
探索 TensorFlow
4.43/5 (3投票s)
以前所未有的方式解构 Tensorflow……分解简单事物
引言
在本文中,我们将涵盖 TensorFlow 的基础知识,然后转向高级主题。我们的重点是我们可以用 TensorFlow 做什么。
背景
我们不会定义 TensorFlow 究竟是什么,因为已经有很多内容,但我们将直接使用它。
让我们开始吧。
我们正在使用 Anaconda Python 发行版,然后通过它安装 TensorFlow。我们使用的是 GPU 版本。
我们激活 anaconda 环境。

我们正在使用 Intel 优化的 Python 编写 Python 代码。
让我们看看如何查看 Tensorflow 的版本。

要检查版本,我们首先导入了 tensorflow。
>>> import tensorflow as tf
>>> print(tf.__version__)
1.1.0
//
让我们分解“张量”这个词,它的意思是 n 维数组。
我们将在 tensorflow 中创建最基本的东西,即常量。我们将创建一个名为“hello Intel”的变量。
>>> import tensorflow as tf
>>> hello = tf.constant("Hello ")
>>> Intel = tf.constant("Intel ")
>>> type(Intel)
<class>
>>> print(Intel)
Tensor("Const_1:0", shape=(), dtype=string)
>>> with tf.Session() as sess:
... result=sess.run(hello+Intel)
Now we print the result.
>>> print(result)
b'Hello Intel '
>>>
</class>
Anaconda 提示窗口中的输出如下所示

现在让我们在 TensorFlow 中添加两个数字。
我们声明两个变量
>>> a =tf.constant(50)
>>> b =tf.constant(70)
我们再次检查其中一个变量的类型
>>> type(a)
<class>
</class>
我们看到对象是 tensor 类型。为了添加两个变量,我们必须创建一个 session。
>>> with tf.Session() as sess:
... result = sess.run(a+b)
如果我们现在想看结果
>>> result
120
使用 TensorFlow 从零开始构建神经网络
在下一节中,我们将从零开始在 TensorFlow 中创建一个神经网络。
在本节中,我们将创建一个神经网络,该神经网络对一些二维数据执行简单的线性拟合。
我们将执行的步骤如下图所示。
我们将要构建的神经网络的图结构如下所示。

首先,我们将导入 numpy 和 tensorflow。
(C:\Program Files\Anaconda3) C:\Users\abhis>activate tensorflow-gpu
(tensorflow-gpu) C:\Users\abhis>python
Python 3.5.2 |Intel Corporation| (default, Feb 5 2017, 02:57:01) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
Intel(R) Distribution for Python is brought to you by Intel Corporation.
Please check out: https://software.intel.com/en-us/python-distribution
>>> import numpy as np
>>> import tensorflow as tf
>>>
我们需要为我们的进程设置一些随机种子值。
>>> np.random.seed(101)
>>> tf.set_random_seed(101)
现在,我们将添加一些随机数据。使用 rand_a =np.random.uniform(0,100(5,5)),我们添加了从 0 到 100 的随机数据点,然后要求它具有 (5,5) 的形状。我们对 b 也做同样的操作。
>>> rand_a =np.random.uniform(0,100,(5,5))
>>> rand_a
array([[ 51.63986277, 57.06675869, 2.84742265, 17.15216562,
68.52769817],
[ 83.38968626, 30.69662197, 89.36130797, 72.15438618,
18.99389542],
[ 55.42275911, 35.2131954 , 18.18924027, 78.56017619,
96.54832224],
[ 23.23536618, 8.35614337, 60.35484223, 72.89927573,
27.62388285],
[ 68.53063288, 51.78674742, 4.84845374, 13.78692376,
18.69674261]])
>>> rand_b
array([[ 99.43179012],
[ 52.06653967],
[ 57.87895355],
[ 73.48190583],
[ 54.19617722]])
现在我们需要为这些均匀对象创建占位符。
>>> a = tf.placeholder(tf.float32)
>>> b = tf.placeholder(tf.float32)
Tensorflow 理解正常的 python 操作。我们将使用它。
>>> add_op = a + b
>>> mul_op = a * b
现在我们将创建一些使用图来馈送字典以获取结果的会话。首先,我们声明会话,然后我们想获取 add 操作的结果。我们需要传入操作和馈送字典。对于占位符对象,我们需要馈送数据。我们将通过馈送字典来完成。首先,我们有键,它们是 a 和 b,然后我们向其传递数据。add_result = sess.run(add_op,feed_dict={a:10,b:20})
>>> with tf.Session() as sess:
... add_result = sess.run(add_op,feed_dict={a:10,b:20})
... print(add_result)
由于我们创建了随机数,我们将把它传递给 feed 字典。
>>> with tf.Session() as sess:
... add_result = sess.run(add_op,feed_dict={a:rand_a,b:rand_b})
现在当我们打印 add_result 的值时
>>> print(add_result)
[[ 151.07165527 156.49855042 102.27921295 116.58396149 167.95948792]
[ 135.45622253 82.76316071 141.42784119 124.22093201 71.06043243]
[ 113.30171204 93.09214783 76.06819153 136.43911743 154.42727661]
[ 96.7172699 81.83804321 133.83674622 146.38117981 101.10578918]
[ 122.72680664 105.98292542 59.04463196 67.98310089 72.89292145]]
我们在这里进行了矩阵加法。
我们对乘法也做同样的操作。
>>> with tf.Session() as sess:
... mul_result = sess.run(mul_op,feed_dict={a:10,b:20})
print(mul_result)
200
使用随机值
>>> with tf.Session() as sess:
... mul_result = sess.run(mul_op,feed_dict={a:rand_a,b:rand_b})
>>> print(mul_result)
[[ 5134.64404297 5674.25 283.12432861 1705.47070312
6813.83154297]
[ 4341.8125 1598.26696777 4652.73388672 3756.8293457 988.9463501 ]
[ 3207.8112793 2038.10290527 1052.77416992 4546.98046875
5588.11572266]
[ 1707.37902832 614.02526855 4434.98876953 5356.77734375
2029.85546875]
[ 3714.09838867 2806.64379883 262.76763916 747.19854736
1013.29199219]]
现在让我们用它来创建一个神经网络。
让我们为数据添加一些特征。
>>> n_features =10
现在我们只需声明有多少层神经元。在下面的例子中,我们有 3 层。
>>> n_dense_neurons = 3
让我们为 x 创建一个占位符,然后我们还添加数据类型 float。然后我们必须找到 shape(),首先我们将其视为 None,因为它取决于我们馈送给神经网络的数据批次。列数将是特征的数量。所以占位符看起来像这样
>>> x = tf.placeholder(tf.float32,(None,n_features))
现在我们将有其他变量。W 是权重变量,我们用某种随机性初始化它,然后它的形状是特征数量和层中神经元数量。
>>> W = tf.Variable(tf.random_normal([n_features,n_dense_neurons]))
现在我们将声明偏差。我们声明变量,我们可以将其设为 1 或 0。我们正在使用 tensorflow 中的函数。我们必须记住 W 将与 x 相乘,因此对于矩阵乘法,我们需要保持列的维度与行的维度一致。
>>> b = tf.Variable(tf.ones([n_dense_neurons])
...
...
...
... )
>>>
现在我们需要某种操作和激活函数。
>>> xW = tf.matmul(x,W)
现在输出 z
>>> z = tf.add(xW,b)
现在是激活函数。
>>> a = tf.sigmoid(z)
为了完成图或流程,我们需要在一个非常简单的会话中运行它。
>>> init = tf.global_variables_initializer()
最后,当我们创建一个 session 时,我们传入一个 feed 字典。
>>> with tf.Session() as sess:
... sess.run(init)
... layer_out = sess.run(a,feed_dict={x:np.random.random([1,n_features])})
>>> print(layer_out)
[[ 0.19592889 0.84230143 0.36188066]]
激活函数
我们现在将开始使用激活函数并在 TensorFlow 中实现它。
现在在本节中,我们将实现一个函数并查看我们想要的任何层。
我们通过 Anaconda 提示符进入 Intel 优化的 python 模式。
>>> import TensorFlow as tf
现在我们将实现层函数。对于层,我们应该有输入,这是从上一层处理的信息。使用 in_size 确定输入的大小,这也描述了上一层的隐藏神经元数量。使用 out_layer 显示该层的神经元数量。然后,我们声明激活函数为 None,这意味着我们正在使用线性激活函数。我们必须根据输入和输出大小定义权重。我们将使用随机正态分布生成权重。我们必须传递输入和输出大小。最初,我们使用随机值,因为它能更好地改善神经网络。我们声明一维偏差。我们将其初始化为零并将所有变量初始化为 0.1。它的维度是 1 行和 out_size 列数。由于我们希望将权重添加到偏差中,所以形状应该相同,因此我们使用 out_size。对于操作或计算过程,它是矩阵乘法。
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
print(outputs)
return outputs
Tensorboard
让我们谈谈 Tensorboard。Tensorboard 是一个数据可视化工具,它与 Tensorflow 打包在一起。当我们处理 TensorFlow 中的网络创建时,它由操作和张量组成。当我们向神经网络馈送数据时,数据以张量的形式流动,执行操作并最终获得输出。
创建 Tensorboard 是为了了解模型中张量的流动。它有助于调试和优化。
现在我们将着手创建图,然后在 Tensorboard 中显示它。
我们将执行的基本操作是
- 加法
- 乘法
我们现在从基本的加法操作开始。在下一节中,我们将讨论如何使用基本的加法操作,然后在 Tensorboard 中查看它。下图向我们展示了整个流程,然后我们详细讨论它。

首先,我们需要导入 Tensorflow。
将 tensorflow 导入为 tf。
之后,我们必须声明 placeholder 变量。
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
接下来,我们需要声明需要执行哪些操作。
addition = tf.add(X, Y, name="addition")
在下一步中,我们必须声明 session,因为我们想执行操作,所以我们需要在 session 中执行操作。我们必须使用 init 初始化变量。然后我们必须在 init 中运行 sess。在下一步中,我们必须声明 session,因为我们想执行操作,所以我们需要在 session 中执行操作。我们必须使用 init 初始化变量。然后我们必须在 init 中运行 sess。
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
当我们使用 feed dictionary 运行会话时,我们初始化变量的值
result = sess.run(addition, feed_dict ={X: [5,2,1], Y: [10,6,1]})
最后,使用 Summary writer,我们获取图的调试日志。
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/nono', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/nono", sess.graph)
整个 python 代码库在单个定向流程中如下所示。
import tensorflow as tf
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
addition = tf.add(X, Y, name="addition")
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/nono', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/nono", sess.graph)
现在让我们可视化它。我们将转到 Anaconda 提示符。激活环境并转到文件夹运行 python 文件。

现在我们需要运行 python 文件。
运行以下命令后
(tensorflow-gpu) C:\Users\abhis\Desktop>python abb2.py
获得以下输出

现在打开 Tensorboard
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/nono
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/nono
WARNING:tensorflow:Found more than one graph event per run,
or there was a metagraph containing a graph_def, as well as one or more graph events.
Overwriting the graph with the newest event.
正在 http://0.0.0.0:6006 启动 TensorBoard b'47'
(按 CTRL+C 退出)
现在让我们打开浏览器以访问 Tensorboard。
需要打开以下链接。
图如下所示

对于乘法,也遵循相同的过程,代码库在下面分享
import tensorflow as tf
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
multiplication = tf.multiply(X, Y, name="multiplication")
sess = tf.Session()
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
result = sess.run(multiplication, feed_dict ={X: [5,2,1], Y: [10,6,1]})
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/no1', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/no1", sess.graph)
我们运行 python 文件并使用 Tensorboard 运行它……图如下所示

让我们来一个更复杂的教程,看看 Tensorboard 可视化是如何工作的。我们将使用上面所示的激活函数定义。
现在我们将声明 placeholders
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
我们将添加一个隐藏层,激活函数使用 relu。
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
我们将添加输出层
prediction = add_layer(l1, 10, 1, activation_function=None)
接下来我们将计算误差
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
接下来,我们需要训练网络。我们将使用梯度下降优化器
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
TensorFlow 图中的作用域。当我们处理图维护的层次结构类型时,可能会有很多复杂性。为了使其更有序,我们使用“作用域”。作用域帮助我们轻松区分特定节点或任何函数的工作方式,如果您想单独可视化和调试。要声明作用域,应用以下过程。
with tf.name_scope(‘<name>’):
</name>
<name> 应替换为您给出的作用域名称。应用作用域后的整个代码如下所示
from __future__ import print_function
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediction and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
# tf.train.SummaryWriter soon be deprecated, use following
if int((tf.__version__).split('.')[1]) < 12 and
int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/eg', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/eg", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
现在让我们运行 python 文件,然后启动 Tensorboard。
(tensorflow-gpu) C:\Users\abhis\Desktop>python ab5.py
运行 Tensorboard
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/eg
主要是在运行 Tensorboard 后,图表如下图所示。请注意声明的作用域。

让我们首先展开层,因为其中定义了很多作用域。

红色勾选标记是“layer”作用域内的作用域。
现在让我们展开 weights 作用域。

现在关注偏差作用域。

现在我们将关注 wx_plus_b 作用域

从对作用域的关注中我们看到,标记它们之后,很容易看到图的清晰可视化,当它变得复杂时,这对我们有极大的帮助。
使用 Tensorboard 进行嵌入可视化
当我们在机器学习和深度学习问题中应用算法时,如果我们能够正确可视化算法的工作方式和流程,这将总是有帮助的。
嵌入可视化是 Tensorboard 中神经网络的一个重要功能。
当我们要共享关于图像的大量信息时,我们必须收集关于它的信息。这样,如果我们分析图像,我们收集信息并将其投影到高维向量中。
这些映射实际上被称为投影。Tensorboard 中有两种类型的投影,如下图所示

- PCA(主成分分析)
- PCA 通常用于找出数据的最佳或前 10 个主成分
- t-SNE(T 分布随机邻域嵌入)
所应用的过程试图保持数据集的局部结构,但会扭曲全局结构。
首先,我们必须获取数据集,可以从下面的链接从 Kaggle 网站下载(如果您没有 Kaggle 帐户,则无法下载,请创建它)。
该网站托管文件,如下图所示

我们下载文件并将其解压到一个文件夹中。我们将其保存在桌面上。我们必须记住位置,因为我们必须向 python 文件提供完整的本地链接。
首先,我们将导入您尝试分析的网络的重要依赖项。在我们的例子中,我们缺少 pandas,我们不得不从 anaconda cloud 下载它。
要为 pandas 安装 Anaconda 包,必须在 Anaconda 提示符中输入以下命令。
conda install -c anaconda pandas
然后我们根据需要导入依赖项。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data
下一步是读取我们保存在 *data* 文件夹中的时尚数据集文件。
test_data = np.array(pd.read_csv(r'data\fashion-mnist_test.csv'), dtype='float32')
我们已将嵌入计数设置为 1600,您可以更改并检查。
embed_count = 1600
现在我们已经导入了数据,我们必须将其分成 x 和 y,如下所示
x_test = test_data[:embed_count, 1:] / 255
y_test = test_data[:embed_count, 0]
现在我们需要指定我们将存储日志的目录
logdir = r'C:\Users\abhis\Desktop\logs\eg4'
下一步是设置 Tensorboard 所需的摘要写入器并创建嵌入传感器,如下所示
summary_writer = tf.summary.FileWriter(logdir)
embedding_var = tf.Variable(x_test, name='fmnist_embedding')
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
embedding.metadata_path = os.path.join(logdir, 'metadata.tsv')
embedding.sprite.image_path = os.path.join(logdir, 'sprite.png')
embedding.sprite.single_image_dim.extend([28, 28])
projector.visualize_embeddings(summary_writer, config)
接下来,我们将运行 session 以获取可视化所需的检查点。
with tf.Session() as sesh:
sesh.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sesh, os.path.join(logdir, 'model.ckpt'))
我们将创建精灵和元数据文件以及时尚数据集的标签。
rows = 28
cols = 28
label = ['t_shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle_boot']
sprite_dim = int(np.sqrt(x_test.shape[0]))
sprite_image = np.ones((cols * sprite_dim, rows * sprite_dim))
index = 0
labels = []
for i in range(sprite_dim):
for j in range(sprite_dim):
labels.append(label[int(y_test[index])])
sprite_image[
i * cols: (i + 1) * cols,
j * rows: (j + 1) * rows
] = x_test[index].reshape(28, 28) * -1 + 1
index += 1
with open(embedding.metadata_path, 'w') as meta:
meta.write('Index\tLabel\n')
for index, label in enumerate(labels):
meta.write('{}\t{}\n'.format(index, label))
plt.imsave(embedding.sprite.image_path, sprite_image, cmap='gray')
plt.imshow(sprite_image, cmap='gray')
现在让我们运行 python 文件。
(C:\Users\abhis\Anaconda3) C:\Users\abhis>activate tensorflow-gpu
(tensorflow-gpu) C:\Users\abhis>cd desktop
(tensorflow-gpu) C:\Users\abhis\Desktop>python abhi7.py
接下来我们需要启动 Tensorboard,并提供日志文件的完整路径。
(tensorflow-gpu) C:\Users\abhis\Desktop>tensorboard --logdir=logs/eg4
Starting TensorBoard b'47' at http://0.0.0.0:6006
(Press CTRL+C to quit)
我们打开 Tensorboard 的本地链接。现在,我们需要前往嵌入选项卡。它将如下所示

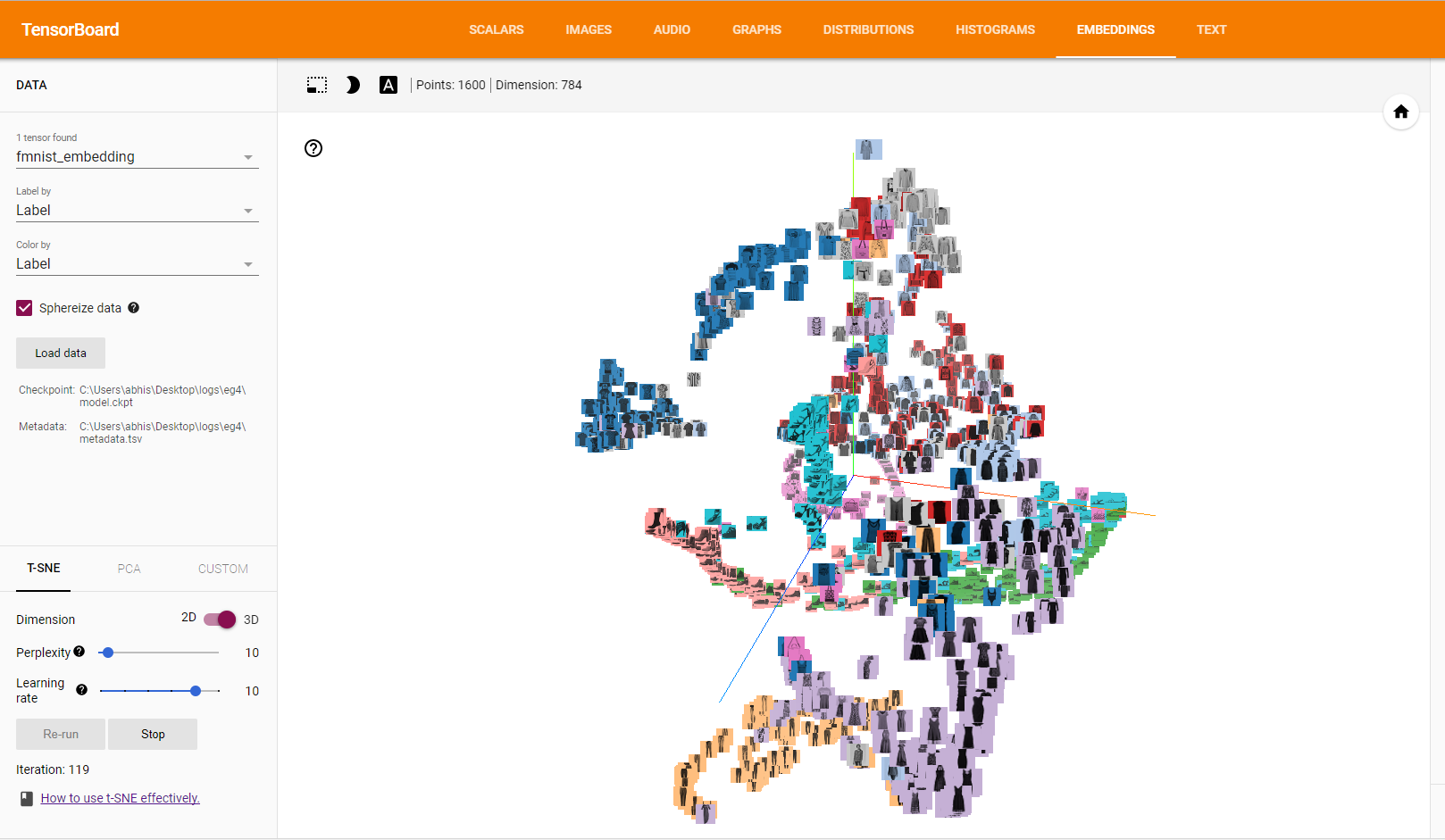
我们目前正在使用 PCA 方法进行可视化,我们也可以切换到 t-SNE。
如果我们想查看彩色索引文件中的对象,需要应用以下方法。

现在它将看起来像这样

当我们将其切换到 t-SNE 时,方法会改变。
结论
在本文中,我们使用 Intel Optimized Python 涵盖了 TensorFlow 的一些基础知识以及它的一些重要功能。完成本文后,我想您将能够理解并实践上面讨论的所有内容。
历史
- V1