
理解长短期记忆网络(LSTM)
5.00/5 (5投票s)
理解长短期记忆网络(LSTM)
还记得我们在上一篇文章中说过,循环神经网络(RNN)可以预测文本并实现出色的语音识别功能吗?事实上,我们在上一篇文章中归功于 RNN 的所有重大成就,实际上都是通过一种特殊的 RNN——长短期记忆单元 (LSTM) 来实现的。
这个升级版的 RNN 解决了这些网络通常存在的一些问题。由于 RNN 的概念,就像该领域的大多数概念一样,已经存在一段时间了,90 年代的一些科学家在使用它时注意到了存在的障碍。标准 RNN 有两个主要问题:长期依赖问题和梯度消失/爆炸问题。

长期依赖问题
我们在上一篇文章中已经提到了长期依赖的主题,所以在这里我们来详细探讨一下。使用 RNN 的一个优点是我们可以将先前的信息与当前任务联系起来,并在此基础上做出某些预测。例如,我们可以尝试根据句子中的前一个词来预测该句子中的下一个词。当只需要查看先前的信息来执行特定任务时,RNN 非常适合这类任务。然而,这真的就是全部情况吗?

以语言模型中的文本预测为例。有时,我们可以根据前一个词预测文本中的下一个词,但更多时候我们需要比前一个词更多的信息。我们需要上下文,我们需要句子中的更多词。RNN 在这方面表现不佳。对于我们的预测,我们需要的前期状态越多,这对标准 RNN 来说问题就越大。
梯度消失/爆炸问题
你可能知道,梯度表示权重随着误差的变化而变化。因此,如果我们不知道梯度,我们就无法以正确的方向更新权重并减少误差。我们在每个人工神经网络中面临的问题是,如果梯度非常小,它将阻止权重改变其值。例如,当你多次应用 sigmoid 函数时,数据会被压平,直到没有可检测到的斜率。数据被压平,直到在很大范围内没有可检测到的斜率。当梯度穿过神经网络的许多层时,也会发生同样的情况。

在 RNN 中,由于在循环神经网络的学习过程中,我们是“随时间”更新它们的,所以这个问题更大。我们使用时间反向传播(Backpropagation Through Time),这个过程引入了比常规反向传播更多的乘法和操作。当然,这个梯度问题也可能走向另一个极端。梯度会逐渐变大,导致 RNN 中出现蝴蝶效应,这就是所谓的梯度爆炸问题。
LSTM 架构
为了解决循环神经网络面临的障碍,Hochreiter & Schmidhuber (1997) 提出了长短期记忆网络的概念。它们在各种问题上表现得非常好,现在非常流行。其结构与标准 RNN 类似,意味着它们将输出信息反馈给输入,但这些网络不会遇到标准 RNN 所面临的问题。在它们的架构中,它们实现了一种记忆长期依赖的机制。
如果我们观察标准 RNN 的展开表示,我们会认为它是一个重复结构的链。这种结构通常相当简单,例如单个 tahn 层。

LSTM 尽管遵循相似的原理,但其架构却复杂得多。它们通常有四个层,而不是一个层,并且在这四个层中有更多的操作。下面图片展示了一个 LSTM 单元结构的例子。

这是图表中元素的图例
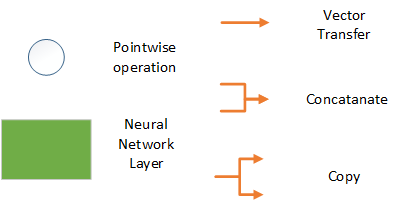
正如你在图片中看到的,我们有四个网络层。一个层使用 tahn 函数,两个层使用 sigmoid 函数。此外,我们还有一些逐点操作和对向量的常规操作,例如拼接。我们将在下一章详细探讨这一点。
然而,需要注意的是上面由字母 C 标记的数据流。这个数据流保存着不在循环神经网络正常流程中的信息,被称为单元状态(cell state)。本质上,通过单元状态传输的数据的功能与计算机内存中的数据非常相似,因为数据可以存储在单元状态中,也可以从中读取。LSTM 单元使用称为门(gates)的模拟机制来决定哪些信息将被添加到单元状态。
这些门是通过与 sigmoids(范围 0-1)进行逐元素乘法来实现的。它们类似于神经网络的节点。根据输入信号的强度,它们将信息传递到单元状态或阻止它。为此,它们有自己的一组权重,这些权重在学习过程中得到维护。这意味着 LSTM 单元被训练来过滤某些数据并保留误差,这些误差以后可以用于反向传播。利用这种机制,LSTM 网络能够学习许多时间步长的数据。
LSTM 处理流程
LSTM 单元分几个步骤运行:
- 遗忘单元状态中不必要的信息
- 向单元状态添加信息
- 计算输出
LSTM 单元中的第一个 sigmoid 层称为遗忘门(forget gate)层。通过这个层/门,LSTM 单元决定了前一个状态 Ct-1 的重要性,我们决定什么将被移除。由于我们使用的是从 0 到 1 的 sigmoid 函数,因此数据可以被完全移除、部分移除或完全保留。这个决定是通过查看前一个状态 Ht-1 和当前输入 Xt 来做出的。使用这些信息和 sigmoid 层,LSTM 单元为单元状态 Ct−1 中的每个数字生成一个介于 0 和 1 之间的数字。
![]()
当移除了不必要的信息后,LSTM 单元会决定将哪些数据添加到单元状态。这通过第二个 sigmoid 和 tahn 层组合来完成。首先,第二个 sigmoid 层,也称为输入门(input gate)层,决定单元状态中的哪些值将被更新(输出 – i),然后 tahn 层创建一个新的候选值向量,这些值可以被添加到单元状态中(输出 ~Ct)。
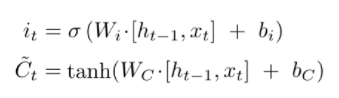
有效地,使用这些信息,就可以计算出单元状态的新值——Ct。

我们需要做的最后一步是计算 LSTM 单元的输出。这是通过第三个 sigmoid 层和一个额外的 tahn 滤波器来完成的。输出值基于单元状态中的值,但也被 sigmoid 层过滤。基本上,sigmoid 层决定了单元状态的哪些部分将影响输出值。然后我们将单元状态值通过 tahn 滤波器(将所有值推到 -1 和 1 之间)并乘以第三个 sigmoid 层的输出。
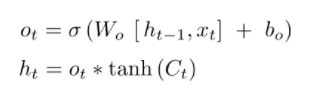
结论
这个升级版的 RNN 实际上使这类网络如此受欢迎。由于其保存数据的能力,它们取得了巨大的成功。这些网络唯一的缺点是训练过程相当耗时,并且需要大量资源。你可以想象,训练如此复杂的结构不会便宜。除此之外,当处理需要序列数据处理的问题时,它们是最好的选择之一。
感谢阅读!