
使用 ClassifyBot 在 .NET 中创建 ML 分类管道
5.00/5 (9投票s)
我们将使用 ClassifyBot 程序构建一个 ML 管道,以使用开源 ML 组件解决文本分类问题。

引言
ClassifyBot 是一个开源的跨平台 .NET 库,它尝试自动化和复现创建对象分类的机器学习管道所需的步骤,使用了 Stanford NLP、NLTK、TensorFlow、CNTK 等不同的开源 ML 和 NLP 库。一个 ML 项目通常可以被认为是一个“管道”或工作流程,数据按顺序通过不同的阶段,每个阶段对数据集执行特定的操作。实际数据或存档数据很少是特定 ML 工具或任务所需的格式,因此所有 ML 项目通常都始于检索、预处理和以特定方式准备数据的代码,以便能够加载到特定的机器学习库中。一旦您拥有正确格式的数据源,您就可以执行诸如选择分类任务的特征、以非确定性方式将数据分割为训练集和测试集、根据训练集创建模型、在测试集上测试模型并报告结果、根据测试结果调整模型和分类器参数等操作。这个过程的每个步骤都需要针对不同的数据源、不同的数据集、不同的分类模型和参数以及不同的分类器库进行重复。
对于您开始的每个 ML 项目,您可以编写代码来实现每个步骤,并手动连接参数和不同的步骤。然而,为了创建可重用和可复现的数据操作,其中很多都可以自动化,这些操作可以从您的 Python、R、F# 或其他代码中导出,还可以与其他应用程序集成,并部署到具有日志记录等共享服务的不同环境中。自动化也不应该是特定于工具、库或语言的,以便您能够独立于特定技术设计您的管道。这些类型的需求通常发生在“数据工程”或“ScienceOps”的背景下,数据科学家或程序员创建的 ML 模型和管道被部署以支持公司的日常运营。但是,任何对 ML 和数据科学感兴趣并希望能够学习和使用不同工具和语言来构建 ML 实验,同时最大限度地减少重复和编写样板代码的人,都会发现这种自动化很有用。
ClassifyBot 试图通过提供一个逻辑模型来自动化构建这些类型的 ML 分类项目和实验,在该模型中,每个管道被分割成不同的离散的、自包含的阶段,这些阶段根据不同的参数执行特定的操作。每个阶段可以使用任何库或语言来实现对输入数据集的操作,并且只需要公开一个由管道驱动程序调用的薄 .NET 接口。与 Cascading 等数据管道库不同,ClassifyBot 对您如何在管道中实现每个阶段没有偏见。每个阶段的默认行为是简单地生成文件(通常是 JSON),这些文件可以被后续阶段以及用户想要使用的任何工具或语言消费。通过 pythonnet 等库或通过命令行调用来实现与 Python、R 和 Java 代码的互操作。使用命令行调用产生一个单独的进程对于与 R 等语言进行互操作很有用,R 语言的工具链和库是根据完整的 GPL 许可的,不能链接到其他非 GPL 代码。例如,这里是使用 Java 编写并以 GPL 许可的 Stanford NLP Classifier 被调用为外部进程的示例。
管道阶段中的数据项或记录派生自 Record<TFeature>,它代表单个数据项,包含一个或多个 string 标签或类及其关联的分数,以及一个或多个 TFeature,它们代表数据项拥有的单个特征。拥有统一的数据模型可以最大限度地减少数据操作中的重复:您可以编写与任何数据项、类和特征组合通用的代码。每个阶段实现一个或多个接口,例如 IExtractor<TRecord, TFeature>,表明它可以执行的操作类型。阶段的参数只是一个 .NET 类属性,用一个属性进行装饰,表明它应该在用户界面中显示为一个选项。整个管道由一个易于使用的 CLI 接口驱动,该接口自动将管道阶段及其参数公开为 CLI 动词和选项。ClassifyBot 会自动将阶段参数连接到命令行选项,例如:
[Option('u', "url", Required = true, HelpText = "Input data file Url.
A file with a .zip or .gz or .tar.gz extension will be automatically decompressed.")]
public virtual string InputFileUrl { get; set; }
声明一个名为 InputFileUrl 的参数,该参数可以在命令行中使用 -u 或 --url 指定。
您可以使用标准的 OOP 机制,如继承、组合等,在不同的管道中创建和重用不同的阶段。例如,WebFileExtract 阶段是一个派生自 FileExtract 类的类,并共享大部分相同的代码。
public abstract class WebFileExtract<TRecord, TFeature> :
FileExtract<TRecord, TFeature> where TFeature : ICloneable, IComparable,
IComparable<TFeature>, IConvertible, IEquatable<TFeature> where TRecord : Record<TFeature>
{
public WebFileExtract() : base("{0}-clbot-web-extract-dl.tmp".F(DateTime.Now.Ticks))
{
Contract.Requires(!InputFileUrl.Empty());
if (Uri.TryCreate(InputFileUrl, UriKind.RelativeOrAbsolute, out Uri result))
{
InputFileUri = result;
}
else throw new ArgumentException
("The input file Url {0} is not a valid Uri.".F(InputFileUrl));
}
基础的 FileExtract 阶段被创建为在由子类 WebFileExtract 下载的临时本地文件上运行。要实现管道中的阶段,您只需要创建一个以 'ClassifyBot' 开头的 .NET 程序集,并将该项目或程序集引用到您的主程序中。ClassifyBot 将在运行时从您的程序集中发现并加载合适的类型。ClassifierBot 附带了一个 ConsoleDriver 类,您可以使用它轻松地从您的程序中启动 ML 管道,例如:
class Program
{
static void Main(string[] args) => ConsoleDriver.RunAndExit(args);
}
这就是在 .NET 控制台程序中使用 ClassifyBot 所需的一切。最终,将添加其他驱动程序,以便从 ASP.NET Web 应用等不同的用户界面执行管道。
学习本质上是一个试错的过程,因此建立一个能够减少重复数据操作的摩擦和努力的流程会非常有益。ClassifyBot 负责 ML 管道中的常见操作,如解析命令行参数、日志记录、计时、从互联网下载和解压压缩的存档数据文件,以及读取和写入 XML、JSON 和 CSV 等常见数据格式。最终,ClassifyBot 将整合 MEX 等本体,用于自动创建描述 ML 管道每个阶段的元数据。ClassifyBot 的一个长期目标是用于实现可复现和可存档的 ML 实验,并成为 PMML 等元数据的自动生成器。
背景
为什么自己编写管道?
市面上有许多商业托管产品,如 Amazon Machine Learning、MonkeyLearn、Azure ML Studio 等,它们允许您使用 GUI 创建 ML 工作流程和管道。构建自己的管道可能看起来是很多不必要的努力,但实际上它比使用预制解决方案有很多优势。
- 使用您想要的 ML 库和工具。使用商业托管的 ML 工作流解决方案意味着您在技术和工具的选择上受到限制。商业 ML 解决方案通常提供易用性作为您付费服务的理由,这通常意味着您必须使用他们构建解决方案所依赖的任何框架或库。大多数预构建的 ML 产品不允许您利用当今大量高质量开源 ML 库、框架和工具的爆发式增长。借助 ClassifyBot,您可以选择使用任何您选择的开源 MLP 或 ML 组件构建管道:Mallet、Vowpal Wabbit、Apache MXNet、Scikit-Learn、spaCy……随心所欲。
- 使用您想编写代码的 ML 语言。ClassifyBot 对于管道阶段中的特定操作实际是用什么语言实现的并不在意。只要您可以通过嵌入式解释器、外部命令行、REST API 或其他某种 IPC 或 RPC 互操作方式从 .NET 调用所需的代码,您就可以为其编写管道阶段接口。您可以重用现有代码,或者在管道中根据需要混合搭配语言和技术,而无需局限于 Python、R 或 Java 等特定语言。
- 简单的版本控制和应用程序生命周期管理。使用 Azure ML Studio 等 GUI 工具创建的 ML 工作流通常需要一个单独的版本控制和 ALM 流程,您需要理解(并担心)它。使用 ClassifyBot 实现的 ML 项目就像 .NET 项目和解决方案中的其他 .NET 代码一样。您可以像版本控制其他 .NET 项目一样版本控制您的 ML 项目。您可以使用 NuGet 管理您的依赖项,并将 ML 管道阶段组织到单独的包中,就像处理其他 .NET 项目一样,这些包可以分发给其他开发人员,或者在 CI 管道中进行测试和部署。
- 可扩展性。您可以无缝地扩展您的管道,以添加其他步骤,例如在 DevOps 环境中的注释、可视化或部署。未来,您将能够使用 ClassifyBot 将您的 ML 管道公开为 ASP.NET Core Web 应用或 Web 服务。您可以实现任何您想要的模式,例如主动学习,在您的 ML 管道中。
- 学习新知识。机器学习是一个无穷无尽的迷人主题,学习不同的工具和库如何工作以及如何将它们组合起来解决 ML 问题是吸收大量可用资源知识的绝佳方式。我最初开始开发 ClassifyBot 是为了扩展和泛化我为客户完成的一些分类工作,尽管我仍然是一名 ML 新手,但在开发它的过程中,我学到了很多关于 ML 的知识。使用预制解决方案会将您学习的范围限制在提供商选择的工具和技术上。
问题
我们将解决最近结束的 CodeProject 机器学习和人工智能挑战赛的语言检测问题。基本挑战是在给定大量已标记正确语言的样本的情况下,准确检测短文本样本的编程语言。这是一个典型的文本分类问题,其中有一个类或标签——编程语言——可以分配多个值,如“C#”、“Python”或“JavaScript”。我们可以使用机器学习分类器来识别编程语言,但首先我们需要从 CodeProject 网站上托管的存档文件中提取数据,然后我们必须从给定的编程语言样本中提取或构建特征。
我们可以确定解决该问题的至少 4 个阶段:
提取(Extract):数据文件位于 CodeProject URL,因此我们需要下载文件并解压缩,根据特定格式读取文件中的文本数据,然后提取各个数据项。如果我们以可移植的形式保存提取的数据,那么这个阶段只需要执行一次,因为管道的其余部分将处理提取的数据。
转换(Transform):利用提取的数据,我们需要将其转换为适合构建分类模型的形式。我们既要识别语言样本中可以用作分类算法输入的特征,也要移除会影响模型准确性的无关数据或噪声。有些特征需要使用文本分析来构建,因为它们没有在文本数据中明确给出。
加载(Load):对于我们模型的初始训练,我们需要将数据分成 2 个子集:训练集和测试集,并创建正确格式的输入数据文件,以供我们想要使用的分类器库使用。我们还可以使用 k-fold 交叉验证等技术,其中数据被分成 k 个折叠,然后使用一个折叠来验证其他 k - 1 个折叠。
训练(Train):我们需要使用训练和测试数据集来训练分类器,并测量我们模型的估计准确度。有很多参数可以调整,定义我们模型的构建方式,我们希望有一种简单的方法来评估不同参数如何影响模型的准确度。
构建
Data
CodeProject 提供的训练数据如下所示:
<pre lang="Swift">
@objc func handleTap(sender: UITapGestureRecognizer) {
if let tappedSceneView = sender.view as? ARSCNView {
let tapLocationInView = sender.location(in: tappedSceneView)
let planeHitTest = tappedSceneView.hitTest(tapLocationInView,
types: .existingPlaneUsingExtent)
if !planeHitTest.isEmpty {
addFurniture(hitTest: planeHitTest)
}
}
}</pre>
<pre lang="Python">
# Import `tensorflow` and `pandas`
import tensorflow as tf
import pandas as pd
COLUMN_NAMES = [
'SepalLength',
'SepalWidth',
'PetalLength',
'PetalWidth',
'Species'
]
# Import training dataset
training_dataset = pd.read_csv('iris_training.csv', names=COLUMN_NAMES, header=0)
train_x = training_dataset.iloc[:, 0:4]
train_y = training_dataset.iloc[:, 4]
# Import testing dataset
test_dataset = pd.read_csv('iris_test.csv', names=COLUMN_NAMES, header=0)
test_x = test_dataset.iloc[:, 0:4]
test_y = test_dataset.iloc[:, 4]</pre>
<pre lang="Javascript">
var my_dataset = [
{
id: "1",
text: "Chairman & CEO",
color: "#673AB7",
css: "myStyle",
},
{
id: "2",
text: "Manager",
color: "#E91E63"
},
...
]</pre>
<pre lang="C#">
public class AppIntents_Droid : IAppIntents
{
public void HandleWebviewUri(string uri)
{
var appUri = Android.Net.Uri.Parse(uri);
var appIntent = new Intent(Intent.ActionView, appUri);
Application.Context.StartActivity(appIntent);
}
}</pre>
每个语言样本都包含在一个 HTML pre 元素中,该元素具有以 lang 属性命名的语言。
逻辑上,我们将处理的数据项由一个 string 标签或类组成,该标签或类代表源代码语言名称,以及一个或多个源代码文本样本的特征。我们将一个数据项建模为 LanguageItem 类。
public class LanguageItem : Record<string>
{
public LanguageItem(int lineNo, string languageName, string languageText) :
base(lineNo, languageName, languageText) {}
}
由于训练数据中没有提供 ID 属性,我们将使用特定文本样本元素开始的行号作为 ID,这将允许我们将 LanguageItem 映射回原始数据。每个 LanguageItem 都派生自 Record<string>,并将包含一个或多个 string 特征,这是最通用的特征类型,可以表示数字和非数字可转换的特征数据。
提取
下面显示了整个语言样本数据提取器的代码。
[Verb("langdata-extract", HelpText = "Download and extract language samples data
from https://codeproject.org.cn/script/Contests/Uploads/1024/LanguageSamples.zip
into a common JSON format.")]
public class LanguageSamplesExtractor : WebFileExtractor<LanguageItem, string>
{
public LanguageSamplesExtractor() : base
("https://codeproject.org.cn/script/Contests/Uploads/1024/LanguageSamples.zip") {}
[Option('u', "url", Required = false, Hidden = true)]
public override string InputFileUrl { get; set; }
protected override Func<FileExtractor<LanguageItem, string>,
StreamReader, Dictionary<string, object>, List<LanguageItem>> ReadRecordsFromFileStream
{ get; } = (e, r, options) =>
{
HtmlDocument doc = new HtmlDocument();
doc.Load(r);
HtmlNodeCollection nodes = doc.DocumentNode.SelectNodes("//pre");
L.Information("Got {0} language data items from file.", nodes.Count);
return nodes.Select(n => new LanguageItem(n.Line, n.Attributes["lang"].Value.StripUTF8BOM(),
n.InnerText.StripUTF8BOM())).ToList();
};
}
它相对简单且简短:首先,我们使用 LanguageItem 类型作为记录类型,string 作为特征类型,派生自基类 WebFileExtractor。我们在构造函数中将 CodeProject 数据文件的 URL 传递给 WebFileExtractor。由于我们不要求用户指定文件 URL,我们重写了 InputFileUrl 属性,以隐藏此特定参数作为用户选项。我们用 Verb 属性装饰 LanguageSamplesExtractor 类,以指示从 CLI 实例化此阶段时使用的命令行动词。当您从控制台运行 ClassifiyBot 时,您将在帮助屏幕上看到此动词以及由其他类定义的阶段的其他动词。

最后,我们重写了 ReadFileStream lambda 函数来指定我们将如何从数据文件流中提取数据。我们将使用 HTML Agility Pack .NET 库来解析输入的 HTML 文档,并选择每个包含语言样本的 pre 元素,然后将其构造为 LanguageItem。一些分类器对文本中的 UTF-8 字节顺序标记 (BOM) 很敏感,因此我们会删除这些字符。您可以在此提取阶段中添加提取的数据所需的任何数据清理操作。通过这段代码,我们现在有了一个完整的 ClassifyBot 阶段,可以从 ClassifyBot CLI 调用。

当调用 langdata-extract 阶段时,文件将被下载、解压缩,并将数据提取为存储在磁盘上的可移植 JSON 格式。当指定 -c 选项时,此存储的 JSON 会被 gzip 压缩。ClassifyBot 假定任何具有 .gz 扩展名的文件都是压缩的,并透明地读取压缩流。此 JSON 文件现在可以用作后续任何阶段的输入。提取阶段产生的 JSON 如下所示:
[
...
{
"_Id": 121,
"Id": null,
"Labels": [
{
"Item1": "C#",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\n public class AppIntents_Droid : IAppIntents\r\n
{\r\n public void HandleWebviewUri(string uri)\r\n
{\r\n var appUri = Android.Net.Uri.Parse(uri);\r\n
var appIntent = new Intent(Intent.ActionView, appUri);\r\n
Application.Context.StartActivity(appIntent);\r\n }\r\n }"
}
]
},
{
"_Id": 133,
"Id": null,
"Labels": [
{
"Item1": "Python",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\n# Import `tensorflow` and `pandas`\r\nimport tensorflow as
tf\r\nimport pandas as pd\r\n\r\nCOLUMN_NAMES = [\r\n
'SepalLength', \r\n 'SepalWidth',\r\n
'PetalLength', \r\n 'PetalWidth', \r\n
'Species'\r\n
]\r\n\r\n# Import training dataset\r\ntraining_dataset = pd.read_csv
('iris_training.csv', names=COLUMN_NAMES, header=0)\r\ntrain_x =
training_dataset.iloc[:, 0:4]\r\ntrain_y = training_dataset.iloc[:, 4]\r\n\r\n#
Import testing dataset\r\ntest_dataset = pd.read_csv('iris_test.csv',
names=COLUMN_NAMES, header=0)\r\ntest_x = test_dataset.iloc[:,
0:4]\r\ntest_y = test_dataset.iloc[:, 4]"
}
]
},
{
"_Id": 28,
"Id": null,
"Labels": [
{
"Item1": "JavaScript",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "\r\nvar my_dataset = [\r\n {\r\n id: \"1\",\r\n
text: \"Chairman & CEO\",\r\n title: \"Henry Bennett\"\r\n },\r\n
{\r\n id: \"2\",\r\n text: \"Manager\",\r\n
title: \"Mildred Kim\"\r\n },\r\n {\r\n id: \"3\",\r\n
text: \"Technical Director\",\r\n title: \"Jerry Wagner\"\r\n },\r\n
{ id: \"1-2\", from: \"1\", to: \"2\", type: \"line\" },\r\n
{ id: \"1-3\", from: \"1\", to: \"3\", type: \"line\" }\r\n];"
}
]
},
您不必编写任何代码来下载、解压缩或将提取的数据保存为 JSON,因为这是我们 LanguageSamplesExtractor 类继承的基类 WebileExtractor 已经完成的工作。每个语言样本最初有一个标签或类,它只是文本所在的语言,以及一个特征,它只是语言文本本身。这些数据现在可以由 Transform 阶段处理,该阶段将提取和构造其他特征。
变换
转换阶段是我们选择或构建文本特征作为分类器输入的地方。我们想要识别有助于识别所用语言的语言样本的特征,同时移除那些无用的元素。拥有像我们的 JSON 这样以常见重复方式排列的数据有助于比较和识别过程,只需大致查看数据,我们就可以猜测如何继续。
我们应该做的第一件事是从语言样本文本中删除所有字符串字面量。这些字符串字面量特定于正在创建的程序,而不是使用的语言,并且只会作为噪声降低我们模型的准确性。
第二件需要观察的事情是,许多编程语言文本的词汇或标记特征很重要,并且可以作为识别特征,而在分析自然语言时则不然。有些语言(如 JavaScript 和 C++)使用分号作为行分隔符,使用花括号来分隔代码块。其他语言(如 Python)则完全回避这些分隔符,以提高可读性。属于“C”家族的编程语言都具有某些词汇特征,例如使用 function 和 class 关键字来声明函数、方法和类,以及使用“//”进行注释。其他语言(如 Python 和 Objective-C)具有其他特征,例如使用 def 或 let 等关键字,或者使用“@”符号表示属性,或“#”表示注释,而 C 系列语言通常没有这些。像 XML 和 HTML 这样的标记语言依赖于由尖括号分隔的元素;像 React 这样的混合语言也将这些类型的元素与 JavaScript 的特征混合在一起。但这些自然识别的词汇特征中的许多并没有被文本分类器库识别,这些库主要关注文本中类似单词的语言术语。像“:”这样的符号被视为标点符号,在分类器将应用于文本的分词阶段可能会被完全忽略。所有这些特征都必须从给定的语言样本中构建,以便分类器识别它们为重要的。
我们创建一个类,它派生自 Transformer<LanguageItem, string> 并添加 Verb 选项,以指示此阶段将使用 langdata-features 动词从 CLI 调用。
[Verb("langdata-features", HelpText = "Select features from language samples data.")]
public class LanguageSamplesSelectFeatures : Transformer<LanguageItem, string>
{
protected override Func<Transformer<LanguageItem, string>,
Dictionary<string, object>, LanguageItem, LanguageItem>
TransformInputToOutput { get; } = (l, options, input) =>
{
string text = input.Features[0].Item2.Trim();
...
};
protected override StageResult Init()
{
if (!Success(base.Init(), out StageResult r)) return r;
FeatureMap.Add(0, "TEXT");
FeatureMap.Add(1, "LEXICAL");
FeatureMap.Add(2, "SYNTACTIC");
return StageResult.SUCCESS;
}
protected override StageResult Cleanup() => StageResult.SUCCESS;
我们重写了 TransformInputToOutput 方法来详细说明每个语言样本的文本将如何处理。我们的语言样本特征可以分为词汇和语法等类别,因此我们将它们添加到阶段的 FeatureMap 字典中。在此阶段,我们没有需要清理的中间文件或资源,因此我们暂时忽略 Cleanup 方法。让我们看一下我们对 TransformInputToOutput 的实现。首先,我们使用正则表达式删除任何 string 字面量。
Regex doubleQuote = new Regex("\\\".*?\\\"", RegexOptions.Compiled);
Regex singleQuote = new Regex("\\\'.*?\\\'", RegexOptions.Compiled);
text = singleQuote.Replace
(text, new MatchEvaluator(ReplaceStringLiteral)); //Remove any quote string literals
text = doubleQuote.Replace
(text, new MatchEvaluator(ReplaceStringLiteral)); //Remove any doublequote string literals
然后,我们使用正则表达式提取识别所用语言的标记,并将代表这些标记的标识符添加到“LEXICAL”特征类别中。
string lexicalFeature = string.Empty;
Regex semiColon = new Regex(";\\s*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex curlyBrace = new Regex("\\{\\s*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex at = new Regex("^\\s*\\@\\w+?", RegexOptions.Compiled | RegexOptions.Multiline);
Regex hashComment = new Regex("#.*$", RegexOptions.Compiled | RegexOptions.Multiline);
Regex doubleSlashComment = new Regex("\\/\\/\\s*\\.*?$",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex markupElement = new Regex("<\\/\\w+>", RegexOptions.Compiled);
if (hashComment.IsMatch(text))
{
lexicalFeature += "HASH_COMMENT" + " ";
text = hashComment.Replace(text, new MatchEvaluator(ReplaceStringLiteral));
}
else if (doubleSlashComment.IsMatch(text))
{
lexicalFeature += "DOUBLESLASH_COMMENT" + " ";
text = doubleSlashComment.Replace(text, new MatchEvaluator(ReplaceStringLiteral));
}
if (semiColon.IsMatch(text))
{
lexicalFeature += "SEMICOLON" + " ";
}
if (curlyBrace.IsMatch(text))
{
lexicalFeature += "CURLY_BRACE" + " ";
}
if (markupElement.IsMatch(text))
{
lexicalFeature += "MARKUP" + " ";
}
if (at.IsMatch(text))
{
lexicalFeature += "AT" + " ";
}
LanguageItem output = new LanguageItem(input._Id.Value, input.Labels[0].Item1, text);
output.Features.Add(("LEXICAL", lexicalFeature.Trim()));
return output;
这将针对每行输入运行,并生成一行输出,该行将被保存在输出文件中。现在我们有了特征类的第一个实现,可以从 CLI 运行。

我们将转换后的数据写入一个名为 LanguageSamplesWithFeatures.json 的新 JSON 文件。数据现在看起来如下:
[
{
"_Id": 1,
"Id": null,
"Labels": [
{
"Item1": "XML",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "<?xml version=?>\r\n<DevelopmentStorage xmlns:xsd= xmlns:xsi= version=>\r\n
<SQLInstance>(localdb)\\v11.0</SQLInstance>\r\n
<PageBlobRoot>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\PageBlobRoot
</PageBlobRoot>\r\n
<BlockBlobRoot>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\BlockBlobRoot
</BlockBlobRoot>\r\n <LogPath>C:\\Users\\Carl\\AppData\\Local\\DevelopmentStorage\\Logs
</LogPath>\r\n <LoggingEnabled>false</LoggingEnabled>\r\n</DevelopmentStorage>"
},
{
"Item1": "LEXICAL",
"Item2": "MARKUP"
}
]
},
{
"_Id": 13,
"Id": null,
"Labels": [
{
"Item1": "Swift",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "@objc func handleTap(sender: UITapGestureRecognizer)
{\r\n if let tappedSceneView = sender.view as? ARSCNView {\r\n
let tapLocationInView = sender.location(in: tappedSceneView)\r\n
let planeHitTest = tappedSceneView.hitTest(tapLocationInView,\r\n
types: .existingPlaneUsingExtent)\r\n
if !planeHitTest.isEmpty {\r\n
addFurniture(hitTest: planeHitTest)\r\n }\r\n }\r\n}"
},
{
"Item1": "LEXICAL",
"Item2": "CURLY_BRACE AT"
}
]
},
{
"_Id": 28,
"Id": null,
"Labels": [
{
"Item1": "JavaScript",
"Item2": 1.0
}
],
"Features": [
{
"Item1": "TEXT",
"Item2": "var my_dataset = [\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n {\r\n id: ,\r\n text: ,\r\n
title: \r\n },\r\n { id: , from: , to: , type: },\r\n
{ id: , from: , to: , type: }\r\n];"
},
{
"Item1": "LEXICAL",
"Item2": "SEMICOLON CURLY_BRACE"
}
]
一些识别性的词汇特征已高亮显示。转换后输出数据的 JSON 格式与输入数据相同。ClassifyBot 的转换器都产生相同的 JSON 格式,以便转换阶段可以相互链接,一个阶段的输出文件作为另一个阶段的输入。
我们可以添加更多的词汇特征以及一些语法特征,例如使用 let 关键字的变量赋值,即“let xx = yyy”。但首先,让我们看看使用我们现有特征的分类器的性能。
Load (加载)
我们将使用Stanford Classifier,这是一个用 Java 编写的 ML 库,专门用于文本分类。我们必须对数据进行最后一次转换,将其从我们一直在使用的可移植 JSON 格式转换为我们将要使用的分类器特定的格式,并将数据分成 2 个数据集。大多数分类器(如 Stanford Classifier)接受 CSV 格式文件,因此我们可以使用 LoadToCsvFile 基类作为我们的 Load 阶段。这是我们的 Load 阶段的代码。
[Verb("langdata-load", HelpText =
"Load language samples data into training and test TSV data files.")]
public class LanguageSamplesLoader : LoadToCsvFile<LanguageItem, string>
{
#region Constructors
public LanguageSamplesLoad() : base("\t") {}
#endregion
}
代码遵循其他阶段的模式。基类 LoadToCsvFile 及其方法将处理读取和写入输入 JSON 和输出 CSV 文件的细节。我们只需要创建一个以制表符作为分隔符的基类,因为这是 Stanford Classifier 接受的格式,并使用 Verb 属性将此类公开为可通过 CLI 调用 langdata-load 动词的阶段。

Load 阶段将输入数据集分割为训练集和测试集。默认情况下,80% 的可用数据进入训练数据集,但您可以使用 -s 选项指定拆分比例。默认情况下,只进行确定性拆分,这意味着每次调用 Load 阶段时,相同的记录都会被分配到两个子集中的每一个。但是,通过重写基类 LoadToCsv 的 Load 方法,可以轻松实现随机分配到训练集和测试集以及任何其他需要的加载任务。
Train (训练)
现在我们有了一个具有正确特征和格式的 dataset,可以将其馈送到我们的分类器中。我们的分类器数据是 TSV 格式,如下所示:
C++ // initializes a vector that holds the numbers from 0-9.
// std::vector<int> v = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; print(v);
// removes all elements with the value 5
// v.erase( std::remove( v.begin(), v.end(), 5 ), v.end() ); print(v);
// removes all odd numbers v.erase( std::remove_if(v.begin(), v.end(), is_odd), v.end() );
// print(v); SEMICOLON 9070
C++ namespace my { template<class BidirIt, class T>
BidirIt unstable_remove(BidirIt first, BidirIt last, const T& value)
{ while (true) { // Find the first instance of ...
// first = std::find(first, last, value);
// ...and the last instance of ...
//do { if (first == last)
//return last; --last; } while (*last == value);
// ...and move the latter over top of the former. *first = std::move(*last);
// Rinse and repeat. ++first; } }
// template<class BidirIt, class Pred>
// BidirIt unstable_remove_if(BidirIt first, BidirIt last, Pred predicate)
// { while (true) {
// Find the first instance of ... first = std::find_if(first, last, predicate);
// ...and the last instance of ... do {
// if (first == last) return last; --last; }
// while (predicate(*last)); // ...and move the latter over top of the former.
// *first = std::move(*last); // Rinse and repeat. ++first; } }}
// namespace my SEMICOLON CURLY_BRACE 9084
C++ // initializes a vector that holds the numbers from 0-9.
// std::vector<int> v = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; print(v);
// removes all elements with the value 5 v.erase( my::unstable_remove( v.begin(),
// v.end(), 5 ), v.end() ); print(v);
// removes all odd numbers v.erase( my::unstable_remove_if(v.begin(), v.end(), is_odd),
// v.end() ); print(v); SEMICOLON 9132
PYTHON class Meta(type): @property def RO(self):
return 13class DefinitionSet(Meta(str(), (), {})):
greetings = myNameFormat = durationSeconds = 3.5
color = { : 0.7, : 400 } @property def RO(self):
return 14 def __init__(self): self.greetings =
self.myNameFormat = self.durationSeconds = 3.6
self.color = { : 0.8, : 410 }instance = DefinitionSet() HASH_COMMENT AT 9146
PYTHON class DefinitionSet: def __init__(self):
self.greetings = self.myNameFormat = self.durationSeconds = 3.5
self.color = { : 0.7, : 400 }definitionSet = DefinitionSet()print (definitionSet.durationSeconds)
HASH_COMMENT 9171
XML <MediaPlayerElement Width= Height=> <i:Interaction.Behaviors>
<behaviors:SetMediaSourceBehavior SourceFile= />
<behaviors:InjectMediaPlayerBehavior MediaPlayerInjector=/>
</i:Interaction.Behaviors></MediaPlayerElement> MARKUP 9484
C# public class MediaPlayerViewModel : ViewModel{
private readonly IMediaPlayerAdapter mediaPlayerAdapter;
public MediaPlayerViewModel(IMediaPlayerAdapter mediaPlayerAdapter)
{ this.mediaPlayerAdapter = mediaPlayerAdapter; }
public IMediaPlayerAdapter MediaPlayerAdapter {
get { return mediaPlayerAdapter; } }} SEMICOLON CURLY_BRACE 9493
C# // get default implementation of IPerson
// interface containing only properties// the default property implementation
// is the auto propertyIPerson person = Core.Concretize<IPerson>();person.FirstName = ;
// person.LastName = ;person.Age = 35;person.Profession = ;
// test that the properties have indeed been assigned. Console.WriteLine($"Name=;
// Age=; Profession="); SEMICOLON 9510
C# public class Person_Concretization : NoClass, IPerson, NoInterface
{ public static Core TheCore { get; set; } public Person_Concretization () { }
public string FirstName { get; set; } public string LastName
{ get; set; } public int Age { get; set; }
public string Profession { get; set; } }
HASH_COMMENT SEMICOLON CURLY_BRACE 9530
REACT class ListBox extends React.Component { render()
{ return ( <div className=>
<select onChange={this.OnChange.bind(this)} ref=>
<option value= disabled selected hidden>{this.props.placeholder}</option>
{this.props.Items.map((item, i) =>
<ListBoxItem Item={{ : item[this.textPropertyName],
: item[this.valuePropertyName] }} />)}
</select>
</div> ); } }
SEMICOLON CURLY_BRACE MARKUP 9668
REACT class ListBoxItem extends React.Component { render()
{ return (
<option key={this.props.Item.Value}
value={this.props.Item.Value}>{this.props.Item.Text}</option>
); } } SEMICOLON CURLY_BRACE MARKUP 9687
XML <ListBox Items={this.state.carMakes} valuePropertyName=
selectedValue={this.state.selectedMake} placeholder=
textPropertyName= OnSelect={this.OnCarMakeSelect} />
<ListBox Items={this.state.carModels} selectedValue={this.state.selectedModel}
placeholder= OnSelect={this.OnCarModelSelect} /> 9700
JAVASCRIPT OnCarMakeSelect(value, text) { /
this.setState({ selectedMake: value, carModels: GetCarModels(value), selectedModel: -1 }); }
OnCarModelSelect(value, text) { this.setState({ selectedModel: value }); }
SEMICOLON CURLY_BRACE 9714
第一列是文本的类或标签,下一列是语言样本文本本身,第三列包含我们从文本中提取的词汇特征。我们对 StanfordNLPClassifier 类的训练阶段的实现,该类提供了对基于 Java 的分类器的命令行程序的接口。
[Verb("langdata-train", HelpText = "Train a classifier for the LanguageSamples
dataset using the Stanford NLP classifier.")]
public class LanguageDetectorClassifier : StanfordNLPClassifier<LanguageItem, string>
{
#region Overriden members
public override Dictionary<string, object> ClassifierProperties
{ get; } = new Dictionary<string, object>()
{
{"1.useSplitWords", true },
{"1.splitWordsRegexp", "\\\\s+" },
{"2.useSplitWords", true },
{"2.splitWordsRegexp", "\\\\s+" },
{"2.useAllSplitWordPairs", true },
};
#endregion
}
ClassifierProperties 包含特定于所用分类器的选项。Stanford Classifier 接受一组特定于列的选项,这些选项以零索引的列号作为前缀。所以我们在这里的意思是,我们的数据集的第 1 列(第 2 列)和第 2 列(第 3 列)应该使用空格进行分词。此外,包含词汇特征列表的第 2 列应该除了单个词之外,还应该被分割成词对。诸如“SEMICOLON CURLY_BRACE”之类的词汇特征对对于识别文本所用语言很重要。有很多分类器属性和参数可以尝试,但我们现在先使用我们拥有的参数,并进行一次分类运行。

调优
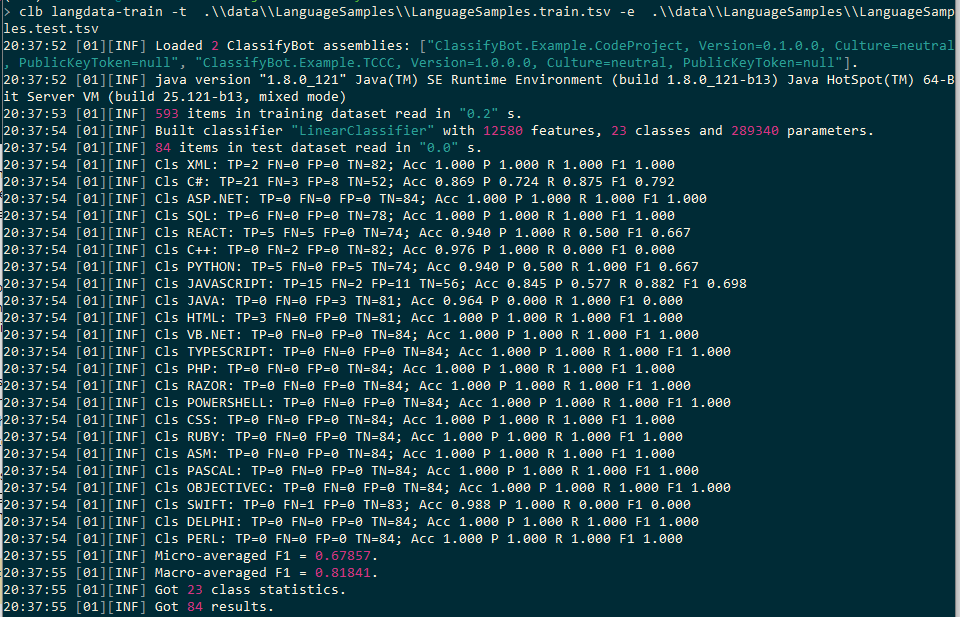
从初始结果来看,分类器能够至少在 50% 的测试数据项中正确分配语言标签或类。然而,存在大量的识别错误:包括假阳性和假阴性。有哪些额外的词汇或语法特征可以帮助提高准确性?
在特定顺序下,标记的组合对于识别语言很重要。我们知道,例如,Python 使用单个冒号和缩进定义方法体。
def RO(self):
C# 允许您定义访问器,如下所示:
X {get; set; }
像 C# 和 C++ 这样的语言包含应用于类和属性声明的访问修饰符。
public class X
我们还可以区分语言如何声明类继承。例如,React 使用以下语法:
class X extends Y
而 C# 使用类似这样的语法:
class X : Y
Python 的语法是:
class X(Y)
一些语言使用 let 关键字进行变量声明和定义。
let x = 500
这些特征可以归类为“SYNTACTIC”,因为它们与语言在词法分析阶段用于解析标记的规则有关。我们可以再次使用正则表达式来检测文本中的这些特征,并将特征标识符添加到“SYNTACTIC”特征类别中。我们将以下代码添加到我们的特征阶段:
//syntax features
string syntacticFeature = string.Empty;
Regex varDecl = new Regex("\\s*var\\s+\\S+\\s+\\=\\s\\S+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex letDef = new Regex("\\s*let\\s+\\w+\\s+\\=\\s\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex defBlock = new Regex("^\\s*(def|for|try|while)\\s+\\S+\\s*\\:\\s*$",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex propertyAccessor = new Regex("\\w+\\s+\\{get;", RegexOptions.Compiled);
Regex accessModifier = new Regex("^\\s*(public|private|protected|internal|friend)\\s+
\\w+?", RegexOptions.Compiled | RegexOptions.Multiline);
Regex classExtendsDecl = new Regex("^\\s*class\\s+\\S+\\s+\\extends\\s+\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex classColonDecl = new Regex("\\s*class\\s+\\w+\\s*\\:\\s*\\w+",
RegexOptions.Compiled | RegexOptions.Multiline);//^\s*class\s+\w+\s*\(\w+\)
Regex classBracketsDecl = new Regex("^\\s*class\\s+\\w+\\s*\\(\\w+\\)",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex fromImportDecl = new Regex("^\\s*from\\s+\\S+\\s+import\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex importAsDecl = new Regex("^\\s*import\\s+\\S+\\s+as\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
Regex newKeywordDecl = new Regex("\\w+\\=\\s*new\\s+\\w+",
RegexOptions.Compiled);
Regex usingKeywordDecl = new Regex("^\\s*using\\s+\\w+?",
RegexOptions.Compiled | RegexOptions.Multiline);
if (varDecl.IsMatch(text))
{
syntacticFeature += "VAR_DECL" + " ";
}
if (letDef.IsMatch(text))
{
syntacticFeature += "LET_DEF" + " ";
}
if (defBlock.IsMatch(text))
{
syntacticFeature += "DEF_BLOCK" + " ";
}
if (accessModifier.IsMatch(text))
{
syntacticFeature += "ACCESS_MODIFIER" + " ";
}
if (propertyAccessor.IsMatch(text))
{
syntacticFeature += "PROP_DECL" + " ";
}
if (classExtendsDecl.IsMatch(text))
{
syntacticFeature += "CLASS_EXTENDS_DECL" + " ";
}
if (classColonDecl.IsMatch(text))
{
syntacticFeature += "CLASS_COLON_DECL" + " ";
}
if (classBracketsDecl.IsMatch(text))
{
syntacticFeature += "CLASS_BRACKETS_DECL" + " ";
}
if (fromImportDecl.IsMatch(text))
{
syntacticFeature += "FROM_IMPORT_DECL" + " ";
}
if (importAsDecl.IsMatch(text))
{
syntacticFeature += "IMPORT_AS_DECL" + " ";
}
if (newKeywordDecl.IsMatch(text))
{
syntacticFeature += "NEW_KEYWORD_DECL" + " ";
}
if (usingKeywordDecl.IsMatch(text))
{
syntacticFeature += "USING_KEYWORD_DECL" + " ";
}
[Option("with-syntax", HelpText = "Extract syntax features from language sample.", Required = false)]
public bool WithSyntaxFeatures { get; set; }
现在我们可以调用我们的转换阶段,并使用新的代码和选项。

我们还将向分类阶段添加一个参数,以启用 Stanford Classifier 的 k-fold 交叉验证功能。
Option("with-kcross", HelpText = "Use k-fold cross-validation.", Required = false)]
public bool WithKFoldCrossValidation { get; set; }
并重写分类器的 Init() 方法以在指定时引入此参数。
protected override StageResult Init()
{
if (!Success(base.Init(), out StageResult r)) return r;
if (WithKFoldCrossValidation)
{
ClassifierProperties.Add("crossValidationFolds", 10);
Info("Using 10-fold cross validation");
}
return StageResult.SUCCESS;
}
我们将折叠数 k 设置为 10。我们也可以使用整数参数允许用户设置 k 的值,但 10 是一个不错的默认值。现在,我们可以使用附加的语法特征运行我们的加载阶段,并使用 10 折交叉验证再次运行训练阶段。

分类器计算每个折叠的结果,允许您比较分类模型在不同数据子集上的表现。

我们看到,即使有了语法特征,许多语言类别仍然存在问题,平均准确率仅为 65%。我们需要进行进一步的测试,并工程化更多的语法特征来区分这些语言,以使分类器表现得更好。好消息是,标记语言以及 Python 和 React 等语言的检测效果很好。
关注点
如果您习惯使用 Python,您可能会觉得 ClassifyBot 有点小题大做且不必要地复杂。毕竟,在 Python 中下载文件或使用 shell 脚本只需要一行代码,并且可以使用 numpy 等库的数据操作能力直接从 Python 控制台操作和转换数据。但是,您应该考虑需要附加的代码来:
- 创建一个可以接受不同数据操作参数的 CLI 程序。
- 将每个文本处理阶段的结果保存到通用格式。
- 在您的整个管道中实现日志记录、计时和其他通用操作。
- 开发一个 OOP 模型,以方便其他开发人员或在其他项目中重用您的代码。
一旦您超越了简单的 ML 实验单用户阶段,使用 ClassifyBot 这样的库的好处就会显现出来。未来的文章将探讨 ClassifyBot 的演进功能,包括自动为管道阶段和逻辑创建文档和图表等内容。
历史
- 第一个版本提交给 CodeProject。