
使用 RavenDB 中的索引进行数据建模
在本文中,我们将介绍如何利用 RavenDB 索引实现比创建高性能查询更多的功能。
引言
RavenDB 是一款跨平台的高性能 NoSQL 文档数据库。在本文中,我们将介绍如何利用 RavenDB 索引实现比创建高性能查询更多的功能。
在传统的关系型数据库中,索引用于优化数据库读取数据的方式,从而提高查询性能。例如,如果您有一个“产品”表,并且想要执行“按名称获取产品”的查询,您可能会在“名称”列上添加索引,以便数据库知道要创建查找。这使得数据库能够更快地按名称查找您的产品,因为它不需要执行完整的表扫描查找,而是可以利用索引。
在数据建模方面,关系型数据库中的索引通常不包含在内。然而,在 RavenDB 中,索引不仅用于提高查询性能,还用于使用 map/reduce 转换和数据集合上的计算来执行复杂的聚合。换句话说,索引可以转换数据并输出文档。这意味着在为 RavenDB 进行数据建模时,可以且应该将它们考虑在内。
Raven 中的索引如何工作?
索引定义存储在您的代码库中,然后部署到数据库服务器。这允许您的索引定义进行源代码控制,并与您的应用程序代码并排存在。这也意味着索引与利用它们的应用程序版本相关联,从而简化了升级和维护。
索引可以用 C#/LINQ 或 JavaScript 定义。在本文中,我们将使用 JavaScript 来展示 RavenDB 的这项功能。值得注意的是,JavaScript 对索引的支持最高支持 ECMAScript 5,但随着 RavenDB 使用的 JavaScript 运行时在不久的将来增加对 ES2015 语法的支持,这将有所提高。
计算订单总额
为了理解基本索引,让我们首先看一个定义索引以查询电子商务网站产品订单的简单示例。
在数据库中,您可能有一个“订单”文档

让我们创建一个新索引以允许按客户查询并计算订单总额。索引可以使用 map 和 reduce 函数定义 - 整个索引定义会更大,但在本文中,我们将只关注核心的 map/reduce 函数。

map("Orders", order => {
return {
Customer: order.Customer
}
})
此索引是一个“map”索引,它接受文档并将其转换为输出索引结果。此索引选择“Orders”集合上的“Customer”属性。
这将允许我们发出查询以查找特定客户的所有订单

from index 'Orders' as o
where o.Customer == 'Customers/101-A'
这使用的是 RavenDB 查询语言 (RQL),它类似于 .NET 中的 LINQ 或 SQL,但查询中使用 JavaScript 表达式。在这种情况下,我们正在查询我们创建的 map 索引以按特定客户 ID 查找订单。
现在,让我们添加一个表示来自Order.LineItems的订单总额的计算属性

map("Orders", order => {
return {
Customer: order.Customer,
Total: order.LineItems.reduce(
(sum, x) => x.Quantity * x.Price + sum, 0)
}
})
现在,我们在索引中添加了一个新的“Total”计算字段。如您所见,我们正在利用标准的 JavaScript 对 reduce 数组函数进行支持,以对订单行项进行求和。
在索引时计算订单总额允许 RavenDB 快速响应查询,而无需实时执行订单总额计算。这种计算能力可以进一步扩展以执行更复杂的聚合。
计算年度总额
到目前为止,我们已经看到了一个带有计算字段的简单 map 索引的示例。RavenDB 还支持 map/reduce 索引,这些索引提供了跨映射索引文档执行聚合操作的能力。
也许我们想知道一年中所有订单的总收入,此外,我们还想知道平均订单总额是多少。
首先,在 map 函数中,我们需要包含一些新的字段以进行聚合,包括存储在OrderedAt文档属性中的订单年份

map("Orders", order => {
return {
Year: new Date(order.OrderedAt).getFullYear()
Customer: order.Customer,
AverageTotal: 0,
OrderCount: 1,
Total: order.LineItems.reduce(
(sum, x) => x.Quantity * x.Price + sum, 0)
}
})
如果您注意到,我们需要在 map 函数中添加AverageTotal和OrderCount,因为在 RavenDB 中,map-reduce 函数的输出结果必须匹配。通过在 map 阶段将OrderCount设置为 1,它充当计数器,我们可以在 reduce 阶段使用它来查找平均值。
现在,我们将添加一个发生在map之后的reduce转换

groupBy(order => order.Year)
.aggregate(group => {
var year = group.key;
var count = group.values.reduce((sum, x) => x.OrderCount + sum, 0);
var total = group.values.reduce((sum, x) => x.Total + sum, 0)
return {
Year: year,
Total: total,
OrderCount: count,
AverageTotal: total / count
}
})
这更有趣!首先,我们按年份分组,因为我们需要一个键来进行聚合。然后,我们对订单数量和总金额进行求和以获得年度聚合。最后,我们使用这两个计算来填充AverageTotal。
还记得前面 RavenDB 允许您从代码部署索引吗?虽然在数据库中执行 JavaScript 可能听起来像是回到了关系型风格的存储过程,但这些代码仍然存在于您自己的代码库中,并受到与您的应用程序代码相同的构建、审查和部署流程的影响。此外,RavenDB 能够引用外部脚本,这些脚本将在执行期间作用于索引定义。
预测未来
使用 map-reduce 索引跨文档聚合数据是一项强大的功能,但前面的示例暗示了使用日期计算的 RavenDB 索引的真正潜力。
与其将自己限制在计算历史总额和平均值,不如让索引使用它聚合的数据来预测我们可以查询的未来数据?
让我们从管理订单转移到管理客户订阅。在此示例中,我们提供了一项订阅服务,客户可以按月或按年付费。我们希望知道未来 3 个月的预测收入,使用过去 3 个月的历史数据,以便轻松查询并在一些业务报告或甚至实时网站上显示。
我们存储的客户文档包含客户自成立以来的所有过往付款,我们将使用这些付款进行聚合并预测未来。

{
"Name": "Sam Samson",
"Status": "Active",
"Subscription": "Monthly",
"Payments": [
{ "Date": "2019-01-01", "Amount": 58 },
{ "Date": "2019-02-01", "Amount": 48 },
{ "Date": "2019-03-01", "Amount": 75 },
{ "Date": "2019-04-01", "Amount": 42 },
{ "Date": "2019-05-01", "Amount": 34 }
]
}
在我们未来的收入索引中,我们需要将客户付款映射到可用于聚合的结果。我们的目标是基于客户的订阅类型(月付或年付)和过去 3 个月的平均值来“预测” 3 次未来付款,并在索引的任何查询中返回它们。

map("Customers", cust => {
// Reverse the array
var latestPayments = cust.Payments.reverse();
// Determine last payment date and components
var lastPayment = latestPayments[0];
var lastPaymentDate = dayjs(lastPayment.Date);
// Average of up to last 3 payments
var recentPayments = latestPayments.slice(0, 3);
var recentAmount = recentPayments.reduce(
(sum, x) => x.Amount + sum, 0);
// Generate next 3 payments based on subscription type
var futurePayments = [1, 2, 3].map(i => {
var nextPayment = cust.Subscription === "Monthly"
? lastPaymentDate.add(i, 'month')
: lastPaymentDate.add(i, 'year');
return {
Date: nextPayment.toDate(),
Amount: recentAmount / recentPayments.length
}
});
return cust.Payments.concat(futurePayments).map(payment => {
return {
Date: new Date(payment.Date),
Amount: payment.Amount
}
})}
)
使用 JavaScript 和 RavenDB 允许您“添加其他源”,在这种情况下,我们利用了轻量级的 Day.js 日期辅助库 来简化日期操作。这包括一个全局范围的模块,我们可以在索引函数中引用它。
这个 map 函数比以前的例子要复杂得多,但它的基本原理仍然很简单
- 从最后一个记录的付款日期开始,创建 3 条新的未来日期付款记录
- 根据订阅类型,取过去 3 个周期的付款并对其进行平均,以用作下 3 个周期的预测付款
- 将额外的付款连接到客户付款
- 映射一个新的索引结果,包含付款日期和金额
索引结果不是不可变的,可以像这样进行转换,以根据需要分割和切片数据。在这种情况下,我们基本上为客户的付款生成了 3 条新的付款记录。这些付款记录不会保存在“Customer”文档中,但它们将在索引结果和对索引的任何查询中可用。
您可能会注意到,我们为每个客户文档生成 N+3 个付款结果——这在 RavenDB 中被称为“扇出”索引,确实需要仔细考虑,因为无界结果集可能导致性能下降。
到目前为止,这个索引将告诉我们个人客户的预测付款是多少,但现在我们可以添加一个索引的缩减阶段,以便更全面地了解未来 3 个月所有的预期付款。

groupBy(payment => payment.Date)
.aggregate(group => {
return {
Date: group.key,
Amount: group.values.reduce((sum, x) => x.Amount + sum, 0)
}
})
reduce 阶段要小得多。我们使用付款日期作为键,通过它计算 map 阶段包含的每个月的预期付款总额。这将告诉我们想要知道的内容:当前的付款加上 3 个月的预测。
使用传统的查询方法实时执行此操作将非常耗时,但借助 Raven 的后台索引,对该索引的查询速度极快,可用于创建实时报告。

使用事件溯源构建购物车
到目前为止,我们已经看到了 RavenDB 索引能够执行 map 转换以及对每个 map 结果进行更复杂的聚合的示例。最后一个示例将更进一步,我们将看到如何从事件序列(也称为事件溯源)构建全新的域模型。
首先,让我们在熟悉的场景中从概念上解释事件溯源如何工作:购物车。当用户将商品添加到购物车、从购物车中移除商品并结账时,这些操作可以被视为“购物”实体状态的变异。然而,将用户的购物车存储为单个实体可能很复杂,因为系统之间存在各种交互,例如地址检查、验证、供应链和应付账款。您是否需要将整个购物车作为对象跨服务边界传递?在微服务架构中,这将是一个巨大的痛苦。
相反,像事件溯源这样的模式可以帮助您以不同的方式思考购物车,而不是将其视为单个对象,而是将其视为某个时间点的状态。与其认为每个用户操作都会变异某个域实体一次,不如考虑操作本身。当用户将商品添加到购物车时,您可以记录一个“AddToCart”事件。如果他们移除商品,则为“RemoveFromCart”,当他们最终付款时,则为“PayForCart”事件。当您为用户会话重放这些事件,一次构建一个状态时,最终您将获得用户购物车的表示。这些事件仍然可以触发下游系统中的其他事件,而无需共享复杂的购物车上下文。这带来了许多额外的好处,例如提供购物车的审计历史记录、仅凭事件流从头开始重建购物车、报告添加商品的价格变动以及允许多个事件消费者。
这是我们接下来将通过 RavenDB 索引进行的示例。像AddToCart、RemoveFromCart和PayForCart这样的事件将表示为与用户关联的单个文档,如下所示





{
"Product": "products/12-A",
"Cart": "carts/294-A",
"Quantity": 1,
"Price": 17.4,
"@metadata": {
"@collection": "AddItemToCart"
}
}
{
"Product": "products/12-A",
"Cart": "carts/294-A",
"Quantity": 1,
"Price": 17.4,
"@metadata": {
"@collection": "AddItemToCart"
}
}
{
"Product": "products/21-A",
"Cart": "carts/294-A",
"Quantity": 1,
"@metadata": {
"@collection": "RemoveItemFromCart"
}
}
{
"Cart": "carts/294-A",
"Paid": 0.5,
"Method": "Cash",
"@metadata": {
"@collection": "PayForCart"
}
}
{
"Cart": "carts/294-A",
"Paid": 20,
"Method": "Visa",
"@metadata": {
"@collection": "PayForCart"
}
}
购物车中添加了一些产品,调整了数量,然后为购物车进行了一些付款。这是一个事件流,我们可以用它来构建购物车状态。
我们希望从索引生成的最终购物车模型看起来像这样

{
"Cart": "carts/294-A",
"Products": {
"products/12-A": {
"Quantity": 1,
"Price": 17.4
},
"products/21-A": {
"Quantity": 1,
"Price": 3.1
}
},
"Paid": {
"Cash": 0.5,
"Visa": 20
},
"TotalPaid": 20.5,
"TotalDue": 20.5,
"Status": "Paid"
}
为了将这些单个文档组合成这个最终的购物车模型,我们将首先映射我们期望的购物车输出形状。请记住,索引中的每个 map/reduce 转换都必须具有相同的输出形状,因此我们将使用扁平化的事件数据在 map 中初始化一个“空”购物车模型。
首先,我们将处理“AddToCart”事件

map("AddItemToCart", event => {
var products = {};
products[event.Product] = {
Quantity: event.Quantity,
Price: event.Price
};
return {
Cart: event.Cart,
Products: products
};
});
此 map 函数包含更多逻辑。我们使用字典存储要添加的产品,以便轻松执行高效的 O(1) 查找。RavenDB 对索引步骤可以评估的语句数量有可配置的保护措施,因此我们需要小心并确保我们的逻辑是高效的。
看起来我们正在覆盖重复产品的产品字典,但这是map阶段,因此每个事件文档都将输出上面形状的单个结果。
下一步是使用“Cart”作为分组键来合并这些不同的字典。在这里,我们将负责增加数量或重用现有的产品字典条目。

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
return {
Cart: g.key,
Products: products
};
})
在 reduce 步骤中,我们通过迭代每个 map 结果对象来构建一个新的“agg”聚合对象。如果产品键不存在于聚合中,我们就直接存储 map 结果。如果它确实存在,我们需要做两件事:a) 增加数量,b) 选择最低价格。选择最低价格实际上是一项业务规则,我们决定,如果客户在结账前多次添加同一产品,我们只反映最低价格。
现在我们在索引中同时拥有 map 和 reduce 操作——但我们只处理了一种类型的事件。我们需要处理“RemoveFromCart”和“PayForCart”事件。RavenDB 允许索引具有多个 map 操作(“multi-map”索引),这就是我们现在要利用的。
现在可以添加映射“RemoveFromCart”的附加 map 操作

map("RemoveItemFromCart", event => {
var products = {};
products[event.Product] = {
Quantity: -event.Quantity,
Price: 0
};
return {
Cart: event.Cart,
Products: products
};
});
但这会改变我们的 reduce 逻辑。我们需要确保当购物车字典的数量达到 0 时删除产品;记住这是一个事件流,所以操作可能以任何顺序发生。由于我们还使用 Math.min 来查找最低价格,而“RemoveFromCart”事件将价格设置为零,因此在这种情况下我们需要忽略更新价格。
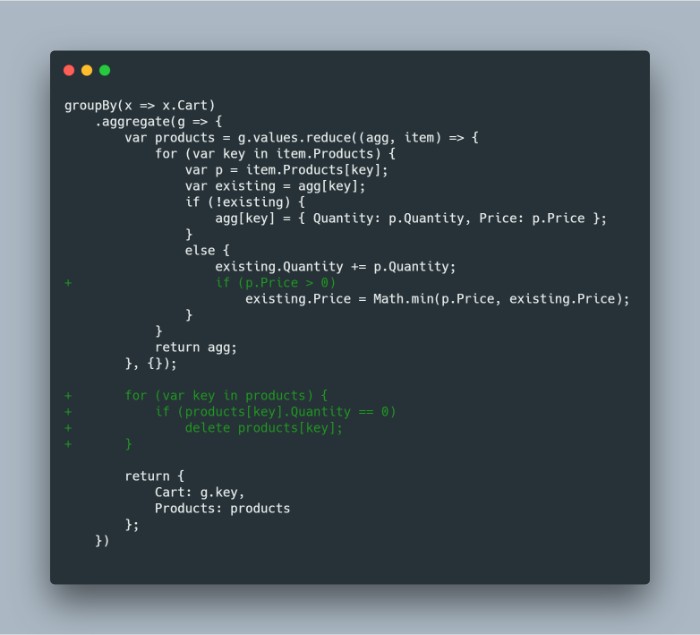
groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if (p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
for (var key in products) {
if (products[key].Quantity == 0)
delete products[key];
}
return {
Cart: g.key,
Products: products
};
})
最后,我们需要处理“PayForCart”事件,我们将创建另一个 map 函数来处理它

map("PayForCart", event => {
var paid = {};
paid[event.Method] = event.Paid;
return {
Cart: event.Cart,
Products: {},
Paid: paid
}
});
注意结果对象中新增的“Paid”属性。这也意味着我们需要更新其他 map 函数以包含一个空的 Paid 字典(同样,以便所有输出形状都匹配)。
在 reduce 函数中,我们将为购物车包含聚合付款信息

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if(p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
for (var key in products) {
if(products[key].Quantity == 0)
delete products[key];
}
var paid = g.values.reduce((agg, item) => {
for (var key in item.Paid){
agg[key] = item.Paid[key] + (agg[key] || 0);
}
return agg;
}, {});
return {
Cart: g.key,
Products: products,
Paid: paid
};
})
现在我们将付款方式和金额的字典存储在聚合对象上。
最后一步是包含我们想要计算的最终购物车属性:TotalPaid、TotalDue和Status(客户是否全额支付了商品)。

groupBy(x => x.Cart)
.aggregate(g => {
var products = g.values.reduce((agg, item) => {
for (var key in item.Products) {
var p = item.Products[key];
var existing = agg[key];
if (!existing) {
agg[key] = { Quantity: p.Quantity, Price: p.Price };
}
else {
existing.Quantity += p.Quantity;
if(p.Price > 0)
existing.Price = Math.min(p.Price, existing.Price);
}
}
return agg;
}, {});
var totalDue = 0
for (var key in products) {
if(products[key].Quantity == 0)
delete products[key];
else
totalDue += products[key].Quantity * products[key].Price;
}
var paid = g.values.reduce((agg, item) => {
for (var key in item.Paid){
agg[key] = item.Paid[key] + (agg[key] || 0);
}
return agg;
}, {});
var totalPaid = 0;
for (var key in paid) {
totalPaid += paid[key];
}
return {
Cart: g.key,
Products: products,
Paid: paid,
TotalPaid: totalPaid,
TotalDue: totalDue,
Status: totalPaid === totalDue ? "Paid" : "Pending"
};
})
新字段使用聚合数据计算并包含在输出中。
就这样!这一切有什么用?
- 关键概念是,通过将事件建模为文档,索引可以使用 map 和 reduce 操作的组合,从事件流中逐步构建数据模型。
- 由于 map/reduce 等索引操作可以并行化并在后台运行,因此这种方法可以从几十个到数万个事件进行扩展。
- 购物车模型输出必须跨 map/reduce 操作匹配形状,虽然这乍一看可能看起来很奇怪,但它是一种强大的技术
现在我们可以查询索引来过滤和选择购物车,如下所示


但是等等,还有更多!

将索引 reduce 结果存储为文档
RavenDB 允许您将索引结果保存为一种人工集合中的物理文档。每次索引运行时,结果都会像您从应用程序创建的任何文档一样被存储为文档。这意味着我们不仅可以使用索引生成新的域实体,还可以反过来创建其他使用这些相同存储文档的索引。
我们将通过选中将索引 reduce 结果存储为集合的选项开始

新文档的外观将与上一节所示的输出完全相同。

文档的 ID 是 reduce 键(在此例中为购物车 ID)的哈希,因此相同的索引购物车结果将被保存到同一个文档中。RavenDB 还在文档元数据中将该文档标记为来自索引的人工文档。
由于我们可以像操作其他文档一样操作这些文档,我们将创建一个新的“按产品销售”索引,该索引返回按产品细分的销售额,跨购物车聚合

// Map
map("ShoppingCarts", cart => {
var results = [];
if (cart.Status !== "Paid") {
return results;
}
return Object.keys(cart.Products).map(product => {
var sale = cart.Products[product]
return {
Product: product,
Amount: sale.Quantity * sale.Price
}
});
});
// Reduce
groupBy(x => x.Product)
.aggregate(g => {
return {
Product: g.key,
Amount: g.values.reduce((sum, p) => p.Amount + sum, 0)
}
});
此索引遍历每个购物车文档(由上面的另一个索引生成),并按产品汇总金额,使我们能够查询销售数据而无需任何额外事件。
本质上,这使您能够构建动态生成自事件的文档,然后从应用程序中将该聚合数据读取为域实体。这种模式适用于单个数据库,但也能够实现高度分布式的场景。例如,设计一个使用仅写入事件数据库的架构,并使用 Raven 的 ETL 功能 复制文档到只读查询/报告 RavenDB 实例或关系数据库。这将使您能够利用 Raven 的高级索引功能进行写入,然后输出到只读数据库以供应用程序进行报告/查询。
处理时间敏感事件
在事件溯源场景或任何需要基于时间逻辑的索引场景中,一个常见的问题是如何处理事件的“顺序”。由于 RavenDB 是一个分布式数据库,在索引过程中处理文档的顺序没有保证。然而,在许多场景中,处理基于时间事件只需要重新调整思维方式,使其适应 RavenDB 处理索引的方式——您可能会发现文档的实际顺序并不重要。
一套熟悉的基于时间事件是偿还抵押贷款。在这种情况下,付款应用的时间非常重要。由于我们不能依赖处理文档的顺序,因此我们需要以不同的方式处理情况。
抵押贷款很复杂,有很多不同的阶段,但我们只关心其中两个阶段
- 批准 - 抵押贷款已创建,包含年利率、期限和本金金额
- 提款 - 取出资金时,这可能分期进行
由于抵押贷款的还款有不同的条款和许多因素,如一次性还款、滞纳金或仅本金还款,我们将按月计算下个月的预期还款金额。抵押贷款创建和预期还款将是系统中的两种事件类型,以及实际还款应用的第三种事件。
首先,我们将有一个“MortgageCreated”事件

{
"APR": 4.85,
"Address": {
"City": "Seattle",
"Country": "United States",
"Line1": "One Mortgage Way",
"State": "WA"
},
"DurationMonths": 216,
"Property": "properties/293994-C",
"TotalAmount": 364000,
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgageCreated"
}
}
这包括抵押贷款的期限、年利率和本金金额的详细信息。
一旦我们计算出预期还款额,它的结构看起来就像

{
"Amount": 444.77,
"DueBy": "2018-02-28T00:00:00Z",
"Interest": 258.67,
"Principal": 186.11,
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "PaymentExpected"
}
}
然后,已应用的付款事件将如下所示

{
"Amount": 229.66,
"DueBy": "2018-02-05T00:00:00Z",
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgagePayment"
}
}
这些是简化的示例,但它们展示了处理基于时间事件的情况。
如果我们已经进入抵押贷款几个月,那么预期的还款可能会看起来像

然后是客户实际应用的付款

让我们定义 map/reduce 索引以按月聚合付款。这将遵循我们之前的示例,为每个事件创建一个map操作,然后是一个最终的 reduce 操作,所有这些操作都具有相同的最终结果形状

map("PaymentExpected", event => {
return {
Mortgage: event.Mortgage,
DueBy: event.DueBy.substring(0, 7),
InterestDue: event.Interest,
PrincipalDue: event.Principal
}
});
map("MortgagePayment", event => {
return {
Mortgage: event.Mortgage,
AmountPaid: event.Amount,
DueBy: event.DueBy.substring(0, 7)
}
});
function normalize(r) {
return parseFloat(r.toFixed(3));
}
function sum(g, fetch) {
var r = g.values.filter(x => fetch(x) != null)
.reduce((acc, val) => acc + fetch(val, 2), 0);
return normalize(r);
}
groupBy(x => ({ Mortgage: x.Mortgage, DueBy: x.DueBy }))
.aggregate(g => {
var interest = sum(g, x => x.InterestDue);
var principal = sum(g, x => x.PrincipalDue);
var amountPaid = sum(g, x => x.AmountPaid);
var interestRemaining = 0, principalRemaining = 0;
if (amountPaid < interest) {
interestRemaining = normalize(interest - amountPaid);
principalRemaining = normalize(principal);
}
else {
principalRemaining = normalize(principal - (amountPaid - interest));
}
return {
Mortgage: g.key.Mortgage,
DueBy: g.key.DueBy,
PrincipalDue: principal,
InterestDue: interest,
PrincipalRemaining: principalRemaining,
InterestRemaining: interestRemaining,
AmountPaid: amountPaid
}
});
这次索引中有真实的业务逻辑——即,低于平均水平的付款首先应用于利息,然后应用于本金。这并不是您实际会放入索引逻辑的内容,而是可能用“AppliesTo”属性来表示。
如果我们查询此索引,我们将获得按月聚合的结果

客户付款存在一个问题——三月份的必需付款增加了,但四月份的客户付款不足。他们仍然欠 1049.86 美元。
这是按月视图,但如果我们想获得抵押贷款的全局视图,我们可以使用我们之前展示过的相同功能,将这些索引结果保存为文档,然后创建一个索引来计算状态。
我们将告诉 RavenDB 将 reduce 结果文档输出到名为“MortgageMonthlyStatuses”的集合。

我们将创建一个新索引,以获取每个状态和抵押贷款付款,以确定每笔抵押贷款的总付款金额

map("MortgageMonthlyStatuses", status => {
return {
Mortgage: status.Mortgage,
PrincipalRemaining: status.PrincipalRemaining,
InterestRemaining: status.InterestRemaining,
AmountPaid: status.AmountPaid,
PastDue: (status.PrincipalRemaining + status.InterestRemaining) > 0 ? 1 : 0
};
});
map("MortgagePayment", amount => {
return {
AmountPaid: amount.AmountPaid,
Mortgage: amount.Mortgage
};
});
function normalize(r) {
return parseFloat(r.toFixed(3));
}
function sum(g, fetch) {
var r = g.values.filter(x => fetch(x) != null)
.reduce((acc, val) => acc + fetch(val, 2), 0);
return normalize(r);
}
groupBy(x => x.Mortgage)
.aggregate(g => {
return {
Mortgage: g.key,
PastDue: Math.max(0, sum(g, x => x.PastDue) - 1),
Amount: sum(g, x => x.Amount),
PrincipalRemaining: sum(g, x => x.PrincipalRemaining),
InterestRemaining: sum(g, x => x.InterestRemaining)
};
});
此索引产生这些查询结果

查询结果显示,该抵押贷款逾期一个月,这意味着剩余的本金和利息反映了错过的那个月的金额(1049.86 美元)以及下个月的付款(1494.64 美元)。
我们可以创建缺失月份的付款事件来弥补缺失的金额

{
"Amount": 1049.86,
"DueBy": "2018-04-30T00:00:00Z",
"Mortgage": "mortgages/4993-B",
"@metadata": {
"@collection": "MortgagePayment"
}
}
一旦此事件处理完毕,索引将更新剩余总额以反映下个月的必需付款金额。
这展示了一个处理时间敏感事件的示例,而无需依赖文档创建或处理的顺序。它并不旨在全面介绍抵押贷款的复杂性,但它确实说明了使用 RavenDB 索引为这些场景建模是一种强大而引人注目的方式。
结论
与传统数据库不同,RavenDB 中的索引不仅用于为您的应用程序提供高性能的查询功能,还可以转换和聚合后台数据。索引可用于简单的 map/reduce 操作,或用于建模复杂场景并将数据聚合从业务层转移到数据层。甚至还有一些方法可以使用索引来创建完全事件溯源的系统,其中文档被聚合然后存储为人工文档,从而使更高级别的索引能够服务于只读聚合层。
包含上述所有索引和文档的示例数据库 可以在此处找到。只需将转储导入您自己的 RavenDB 实例!如果您有兴趣了解更多关于 RavenDB 的信息,可以在 RavenDB 学习网站上找到更多信息。
