
关于核心 NodeJS - 第 1 部分
4.86/5 (5投票s)
在这一系列文章中学习所有关于核心 NodeJS 的知识。

必备组件
- JavaScript基础知识
- HTML/CSS基础知识
- 假设您知道如何安装 Node
在本文中,我将把 Node.js 称为 Node。我可能会互换使用这些术语,但它们指的是同一个东西。
完整的源代码可以在 https://github.com/rajeshpillai/node-tutorial 获取。
致谢
在开始之前,本文的功劳归于 Node 文档、我阅读的众多 Node 书籍、我过去 5 年使用 Node 的经验、我的公司和我的同事以及我的培训活动。
“一篇文章涵盖所有 xyz”系列的目标
我正在经营一家初创公司,我们培训来自各行各业的应届毕业生或实习生,帮助他们在计算机科学、网络开发、数据科学等领域发展职业。
我们发现,在他们接受培训期间,他们不得不参考大量文档、文章、书籍、博客和视频来衡量某个主题的深度(这很好,但很耗时)。
这就是“一篇文章涵盖所有 xyz”这个想法的由来,以便参与者**可以获得对各自学习领域大多数主要主题的单一参考点**。
他们仍然需要搜索、观看视频、阅读书籍、文章等,但现在他们可以以更专注的方式进行。
但是,NodeJS 无法在一篇文章中涵盖,因此我将其分成多篇文章,本文是第一部分。
首先
请注意,本文篇幅会很长,我希望逐步发布,以便感兴趣的读者有足够的时间赶上、提供反馈等,我也可以在此过程中改进文章。
完成整个内容可能需要一个月的时间,但我不希望一次性发布一个长达 100 页的故事,因为那不会给那些有兴趣跟进的人足够的时间和优势。
因此,我**采取了增量发布的方式。**
Hello World
让我们从 hello world 程序开始,毕竟传统很重要。
创建一个名为 helloworld.js 的文件(我正在使用 vscode,您可以随意使用任何编辑器)。
let hello = `Welcome to NodeJS Tutorial. Hello World!`
console.log(“Welcome to NodeJS Tutorial”);
要运行此代码,请打开命令 shell/终端并执行以下代码
node helloworld
输出将是在屏幕上显示的一条漂亮消息。

注意:Mac/Linux 用户请相应调整脚本。
输出将是在屏幕上显示的一条漂亮消息。
Node 文件中的代码是如何执行的?
在 Node.js 模块系统中,每个文件都被视为一个单独的模块。因此,在我们的例子中, helloworld.js 和 global.js 是单独的模块。
主源代码/脚本包装在一个 IIFE(立即调用函数表达式)中,该表达式将一些全局对象传递给每个模块/文件。
代码可能如下所示
(function(exports, require, module, __filename, __dirname) {
// Module code actually lives in here
// For e.g. our helloworld.js
})(exports, require, module,__filename, __dirname);
现在您可以看到,这就是为什么 require、module、__filename、__dirname 在所有 node.js 文件中都直接可用,而无需明确要求或导入的原因。
模块
模块是可重用的功能。它可以是一个函数,可以是一个类,可以是一个对象,甚至是简单的变量。
要导入模块,我们在 Node 中使用 require() 函数。Require 函数是全局可用的。
注意:新版本的 Node.js 支持 ES6 语法的 import 和 export 语句。
让我们看看下面示例中模块的一些特性。参考 global.js 文件。
var path = require("path");
console.log(`Full path: ${__filename} and filename is ${path.basename(__filename)}`);
上述代码的输出将是(在您的终端中运行命令:node global)

path 模块为我们提供了一些处理文件/文件夹的方法。basename 方法从完整路径中返回文件名。
__filename is a variable that is available in all node file and
it refers the complete path of the current file.
require() 的工作原理
在 Node 中,模块通过文件路径或名称引用。通过名称引用的模块最终将映射到文件路径,除非该模块是一个核心模块。
Node 的核心模块向程序员公开了一些 Node 核心功能,它们在 Node 进程启动时预加载(参考上面的 IIFE)。
其他模块包括您使用 NPM(Node Package Manager)安装的第三方模块,或您或世界各地的开发人员创建的本地模块。
任何类型的每个模块都公开一个 public API,程序员在将模块导入当前脚本后可以使用该 API。
要使用任何类型的模块,您必须使用 require 函数,如下所示
var module = require('module_name');
这将导入一个核心模块或由 NPM 安装的模块。require 函数返回一个表示模块公开的 JavaScript API 的对象。
根据模块的不同,该对象可以是任何 JavaScript 值,一个函数,一个带有一些属性的对象(这些属性可以是函数),一个数组,或任何其他类型的有效 JavaScript 对象。
现在,我们只能导入已导出的模块。
待办事项:Require 流程图(即将推出)
导出模块
Node 使用 CommonJS 模块系统在文件之间共享对象或函数。
对于最终用户,模块精确地公开您指定的内容。
在 Node 中,文件和模块之间存在一对一的对应关系,您可以在以下示例中看到。
让我们创建一个名为 square.js 的文件,它只导出 Square 构造函数。有关构造函数的更多信息,您可以阅读我的另一篇文章 一篇文章涵盖 JavaScript 中的所有函数。
function Square(side) {
function area () {
return side * side;
}
return {
area: area
}
}
module.exports = Square;
这里重要的一点在于最后一行,您在此处定义了模块要导出的内容。module 是一个变量,表示您当前所在的模块。module.exports 是该模块将导出给需要此模块的其他脚本的对象。
您可以导出任何对象。在本例中,我们只导出 Square 构造函数,模块用户可以使用它来创建功能齐全的 Square 实例。
让我们在另一个程序中使用这个 Square 模块。让我们创建一个名为 square-test.js 的文件并添加以下代码
// Load from current module path
var Square = require('./square');
// Since the module exports a constructor function we
// have to create an instance before using it.
var square = new Square(5);
console.log(square.area());
上述程序的输出如下所示

这里还要注意一个重要的事情,由于我们正在导入一个本地模块,我们必须在 require 语句中使用模块的相对路径。
导出多个模块
现在让我们看一个在一个模块中导出多个对象的例子。让我们编写一个小的 string 实用模块,它将帮助我们用字符填充 string 并将文本的第一个字符大写。
将以下代码添加到名为 string-module.js 的文件中(您可以随意命名文件)
function pad(text, padChar='', len) {
let result = padChar.repeat(len);
result = result + text + result;
return result;
}
function capitalizeFirstLetter(text) {
return text.charAt(0).toUpperCase() + text.slice(1);
}
module.exports.pad = pad;
module.exports.capitalizeFirstLetter = capitalizeFirstLetter;
现在在上面的模块/文件中,我们导出了两个函数。让我们在另一个模块中使用这些函数。
创建一个名为 string-module-test.js 的文件并添加以下代码
var util = require('./string-module');
console.log(util.pad("Hello","*",5));
console.log(util.capitalizeFirstLetter("Rajesh is learning to code!"));
上述代码的输出如下所示。现在,函数实际做什么并不重要。在我们的例子中,pad 函数用填充字符和长度对原始字符串的左侧和右侧进行填充,而 capitalizeFirstLetter 则像其名称所暗示的那样进行操作。

注意:为简洁起见,我没有在上述代码中进行任何异常处理。
现在,让我们看看所有三种类型的模块加载。
加载核心模块
Node 有几个模块编译到其二进制发行版中。这些被称为核心模块,并通过模块名称而不是路径引用。
即使存在同名的第三方模块,它们也优先加载。
例如,以下代码显示了如何加载核心 http 模块。
var http = require('http');
这会返回支持各种标准 HTTP 功能的 HTTP 模块对象。有关更多详细信息,请参阅文档。
加载文件模块
我们还可以通过提供绝对路径从文件系统加载非核心模块,如下所示
var myModule = require('/home/rajesh/my_modules/mymodule');
或者您可以提供相对路径,如下所示
var myModule = require('./my_modules/module1');
var myModule2 = require('./lib/module2');
注意:您可以省略“.js”扩展名。
加载文件夹模块
我们可以使用文件夹的路径来加载模块,如下所示
var module1 = require('./moduleFolder');
在这种情况下,Node 将在该文件夹内搜索,并假定此文件夹是一个包,并尝试查找名为 package.json 的包定义文件。
如果该文件夹不包含名为 package.json 的包定义文件,则包入口点将采用默认值 index.js,并且 Node 将在路径 ./moduleFolder/index.js 下查找文件。
但是,如果您在 module 目录中放置一个名为 package.json 的文件,Node 将尝试解析该文件,并查找并使用 main 属性作为入口点的相对路径。
例如,如果我们的 ./myModuleFolder/package.json 文件如下所示,Node 将尝试加载路径为 ./myModuleFlder/lib/module1.js 的文件
{
"name": "module1",
"main": "./lib/module1.js"
}
从 node_modules 文件夹加载
如果您正在加载的模块名称不是相对路径且不是核心模块,Node 将尝试在当前目录的 node_modules 文件夹中查找它。
例如,在下面的代码片段中,Node 将尝试在 ./node_modules/module1.js 中查找文件
var module1 = require('module1.js');
如果 Node 未能找到该文件,它将查找父文件夹 ../node_modules/module1.js。
如果再次失败,它将尝试父文件夹并继续向下搜索,直到到达根目录或找到所需的模块。
我们稍后将讨论 node_modules 和 NPM。
因此,这里的 node_modules 是当您运行 NPM 安装命令时,模块安装/复制到的本地文件夹。
模块缓存
模块在第一次加载时会被缓存,这意味着每次调用 require('module1') 都将返回完全相同的模块,如果模块名称解析为完全相同的文件名。
让我们通过一个例子来实际操作一下。创建一个名为 counter.js 的文件和一个名为 counter-test.js 的文件来演示缓存功能。
counter.js
var counter = 1;
console.log('module counter initializing...');
module.exports = {
value: counter
};
console.log('module counter initialized.');
上面的模块在第一次加载时应该输出 console.log 中提到的文本。第二次 require 时,不应该再出现这个日志,这表明文件是从缓存加载的。
counter-test.js
var counter = require('./counter');
console.log(counter.value);
counter.value++;
// Let us require the module one more time
var counter1 = require('./counter');
console.log(counter.value);
现在,您可以创建多个文件并加载相同的模块并尝试此操作,或者在同一个文件中,如上所示,行为将保持不变。
现在,让我们看看输出。

在上面的代码中,我们两次要求模块,但您只看到一次初始化日志。
您还可以看到,第二次我们获得了更新的计数器值,表明该模块是一种单例实例。
进程对象
process 对象在每个 Node 模块中都是全局可用的。它包含允许我们与系统中当前进程交互的功能。
Process 对象还提供了关于运行时环境的信息。此外,标准输入/输出 (I/O) 通过进程发生,我们还可以优雅地终止 Node 应用程序,甚至可以发出 Node 事件循环(我们稍后将讨论)完成一个周期的信号。
这对于构建命令行应用程序也很有用,因为我们可以捕获从终端调用程序时传递给程序的所有用户参数。
用户提供的参数在 process.argv 变量中可用。
让我们创建一个小型终端程序,将消息传递给模块。创建一个名为 greeting.js 的文件。
console.log("Total Arguments: ", process.argv.length);
console.log(process.argv);
上述程序在命令提示符/终端中执行时将输出以下详细信息
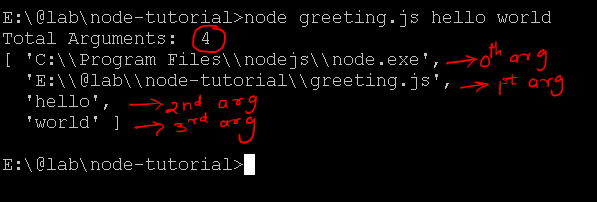
用两个参数“hello”和“world”调用上述程序会产生上述输出。第一个参数是 Node 进程本身,后面是要执行的文件/模块。
使用进程对象理解 Node 环境
现在让我们使用 Process 和 Node 的 -p 命令行选项来探索 Node 环境。
例如,要查看 process.version,请键入以下内容
node -p "process.versions"
看看上面命令的输出

注意:双引号适用于所有平台。单引号可能不适用于 Windows。即使不加任何引号也能正常工作。
process.env 属性是了解开发/生产环境的绝佳方式。
node -p "process.env"
输出太长,无法在此处显示,但我相信您已经明白了。
您甚至可以深入了解对象的详细信息,如下所示
process -p "process.release.lts"
上述命令的输出可能因我们安装的内容而异。
对我来说,输出如下所示

但如果您同时拥有 LTS 和 Current 环境,输出可能会有所不同。
进程 I/O 函数:标准流
标准流是应用程序与其环境之间预先建立的通信通道。它们由标准输入(stdin)、标准输出(stdout)和标准错误(stderr)组成。
进程 I/O 函数继承自 EventEmitter(我们很快就会介绍)。
在 Node 应用程序中,这些通道提供了 Node 应用程序与终端之间的通信。简而言之,它们是我们与应用程序进行通信的手段。
我们可以从 stdin 接收输入,并将输出写入 stdout 和 stderr 通道。
注意:您无法在应用程序中关闭或终止这些 stream。
提示:在使用 stream 之前设置其编码。
读取和写入标准 I/O
每当我们需要将数据输入和输出程序时,一种有用的技术是使用 process 对象来读取和写入标准 I/O stream。
问题:如何将数据管道传输到 Node 程序和从 Node 程序传输数据
解决方案:使用 process.stdout 和 process.stdin
讨论
process.stdout 对象是一个可写入 stdout 的 stream,每个 Node 程序都可以访问它。
示例:一个将输入流转换为大写数据的示例程序。
/* USAGE: cat file.txt | node uppercase-pipe.js
*/
// Tell the stream we're ready to start reading
process.stdin.resume();
process.stdin.setEncoding('utf8');
process.stdin.on('data', function (data){
process.stdout.write(data.toUpperCase());
});
上述程序的输出如下所示。Windows 用户请使用 git bash/git shell 执行程序。

在上面的截图中,我们将 cat 的输出管道传输到我们的程序,该程序将文本转换为大写。
您可以将任何文件作为输入传递给此程序,在此程序中,程序本身就是输入。
它是如何工作的?
每次从输入流中读取一块文本时,它都会被转换为大写,然后写入 stdout。
日志消息
让我们使用控制台对象的一些日志记录功能并查看其行为。
let data = "An important message";
let from = {name: "admin"};
// A space is automatically added after':'
console.log('Notice:', from);
console.log('Hello %s:', from);
console.error('Error: ', from);
让我们执行程序,如下所示
$ node consolelog.js 2>error-log.txt
现在让我们看看输出并了解正在发生的错误日志重定向。

您会看到 console.log 在这里被记录下来,但 console.error 没有。原因是我们用 2>error-log.txt 指示将所有错误重定向到文件中。
如果您查看文件 error-log.txt,您应该会看到以下输出

注意:标准流有三种类型:stdin、stdout 和 stderr。在基于 Unix 的系统中,它们用数字表示。
0 — is used for standard input
1 — is used for standard output
2 — is used for standard error
同样适用于 Windows。
因此,在上述执行 2> error-file.txt 中,2 指的是错误 stream。这意味着我们可以将错误重定向到日志文件,而无需在我们的 Node 程序中打开文件,或使用特定的日志模块。
Node 性能基准测试
一项有用的技能是知道如何使用内置语言功能来测量应用程序的时间。
问题:对慢速操作进行基准测试
解决方案:使用 console.time() 和 console.timeEnd()
讨论
使用 console.time('label') 记录当前的毫秒时间,然后稍后调用 console.timeEnd('label') 显示从那时起的持续时间。
注意:毫秒时间将与标签一起自动打印。
示例
// BEGINNING OF PROGRAM
let fs = require('fs');
let args = {
'-h': commandUsage,
'-r': readFile
};
function commandUsage() {
console.log(args);
}
function readFile(file) {
if (file && file.length) {
console.log('Reading: ', file);
console.time('read'); // START TIMING
let stream = fs.createReadStream(file);
stream.on('end', function () {
console.log("\n");
console.timeEnd('read'); // END TIMING
});
// OUTPUT to console
stream.pipe(process.stdout);
} else {
console.error('Please provide a file with the -r option');
process.exit(1);
}
}
let flag = process.argv[2];
let fileName = process.argv[3];
if (!flag) {
console.log("Usage: filereader-bm [-h/-r] [filename] \n\n");
process.exit(1); // non-zero menas an error occured
}
switch(flag) {
case '-h':
commandUsage();
break;
case '-r':
readFile(fileName);
break;
}
// END OF PROGRAM

让我们执行 node filereader-bm.js -r filereader-bm.js 并查看输出。上述命令执行会计时读取 filereader-bm.js 需要多长时间。
输出将是文件内容,后跟时间。内容摘录如下所示

提示:我们可以使用多个带有不同标签的 console.time 来计时代码的不同甚至嵌套部分。
注意:我们将在本文的后面部分介绍文件处理函数。
缓冲区 (wip)
JavaScript 传统上对二进制数据没有很好的支持。因此,Node 开发人员不得不解决这个问题,主要是出于性能原因,这就是 Buffer 数据类型出现的原因。
它们在处理 TCP 流和文件操作时也特别有用。
缓冲区是堆的原始分配,包含二进制数据,只由位组成,即 0 或 1。
缓冲区文档可以在 此处 找到。
它们是全局可用的,因此无需导入,并且可以像任何其他 JavaScript 类型一样对待。
我们将通过以下活动来理解缓冲区
- 从
string创建缓冲区 - 从数组创建缓冲区
- 将缓冲区转换为 JSON
- 拼接缓冲区
- 比较缓冲区
- 将缓冲区转换为不同的编码
- 使用 Buffer API 将二进制文件转换为 JSON
- 编码和解码您自己的二进制协议
更改数据编码
在使用文件时,如果没有给出编码,文件操作和许多网络**操作将以 Buffer 的形式返回数据**。
例如,看看这个 fs.readFile(看看源代码,buffer 文件夹)
let fs = require('fs');
fs.readFile('./phone.txt', function (err, buf) {
console.log(Buffer.isBuffer(buf)); // true
});
将此程序作为 node readfile.js 运行将得到以下输出

示例 1:将缓冲区转换为纯文本
让我们以文本文件 phone.txt 为例,它包含以下数据
name,mobile
a,987837373
b,897878787
c,383783737
默认情况下,如果我们加载此文件而不指定任何编码,我们将默认获得一个 Buffer 对象。

输出如下所示

但在上面的示例中,由于我们已经知道这些数据只包含 ASCII 字符,**我们还可以通过将编码更改为 ASCII 而不是 UTF-8 来获得性能优势**。
为此,我们将编码类型作为第一个参数传递给 toString,如下所示
let fs = require('fs');
fs.readFile('./phone.txt', function (err, buf) {
console.log(buf.toString('ascii'));
});
运行此操作将产生与以前相同的输出,但对于较大的文件,性能会好得多。
Buffer API 提供了其他编码,例如 base64、hex、utf16le 等。有关更多详细信息,请参阅 Node 文档以及 http://unicode.org/faq/utf_bom.html。
使用缓冲区更改字符串编码
除了转换缓冲区,我们还可以利用缓冲区将一种 string 编码转换为另一种。
示例 1:您想从一种字符串编码更改为另一种。
让我们通过创建一个基本身份验证头来解决上述问题。
有时,构建数据 string 然后更改其编码非常有帮助。例如,如果您想从使用基本身份验证的服务器请求数据,您需要发送您的凭据,例如使用 Base64 编码的用户名和密码。
授权:基本 dG9tbXk6c2VjcmV0
在应用 Base64 编码之前,基本身份验证凭据将用户名和密码组合在一起,并用 :(冒号)分隔。对于我们的示例,让我们使用以下凭据
username: tommy
password: secret
let username = 'tommy';
let password = 'secret';
let authvalue = username + ':' + password;
现在让我们将其转换为 Buffer,以便将其更改为另一种编码。Buffer 可以通过字节分配,也可以通过传入 string 数据分配。
// Let's convert the string value to a Buffer
let buf = new Buffer(authvalue);
let encoded = buf.toString('base64');
console.log(encoded); // outputs: dG9tbXk6c2VjcmV0
注意:默认情况下,当 string 用于分配 Buffer 时,它们被假定为 UTF-8 string。但我们也可以使用第二个编码参数指定传入数据的编码,如下所示
new Buffer('dG9tbXk6c2VjcmV0', 'base64')
示例 2:将 PNG 嵌入为数据 URI
数据 URI 是另一个使用 Buffer API 有帮助的例子。Data URI 允许使用以下方案将资源内嵌到网页中
data:[MIME-type][;charset=<encoding>[;base64],<data>
例如,以下功夫熊猫 https://static.wixstatic.com/media/2cd43b_d1ecd76051de458b9041402093ffeb54~mv2.png 图像可以表示为数据 URI

data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQ...
让我们检查一下实现此目的的代码。让我们将此代码放入一个名为 png-to-datauri.js 的文件中。

示例 3:从数据 URI 创建图像文件
让我们获取上面创建的数据 URI,并将其反转为 PNG 文件。要获取完整的数据 URI,您可以将输出重定向到文件,如下所示。

运行上述命令会将 PNG 作为 base64 保存到名为 base64png.txt 的文件中。
让我们看看反转过程并创建 PNG 的代码。(文件:datauri-to-png.js)

代码的重要部分是 uri.split,然后我们获取 base64 编码的 string 并创建一个缓冲区。
注意:我们为了演示使用了 fs 的 sync 方法(对于实际应用程序,请在适用情况下使用异步版本)。
运行命令...
![]()
...创建一个名为 secondpanda.png 的文件。
示例 4:使用 gzip 压缩文件(缓冲区)
(也请查看流版本。)
代码很小,易于理解,因此我将其列出供您参考。
我们导入所需的库,并将命令行中传递的文件名存储到一个名为 file 的变量中。
使用缓冲区进行 gzip 的步骤如下
- 使用
fs读取文件 - 使用 zlib.gzip 压缩从
readFile方法传递的缓冲区。 - 使用
fs writeFile将文件存储到磁盘。

您可以在终端中运行以下命令
node gzipbuffer.js <filenametocompress>
流 (wip)
Node 基本有两种流,一种是可读流,一种是可写流。流的一个例子是我们可以读取和写入的 TCP 套接字,或者我们可以顺序附加或读取的文件。
示例 1:让我们使用 Node 和 Express 创建一个 HTML5 视频流服务器
为什么我们需要流媒体?如果我们不需要,那么整个视频文件将被下载到客户端并加载到内存中,这可能好也可能不好。
想象一下视频大小为数百兆字节,在这种情况下,网络带宽等将破坏用户体验。
此外,考虑这个场景。您的服务器有 8GB 内存,但驱动器上有 20GB 视频文件,您想加载该文件吗?
欢迎来到流媒体!
通过流,文件保留在磁盘上,只有整个文件的一部分被传输到客户端。例如,每次只传输 1MB。
管道
Unix 的 | (管道) 是最常见的将一个程序的输出传递给另一个程序的方式。
在 Node 中,我们可以在代码内部使用管道将一个函数的结果传递给下一个函数。
例如
somefile.pipe(somewritableStream).pipe(toSomeOtherWritableStream)
结合管道和流
我们将结合管道和流来构建我们的视频流服务器。
有关完整的源代码,请参阅 streams\video-streaming 文件夹。
让我们首先通过运行以下命令来设置 ExpressJs
npm install --save express
现在让我们创建一个 index.html 文件来承载 <video> 标签。
<!DOCTYPE html>|
<html>
<head>
<meta charset="utf-8">
<title>Stream Video</title>
<meta name="viewport"
content="width=device-width,initial-scale=1">
</head>
<body style="text-align:center">
<div style="margin:0 auto;">
<video src="" controls
width="640"
height="480">
</video>
</div>
</body>
</html>
HTML 文件就这些了。注意我们使用的是 <video> 元素,src 设置为空,因为我们将从 URL 传递它。
所有视频将存储在我们项目中的 videos 子文件夹中,如下所示

所有带注释的源代码都在 index.js 中。
让我们了解代码的重要部分,首先让我们设置服务 index.html 文件的路由。

让我们从 /video/:videoname 路由开始。以下是请求流媒体的示例。
上述请求将从 videos 文件夹获取媒体并进行流式传输。

首先,我们从参数中获取文件名,然后使用 fs.state 检查文件的状态。如果出现任何错误,我们只需用消息结束响应。
接下来,让我们从 stats 变量中获取浏览器将请求的范围以及 filesize,该变量是调用 fs.stat 的结果。

一旦我们获得了范围和大小,让我们计算缓冲区的开始和结束。结束将保持不变,开始将随每个缓冲请求而变化。我们必须计算 chunksize。

请注意在上面的截图中,范围格式为 bytes=0-100,其中 0 是 start,100 是 end,仅作示例。
如果 end 值不可用,则我们将文件大小作为 end 值。
一旦我们得到 start 和 end,我们就计算 chunkSize。这是 Node 服务器在每次客户端请求数据时将发送回的响应大小。
现在让我们设置响应头,其中包含支持发送分块数据所需的信息,如下所示,并将状态码设置为 206,表示状态设置为部分内容。

让我们更详细地了解这一点。为了在服务器端支持 HTML5 视频流,我们需要处理来自浏览器的 Range HTTP 头。
Range HTTP 头指定浏览器正在请求视频的哪个字节范围。
如果缺少 range,我们可以从字节 0 开始发送整个视频。否则,我们将只发送由 start 和 end 值指示的字节范围。
如前所述,range 头格式的变体如下
Range: bytes=0-
上述意味着浏览器正在请求整个视频,或者至少这是初始请求,因此浏览器可以根据响应中的 Content-Length 头确定视频的大小。
Range: bytes=2000–5000
上述值表示浏览器正在请求从 2000 字节到 10000 字节的视频(可能是用户在视频中向前跳过了)。
另外,请注意 Node 服务器正在发送的响应头。
Accept-Ranges: bytes
Content-Type: video/html
Content-Length: (length)
Content-Range: bytes (start)-(end)/(total)
Accept-Ranges 告诉浏览器服务器支持 HTML5 视频流并且可以处理字节范围。
Content-Length 以字节为单位发送文件的总长度。
Content-Range 发送正在返回的内容的字节范围。
下一步是创建一个读取流,如下所示,并监听 open 事件。

我们使用 fs.createReadStream 打开一个可读 stream,并传入可选的 start 和 end 字节范围。
一旦 stream 打开,我们将 stream 数据管道传输到响应,以便数据可供客户端/浏览器使用。
然后我们处理可能出现的错误并关闭 fs.state 函数调用。

最后,让我们在指定端口上启动我们的服务器,如下所示

现在让我们在终端使用 node index.js 运行我们的应用程序,然后打开浏览器并向 videos 文件夹中的视频文件发出请求(参考源代码)。
流媒体视频的输出如下所示,供您参考

示例 2:使用 gzip 压缩文件(流)
让我们快速编写一个使用 gzip 压缩文件的程序。(为了简洁起见,我没有做任何错误处理。)
让我们导入 fs 和 zlib 模块(它们是 Node 内置的)

让我们从命令行参数中获取文件名。

现在让我们使用 fs.createReadStream 方法读取文件,然后将输出管道传输到 zlib,然后创建一个新的 .gz 压缩文件。

如果您在终端中运行以下代码

您将得到新的压缩文件作为输出,如下所示。我在文件本身上运行了代码,但您可以随意将任何文件作为第二个参数传入。
注意:您可以使用 winrar 或 7zip 或任何其他标准工具解压缩,或者作为练习,自行编写解压缩命令。
即将推出
- 缓冲区(更多更新)
- 流(更多更新)
- 网络和套接字
- 子进程
- 集群
- 事件发射器
- 事件循环
setImmediate()vsprocess.nextTick()
历史
- 2018年10月22日 - 首次在 CP 发布
附注:文章将不时更新,包含更深入的内容和示例。如果您想详细了解任何特定主题或只是分享您的想法并保持对话活跃,请随时分享。