
数据科学——生命周期之旅。第一部分
4.94/5 (9投票s)
本文探讨了数据科学的生命周期——业务理解、数据理解和数据准备
引言
大家都在谈论数据科学及其不同的步骤和阶段。本文将探讨数据科学的生命周期、各个阶段(每个生命周期中的步骤),并将是数据科学初学者踏上数据科学之旅的绝佳起点。
数据科学生命周期
根据其简单定义,数据科学是一个多学科领域,包含多个过程,用于从输入数据中提取知识或有用输出。输出可能是预测性或描述性分析、报告、商业智能等。数据科学拥有与其他任何项目类似的明确定义的生命周期,CRISP-DM 和 TDSP 是经过验证的一些标准。
CRISP–DM:跨行业标准数据挖掘流程
TDSP:Microsoft 的团队数据科学流程
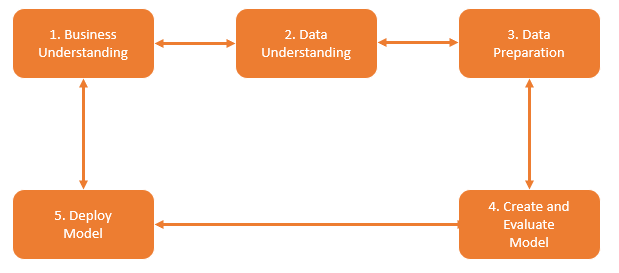
让我们来了解一下数据科学中的常见生命周期
- 业务理解
- 数据理解
- 数据探索与准备
- 创建和评估模型
- 部署模型并产生有效输出
每个生命周期都有不同的步骤和规则来实现期望的输出。每个生命周期的多次迭代和每个周期中的不同组件使得数据科学输出更加准确。在本文中,我们将讨论数据科学生命周期中的前 3 个阶段——业务理解、数据理解和数据探索与准备。
业务理解
业务理解在任何 SDLC 中始终是一个关键阶段,但在数据科学生命周期中更为关键。如果我们误解了业务,最终的输出将会是错误的,或者即使我们预测了良好的输出,客户也可能无法接受。此阶段的主要步骤是:
识别利益相关者
利益相关者是业务分析师/专家,他们的职责是澄清数据科学家在数据科学生命周期的任何阶段提出的所有业务查询。
设定目标
理解业务问题,并确定该问题是否适用于分析解决方案,换句话说,数据科学是否可以解决业务问题。为此,数据科学家通过向利益相关者提出相关且尖锐的问题来构建业务目标。请参考这篇博客,了解一些需要向利益相关者提出的相关问题。
完成此步骤后,数据科学家将总结:
-
正确的业务需求并定义需求,例如——如何将业务利润从 50 提高到 100 / 如何防止客户流失率等。
-
根据业务需求识别数据科学问题类型,并找到一些数据科学问题类型。
数据科学问题类型
| 预测分析 | 未来会发生什么? |
| 描述性分析 | 过去和现在发生了什么? |
| 规定性分析 | 应该做什么来改善或防止当前或未来的发生? |
识别和定义目标变量
每个数据科学项目都包含监督学习或无监督学习数据。
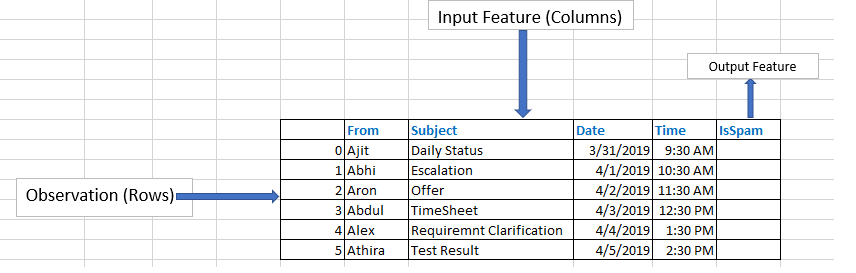
监督学习——在监督学习中,数据科学家识别输入和输出(目标)特征。监督学习有 2 种类型。
-
分类问题
-
二元分类——识别的目标特征值是
0或1。例如——人们是否生存,这封邮件是否为垃圾邮件等。 -
类别分类——识别的目标特征值包含多个离散值。例如——产品如何被不同类别标记。
-
-
回归问题——识别的目标特征值是连续类型。例如——不同类型汽车的预期里程。
无监督学习——在未给出正确输出特征的情况下学习数据,主要侧重于数据的分组或聚类。例如——从视频视觉中识别人类行为。
数据科学项目执行计划
使用 VSTS、JIRA 等项目管理工具,创建项目执行计划,并跟踪数据科学生命周期不同阶段的每个里程碑和可交付成果。
数据理解
此阶段的主要步骤是:
收集适当的数据集
数据科学家收集适当的数据集,涵盖所有业务目标,并确保数据集包含回答所有业务问题的必需输入特征。数据可能存储在 CSV 文件、数据库或不同的格式和存储介质中。我们可以通过数据流使用安全的 API 来访问所有数据并从其源下载。
设置数据环境
在数据科学家收集数据集后,设置数据托管环境。该环境可能是本地计算机、云或本地部署等。云环境的例子是——Azure Blob 存储、Azure SQL 数据库。
此外,有时数据可能是非结构化的,在进行分析之前需要将其转换为结构化格式。
请参阅 Azure 环境。
- Azure Notebooks - 免费订阅,支持多个目标环境,网址是 - https://notebooks.azure.com/
- 数据科学虚拟机 (DSVM) / 深度学习虚拟机(IaaS 解决方案)- 预先配置了不同工具并在 Azure 上预先安装的定制虚拟机
- 基于云的 Notebook VM
- ML Studio - Microsoft 的 UI 驱动工具 - https://studio.azureml.net/
- ML Service - PaaS 解决方案
设置工具和包
设置用于数据处理的工具并安装包。请参阅 DS 中使用的一些工具——Python、R、Azure 机器学习环境、SQL 和 RapidMiner、TensorFlow 等。每个工具中都有多个包可用于处理、操作和可视化数据。Panda 和 Numpy 是 Python 的一些主要包。
识别特征类别
数据集中的每个特征大致分为分类(对于 string 类型)或连续(对于数字类型)类型。分类类型进一步分为——有序和二元。
| 特征类型 | 描述 |
| 分类(或名义) | 一个或多个类别,但不是定量值。例如——颜色,其值为红色、绿色、黄色等,与其他颜色相比没有数值意义。 |
| Ordinal | 一个或多个类别,但与其他类别相比是可量化的。例如—— Bug 优先级,其值为低、中、高和严重,与其他人相比,这些值具有数值意义。 |
| 二进制 | 此特征的值应为 1 或 0。例如——男性或女性 |
| 连续 | 负无穷到正无穷之间的值。例如:年龄 |
此外,还有一些其他特征类型,如——区间、图像、文本、音频和视频。
数据探索与准备
此阶段的主要步骤是:
数据探索
在此阶段,数据科学家熟悉数据集中的每个特征,包括:识别特征类型(如分类、连续等)、数据分布情况、是否存在两个特征之间的关系等。
数据科学家使用不同的可视化工具来探索数据,此步骤有助于在数据准备阶段修复——缺失值、极端值(异常值)和噪声值,并在模型创建步骤中确定适当的缩放因子。在这里,我们主要关注两种特征类型——分类(假设所有字符串类型)和连续(用于数字类型)。让我们讨论数据探索中的不同方法。
数据探索 - 连续特征类型
- 检查中心趋势度量数据 - 总结特定特征测量的最佳值
- 检查离散度度量 - 数据如何分布及其特定特征的分布
| 平均 | 平均值,但受极端值影响 |
| 中位数 | 排序列表的中心值,不受极端值影响,当然,如果数据存在极端值,中位数是最佳的中心趋势度量。 |
检查中心趋势度量数据
| Range | 最大值和最小值之间的差值,如果差值很小,则数据紧密聚集,否则数据分布广泛。 |
| 箱线图 | 此图显示了数据的分布情况,并以不同的百分位数表示,例如 25%、50%、75%、最小值和最大值。此图还显示了任何较低和较高的异常值。例如:对于具有 1000 个值的 Age 特征,如果 25% 为 32,则意味着 25% 的值小于 32。
|
| 方差 | 表示每个值与均值的距离。小的方差意味着数据紧密聚集,否则则广泛聚集。 |
| 直方图 | 此图表示数据在不同 bin 中的分布情况,这将有助于识别异常值和缺失值。从直方图中,我们可以识别——数据正态分布(偏度 = 0)、正偏分布和负偏分布。
|


离散度度量
数据探索 - 分类特征类型
以下选项用于分类特征类型的数据探索。
- 类别的总计数
- 类别的唯一计数
- 条形图用于显示各个类别的状态
此外,散点图、分组、交叉表和透视表以及其他统计函数可用于探索连续和分类数据。每种数据科学语言都有许多可用的框架和包,用于实践上述任何一种方法。散点图(检查两个特征之间的关系)和折线图(用于时间序列数据)是数据探索的其他选项,主要用于高级数据分析。
IDEAR 和 AMAR 是用于数据探索的自定义构建的实用程序,这些实用程序根据其类型为每个特征提供清晰的数据洞察报告。
数据准备
根据数据探索,可以识别出一些异常行为,例如——缺失数据、极端值(异常值)和噪声数据。这些行为可能会影响数据科学输出的准确性,建议在创建模型之前进行修复。
- 删除不相关的特征 - 删除对数据分析没有影响的特征,如姓名、学号等。
- 修复缺失值
- 删除包含缺失特征的行(观测值)
- 插补
- 使用均值、中位数或范围等可能的值替换缺失值
- 用虚拟值替换缺失值
- 用最常见的值替换,这对于类别特征类型更适用
- 向前填充或向后填充,尤其是对于时间序列数据
- 修复异常值(极端值)- 可以通过直方图、箱线图或散点图识别异常值
- 删除包含缺失特征的行(观测值)
- 插补
- 使用均值、中位数或范围等可能的值替换缺失值
- 用虚拟值替换缺失值
- 用最常见的值替换,这对于类别特征类型更适用
- 分箱 - 从连续特征创建离散类别,这将有助于将异常值放置在任何一个 bin 中。
-
修复错误或噪声值 - 使用与修复异常值相同的方法
-
文本清洗 - 清理文本数据中的 Enter、Tab 等字符。
在某些情况下,无法修复缺失或异常值,因此数据科学家会创建两个模型——一个模型排除缺失数据和异常值,另一个模型使用所有数据,然后取两者的平均结果作为输出。
特征工程
将数据转换为另一种更易于理解的特征,以创建更好的预测模型的过程。特征工程是任何数据科学旅程中的关键步骤,没有适当的领域知识就无法实施。
例如:从 Age 特征派生一个名为 IsAdult 的新特征,例如,如果 Age > 18,则 IsAdult = 1,否则 0。
分类特征编码
大多数机器学习算法都基于数值数据,而不是分类数据。因此,数据科学家需要将分类类型特征转换为连续特征。
可以根据特征类型使用以下方法从分类特征转换出连续特征。
二元编码——如果 Category 特征只有 2 个值,例如——Male/Female,则使用此方法。在这种情况下,数据科学家会创建一个名为 Is_Male 的新特征,其值为 0 或 1。
标签编码——如果 Category 值类型是序数类型,即特征值具有清晰的内在排序顺序,则使用此方法。例如:软件 Bug 严重性 - Low、Medium、High 和 Critical。在这里,数据科学家为 Low 到 Critical 的值创建 1 到 4。
独热编码——用于名义类别类型。例如——Color,其值为 Red、Blue 和 Green。在这里,我们需要创建 3 个特征,如——color_red、color_blue 和 color_green,并相应地填充值。

到目前为止,我们已经涵盖了数据科学的 3 个重要生命周期——业务理解、数据理解和数据准备,现在数据已经准备好进行模型创建。我将在下一篇文章中讨论另外两个生命周期,并请求您宝贵的反馈。
关注点
熟悉数据科学术语,如——监督学习、特征工程等,是数据科学旅程中最重要方面之一。
在本文中,我涵盖了前 3 个生命周期中的大多数定义,但建议阅读一些其他定义,如数据相关性、数据整理、数据因子化和归一化以及高级统计函数等。
感谢阅读本文。
历史
- 2019 年 4 月 29 日:第一个版本
- 2019 年 11 月 26 日:添加了 Azure 环境