
使用 C# Sockets 的简单爬虫
4.87/5 (104投票s)
2006年3月19日
6分钟阅读
934404
40834
一个使用 C# Sockets 的多线程简单爬虫,用于解决 WebRequest.GetResponse() 的锁定问题。
目录
引言
网络爬虫(也称为网络蜘蛛或机器人)是一种以有条理、自动化的方式浏览万维网的程序。网络爬虫主要用于为搜索引擎创建所有访问过页面的副本,以便后续处理,搜索引擎会对下载的页面进行索引,以提供快速搜索。爬虫也可用于自动化网站的维护任务,例如检查链接或验证 HTML 代码。此外,爬虫还可用于从网页中收集特定类型的信息,例如收集电子邮件地址(通常用于发送垃圾邮件)。
爬虫概述
在本文中,我将介绍一个具有简单界面的简单网络爬虫,用一个简单的 C# 程序来描述爬取过程。我的爬虫采用了类似于任何互联网浏览器的输入界面,以简化操作。用户只需在导航栏中输入要爬取的 URL,然后点击“Go”。

该爬虫有一个 URL 队列,相当于任何大型搜索引擎中的 URL 服务器。爬虫使用多个线程从爬虫队列中获取 URL。然后,检索到的页面会保存在一个存储区域,如图所示。
为了避免 C# 其他库的锁定问题,爬虫使用 C# Sockets 库从 Web 请求获取的 URL。然后对检索到的页面进行解析,以提取新的 URL 引用,并将其再次放入爬虫队列中,直到达到在设置中定义的特定深度。
在接下来的章节中,我将描述程序的视图,并讨论一些与界面相关的技术要点。
爬虫视图
我的简单爬虫包含三个视图,可以跟踪爬取过程、检查详细信息并查看爬取错误。
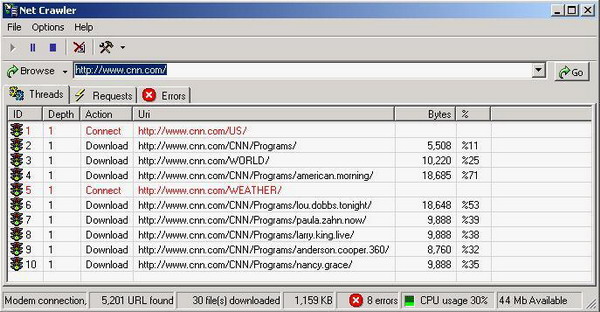
线程视图
线程视图只是一个向用户显示所有线程工作情况的窗口。每个线程从 URI 队列中取出一个 URI,并开始连接处理以下载该 URI 对象,如图所示。
 .
.
请求视图
请求视图显示了线程视图中最近下载的请求列表,如下图所示

此视图使您能够查看每个请求的头部,例如
GET / HTTP/1.0
Host: www.cnn.com
Connection: Keep-Alive
您可以查看每个响应的头部,例如
HTTP/1.0 200 OK
Date: Sun, 19 Mar 2006 19:39:05 GMT
Content-Length: 65730
Content-Type: text/html
Expires: Sun, 19 Mar 2006 19:40:05 GMT
Cache-Control: max-age=60, private
Connection: keep-alive
Proxy-Connection: keep-alive
Server: Apache
Last-Modified: Sun, 19 Mar 2006 19:38:58 GMT
Vary: Accept-Encoding,User-Agent
Via: 1.1 webcache (NetCache NetApp/6.0.1P3)
在下载的页面中,还提供了一个找到的 URL 列表
Parsing page ...
Found: 356 ref(s)
http://www.cnn.com/
http://www.cnn.com/search/
http://www.cnn.com/linkto/intl.html
爬虫设置
爬虫设置并不复杂,它们是从市场上许多现有爬虫中选择出来的选项,包括支持的 MIME 类型、下载文件夹、工作线程数等设置。
MIME 类型
MIME 类型是爬虫支持下载的类型,爬虫包含了默认使用的类型。用户可以添加、编辑和删除 MIME 类型。用户可以选择允许所有 MIME 类型,如下图所示

输出
输出设置包括下载文件夹,以及在请求视图中保留的请求数量,以便查看请求详情。

连接
连接设置包含
- 线程数:爬虫中并发工作的线程数量。
- 当引用队列为空时线程的休眠时间:当引用队列为空时,每个线程休眠的时间。
- 两次连接之间线程的休眠时间:每个线程在处理完任何请求后休眠的时间,这是一个非常重要的值,可以防止主机因负载过重而屏蔽爬虫。
- 连接超时:表示所有爬虫套接字的发送和接收超时时间。
- 页面导航深度:表示爬取过程中的导航深度。
- 保持在同一 URL 服务器:将爬取过程限制在与原始 URL 相同的主机内。
- 保持连接活动:为后续请求保持套接字连接打开,以避免重新连接的时间开销。

高级
高级设置包含
- 用于编码下载的文本页面的代码页。
- 用户定义的限制词列表,以便用户阻止任何不良页面。
- 用户定义的限制主机扩展名列表,以避免被这些主机屏蔽。
- 用户定义的限制文件扩展名列表,以避免解析非文本数据。

兴趣点
- 保持活动连接 (Keep-Alive):
Keep-Alive 是客户端向服务器发出的请求,要求在响应完成后为后续请求保持连接打开。这可以通过在向服务器发出的请求中添加一个 HTTP 头部来实现,如下面的请求所示
GET /CNN/Programs/nancy.grace/ HTTP/1.0 Host: www.cnn.com Connection: Keep-Alive
“Connection: Keep-Alive”告诉服务器不要关闭连接,但服务器可以选择保持打开或关闭它,但应就其决定向客户端套接字回复。因此,服务器可以通过在其回复中包含“Connection: Keep-Alive”来持续告知客户端它将保持连接打开,如下所示
HTTP/1.0 200 OK Date: Sun, 19 Mar 2006 19:38:15 GMT Content-Length: 29025 Content-Type: text/html Expires: Sun, 19 Mar 2006 19:39:15 GMT Cache-Control: max-age=60, private Connection: keep-alive Proxy-Connection: keep-alive Server: Apache Vary: Accept-Encoding,User-Agent Last-Modified: Sun, 19 Mar 2006 19:38:15 GMT Via: 1.1 webcache (NetCache NetApp/6.0.1P3)
或者,它也可以告诉客户端它拒绝该请求,如下所示
HTTP/1.0 200 OK Date: Sun, 19 Mar 2006 19:38:15 GMT Content-Length: 29025 Content-Type: text/html Expires: Sun, 19 Mar 2006 19:39:15 GMT Cache-Control: max-age=60, private Connection: Close Server: Apache Vary: Accept-Encoding,User-Agent Last-Modified: Sun, 19 Mar 2006 19:38:15 GMT Via: 1.1 webcache (NetCache NetApp/6.0.1P3)
- WebRequest 和 WebResponse 的问题:
当我开始编写本文的代码时,我使用了
WebRequest和WebResponse类,如下面的代码所示WebRequest request = WebRequest.Create(uri); WebResponse response = request.GetResponse(); Stream streamIn = response.GetResponseStream(); BinaryReader reader = new BinaryReader(streamIn, TextEncoding); byte[] RecvBuffer = new byte[10240]; int nBytes, nTotalBytes = 0; while((nBytes = reader.Read(RecvBuffer, 0, 10240)) > 0) { nTotalBytes += nBytes; ... } reader.Close(); streamIn.Close(); response.Close();
这段代码工作得很好,但它有一个非常严重的问题,因为
WebRequest类的GetResponse函数会锁定对所有其他进程的访问,WebRequest会将检索到的响应标记为已关闭,如前述代码的最后一行所示。因此,我注意到总是只有一个线程在下载,而其他线程都在等待GetResponse。为了解决这个严重的问题,我实现了自己的两个类,MyWebRequest和MyWebResponse。MyWebRequest和MyWebResponse使用Socket类来管理连接,它们与WebRequest和WebResponse类似,但支持同时进行并发响应。此外,MyWebRequest还支持一个内置的标志KeepAlive,以支持 Keep-Alive 连接。所以,我的新代码会是这样的
request = MyWebRequest.Create(uri, request/*to Keep-Alive*/, KeepAlive); MyWebResponse response = request.GetResponse(); byte[] RecvBuffer = new byte[10240]; int nBytes, nTotalBytes = 0; while((nBytes = response.socket.Receive(RecvBuffer, 0, 10240, SocketFlags.None)) > 0) { nTotalBytes += nBytes; ... if(response.KeepAlive && nTotalBytes >= response.ContentLength && response.ContentLength > 0) break; } if(response.KeepAlive == false) response.Close();
只需将
GetResponseStream替换为对MyWebResponse类的socket成员的直接访问。为此,我做了一个简单的小技巧,通过一次读取一个字节来判断头部是否结束,从而让套接字的下一次读取从响应头部之后开始,如下面的代码所示/* reading response header */ Header = ""; byte[] bytes = new byte[10]; while(socket.Receive(bytes, 0, 1, SocketFlags.None) > 0) { Header += Encoding.ASCII.GetString(bytes, 0, 1); if(bytes[0] == '\n' && Header.EndsWith("\r\n\r\n")) break; }
因此,
MyResponse类的用户将直接从页面的起始位置继续接收数据。 - 线程管理:
爬虫中的线程数由用户通过设置定义。其默认值为 10 个线程,但可以从“设置”选项卡的连接部分进行更改。爬虫代码使用
ThreadCount属性处理此更改,如下面的代码所示// number of running threads private int nThreadCount; private int ThreadCount { get { return nThreadCount; } set { Monitor.Enter(this.listViewThreads); try { for(int nIndex = 0; nIndex < value; nIndex ++) { // check if thread not created or not suspended if(threadsRun[nIndex] == null || threadsRun[nIndex].ThreadState != ThreadState.Suspended) { // create new thread threadsRun[nIndex] = new Thread(new ThreadStart(ThreadRunFunction)); // set thread name equal to its index threadsRun[nIndex].Name = nIndex.ToString(); // start thread working function threadsRun[nIndex].Start(); // check if thread dosn't added to the view if(nIndex == this.listViewThreads.Items.Count) { // add a new line in the view for the new thread ListViewItem item = this.listViewThreads.Items.Add( (nIndex+1).ToString(), 0); string[] subItems = { "", "", "", "0", "0%" }; item.SubItems.AddRange(subItems); } } // check if the thread is suspended else if(threadsRun[nIndex].ThreadState == ThreadState.Suspended) { // get thread item from the list ListViewItem item = this.listViewThreads.Items[nIndex]; item.ImageIndex = 1; item.SubItems[2].Text = "Resume"; // resume the thread threadsRun[nIndex].Resume(); } } // change thread value nThreadCount = value; } catch(Exception) { } Monitor.Exit(this.listViewThreads); } }
如果用户增加了
ThreadCount,代码会创建一个新线程或恢复被挂起的线程。否则,系统将挂起多余工作线程的任务交给线程自身处理,如下所示。每个工作线程都有一个等于其在线程数组中索引的名称。如果线程名称的值大于ThreadCount,它会继续完成当前任务然后进入挂起模式。 - 爬取深度:
这是爬虫在导航过程中深入的层级。每个 URL 的初始深度等于其父 URL 的深度加一,用户输入的第一个 URL 的深度为 0。从任何页面获取的 URL 都被插入到 URL 队列的末尾,这意味着“先进先出”的操作。并且所有线程可以随时插入到队列中,如下面的代码所示
void EnqueueUri(MyUri uri) { Monitor.Enter(queueURLS); try { queueURLS.Enqueue(uri); } catch(Exception) { } Monitor.Exit(queueURLS); }
每个线程可以检索队列中的第一个 URL 以进行请求,如下面的代码所示
MyUri DequeueUri() { Monitor.Enter(queueURLS); MyUri uri = null; try { uri = (MyUri)queueURLS.Dequeue(); } catch(Exception) { } Monitor.Exit(queueURLS); return uri; }
参考文献
鸣谢
感谢上帝!