
访问 EDGAR 数据库中的财务报告
5.00/5 (5投票s)
从电子数据收集、分析和检索(EDGAR)系统中获取财务记录
美国所有上市公司都必须向美国证券交易委员会(SEC)提交报告。SEC通过其电子数据收集、分析和检索系统(即EDGAR)免费提供许多此类报告。EDGAR为投资者提供了丰富的信息,您可以通过访问https://www.sec.gov/edgar.shtml来访问其主站点。
EDGAR提供了大量数据,但其文档并不十分清晰。撰写本文的目的是介绍EDGAR提供的多种报告以及访问它们的各种方法。
1. EDGAR概述
EDGAR已于2016年停止支持FTP,据我所知,它不通过Web服务提供报告数据。要访问报告,您需要向以https://www.sec.gov/cgi-bin/browse-edgar?开头的URL提交HTTPS请求。我将此称为EDGAR URL。
要指定您感兴趣的报告,您需要在URL后附加一个查询字符串,该字符串提供以下信息:
- 公司标识符(
CIK) - 报告类型(
type) - 截至日期(
dateb) - 报告数量(
count) - 所有权(
owner)
例如,假设您想下载IBM在2015年之前的年度报告。IBM的标识符是 0000051143,年度报告用10-K表示,所以您需要向以下URL发送请求:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0000051143&type=10-K&dateb=20150101&count=10&owner=exclude
如您所见,URL的查询字符串由名称=值对组成,并用&符号分隔。第一个对action=getcompany,用于标识EDGAR搜索的目标。本节的其余部分将探讨您可以在查询字符串中设置的其余名称=值对。
1.1 中心索引键(CIKs)
SEC为每个提交报告的公司或个人分配了一个唯一的标识符。这个十位数的标识符称为中心索引键(CIK)。在访问公司报告之前,您需要知道其CIK。您可以通过访问此网站并输入公司名称来查找公司的CIK。
一旦您知道了感兴趣的公司CIK,就可以将其分配给EDGAR URL中的CIK参数。例如,eBay的CIK是0001065088,因此您可以通过将CIK=0001065088添加到EDGAR URL来访问eBay的财务报告:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088
1.2 表格类型
EDGAR提供了数百种不同类型的财务报告,您可以下载一份PDF文档,其中描述了所有这些报告。根据我的经验,大多数投资者只需要关注表1中列出的类型。
表1:EDGAR表格类型
| 表格类型 | ID | 描述 |
|---|---|---|
| 招股说明书 | 424 | 提供公司的一般信息 |
| 年度报告 | 10-K | 公司财务年度报表 |
| 季度报告 | 10-Q | 公司财务季度报表 |
| 年度代理声明 | 14-K | 公司所有者信息 |
| 当前事件报告 | 8-K | 重要事件通知 |
| 证券销售 | 144 | 重要股票出售通知 |
| 受益所有权报告 | 13-D | 识别公司主要所有者(>5%) |
对于本文,您关于这些类型只需要知道的是,您可以通过将URL查询字符串中的type参数设置为报告的ID来访问报告。例如,您可以通过向以下URL发送请求来访问eBay(0001065088)的年度报告(10-K):
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K
1.3 报告日期和数量
EDGAR不允许您按特定日期或日期范围查询报告。相反,EDGAR接受一个截至日期(dateb),该日期标识您感兴趣的最新日期,以及一个数量(count),该数量标识截至该日期的报告数量。
您可以通过将dateb参数设置为所需的日期(YYYYMMDD格式)来在EDGAR URL中设置截至日期。例如,您可以通过向以下URL发送请求来访问eBay(0001065088)在2016年之前(20160101)的所有年度报告(10-K):
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101
您可以通过将URL的count参数设置为所需的数量来限制EDGAR提供的报告数量。例如,您可以通过向以下URL发送请求来访问2016年(20160101)之前eBay(0001065088)的十份年度报告(10-K):
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101&count=10
1.4 所有权
SEC要求公司董事、公司高管以及持有公司大量股票的个人提交文件。默认情况下,EDGAR会提供公司所有可用的报告,无论其来源如何。这相当于在EDGAR URL中将owner参数设置为include。
您可以通过将owner设置为exclude或only来定制EDGAR的行为。如果将owner设置为exclude,EDGAR将不提供任何与公司董事或高管所有权相关的报告。如果将owner设置为only,EDGAR将只提供与董事或高管所有权相关的报告。
2. 以编程方式获取报告
如果您有兴趣手动访问EDGAR报告,则无需继续阅读。只需在浏览器中输入正确的URL并单击其中一个下载链接即可。请记住,“Documents”链接指向可下载文件,而“Interactive Data”链接则在网页中显示报告数据。
如果您想以编程方式下载EDGAR报告,那么确定URL只是第一步。您需要执行至少四个步骤:
- 向URL发送请求并接收HTML响应。
- 解析HTML以查找感兴趣的报告的URL。
- 对于每份感兴趣的报告,向该报告的URL发送请求。
- 解析响应以下载所需的报告。
本节将介绍如何使用Python和Beautiful Soup包来解析HTML。在介绍完Beautiful Soup工具集后,我将解释如何查找EDGAR HTML搜索结果中的报告URL。
2.1 使用Beautiful Soup解析HTML
在撰写本文时,Beautiful Soup项目的官方网站是这里,最新版本是4.6.0。如果您已经安装了Python和pip,可以使用以下命令安装该包:
pip install beautifulsoup4
安装完包后,您就可以使用其功能了。使用Beautiful Soup解析HTML的一般过程包括两个步骤:
- 使用包含HTML的文件或包含HTML的字符串创建一个
BeautifulSoup实例。 - 通过访问
BeautifulSoup实例的子Tag来读取HTML标签数据。
这个简短的讨论介绍了Beautiful Soup工具集的基础知识,但并未涵盖其所有类和功能。如果您想进行更深入的研究,我推荐阅读官方文档。
2.1.1 创建BeautifulSoup实例
当您向EDGAR发送请求时,响应将是HTML格式的文本。您可以通过创建BeautifulSoup类的实例来在Python中解析此HTML。类构造函数接受两个参数:
- 包含HTML的字符串或指向包含HTML的打开文件的句柄
- (可选)要使用的解析库的名称
如果使用一个参数调用构造函数,Beautiful Soup将使用它可以找到的最佳解析器。要指定解析库,您可以将此参数设置为lxml、html5lib或html.parser。例如,以下代码创建了一个BeautifulSoup实例,该实例使用Python内置的html.parser库解析html_str的内容:
soup = BeautifulSoup(html_str, 'html.parser')
调用构造函数后,您就可以通过BeautifulSoup实例的属性和方法来访问已解析的数据了。我将在下一节讨论这些。
2.1.2 访问标签
BeautifulSoup实例有很多属性,其名称与HTML标签相对应。如果soup是实例的名称,则soup.head提供了一个表示文档<head>标签的Tag;soup.body提供了一个表示文档<body>标签的Tag;soup.p提供了一个表示文档中第一个<p>标签的Tag。
在每种情况下,该属性都提供一个Tag实例,其中包含相应HTML标签的数据。方便的是,每个Tag都具有与BeautifulSoup实例相同的与标签相关的属性。表2列出了BeautifulSoup和Tag实例的许多可用属性。
表2:BeautifulSoup和Tag类的与标签相关的属性(节选)
| 属性 | 描述 |
|---|---|
head | 表示文档<head>标签的Tag |
body | 表示文档<body>标签的Tag |
a | 表示第一个超链接(<a>标签)的Tag |
p | 表示第一个段落(<p>标签)的Tag |
b | 表示第一个粗体文本跨度(<b>标签)的Tag |
i | 表示第一个斜体文本跨度(<i>标签)的Tag |
img | 表示文档中第一个图像(<img>标签)的Tag |
字符串 | 包含标签主体文本的NavigableString |
由于BeautifulSoup和Tag类提供了这些属性,因此您可以将它们链接起来以访问HTML文档中的嵌套标签。例如,以下代码将打印example.html中文档的标题:
with open('example.html') as file:<br /> soup = BeautifulSoup(file, 'html.parser')<br /> print(soup.head.title.string)
获取Tag后,您可以使用字典表示法访问相应标签的属性。为了说明这一点,假设example.html包含以下标记:
<html><br /> <body><br /> <p>这是指向 <a href="https://www.google.com">Google!</a> 的链接。</p><br /> </body><br /> </html>
您可以使用以下代码访问超链接的URL:
with open('example.html') as file:<br /> soup = BeautifulSoup(file, 'html.parser')<br /> url = soup.body.p.a['href']
您可以使用类似的代码来确定标签的ID。如果一个属性可以有多个值,字典将返回一个包含该属性值的列表。例如,如果一个文档使用class属性将一个div放置在多个CSS类中,您可以使用div['class']来获取类名列表。
2.1.3 find()和find_all()
表2中的属性只有在您对给定类型的第一个标签感兴趣时才有用。但在许多情况下,您需要访问符合特定条件的一组标签。为了实现这一点,Tag和BeautifulSoup类提供了find()和find_all()方法。您可以通过在方法中插入参数来定义标签选择标准。这两种方法接受相同类型的参数,但find()返回符合您条件的第一个Tag,而find_all()返回一个包含所有符合您条件的Tag的列表。
要搜索特定类型的标签,您可以调用find或find_all,并传入一个标签名称或一个标签名称列表。例如,以下代码返回一个表示文档第一个段落标签的Tag(等同于soup.p):
soup.find('p')
以下代码返回一个列表,其中包含每个段落和超链接的Tag:
soup.find_all(['p', 'a'])
您可以通过调用find/find_all并传入名称=值对来搜索具有特定属性值的标签。例如,以下代码访问id属性设置为mytag的元素:
soup.find(id='mytag')
以下代码查找title属性设置为mytitle且href属性设置为https://www.google.com的元素:
soup.find(title='mytitle', href='https://www.google.com')
如果您想按CSS类搜索标签,则需要使用class_属性。例如,以下代码返回一个列表,其中包含属于new_link类的每个超链接的Tag:
soup.find_all('a', class_='new_link')
除了字符串之外,find和find_all还接受正则表达式,您可以通过调用re模块的compile函数来获取正则表达式。Beautiful Soup文档提供了许多示例。
2.2 查找EDGAR报告的URL
前面,我解释了如何查找特定公司报告的EDGAR URL。例如,如果您想要2016年之前eBay的最新十份年度报告,您可以向以下URL发送请求:
https://www.sec.gov/cgi-bin/browse-edgar?action=getcompany&CIK=0001065088&type=10-K&dateb=20160101&count=10
当我在浏览器中访问此URL时,Chrome显示了图1所示的网页。
图1:搜索页面提供财务报告的链接
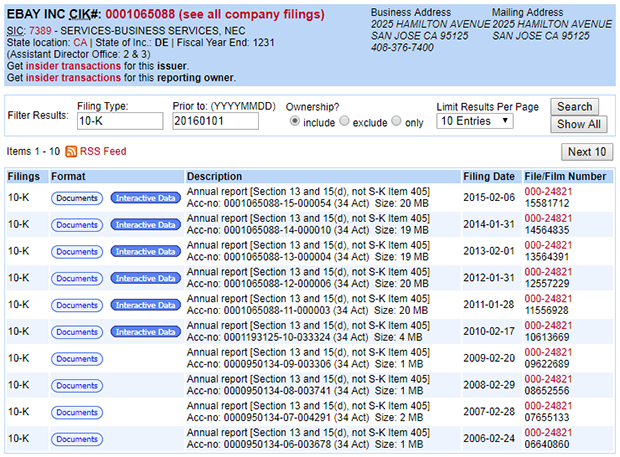
如您所见,EDGAR在一个大表中提供搜索结果。第一列提供报告类型(10-K),第二列提供下载报告的链接,第四列提供提交日期。以下标记可以帮助您了解此表的第一行在HTML中是如何定义的:
<table class="tableFile2" summary="Results">
...
<tr>
<td nowrap="nowrap">10-K</td>
<td nowrap="nowrap">
<a href="..." id="documentsbutton">Documents</a>
<a href="..." id="interactiveDataBtn">Interactive Data</a>
</td>
<td class="small" >...</td>
<td>2015-02-06</td>
<td nowrap="nowrap"><a href="...">000-24821</a><br>15581712</td>
</tr>
...
</table>
您可以通过其CSS类tableFile2来访问该表。我一直认为HTML ID必须是唯一的,但在搜索结果页面中,每个Documents链接的id都是documentsbutton。同样,每个Interactive Data链接的id都设置为interactiveDataBtn。我更喜欢Documents链接,因为该链接适用于所有EDGAR报告,而不仅仅是近期报告。
如果您将EDGAR搜索页面下载到Python字符串(edgar_str)并使用Beautiful Soup,则可以使用以下代码打印报告的URL:
soup = BeautifulSoup(edgar_str, 'html.parser')<br /> tag_list = soup.find_all('a', id='documentsbutton')<br /> for tag in tag_list:<br /> print(tag['href'])
根据我的经验,搜索页面中的每个href属性值都具有相同的通用形式:
/Archives/edgar/data/.../.../...-...-...-index.htm
要获取绝对URL,请在href值前加上https://www.sec.gov。因此,报告的绝对URL的通用形式如下:
https://www.sec.gov/Archives/edgar/data/.../.../...-...-...-index.htm
2.3 下载EDGAR报告
如果您单击表1所示表格的第一行中的Documents按钮,您将进入第二个网页,其中提供了直接下载报告的链接。图2显示了第二个页面的外观。
图2:文档页面提供报告下载链接

在此页面中,上面的表格以文本形式提供报告数据,下面的表格以一种称为XBRL(可扩展商业报告语言)的特殊XML格式提供数据。*.xml文件更容易被计算机解析,但仅适用于2010年之后的报告。2010年之前提交的报告仅以文本格式提供。
如果您查看这两个表格的HTML,其内容将类似于以下内容:
<table class="tableFile" summary="Document Format Files">
<tr>
<td scope="row">1</td>
<td scope="row">FORM 10-K</td>
<td scope="row"><a href="...">ebay201410-k.htm</a></td>
<td scope="row">10-K</td>
<td scope="row">3126866</td>
</tr>
</table>
<table class="tableFile" summary="Data Files">
<tr>
<td scope="row">11</td>
<td scope="row">XBRL INSTANCE DOCUMENT</td>
<td scope="row"><a href="...">ebay-20141231.xml</a></td>
<td scope="row">EX-101.INS</td>
<td scope="row">3504231</td>
</tr>
</table>
在此标记中,区分两个表格的唯一方法是查看summary属性。对于提供文本文件的表格,summary属性设置为Document Format Files。对于提供XBRL文件的表格,summary设置为Data Files。
在这两个表格中,超链接都没有属性。因此,如果您想查找特定表格,您需要遍历表格行,找到具有正确描述(第二列)的行,并从该行的URL(第三列)下载文件。
历史
2018年1月29日 - 初始文章提交