
大数据 MapReduce Hadoop Scala 在 Ubuntu Linux 上通过 Maven intellj Idea
4.63/5 (13投票s)
本文是最全面的大数据从零到实战的文章。
引言
我想开始在网上浏览大数据相关内容,但我找不到一篇从头到尾解释这个过程的完整文章。每篇文章都只描述了这个巨大概念的一部分。我感到缺乏一篇全面的文章,于是决定写下这篇论文。
如今,我们面临着数据量不断增长的现象。我们希望长期保存所有这些数据,并高速处理和分析它们,这催生了构建良好解决方案的需求。对于数据科学家来说,找到一种合适的替代传统数据库的解决方案,以存储任何类型的结构化和非结构化数据,是最具挑战性的事情。

我选择了一个完整的场景,从第一步到结果,这在互联网上很难找到。我选择了 MapReduce,它是通过 hadoop 和 scala 在 intellij idea 中处理数据,而这一切故事都将在 ubuntu Linux 操作系统下发生。
什么是大数据?
大数据是指海量、庞大的结构化、非结构化或半结构化数据,用传统数据库难以存储和管理。其体积从 TB 到 PB 不等。关系型数据库(如 SQL Server)不适用于存储非结构化数据。正如您在下图中所见,大数据是指所有类型的结构化或非结构化数据的集合,它具有存储、管理、共享、分析等基本要求。

什么是 Hadoop?
事实上,我们对所有数据库都寄予两种期望。首先,我们需要存储数据;其次,我们希望以快速准确的方式正确处理已存储的数据。由于大数据的任意形状和巨大体积,无法将其存储在传统数据库中。我们需要考虑一种新的数据库,它能够同时处理大数据的存储和处理。
Hadoop 是一种革命性的大数据数据库,能够存储任何形状的数据并在节点集群中进行处理。它还极大地降低了数据维护成本。借助 hadoop,我们可以长期存储任何类型的数据,例如所有用户点击。这使得历史分析变得容易。Hadoop 具有分布式存储和分布式处理系统,如 Map Reduce。

正如您在下面的图片中看到的,数据库有两个不同的期望职责。左边是存储,这是开始步骤,然后右边是处理。Hadoop 是一种创新的数据库,与传统和关系型数据库不同。Hadoop 在多个机器的集群中运行,每个集群包含许多节点。
什么是 Hadoop 生态系统?
正如我上面提到的,hadoop 既适合存储非结构化数据库,也适合处理它们。hadoop 生态系统有一个抽象的定义。数据存储在左侧,有两种不同的存储可能性:HDFS 和 HBase。HBase 建立在 HDFS 之上,两者都是用 Java 编写的。

HDFS
- Hadoop 分布式文件系统允许在分布式平面文件中存储大数据。
- HDFS 适合对数据进行顺序访问。
- 它不支持随机实时读/写访问数据。它更适合离线批处理。
HBase
- 以键/值对的形式以列式存储数据。
- HBase 具有实时读/写的能力。
Hadoop 是用 Java 编写的,但您也可以使用 R、Python、Ruby 实现。
Spark 是一个开源集群计算框架,用 Scala 实现,适合支持分布式计算上的作业迭代。Spark 具有高性能。
Hive、Pig、Sqoop 和 Mahout 是数据访问工具,它们使得对数据库进行查询成为可能。Hive 和 Pig 类似于 SQL;Mahout 用于机器学习。
MapReduce 和 Yarn 都用于处理数据。MapReduce 被设计用于在分布式系统中处理数据。MapReduce 可以处理作业和任务跟踪器、监控和并行执行等所有任务。Yarn,Yet Another Resource Negotiator,是 MapReduce 2.0,具有更好的资源管理和调度能力。
Sqoop 是一个连接器,用于从外部数据库导入和导出数据。它能够以并行方式轻松快速地传输数据。
Hadoop 是如何工作的?
Hadoop 遵循主/从架构模型。对于 HDFS,主节点 NameNode 负责监控并跟踪所有从节点,这些从节点是一组存储集群。

MapReduce 处理涉及两种不同类型的作业。Map 作业将查询发送到集群中的各个节点进行处理。这个作业会被分解成更小的任务。然后 Reduce 作业收集每个节点产生的所有输出,并将它们组合成一个单一的值作为最终结果。

这种架构使 Hadoop 成为一个廉价、快速且可靠的解决方案。它将大的作业分解成小的作业,并将每个任务放在不同的节点上。这个过程可能会让您想起多线程。在多线程中,所有并发进程都通过锁和信号量共享,但 MapReduce 中的数据访问受 HDFS 控制。
准备动手实践
到目前为止,我们已经介绍了 Hadoop 和大数据的抽象含义。现在是时候深入研究并创建一个实际项目了。我们需要准备一些满足我们需求的硬件。
硬件
- 内存:8 GB
- 硬盘剩余空间:50 GB

软件
- 操作系统:Windows 10 - 64 位
- Oracle Virtual Machine VirtualBox
- Linux-ubuntu 17.04
- Jdk-8
- Ssh
- Hadoop
- Hadoop jar
- Intellij idea
- Maven
- 编写 Scala 代码或 wordcount 示例
1. 操作系统:Windows 10 - 64 位
如果您还没有 Win 10 并想升级您的操作系统,请访问以下链接立即获取:

2. Oracle Virtual Machine VirtualBox
请访问 此链接,点击 Windows hosts 并下载最新版本的 virtual box。然后按照以下说明操作:






3. Linux-ubuntu 17.04
请访问 此链接,点击 64 位并下载最新版本的 ubuntu。然后按照以下说明操作:

点击“新建”来为新操作系统(Linux/Ubuntu 64 位)创建一个新的虚拟机。
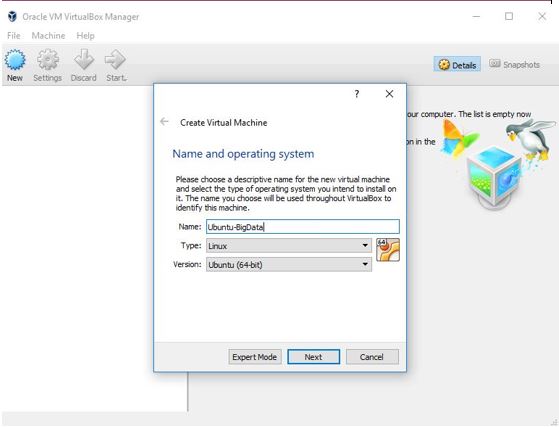
在下面的图片中,您应该为新操作系统分配内存。




在下面的图片中,您应该为新操作系统分配硬盘。

现在,是时候选择您的 ubuntu 17 了,它是 .iso 格式。请选择“ubuntu-17.04-desktop-amd64”。




现在,双击新创建的 vm 并开始安装。

选择您的语言,然后点击“安装 Ubuntu”。





在下面的图片中,您指定了您的身份,因此这是第一个可以使用 ubuntu 的用户。







sudo apt-get install update
如果您看到以下错误,让我们尝试使用以下两种解决方案之一:

解决方案一
sudo rm /var/lib/apt/lists/lock
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock

解决方案二
sudo systemctl stop apt-daily.timer
sudo systemctl start apt-daily.timer

然后再次尝试
sudo apt-get install update




让我们为 hadoop 创建一个新用户和组。
sudo addgroup hadoop

将用户添加到组
sudo adduser --ingroup hadoop hduser

输入您的详细信息,然后按“y”进行保存。

4. 安装 JDK
sudo apt-get update
java -version
sudo apt-get install default-jre


5. 安装 open-ssh 协议
OpenSSH 通过使用 SSH 协议在网络上提供安全和加密的通信。问题是,为什么我们要使用 openssh?这是因为 hadoop 需要密码才能允许访问其节点。
sudo apt-get install openssh-server


ssh-keygen -t rsa -P ''
运行上述代码后,如果您被要求输入文件名,请将其留空并按 Enter 键。

然后尝试运行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果您遇到“文件或目录不存在”错误,请按照以下说明操作:

运行“cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys” -> 错误:“No such file or directory”
- mkdir ~/.ssh
- chhmod 700 ~/.ssh
- touch ~/.ssh/authorized_keys
- chmod 600 ~/.ssh/authorized_keys
- touch ~/.ssh/id_rsa.pub
- chmod 600 ~/.ssh/id_rsa.pub




6. 安装 Hadoop
首先,您应该使用以下代码下载 hadoop:
wget http://apache.cs.utah.edu/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz

提取 hadoop 文件
tar xzf hadoop-2.7.1.tar.gz

查找 Java 路径
update-alternatives --config java
/jre 之后的所有内容都是您的 Java 路径。

1. 编辑 ~/.bashrc
nano ~/.bashrc

上面的代码行将打开 addop-ev.sh,滚动到文件末尾,找到 java-home 并以硬编码的 Java 路径输入,该路径您通过“update-alternatives --config java”找到。
然后,在最后,输入以下行:
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_INSTALL=/home/mahsa/hadoop-2.7.1
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS=”-Djava.library.path= $HADOOP_INSTALL/lib/native”
#HADOOP VARIABLES END

还应硬编码 Java 主目录,例如:

要关闭并保存文件,请按“ctl+X”,当提示保存时按“y”,当提示更改文件名时,只需按“Enter”即可,不要更改文件名。
为了确认您的上述操作,让我们执行:
source ~/.bashrc

2. 编辑 hadoop-env.sh
sudo nano /home/mahsa/hadoop-2.7.1/etc/hadoop/hadoop-env.sh

在文件末尾写入:
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>

3. 编辑 yarn-site.xml
sudo nano /home/mahsa/hadoop-2.7.1/etc/hadoop/yarn-site.xml
在文件末尾写入:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>

4. 编辑 mapred-site.xml
cp /home/mahsa/hadoop-2.7.1/etc/hadoop/mapred-site.xml.template
/home/mahsa/hadoop-2.7.1/etc/hadoop/mapred-site.xml
sudo nano /home/mahsa/hadoop-2.7.1/etc/hadoop/mapred-site.xml
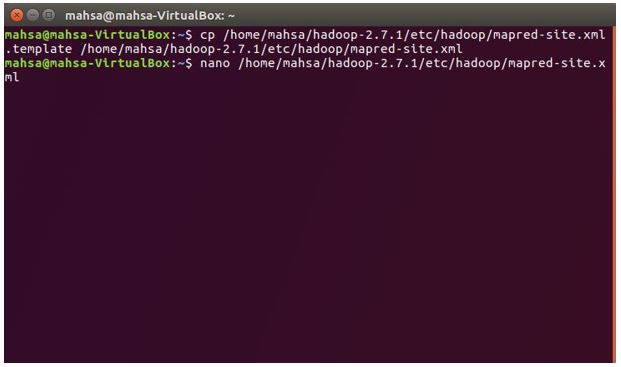
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

5. 编辑 hdfs
mkdir -p /home/mahsa/hadoop_store/hdfs/namenode

mkdir -p /home/mahsa/hadoop_store/hdfs/datanode

sudo nano /home/mahsa/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/mahsa/hadoop_store/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/mahsa/hadoop_store/hdfs/datanode</value>
</property>

6. 格式化
hdfs namenode -format


start-dfs.sh

start-yarn.sh

通过运行“jps”,您可以确保 hadoop 已正确安装。
jps

6. 安装 Intellij Idea



![]()









MapReduce 的实现有两种可能性:一种是 scala-sbt,另一种是 maven。我想描述这两种方法。首先是 scala-sbt。







7. 安装 Maven





下面的图片中有三个文本文件用于练习 word count。MapReduce 开始将每个文件拆分到节点集群中,正如我在本文开头解释的那样。在 Map 阶段,每个节点负责计算单词。在每个节点上的中间拆分只是同质单词,并且在前一个节点中该特定单词的数量。然后在 Reduce 阶段,每个节点将被求和,并将其自己的结果收集起来以生成单个值。





在下面的弹窗图片中,您必须点击“Enable Auto Import”,它将处理所有库。




转到菜单“Run” -> 选择“Edit Configurations”
- 选择“Application”
- 选择 Main Class = “App”
- 将参数设置为:“input/ output/”
您只需要创建一个名为“input”的目录,输出目录将由 intellij 创建。
运行应用程序后,您将看到两个文件:
- “_SUCCESS”
- “part-r-00000”
如果您打开“part-r-00000”,您将看到如下结果:
- moon 2
- sun 3
- day 3
- night 3
Using the Code
-package bigdata.mahsa;
/**
* wordcount!
*
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.StringTokenizer;
public class App extends Configured implements Tool {
public static class Mapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable ONE = new IntWritable(1);
private final transient Text word = new Text();
@Override public void map
(final LongWritable key, final Text value, final Context context)
throws IOException, InterruptedException {
final String line = value.toString();
final StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) { //splitting
word.set(tokenizer.nextToken());
context.write(word, ONE);
}
}
}
public static class Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(final Text key, final Iterable<IntWritable> values,
final Context context)
throws IOException, InterruptedException {
int sumofword = 0;
for (final IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sumofword));
}
}
@Override public int run(final String[] args) throws Exception {
final Configuration conf = this.getConf();
final Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class);
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0])); // ** get text from input
FileOutputFormat.setOutputPath(job, new Path(args[1])); // ** write result to output
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(final String[] args) throws Exception {
final int result = ToolRunner.run(new Configuration(), new App(), args);
System.exit(result);
}
}
Pom.xml
<project xmlns="<a data-saferedirecturl="https://www.google.com/url?
hl=en&q=http://maven.apache.org/POM/4.0.0&source=gmail&ust=1505079008271000&
usg=AFQjCNELhZ47SF18clzvYehUc2tFtF4L1Q" href="http://maven.apache.org/POM/4.0.0"
target="_blank">http://maven.apache.org/POM/4.0.0</a>"
xmlns:xsi="<a data-saferedirecturl="https://www.google.com/url?
hl=en&q=http://www.w3.org/2001/XMLSchema-instance&source=gmail&
ust=1505079008271000&usg=AFQjCNFD9yHHFr1eQUhTqHt1em3OxoDqEg"
href="http://www.w3.org/2001/XMLSchema-instance" target="_blank">
http://www.w3.org/2001/XMLSchema-instance</a>"
xsi:schemaLocation="<a data-saferedirecturl="https://www.google.com/url?
hl=en&q=http://maven.apache.org/POM/4.0.0&source=gmail&ust=1505079008271000&
usg=AFQjCNELhZ47SF18clzvYehUc2tFtF4L1Q" href="http://maven.apache.org/POM/4.0.0"
target="_blank">http://maven.apache.org/POM/4.0.0</a>
<a data-saferedirecturl="https://www.google.com/url?hl=en&
q=http://maven.apache.org/xsd/maven-4.0.0.xsd&source=gmail&ust=1505079008271000&
usg=AFQjCNF31lT_EYlu0SxGI9EvuhtJcJ9Y0w" href="http://maven.apache.org/xsd/maven-4.0.0.xsd"
target="_blank">http://maven.apache.org/xsd/maven-4.0.0.xsd</a>">
<modelVersion>4.0.0</modelVersion>
<groupId>bigdata.mahsa</groupId>
<artifactId>App</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>wordcount</name>
<url><a data-saferedirecturl="https://www.google.com/url?hl=en&
q=http://maven.apache.org&source=gmail&ust=1505079008271000&
usg=AFQjCNHfdU8bl-1WzHoSKompqgsFvDc6cA" href="http://maven.apache.org/"
target="_blank">http://maven.apache.org</a></url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsplugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>bigdata.mahsa.App</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
反馈
请随时对本文发表任何反馈;很高兴看到您的意见和对该代码的**投票**。如果您有任何问题,请随时在此处提问。
历史
- 2017年9月9日:初始版本