
CodAI - 编程语言检测 AI
4.59/5 (12投票s)
编程语言检测 AI
注意: 您可以通过访问 https://codai.herokuapp.com/ 来评估 CodAI。
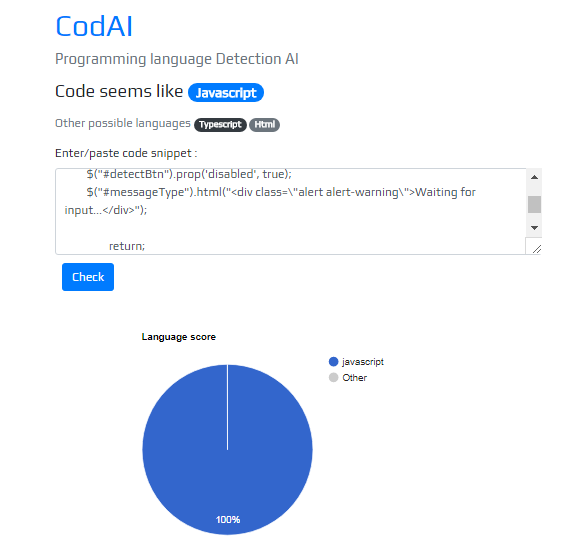
引言
在本文中,我们将讨论使用深度神经网络进行编程语言检测。我使用了 Keras,后端为 tensorflow,来完成这项任务。CodAI 使用的神经网络与我之前的文章 LSTM 垃圾邮件检测器网络 https://codeproject.org.cn/Articles/1231788/LSTM-Spam-Detection 的网络非常相似。
本文包含以下主题
- 准备训练和测试数据
- 构建模型
- 将模型作为 REST API 提供
使用代码
1. 准备训练和测试数据
第一步是准备测试数据,我们的测试数据是一个包含 PRE 块的代码样本的文本文件。我使用了 BeautifulSoup 来提取所有 PRE 标签的内容。
soup = BeautifulSoup(open("LanguageSamples.txt"), 'html.parser')
count=0
code_snippets=[]
languages=[]
for pretag in soup.find_all('pre',text=True):
count=count+1
line=str(pretag.contents[0])
code_snippets.append(line)
languages.append(pretag["lang"].lower())
接下来,我们需要对输入进行分词,Keras Tokenizer 用于此目的,最大特征数为 10000,并将词索引保存到 json 文件。
max_fatures=10000
tokenizer = Tokenizer(num_words=max_fatures)
tokenizer.fit_on_texts(code_snippets)
dictionary = tokenizer.word_index
# Let's save this out so we can use it later
with open('wordindex.json', 'w') as dictionary_file:
json.dump(dictionary, dictionary_file)
X = tokenizer.texts_to_sequences(code_snippets)
X = pad_sequences(X,100)
Y = pd.get_dummies(languages)
2. 构建模型
CodAI 神经网络由卷积神经网络、LSTM 和前馈网络组成。
embed_dim =128
lstm_out = 64
model = Sequential()
model.add(Embedding(max_fatures, embed_dim,input_length = 100))
model.add(Conv1D(filters=128, kernel_size=3, padding='same', dilation_rate=1,activation='relu'))
model.add(MaxPooling1D(pool_size=4))
model.add(Conv1D(filters=64, kernel_size=3, padding='same', dilation_rate=1,activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(lstm_out))
model.add(Dropout(0.5))
model.add(Dense(64))
model.add(Dense(len(Y.columns),activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
模型摘要如下所示

该模型训练了 400 个 epoch,并在验证数据上获得了 100% 的准确率。

3. 将模型作为 REST API 提供
我使用了 Flask 和 Heroku 云平台来提供 Keras 模型。convert_text_to_index_array 函数用于将输入代码片段转换为词向量,并将其输入到我们的神经网络中。
def convert_text_to_index_array(text):
wordvec=[]
global dictionary
for word in kpt.text_to_word_sequence(text) :
if word in dictionary:
if dictionary[word]<=10000:
wordvec.append([dictionary[word]])
else:
wordvec.append([0])
else:
wordvec.append([0])
return wordvec
predict 路由处理输入并预测每个类别的分数,并将结果作为 json 返回。
@app.route("/predict", methods=["POST"])
def predict():
global model
data = {"success": False}
X_test=[]
if flask.request.method == "POST":
code_snip=flask.request.json
word_vec=convert_text_to_index_array(code_snip)
X_test.append(word_vec)
X_test = pad_sequences(X_test, maxlen=100)
y_prob = model.predict(X_test[0].reshape(1,X_test.shape[1]),batch_size=1,verbose = 2)[0]
languages=['angular', 'asm', 'asp.net', 'c#', 'c++', 'css', 'delphi', 'html',
'java', 'javascript', 'objectivec', 'pascal', 'perl', 'php',
'powershell', 'python', 'razor', 'react', 'ruby', 'scala', 'sql',
'swift', 'typescript', 'vb.net', 'xml']
data["predictions"] = []
for i in range(len(languages)):
r = {"label": languages[i], "probability": format(y_prob[i]*100, '.2f') }
data["predictions"].append(r)
data["success"] = True
return flask.jsonify(data)
结论
我从这个项目中学习了很多新东西。编程语言检测对我来说有点具有挑战性。希望你喜欢这篇文章。
历史
更新了损坏的图片链接