
GCloud - Cloud Functions 和 Bulk Load 到 Datastore(PubSub 触发)
0/5 (0投票)
GCloud - Cloud Functions 和 Bulk Load 到 Datastore(PubSub 触发)
这篇博文承接了之前的博文,我们在之前的博文中从 BSE 网站下载文件。本文在此基础上进一步添加了一个函数,用于读取这些文件并将其加载到 Datastore 中。
解决方案
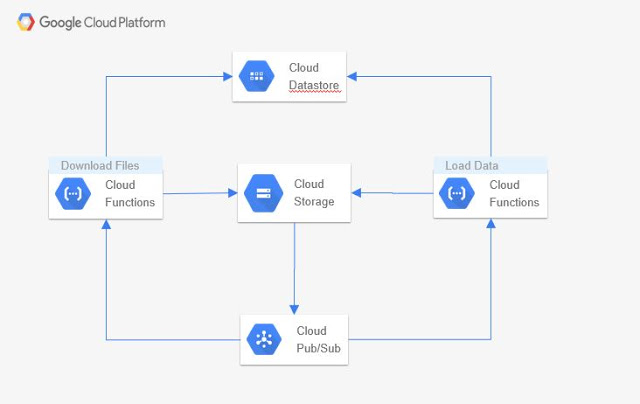
在上一篇文章中,除了“加载数据”功能之外,所有组件都已添加。本篇博文添加并执行了该功能。
我们首先执行代码,然后解释代码。
安装
之前的博文中已经完成了所有必要的设置,我们现在需要做的就是下载函数代码并将其上传到 Google Cloud,然后将其链接到 PubSub 主题。
git clone https://github.com/skamalj/gcloud-functions.git
cd gcloud-functions/load-bhavcopy-data
gcloud functions deploy load_bhavcopy_data --trigger-topic bhavcopy-messages --source .
--runtime python37
清理和执行
如果您遵循了之前的博文,您可能已经在 Datastore 中创建了名为“RecievedFiles”的数据实体。需要从 Datastore 管理控制台删除它。
代码将下载并覆盖云存储中的文件,因此无需从存储桶中删除文件。
现在,像之前的博文一样,通过向云存储存储桶添加一个虚拟文件来触发执行。
您可以在 Datastore 中看到您的数据,如下所示

代码解释
主函数读取事件并将接收到的文件名传递给 lock_and_load 函数。
lock_and_load
- 该函数使用事务 - 第 5 行 - 以确保多个进程不会上传文件,并将一个状态字段添加到实体中,其值为“
Datastore”。 - 另一个重要一点是使用变量 -
load_data。加载数据的过程是 - 从“RecievedFiles”实体读取并锁定文件名,然后将数据加载到“DailyBhavcopy”实体中。这涉及多个实体,而 Datastore 不支持在一个事务中处理多个实体。因此,使用外部变量,可以在事务范围内设置 - 第 11 行 - 用于锁定,然后在退出事务后使用其值 - 第 12 行 -。
def lock_and_load(fname):
client = datastore.Client(project='bhavcopy')
load_data = False
try:
with client.transaction():
key = client.key('RecievedFiles', fname)
row = client.get(key)
if (row is not None) and ('status' not in row):
row['status'] = 'Datastore'
client.put(row)
load_data = True
if load_data:
store_data(fname)
logging.info('Data loaded in datastore for ' + fname)
else:
logging.info('No database entry for file or it is already loaded: ' + fname)
except Exception as e:
logging.info("Cannot start transaction for loading file "+ fname + ".Recieved error:" + str(e))
Store_data - Datastore 批量插入
- 此函数解析文件名,然后从存储中读取文件并解压缩它。这段代码没有在代码块中显示。
- 标题列从文件中的第一行推断出来,并添加了“
File_Date”列 - 在此函数中,我们首先将所有数据加载到内存中
- 第 1 行以下创建并清空数组
- 从第 11-17 行,我们创建单行
- 然后将此行附加到数组 - 第 20 行
- 因此,当循环退出时,文件中的所有数据都转换为数组中的实体行。
- 我们这样做是为了避免由于大量单行写入而导致性能和争用问题。
- 相反,我们使用
put_multi- 第 25-27 行 - 一次插入 400 行,这很有效。最大支持值为 500。
bhavcopy_rows = []
# First line of each file is header, we collect column names from this line and then for each
# subsequent row entity is created using file header fields as column names.
for line in data:
if not header_read:
headers = line.split(',')
header_read = True
else:
row_data = line.split(',')
bhavcopy_row = datastore.Entity(client.key('DailyBhavcopy',row_data[1]+'-'+extracted_date))
bhavcopy_row['FILE_DATE'] = file_date
for i in range(12):
if i in (1,2,3):
bhavcopy_row[headers[i]] = str(row_data[i]).strip()
else:
bhavcopy_row[headers[i]] = float(row_data[i].strip())
# Do not use extend() function, it changes the entity object to string.
bhavcopy_rows.append(bhavcopy_row)
logging.info('Collected '+str(len(bhavcopy_rows))+' rows from '+fname)
# Bulk insert has limied to maximum 500 rows, hence this block
for i in range(0,len(bhavcopy_rows),400):
client.put_multi(bhavcopy_rows[i:i+400])
logging.info(fname+": "+ "Storing rows from " + str(i) +" to "+ str(i+400))
历史
- 2019 年 1 月 21 日:初始版本