
用 C# 构建推荐引擎
4.94/5 (35投票s)
使用协同过滤和矩阵分解构建推荐系统。

目录
引言
本文解释了推荐系统的理论工作原理,演示了四种不同类型的推荐系统,然后提供了一个使用Code Project挑战数据的示例。
在为本文收集研究资料时,我注意到现有的大部分信息要么完全侧重于底层数学,要么是用Python编写的,要么就没有尝试在真实数据上测试系统。我写这篇文章的目的是尽可能少地使用线性代数来解释推荐系统,用C#构建整个系统,并向您提供有关我结果的真实细节。
基础
表示
推荐系统是一种算法,可以通过用户列表、物品列表以及用户对物品的评分列表进行训练,从而做出未来的推荐。
为了使数据更易于可视化,我们将它表示为一个表格,其中每一行代表一个用户,每一列代表一个物品,每个单元格包含一个评分。

例如,给定我们包含5个用户和5个物品的示例表,我们可以看到用户3(蓝色行)给物品2(黄色列)打了1分(绿色单元格)。
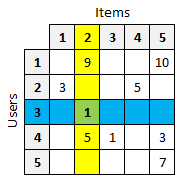
我们推荐系统的目标是填充缺失的单元格。为了实现这一点,我们将检查四种类型的推荐引擎。
基于用户的协同过滤
我们列表中的第一个推荐器是基于用户的协同过滤。这种形式的推荐器基于这样的假设:过去意见一致的用户将来很可能也会意见一致。
在使用用户-文章表时,我们首先需要找到与目标用户相似的用户列表。我们通过将目标用户的物品评分与表中其他所有用户的物品评分进行比较来做到这一点。
例如,由于用户1和用户4都对物品2和物品5进行了评分,我们可以根据这4个评分计算这两个用户之间的相似度得分。请注意,我们不是在比较整行用户;我们只比较两个用户都评分过的物品。

计算用户之间相似度得分有几种方法,它们都以两个用户行作为输入,并输出一个表示相似度的单一数值。常用的算法包括余弦相似度和皮尔逊相关系数,本项目均实现了这些算法。
一旦我们计算出目标用户与表中其他所有用户的相似度得分,我们就可以对这些相似用户(或邻居)进行排序,并只保留最相似(或最近)的用户。这个算法被称为K近邻(KNN)算法。
现在我们有了与目标用户(我们正在为其获取推荐)最相似的用户列表,我们可以获取这些邻居看过的物品,并向目标用户推荐它们。
例如,让我们为用户1找到一个推荐。首先,我们查找他最近的邻居,结果发现是用户4(基于物品2和物品5之间的相似度)。从表中我们可以看到,我们最近的邻居(用户4)喜欢物品3,所以我们可以向尚未评价过该物品的用户1推荐物品3。

基于物品的协同过滤
基于物品的系统与基于用户的系统非常相似。在为特定用户寻找建议时,它们会查找与用户已看过的物品相似的物品。
主要区别在于,我们不是查找最近的用户,而是查找最近的物品。例如,由于用户4喜欢物品2,我们可以查找与物品2相似的物品(如物品5),并将其推荐给用户4。

基于模型的推荐系统
基于模型的系统与协同系统不同。它们不是试图通过查找相似用户或物品来提供建议,而是构建一个数学模型来做出预测。
有许多不同的基于模型的算法可供选择。其中一种更常见的方法称为奇异值分解(SVD),它通过将用户-物品矩阵分解为较小的矩阵,然后可以使用这些较小的矩阵来填充缺失的评分。

实际上,纯数学形式的SVD在存在缺失值时效果并不好,所以我们需要使用一种称为SVD++的变体,它针对带有缺失数据的矩阵进行了优化。我们稍后会详细讨论这一点。
混合推荐系统
混合系统简单地组合了多个推荐引擎,并利用多种算法之一将各个结果聚合为单一推荐。
挑战数据
现在我们对推荐系统的基本工作原理有了了解,我们将通过一个示例来演示如何构建一个。为此,我们将使用Code Project挑战中的用户行为数据。
我们将处理的数据文件分为四个部分:标签、文章、用户和用户操作。这是文件的一个小片段。
# Tags
Tag 1, Tag 2, Tag 3, Tag 4, Tag 5...
...
# Articles
# Article ID, Article Name
1,Article 1, Tag 1, Tag 5, Tag 23
2,Article 2, Tag 4, Tag 9, Tag 1, Tag 6, Tag 8
3,Article 3, Tag 9, Tag 7, Tag 19
...
# Users
# User ID, User Name
1,User 1
2,User 2
3,User 3
4,User 4
...
# User actions
# Day, Action, UserID, UserName, ArticleID, ArticleName
1,View,1,User 1,305,Article 305
1,View,2,User 2,7,Article 7
1,DownVote,2,User 2,7,Article 7
这组数据包含30个标签、3,000篇文章、3,000个用户和105,873个用户操作。当我们将在下一节中将此数据解析为用户-物品表(或矩阵)时,将有9,000,000个单元格(3,000个用户乘以3,000篇文章)。
困扰推荐系统的问题之一是矩阵的稀疏性(值缺失)。如果每个用户都对每篇文章进行了评分,我们的表格可能可以容纳900万个评分,但实际上我们的矩阵有99.17%是空的。这是大量缺失的数据。
在处理新数据集之前,我认为花时间理解它很有帮助。我创建了几种可视化来帮助理解。首先,看起来大多数用户在整个数据集中与20到29篇文章进行了交互。

从另一个角度来看,我们看到被N个用户阅读的文章数量相当均匀。

我还做了一件事,生成了一个3000x3000像素的图像来表示每个用户对每篇文章的评分。黑色像素表示该行中的用户对该列中的文章进行了评分。在下面这张缩放后的图像中,您可以看到三个较暗的框。

无论出于何种原因,我们的数据显示,前1,000名用户通常偏爱前1,000篇文章,第二千名用户阅读第二千篇文章,以此类推。这可能是由于该数据集的生成方式。
在我们开始之前,我们将把数据分成两组。第一组将包含前27天的数据,用于训练。第二组将包含剩余的3天数据,用于训练完成后进行验证。
我们之所以这样划分数据,是因为我们不能使用与训练相同的数据进行测试。为了真正衡量我们推荐器的准确性,我们需要使用训练过程中未使用过的数据。
开发
我们的要求是能够为任何给定用户提供建议列表,并能够预测特定用户对特定文章的评分。
为此,我们将开发几种不同的推荐器,以尝试创建有意义的推荐。每个推荐器都将实现以下接口,该接口公开了一种训练模型、获取用户建议、预测文章评分以及保存和加载训练模型的方法。
public interface IRecommender
{
void Train(UserBehaviorDatabase db);
List<Suggestion> GetSuggestions(int userId, int numSuggestions);
double GetRating(int userId, int articleId);
void Save(string file);
void Load(string file);
}
我们将在此项目中使用一些抽象和通用对象。我们将首先看这些,然后解释它们如何在每个推荐器中以不同的方式实现。
第一个对象是`UserBehaviorDatabase`类,它将保存我们从训练数据文件中解析出的数据。
public class UserBehaviorDatabase
{
public List<Tag> Tags { get; set; }
public List<Article> Articles { get; set; }
public List<User> Users { get; set; }
public List<UserAction> UserActions { get; set; }
}
下一个重要项目是`UserArticleRatingsTable`类。它将我们的用户操作列表转换为用户-文章评分表。
/// <summary>
/// Get a list of all users and their ratings on every article
/// </summary>
public UserArticleRatingsTable GetUserArticleRatingsTable(IRater rater)
{
UserArticleRatingsTable table = new UserArticleRatingsTable();
table.UserIndexToID = db.Users.OrderBy(x => x.UserID)
.Select(x => x.UserID).Distinct().ToList();
table.ArticleIndexToID = db.Articles.OrderBy(x => x.ArticleID)
.Select(x => x.ArticleID).Distinct().ToList();
foreach (int userId in table.UserIndexToID)
{
table.Users.Add(new UserArticleRatings(userId, table.ArticleIndexToID.Count));
}
var userArticleRatingGroup = db.UserActions
.GroupBy(x => new { x.UserID, x.ArticleID })
.Select(g => new { g.Key.UserID, g.Key.ArticleID, Rating = rater.GetRating(g.ToList()) })
.ToList();
foreach (var userAction in userArticleRatingGroup)
{
int userIndex = table.UserIndexToID.IndexOf(userAction.UserID);
int articleIndex = table.ArticleIndexToID.IndexOf(userAction.ArticleID);
table.Users[userIndex].ArticleRatings[articleIndex] = userAction.Rating;
}
return table;
}
在该方法中间,您可以看到我们正在按唯一的用户-文章对进行分组,然后对聚合到组中的行调用`rater.GetRating()`。这是因为每个唯一的用户-文章对可能在数据集中有多个操作。例如,如果用户84对文章305执行了3种不同的操作,就会出现这种情况。
1,View,1,User 84,305,Article 305
1,Upvote,1,User 84,305,Article 305
1,Download,1,User 84,305,Article 305
这个给定用户-文章对的操作列表需要被转化为一个单一的数字,代表一个用户对一篇文章的评分。
由于用户没有明确提供评分,我们需要代表他生成一个隐式评分。目前,我们只需要知道`IRater`接口提供了一种将一组用户-文章操作转化为单个评分的方法。稍后我们将找到一种方法来优化我们计算此评分的方法。
public interface IRater
{
double GetRating(List<UserAction> actions);
}
最后要强调的一个接口是`IComparer`,它接收两个向量(用户或文章),并返回一个单一的值,表示它们的相似度或差异度。如前所述,本项目包含均方根误差(RMSE)、余弦相似度和皮尔逊相关系数比较算法的实现。
public interface IComparer
{
double CompareVectors(double[] userFeaturesOne, double[] userFeaturesTwo);
}
有了这些信息,我们就可以开始设计一些推荐器了。
基于用户的协同过滤
我们将训练的第一个推荐器是基于用户的协同过滤。如果您还记得之前的内容,这种类型的系统会根据相似用户喜欢的内容来提供推荐。这是训练步骤的样子。
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
}
很简单,对吧?我们所做的只是生成一个用户-文章对的表。基于用户的k近邻系统的计算复杂部分在于查找邻居。
这里是我们最终能够为用户生成建议列表的地方。我们首先调用`GetNearestNeighbors()`,它将遍历用户-文章矩阵中的每个用户,计算每个用户与目标用户的相似度,然后返回最接近的匹配项。
var neighbors = GetNearestNeighbors(user, neighborCount);
private List<UserArticleRatings> GetNearestNeighbors(UserArticleRatings user, int numUsers)
{
List<UserArticleRatings> neighbors = new List<UserArticleRatings>();
for (int i = 0; i < ratings.Users.Count; i++)
{
if (ratings.Users[i].UserID == user.UserID)
{
ratings.Users[i].Score = double.NegativeInfinity;
}
else
{
ratings.Users[i].Score =
comparer.CompareVectors(ratings.Users[i].ArticleRatings, user.ArticleRatings);
}
}
var similarUsers = ratings.Users.OrderByDescending(x => x.Score);
return similarUsers.Take(numUsers).ToList();
}
一旦我们有了目标用户最相似的邻居列表,我们就可以遍历所有可能的文章,并获取我们最接近的邻居对每篇文章的看法。如果我们的邻居对给定文章的评分足够高,我们就会将其推荐给目标用户。
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
// If the user in question hasn't rated the given article yet
if (user.ArticleRatings[articleIndex] == 0)
{
double score = 0.0;
int count = 0;
for (int u = 0; u < neighbors.Count; u++)
{
if (neighbors[u].ArticleRatings[articleIndex] != 0)
{
score += neighbors[u].ArticleRatings[articleIndex];
count++;
}
}
if (count > 0)
{
score /= count;
}
suggestions.Add(new Suggestion(userId, ratings.ArticleIndexToID[articleIndex], score));
}
}
一旦我们有了邻居对所有文章的看法,我们就可以按评分对我们的`suggestions`列表进行排序,并返回评分最高的几项。
var similarUsers = ratings.Users.OrderByDescending(x => x.Score);
如果相反,我们想预测一个用户是否会喜欢一篇文章,我们可以使用`GetRating()`方法。
public double GetRating(int userId, int articleId)
{
UserArticleRatings user = ratings.Users.FirstOrDefault(x => x.UserID == userId);
List<UserArticleRatings> neighbors = GetNearestNeighbors(user, neighborCount);
return GetRating(user, neighbors, articleId);
}
private double GetRating(UserArticleRatings user, List<UserArticleRatings> neighbors, int articleId)
{
int articleIndex = ratings.ArticleIndexToID.IndexOf(articleId);
var nonZero = user.ArticleRatings.Where(x => x != 0);
double avgUserRating = nonZero.Count() > 0 ? nonZero.Average() : 0.0;
double score = 0.0;
int count = 0;
for (int u = 0; u < neighbors.Count; u++)
{
var nonZeroRatings = neighbors[u].ArticleRatings.Where(x => x != 0);
double avgRating = nonZeroRatings.Count() > 0 ? nonZeroRatings.Average() : 0.0;
if (neighbors[u].ArticleRatings[articleIndex] != 0)
{
score += neighbors[u].ArticleRatings[articleIndex] - avgRating;
count++;
}
}
if (count > 0)
{
score /= count;
score += avgUserRating;
}
return score;
}
同样,我们将找到目标用户的所有邻居,并计算他们对给定文章的平均评分。为了考虑每个用户的行为不同,我们通过从每个邻居的平均评分中减去他们的平均评分,然后加上目标用户的平均评分来规范化平均值。这将有助于使预测评分更符合目标用户的历史记录,而不是其邻居的历史记录。
基于物品的协同过滤
下一个我们将探讨的推荐器是基于物品的协同过滤。这个系统与基于用户的系统的工作方式相似,但我们查找的是邻近物品,而不是邻近用户。
在开始之前,我想指出,对于这个推荐器,我们还将包含文章标签数据。每篇文章有几个标签,所以我们将向用户-物品表中添加行,这些行要么是1(文章具有给定标签),要么是0(文章不具有该标签)。

这将为我们在查找相似文章时提供一些额外的信息。

和以前一样,我们将创建一个巨大的用户-文章对表。请注意,我们还添加了额外的文章标签信息。
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
List<ArticleTagCounts> articleTags = ubt.GetArticleTagCounts();
ratings.AppendArticleFeatures(articleTags);
FillTransposedRatings();
}
在我们查找邻近物品之前,我们需要弄清楚我们要为哪些物品查找邻近项。毕竟,我们正在为用户寻找建议,而不是为另一个物品。为此,我们将首先找到目标用户已评分的所有文章。
List<int> articles = GetHighestRatedArticlesForUser(userIndex).Take(5).ToList();
private List<int> GetHighestRatedArticlesForUser(int userIndex)
{
List<Tuple<int, double>> items = new List<Tuple<int, double>>();
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
// Create a list of every article this user has viewed
if (ratings.Users[userIndex].ArticleRatings[articleIndex] != 0)
{
items.Add(new Tuple<int, double>(articleIndex,
ratings.Users[userIndex].ArticleRatings[articleIndex]));
}
}
// Sort the articles by rating
items.Sort((c, n) => n.Item2.CompareTo(c.Item2));
return items.Select(x => x.Item1).ToList();
}
一旦我们有了目标用户已阅读的所有文章的列表,我们将为这些物品中的每一个找到一些邻居,对它们进行排序,然后将它们作为建议返回。
foreach (int articleIndex in articles)
{
int articleId = ratings.ArticleIndexToID[articleIndex];
List<ArticleRating> neighboringArticles = GetNearestNeighbors(articleId, neighborCount);
foreach (ArticleRating neighbor in neighboringArticles)
{
int neighborArticleIndex = ratings.ArticleIndexToID.IndexOf(neighbor.ArticleID);
var nonZeroRatings = transposedRatings[neighborArticleIndex].Where(x => x != 0);
double averageArticleRating = nonZeroRatings.Count() > 0 ? nonZeroRatings.Average() : 0;
suggestions.Add(new Suggestion(userId, neighbor.ArticleID, averageArticleRating));
}
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
为了更轻松、更快速地计算列之间的相似度,我转置了用户-物品矩阵,使得所有用户行变成列,所有文章列变成行。生成的文章-用户矩阵使我们能够使用`IComparer`轻松比较文章。
// Precompute a transposed ratings matrix where each row
// becomes an article and each column becomes a user
for (int a = 0; a < ratings.ArticleIndexToID.Count; a++)
{
transposedRatings[a] = new double[features];
for (int f = 0; f < features; f++)
{
transposedRatings[a][f] = ratings.Users[f].ArticleRatings[a];
}
}
由于我们需要为多个物品查找邻居,因此这个基于物品的推荐器比基于用户的推荐器速度要慢一些。
基于模型的推荐系统
接下来,我们将执行矩阵分解来从用户-物品矩阵中提取特征。这是我无法完全避免讨论其底层线性代数的部分。
矩阵分解,就像普通的数字分解(例如,21 = 3 x 7)一样,是一个查找单独的矩阵的过程,当这些矩阵相乘时会得到原始矩阵。理论是,如果我们能找到两个能够准确近似用户-物品矩阵的较小矩阵,那么我们也许也能近似缺失的值。
当我们分解矩阵时,我们可以选择要使用的特征数量。这个特征数量最终成为每个矩阵的两个维度之一。例如,我们的用户-特征矩阵的行数将与用户-物品矩阵相同,但列数将等于所选特征的数量。
选择特征数量有点像一门艺术。如果你选择的太少,你就无法学习现有数据。如果你选择的太多,你可能会记住(或过拟合)数据。

这些特征矩阵包含了我们近似原始矩阵中任何值所需的所有信息。我们只需要计算适当的用户-特征矩阵列与文章-特征矩阵行之间的点积。
点积定义为内积的和,所以在下面的例子中,我们可以这样计算用户2对文章4的评分:`(1 x 1) + (3 x 2) + (2 x -1) = 1 + 6 - 2 = 5`

这里有趣的是,一旦生成了这些特征矩阵,您就可以使用它们来计算原始值以及填充缺失值。这就是我们将如何生成建议和预测评分。

唯一的问题是,我们不能使用纯数学形式的矩阵分解,否则我们会学到预测缺失数据的零值。我们需要一种不同的方法来查找这些矩阵,以便我们只使用非零值进行训练。
为了找到最优矩阵,我们将随机尝试不同的值,查看它们的表现如何,进行微小调整,然后再次尝试。我们将重复这个过程,直到我们的特征矩阵能够准确地预测已知值。
我们将使用的算法称为随机梯度下降,这是一种花哨的说法,意思是我们将迭代地调整输入参数,直到获得我们想要的输出。再次,我们将从查看我们的训练方法开始。这次我们实际上是在*训练*。
public void Train(UserBehaviorDatabase db)
{
UserBehaviorTransformer ubt = new UserBehaviorTransformer(db);
ratings = ubt.GetUserArticleRatingsTable(rater);
SingularValueDecomposition factorizer =
new SingularValueDecomposition(numFeatures, learningIterations);
svd = factorizer.FactorizeMatrix(ratings);
}
而这正是实际工作完成的地方。这个方法将遍历每个用户-文章评分,使用特征矩阵计算该评分的点积,然后计算它偏离了多少(误差)。利用我们的梯度下降算法和计算出的误差,我们可以缓慢地调整我们的特征矩阵中的值,以便我们逐渐更接近正确的结果。
averageGlobalRating = GetAverageRating(ratings);
for (int i = 0; i < learningIterations; i++)
{
squaredError = 0.0;
count = 0;
for (int userIndex = 0; userIndex < numUsers; userIndex++)
{
for (int articleIndex = 0; articleIndex < numArticles; articleIndex++)
{
if (ratings.Users[userIndex].ArticleRatings[articleIndex] != 0)
{
double estimatedRating = averageGlobalRating +
userBiases[userIndex] + articleBiases[articleIndex] +
Matrix.GetDotProduct(userFeatures[userIndex], articleFeatures[articleIndex]);
double error = ratings.Users[userIndex].ArticleRatings[articleIndex] - estimatedRating;
squaredError += Math.Pow(error, 2);
count++;
averageGlobalRating += learningRate *
(error - regularizationTerm * averageGlobalRating);
userBiases[userIndex] += learningRate *
(error - regularizationTerm * userBiases[userIndex]);
articleBiases[articleIndex] += learningRate *
(error - regularizationTerm * articleBiases[articleIndex]);
for (int featureIndex = 0; featureIndex < numFeatures; featureIndex++)
{
userFeatures[userIndex][featureIndex] += learningRate *
(error * articleFeatures[articleIndex][featureIndex] -
regularizationTerm * userFeatures[userIndex][featureIndex]);
articleFeatures[articleIndex][featureIndex] += learningRate *
(error * userFeatures[userIndex][featureIndex] -
regularizationTerm * articleFeatures[articleIndex][featureIndex]);
}
}
}
}
squaredError = Math.Sqrt(squaredError / count);
rmseAll.Add(squaredError);
learningRate *= learningDescent;
}
以下是这段代码实际功能的逐步解释。当我们开始训练时,我们的特征矩阵中的值是随机的。现在,让我们只看一个单元格以及它对应的用户和物品特征。

此时我们所知道的是,用户2给文章4打了5分。我们首先使用最初的随机特征矩阵计算该评分的点积。

我们的估计值是9,这是不正确的。为了弄清楚我们错得有多离谱,我们将估计值减去正确值,看看我们偏离了4。

然后,我们将其代入梯度下降算法,该算法将我们原始特征矩阵中的值调整到接近正确的值。`0.02`值是训练速度,`0.01`是帮助防止训练期间过度调整的值。

有了这些新特征,我们可以再次计算这个单元格的值。这次我们的估计值要接近得多。

您可能会注意到,在代码中有一个全局平均评分,以及每个用户和每个文章的偏差。这有助于我们消除用户或文章之间的任何差异,以防某些用户倾向于给更高的评分。这样,所有的评分都在同一水平上。
我们可以通过在每次迭代后计算均方根误差来跟踪模型的整体准确性。RMSE的计算方法是:减去每个用户-文章对的预期结果与实际结果之差,将其平方,加到一个运行总数中,然后取平方根。
我们的目标是在训练过程中最小化RMSE;但是,我们最终会达到一个训练不再有意义的点。如果我们试图挤出每一个最后的误差,我们就有可能导致模型过拟合(即它记住了少数过去样本,而不是学习一般规则)。

现在我们可以根据训练好的模型来提供建议了。我们将首先计算目标用户尚未阅读的每篇文章的评分。然后,我们将按评分对列表进行排序,并推荐评分最高的文章。
public List<Suggestion> GetSuggestions(int userId, int numSuggestions)
{
int userIndex = ratings.UserIndexToID.IndexOf(userId);
UserArticleRatings user = ratings.Users[userIndex];
List<Suggestion> suggestions = new List<Suggestion>();
for (int articleIndex = 0; articleIndex < ratings.ArticleIndexToID.Count; articleIndex++)
{
// If the user in question hasn't rated the given article yet
if (user.ArticleRatings[articleIndex] == 0)
{
double rating = GetRatingForIndex(userIndex, articleIndex);
suggestions.Add(new Suggestion(userId, ratings.ArticleIndexToID[articleIndex], rating));
}
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
return suggestions.Take(numSuggestions).ToList();
}
计算给定用户和文章的评分非常简单快捷。我们只需要从特征矩阵中计算点积,然后加上偏差。
public double GetRating(int userId, int articleId)
{
int userIndex = ratings.UserIndexToID.IndexOf(userId);
int articleIndex = ratings.ArticleIndexToID.IndexOf(articleId);
return GetRatingForIndex(userIndex, articleIndex);
}
private double GetRatingForIndex(int userIndex, int articleIndex)
{
return svd.AverageGlobalRating +
svd.UserBiases[userIndex] + svd.ArticleBiases[articleIndex] +
Matrix.GetDotProduct(svd.UserFeatures[userIndex], svd.ArticleFeatures[articleIndex]);
}
混合推荐系统
我们的最后一个推荐器实际上并不是一个推荐器本身,而是多个推荐器的组合。这个系统将采用多个其他推荐器的输出,并将它们聚合起来,希望能提供比其组成推荐器更好的建议。训练非常直接。
public void Train(UserBehaviorDatabase db)
{
foreach (IRecommender classifier in classifiers)
{
classifier.Train(db);
}
}
混合系统聚合组件推荐器结果的方式有很多,但就我们的目的而言,我们将简单地从每个系统中返回相同数量的建议。这有望让一个系统能够发现另一个系统没有找到的文章。
public List<Suggestion> GetSuggestions(int userId, int numSuggestions)
{
List<Suggestion> suggestions = new List<Suggestion>();
int numSuggestionsEach = (int)Math.Ceiling((double)numSuggestions / classifiers.Count);
foreach (IRecommender classifier in classifiers)
{
suggestions.AddRange(classifier.GetSuggestions(userId, numSuggestionsEach));
}
suggestions.Sort((c, n) => n.Rating.CompareTo(c.Rating));
return suggestions.Take(numSuggestions).ToList();
}
优化
有了框架,我们现在可以开始微调一些设置。由于我们隐式地根据观看历史为文章分配评分,所以我们应该花一些时间来确定什么对用户的评分贡献最大。
数据包含4种不同的操作:`UpVote`(点赞)、`DownVote`(点踩)、`View`(查看)和`Download`(下载)。每个用户可以对单个文章执行任意数量的这些操作,所以我们需要一种方法将该历史记录压缩成一个单一的评分。为此,我们将定义一个简单的线性回归,将每个操作乘以一个权重。
public double GetRating(List<UserAction> actions)
{
int up = actions.Count(x => x.Action == "UpVote");
int down = actions.Count(x => x.Action == "DownVote");
int view = actions.Count(x => x.Action == "View");
int dl = actions.Count(x => x.Action == "Download");
double rating = up * upVoteWeight + down * downVoteWeight +
view * viewWeight + dl * downloadWeight;
return Math.Min(maxWeight, Math.Max(minWeight, rating));
}
现在我们所需要做的就是找到能产生最准确推荐器的权重。说实话,我曾有宏伟的计划用遗传算法来优化这个方程,但最终我变得懒惰了,只是使用一台拥有36个vCPU的Amazon AWS机器暴力破解了所有参数。
Parallel.ForEach(options, set =>
{
var rate = new LinearRater(set.down, set.up, set.view, set.dl);
var mfr = new MatrixFactorizationRecommender(set.features, rate);
mfr.Train(sp.TrainingDB);
var score = mfr.Score(sp.TestingDB, rate);
var results = mfr.Test(sp.TestingDB, 100);
using (StreamWriter w = new StreamWriter("rater-weights.csv", true))
{
w.WriteLine(set.down + "," + set.up + "," + set.view + "," +
set.dl + "," + set.features + "," + score.RootMeanSquareDifference + "," +
results.UsersSolved + "," + results.TotalUsers);
}
});
在此过程完成后,我们发现我们表现最好的权重如下。
downVote upVote view download
-4 2 3 1
对于点踩减分,而对于点赞、查看和下载加分,这是有道理的。这些是在评分范围设置为`[0.1, 5.0]`时发现的,所以您只需要一次查看和一次点赞就可以获得最高评分。
用法
使用推荐系统很简单。我们需要创建一个`IRater`来使用我们先前发现的权重从用户操作中计算隐式评分。然后,我们需要选择一个`IComparer`算法来比较用户。最后,我们可以选择我们喜欢的`IRecommender`推荐引擎。
IRater rate = new LinearRater(-4, 2, 3, 1);
IComparer compare = new CorrelationUserComparer();
IRecommender recommender = new UserCollaborativeFilterRecommender(compare, rate, 50);
然后,我们可以加载训练数据,进行训练,并可以选择性地保存训练好的模型。
UserBehaviorDatabaseParser parser = new UserBehaviorDatabaseParser();
UserBehaviorDatabase db = parser.LoadUserBehaviorDatabase("UserBehavior.txt");
recommender.Train(db);
recommender.Save(savedModel);
最后,我们可以获得一些推荐。
List<Suggestion> suggestions = recommender.GetSuggestions(userId, ratingsToGet);
如果您运行包含的示例项目,所有这些都已为您完成。

结果
我的总体结果并不辉煌。事实上,它们几乎是糟糕的。
衡量推荐系统成功程度有两种常见方法。一种是精确率,另一种是召回率。我还包括了被推荐至少一篇最终阅读的文章的用户百分比。
精确率是我们建议中相关的(即用户最终会阅读的)建议的百分比。基本上,如果我们要求10个推荐,只有3个是正确的,那么我们的精确率得分将是30%。请注意,*正确推荐*被定义为任何被建议的文章也恰好在测试数据集中的文章。
召回率是我们能够推荐的正确解决方案的百分比。例如,如果测试数据包含用户2最终将阅读的10篇文章,但我们只找到了其中的4篇,那么我们的召回率得分将是40%。
以下是每次提供30个建议时的原始结果。
model precision recall users
UCF 0.29% 1.88% 8.60%
ICF 0.26% 1.70% 7.03%
SVD 0.13% 0.92% 3.90%
HR 0.22% 1.55% 6.36%
表现最好的模型能够正确推荐至少一篇相关文章的次数占 **8.6%**。
总结
我们学会了如何使用协同过滤和矩阵分解来向用户推荐文章和预测评分。此外,我们还研究了如何从单个用户操作中派生评分,并利用文章标签数据来改进我们的评分。
在进入这个项目时,我承认我对推荐系统知之甚少。强迫自己理解一个话题,直到能够向他人解释,结果证明是非常有益的。
感谢您的时间!
历史
- 2018/3/3 - 初始发布
- 2018/3/17 - 修复了格式
- 2018/3/22 - 修复了排序错误