
Python 单线程 vs 多线程 vs 多进程——蒙提霍尔问题
这是一个基于概率的模拟,它证明了“交换”被认为是最佳选择!我们还探讨了 Python 中多线程和多进程的影响。

引言
自 2015 年以来,由于工作和居住地的不断搬迁,我真的已经放弃了做任何软件或硬件/微控制器相关的事情。我需要重新投入其中。我真的不确定要做什么,但就是需要一些东西来再次激活我的大脑。
第一步是把我主要的开发电脑搞定。它的噪音快把我逼疯了,而且硬盘也满了。我下定决心组装一台新的水冷电脑,并给它取名“宁静号”(Serenity)。这给了我一些乐趣,因为我已经有一段时间没有升级我的电脑了,而增加水冷不仅帮助解决了噪音问题,还给了我一些可以摆弄的硬件。我写了一篇完整的装机日志,附有图片并进行了一些基准测试,你可以在这篇文章中读到相关内容。
然后,我在 YouTube 上闲逛时,偶然看到了一个讨论蒙提霍尔问题的视频,这是有人提交给Engineer Man频道的。他基本上只展示了这个程序的输出结果,但没有详细说明它是如何构建的等等。他在引言中对蒙提霍尔问题做了一个基本的解释。这两件事给了我足够的动力,于是我就开始动手了,然后就有了现在这篇文章。
手持Visual Studio Code,笔记本电脑上安装了Python,随时准备好使用谷歌……是时候开始了。
蒙提霍尔问题
你可以在维基百科上阅读更多相关内容,但简而言之如下:
你是一个游戏节目的参赛者,你必须从三个选项中选择一个,其中一个是奖品。主持人,也就是蒙提·霍尔,知道哪个选项是中奖的。一旦你(参赛者)选好了你的选项,主持人会向你展示另外两个选项中的一个,揭示它是输的那个。现在你可以选择坚持你最初的选择,或者换成最后一个未揭示的选项。
概率学表明,你应该总是交换,因为它有最高的获胜机会,为 66%。而如果你坚持最初的选择,你获胜的几率只有 33%。
我还决定用 Python 来写这个程序,因为我之前只接触过一次这门语言,而且那次基本上只是直接从一个例子中复制粘贴,用来通过树莓派读取一个温度传感器的数据,所以并不足以让我深入思考。Python 似乎是那种越来越流行的语言,并且越来越受欢迎。至少从我在网上看到它被提及的频率来看是这样的。
这本是计划的终点。然而,我开始研究程序的运行性能,这把我带入了多线程的领域,以及它在 Python 中一个令人惊讶的结果。这反过来又让我去研究多进程是如何融入并实现的。后者一开始真是个头疼的问题!
深入代码
当我第一次写完程序并让它工作时,我心里想‘太棒了!’。然后我想能够改变代码运行的轮数,并且希望能够关闭每轮的输出,以加快长时间运行的速度。这促使我增加了通过命令行输入来设置这些选项的附加功能,而不需要每次都去修改代码中的变量。
我们接下来要过一遍的,就是实现这个功能的代码——一个单线程的端到端程序。
我们需要做的第一件事是导入我们将需要其功能的各种库。
import argparse # argparse added to support command line parameter functionality
from random import randint, choice # used for selections
from timeit import default_timer as timer # used for timing the runs.
argparse 提供了处理和解析命令行参数的功能。要正确设置它有点复杂,我不得不搜索了几个不同的资源来找例子。正如我们稍后会看到的,我并没有做什么复杂的事情,但仍然遇到了一些问题才让它正常工作。
你也可以看到,对于 default_timer,我们还给它起了一个别名 timer。
接下来,我们将为程序设置几个带有默认值的变量。即,我们将运行多少轮,以及我们是否将显示单轮的输出。
numberOfRounds = 1000 # Set default for number of rounds
roundOutput = False # Set default for display of individual round output
下一部分涉及通过配置 argparse 如何处理各种参数来处理命令行参数。
# Setup the argparse
parser = argparse.ArgumentParser(prog="montyhallsim",
description='''Monty Hall Simulation. This is a basic Monty Hall Simulation,
the program will run for a given number of rounds
and display the number of wins for the different methods (stick/random/swap).''',
epilog='''For more information on the Monty Hall paradox, visit; \n
https://en.wikipedia.org/wiki/Monty_Hall_problem''')
# Sdd argument for displaying the round output.
parser.add_argument("-o", "--output", action="store_true",
help="Display individual round output. Default is hidden.")
parser.add_argument("-r", "--rounds", nargs=1, type=int, default=1000,
help="Set the number of rounds. Integer. Default is 1000.")
args = parser.parse_args()
if args.output:
roundOutput=True
if args.rounds:
if type(args.rounds) is int: # If not supplied on cli, defaults value returns int type
numberOfRounds = args.rounds
elif type(args.rounds) is list: # If supplied on cli, it returns a list of int, need 1st one.
numberOfRounds = args.rounds[0]
if numberOfRounds == 0: # Prevent user providing 0 as a number
numberOfRounds = 1
第一部分声明了一个变量 parser,它是 argparse 的实例,然后设置了一些参数,包含将呈现给用户的关于程序的信息。
参数被添加进来,你可以看到短格式和长格式都可以设置,例如 -o 和 --output。在这个例子中,对于 --output,定义了一个动作,如果指定了它,就将参数设置为一个 true 值。
然后,使用 args 集合对各种参数应用逻辑,以确定程序应如何响应用户的命令行输入。
一个值得注意的有趣之处是,--rounds 参数值的类型会根据它是被提供还是自动默认而改变。如果它是默认的,它是一个 int 类型;如果它是被提供的,它是一个 list 类型,所以你需要相应地进行测试。
我们需要一个地方来存储每一轮(round)的结果,以及模拟的最终结果(results),为此声明了两个变量,round 将在每次迭代中被重用。
# current round array contains, [RoundNumber, WinningNumber, ParticipantPick,
HostShow, ResultStick, ResultRandom, ResultSwap]
round = [0,0,0,0,False,False,False]
# count of wins for each strategy, stick, random, swap
results = [0,0,0]
最后一部分真正的设置是与执行时间测定相关的变量。我们声明了两个变量来保存开始和结束时间。
# Timings for Run
startTime = timer()
finishTime = timer()
现在我们差不多准备好开始执行一次运行了,在我们能真正触发运行之前,我们定义了构成主执行循环的各种方法。
第一部分是 main() 方法。在这里,我们使用一些基本的 print() 语句生成一些输出来告诉用户我们正在做什么。我们检查用户是否要求查看单轮输出,如果是,则打印标题,以便他们知道该轮输出的内容是什么意思。这是一个对在开始时声明并通过命令行设置的 roundOutput 变量的简单 if 测试。接下来,我们进入一个 for 循环,该循环重复直到达到 numberOfRounds 的 range。这个变量也是在开始时声明的,如果需要,可以通过命令行设置。在每次迭代中调用 runRound() 方法。
循环完成后,输出会打印出各轮的结果,并计算运行时间,然后程序退出。
def main():
# Initialise current round by setting up the winning number
print("Monty Hall Simulator, 3 boxes.")
print("Number of Rounds: " + str(numberOfRounds))
if roundOutput == True:
print("RoundNumber, WinningNumber, ParticipantPick, HostShow, ResultStick, ResultRandom, ResultSwap")
for round[0] in range(numberOfRounds):
runRound()
else:
finsihTime = timer()
duration = finishTime - startTime
print("Results for Number of Rounds: " + str(numberOfRounds))
print("============================================================")
print("Duration, " + str(duration) + " seconds.")
print("Stick = " + str(results[0]) + " : " + str((float(results[0]) / numberOfRounds) * 100) + " %")
print("Random = " + str(results[1]) + " : " + str((float(results[1]) / numberOfRounds) * 100) + " %")
print("Swap = " + str(results[2]) + " : " + str((float(results[2]) / numberOfRounds) * 100) + " %")
在 main() 方法的循环中,我们调用了 doRound() 方法。这个方法开始了执行与单轮相关的逻辑过程。第一部分是随机选择获胜的箱子,以及由参与者进行随机选择。之后,它调用该轮的下一阶段,即 hostPick() 函数。
def runRound():
# Increment Round Number
round[0] += 1
# Select the rounds winning box, random choice
round[1] = randint(1,3)
# Select the participant random choice
round[2] = randint(1,3)
# Host does their reveal next.
hostPick()
由于主持人知道参与者选择了什么,也知道获胜的数字在哪里,所以通过一些基本逻辑,主持人决定向参与者展示哪个选项。这当然是一个没有奖品的箱子。然后该方法调用下一个 participantChoiceResult(),在这里参与者做出最终的轮次选择,并确定本轮的结果。
def hostPick():
#host compares winning box with participant choice and shows a losing box
# 1st Case, Participant has chosen the right box
if round[1] == round[2]:
if round[1] == 1:
round[3] = choice([2,3]) #Participant Pick 1, Host Show 2 or 3
if round[1] == 2:
round[3] = choice([1,3]) #Participant Pick 2, Host Show 1 or 3
if round[1] == 3:
round[3] = choice([1,2]) #Participant Pick 3, Host Show 1 or 2
# 2nd Case, Participant has chosen the wrong box
if round[1] <> round[2]:
if round[1] == 1 and round[2] == 2:
round[3] = 3 #Participant Picked 1, correct is 2, Host Show 3
if round[1] == 1 and round[2] == 3:
round[3] = 2 #Participant Picked 1, correct is 3, Host Show 2
if round[1] == 2 and round[2] == 1:
round[3] = 3 #Participant Picked 2, correct is 1, Host Show 3
if round[1] == 2 and round[2] == 3:
round[3] = 1 #Participant Picked 2, correct is 3, Host Show 3
if round[1] == 3 and round[2] == 1:
round[3] = 2 #Participant Picked 3, correct is 1, Host Show 2
if round[1] == 3 and round[2] == 2:
round[3] = 1 #Participant Picked 3, correct is 2, Host Show 1
#Participant has their 2nd choice next
participantChoiceResult()
在主持人向参与者展示了他的选项之后,参与者现在做出最终选择,即他们是坚持自己最初的选择,还是换成最后一个未揭示的箱子。现在,在代码中,我还添加了另一个选项,即参与者无法决定是坚持还是交换,于是从两个有效选项中随机选择一个。在每次检查中,任何获胜都会被记录到 results 数组中。最后,如果设置了 roundOutput 标志,那么这也会被打印出来。
def participantChoiceResult():
# 1st Case Participant Sticks
if round[1] == round[2]:
round[4] = True
results[0] += 1 # Increment Win count
else:
round[4] = False
# 2nd Case Participant Picks Random box from remaining 2
if round[3] == 1:
if choice([2,3]) == round[1]:
round[5] = True
results[1] += 1 # Increment Win count
else:
round[5] = False
if round[3] == 2:
if choice([1,3]) == round[2]:
round[5] = True
results[1] += 1 # Increment Win count
else:
round[5] = False
if round[3] == 3:
if choice([1,2]) == round[2]:
round[5] = True
results[1] += 1 # Increment Win count
else:
round[5] = False
# 3rd Case Participant Swaps box
if round[2] == round[1]:
#If Participant had originally picked winning number, then loses.
round[6] = False
else:
round[6] = True
results[2] += 1 # Increment win count
#Show round output
if roundOutput == True:
printRoundOutput()
下面的方法是用来打印每轮输出的。
def printRoundOutput():
# Display the ouptut for the current round
print(str(round[0]) + ":" + str(round[1]) + ":" + str(round[2]) + ":" +
str(round[3]) + ":" + str(round[4]) + ":" + str(round[5]) + ":" + str(round[6]))
定义了所有必要的方法后,现在就可以通过调用 main() 方法来真正启动一切了。
# Let's Go!
main()
执行与输出
打开一个命令提示符,执行以下不带参数的命令,你将得到默认输出,即 1000 轮且没有单轮输出。
python montyhallsim.py

下一个例子指定用户希望看到输出,并使用命令行将轮数设置为 10。
python montyhallsim.py --output --rounds 10

如果你还记得,我们在开始的 argparse 定义中添加了一些其他的 description 和 epilog 参数。当用户使用 --help 选项请求帮助时,可以看到这些信息。
python montyhallsim.py --help

结果
从这两个例子中可以看出,对于默认的 1000 轮和 10 轮,从概率的角度来看,交换是正确的选择。如果我们将轮数扩大到 1,000,000 轮,输出结果是:
Results for Number of Rounds: 1000000
=====================================
Duration, 4.97863848097 seconds.
Stick = 332312 : 33.2312 %
Random = 499819 : 49.9819 %
Swap = 667688 : 66.7688 %
所以,看起来**交换**绝对是明智之举!
等等,性能怎么样?
啊,好问题!在我的笔记本电脑(Intel Core i7-5600U @ 2.6GHz)上运行 1,000,000 轮,执行时间不到 5 秒(你可以在上面的结果中看到时间)。然而,这个程序只在单线程中执行。我笔记本电脑的 CPU 是 2 核/4 线程的。如果我运行 10,000,000 轮并截取 CPU 性能快照,你可以看到负载似乎分布在 4 个 CPU 上,平均总负载为 35%,持续时间为 49.9470172114 秒。

所以问题必然是,我们能把程序转换成多线程,并利用所有 4 个线程的优势吗?
切换到多线程
切换到多线程需要对代码进行一些更改,不仅在于我们如何设置线程,还在于公共变量如何在线程之间共享。下面我们边过代码边展示更改的概要。
首先是通常的对任何库依赖的添加。
import threading # Required for multi-threading
import multiprocessing # Required to get CPU max logical cores.
增加一个新变量来存放我们将限制自己使用的线程数。这默认设置为系统通过调用多进程库报告的逻辑处理器数量。
threadLimit = multiprocessing.cpu_count() # Set default number of threads.
与其将自己限制在固定数量的线程上,不如通过向我们的命令行处理中添加一个新参数 --threads,来提供调整所用线程数的能力。这个参数将默认为先前确定的 threadLimit。
parser.add_argument("-t", "--threads", nargs=1, type=int, default=threadLimit,
help="Set the number of threads. Integer. Default is CPU Logical Cores."+ str(threadLimit))
命令行参数也将用于调整前面声明的 threadLimit 变量。进行了一次检查以防止用户将线程数设置为 0。
if args.threads:
if type(args.threads) is int: # If not supplied on cli, defaults value returns int type
threadLimit = args.threads
elif type(args.threads) is list: # If supplied on cli, it returns a list of int, need 1st one.
threadLimit = args.threads[0]
if threadLimit == 0: # Prevent user providing 0 as a number
threadLimit = 1
为防止线程试图同时访问一个公共资源,需要线程锁定机制。我们需要 3 种不同的锁,一个用于轮次计数器,一个用于结果变量,还有一个用于输出。还添加了一个变量 threads[] 来存储线程集合。
# Threads collection
threads = []
# Current Round Number
currentRound = 0
currentRoundLock = threading.Lock() # Each Thread needs to acquire this lock
for updating the currentRound counter.
# Output Print Lock
outputLock = threading.Lock() # Each Thread needs to acquire this lock for printing output,
helps keeping alignment of text.
# count of wins for each strategy, stick, random, swap
results = [0,0,0]
resultsLock = threading.Lock() #Each Thread needs to acquire this lock for updating results.
在 main() 函数中,现在创建线程并将其添加到 threads[] 集合中,注意 target 参数,它包含了线程应该执行的函数名 runRound。线程也被赋予了一个简单的名称,这个名称可以显示在输出中,这样你就可以看到哪个线程执行了哪一轮。然后线程被启动。程序现在会等待所有线程返回,通过在每个线程上使用 join 方法,然后正常结束。
# Register the threads upto the thread limit
for t in range(threadLimit):
newThread = threading.Thread(target=runRound, name="t"+str(t))
threads.append(newThread)
for t in threads:
t.start()
for t in threads:
t.join()
runRound 函数需要被修改以支持多线程。
当函数首次被调用时,它会检查当前轮次是否小于目标轮次数量。然后获取 currentRound 变量的锁,并再次进行检查,因为在第一次检查和获取锁之间,其他线程可能已经增加了 currentRound 变量的值。
如果仍有工作要做,则函数继续。一旦 round[0] 的值被设置为 currentRound 的值,我们就不再需要线程锁了,所以释放它。如果没有更多的工作要做,那么我们释放已获取的锁,然后直接跳出函数。
这是我曾把自己搞糊涂并因竞态条件导致程序锁死的一个地方,else 之后的 release() 是解决问题的关键。
def runRound():
global currentRound
while currentRound < numberOfRounds:
currentRoundLock.acquire()
if currentRound < numberOfRounds:
currentRound += 1
# current round array contains, [RoundNumber, WinningNumber, ParticipantPick,
HostShow, ResultStick, ResultRandom, ResultSwap]
round = [0,0,0,0,False,False,False]
# Increment Round Number
round[0] = currentRound
currentRoundLock.release()
# Select the rounds winning box, random choice
round[1] = randint(1,3)
# Select the participant random choice
round[2] = randint(1,3)
# Host does their reveal next.
hostPick(round)
else:
currentRoundLock.release()
在修改后的函数中,还有另外两件事需要注意。第一件是,我们已经将 round[] 数据从一个全局变量移到了线程内部,这是因为每个线程都需要它自己的副本。我们还将这个变量传递给下一个被调用的函数,以便线程继续使用同一个变量。另一件需要注意的是,在函数开始处添加了 global currentRound 语句。解析器不喜欢这个变量被 while 语句使用,并报告它是一个问题,即它没有被定义,使用 global 关键字告知该变量是全局级别的。
其他需要的更改是在每个函数中处理传入的轮次数据,以及处理结果。为了最小化结果变量的锁定时长,所有逻辑首先被应用并更新到轮次数据中,然后在增加结果时才获取锁。
函数处理记录数据传递的典型更改
def hostPick(roundData):
#host compares winning box with participant choice and shows a losing box
round = roundData
...
结果更新从核心逻辑中剥离并独立出来
# Now update results if required, first acquiring lock object
if round[4] or round[5] or round[6]:
resultsLock.acquire()
if round[4]:
results[0] += 1
if round[5]:
results[1] += 1
if round[6]:
results[2] += 1
resultsLock.release()
如果我们现在用 4 个线程运行代码并显示 10 轮的输出,你可以看到每个线程名出现在轮次数据的末尾。
python monty_hall_threaded_test.py --threads 4 --rounds 10 --output
Monty Hall Simulator
Number of Rounds: 10
Number of threads: 4
RoundNumber, WinningNumber, ParticipantPick, HostShow, ResultStick, ResultRandom, ResultSwap, Thread
1:3:1:2:False:False:True:t0
2:3:3:2:True:False:False:t1
3:1:3:2:False:False:True:t0
4:3:1:2:False:True:True:t2
5:2:3:1:False:True:True:t3
6:3:3:1:True:False:False:t1
7:2:3:1:False:True:True:t0
8:2:1:3:False:True:True:t2
9:3:1:2:False:False:True:t3
10:2:3:1:False:False:True:t1
Results for 10 rounds using 4 threads.
============================================================
Duration, 0.0241714037581 seconds.
Stick = 2 : 20.0 %
Random = 4 : 40.0 %
Swap = 8 : 80.0 %
你可以从上面看到,t0 完成了 3 轮,t1 3 轮,而 t2 和 t3 各完成了 2 轮。
太棒了,我们现在有了一个可以工作的多线程代码库。
多线程性能
我们将用 1、2、4、8 和 128 个线程多次运行程序,每轮 1,000,000 次,看看我们得到了什么结果。
Threads | Time (seconds)
------------------------
1 | 6.04301673772
2 | 31.2029141007
4 | 38.0319919469
8 | 38.4018383862
128 | 38.6696277436
等等! 随着线程数的增加,这些持续时间变得越来越糟了。你还会注意到,基本上在 4 个线程之后,就没有什么真正的变化了。而且,在 1 个线程上的情况比最初只为单线程编写而没有内置线程能力的应用还要差。
这突显了在编写任何程序时你必须考虑的关键因素,基本上就是瓶颈在哪里。在这里,我们正在进行一项 CPU 密集型活动。在 Python 中,线程处理对 I/O 约束有好处。正如线程模块的文档中所述,“由于全局解释器锁(Global Interpreter Lock),一次只有一个线程可以执行 Python 代码”。如果我们查看使用逻辑处理器数量(本例中为 4)运行时 CPU 的使用情况,就可以看到这一点。

CPU 利用率没有超过 50%。单线程版本比使用 1 个线程运行的线程版本快,这个事实可能可以通过频繁获取和释放锁带来的额外开销来解释。
那么对于这种 CPU 密集型活动,我们能做些什么来提高性能呢?嗯,Python 文档的线程模块中也告诉我们,多进程也许是可行之道。
转向多进程
当我查看多进程模块的文档,以及网上的一些基本示例时,它看起来相当简单,你基本上把线程换成进程就行了。嗯,这与事实相去甚远!首先要意识到的是多进程是如何创建和数据是如何共享的。没有状态信息会被复制过去,所以你需要首先考虑如何协调对共享数据的访问。
这里事情就变得有点伤脑筋了,我根据多进程模块中的文档尝试了各种方法,并在我的代码不工作时搜索了各种例子。这一切变得有点沉重,我的头真的开始疼了。感觉就像在原地打转,所有基本的例子都解决不了问题,而所有复杂的例子又太过火了。
最后,我决定使用**进程池(Pool)**的方法,这显示出了希望。然后偶然发现并加入了**偏函数(Partial)**的使用,这进一步有所帮助。最后又加入了**初始化器(Initializer)**和一个**队列(Queue)**。然后,砰!一切都完美地工作了。
这一切都是通过将遇到的问题分解成小块并逐步构建而实现的。
- 如何在进程池中实现多进程
- 如何向进程池中的进程输入多个参数并从中获取结果
- 如何将额外的标志传入进程
- 如何同步来自各进程的打印语句
考虑到 Python 生成子进程的方式,区分哪些代码只在主进程中运行至关重要,这样它就不会在子进程中被执行。这是通过一个简单的 If 语句实现的,只包裹 main 代码;
if __name__ == "__main__":
# main process only code
在此范围内,我们做了常规工作,设置默认值等,并初始化 argparse。我添加了一个与线程版本类似的附加参数,但这次是用于设置进程限制;
parser.add_argument("-p", "--procs", nargs=1, type=int, default=processLimit,
help="Set the number of processes. Integer. Default is CPU Logical Cores. " + str(processLimit))
if args.procs:
if type(args.procs) is int: # If not supplied on cli, defaults value returns int type
processLimit = args.procs
elif type(args.procs) is list: # If supplied on cli, it returns a list of int, need 1st one.
processLimit = args.procs[0]
if processLimit == 0: # Prevent user providing 0 as a number
processLimit = 1
我使用的方法与之前的版本略有不同,每一轮都会返回其自己的结果副本,而不是所有轮次都使用一个共同的共享数组。在所有进程完成后,结果将被聚合回一个单一的结果数组中。这被定义为一个简单的数组。
# count of wins for each strategy, stick, random, swap,
finalResults = [0,0,0]
稍后你会看到它是如何被使用的。
接下来是定义**队列(Queue)**。如果命令行上设置了 --output 标志,它将处理任何单轮输出的打印。当我最初在单轮中执行 print() 语句时,所有进程都打印到同一个控制台,导致所有输出都混杂在一起。现在,每个进程会将输出文本推送到队列中,而主进程将是那个把它从队列中卸载并打印到控制台的进程。
# Global queue for passing print output from pool processes to main for display
outputQ = multiprocessing.Queue()
如前所述,我使用了一个**偏函数(Partial)**。这是一种将多个变量传递给进程池的 map 函数的方法。
# Variable for passing multiple arguments to the process.map
target = partial(processRound, output=roundOutput)
processRound 是进程池在每个子进程中执行的函数,而 roundOutput 是一个标志,用来表示该轮是否应该打印其独立数据。后者是固定的,不会改变。
现在我们可以创建**进程池(Pool)**并让子进程开始工作了。
# Setup the pool and initiate the work
p = multiprocessing.Pool(processLimit, initializer=initProc, initargs=(outputQ, ))
results = p.map(target, range(numberOfRounds))
进程池的第一个参数是一个数字,用于指定创建进程数量的上限。initialize 参数指定一个在初始化进程时运行的函数。initargs 参数指定将传递给初始化函数的变量。在这种情况下,它是用于输出消息的队列的引用。
results 是一个包含所有进程结果的数组。在这种情况下,每一轮都会返回一个数组,其中包含“坚持、随机、交换”是否获胜。[0,0,1],其中 0 代表输,1 代表赢。
p.map 被传入先前定义的偏函数,以及要被子进程分发和处理的数据的细节,在这种情况下,是一个从 0 到 numberOfRounds 的范围。
results = p.map() 实际上是一个 map/reduce 函数。
现在子进程已经启动并运行了。如果我们设置了输出标志,我们需要从队列中取出这些消息并打印到输出。这是一个循环,它会检查队列是否为空以及进程池是否还有子进程。它不断循环,从队列中获取消息并打印它们。
# Check if we have child processes in the pool and the shared queue is not empty
# print the queue to the standard output.
while not (outputQ.empty() and (p._pool.count > 0)):
print(outputQ.get_nowait())
工作完成后,我们必须关闭进程池并将其重新合并。
p.close()
p.join()
所有结果都存放在结果数组中,我们需要将它们聚合成最终结果。
来自 map 函数的结果会像这样 [[0,1,0],[1,1,0],[1,0,0],...]。为了聚合,运行一个循环并递增最终结果的计数。对于上面的例子,最终结果会是 [2,2,0]。
# Aggregate results from pool results.
for result in results:
finalResults[0] += result[0]
finalResults[1] += result[1]
finalResults[2] += result[2]
加入相同的计时器和结果输出打印,这就完成了主进程中的需求。
所有其他函数都在代码的前面定义。其中一个是初始化器(Initializer),它接收 outputQ 并为子进程创建全局引用。
def initProc(outQ):
# Used by the process pool to initialize the shared global queue on the child processes
global outputQ # The shared queue
outputQ = outQ
当轮次处理被启动时,现在需要做一些其他的改动。
首先,我们现在传入要处理的 currentRound 以及是否应该打印 output。每一轮现在将持有自己的轮次数组,包含确定结果所需的所有数据。这个数组会在函数链中向下传递,每个函数完成其部分工作并相应更新轮次数组。
每一轮也有自己的结果数组,这个数组也沿着调用链向下传递,在链的末尾,结果检查会填充结果数组,并将其一直返回到栈顶,交还给 map 的结果集。
如果我们看一下 runRound 函数,你可以看到这一点
def processRound(currentRound, output):
# Local Round Data
round = [0,0,0,0,False,False,False] #
[RoundNumber, WinningNumber, ParticipantPick, HostShow, ResultStick, ResultRandom, ResultSwap]
result = [0,0,0] # [stick, random, swap]
# store the round number
round[0] = currentRound
# Select the rounds winning box, random choice
round[1] = randint(1,3)
# Select the participant random choice
round[2] = randint(1,3)
# Host does their reveal next. pass on the local data
hostPick(round, output, result)
# Pass result back to caller
return result
栈中的最后一个函数不仅计算结果,还决定是否需要打印该轮的数据。如果需要,它会调用必要的 printRoundOutput 函数。这个函数然后使用之前引用的全局队列,并将输出推送到队列中。
def printRoundOutput(round):
# Place the output text for the current round onto the shared queue.
text = str(round[0]) + ":" + str(round[1]) + ":" + str(round[2]) + ":" +
str(round[3]) + ":" + str(round[4]) + ":" + str(round[5]) + ":" + str(round[6]) + ":" +
multiprocessing.current_process().name
outputQ.put(text)
太棒了!我们现在有了一个多进程版本的蒙提霍尔问题程序。
多进程性能
为了进行比较,让我们运行同样的 1,000,000 轮,使用与线程版本相同的 1、2、4、8、128 个进程,并与单线程版本进行比较。
Process | Time (seconds) Threads | Time (seconds) Single Thread Version (seconds)
------------------------ -------------------------- -------------------------------
1 | 7.84796339471 1 | 6.04301673772 4.9596014663
2 | 5.13545195655 2 | 31.2029141007
4 | 4.09028748777 4 | 38.0319919469
8 | 4.19029514611 8 | 38.4018383862
128 | 9.12885394124 128 | 38.6696277436
很好,利用全部 4 个逻辑核心来运行 1,000,000 轮,速度快了大约 18%。
我们可以忽略线程版本,因为它显然不适用于这类问题。如果我们将工作量增加到 10,000,000 轮,并比较单线程与多进程,结果就不那么令人印象深刻了。49.5728323937 秒对 45.8644244836 秒。
虽然改进不大,但终究是改进。所做工作的类型以及如何分配显然是关键。也许如果采用分发数据并运行独立进程而不是使用进程池的方法,可能还会带来进一步的改进,特别是在没有池化等额外开销的情况下。
你还可以看到,当你超过逻辑 CPU 数量(本例中为 4)时,性能也开始下降。这是预料之中的,因为你现在必须开始尝试将那些额外的进程分配到那些已经在全力工作的核心上。
然而,我们可以清楚地看到,CPU 现在被 100% 利用了,而这正是我们从单线程转向多进程所要达到的目标。
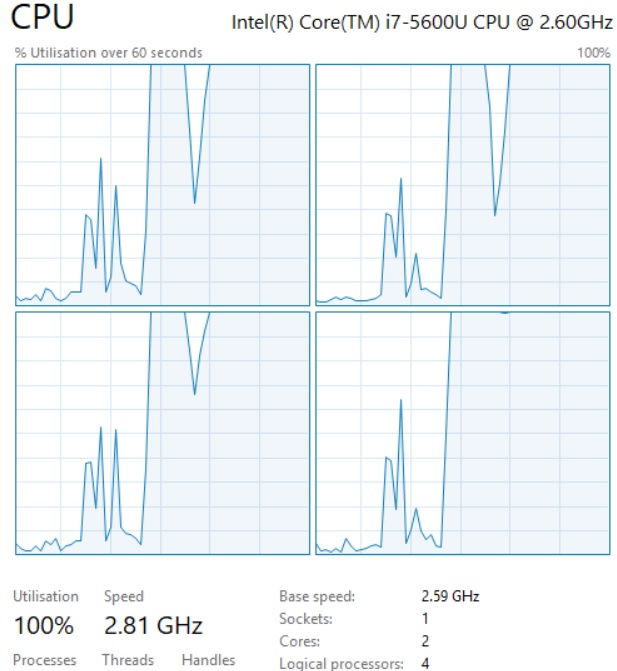
接下来呢?性能一定还能变得更好……也许可以留到以后再来探索不同的多进程选项。
2018年10月11日更新:在“宁静号”上运行
上述文章的主要内容都是在我的笔记本电脑上开发和运行的。当时我正在外地工作,所以手头只有这些。现在回到家,我有机会在我最近组装的新电脑上运行代码。你可以在这里读到相关信息。
“宁静号”(Serenity)是一台搭载 Intel i9-7920x 的电脑,拥有 12 核/24 线程,这比笔记本电脑的 CPU 要强得多!
我用全部 24 个线程运行了多进程版本的代码,同样是 1,000,000 轮。笔记本电脑完成这项任务的最佳时间是 **4.09028748777** 秒。从上面的截图中你也可以看到,这完全耗尽了笔记本电脑的 CPU,达到了 100%。
那么“宁静号”表现如何呢?它在 **1.5631458167** 秒内完成了相同的任务。相比之下,它快得让 CPU 甚至没有时间完全加速到睿频速度。如果你看 CPU 图表,会发现每个线程上都有一个短暂的峰值。可以肯定地说,CPU 根本没感觉到什么压力!

好吧,那如果我们把它提升到下一个比较级别,即 10,000,000 轮,会发生什么呢?笔记本电脑能达到的最快速度是 **45.8644244836** 秒,而“宁静号”则在 **16.0187814005** 秒内完成了同样的任务。同样,从下面可以看出,CPU 基本上没有太多负载,只有最初的峰值,然后在运行期间趋于稳定。

结论
所以,我们就是这样,从一个单一的算法问题出发,探索了从单线程、多线程到多进程的整个过程。
由于之前没有真正关注过 Python,这对我自己来说更多的是一次学习。可能还有很多可以改进的地方,很多不好的设计选择,缺乏标准/最佳实践的使用等等,但不管那些,这都是一次经历。转向多进程的过程真的比我最初从阅读文档时预期的要困难得多。
我可能会在以后再回来重新审视这个问题。我相信多进程方法的性能可以进一步提高。也许你可以把这个当作一个课题去探索,当然,也欢迎与我们所有人分享你的发现和知识,让我们共同学习。
参考文献
历史
- 2018年10月11日 - 添加了在“宁静号”上的测试运行
- 2018年9月13日 - 首次发布