
使用 Terraform 构建云基础设施
5.00/5 (5投票s)
如何使用 Terraform 构建更复杂的网络
引言
在本系列的第一篇文章中,我介绍了“Terraform”,并简要说明了它是什么以及如何使用它。本文将更深入一些,探讨如何创建机器集群。如果您必须手动管理基础设施,那么除了最基本的场景外,这会耗费您所有的时间,因此使用像 Terraform 这样的自动化技术可以解放您的时间,去做更有趣的事情!
声明式方法
Terraform 的一个关键特性,也是其被使用的主要原因之一,是它的声明性。换句话说,我们*描述*我们希望基础设施达到的状态,然后由 Terraform 完成所有繁重的工作来创建这个理想状态。Terraform 会记住您基础设施应有的状态,并维护该状态。如果您后来进行了更改,Terraform 会负责处理好您第一次基础设施设计和第二次之间的任何变化。因此,您可以把它看作是一种基础设施的自动合并/差异比较工具。下面的截图显示了创建一个基础设施,然后对基础设施计划进行更改,并要求 Terraform 执行它之后的结果。您可以看到它是如何识别所需更改,并告诉您它在执行时“计划”做什么。
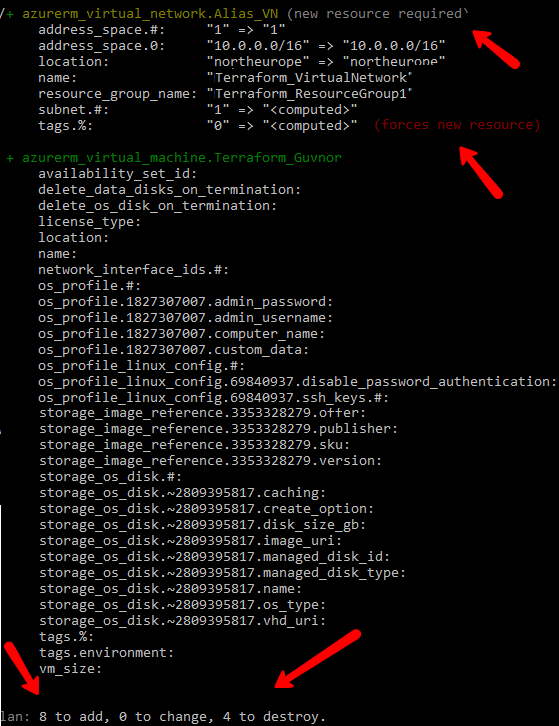
那么,为什么这种声明式方法如此有用呢?……好吧,想象一下,如果您必须使用自己编写的一些简单脚本来管理自动化基础设施,也许是用 PowerShell 或 bash,甚至是像 Ansible 这样的工具。最初的一两次运行通常都很顺利,但当您开始进行更多更改时,您需要编写代码来记住之前的状态,然后再去修改它。久而久之,这会导致所谓的“配置漂移”,尤其是在一个由多名开发人员共同管理机器的团队中。配置漂移简单来说就是,随着时间的推移,您*期望*的基础设施状态与实际状态不符……在某个环节上,配置与现有状态不同步了,现在一切都搞砸了。如果您经历过这种情况,您将会非常欣赏我在这里演示的方法。
Azure 的一个坑!
Terraform 可以在多种云提供商上运行,如 Azure、AWS、阿里巴巴、谷歌。我个人偏好 Azure,因此我用它来演示这项技术。遗憾的是,开发者开发系统而不进行压力测试几乎已成常态。我在世界各地的许多不同组织和地方工作过,一次又一次地看到这个问题抬头。用少量数据或少量自动生成的机器来开发和测试一个系统是可以的,但要真正知道您的解决方案是否能在生产环境中正常工作,不仅是现在,而且在未来的 12/24/36 个月内,您需要给它施加压力,并观察会发生什么。我正在构建的基础设施在第一天将以 50 台机器开始,我预计在 6 个月内会增加到 100 台,而从 12 个月后开始,我们预计所有东西都将增长 10 倍。因此,虽然上一篇文章中针对一台机器的设置很棒,但我想启动多台机器看看情况如何。总之,在测试过程中,我遇到了一个很棘手的坑,花了我一些功夫才解决。
用 1 台机器进行测试效果很好。然后我复制粘贴了我的代码,测试了两台。太棒了——正如预期。接着我决定加大规模,启动 100 台机器。好吧,它运行了一会儿,然后“砰”的一声!……给我报了个错。
原来,Azure 默认限制了您可以启动的资源数量——我想这既是为了保护您,也是为了保护他们自己。解决方法是提交一个支持请求,要求增加配额。当我看到“支持请求”时,我想,哦,天哪,我得等 24/48 小时才能得到回应。但我非常高兴地告诉大家,这似乎是一个自动化系统,我在不到一分钟内就收到了一封邮件,说我的工单已经解决,配额也增加了……为微软 Azure 团队点赞……太给力了!
如果您遇到这个障碍,需要这样做:
- 在您的门户仪表板右上角,选择 帮助 + 支持

- 在弹出的边栏中,将问题类型设置为“配额”,配额类型设置为“核心”。

- 设置此问题对您组织的影响(请公平对待!……)……就我而言,它并非任务关键型,但确实阻止了我进行这项特定的测试,所以算是中等严重。然后,关键部分来了,选择您想要增加配额的 SKU 系列,并设置您想要的新限制。
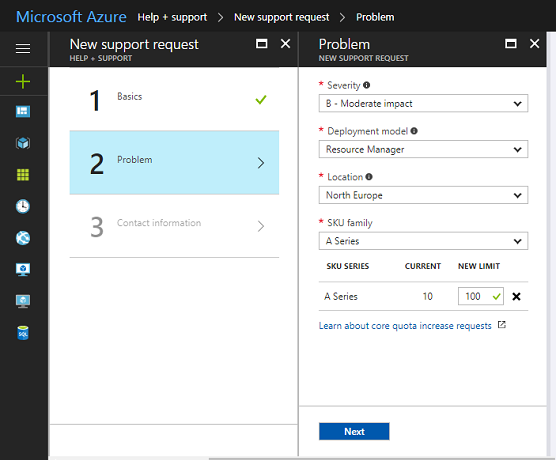
就我而言,如我所说,我在一分钟内就获得了额外的资源——您的体验可能会有所不同!
构建基础设施
在第一篇文章中,我们走过了为单个虚拟机资源构建 Terraform 配置文件的过程(如果您还没有阅读那篇关于 Terraform 的介绍性文章,请现在就去阅读,否则您可能会很快迷失方向!)。现在让我们看看需要做些什么来进行一些扩展。通常在云基础设施中,您有特定类型的机器。一些用于管理系统,一些用于报告,另一些用于基本工作等。在这种情况下,复制粘贴我们想要的 X 台虚拟机是毫无意义的……那会相当疯狂 :P
相反,我们将定义一个特定的虚拟机配置,并指定我们希望它重复 X 次。这通过提供一个新的键 "count" 并设置其值来实现。
resource "azurerm_virtual_machine" "workerNode" {
count = "10"
name = "workerNode"
location = "North Europe"
resource_group_name = "${azurerm_resource_group.Alias_RG.name}"
network_interface_ids = [network_interface_ids = ???]
vm_size = "Standard_A0"
好的,这看起来没问题,但是,有一个问题在等着我们。问题是,这个机器声明基本上会自我循环 X COUNT 次(10 次),在循环过程中,它会复制所有的属性。对于大多数属性来说,这没问题,也是我们想要的,然而,对于像节点名称和网络接口这样的东西,我们需要唯一的标识——我们不能让多台机器使用同一个虚拟网络接口,也不能让我们所有的机器都叫同一个名字。幸运的是,我们可以解决这个问题。Terraform 有一个叫做“插值语法”的东西……这可真是个花哨的词!……字典上说它是“将某种不同性质的东西插入到别的东西中”或“在对话中插入的评论”……所以下次你参加派对时,就挤进一群你不认识的人中,简单地说一句‘哦,请原谅我插个值…’”(哈哈,小心点,你可能会被逮捕!)。
插值语法意味着您可以在一行代码中注入一些计算,应用程序会评估您的内容并进行转换。插值使用 ${} 包裹,例如 ${var.foo}。这是一个非常简单却强大的功能。您可以进行多种不同的操作,'count' 和 'format' 只是其中的两种。您可以在 Terraform 插值文档页面上找到有关插值选项的更多详细信息。
那么,让我们通过修改代码来看看这对我们有何帮助。
resource "azurerm_virtual_machine" "workerNode" {
count = "10"
name = "WorkerNode-${count.index}"
...
因此,当 Terraform 构建配置时,它会评估 "WorkerNode-X" 并在迭代时递增数字,从而为我们每个虚拟机提供一个唯一的名称。我们最终会得到:
WorkerNode-1
WorkerNode-2
WorkerNode-3
……以此类推……
这解决了我们机器名称的问题,但是虚拟网络接口呢?……嗯,我们也可以处理这个问题。在这种情况下,我的方法是在 Terraform 中声明一个全局的“count”变量(命名为“WorkerCount”),然后在这两个地方使用它。
创建变量非常简单。您声明 Variable,后跟其名称,然后是包含变量细节的括号。我们只关心“名称”和“默认值”。
variable "WorkerCount" {
type = "string"
default = "20"
}
variable 通过其声明后跟随的字符串(WorkerCount)来引用,我们告诉它类型是字符串,而默认值是我设置的起始值。现在我们可以将我们的 WorkerNode 声明更改为以下内容:
resource "azurerm_virtual_machine" "workerNode" {
count = "${var.WorkerCount}"
name = "WorkerNode-${count.index}"
...
如上所示,我们可以通过插值(耶!派对时间!)来访问我们声明的变量。
现在让我们看看这如何帮助我们处理虚拟网络接口。在创建工作虚拟机之前,我创建了一系列的网络接口资源,同样也使用了变量 WorkerCount。我还使用相同的 ${count.index} 来附加到一个字符串上,并为每个接口分配一个唯一的名称。
# create network interface for WorkerNodes x WorkerCount
resource "azurerm_network_interface" "NodeNIC" {
count = "${var.WorkerCount}"
name = "workerNIC.${count.index}"
location = "North Europe"
resource_group_name = "${azurerm_resource_group.Alias_RG.name}"
internal_dns_name_label = "nodeNic${count.index}"
ip_configuration {
name = "node-nic-${count.index}"
subnet_id = "${azurerm_subnet.Alias_SubNet.id}"
private_ip_address_allocation = "dynamic"
# private_ip_address = "10.0.2.5"
# public_ip_address_id = "${azurerm_public_ip.Alias_PubIP.id}"
}
}
现在我们可以更新我们的虚拟机资源,以映射到这些接口,如下所示:
resource "azurerm_virtual_machine" "workerNode" {
count = "${var.WorkerCount}"
name = "WorkerNode-${count.index}"
internal_dns_name_label = "nodeNic${count.index}"
ip_configuration {
name = "workerNIC.${count.index}"
subnet_id = "${azurerm_subnet.Alias_SubNet.id}"
private_ip_address_allocation = "dynamic"
}
目前我们只需要这些。在下一篇文章中,我们将探讨如何在这些机器创建后进入它们,并安装一些有用的软件(例如 docker……哦是的,我们将全面容器化!)
历史
- 2017年8月3日 - 第1版