有采用标题大小写格式。因此,我们需要遍历标题行中的每个单元格,并为其设置正确的标题。
// rows and columns indices
int startRowIndex = 2;
int territoryGroupIndex = 2;
int territoryNameIndex = 3;
int salesPersonIndex = 4;
int orderDateIndex = 5;
int productCategoryIndex = 6;
int productSubcategoryIndex = 7;
int productIndex = 8;
int orderQtyIndex = 9;
int unitPriceDiscountIndex = 10;
int discountIndex = 11;
int unitPriceIndex = 12;
int lineTotalIndex = 13;
int orderYearIndex = 14;
int orderMonthIndex = 15;
IEnumerable<DataRow> data;
bool printHeaders = true;
var tableStyle = OfficeOpenXml.Table.TableStyles.Medium2;
using (ExcelRangeBase range = ws.Cells[startRowIndex, territoryGroupIndex]
.LoadFromCollection<DataRow>(data, printHeaders, tableStyle))
{
// border style
range.Style.Border.Top.Style = ExcelBorderStyle.Thin;
range.Style.Border.Bottom.Style = ExcelBorderStyle.Thin;
range.Style.Border.Left.Style = ExcelBorderStyle.Thin;
range.Style.Border.Right.Style = ExcelBorderStyle.Thin;
// border color
range.Style.Border.Top.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Bottom.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Left.Color.SetColor(System.Drawing.Color.LightGray);
range.Style.Border.Right.Color.SetColor(System.Drawing.Color.LightGray);
}
// data table
OfficeOpenXml.Table.ExcelTable tblData = ws.Tables[ws.Tables.Count - 1];
tblData.Name = "tblData";
// headers
ws.Cells[startRowIndex, territoryGroupIndex].Value = "Territory Group";
ws.Cells[startRowIndex, territoryNameIndex].Value = "Territory";
ws.Cells[startRowIndex, salesPersonIndex].Value = "Salesperson";
ws.Cells[startRowIndex, orderDateIndex].Value = "Order Date";
ws.Cells[startRowIndex, productCategoryIndex].Value = "Product Category";
ws.Cells[startRowIndex, productSubcategoryIndex].Value = "Product Subcategory";
ws.Cells[startRowIndex, productIndex].Value = "Product";
ws.Cells[startRowIndex, orderQtyIndex].Value = "Quantity";
ws.Cells[startRowIndex, unitPriceDiscountIndex].Value = "Unit Price Discount";
ws.Cells[startRowIndex, discountIndex].Value = "Discount";
ws.Cells[startRowIndex, unitPriceIndex].Value = "Unit Price";
ws.Cells[startRowIndex, lineTotalIndex].Value = "Revenue";
ws.Cells[startRowIndex, orderYearIndex].Value = "Order Year";
ws.Cells[startRowIndex, orderMonthIndex].Value = "Order Month";
// headers style
using (var cells = ws.Cells[startRowIndex, territoryGroupIndex, startRowIndex, orderMonthIndex])
{
cells.Style.Font.Bold = true;
cells.Style.Font.Size = 11;
cells.Style.HorizontalAlignment = ExcelHorizontalAlignment.Center;
}
数据透视表
AdventureWorks8_PivotTables.xlsx
数据透视表允许您通过提取汇总数据并以视觉简洁的方式显示来分析大型数据集。EPPlus 支持数据透视表,但仅在一定程度上。缺失的功能都是在创建数据透视表后,最后的一些小修小补。在这个 Excel 中,我们将创建六个不同的数据透视表,每个都将强调其不同的方面以及克服 EPPlus 缺陷的不同方法。我们将采用与之前 Excel 中制作图表时相同的策略,我们会让 EPPlus 完成所有它能做的工作,然后用 Open XML 在这里那里做一些修改。
按销售人员统计的销售额
此数据透视表显示了所有销售人员及其总收入的列表。数据透视表将按收入降序排列。我们还将在其旁边添加一个图表,每当数据透视表更改时,图表也会相应更改。

首先,我们获取数据单元格。这些是构成我们在上一个 Excel 中构建的数据表的所有单元格。数据表在另一个工作表中,所以我们首先选择“Data”工作表,然后是该工作表中的数据表,最后是数据表单元格。
// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
接下来,我们创建数据透视表。方法 ExcelWorksheet.PivotTables.Add() 接受三个参数。第一个参数是数据透视表左上角的位置。第二个参数是数据透视表的数据单元格。第三个参数是数据透视表的名称。还有一些美学选择,例如启用总计行、设置标题和表格样式。
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtSalesBySalesperson";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Salesperson";
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium9;
当我们使用 ExcelWorksheet.PivotTables.Add() 创建数据透视表时,EPPlus 查看了“tblData”数据表中的所有列,并将它们添加到了数据透视表的 ExcelPivotTable.Fields 集合中。这个属性是我们可以使用的所有可能字段的集合。如果您碰巧创建了一个没有标题行的数据表,也就是说列没有合适的名称,您仍然可以通过其列索引选择一个字段。
数据透视表有四个部分:筛选器、行、列、值。数据透视表的行为取决于我们在每个部分放置哪些字段。相应的 ExcelPivotTable 属性是 PageFields(筛选器)、RowFields(行)、ColumnFields(列)、DataFields(值)。在我们的例子中,用 SQL 术语来说,我们想要对销售人员进行分组,并为每个人汇总其收入。我们还想为地区组设置一个筛选器,它将只显示属于从筛选器中选择的地区组值的销售人员。这段代码通过简单地将正确的透视表字段添加到正确的部分来完成所有这些操作。另外,请注意我们没有对销售人员字段进行排序,因为我们的目标是按收入排序,然而 EPPlus 没有实现在数据字段上排序的功能。我们接下来将通过 Open XML 来实现这一点。
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Salesperson
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
这是数据透视表的初始外观。

数据字段排序
我们希望在数据透视表的顶部看到收入最高的人。为此,我们需要按收入降序对数据透视表进行排序。为了实现这一点,我们需要根据收入字段对销售人员字段进行排序。被排序的字段是销售人员字段,排序的标准是收入字段。所以第一个任务是在 XML 内部定位这个字段。数据透视表 Open XML 的入口点是 ExcelPivotTable.PivotTableXml。第一个 XML 元素是 PivotTableDefinition class。这个 XML 元素包含了所有其他共同定义数据透视表的 XML 元素,例如行字段、列字段、数据字段、筛选器等等。XML 元素 PivotFields class 是参与数据透视表的所有字段的集合。在我们的例子中,我们只有三个这样的字段:地区组、销售人员和收入。一个数据透视表字段由 XML 元素 PivotField class 定义,我们通过它在集合中的位置找到我们想要的那个。EPPlus 通过属性 ExcelPivotTableField.Index 提供了数据透视表字段的位置。这是一个实现所有这些的代码片段。我想提醒您,XPath 的 position() 是一个基于 1 的索引。
ExcelPivotTableField field = salesPersonRowField;
var pivotField = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:pivotFields/x:pivotField[position()=" + (field.Index + 1) + "]",
nsm
);
现在我们选择了正确的透视字段,就可以开始操作它的排序了。属性 sortType 设置排序方向。其可能的值是 "ascending" 和 "descending",所以我们直接将它设置为 "descending"。接下来,元素 AutoSortScope class 处理数据透视表的排序范围。然后,元素 PivotArea class 定义要处理的数据透视表的哪个部分。再然后,元素 PivotAreaReferences class 定义了一组引用的字段。我们将在这里放置对收入数据字段的引用。count 属性指定有多少个引用,所以对我们来说它只是 "1"。元素 PivotAreaReference class 定义字段引用,其 field 属性是该引用字段的索引。然而,如果引用的字段是数据字段,则该属性值必须设置为 -2。从 MSDN 页面中的规范可以看出,field 属性的数据类型是无符号整数。负数的 int 到无符号 int 的转换是什么?计算是 ((2^32)-2) = 4294967296-2 = 4294967294。值 4294967294 就是我们放在属性中以指示引用字段是数据字段的值。XML 元素 FieldItem class 定义了一个字段的索引。字段索引在 v 属性中设置。我们需要在所有数据字段中找到该数据字段的索引。由于我们只有一个数据字段——收入——所以该索引将简单地为 0。
<x:pivotField sortType="descending">
<x:autoSortScope>
<x:pivotArea>
<x:references count="1">
<x:reference field="4294967294">
<x:x v="0" />
</x:reference>
</x:references>
</x:pivotArea>
</x:autoSortScope>
</x:pivotField>
排序是在 ExcelPivotTableField salesPersonRowField 上执行的,这是我们添加到数据透视表“行”区域的“销售人员”列。排序标准基于数据字段 ExcelPivotTableDataField revenueDataField,这是我们添加到数据透视表“值”区域的“收入”列。
ExcelPivotTableField field = salesPersonRowField;
ExcelPivotTableDataField dataField = revenueDataField;
bool descending = true;
/*************************************************/
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
// <x:pivotField sortType="descending">
var pivotField = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:pivotFields/x:pivotField[position()=" + (field.Index + 1) + "]",
nsm
);
pivotField.AppendAttribute("sortType", (descending ? "descending" : "ascending"));
// <x:autoSortScope>
var autoSortScope = pivotField.AppendElement(schemaMain, "x:autoSortScope");
// <x:pivotArea>
var pivotArea = autoSortScope.AppendElement(schemaMain, "x:pivotArea");
// <x:references count="1">
var references = pivotArea.AppendElement(schemaMain, "x:references");
references.AppendAttribute("count", "1");
// <x:reference field="4294967294">
var reference = references.AppendElement(schemaMain, "x:reference");
// Specifies the index of the field to which this filter refers.
// A value of -2 indicates the 'data' field.
// int -> uint: -2 -> ((2^32)-2) = 4294967294
reference.AppendAttribute("field", "4294967294");
// <x:x v="0">
var x = reference.AppendElement(schemaMain, "x:x");
int v = 0;
foreach (ExcelPivotTableDataField pivotDataField in pivotTable.DataFields)
{
if (pivotDataField == dataField)
{
x.AppendAttribute("v", v.ToString());
break;
}
v++;
}
数据透视表按收入降序排序。
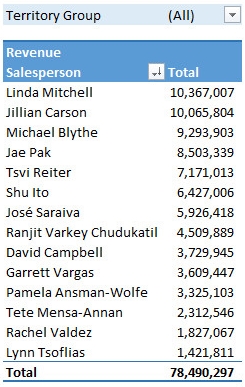
数据透视表图表
现在我们添加数据透视表图表。代码与添加普通图表非常相似,只是最后一个参数是作为图表数据源的数据透视表。这将把数据透视表和图表连接在一起。如果您更改数据透视表——在 Excel 中,而不是在代码中——图表也会相应地改变以反映数据透视表的变化。
ExcelBarChart chart = ws.Drawings.AddChart(
"crtSalesBySalesperson",
eChartType.BarClustered,
pivotTable
) as ExcelBarChart;
chart.SetPosition(1, 0, 4, 0);
chart.SetSize(600, 400);
chart.Title.Text = "Sales by Salesperson";
chart.Title.Font.Size = 18;
chart.Title.Font.Bold = true;
chart.GapWidth = 25;
chart.DataLabel.ShowValue = true;
chart.Legend.Remove();
chart.XAxis.MajorTickMark = eAxisTickMark.None;
chart.XAxis.MinorTickMark = eAxisTickMark.None;
chart.YAxis.DisplayUnit = 1000; // K
chart.YAxis.Deleted = true;
ExcelBarChartSerie serie = chart.Series[0] as ExcelBarChartSerie;
serie.Fill.Color = System.Drawing.Color.FromArgb(91, 155, 213);
我们需要修复两件事。移除垂直网格线,并按降序对图表进行排序。图表从一开始就没有按降序排序的原因是,我们之前的更改是通过 Open XML 而非 EPPlus 完成的。

图表网格线
我们之前看到,有趣的图表内容是在 PlotArea class 中定义的,所以我们就从那里开始。绘图区有两个坐标轴 XML 元素。第一个是 ValueAxis class,第二个是 CategoryAxis class。粗略地说,第一个处理 X 轴,第二个处理 Y 轴。对于我们的数据透视图,我们需要更改 X 轴。垂直网格线是 X 轴,因为 eChartType.BarClustered 的方向是垂直的。两个轴都有主要和次要网格线。主要网格线由 MajorGridlines class 定义,次要网格线由 MinorGridlines class 定义。图表中网格线的存在取决于相应的网格线 XML 元素是否存在。所以我们需要做的就是简单地删除 X 轴的主要网格线 XML 元素。
这段代码不仅仅是删除网格线。它也可以用来添加 X 轴和 Y 轴的主要和次要网格线。
bool isXAxis = true;
bool isMajorGridlines = true;
bool enable = false;
/*************************************************/
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/drawingml/2006/chart"
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
var axes = xdoc.SelectNodes(
string.Format("/c:chartSpace/c:chart/c:plotArea/{0}", (isXAxis ? "c:valAx" : "c:catAx")),
nsm
);
if (axes != null && axes.Count > 0)
{
foreach (XmlNode axis in axes)
{
var gridlines = axis.SelectSingleNode(
(isMajorGridlines ? "c:majorGridlines" : "c:minorGridlines"),
nsm
);
if (gridlines != null)
{
if (enable)
{
if (gridlines == null)
{
axis.AppendElement(
schemaChart,
(isMajorGridlines ? "c:majorGridlines" : "c:minorGridlines")
);
}
}
else
{
if (gridlines != null)
axis.RemoveChild(gridlines);
}
}
}
}
这是没有 X 轴网格线的图表。

图表分类顺序
剩下要做的就是将收入的顺序从高到低反转。正如我们之前看到的,CategoryAxis class 处理 Y 轴,而我们的 Y 轴是收入。在它内部,XML 元素 Scaling class 处理更多关于轴的设置,例如最小值和最大值。我们需要的元素是 Orientation class。在坐标轴的上下文中,此元素确定类别是从最小值到最大值排序,还是从最大值到最小值排序。val 属性的可能方向值是 "minMax" 和 "maxMin"。
<c:catAx>
<c:scaling>
<c:orientation val="maxMin">
</c:orientation>
</c:scaling>
</c:catAx>
这段代码设置了分类 (Y) 轴的顺序。
bool maxMin = true;
/*************************************************/
var xdoc = chart.ChartXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/drawingml/2006/chart"
var schemaChart = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("c") == false)
nsm.AddNamespace("c", schemaChart);
// <c:catAx>
var catAxs = xdoc.SelectNodes("/c:chartSpace/c:chart/c:plotArea/c:catAx", nsm);
if (catAxs != null && catAxs.Count > 0)
{
foreach (XmlNode catAx in catAxs)
{
// <c:scaling>
var scaling = catAx.AppendElement(schemaChart, "c:scaling");
// <c:orientation val="maxMin">
var orientation = scaling.AppendElement(schemaChart, "c:orientation");
orientation.AppendAttribute("val", (maxMin ? "maxMin" : "minMax"));
}
}
数据透视表图表的最终外观。

按产品子类别统计的销售额
此数据透视表显示了每个产品子类别的总收入,并筛选为仅显示前 5 名的收入。

主要代码与“按销售人员统计销售额”数据透视表基本相同。关键区别在于,产品子类别列被添加为行数据透视表字段,而不是销售人员列。图表的创建方式也与“按销售人员统计销售额”图表相同,因此我不会详细介绍。

// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtSalesByProductSubcategory";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium14;
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Product Subcategory
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
// sort on revenues
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = revenueDataField;
bool descending = true;
pivotTable.SortOnDataField(field, dataField, descending);
前 10 项
产品子类别的列表相当长,确切地说是 33 个子类别,但这对任何阅读它的人来说可能没什么用。我们只想关注顶部的子类别收入,而不关心谁在列表的底部。在 Excel 中,您可以启用“前 10 项”值筛选器,但 EPPlus 不提供任何类型的数据字段筛选器。

PivotFilters 类元素是所有筛选器的容器。count 属性表示数据透视表筛选器的数量。元素 PivotFilter 类是数据透视表筛选器。id 属性是一个无符号整数,用于标识筛选器。这意味着所有筛选器的 id 属性值只是一个从 1 开始的连续数字。type 属性设置筛选器的类型。可能的值为“count”、“percent”和“sum”。“count”类型会将弹出窗口(见上图)中的数据透视表筛选器设置为“项”。fld 属性告诉数据透视表筛选器要对哪个字段进行排序。iMeasureFld 属性告诉数据透视表筛选器要按哪个数据字段进行排序。在我们的例子中,fld 属性是“产品子类别”数据透视字段的索引,而 iMeasureFld 属性是“收入”数据字段的索引。如果再看一下数据工作表,您会发现“产品子类别”是第 6 列,所以 fld 属性的值是 5。只有一个数据字段,即“收入”列,所以 iMeasureFld 属性的值是 0。
<x:filters count="1">
<x:filter id="1" type="count" fld="5" iMeasureFld="0">
</x:filter>
</x:filters>
AutoFilter 类元素定义了筛选条件。我们已经在预选筛选器中遇到过这个元素。FilterColumn 类标识了将应用筛选的自动筛选列,其 colId 属性指定了它的索引。如果再看一下数据透视表,您会发现唯一的自动筛选列是数据透视表的第一列。所以,colId 属性的值是 0。元素 Top10 类定义了“前 10 项”筛选器。val 属性设置要显示的项数(或百分比)。top 属性决定是显示前几项(“1”)还是后几项(“0”)。percent 属性决定是按百分比值筛选(“1”),还是按项数筛选(“0”)。
<x:filters count="1">
<x:filter id="1" type="count" fld="5" iMeasureFld="0">
<x:autoFilter>
<x:filterColumn colId="0">
<x:top10 val="5" top="1" percent="0">
</x:top10>
</x:filterColumn>
</x:autoFilter>
</x:filter>
</x:filters>
这段代码会检查数据透视表是否还有其他筛选器,如果有,则保留它们,并将“前 10 项”筛选器附加到筛选器集合的末尾。
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = revenueDataField;
int number = 5;
bool bottom = false;
bool percent = false;
/*************************************************/
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
// <x:filters>
var filters = xdoc.SelectSingleNode("/x:pivotTableDefinition/x:filters", nsm);
int filtersCount = 0;
if (filters == null)
{
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
filters = pivotTableDefinition.AppendElement(schemaMain, "x:filters");
filtersCount = 1;
}
else
{
XmlAttribute countAttr = filters.Attributes["count"];
int count = int.Parse(countAttr.Value);
filtersCount = count + 1;
}
// <x:filters count="1">
filters.AppendAttribute("count", filtersCount.ToString());
// <x:filter id="1" type="count">
var filter = filters.AppendElement(schemaMain, "x:filter");
filter.AppendAttribute("id", filtersCount.ToString());
filter.AppendAttribute("type", (percent ? "percent" : "count"));
// <x:filter fld="5">
int fld = 0;
foreach (ExcelPivotTableField pivotField in pivotTable.Fields)
{
if (pivotField == field)
{
filter.AppendAttribute("fld", fld.ToString());
break;
}
fld++;
}
// <x:filter iMeasureFld="0">
int iMeasureFld = 0;
foreach (ExcelPivotTableDataField pivotDataField in pivotTable.DataFields)
{
if (pivotDataField == dataField)
{
filter.AppendAttribute("iMeasureFld", iMeasureFld.ToString());
break;
}
iMeasureFld++;
}
// <x:autoFilter>
var autoFilter = filter.AppendElement(schemaMain, "x:autoFilter");
// <x:filterColumn colId="0">
var filterColumn = autoFilter.AppendElement(schemaMain, "x:filterColumn");
filterColumn.AppendAttribute("colId", "0"); // the first auto filter in the pivot table
// <x:top10 val="5" top="1" percent="0">
var top10 = filterColumn.AppendElement(schemaMain, "x:top10");
top10.AppendAttribute("val", number.ToString());
top10.AppendAttribute("top", (bottom ? "0" : "1"));
top10.AppendAttribute("percent", (percent ? "1" : "0"));
订单
此数据透视表显示了每个产品子类别的收入明细。收入明细包括平均单价、售出单位数以及商品被订购的次数(一个订单可以包含多个单位)。数据透视表按订单数量降序排序。所有这些指标都反映了商品的销售情况。如果每个订单的单位数量增加(批量采购)、订单数量增加或两者兼有,平均单价就会提高。这类信息对于销售分析非常有用,数据透视表能以清晰简洁的方式展示销售趋势。

代码的开头部分非常简单。“区域组”列放入筛选器区域,“产品子类别”列放入行区域,“收入”列作为数据字段添加,就像我们之前处理数据透视表时一样。
// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtOrders";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium10;
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Product Subcategory
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
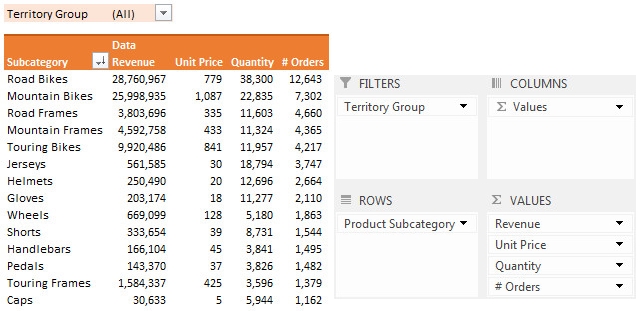
按平均值汇总值
到目前为止,所有的数据字段都是设置为对数据进行求和计算。我们通过将数据字段的 Function 属性设置为 DataFieldFunctions.Sum 来实现。现在,我们需要将“单价”列添加为数据字段,但需要将其计算为平均价格,为此,我们将 Function 属性设置为 DataFieldFunctions.Average 函数。
// values: Unit Price
ExcelPivotTableDataField unitPriceDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Unit Price"]
);
unitPriceDataField.Function = DataFieldFunctions.Average;
unitPriceDataField.Format = "#,##0_);(#,##0)";
unitPriceDataField.Name = "Unit Price";

售出的单位数量是“数量”列的总和。
// values: Quantity
ExcelPivotTableDataField quantityDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Quantity"]
);
quantityDataField.Function = DataFieldFunctions.Sum;
quantityDataField.Format = "#,##0_);(#,##0)";
quantityDataField.Name = "Quantity";
按计数汇总值
数据中的每一行代表一个订单,因此要找出某个产品子类别被订购了多少次,我们只需计算行数即可。对于这个数据字段,我们将 Function 属性设置为 DataFieldFunctions.Count 函数。我想指出的是,我们使用哪一列来计算行数并不重要。您可以在代码中看到,我们使用“数量”列作为数据字段的来源,但由于我们不需要实际的数量值,所以可以将其替换为任何我们喜欢的其他列,并且仍然能得到正确的结果。
// values: # Orders: Quantity Count
ExcelPivotTableDataField ordersCountDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Quantity"]
);
ordersCountDataField.Function = DataFieldFunctions.Count;
ordersCountDataField.Format = "#,##0_);(#,##0)";
ordersCountDataField.Name = "# Orders";

最后,我们按订单数量对产品子类别进行降序排序。
// sort on # orders
ExcelPivotTableField field = productSubcategoryRowField;
ExcelPivotTableDataField dataField = ordersCountDataField;
bool descending = true;
pivotTable.SortOnDataField(field, dataField, descending);
收入百分比
此数据透视表按每个产品子类别以及每个类别下的销售人员细分了总收入。产品子类别按收入降序排列,销售人员按收入升序排列。这种数据视图突出了那些销售业绩不佳的销售人员。收入排名前列的产品子类别很容易销售。那些在这些产品类别中收入占比较低的销售人员,不能将销售不佳归咎于产品本身,这意味着他们在工作中懈怠,或者作为销售人员的能力较差。除了总收入外,数据透视表还显示了每个销售人员的收入占总计的百分比,以及占其上级产品子类别的百分比。

这段代码构建了数据透视表的主体结构,但尚未添加百分比列。我们向行区域添加了两列,“产品子类别”和“销售人员”,但顺序很重要。顺序决定了哪个是父级,哪个是子级。如前所述,产品子类别的外部排序是降序,而销售人员的内部排序是升序。
// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtRevenuePercentage";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = true;
pivotTable.RowHeaderCaption = "Subcategory";
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium11;
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Product Subcategory
ExcelPivotTableField productSubcategoryRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Product Subcategory"]
);
// rows: Salesperson
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
// sort product subcategory on revenue, descending
pivotTable.SortOnDataField(productSubcategoryRowField, revenueDataField, true);
// sort salesperson on revenue, ascending
pivotTable.SortOnDataField(salesPersonRowField, revenueDataField, false);

将值显示为总计的百分比
EPPlus 不支持数据透视表数据字段的“值显示方式”功能。我们再次需要通过修改 Open XML 来实现。数据透视表列“收入百分比”将每个产品子类别和每个销售人员的收入显示为占总收入的百分比。在任何给定的产品子类别下,所有销售人员的百分比总和将等于该子类别占总收入的百分比。
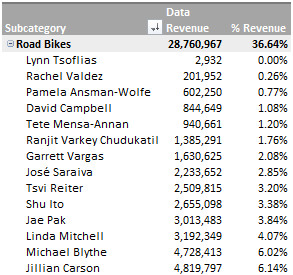
我们首先将“收入”列添加为数据透视表的数据列,同时将其显示格式设置为百分比格式 0.00%。
// values: % Revenue
ExcelPivotTableDataField revenuePercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenuePercentageDataField.Function = DataFieldFunctions.Sum;
revenuePercentageDataField.Format = "0.00%";
revenuePercentageDataField.Name = "% Revenue";

和之前一样,我们从 PivotTableDefinition 类开始。它包含 XML 元素 DataFields 类,这是一个包含各个数据字段的集合。数据字段由 XML 元素 DataField 类定义。name 属性设置数据字段的名称,我们通过这个属性找到需要操作的数据字段。
<x:pivotTableDefinition>
<x:dataFields>
<x:dataField name="% Revenue" showDataAs="percentOfTotal">
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
showDataAs 属性设置数据字段的显示方式。可能的值在 ShowDataAsValues 枚举中定义。我们的目标是将此数据字段设置为显示为“占总计的百分比”,为此,该属性的正确值是“percentOfTotal”。
// show % Revenue as percentage of revenue grand total
ExcelPivotTableDataField dataField = revenuePercentageDataField;
string showDataAs = "percentOfTotal";
/*************************************************/
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
// <x:dataField name="% Revenue">
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
// <x:dataField showDataAs="percentOfTotal">
dataFieldNode.AppendAttribute("showDataAs", showDataAs);
将值显示为父行汇总的百分比
此数据透视表列显示了每个销售人员的收入占其上级产品子类别的百分比。

与前一个数据透视表列一样,我们将“收入”列添加为数据透视表的数据列,并将其显示格式设置为百分比格式。
// values: % Parent
ExcelPivotTableDataField parentRowPercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
parentRowPercentageDataField.Function = DataFieldFunctions.Sum;
parentRowPercentageDataField.Format = "0.00%";
parentRowPercentageDataField.Name = "% Parent";

让我们再看一下 ShowDataAsValues 枚举。它只有 9 个可能的值,其中没有一个表示“按父行汇总的百分比”来显示值。实际上,Excel 程序中数据透视表数据列编辑弹窗中提供的许多其他选项,这个枚举中都没有。那么,它们到底在哪里定义呢?Open XML 的最初版本并没有列出这些选项,它们当时根本不存在。这些选项是在 Open XML 的后续版本(Excel 2010)中通过 Open XML 扩展定义的。
Open XML 具有扩展机制来定义未来的功能。它通过扩展来实现。扩展定义了 Open XML 标记的未来版本。扩展的集合由 ExtensionList 类元素定义。单个扩展由 Extension 类元素定义。每个扩展都有一个 uri 属性,它作为一个标识符,指示有关扩展的信息。由 XML 的使用者(例如 Excel 程序)根据 uri 的值来决定是否知道如何处理该扩展。实际的功能定义在扩展的 XML 元素内部。
数据透视表的扩展列在这个 MSDN 页面上:数据透视表扩展。我们需要的扩展是用于扩展数据透视字段的,其 uri 是 {E15A36E0-9728-4e99-A89B-3F7291B0FE68}。XML 元素 dataField 是这个扩展的实际实现。该元素定义的命名空间是 "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main",前缀是 "x14"。dataField 元素是 CT_DataField 类型的,这是一个复杂类型。关于这个类型的文档可以在此链接中找到:CT_DataField。我们感兴趣的是该类型的 pivotShowAs 属性。pivotShowAs 属性可以设置为 PivotShowAs 枚举中的一个值。这个枚举列出了所有与父级相关的选项和排名选项。我们需要的选项是“占父行汇总的百分比”,其值为“percentOfParentRow”。
最后,XML 元素 PivotTableDefinition 类有一个 updatedVersion 属性,正如 MSDN 所说,“指定上次更新数据透视表视图的应用程序的版本”。您为该属性设置的版本与 Excel 的版本相关,如果不设置此属性,Open XML 扩展将不起作用。对于 Excel 2013 及更高版本,我建议您将此属性设置为“5”或更高。
<x:pivotTableDefinition updatedVersion="5">
<x:dataFields>
<x:dataField name="% Parent">
<x:extLst>
<x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
<x14:dataField pivotShowAs="percentOfParentRow">
</x14:dataField>
</x:ext>
</x:extLst>
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
以上 XML 的实现。
// show % Parent as percentage of parent row (= product subcategory revenue)
ExcelPivotTableDataField dataField = parentRowPercentageDataField;
string pivotShowAs = "percentOfParentRow";
/*************************************************/
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var schemaMainX14 = "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main";
if (nsm.HasNamespace("x14") == false)
nsm.AddNamespace("x14", schemaMainX14);
// <x:pivotTableDefinition updatedVersion="5">
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
pivotTableDefinition.AppendAttribute("updatedVersion", "5");
// <x:dataField name="% Parent">
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
// <x:extLst>
var extLst = dataFieldNode.AppendElement(schemaMain, "x:extLst");
// <x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
var ext = extLst.AppendElement(schemaMain, "x:ext");
ext.AppendAttribute("uri", "{E15A36E0-9728-4e99-A89B-3F7291B0FE68}");
// <x14:dataField pivotShowAs="percentOfParentRow">
var x14DataField = ext.AppendElement(schemaMainX14, "x14:dataField");
x14DataField.AppendAttribute("pivotShowAs", pivotShowAs);
将值显示为父级汇总的百分比(使用基本字段)
在前一个数据透视表列中,我们将父行(产品子类别)作为其所有子行(销售人员)的总计值。当我们指向父行时,我们是隐式地指向了产品子类别。对于这个数据透视表列,我们旨在实现相同的列,但我们将显式地指向产品子类别作为父级。

和之前一样,我们将“收入”列添加为数据透视表的数据列,并将其显示设置为百分比格式。
// values: % Subcategory
ExcelPivotTableDataField subcategoryPercentageDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
subcategoryPercentageDataField.Function = DataFieldFunctions.Sum;
subcategoryPercentageDataField.Format = "0.00%";
subcategoryPercentageDataField.Name = "% Subcategory";

再看一下上面的图片,您会看到“基本字段”列表已启用,并且选择了“产品子类别”字段。“基本字段”列表之所以启用,是因为值被设置为显示为“占父行汇总的百分比”,并且系统提示用户选择哪个字段是父级。
除了两个变化外,这个 XML 与我们之前做的那个相同。pivotShowAs 属性的值设置为“percentOfParent”,这是 PivotShowAs 枚举的一部分。baseField 属性是数据透视表字段在所有字段中的索引。碰巧的是,EPPlus 在 ExcelPivotTableField.Index 属性中为每个数据透视表字段提供了一个索引,就像这样:
ExcelPivotTableField baseField = pivotTable.Fields["Product Subcategory"];
int index = baseField.Index; // 5
这是 XML 代码。
<x:pivotTableDefinition updatedVersion="5">
<x:dataFields>
<x:dataField name="% Subcategory" baseField="5">
<x:extLst>
<x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
<x14:dataField pivotShowAs="percentOfParent">
</x14:dataField>
</x:ext>
</x:extLst>
</x:dataField>
</x:dataFields>
</x:pivotTableDefinition>
以及实现代码。我高亮显示了与前一个数据透视表列的主要区别。
// show % Subcategory as percentage of product subcategory revenue
ExcelPivotTableDataField dataField = subcategoryPercentageDataField;
string pivotShowAs = "percentOfParent";
ExcelPivotTableField baseField = pivotTable.Fields["Product Subcategory"];
/*************************************************/
var xdoc = pivotTable.PivotTableXml;
var nsm = new XmlNamespaceManager(xdoc.NameTable);
// "http://schemas.openxmlformats.org/spreadsheetml/2006/main"
var schemaMain = xdoc.DocumentElement.NamespaceURI;
if (nsm.HasNamespace("x") == false)
nsm.AddNamespace("x", schemaMain);
var schemaMainX14 = "http://schemas.microsoft.com/office/spreadsheetml/2009/9/main";
if (nsm.HasNamespace("x14") == false)
nsm.AddNamespace("x14", schemaMainX14);
// <x:pivotTableDefinition updatedVersion="5">
var pivotTableDefinition = xdoc.SelectSingleNode("/x:pivotTableDefinition", nsm);
pivotTableDefinition.AppendAttribute("updatedVersion", "5");
// <x:dataField name="% Subcategory">
var dataFieldNode = xdoc.SelectSingleNode(
"/x:pivotTableDefinition/x:dataFields/x:dataField[@name='" + dataField.Name + "']",
nsm
);
// <x:dataField baseField="5">
dataFieldNode.AppendAttribute("baseField", baseField.Index.ToString());
// <x:extLst>
var extLst = dataFieldNode.AppendElement(schemaMain, "x:extLst");
// <x:ext uri="{E15A36E0-9728-4e99-A89B-3F7291B0FE68}">
var ext = extLst.AppendElement(schemaMain, "x:ext");
ext.AppendAttribute("uri", "{E15A36E0-9728-4e99-A89B-3F7291B0FE68}");
// <x14:dataField pivotShowAs="percentOfParentRow">
var x14DataField = ext.AppendElement(schemaMainX14, "x14:dataField");
x14DataField.AppendAttribute("pivotShowAs", pivotShowAs);
月度销售额
此数据透视表按年份细分了每个销售人员的月度销售额。在横轴上,它显示了每月销售额的进展。在纵轴上,您可以按月比较当前年份和前一年的收入。此数据透视表的关键点在于将“订单日期”按月份进行分组。

除了“月份”数据透视表列之外,我们构建此数据透视表的方式与之前相同。“区域组”列放入筛选器区域。“销售人员”和“订单年份”列放入行区域,并且“年份”数据透视表列按降序排序。“收入”列放入值区域。

代码非常直观,完成了我们为这个数据透视表所计划的功能。
// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtMonthlySales";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = false;
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium6;
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Salesperson
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
salesPersonRowField.Sort = eSortType.Ascending;
// rows: Year
ExcelPivotTableField yearRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Order Year"]
);
yearRowField.Sort = eSortType.Descending;
yearRowField.Name = "Year";
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
按月份对日期进行分组
我们需要添加“月份”数据透视表列来完成这个数据透视表。如果我们直接在 Excel 中操作,我们会将“订单日期”列拖到“列”区域,右键点击日期,然后点击“组合”。“组合”弹窗会让我们选择要启用的分组,在我们的例子中,我们会选择“月”。

我们首先将“订单日期”列添加到数据透视表的“列”区域。然后,我们使用 ExcelPivotTableField.AddDateGrouping(eDateGroupBy groupBy) 方法将其设置为按月对日期进行分组。eDateGroupBy 枚举被标记为 [Flags] 属性,这意味着您可以选择多种分组类型。我们将在下一个数据透视表中看到它是如何工作的。对于这个数据透视表列,我们只需要 eDateGroupBy.Months。
monthColumnField.AddDateGrouping(eDateGroupBy.Months);
当 EPPlus 创建分组项时,除了您指定的分组外,它还会创建另外两个项。它们是“低于”和“高于”项。它们的含义是低于和高于我们指定为数据范围的日期。有时它们可能没有用处,这取决于分组方式,因为它们没有实际意义,但 EPPlus 仍然会创建它们。因此,我们按月并按升序分组,所以分组项按索引顺序是:低于最小日期(索引 0)、1(索引 1)、...、12(索引 12)、高于最大日期(索引 13)。显然,“低于”和“高于”项没有任何意义,因此没有被使用。
最后,我们需要将月份项从其数值(1, 2, ...)重命名为其英文缩写名称(Jan, Feb, ...)。EPPlus 允许您通过 ExcelPivotTableField.Items 属性访问分组项。我们遍历这些项,并使用 en-US 区域性来设置月份名称。
// columns: Month
ExcelPivotTableField monthColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
monthColumnField.AddDateGrouping(eDateGroupBy.Months);
monthColumnField.Sort = eSortType.Ascending;
monthColumnField.Name = "Month";
var enUS = System.Globalization.CultureInfo.CreateSpecificCulture("en-US");
monthColumnField.Items[0].Text = "<"; // below min date. not in use.
for (int month = 1; month <= 12; month++)
monthColumnField.Items[month].Text = enUS.DateTimeFormat.GetAbbreviatedMonthName(month);
monthColumnField.Items[13].Text = ">"; // above max date. not in use.
季度销售额
此数据透视表显示了每个销售人员的季度收入,并按年份和季度的降序排列。

此数据透视表的重点是展示如何对一个日期列进行多重分组。但首先,我们从其余的数据透视表列开始。“区域组”列放入筛选器区域,“销售人员”列放入行区域,“收入”列放入值区域。

以及构建此数据透视表的代码。
// data cells
ExcelWorksheets wsData = ep.Workbook.Worksheets["Data"];
ExcelTable tblData = wsData.Tables["tblData"];
ExcelRange dataCells = wsData.Cells[tblData.Address.Address];
// pivot table
ExcelRange pvtLocation = ws.Cells["B4"];
string pvtName = "pvtQuarterlySales";
ExcelPivotTable pivotTable = ws.PivotTables.Add(pvtLocation, dataCells, pvtName);
// headers
pivotTable.ShowHeaders = false;
// grand total
pivotTable.ColumGrandTotals = true;
pivotTable.GrandTotalCaption = "Total";
// data fields are placed in columns
pivotTable.DataOnRows = false;
// style
pivotTable.TableStyle = OfficeOpenXml.Table.TableStyles.Medium1;
// filters: Territory Group
ExcelPivotTableField territoryGroupPageField = pivotTable.PageFields.Add(
pivotTable.Fields["Territory Group"]
);
territoryGroupPageField.Sort = eSortType.Ascending;
// rows: Salesperson
ExcelPivotTableField salesPersonRowField = pivotTable.RowFields.Add(
pivotTable.Fields["Salesperson"]
);
salesPersonRowField.Sort = eSortType.Ascending;
// values: Revenue
ExcelPivotTableDataField revenueDataField = pivotTable.DataFields.Add(
pivotTable.Fields["Revenue"]
);
revenueDataField.Function = DataFieldFunctions.Sum;
revenueDataField.Format = "#,##0_);(#,##0)";
revenueDataField.Name = "Revenue";
按季度和年份对日期进行分组
剩下的是创建“季度”和“年份”数据透视表列。

那么,当我们对一个日期列进行两种或更多种日期分组时会发生什么呢?EPPlus 会为每个日期分组创建多个分组字段。这些分组之间存在层级关系,其中粒度最粗的日期分组是父分组,而粒度最细的日期分组是子分组。在我们的数据透视表中,“年份”日期分组将是外部的数据透视表列,因为它是粒度最粗的日期分组;而“季度”日期分组将是内部的数据透视表列,因为它是粒度最细的日期分组。
当您调用 AddDateGrouping 方法时,您指定的 eDateGroupBy 枚举值的数量决定了 EPPlus 将创建多少个数据透视表列。我们用来执行日期分组的那个 ExcelPivotTableField 将成为粒度最细的日期分组。在我们的例子中,那将是“季度”数据透视表列。
ExcelPivotTableField quarterColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
quarterColumnField.AddDateGrouping(eDateGroupBy.Years | eDateGroupBy.Quarters);
方法 ExcelPivotTable.Fields.GetDateGroupField(eDateGroupBy grouypBy) 可以检索日期分组中的任何数据透视表列。我们用它来获取“年份”数据透视表列。
ExcelPivotTableField yearColumnField = pivotTable.Fields.GetDateGroupField(eDateGroupBy.Years);
我们也可以使用 GetDateGroupField 方法来检索“季度”数据透视表列,但这将得到与 quarterColumnField 相同的对象。
bool areSame = (quarterColumnField == pivotTable.Fields.GetDateGroupField(eDateGroupBy.Quarters));
最后,我们需要将季度的默认文本(Qtr1-Qtr4)重命名为这种格式 Q1-Q4。“季度”数据透视表列的分组项按索引顺序是:低于最小日期(索引 0)、Q1(索引 1)、...、Q4(索引 4)、高于最大日期(索引 5)。我们遍历这些项并重命名它们。
// columns: Year, Quarter
ExcelPivotTableField quarterColumnField = pivotTable.ColumnFields.Add(
pivotTable.Fields["Order Date"]
);
quarterColumnField.AddDateGrouping(eDateGroupBy.Years | eDateGroupBy.Quarters);
quarterColumnField.Sort = eSortType.Descending;
quarterColumnField.Name = "Quarter";
ExcelPivotTableField yearColumnField = pivotTable.Fields.GetDateGroupField(eDateGroupBy.Years);
yearColumnField.Sort = eSortType.Descending;
yearColumnField.Name = "Year";
quarterColumnField.Items[0].Text = "<"; // below min date. not in use.
for (int quarter = 1; quarter <= 4; quarter++)
quarterColumnField.Items[quarter].Text = "Q" + quarter;
quarterColumnField.Items[5].Text = ">"; // above max date. not in use.
杂项
克隆 ExcelPackage
您可能会遇到需要生成 2 个或更多个 Excel 文件的情况,它们之间有细微(或不那么细微)的差别。如果生成这些文件很耗时,您会希望只创建一个,然后根据需要克隆它多次,并对克隆进行修改。
理解 EPPlus 如何处理 ExcelPackage 很重要。当 ExcelPackage 处于打开状态时,您可以编辑它,但无法获取底层的 Excel 流或 Excel 字节数组。一旦您通过调用 ExcelPackage.Save、ExcelPackage.SaveAs 或 ExcelPackage.GetAsByteArray 这些方法之一来最终确定 ExcelPackage,您就不能再对其进行任何更改,但可以获取流或字节数组,并用它们进行克隆。您会注意到,您不能创建一个克隆然后继续对原始文件进行更改。一旦原始的 ExcelPackage 被最终确定,它就永远关闭了。
这个例子完全在内存中操作。ExcelPackage 在构造函数中接收一个 MemoryStream,当调用 ExcelPackage.Save 方法时,ExcelPackage 会将 Excel 字节写入其中。现在原始的 Excel 已经写入 MemoryStream,它被再次用来通过 ExcelPackage.Load 方法从中加载两个克隆。
using (var ms = new MemoryStream())
{
// original excel
using (var ep = new ExcelPackage(ms))
{
var wb = ep.Workbook;
var ws = wb.Worksheets.Add("Original");
ws.Cells[1, 1].Value = "Value from original workbook";
ws.Column(1).AutoFit();
// original excel is written into ep.Stream
// ep.Stream is the same MemoryStream as ms
ep.Save();
// you can't edit ExcelPackage after it was finalized (Save, SaveAs, GetAsByteArray)
}
// excel copy 1
using (var ep = new ExcelPackage())
{
ep.Load(ms);
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 1";
ws.Cells[2, 1].Value = "Copy 1";
using (var file = System.IO.File.OpenWrite("Copy 1.xlsx"))
{
ep.SaveAs(file);
}
}
// excel copy 2
using (var ep = new ExcelPackage())
{
ep.Load(ms);
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 2";
ws.Cells[2, 1].Value = "Copy 2";
using (var file = System.IO.File.OpenWrite("Copy 2.xlsx"))
{
ep.SaveAs(file);
}
}
}
这个例子假设您已经有了一个 Excel 字节数组,并且需要用它来制作克隆。该例子使用 ExcelPackage.GetAsByteArray 来获取原始 Excel 的字节数组,但您也可以通过任何其他方式获取它们,例如读取一个现有 Excel 文件的字节。关键是,在克隆之前,您已经持有了 byte[]。
// original excel
byte[] excel = null;
using (var ep = new ExcelPackage())
{
var wb = ep.Workbook;
var ws = wb.Worksheets.Add("Original");
ws.Cells[1, 1].Value = "Value from original workbook";
ws.Column(1).AutoFit();
excel = ep.GetAsByteArray();
}
// excel copy 1
using (var ep = new ExcelPackage())
{
using (var ms = new MemoryStream(excel))
{
ep.Load(ms);
}
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 1";
ws.Cells[2, 1].Value = "Copy 1";
using (var file = System.IO.File.OpenWrite("Copy 1.xlsx"))
{
ep.SaveAs(file);
}
}
// excel copy 2
using (var ep = new ExcelPackage())
{
using (var ms = new MemoryStream(excel))
{
ep.Load(ms);
}
var wb = ep.Workbook;
var ws = wb.Worksheets[1];
ws.Name = "Copy 2";
ws.Cells[2, 1].Value = "Copy 2";
using (var file = System.IO.File.OpenWrite("Copy 2.xlsx"))
{
ep.SaveAs(file);
}
}
在内存中处理 Excel
您可能需要在内存中打开一个现有的 .xlsx Excel 文件进行读写。您应该还记得,这个文件不过是一个包含多个 XML 文件的 zip 压缩文件。为此,您需要一个能处理 zip 文件的 zip 库。我选择使用 DotNetZip,因为 EPPlus 内部本身就使用这个 zip 库,但这并不意味着其他 zip 库无法打开 EPPlus 生成的 Excel 文件:zip 文件就是 zip 文件。
PM> Install-Package DotNetZip -Version 1.10.1
接下来的两个例子假设存在一个 byte[] excel,但这个文件不一定是用 EPPlus 生成的。它可以是由 Excel 程序或其他 .NET Excel 库(如 ClosedXML)创建的。关键是,这些例子无论 EPPlus 如何都适用。
这是一个在内存中修改现有 Excel 的模板代码。需要注意的是,原始的 Excel(byte[] excel)保持不变。当文件加载到 Ionic.Zip.ZipFile 中时,它实际上是在内存中创建了一个新的 zip 文件。任何后续的修改都只对这个新的 zip 文件进行。
byte[] excel; // from EPPlus, from file
byte[] excelNew = null;
using (var zipStream = new MemoryStream(excel))
{
using (Ionic.Zip.ZipFile zipFile = Ionic.Zip.ZipFile.Read(zipStream))
{
// change zip file
// zipFile.AddEntry();
// zipFile.RemoveEntry();
using (var outStream = new MemoryStream())
{
zipFile.Save(outStream);
excelNew = outStream.ToArray();
}
}
}
// save new excel
System.IO.File.WriteAllBytes(@"C:\excelNew.xlsx", excelNew);
这段代码在内存中打开一个 Excel 文件,将每个 XML 文件提取到 XmlDocument 中,并使用 System.Xml.XmlTextWriter 将其格式化(pretty-print)输出到一个输出文件夹。XML 将使用单个制表符缩进,并且 XML 文件将是 UTF-8 编码的。
byte[] excel; // from EPPlus, from file
string outputFolder = @"C:\";
using (var zipStream = new MemoryStream(excel))
{
using (Ionic.Zip.ZipFile zipFile = Ionic.Zip.ZipFile.Read(zipStream))
{
// assumption that all the files are XMLs
// not testing for other resources such as images
foreach (Ionic.Zip.ZipEntry zipEntry in zipFile)
{
XmlDocument xdoc = new XmlDocument();
using (var ms = new MemoryStream())
{
// extract to memory
zipEntry.Extract(ms);
// load XmlDocument
ms.Position = 0;
xdoc.Load(ms);
}
// output path
string outputPath = Path.GetFullPath(
Path.Combine(outputFolder, zipEntry.FileName)
);
// create output directory
string directory = Path.GetDirectoryName(outputPath);
if (Directory.Exists(directory) == false)
Directory.CreateDirectory(directory);
// write xml to file, tab indentation, UTF-8 encoding
using (var writer = new System.Xml.XmlTextWriter(outputPath, System.Text.Encoding.UTF8))
{
writer.Formatting = Formatting.Indented;
writer.Indentation = 1;
writer.IndentChar = '\t';
xdoc.Save(writer);
}
}
}
}
从网页发送 Excel 文件
如果您需要将 .xlsx Excel 文件发送到客户端,正确设置 content-type 和 content-disposition 响应头非常重要。请注意,如果您发送其他类型的 Excel 文件,如 .xls 文件(EPPlus 不创建这种文件)或 .xlsm(带 VB 代码的 Excel,“m”代表宏),这些头信息是不同的。这是一个简短但绝不详尽的 Excel 文件类型及其内容类型列表。
- .xlsx application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- .xlsm application/vnd.ms-excel.sheet.macroEnabled.12
- .xltx application/vnd.openxmlformats-officedocument.spreadsheetml.template
- .xls application/vnd.ms-excel
byte[] excel; // from EPPlus, from file
string excelFileName = "MyExcel.xlsx";
string contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
string contentDisposition = string.Format("attachment; filename=\"{0}\"",
System.Uri.EscapeDataString(excelFileName)
);
System.Web.HttpResponse response = Page.Response;
response.ContentEncoding = System.Text.Encoding.Unicode;
response.ContentType = contentType;
response.AddHeader("content-disposition", contentDisposition);
response.BinaryWrite(excel);
response.Flush();
response.End();
结束语
本文仅应作为您创建自己的 Excel 文件的起点。您必须根据自己的需求进行调整,这需要付出努力。并非所有事情都可以用 EPPlus 实现,但我试图涵盖您最可能遇到的场景。我还尝试详细展示了修改 Open XML 的过程,如何在 MSDN 上查找相关信息,然后相应地重写 Excel。随着 EPPlus 新版本的发布,一些技巧可能会过时,但您仍然需要卷起袖子,深入研究。