
信用风险分类:使用 Intel 优化包进行更快的机器学习
本文阐述了使用 Intel® Performance Libraries 解决信用风险分类等机器学习问题的重要性。
摘要
本文阐述了使用 Intel® Performance Libraries 解决信用风险分类等机器学习问题的重要性。解决信用风险分类问题的目标是从银行的角度最大程度地减少损失;例如,当某人申请贷款时,银行需要决定批准哪些贷款申请,不批准哪些。本案例研究使用 Intel® Distribution for Python* 和 Intel® Data Analytics Acceleration Library (Intel® DAAL) 的 Python API(名为 PyDAAL)来提升机器学习和数据分析性能。利用 Intel® Distribution for Python* 提供的优化的 scikit-learn*(集成了 Intel DAAL 的 Scikit-learn),我们在预测问题上取得了良好的结果。
引言
信用风险是银行业中存在的主要金融风险之一。银行如何管理其信用风险对其长期绩效至关重要;贷款损失导致的资本损耗是大多数机构失败的直接原因。区分和评级信用风险是有效管理它的首要步骤。如果用户很可能偿还贷款,则该申请人被视为良好的信用风险。反之,如果用户很可能不偿还贷款,则该申请人被视为不良信用风险。银行在做出是否批准其贷款申请的决定之前,需要分析申请人的个人统计和社会经济资料。
借助 Intel 优化计算软件包和 Intel® Xeon® Gold 6128 处理器,基于这些数据开发了一个更快的预测模型。该机器学习模型可帮助银行经理根据潜在申请人的资料,决定是否批准其贷款申请。
硬件详情
Intel® Xeon® Gold 6128 处理器的硬件配置如表 1 所示。
表 1. 硬件配置。
| 名称 | 描述 |
| 基于 Intel® Xeon® Gold 处理器的架构 | x86_64 |
| CPU 操作模式 | 32 位,64 位 |
| 字节顺序 | 小端 |
| CPU(s) | 24 |
| 在线 CPU 列表 | 0-23 |
| 每个核心的线程数 | 2 |
| 每个插槽的核数 | 6 |
| 插槽数 | 2 |
| NUMA 节点数 | 2 |
| 供应商 ID | Genuine Intel |
| CPU 系列 | 6 |
| 模型 | 85 |
| 型号名称 | Intel® Xeon® Gold 6128 处理器 3.40 GHz |
| 步进 | 4 |
| CPU MHz | 1199.960 |
| BogoMIPS | 6800.00 |
| 虚拟化类型 | VT-x |
| L1d 缓存 | 32K |
| L1i 缓存 | 32K |
| L2 缓存 | 1024K |
| L3 缓存 | 19712K |
| NUMA 节点 0 CPU(s) | 0-5,12-17 |
| NUMA 节点 1 CPU(s) | 6-11,18-23 |
软件配置
此用例的开发具有以下依赖项(表 2)。
表 2. 软件配置。
| 库 | 版本 |
| Anaconda* 附带 Intel 通道 | 4.3.21 |
| Intel® 针对 Python* 的优化 | 3.6.3 |
| 优化的 scikit-learn* | 0.19.0 |
| Intel® 针对 NumPy 的优化 | 1.13.3 |
数据集描述
原始数据集包含 1,000 条记录,具有 20 个分类和符号属性。每条记录代表一位向银行申请信用贷款的个人。根据属性集,每个人被归类为良好或不良信用风险。表 3 显示了数据集中属性的集合。
表 3. 数据集描述。
| 属性名称 | 属性描述 |
checking_status | 现有支票账户状态,以德国马克 (DM) 为单位 |
duration | 持续时间(月) |
credit_history | 信用历史(已获得的信贷、按时偿还、延迟、不良账户) |
purpose | 信贷用途(汽车、电视等) |
credit_amount | 信用贷款金额,以德国马克 (DM) 为单位 |
savings_status | 储蓄账户和债券状态,以德国马克为单位 |
employment | 当前就业状况(年数) |
installment_commitment | 分期付款占可支配收入的百分比 |
personal_status | 个人状况(已婚、单身等)和性别 |
other_parties | 其他债务人和担保人 |
residence_since | 现居住年限 |
property_magnitude | 财产(例如,房地产) |
age | 年龄(岁) |
other_payment_plans | 其他分期付款计划(银行、商店等) |
housing | 住房(租房、自有) |
existing_credits | 在此银行的现有信贷数量 |
job | 作业 |
num_dependents | 需要承担赡养义务的人数 |
own_telephone | 电话(有和无) |
foreign_worker | 外籍工人(有和无) |
类 | 良好信用或不良信用 |
Intel® Distribution for Python*、优化的 scikit-learn* 和 PyDAAL 模块
使用 Python 进行的机器学习和数据分析通过 Intel® Distribution for Python1 获得了强大的支持。Intel® Distribution for Python* 配备了 Intel 优化的计算软件包2,如 NumPy、SciPY、scikit-learn* 和 PyDAAL(一个免费软件包,实现了 Intel® Data Analytics Acceleration Library,即 Intel® DAAL 的 Python 绑定)3。
Scikit-learn 是一个常用的机器学习库,主要是因为它算法丰富。Intel DAAL 不仅仅是一组机器学习算法,它实现了完整的数据分析流程,包括数据加载、转换、过滤、分析和建模,涵盖经典的统计和机器学习技术以及先进的深度学习方法。Intel® Distribution for Python* 中包含的 scikit-learn 算法利用了 PyDAAL 的优势,将 scikit-learn 的性能提升到了新的水平。
解决方案设计
图 1 显示了解决方案设计的主要步骤。

下面对每个步骤进行详细解释。
数据集分析
任何预测建模任务中的首要部分是数据集分析,这无非是对数据进行的初步探索。数据集分析的目的是对数据有扎实的了解,从而得出更好的解决方案。收集有关数据的好信息也有助于特征工程和特征选择。使用图形进行数据可视化有助于我们理解属性之间的关系以及数据中的模式。
德国信用数据集4 包含 21 个特征,其中 14 个是分类变量,其余 7 个是数值变量。最后一列是标签,表示信用风险,只有两个可能的值:良好信用风险和不良信用风险。由于数据集中既包含分类变量又包含数值变量,因此提供了适当的统计和分布分析。
数值变量分析
表 4 显示了数据集中所有数值变量的摘要。它在输出中包括计数、平均值、标准差 (std)、最小值、四分位数和最大值。
表 4. 数值变量分析。

![]()
以下是一些得出的推论:
- 数据集中没有缺失值。所有列的计数均为 1,000,这意味着数据集中 1,000 行的每个属性都有值。
- 大多数信用贷款金额请求在 3,000DM-4,000DM 之间。
- 平均贷款持续时间约为 21 个月,平均年龄约为 36 岁。
分类变量分析


大多数信用贷款金额在 2,000DM-4,000DM 之间(图 2)。最高贷款金额高达 18,000DM。箱线图分析表明,较高的信用贷款金额大多对应于不良信用风险(图 3)。

电视、收音机或新车是大多数申请人寻求信贷的主要原因。很少有申请人为了教育或再培训而寻求信用贷款。这可能意味着教育和再培训不值得贷款,或者它们的成本已由学校、大学、政府或其他方式完全覆盖,这似乎不太可能。

图 5 中的信用贷款频率与年龄组的绘制显示,20 至 39 岁申请人的信贷需求约占总信贷需求的 2/3。
数据预处理
数据预处理包括在将数据输入算法之前对其进行的转换。由于数据集中大多数变量是分类变量,因此需要应用各种技术将分类变量转换为数值变量。
- 将二元分类数据转换为数值:在此步骤中,'yes' 或 'no' 列
own_telephone、foreign_worker(参考表 3)被转换为 1 和 0。 - 独热编码:此技术将每个具有 n 个可能值的分类特征转换为 n 个二元特征,其中只有一个是激活的。Python 中的 Pandas 包使用
get_dummies方法支持此功能。该函数之所以这样命名,是因为它创建了虚拟和指示列。德国信用数据中的以下列经过独热编码:checking_status, credit_history, savings_status, employment, personal_status, other_parties, job, housing, other_payment_plans, property_magnitude - 标签编码:将分类变量转换为数值的另一种方法是使用标签编码,它将列中的每个值转换为数值。数据中的
purpose列经过标签编码。优化的 scikit-learn* 具有预先构建的预处理功能,可通过 scikit-learn 预处理模块使用。
特征选择
数据集可能包含不相关或冗余的特征,这可能会使机器学习模型更加复杂。在此步骤中,我们旨在移除可能导致运行时间增加、生成复杂模式等的无关特征。生成的特征子集用于进一步分析。特征选择可以通过使用 Random Forest 或 Xgboost 算法来完成。在本实验中,使用 Xgboost 算法来选择分数高于预定义阈值的最佳特征。表 5 显示了一些按分数值排序的特征。
表 5. 特征重要性
| 功能 | 分数 |
credit_amount | 0.1724 |
duration | 0.1122 |
age | 0.1057 |
purpose | 0.0634 |
checking_status_no checking | 0.0423 |
installment_commitment | 0.0341 |
plan_none | 0.0309 |
employment_4<=X<7 | 0.0293 |
residence_since | 0.0260 |
credit_history_all paid | 0.0244 |
数据分割
分割训练和测试数据:然后将数据分割为训练集和测试集以供进一步分析。90% 的数据用于训练,10% 用于测试。scikit-learn 中的 train_test_split 函数用于数据分割。
分类器实现
使用两个软件包实现分类器:scikit-learn with Intel DAAL 和 PyDAAL。
scikit-learn with Intel DAAL
平衡数据集
数据集高度不平衡,70% 的数据包含良好信用风险。这种数据不平衡通过 SMOTE 算法进行处理,该算法生成新的 SMOTED 数据集来解决类别不平衡问题。它使用该类别元素的最近邻来人工生成少数类别的观测值,以平衡训练数据集。
模型构建和训练
多年来,研究人员和数据科学家创建了各种机器学习模型(算法)。在此阶段,选择机器学习模型进行训练。scikit-learn 中的所有分类器都使用 fit (X, y) 方法来拟合给定训练数据 X 和训练标签 y 的模型。为了比较各种模型的性能,使用了分类器集成。模型训练完成后,即可用于预测。
预测
在此阶段,训练好的模型根据其学习到的知识预测给定输入的输出。也就是说,给定一个未标记的观测值 X,predict (X) 返回预测标签 y。
评估版
为了衡量模型的性能,有各种性能评估指标可用。我们将准确率、精确率和召回率作为评估指标来选择该问题的最佳模型。
Intel DAAL 的 Python API - PyDAAL
PyDAAL 中的数据表示
直到步骤 4(数据分割)的所有预处理步骤对于 PyDAAL 实现都是相同的。DAAL 中的每个算法都接受 NumericTables 形式的输入,这是一种用于在内存中表示数据的通用数据类型。由于所有转换后的特征类型相同,我们使用了 HomogenNumericTables 进行表示。在 scikit-learn 中进行特征选择后获得的数据集是 NumPy ndarray 格式。可以使用 DAAL 数据管理模块5 中的内置函数轻松将其转换为 HomogenNumericTable。
模型构建和训练
创建一个算法对象,以适当的处理模式(批处理、在线和分布式)5 训练分类器。使用算法对象的 input.set 成员方法6 设置两个输入(即数据和标签)。此外,使用 compute() 方法更新部分模型。
预测
创建模型后,定义一个预测对象。分别使用 input.setTable() 和 input.setModel() 方法将测试数据集和训练模型传递给算法。使用 compute() 方法计算预测。
评估版
使用 compute() 方法找到预测后,计算模型的准确率、精确率、召回率和 F1 分数。
实验结果
由于问题是二元分类,除了准确率之外,还使用精确率、召回率和 F1 分数等评估指标来识别集成算法中的最佳分类器。根据性能评估指标,分类器分为最佳、良好和差。给出稳定准确率、精确率、召回率和 F1 分数值的分类器被归类为最佳分类器,而给出评估指标值高度变化的分类器则被归类为差分类器。
使用 scikit-learn with Intel DAAL
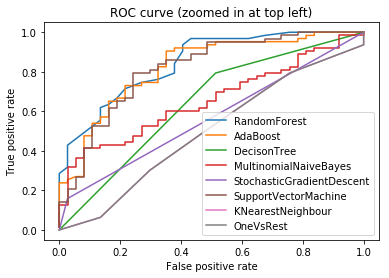
表 6 描绘了在平衡和不平衡数据集上使用各种分类器的结果。还给出了完整数据集和特征选择数据集的比较结果。所有特征都使用了数据预处理部分讨论的编码技术进行预处理。还为每个分类器绘制了接收者操作特征曲线(或 ROC 曲线)以分析分类器性能。曲线越接近 ROC 空间的左边界然后是顶部边界,则被认为是最佳分类器。图 6 显示了 scikit-learn with Intel® DAAL 中分类器的 ROC 曲线。ROC 曲线表明,随机森林分类器和 Ada Boost 分类器是最佳分类器。
表 6. scikit-learn* with Intel® DAAL 的实验结果。
| 分类器 | 不平衡完整训练数据 (%) | 不平衡特征选择数据 (%) | 平衡特征选择数据 (%) | |||||||||
| Acc. | 精度 | 召回率 | F1-score | Acc. | 精度 | 召回率 | F1-score | Acc. | 精度 | 召回率 | F1-score | |
| 最佳 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 随机森林 | 77 | 76 | 77 | 75 | 76 | 78 | 76 | 74 | 82 | 84 | 82 | 81 |
| Ada Boost | 77 | 77 | 77 | 77 | 74 | 74 | 74 | 73 | 81 | 81 | 81 | 81 |
| Good | ||||||||||||
| 决策树 | 69 | 71 | 69 | 70 | 66 | 65 | 66 | 65 | 68 | 67 | 68 | 67 |
| 支持向量机 | 79 | 79 | 79 | 77 | 73 | 71 | 73 | 71 | 71 | 74 | 71 | 71 |
| 高斯朴素贝叶斯 | 65 | 67 | 65 | 66 | 73 | 75 | 73 | 74 | 75 | 75 | 75 | 75 |
| 多项式朴素贝叶斯 | 60 | 61 | 60 | 60 | 62 | 63 | 62 | 63 | 61 | 61 | 61 | 61 |
| K 近邻 | 66 | 63 | 66 | 64 | 66 | 63 | 66 | 64 | 51 | 54 | 51 | 52 |
| 差 | ||||||||||||
| 随机梯度下降 | 70 | 49 | 70 | 58 | 70 | 49 | 70 | 58 | 46 | 72 | 46 | 38 |
| One Vs Rest | 70 | 49 | 70 | 58 | 70 | 49 | 70 | 58 | 65 | 78 | 65 | 53 |
使用 PyDAAL
表 7 给出使用 PyDAAL 算法进行的分类结果。
表 7. PyDAAL 的实验结果。
| 分类器 | 准确率 % | 精确率 % | 召回率 % | F1-score % | ||||||||
| 最佳 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 决策树 | 74 | 72 | 74 | 72 | ||||||||
| 支持向量机 | 65 | 79 | 71 | 75 | ||||||||
| Good | ||||||||||||
| 多项式朴素贝叶斯 | 62 | 64 | 62 | 63 | ||||||||
| 差 | ||||||||||||
| Ada Boost | 70 | 49 | 70 | 58 | ||||||||
观察
- 在 scikit-learn Intel DAAL 中,随机森林分类器和 Ada Boost 分类器被确定为给定问题的最佳分类器。
- 移除不相关特征后,分类器性能仅有小幅提升,但运行时间有显著缩短。
- 使用 SMOTE 算法平衡数据集为 scikit-learn 带来了更好的结果,而 PyDAAL 则没有改善。
- PyDAAL 足够通用,可以适应不同内存布局的数据。像 NumPy 这样的数据分析过程中使用的流行库可以轻松地与 Intel DAAL 接口,以创建数值表。
- PyDAAL 只支持少量机器学习算法,并且在决策树上获得了最高分数。
结论
Intel® Distribution for Python* 中包含的 scikit-learn 算法利用 PyDAAL 的优势,将 scikit-learn 的性能提升到了新的水平。与 PyDAAL 相比,它在机器学习算法方面也更为丰富。在 Intel® Xeon® Gold 6128 处理器上使用 Intel 优化性能库,帮助机器学习应用程序更快地进行预测。与 PyDAAL 算法相比,优化后的 scikit-learn 算法获得了更高的准确率。PyDAAL 主要处理数值表数据,这可以减小内存占用并实现高效处理。
关于作者
Nikhila Haridas 是 Intel® AI Academy Program 的技术咨询工程师。
参考文献
- Intel Distribution for Python
- Intel® Distribution for Python* 的 Intel 优化软件包
- PyDAAL
- 德国信用数据集
- DAAL:数据结构
- DAAL 编程指南
有关编译器优化的更完整信息,请参阅我们的优化声明。