
统一并发 II - 基准测试方法学
统一并发的目标是以面向对象的方式,通过一个模式和两个接口(用于通用方法和异步/await方法)来统一访问不同的同步原语。

系列文章
- 统一并发 I - 简介
- 统一并发 II - 基准测试方法学
- 统一并发 III - 跨基准测试
- 统一并发 IV - 实现跨平台 (.NET Core 2.1 / .NET Standard 2.0)
引言
在第一篇关于统一并发和已实现同步原语的文章中,我跳过了所有关于基准测试方法的复杂部分,并且还敢于在没有任何证明的情况下,对每个同步原语进行一些基本的性能评估。现在是时候深入研究基准测试和用于理解通用同步原语特性的方法的黑暗魔法了。我将介绍我用来理解统一并发框架下已实现或封装的同步原语的特性和行为的基准测试方法,并将该方法应用于 C# lock (Monitor 类) 并对其进行研究。
我们将不得不考虑不同的场景、比较多个数据序列的问题、数据序列的校准以确保相关性,甚至数据类型的选择。最后,将大量数据放入一个合理且自解释的图表中。
统一并发框架 实现于开源的 GreenSuperGreen 库 中,可在 GitHub 和 Nuget (3 个包:lib、unit tests、benchmark) 上找到。
- http://github.com/ipavlu/GreenSuperGreen
- https://nuget.net.cn/packages/GreenSuperGreen/
- https://nuget.net.cn/packages/GreenSuperGreen.Test/
- https://nuget.net.cn/packages/GreenSuperGreen.Benchmarking/
测量参数
我们需要测量三个重要参数:
- CPU 负载(处理器时间)- 性能计数器
- 获得锁访问的次数
- 同步原语进入和同步原语退出之间的时间间隔
CPU 负载需要每秒一次的性能计数器测量。访问计数器很简单。时间间隔则比较棘手。在没有特殊硬件的情况下,我们无法精确测量低于毫秒的短时间间隔,我们需要一个可靠的、不影响测量且具有微秒不确定性的时间源,该时间源在单线程和多线程场景下都能正常工作。调用系统获取时间是有成本的。显然,我们正在处理的系统并非为精确的实时测量而设计。
我们必须放弃直接测量每次访问时间间隔的希望。为了获得亚毫秒级的时间间隔精度,我们必须进行调整,测量约十秒的大量访问,然后将时间进行除法。我们能获得精确的时间间隔测量吗?可以。通过足够多的访问次数,我们可以精确测量这些时间间隔,并且如果我们使用中位数而不是简单平均值,我们可以忽略由操作系统线程引起的一些不规则性。当然,存在一些限制,我将在 SpinLock 中讨论这些限制。
中位数吞吐量周期
从这些测量中计算出的时间间隔描述了给定计算复杂度的受给定同步原语保护的锁定代码的中位数吞吐量周期。中位数吞吐量周期有效地描述了获得锁访问、在锁定区域执行代码和退出锁所需的最小时间间隔。通过 n 线程和给定锁定代码的计算复杂度进行测量,我们可以获得关于在特定配置下通过给定同步原语可以完成多少工作以及工作的频率的信息。
顺序和并发测量
统一并发框架目前能够统一锁类型的同步原语。有趣的是,这些类型的同步原语的最终目标是模仿顺序执行,即单线程执行。我们可以使用顺序单线程执行测量来描述理想的同步原语,并为比较创建基础。
假设顺序单线程情况下的理想线性加速比为一。对于运行 n 个线程争用理想同步原语的 n 核 CPU,我们可以假设加速比为 1/n。真实的同步原语会比 1/n 差很多,它们必须在通信和协调线程以及通过 CPU/缓存/内存总线传输数据上花费一些时间。
这些关系对于理解将过多的并行性应用于顺序问题不会提高性能非常重要。
工作单元
工作单元与给定硬件相关。如果工作单元在单线程、无竞争 CPU 上执行多次循环时,其执行时间具有合理的不确定性是相似的,那么这已经足够了。在现代 CPU 架构上,计算指令、操作数而忽略同步原语之间的相对差异是没有意义的。工作单元存在一些限制,它将是堆栈上对单个整数值进行的操作。
频谱数据
为了充分理解每个同步原语的行为,我们将基于工作单元的旋转次数创建频谱数据。给定次数的工作单元旋转创建了定义的计算复杂度,并与给定配置(同步原语、线程数和场景)的特定中位数吞吐量周期相关。我们将创建一个旋转列表。对于每个旋转次数,我们将测量多个 CPU 负载和吞吐量周期,并计算给定旋转次数的中位数 CPU 负载和给定旋转次数的中位数吞吐量周期。
数据比较
为了理解关系,我们将比较相同旋转次数的中位数吞吐量周期和中位数 CPU 负载。在相同的硬件上,我们可以比较具有相同工作单元旋转次数的配置的测量数据。这将使我们能够比较不同同步原语和/或配置之间相同旋转次数的中位数吞吐量周期和中位数 CPU 负载。
图表构建和理解
X 轴是工作单元的旋转次数,所有其他数据序列都由该数字驱动。
左侧 Y 轴是 10 秒测量CPU 使用率的中位数,实线轴,始终由实心数据线表示,测量的点是与数据线相同颜色的完全填充的实心数据点。
右侧 Y 轴是 10 秒测量吞吐量周期的中位数,虚线轴,始终由虚线数据线表示,测量的圆形数据点中心有不同的颜色。
注意:X 轴和右侧 Y 轴按log2缩放,这有助于避免数据系列变化不够大的宽阔区域。
重要的是要理解,图表上任何穿过中位数 CPU 数据点、中位数吞吐量周期数据点和工作单元旋转次数数据点的垂直线实际上代表了 10 秒的测量,其中旋转次数是恒定的,等于穿过垂直线的旋转次数。
每个图表都是由在每个同步原语上经过数分钟测量收集的大量数据构成的。
理想同步原语基准测试
基于上述方法,我们可以为理想同步原语构建第一个基准测试图表。
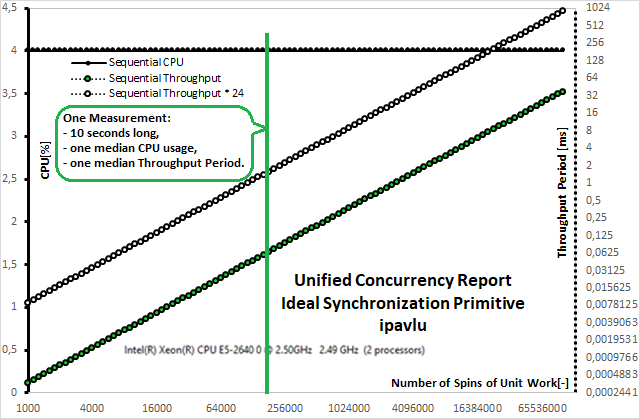
在图表 1 中,我们可以看到一条恒定的数据线,中位数 CPU 使用率约为 4%。虽然不明显,但 CPU 数据始终是实心数据线,其圆点测量值填充为与数据线相同的颜色。
理想同步原语的中位数吞吐量周期由于 X 轴和右侧 Y 轴的 log2 缩放而形成一条对角线,但与所有非理想同步原语的非理想吞吐量周期存在一些差异。在图表 1 中,我们可以看到两条对角线。一条是干净的测量,另一条是针对 24 个线程争用理想同步原语的情况进行了校准。这种校准将适用于所有同步原语的基准测试。
测量次数的设计是为了 Excel 中更大的图表,尺寸是原来的两倍。将相同的图表强行放入 640 像素是具有挑战性的,但仍然,所有部分都可识别,数据系列不完全恒定的情况也不会引起任何问题。
任何依赖于同步的多线程软件都会隐藏其行为的一部分,只有在边缘情况下才能显现。软件越复杂,我们对自己的软件了解就越少,因为将其推入所有可能的边缘情况变得越来越困难,有时甚至列出所有边缘情况本身就是一个问题。生产阶段以外的性能测试并不总能成功检测到问题,原因在于难以准备生产阶段随机发生的各种边缘情况(峰值负载)。
我坚信,解决这些问题的方法在于对同步原语的详细了解,因为它们在边缘情况下驱动软件的行为。如果我们从时间域的争用角度来看待高度并发的多线程环境中的软件执行路径,我们可以识别两种类型的争用:
- 直接争用 – 共享同步原语,多个线程敲同一个门。
- 间接争用 – 多个不相关的线程组,每个组都在最小程度上争用,每个组都有自己的同步原语,多个门。
现在,有趣的部分在于,间接争用情况下的争用来源是什么?这些组之间不共享同步原语,它们实际上可以被分成不同的进程。这里的争用来源是共享的 CPU、内存带宽和总线,尤其是在使用原子指令获取锁(混合锁定方法)的情况下。忙碌的自旋等待也在消耗 CPU 周期,这在具有同步多线程的现代 CPU 上已大大减少,但内存带宽的减少是无法避免的,可重复获取条目的交错操作会带来高频率的缓存同步,从而影响共享服务器框上的其他服务。


上图描述了一个简单的基准测试,远未达到边缘情况,平均争用,同步造成的资源浪费通常很小。这是最简单的测试场景,通常不需要对测试代码进行复杂的更改,但它不能用于推断或推理峰值负载下边缘情况的行为,因为峰值负载下同步的成本足以消耗 99% 的 CPU 资源,而只有很少的工作完成,并且在简单的基准测试中,同步争用的概率大大降低,这意味着我们通常无法在不修改代码的情况下观察到代码中的边缘情况和重度争用。简单的基准测试只能描述同步原语影响的不完整图景。在这种情况下,我们必须关注重度直接争用,其中同步原语的成本将是可见且可衡量的,并且还可以及时调整以研究两种关系(A:旋转次数 x CPU 使用率,B:旋转次数 x 吞吐量周期)的频谱行为。

重度间接争用场景也会类似,能够研究多个不共享任何东西但共享硬件的无关同步原语之间的硬件副作用。

测试场景
将有两种类型的测试场景:
- 重度争用 – 代表最严峻的重度直接争用情况
- 糟糕的邻居 – 代表最严峻的重度间接争用情况,其中最小化争用的线程对的累积效应以及与他人良好协作的能力将尽可能地显现出来
在边缘情况和峰值负载下,这两种场景可以看作是时间域的压缩,它会增加争用级别,因为更有可能遇到其他线程的独占访问。
目标硬件和软件

基准测试:Monitor (C# Lock) - 重度争用
Monitor(C# Lock)的吞吐量表现非常好,单调地以与顺序吞吐量类似的方式进行,没有意外。但是,消耗的 CPU 资源量令人担忧。吞吐量越短,在重度争用场景下浪费的 CPU 资源就越多!这实际上是重要的,因为它违背常识!
解释非常简单。如前所述,Monitor (C# Lock) 是一个混合锁。在尝试获取访问权限时,当另一个线程已经拥有访问权限时,该线程不会立即被挂起,而是会自旋等待,试图尽快获取访问权限,以期限制线程挂起/恢复的成本,如果无效,则线程会被挂起。这种混合方法是在第一批多核盒子时代引入的,当时它提高了吞吐量,但现在拥有 24 个或更多核心,其成本很高,而且随着每个额外核心的增加,成本会变得更糟。
在 Monitor (C# Lock) 中,工作时间很短但请求很多的情况下,会浪费大量 CPU 资源!显然,我们不能再忽视落后于硬件架构的遗留代码库和老旧软件架构了。
根据图表,应避免在该盒子上的吞吐量低于 64 毫秒,因为超过 60% 的 CPU 资源将被浪费在热量中!线程数较少时,这个数字可能会降低。避免高并发级别始终是一个很好的检查点,看看我们是否没有将过多的并行性应用于顺序问题。但是,浪费 60% 或更多 CPU 资源的吞吐量级别会随着 CPU 核心数量的增加而升高,而这正是目前的趋势。

基准测试:Monitor (C# Lock) - 重度间接争用 - 糟糕的邻居
请记住,糟糕的邻居场景是关于多个不相关线程对(每个线程都有最小化争用)的累积效应。如上面报告中关于 Monitor (C# Lock) 的重度争用场景所述,在低争用情况下,Monitor (C# Lock) 的吞吐量周期可能显著降低,而 CPU 浪费并不大,但即使在这种情况下,我们也可以看到,Monitor (C# Lock) 在 CPU 浪费中起着作用,对于吞吐量低于 16 毫秒的情况,其浪费是预期的两倍,因此 Monitor (C# Lock) 确实是一个糟糕的邻居,少数不相关的服务/线程以低争用可能累积浪费超过 50% 的 CPU 资源,只有 48% 的有用工作正在进行。此陈述基于图表中的理想顺序趋势线。

摘要
本文的主要目的是介绍统一并发框架/Green Super Green 库下的基准测试方法。我们研究了作为主要同步原语 Monitor (C# Lock) 的比较基础的理想同步原语。
已注意到 Monitor (C# Lock) 的一些问题。
在下一篇文章中,我们将最终一次性讨论所有基准测试,并有机会相对比较它们,以找到它们的优缺点。
历史
- 2018 年 4 月 26 日:初始版本