
Redux 状态组织提案
4.67/5 (2投票s)
一种基于关系数据的 Redux 状态组织提案,该提案可扩展
引言
在使用 Redux 时,很难开始组织你的状态。我看到我的许多学生在需要时就随手添加属性。这种混乱的策略可能会导致你因巨大的状态而产生可怕的技术债务。
例如,遵循这种策略,你可能会得到类似这样的结果

我在上面的状态中发现的问题是所有属性都混杂在一起了。
auth_token主要将在中心化方式中使用:一个ApiClient服务或中间件。movies是一个实体列表。它将在整个应用程序中使用,以渲染应用程序提供的信息。fetching是一个表示标志,我们将它用于特定的视图(Component),例如显示加载旋转器。
我们可以看到属性在 **数量级**——因为 movies(数据)与 fetching(标志)的优先级不同——以及 **用途**——因为它们在完全不同的地方和时间使用——方面是如何混杂的。
这两点可能会影响设计,**混乱的状态组织可能会影响我们选择器(mapStateToProps)的模块化。**
经过一些尝试,我提出了一种状态组织方式,解决了上述问题。它最终非常灵活,适合不同结构的某些项目。

此状态是使用 combineReducers 创建的,用于定义由不同 reducers 控制的独立状态部分。请注意,我使用了 **简写属性名** **来定义对象的属性:**authentication 是 authentication: authentication 的简写,其中第二个是稍后将描述的 reducer 函数。
authentication reducer 用于存储和控制与当前登录用户相关的所有数据。如果你的应用程序没有认证策略,可以跳过这部分。你可以在其中保存当前用户对象、认证令牌等信息。这非常有用,例如,当你想要记住会话时,因为它可以被持久化并在创建 store 时预加载。这里有一个 Dan Abramov 关于如何轻松实现此功能的 精彩教程。
它的 reducer 将监听与认证相关的特定 action 类型:SIGN_IN_SUCCESS、SIGN_UP_SUCCESS、LOG_OUT……
这是 reducer 最特别的部分。我们习惯于看到基于 action.type 的巨大 switch 语句的 reducers,其中列出了对状态的转换。但这个 reducer 将在不到 20 行代码中控制我们前端的全部数据。
这个想法是,状态的这个属性存储了一个本地数据库,其中包含我们必须处理的所有实体,并且这些实体在某个时候由后端提供给我们。假设我们继续以电影为例,那么这可能是一个可能的状态

如你所见,状态被分成了不同的实体组。这些组不是数组,而是具有与每个实体对象的 ID 相关的键的对象。这将避免重复。 **主要思想是它必须像一个微型本地关系数据库:** 没有任何东西是重复的,而是被引用的。通过避免嵌套,我们使 **关联数据和避免不一致性变得更容易**。
如果你的数据全部是本地的,你将没有问题以这种方式管理它,但是如果你正在消费 API,它很可能会以嵌套的方式提供数据。为了将数据处理成我们的格式,你可以使用 normalizr。经过一些配置,它将能够通过调用 normalize 函数来扁平化。它将返回一个具有两个属性的对象:entities 和 result。Entities 将是被获取并以我们的格式规范化的数据;Result 将是你刚刚获取的根实体的 ID 关系。
Entities!多么巧合,嗯?其实不是。实际上,我从 Redux 的 Real World Example 中获得了这个模式,它消费了 Github 的 API,然后对其数据进行规范化。
得益于这种格式,我们可以编写一个只用几行代码就能控制状态整个 entities 部分的 reducer。

每次我们的 action 包含 entities 属性时,它都会与我们当前状态的 entities 值合并。
警告:这个 reducer 只会添加或覆盖传入的数据,没有删除数据的 case。有些人可能会说它不需要,因为删除可以看作是对元素 delete 标志的修改(软删除)。你认为呢?有什么改进这个 case 的建议吗?让我们在评论区讨论一下!
我们所有的数据都被自动处理并合并到 state 中。但我们应该小心:我们的数据存储在对象中,没有数组,所以没有顺序。
我们应该保留后端提供的顺序,它们可能花费了大量资源(所以是金钱 💸)来决定电影如何呈现给每个用户(Netflix,某人?)。但通过规范化它们,我们忽略了这种顺序。这就是为什么 normalizr 也提供 results,它是一个表示已获取资源的 ID 关系。
你获取了一个 ID 为 101 的电影(API 返回一个对象)?results 属性将是 101;获取了一组 ID 为 101 和 100 的电影(API 发送一个数组)?results 将是这个数组 [101,100](保持顺序)。下面看一个例子

请注意,原始响应是一个电影数组,规范化对象的 results 属性也是一个数组,保持了原始顺序。
entities reducer 没有为这个 results 数组留出空间,所以我们必须把它放到别的地方:pages reducer。pages reducer 主要用于不同页面渲染其信息所需的本地变量。元素数组、加载标志、可能还有表单数据(如果未使用 redux-form)。基本思想是,虽然 entities reducers 正在保存来自资源的数据,但 **pages reducer 存储与渲染屏幕相关的数据**。
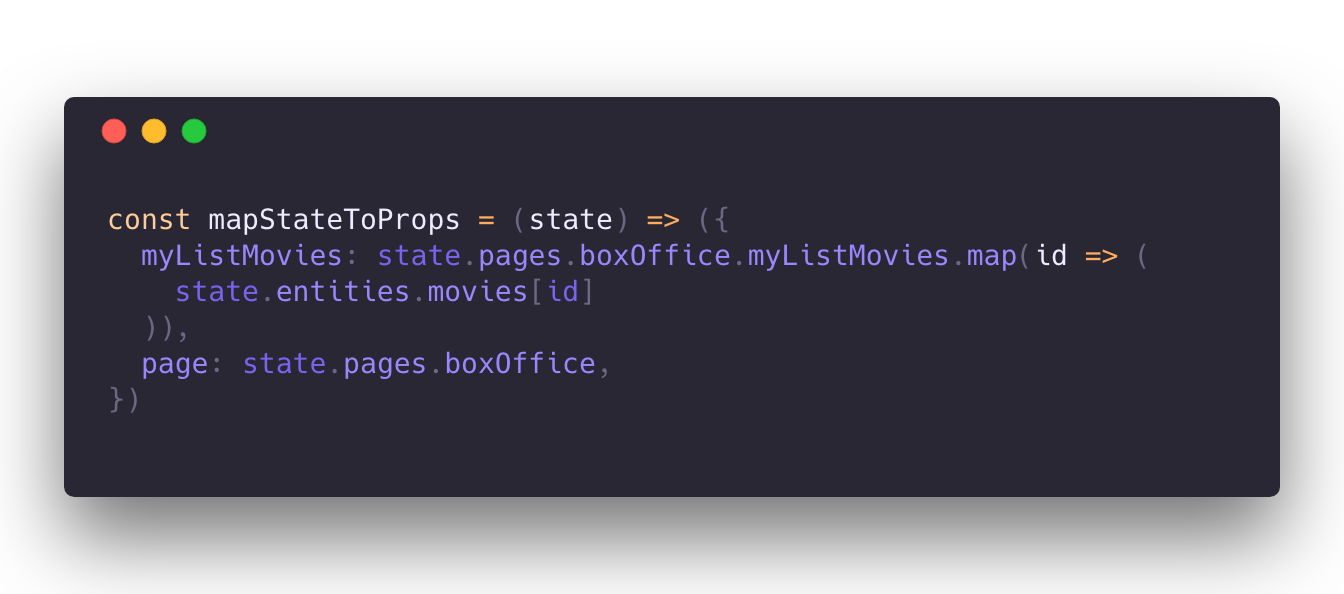
如你所见,在我们的容器中将 state 映射到 props 时,我们创建了一个数组,将 results 中的所有元素(state.pages.boxOffice.myListMovies,ID 列表)映射到 entities 中的实际数据。
这个想法是将 state.pages 属性再次分割成应用程序中显示的所有页面的集合。例如,React Router 加载的每个组件。
这种结构将帮助你轻松扩展数据驱动型应用程序。如果你必须添加其他类型的实体,它不会影响 pages 结构。如果你想添加另一个以不同方式加载现有实体的屏幕,你可以使用 pages reducer,而无需担心数据控制。所有这些都将帮助我们遵循简单的单一事实来源原则,这将帮助你在开发过程中避免许多问题。
将来,我想使用这个模式来编写关于 Redux 的 Reselect。
请在评论区告诉我你的想法,让我们讨论更好的实践或修改。
祝您编码愉快!
- Arol Viñolas,Codeworks 的研究主管(或 CTO)