
异常管理:假设和异常
4.77/5 (8投票s)
异常处理实践,例如避免 null 值,编写可预测的函数签名,避免 null 引用异常等。
引言
您在生产环境中遇到过多少次“NullReferenceException”并花费数小时来找出问题根源?在此过程中,您是否遇到过以下陈述之一?
return null;
或
return 0;
或
return -1;
异常管理是至关重要的,也是软件开发中最重要的主题之一,但也是最被低估的主题之一。开发人员在开发业务需求时可能会忽略日志记录和异常管理。因为在正常情况下它们不会做任何事情。另一方面,当生产环境中发生异常时,由于缺乏日志记录和糟糕的异常管理,解决问题可能需要几个小时。
在本文中,我将介绍一些异常处理实践,例如避免 null 值,编写可预测的函数签名,避免 null 引用异常等。
背景
第一个问题是,为什么会发生异常?软件程序有几个函数和子函数。每个函数按顺序执行,并且可以具有输入和输出参数。通常,一个函数的输出成为另一个函数的输入(图 1-a)。在编写函数时,我们会处理这些输入和输出变量。我们有意识或无意识地对这些变量做出一些假设。如果我们的假设成立,我们的代码就能正常工作(图 1-a)。如果发生与我们的假设相矛盾的事情,那么我们的代码就会表现出预期之外的行为(图 1-b)。为了防止这些意外行为,我们通常会抛出异常。因此,良好的异常管理始于正确的假设。

如何做假设?
假设我们得到一个接口,其中包含以下两个函数。这两个函数中的一个返回 null(我们不知道是哪个),另一个在客户不存在时抛出异常。
Customer GetCustomerByEmail(String email);
Customer GetCustomerById(int customerId);
并且我们正在使用其中一个函数
Customer customer = customerProvider.GetCustomerByEmail(email);
//Should I check null value?
CallCustomer(customer.PhoneNumber);
在使用 customer 变量之前,我们应该检查 null 值吗?即使我们知道这一点,我们也很容易忘记检查。我们也可能编写不必要的 null 检查块,这会使我们的代码混乱。但如果我们返回一个可空类型而不是 null 值,那么我们可以通知开发人员并强制他们像这样检查一个变量
TNullable<Customer> GetCustomerByEmail(String email);
TNullable<Customer> customer = customerProvider.GetCustomerByEmail(email);
if (customer.HasValue()){
CallCustomer(customer.Value.PhoneNumber)
}
请注意,Nullable<t> 类型不能与引用类型一起使用。所以我写了一个 TNullable<t> 类型,它可以与引用类型一起使用。幸运的是,可空引用类型已在 C# 8 中引入。如果您使用 C# 8,则无需创建新类型。
如果我们知道一个函数永远不会返回 null 值,那么我们就无需编写不必要的 null 检查块。
现在,我们可以再次关注这两个函数,并确定哪个应该返回 null,哪个应该抛出异常。
如果我们编写 GetCustomerById 方法作为我们将在内部使用的辅助方法,那么我们可以假设该方法始终接受一个现有客户数据的标识符。
//A SaleOrder has always an existing customer.
Customer customer = customerProvider.GetCustomerById(order.CustomerId);
客户不存在于数据库中的情况是一种意外行为。所以在这里抛出异常是很好的。不要忘记记录有关异常的有用信息。建议也使用自定义异常类。
public Customer GetCustomerById(int customerId){
Customer customer = db.GetCustomerById(customerId);
if (customer == null)
throw new EntityNotFoundException("Customer not found. CustomerId:" + customerId);
return customer;
}
现在,假设我们有一个网页,可用于通过电子邮件地址搜索 customer。
TNullable<Customer> customer = db.GetCustomerByEmail(txtEmail.Text);
我们不能假设具有给定电子邮件地址的 customer 始终存在于数据库中。很有可能不存在具有给定电子邮件地址的客户。在这种情况下,与其返回 Customer 类型,不如返回一个可空的 Customer 类型(TNullable<Customer>)来通知开发人员该方法可能返回 null 值。
public TNullable<Customer> GetCustomerByEmail(String email){
Customer customer = db.GetCustomerByEmail(email);
return new TNullable<Customer>(customer);
}
何时处理异常?
通常(但不总是)true,最好在调用链的外围部分处理异常。但如果异常发生在不重要或可选的操作中,您可以将警告写入日志文件并忽略异常。然后,您可以在调用链的内部部分捕获异常。此外,您可能希望捕获异常并向日志记录器写入信息性行,然后重新抛出异常以便由调用链的外围部分处理。
Using the Code
为了演示我所说的想法,我创建了一个示例应用程序。这个示例应用程序包含非常简单的模型类,这些类只有几个我们将要使用的属性。

项目中的其他文件/类
DBConnection:一个数据库模拟类,返回预定义的��象TNullable:一个用于定义可空引用类型的类EntityNotFoundException:一个自定义异常类Example1、Example2、Example3:三个示例文件。详细信息如下Program:应用程序的入口点。默认情况下,Main方法如下所示
static void Main(string[] args)
{
try
{
RunExample1();
//RunExample2();
//RunExample3();
}
catch (Exception ex)
{
LogEx(ex);
}
Console.ReadLine();
}
您可以运行其他示例。只需注释掉 RunExample1() 并取消注释其他行之一。
示例1
具有不良实践的初始代码。实际上,根本没有异常管理。运行后,您会收到“NullReferenceException”。您对导致该异常的原因一无所知。

示例 2
示例的更好实现。它抛出异常或为 null 值返回 TNullable 对象。现在我们知道异常发生在加载 Address 的 City 引用时。但我们仍然不知道哪个订单的地址具有无效的 City 引用。

示例3
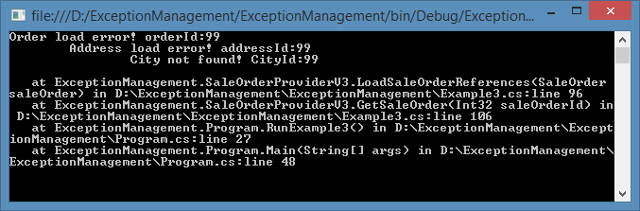
在第三个示例中,我添加了异常处理块,编写了有用的信息并重新抛出了异常。现在我们知道是哪个 order、address 和 city 数据导致了异常!
结论
我试图解释如何避免 null 引用,以及如何编写可预测的方法签名来帮助开发人员避免不必要的 null 检查块。我希望您喜欢这篇文章。请分享您的意见和建议。