
加速 ASP.NET Core WEB API 应用程序。第 2 部分
4.97/5 (33投票s)
使用多种方法提高 ASP.NET Core WEB API 应用程序的生产力
引言
- 第 1 部分。创建一个测试用的 RESTful WEB API 应用程序
- 第 2 部分。提高 ASP.NET Core WEB API 应用程序的生产力
- 第 3 部分。对 ASP.NET Core WEB API 应用程序代码进行深度重构和优化
在第 2 部分,我们将回顾以下内容
- 应用程序生产力
- 异步设计模式
- 数据规范化与 SQL 查询效率
- NCHAR 与 NVARCHAR 数据类型
- 使用 MSSQL 服务器的全文搜索引擎
- 存储过程
- 优化存储过程
- 预编译和重用存储过程执行计划
- 将 Entity Framework Core 与全文搜索结合使用
- Entity Framework Core 性能
- 对 Prices 表进行全文搜索
- 对数值进行全文搜索
- 更改计算列公式
- 缓存数据处理结果
- Redis 缓存
- 在 Windows 上安装 Redis
- Redis 桌面管理器
- Redis NuGet 包
- 缓存过期控制
- 在何处应用缓存?
- 缓存实现
- 提前准备数据的概念
- 提前准备数据的实现
- 思考微服务架构
- 为价格准备创建 API
- HttpClient 的问题
- 使用 HttpClientFactory 管理 HttpClient
应用程序生产力
可以采取一些步骤来提高我们应用程序的生产力
- 异步设计模式
- 反规范化数据
- 全文搜索
- 优化 Entity Framework Core
- 缓存数据处理结果
- 提前准备数据
异步设计模式
异步工作是提高我们应用程序生产力的第一步。
异步设计模式已在第 1 部分中实现。它需要一些额外的编码,并且通常比同步模式工作得稍慢,因为它需要系统进行一定的后台活动来提供异步性。因此,在没有长时间 I/O 操作的小型应用程序中,异步工作甚至可能降低应用程序性能。
但在高负载的应用程序中,异步可以通过更有效地使用资源来提高其生产力和弹性。让我们观察一下 ASP.NET Core 中是如何处理请求的
每个请求都在一个从线程池中取出的独立线程中处理。如果同步工作并发生长时间的 I/O 操作,该线程会一直等待直到操作结束,然后在操作完成后返回线程池。但在等待期间,该线程被阻塞,无法被其他请求使用。因此,对于一个新的请求,如果在线程池中找不到可用线程,将创建一个新线程来处理该请求。创建新线程需要时间,并且每个被阻塞的线程都有一部分内存被分配给它并被阻塞。在高负载的应用程序中,大量创建线程和阻塞内存可能导致资源不足,从而显著降低应用程序和整个系统的生产力。它甚至可能导致应用程序崩溃。
但如果异步工作,I/O 操作开始后,处理该操作的线程就会返回线程池,并可用于处理另一个请求。
因此,异步设计模式通过更有效地使用资源来增加应用程序的可伸缩性,从而使应用程序更快、更有弹性。
数据规范化与 SQL 查询效率
您可能已经注意到,SpeedUpCoreAPIExampleDB 数据库结构几乎完全符合预期的输出结果。这意味着从数据库中获取数据并发送给用户不需要任何数据转换,从而提供了最快的结果。我们通过对 Prices 表进行反规范化,并使用供应商名称而不是供应商 ID 来实现了这一点。
我们当前的数据库结构是

可以通过一个请求获取价格表中的所有价格
SELECT PriceId, ProductId, Value, Supplier FROM Prices
执行计划如下

我们的数据库结构在完全规范化的情况下会是什么样子?

但在一个完全规范化的数据库中,Prices 和 Suppliers 表需要在 SQL 查询中进行连接,查询可能会是这样
SELECT Prices.PriceId, Prices.ProductId, Prices.Value, Suppliers.Name AS Supplier
FROM Prices INNER JOIN
Suppliers ON Prices.SupplierId = Suppliers.SupplierId
执行计划如下

第一个查询显然要快得多,因为 Prices 表已经为读取进行了优化。但对于完全规范化的数据模型来说,情况并非如此,该模型为存储复杂对象而优化,而不是为了快速读取。因此,对于完全规范化的数据,我们可能会遇到 SQL 查询效率的问题。
并且请注意,Prices 表不仅为读取进行了优化,也为数据填充进行了优化。例如,现在很多价格表都是通过 Excel 文件或 .csv 文件提供的,这些文件可以轻松地从 Excel、任何 MS SQL 表或视图以及其他来源获得。通常,这类文件有以下几列:Code;SKU;Product;Supplier;Price;其中 Supplier 是名称,而不是代码。如果文件中的 Code 值对应于 Products 表中的 ProductId,那么用这样包含数百万条记录的文件填充 Prices 表,只需一行 T-SQL 代码,几秒钟即可完成
EXEC('BULK INSERT Prices FROM ''' + @CsvSourceFileName + ''' WITH _
( FORMATFILE = ''' + @FormatFileName + ''')');
当然,反规范化是有代价的——数据冗余以及需要解决 Prices 和 Suppliers 表中数据一致性的问题。但如果目标是生产力,这是值得的。
注意! 在第 1 部分的末尾,我们测试了 DELETE API。您的数据可能与我们的示例不同。如果是这样,请使用第 1 部分中的脚本重新创建数据库。
NCHAR 与 NVARCHAR
在我们的数据库中,所有的 string 字段都使用了 NCHAR 数据类型,这显然不是最佳方案。事实是,NCHAR 是一种定长数据类型。这意味着 SQL Server 会为每个字段保留一个固定大小(我们为字段声明的大小)的空间,而不管字段内容的实际长度如何。例如,Prices 表中的 “Supplier” 字段声明为
[Supplier] NCHAR (50) NOT NULL
这就是为什么当我们从 Prices 表接收价格时,结果看起来像这样
[
{
"PriceId": 7,
"ProductId": 3,
"Value": 160.00,
"Supplier": "Bosch "
},
{
"PriceId": 8,
"ProductId": 3,
"Value": 165.00,
"Supplier": "LG "
},
{
"PriceId": 9,
"ProductId": 3,
"Value": 170.00,
"Supplier": "Garmin "
}
]
为了去除 Suppliers 值中的尾随空格,我们不得不在 PricesService 中应用 Trim() 方法。对于 ProductsService 中的 SKU 和 Name 结果也是如此。因此,我们在数据库大小和应用程序性能上都有损失。
为了解决这个问题,我们可以将 NCHAR 字段的数据类型更改为 NVARCHAR,这是一种可变长度的 string 数据类型。对于 NVARCHAR 字段,SQL Server 只分配保存字段内容所需的内存,并且不会向字段数据添加尾随空格。
我们可以通过 T-SQL 脚本更改字段的数据类型
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Products]
ALTER COLUMN SKU nvarchar(50) NOT NULL
ALTER TABLE [Products]
ALTER COLUMN [Name] nvarchar(150) NOT NULL
ALTER TABLE [Prices]
ALTER COLUMN Supplier nvarchar(50) NOT NULL
但尾随空格仍然存在,因为 SQL Server 为了不丢失数据而没有对它们进行修剪。所以,我们应该主动进行修剪
USE [SpeedUpCoreAPIExampleDB]
GO
UPDATE Products SET SKU = RTRIM(SKU), Name = RTRIM(Name)
GO
UPDATE Prices SET Supplier = RTRIM(Supplier)
GO
现在我们可以移除 ProductsService 和 PricesService 中所有的 .Trim() 方法,输出结果将不再有尾随空格。
使用 MSSQL Server 的全文搜索引擎
如果 Products 表非常大,通过使用 MSSQL Server 的全文搜索引擎的强大功能,可以显著提高 SQL 查询的执行速度。在 MSSQL Server 中使用 FTS(全文搜索)只有一个限制——只能按字段的前缀搜索文本。换句话说,如果对 SKU 列应用全文搜索并尝试查找 SKU 包含“ab”的记录,只能找到“abc”,而找不到“aab”的记录。如果这种搜索结果适合应用程序的业务逻辑,那么就可以实现全文搜索。
因此,将在 Products 表的 SKU 列中搜索一个 sku 或其开头部分。为此,在我们的 SpeedUpCoreAPIExampleDB 数据库中,我们应该创建一个 FullText catalog
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT CATALOG [ProductsFTS] WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
GO
然后在 ProductsFTS 目录中创建 FULLTEXT INDEX
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT INDEX ON [dbo].[Products]
(SKU LANGUAGE 1033)
KEY INDEX PK_Products
ON ProductsFTS
GO


SKU 列将被包含在全文索引中。该索引将自动填充。但如果你想手动执行此操作,只需右键单击 Products 表,然后选择 Full-Text index > Start Full population。
结果应该是

让我们创建一个存储过程来检验全文搜索是如何工作的。
存储过程
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE PROCEDURE [dbo].[GetProductsBySKU]
@sku [varchar] (50)
AS
BEGIN
SET NOCOUNT ON;
Select @sku = '"' + @sku + '*"'
-- Insert statements for procedure here
SELECT ProductId, SKU, Name FROM [dbo].Products WHERE CONTAINS(SKU, @sku)
END
GO
关于 @sku 格式的一些解释 - 为了让全文搜索能够按单词前缀进行搜索,搜索参数应带有结尾的 * 通配符:'"aa*"'。所以,Select @sku = '"' + @sku + '*"' 这行代码只是格式化了 @sku 的值。
让我们检查一下这个过程是如何工作的
USE [SpeedUpCoreAPIExampleDB]
GO
EXEC [dbo].[GetProductsBySKU] 'aa'
GO
结果将是。

结果完全符合预期。
优化存储过程
别忘了 "SET NOCOUNT ON" 以防止不必要地计算已处理的记录数。
请注意,使用了查询
SELECT ProductId, SKU, [Name] FROM [dbo].Products WHERE CONTAINS(SKU, @sku)
而不是
SELECT * FROM Products WHERE CONTAINS(SKU, @sku)
虽然两个查询的结果是相同的,但第一个查询的执行速度更快。因为如果使用 * 通配符代替列名,SQL Server 会首先查找表的所有列名,然后用这些名称替换 * 通配符。如果明确指定了列名,这个额外的工作就被省略了。而且,如果不指定表架构(在我们的例子中是 [dbo]),SQL Server 将在所有架构中搜索表。但如果明确指定了架构,SQL Server 在该架构内搜索表的速度会更快。
预编译和重用存储过程执行计划
使用存储过程的一个重要好处是,在首次执行之前,过程会被编译,并创建其执行计划并放入缓存中。然后,当下次执行该过程时,编译操作被省略,直接从缓存中获取现成的执行计划。所有这些都使得请求处理速度快得多。
让我们确保 SQL Server 重用一个过程的执行计划和预编译代码。为此,首先从 SQL Server 内存中清除所有缓存的执行计划 - 在 Microsoft SQL Server Management Studio 中,创建一个新的查询
USE [SpeedUpCoreAPIExampleDB]
GO
--clear cache
DBCC FREEPROCCACHE
然后通过一个新的查询检查缓存状态
SELECT cplan.usecounts, cplan.objtype, qtext.text, qplan.query_plan
FROM sys.dm_exec_cached_plans AS cplan
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS qtext
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qplan
ORDER BY cplan.usecounts DESC
结果将是。

再次执行存储过程
EXEC [dbo].[GetProductsBySKU] 'aa'
然后检查缓存

我们可以看到一个过程执行计划被缓存了。执行该过程并再次检查当前缓存计划的信息

在“usecounts”字段中,我们可以看到该计划被重用了多少次。您可以在“usecounts”字段中看到该计划已被重用两次,这证明了执行计划缓存对我们的过程确实有效。
将 Entity Framework Core 与全文搜索结合使用
关于全文搜索的最后一个问题是如何将其与 Entity Framework Core 一起使用。EFC 会自行生成对数据库的查询,并且不会考虑全文索引。有一些方法可以解决这个问题。最简单的方法是调用我们已经实现了全文搜索的存储过程 GetProductsBySKU。
为了执行我们的存储过程,我们将使用 FromSql 方法。此方法在 Entity Framework Core 中用于执行返回数据集的存储过程和原始 SQL 查询。
在 ProductsRepository.cs 中,将 FindProductsAsync 方法的代码更改为
public async Task<IEnumerable<Product>> FindProductsAsync(string sku)
{
return await _context.Products.FromSql
("[dbo].GetProductsBySKU @sku = {0}", sku).ToListAsync();
}
注意:为了加快过程的启动速度,我们使用了它的完全限定名称 [dbo].GetProductsBySKU,其中包括 [dbo] 架构。
使用存储过程的一个问题是其代码不在源代码控制之外。要解决此问题,您可以调用具有相同脚本的原始 SQL 查询,而不是存储过程。
注意! 仅使用参数化的原始 SQL 查询,以利用执行计划的重用并防止 SQL 注入攻击。
但是存储过程仍然更快,因为在调用过程时,我们只将其名称传递给 SQL Server,而不是像调用原始 SQL 查询那样传递完整的脚本文本。
让我们检查一下存储过程和 FTS 在我们的应用程序中是如何工作的。启动应用程序并测试 /api/products/find/。
https://:49858/api/products/find/aa
结果将与没有全文搜索时相同

Entity Framework Core 性能
由于我们的存储过程返回的是预期的实体类型 Product 的列表,EFC 会自动执行跟踪以分析哪些记录被更改,以便只更新那些记录。但是当获取 Products 列表时,我们不打算更改任何数据。因此,通过使用 AsNoTracking() 方法关闭跟踪是合理的,这可以禁用 EF 的额外活动并显著提高其生产力。
不带跟踪的 FindProductsAsync 方法的最终版本是
public async Task<IEnumerable<Product>> FindProductsAsync(string sku)
{
return await _context.Products.AsNoTracking().FromSql
("[dbo.GetProductsBySKU @sku = {0}", sku).ToListAsync();
}
我们也可以在 GetAllProductsAsync 方法中应用 AsNoTracking
public async Task<IEnumerable<Product>> GetAllProductsAsync()
{
return await _context.Products.AsNoTracking().ToListAsync();
}
以及在 GetProductAsync 方法中
public async Task<Product> GetProductAsync(int productId)
{
return await _context.Products.AsNoTracking().Where
(p => p.ProductId == productId).FirstOrDefaultAsync();
}
请注意,使用 AsNoTracking() 方法时,EFC 不会执行对已更改实体的跟踪,如果不将实体附加到 _context,您将无法保存在 GetProductAsync 方法中找到的实体(如果有的话)的更改。但是 EFC 仍然执行标识解析,所以我们可以轻松删除通过 GetProductAsync 方法找到的 Product。这就是为什么我们的 DeleteProductAsync 方法在新版本的 GetProductAsync 方法下可以正常工作。
对 Prices 表进行全文搜索
如果 ProductId 是 NVARCHAR 数据类型,我们在获取价格时可以显著提高 SQL 查询性能,因为我们可以在 ProductId 列上应用全文搜索。但它的类型是 INTEGER,因为它是指向 Products 表的 ProductId 主键的外键,该主键是带有自动增量标识的整数。
解决此问题的一种可能方案是在 Prices 表中创建一个计算列,该列将由 ProductId 字段的 NVARCHAR 表示组成,并将此列添加到全文索引中。
让我们创建一个名为 xProductId 的新计算列
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
ADD xProductId AS convert(nvarchar(10), ProductId) PERSISTED NOT NULL
GO
我们已将 xProductId 列标记为 PERSISTED,以便其值物理存储在表中。如果不是持久化的,xProductId 列的值将在每次访问时重新计算。这些重新计算也可能影响 SQL Server 的性能。
xProductId 字段中的值将是作为 string 的 ProductId

表的新内容

然后在 xProductId 字段上创建一个新的 PricesFTS 全文目录,并带有 FULLTEXT INDEX
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT CATALOG [PricesFTS] WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
GO
CREATE FULLTEXT INDEX ON [dbo].[Prices]
(xProductId LANGUAGE 1033)
KEY INDEX PK_Prices
ON PricesFTS
GO
最后,创建一个存储过程来测试结果
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE PROCEDURE [dbo].[GetPricesByProductId]
@productId [int]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @xProductId [NVARCHAR] (10)
Select @xProductId = '"' + CONVERT([nvarchar](10),@productId) + '"'
-- Insert statements for procedure here
SELECT PriceId, ProductId, [Value], Supplier FROM [dbo].Prices _
WHERE CONTAINS(xProductId, @xProductId)
END
GO
在存储过程中,我们声明了 @xProductId 变量,将 @productId 转换为 NVARCHAR,并执行了全文搜索。
执行 GetPricesByProductId 过程
USE [SpeedUpCoreAPIExampleDB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[GetPricesByProductId]
@productId = 1
SELECT 'Return Value' = @return_value
GO
但什么也没找到

对数值进行全文搜索
从 SQL Server 2012 开始,由于其新版本的分词器,在包含数值的 string 列上进行全文搜索会出现问题。让我们检查一下全文搜索引擎是如何解析 xProductId 值(“1”、“2”等)的。执行
SELECT display_term FROM sys.dm_fts_parser (' "1" ', 1033, 0, 0)

您可以看到,解析器将值 "1" 在第 1 行识别为 string,在第 2 行识别为数字。这种模糊性导致 xProductId 列的值无法被包含在全文索引中。解决此问题的一种可能方法是“将搜索使用的分词器还原到以前的版本”。但我们采用了另一种方法——在 xProductId 列的每个值的开头加上一个字符(例如“x”),以强制全文解析器将值识别为 string。让我们来确认一下
SELECT display_term FROM sys.dm_fts_parser (' "x1" ', 1033, 0, 0)

结果中不再有歧义。
更改计算列公式
修改计算列的唯一方法是先删除该列,然后再用其他条件重新创建它。
由于 ProductId 列已启用全文搜索,我们在删除该列之前必须先删除全文索引
USE [SpeedUpCoreAPIExampleDB]
GO
DROP FULLTEXT INDEX ON [Prices]
GO
然后删除该列
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
DROP COLUMN xProductId
GO
然后用新公式重新创建该列
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER TABLE [Prices]
ADD xProductId AS 'x' + convert(nvarchar(10), ProductId) PERSISTED NOT NULL
GO
检查结果
USE [SpeedUpCoreAPIExampleDB]
GO
SELECT * FROM [Prices]
GO
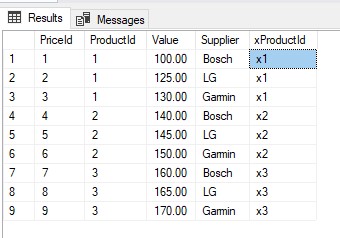
重新创建全文索引
USE [SpeedUpCoreAPIExampleDB]
GO
CREATE FULLTEXT INDEX ON [dbo].[Prices]
(xProductId LANGUAGE 1033)
KEY INDEX PK_Prices
ON PricesFTS
GO
更改我们的 GetPricesByProductId 存储过程,以便在搜索模式中添加 ‘x’
USE [SpeedUpCoreAPIExampleDB]
GO
ALTER PROCEDURE [dbo].[GetPricesByProductId]
@productId [int]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @xProductId [NVARCHAR] (10)
Select @xProductId = '"x' + CONVERT([nvarchar](10),@productId) + '"'
-- Insert statements for procedure here
SELECT PriceId, ProductId, [Value], Supplier FROM [dbo].Prices _
WHERE CONTAINS(xProductId, @xProductId)
END
最后,检查过程的工作结果
USE [SpeedUpCoreAPIExampleDB]
GO
DECLARE @return_value int
EXEC @return_value = [dbo].[GetPricesByProductId]
@productId = 1
SELECT 'Return Value' = @return_value
GO

它工作正常。现在让我们更改 PricesRepository 中的 GetPricesAsync 方法。更改这行代码
return await _context.Prices.Where(p => p.ProductId == productId).ToListAsync();
to
return await _context.Prices.AsNoTracking().FromSql_
("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
启动应用程序并检查 https://:49858/api/prices/1 的结果。结果将与没有全文搜索时相同

缓存数据处理结果。
再看一遍上面的图片。在我们的例子中,https://:49858/api/prices/1 请求的结果可以缓存一段时间。下次尝试获取 Product1 的价格时,现成的价格表将从缓存中获取并发送给用户。如果缓存中仍然没有 Id=1 的结果,价格将从数据库中获取,然后放入缓存。这种方法将减少相对较慢的数据库访问次数,转而从内存中的缓存中快速检索数据。
Redis 缓存
对于缓存,将使用 Redis 缓存服务。Redis 缓存的优点是
- Redis 缓存是数据的内存存储,因此其性能远高于将数据存储在磁盘上的数据库。
- Redis 缓存实现了
IDistributedCache接口。这意味着我们可以轻松地将缓存提供程序更改为另一个IDistributedCache提供程序,例如 MS SQL Server,而无需更改缓存管理逻辑。 - 如果将服务迁移到 Azure 云,切换到 Azure Redis 缓存将非常容易。
在 Windows 上安装 Redis
最新版本的 Redis for Windows 可以从 https://github.com/MicrosoftArchive/redis/releases 下载。
目前版本是 3.2.100。
保存并运行 Redis-x64-3.2.100.msi。
安装过程非常标准。出于测试目的,您可以保留所有默认选项。安装后,打开任务管理器并检查 Redis 服务是否正在运行。

另外,请确保该服务是自动启动的。为此,请打开:Windows > 开始菜单 > 管理工具 > 服务。

Redis 桌面管理器
出于调试目的,有一个用于 Redis 服务器的客户端应用程序来观察缓存值会很方便。为此,可以使用 Redis Desktop Manager。您可以从 https://redisdesktop.com/download 下载它。
Redis Desktop Manager 的安装也非常简单——一切都使用默认设置。
打开 Redis Desktop Manager,点击“连接到 Redis 服务器”按钮,然后选择名称:Redis 和地址:localhost

然后点击 OK 按钮,您将看到 Redis 缓存服务器的内容。
Redis NuGet 包
将 Redis NuGet 包添加到我们的应用程序中
主菜单 > 工具 > NuGet 包管理器 > 管理解决方案的 NuGet 包
在浏览字段中输入 Microsoft.Extensions.Caching.Redis 并选择该包

注意! 请确保选择的是官方的 Microsoft 包 Microsoft.Extensions.Caching.Redis(而不是 Microsoft.Extensions.Caching.Redis.Core)。
在此阶段,您必须已安装以下包

在 Startup 类的 ConfigureServices 方法中,在仓储(repositories)之前声明 AddDistributedRedisCache。
//Cache
services.AddDistributedRedisCache(options =>
{
options.InstanceName = Configuration.GetValue<string>("Redis:Name");
options.Configuration = Configuration.GetValue<string>("Redis:Host");
});
在配置文件 appsettings.json(以及 appsettings.Development.json)中添加 Redis 连接设置。
"Redis": {
"Name": "Redis",
"Host": "localhost"
}
缓存过期控制
对于缓存,可以应用滑动过期或绝对过期模型。
- 当您有大量的
Products列表,但只有一小部分产品需求量很大时,滑动过期会很有用。因此,只有这部分产品的价格会一直被缓存。所有其他价格将自动从缓存中移除,因为它们很少被请求,而滑动过期模型只对在指定时间段内被重新请求的项目继续缓存。这可以保持内存不被不重要的数据占用。这种方法的缺点是我们必须实现某种机制,在数据库中价格发生变化时从缓存中删除项目。 - 绝对过期模型是应用程序中使用的模型。在这种情况下,所有项目将在指定的时间段内被同等缓存,然后自动从缓存中移除。在缓存中维护实际价格的问题将自行解决,尽管可能会有轻微的延迟。
在 appsettings.json(以及 appsettings.Development.json)文件中为缓存设置添加一个部分。
"Caching": {
"PricesExpirationPeriod": 15
}
价格将被缓存 15 分钟。
在何处应用缓存?
由于在应用程序架构中,服务对数据存储方式一无所知,因此缓存的合适位置是负责基础设施层的仓储。为了缓存价格,RedisCache 将与提供对缓存设置访问的 IConfiguration 一起注入到 PricesRepository 中。
缓存实现
在此阶段,PricesRepository 类的最终版本将是
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Caching.Distributed;
using Microsoft.Extensions.Configuration;
using Newtonsoft.Json;
using SpeedUpCoreAPIExample.Contexts;
using SpeedUpCoreAPIExample.Interfaces;
using SpeedUpCoreAPIExample.Models;
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Repositories
{
public class PricesRepository : IPricesRepository
{
private readonly Settings _settings;
private readonly DefaultContext _context;
private readonly IDistributedCache _distributedCache;
public PricesRepository(DefaultContext context,
IConfiguration configuration, IDistributedCache distributedCache)
{
_settings = new Settings(configuration);
_context = context;
_distributedCache = distributedCache;
}
public async Task<IEnumerable<Price>> GetPricesAsync(int productId)
{
IEnumerable<Price> prices = null;
string cacheKey = "Prices: " + productId;
var pricesTemp = await _distributedCache.GetStringAsync(cacheKey);
if (pricesTemp != null)
{
//Deserialize
prices = JsonConvert.DeserializeObject<IEnumerable<Price>>(pricesTemp);
}
else
{
prices = await _context.Prices.AsNoTracking().FromSql
("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
//cache prices for PricesExpirationPeriod minutes
DistributedCacheEntryOptions cacheOptions =
new DistributedCacheEntryOptions()
.SetAbsoluteExpiration(TimeSpan.FromMinutes
(_settings.PricesExpirationPeriod));
await _distributedCache.SetStringAsync
(cacheKey, JsonConvert.SerializeObject(prices), cacheOptions);
}
return prices;
}
private class Settings
{
public int PricesExpirationPeriod = 15; //15 minutes by default
public Settings(IConfiguration configuration)
{
int pricesExpirationPeriod;
if (Int32.TryParse(configuration["Caching:PricesExpirationPeriod"],
NumberStyles.Any, NumberFormatInfo.InvariantInfo,
out pricesExpirationPeriod))
{
PricesExpirationPeriod = pricesExpirationPeriod;
}
}
}
}
}
代码的一些解释
在该类的构造函数中,注入了 DefaultContext、IConfiguration 和 IDistributedCache。然后创建了一个新的 Settings 类实例(在 PricesRepository 类的底部实现)。Settings 用于获取配置中 “Caching” 部分的 “PricesExpirationPeriod” 值。在 Settings 类中还提供了对 PricesExpirationPeriod 参数的类型检查。如果该周期不是整数,则使用默认值(15 分钟)。
在 GetPricessAsync 方法中,我们首先尝试从注入为 IDistributedCache 的 Redis 缓存中获取 ProductId 的价格列表。如果值存在,我们将其反序列化并返回价格列表。如果不存在,我们从数据库中获取列表,并将其缓存,缓存时间为 Settings 的 PricesExpirationPeriod 参数指定的分钟数。
让我们检查一下一切是如何工作的。
在 Firefox 或 Chrome 浏览器中,启动 Swagger Inspector 扩展(之前已安装)并调用 API https://:49858/api/prices/1。
API 以 Status: 200 OK 和 Product1 的价格列表作为响应
打开 Redis Desktop Manager,连接到 Redis 服务器。现在我们可以看到一个名为 RedisPrices 的组和键为 Prices: 1 的缓存值。

Product1 的价格已被缓存,在 15 分钟内再次调用 API api/prices/1 将从缓存中获取它们,而不是从数据库中获取。
提前准备数据的概念
在数据库非常庞大,或者价格只是基础价格,需要为特定用户进行额外重新计算的情况下,如果我们能在用户申请价格之前就准备好价格,并将预计算的价格缓存起来供后续请求使用,那么响应速度的提升可能会大得多。
让我们用参数“aa”分析 api/products/find API 的结果。
https://:49858/api/products/find/aa
我们可以找到两个 sku 包含“aa”的条目。在这个阶段,我们不知道用户可能会请求哪一个的价格。
但如果参数是“abc”,我们将在响应中只得到一个 Product。

用户最可能的下一步将是请求这个特定产品的价格。如果我们在这个阶段获取该产品的价格并缓存结果,那么下一次调用 API https://:49858/api/prices/3 将从缓存中获取现成的价格,从而节省大量时间和 SQL Server 的活动。
提前准备数据的实现
为了实现这个想法,我们在 PricesRepository 和 PricesService 中创建了 PreparePricessAsync 方法。
首先,在 IPricesRepository 和 IPricesService 接口中声明这些方法。在这两种情况下,该方法都将不返回任何内容。
using SpeedUpCoreAPIExample.Models;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Repositories
{
public interface IPricesRepository
{
Task<IEnumerable<Price>> GetPricesAsync(int productId);
Task PreparePricesAsync(int productId);
}
}
和
using Microsoft.AspNetCore.Mvc;
using System.Threading.Tasks;
namespace SpeedUpCoreAPIExample.Interfaces
{
public interface IPricesService
{
Task<IActionResult> GetPricesAsync(int productId);
Task PreparePricesAsync(int productId);
}
}
PricesService 的 PreparePricessAsync 方法只是在 try-catch 结构内部调用 PricesRepository 的 PreparePricessAsync。请注意,在 PreparePricessAsync 过程中没有任何异常处理,我们只是完全忽略了可能出现的错误。这是因为我们不想在这个地方中断程序的流程,因为用户仍然有可能永远不会请求该产品的价格,而一条错误消息可能会成为他工作中不必要的障碍。
public async Task PreparePricesAsync(int productId)
{
IEnumerable<Price> prices = null;
string cacheKey = "Prices: " + productId;
var pricesTemp = await _distributedCache.GetStringAsync(cacheKey);
if (pricesTemp != null)
{
//already cached
return;
}
else
{
prices = await _context.Prices.AsNoTracking().FromSql
("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
//cache prices for PricesExpirationPeriod minutes
DistributedCacheEntryOptions cacheOptions = new DistributedCacheEntryOptions()
.SetAbsoluteExpiration(TimeSpan.FromMinutes
(_settings.PricesExpirationPeriod));
await _distributedCache.SetStringAsync
(cacheKey, JsonConvert.SerializeObject(prices), cacheOptions);
}
return;
}
在 PricesService.cs 中
using System;
…
public async Task PreparePricesAsync(int productId)
{
try
{
await _pricesRepository.PreparePricesAsync(productId);
}
catch (Exception ex)
{
}
}
让我们检查一下 PreparePricesAsync 方法是如何工作的。首先将 PricisService 注入到 ProductsService 中
private readonly IProductsRepository _productsRepository;
private readonly IPricesService _pricesService;
public ProductsService(IProductsRepository productsRepository,
IPricesService pricesService)
{
_productsRepository = productsRepository;
_pricesService = pricesService;
}
注意! 我们将 PricisService 注入到 ProductsService 中仅用于测试目的。以这种方式耦合服务不是一个好习惯,因为如果我们决定实现微服务架构,这将使事情变得困难。在理想的微服务世界中,服务之间不应该相互依赖。
但让我们更进一步,在 Product Service 类中创建 PreparePricessAsync 方法。该方法将是 Private 的,因此不需要在 IProductsRepository 接口中声明。
private async Task PreparePricesAsync(int productId)
{
await _pricesService.PreparePricesAsync(productId);
}
该方法除了调用 PricesService 的 PreparePricessAsync 方法外,什么也不做。
然后,在 FindProductsAsync 中,检查产品列表的搜索结果中是否只有一项。如果只有一项,我们就为这个单项的产品 ID 调用 PricesService 的 PreparePricessAsync。注意,我们在向用户返回 products 列表之前调用了 _pricesService.PreparePricessAsync——原因稍后解释。
public async Task<IActionResult> FindProductsAsync(string sku)
{
try
{
IEnumerable<Product> products = await _productsRepository.FindProductsAsync(sku);
if (products != null)
{
if (products.Count() == 1)
{
//only one record found - prepare prices beforehand
await PreparePricesAsync(products.FirstOrDefault().ProductId);
};
return new OkObjectResult(products.Select(p => new ProductViewModel()
{
Id = p.ProductId,
Sku = p.Sku,
Name = p.Name
}
));
}
else
{
return new NotFoundResult();
}
}
catch
{
return new ConflictResult();
}
}
我们也可以在 GetProductAsync 方法中添加 PreparePricessAsync。
public async Task<IActionResult> GetProductAsync(int productId)
{
try
{
Product product = await _productsRepository.GetProductAsync(productId);
if (product != null)
{
await PreparePricesAsync(productId);
return new OkObjectResult(new ProductViewModel()
{
Id = product.ProductId,
Sku = product.Sku,
Name = product.Name
});
}
else
{
return new NotFoundResult();
}
}
catch
{
return new ConflictResult();
}
}
从 Redis 缓存中移除缓存值,启动应用程序并调用 https://:49858/api/products/find/abc。
打开 Redis Desktop Manager 并检查缓存值。你可以找到 "ProductId":3 的价格列表。
[
{
"PriceId": 7,
"ProductId": 3,
"Value": 160.00,
"Supplier": "Bosch"
},
{
"PriceId": 8,
"ProductId": 3,
"Value": 165.00,
"Supplier": "LG"
},
{
"PriceId": 9,
"ProductId": 3,
"Value": 170.00,
"Supplier": "Garmin"
}
]
然后检查 /api/products/3 API。从缓存中删除数据并调用 https://:49858/api/products/3。
在 Redis Desktop Manager 中检查,你会发现这个 API 也能正确地缓存价格。
但我们没有获得任何速度上的提升,因为我们同步调用了异步方法 GetProductAsync——应用程序工作流一直等到 GetProductAsync 准备好价格列表。所以,我们的 API 完成了两次调用的工作。
为了解决这个问题,我们应该在一个单独的线程中执行 GetProductAsync。在这种情况下,api/products 的结果将立即传递给用户。同时,GetProductAsync 方法将继续工作,直到它准备好价格并缓存结果。
为此,我们必须稍微更改 PreparePricesAsync 方法的声明——让它返回 void。
在 ProductsService 中
private async void PreparePricesAsync(int productId)
{
await _pricesService.PreparePricesAsync(productId);
}
将 System.Threading 命名空间添加到 ProductsService 类中。
using System.Threading
现在我们可以将对此方法的调用更改为线程调用。
在 FindProductsAsync 方法中
…
if (products.Count() == 1)
{
//only one record found - prepare prices beforehand
ThreadPool.QueueUserWorkItem(delegate
{
PreparePricesAsync(products.FirstOrDefault().ProductId);
});
};
…
以及在 GetProductAsync 方法中
…
ThreadPool.QueueUserWorkItem(delegate
{
PreparePricesAsync(productId);
});
…
一切似乎都正常。从 Redis 缓存中删除缓存值,启动应用程序并调用 https://:49858/api/products/find/abc。
结果状态是 Status: 200 OK,但缓存仍然是空的。所以,发生了一些错误,但我们看不到它,因为我们没有在 PricesService 中为 PreparePricessAsync 方法执行错误处理。
让我们在 PricesService 的 PreparePricesAsync 方法中的 catch 语句之后设置一个断点

然后再次调用 API https://:49858/api/products/find/abc。
现在我们有一个异常,可以检查详细信息
System.ObjectDisposedException:“无法访问已释放的对象。此错误的常见原因是释放从依赖注入解析的上下文,然后稍后在应用程序的其他地方尝试使用相同的上下文实例。如果您在上下文上调用 Dispose(),或者将上下文包装在 using 语句中,则可能会发生这种情况。如果您正在使用依赖注入,您应该让依赖注入容器来处理上下文实例的释放。”
这意味着,当结果发送给用户后,我们不能再使用通过依赖注入注入的 DbContext,因为此时 DbContext 已经被释放了。而且,DbContext 在我们的依赖注入链中注入得有多深都无关紧要。
让我们检查一下,在没有 DbContext 依赖注入的情况下,我们是否能完成这项工作。在 PricesRepository.PreparePricessAsync 中,我们将动态创建 DbContext 并在 using 结构中使用它。
添加 EntityFrameworkCore 命名空间
using Microsoft.EntityFrameworkCore
获取价格的代码块将如下所示
using Microsoft.EntityFrameworkCore
…
public async Task PreparePricessAsync(int productId)
{
…
var optionsBuilder = new DbContextOptionsBuilder<DefaultContext>();
optionsBuilder.UseSqlServer(_settings.DefaultDatabase);
using (var _context = new DefaultContext(optionsBuilder.Options))
{
prices = await _context.Prices.AsNoTracking().FromSql
("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
}
…
并在 Settings 类中添加两行
public string DefaultDatabase;
…
DefaultDatabase = configuration["ConnectionStrings:DefaultDatabase"];
然后启动应用程序,再次尝试 https://:49858/api/products/find/abc。
现在没有错误了,价格也已缓存在 Redis 缓存中。如果我们在 PricesRepository.PreparePricessAsync 方法内部设置一个断点,然后再次调用 API,我们可以看到,在结果发送给用户之后,程序会停在这个断点上。所以,我们达到了我们的目的——价格在后台预先准备,并且这个过程不会阻塞应用程序的流程。
但这个解决方案并不理想。一些问题是
- 通过将
PricisService注入到ProductsService中,我们耦合了服务,因此如果我们想应用微服务架构,就会变得困难; - 我们无法获得
DbContext依赖注入的优势; - 混合使用多种方法,使我们的代码不够统一,因此更加混乱。
思考微服务架构
在本文中,我们描述的是一个单体应用程序,但在完成了所有生产力改进之后,提高高负载应用程序性能的一种可能方法是进行水平扩展。为此,应用程序可能会被拆分为两个微服务,ProductsMicroservice 和 PricesMicroservice。如果 ProductsMicroservice 想要提前准备价格,它将调用 PricesMicroservice 的相应方法。该方法应通过 API 访问。
我们将遵循这个思路,但在我们的单体应用程序中实现它。首先,我们将在 PricesController 中创建一个 API api/prices/prepare,然后从 ProductsServive 通过 Http 请求调用这个 API。这应该能解决我们遇到的所有关于 DbContext 依赖注入的问题,并为应用程序向微服务架构过渡做好准备。而且,即使在单体应用中使用 Http 请求,还有一个好处是,在负载均衡器后面的多租户应用程序中,这个请求可能会由应用程序的另一个实例处理,这样我们就能获得水平扩展的好处。
首先,让我们将 PricesRepository 恢复到开始测试 PreparePricessAsync 方法之前的状态:在 PricesRepository.PreparePricessAsync 方法中,我们移除“using”语句,只留下一行代码
public async Task PreparePricessAsync(int productId)
{
…
prices = await _context.Prices.AsNoTracking().FromSql
("[dbo].GetPricesByProductId @productId = {0}", productId).ToListAsync();
…
并从 PricesRepository.Setting 类中移除 DefaultDatabase 变量。
为价格准备创建 API
在 PricesController 中,添加该方法
// POST api/prices/prepare/5
[HttpPost("prepare/{id}")]
public async Task<IActionResult> PreparePricessAsync(int id)
{
await _pricesService.PreparePricesAsync(id);
return Ok();
}
请注意,调用方法是 POST,因为我们不打算用这个 API 获取任何数据。并且该 API 总是返回 OK——如果在 API 执行过程中发生任何错误,它将被忽略,因为它在这个阶段不重要。
清除 Redis 缓存,启动我们的应用程序,调用 POST https://:49858/api/prices/prepare/3
API 工作正常 - 我们得到 Status: 200 OK,并且 Product3 的价格表已被缓存。
所以,我们的意图是从 ProductsService.PreparePricessAsync 方法的代码中调用这个新的 API。要做到这一点,我们必须决定如何获取 API 的 URL。我们将在 GetFullyQualifiedApiUrl 方法中获取 URL。但是,如果我们无法访问当前的 Http 上下文来找出主机、工作协议和端口,我们如何在 service 类内部获取 URL 呢?
我们至少有三种可能性可以使用
- 将完全限定的 API URL 放入配置文件中。这是最简单的方法,但如果将来我们决定将应用程序迁移到另一个基础设施,可能会导致一些问题——我们将不得不关心配置文件中实际的 URL。
- 当前的 Http 上下文在控制器级别可用。所以,我们可以在那里确定 URL,并将其作为参数传递给
ProductsService.PreparePricessAsync方法,甚至可以传递 Http 上下文本。这两种选择都不是很好,因为我们不想在控制器中实现任何业务逻辑,而且从服务类的角度来看,它变得依赖于控制器,结果导致服务的测试更难建立。 - 使用
HttpContextAccessor服务。它可以在应用程序的任何地方提供对 HTTP 上下文的访问。并且它可以通过依赖注入进行注入。当然,我们选择这种方法,因为它通用且是 ASP.NET Core 的原生方法。
为了实现这一点,我们在 Startup 类的 ConfigureServices 方法中注册 HttpContextAccessor
using Microsoft.AspNetCore.Http;
…
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddSingleton<IHttpContextAccessor, HttpContextAccessor>();
…
该服务的作用域应为 Singleton。
现在我们可以在 ProductService 中使用 HttpContextAccessor。注入 HttpContextAccessor 而不是 PriceServive
using Microsoft.AspNetCore.Http;
…
public class ProductsService : IProductsService
{
private readonly IProductsRepository _productsRepository;
private readonly IHttpContextAccessor _httpContextAccessor;
private readonly string _apiUrl;
public ProductsService(IProductsRepository productsRepository,
IHttpContextAccessor httpContextAccessor)
{
_productsRepository = productsRepository;
_httpContextAccessor = httpContextAccessor;
_apiUrl = GetFullyQualifiedApiUrl("/api/prices/prepare/");
}
…
添加一个方法 ProductsService.GetFullyQualifiedApiUrl,代码如下
private string GetFullyQualifiedApiUrl(string apiRout)
{
string apiUrl = string.Format("{0}://{1}{2}",
_httpContextAccessor.HttpContext.Request.Scheme,
_httpContextAccessor.HttpContext.Request.Host,
apiRout);
return apiUrl;
}
注意:我们在类构造函数中设置了 _apiUrl 变量的值。并且我们通过移除 PricesService 的依赖注入,并更改 ProductService.PreparePricessAsync 方法——调用新的 API 而不是调用 PriceServive.PreparePricessAsync 方法,从而解耦了 ProductService 和 PricesService
using System.Net.Http;
…
private async void PreparePricesAsync(int productId)
{
using (HttpClient client = new HttpClient())
{
var parameters = new Dictionary<string, string>();
var encodedContent = new FormUrlEncodedContent(parameters);
try
{
var result = await client.PostAsync(_apiUrl + productId,
encodedContent).ConfigureAwait(false);
}
catch
{
}
}
}
在这个方法中,我们在 try-catch 块内调用 API,不进行错误处理。
清除 Redis 缓存,启动我们的应用程序,调用 https://:49858/api/products/find/abc 或 https://:49858/api/products/3
API 工作正常 - 我们得到 Status: 200 OK,并且 Product3 的 pricelist 已被缓存。
HttpClient 的问题
在“Using”结构中使用 HttpClient 并不是最佳解决方案,我们只是用它作为概念验证。我们可能在两点上损失生产力
- 每个
HttpClient都有自己的连接池,用于存储和重用连接。但是,如果为每个请求创建一个新的HttpClient,新HttpClient无法重用先前创建的HttpClients的连接池。因此,它必须浪费时间来建立到同一服务器的新连接。 - 在“
using”构造结束时释放HttpClient后,其连接不会立即释放。相反,它们会在TIME_WAIT状态下等待一段时间,阻塞分配给它们的端口。在高负载的应用程序中,短时间内会创建大量连接,但这些连接在一段时间内(默认为 4 分钟)仍然无法重用。这种对资源的低效使用可能导致生产力的显著损失,甚至导致“套接字耗尽”问题和应用程序崩溃。
解决此问题的一种可能方法是为每个 Service 提供一个 HttpClient,并将该 Service 添加为 Singleton。但我们将采用另一种方法——使用 HttpClientFactory 以正确的方式管理我们的 HttpClients。
使用 HttpClientFactory 管理 HttpClient
HttpClientFactory 控制 HttpClients 处理程序的生命周期,使其可重用,从而防止应用程序低效地使用资源。
自 ASP.NET Core 2.1 起,HttpClientFactory 就已可用。要将其添加到我们的应用程序中,我们应该安装 Microsoft.Extensions.Http NuGet 包

通过应用 AddHttpClient() 方法,在应用程序的 Startup.cs 文件中注册默认的 HttpClientFactory
…
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddSingleton<IHttpContextAccessor, HttpContextAccessor>();
services.AddHttpClient();
…
在 ProductsService 类中,通过依赖注入注入 HttpClientFactory
…
private readonly IProductsRepository _productsRepository;
private readonly IHttpContextAccessor _httpContextAccessor;
private readonly IHttpClientFactory _httpClientFactory;
private readonly string _apiUrl;
public ProductsService(IProductsRepository productsRepository,
IHttpContextAccessor httpContextAccessor, IHttpClientFactory httpClientFactory)
{
_productsRepository = productsRepository;
_httpContextAccessor = httpContextAccessor;
_httpClientFactory = httpClientFactory;
_apiUrl = GetFullyQualifiedApiUrl("/api/prices/prepare/");
}
…
更正 PreparePricesAsync 方法 - 移除“Using”结构,并通过注入的 HttpClientFactory 的 .Create Client() 方法创建一个 HttpClient
…
private async void PreparePricesAsync(int productId)
{
var parameters = new Dictionary<string, string>();
var encodedContent = new FormUrlEncodedContent(parameters);
try
{
HttpClient client = _httpClientFactory.CreateClient();
var result = await client.PostAsync(_apiUrl + productId,
encodedContent).ConfigureAwait(false);
}
catch
{
}
}
…
.CreateClient() 方法通过从池中取出一个 HttpClientHandler 并将其传递给新创建的 HttpClient 来重用它们。
最后一个阶段已经通过,我们的应用程序可以提前准备价格,并且遵循 .NET Core 范式,以一种高效和有弹性的方式完成这项工作。
摘要
最后,我们得到了应用了各种提高生产力方法的应用程序。
与第 1 部分中的测试应用程序相比,最新版本要快得多,并且更有效地使用了基础设施。
关注点
在第 1 部分和第 2 部分中,我们一步步地开发应用程序,主要关注于易于应用和检验不同的方法、修改代码和检查结果。但现在,在我们选择了方法并实现它们之后,我们可以将我们的应用程序视为一个整体。很明显,代码需要进行一些重构。
因此,在名为《ASP.NET Core WEB API 应用程序代码的深度重构与优化》的第 3 部分中,我们将专注于简洁的代码、全局错误处理、输入参数验证、文档化以及一个编写良好的应用程序必须具备的其他重要特性。
历史
- 2018年10月13日:初始版本