
C# 光学字符识别(OCR)项目,使用链码
4.87/5 (73投票s)
本文探讨如何使用链码进行光学字符识别。
引言:什么是 OCR?
OCR 是光学字符识别的缩写,即它是一种帮助计算机识别不同纹理或字符的方法。
OCR 有时用于签名识别,签名识别用于银行。
以及其他高安全性的建筑物。
此外,纹理识别也可用于指纹识别。
OCR 已知用于雷达系统,用于读取超速者的车牌以及许多其他事物。
详细了解 OCR 实现及其在本论文中的应用。
光学字符识别 (OCR) 的目标是分类光学模式(通常包含
数字图像),对应于字母数字或其他字符。OCR 的过程
包括分割、特征提取和分类等几个步骤。每个
这些步骤本身就是一个领域,在此简要描述。
OCR 的实现。
下面展示了一个 OCR 示例。摘自
网络,显示了文本的扫描图像的一部分,以及该文本中对应的(人类识别的)字符。

关于作者和出版社的描述性书目。他在书目和文本研究的广阔领域中无处不在,他对它的似乎完全占有,使他有别于他杰出的前辈,并使他成为他那个时代书目学术的化身。
这里列出了一些 OCR 应用的例子。最常用于 OCR 的是第一个
项目,人们经常希望将文本文档转换为某种数字表示。
- 人们希望扫描文档,并在文字处理器中获得该文档的文本。
- 识别车牌号码。
- 邮局需要识别邮政编码。
其他模式识别示例。
- 面部特征识别(机场安检)- 此人是坏人吗?
- 语音识别 - 将声波转换为文本。
- 一艘潜艇希望对水下声音进行分类 - 一头鲸鱼。一艘俄罗斯潜艇?一
艘友好的船?
分类过程。
(任何类型的分类器的通用分类)构建分类器有两个步骤:
训练和测试。这些步骤可以进一步细分为子步骤。
- 培训
- 预处理 - 处理数据,使其成为适合...的形式。
- 特征提取 - 通过提取相关信息来减少数据量。
信息——通常会得到一个标量值的向量。(我们也需要
对特征进行归一化以进行距离测量!)
- 模型估计 - 从有限的特征向量集合中,需要估计一个模型
(通常是统计的)用于训练数据的每个类。
- 测试
- 预处理。
- 特征提取 - (与上面相同)
- 分类 - 将特征向量与各种模型进行比较,找到
最接近的匹配。可以使用距离度量。

OCR - 预处理。
这些是 OCR 中通常执行的预处理步骤。
- 二值化 - 通常给定一个灰度图像,二值化然后只是选择一个阈值的问题。
- 形态学算子 - 去除字符中孤立的点和孔,可以使用多数算子。
- 分割 - 检查形状的连通性,标记并隔离。
分割是预处理阶段最重要的方面。它允许
识别器从每个单独的字符中提取特征。在更复杂的情况下
手写文本,分割问题变得更加困难,因为字母倾向于
相互连接。
OCR - 特征提取。
给定一个分割(分离)的字符,有哪些有用的特征可用于识别?
- 基于矩的特征。
将每个字符视为一个 PDF。字符的二维矩是

从矩中,我们可以计算出诸如
- 总质量(二值化字符中的像素数)。
- 质心 - 质量中心。
- 椭圆参数。
- 离心率(长轴与短轴之比)。
- 方向(长轴的角度)。
- 偏度。
- 峰度。
- 高阶矩。
- 霍夫变换和链码变换。
- 傅里叶变换和级数。
特征提取或查找图像描述符有不同的方法,这些方法分为两类:
- 一种使用图像的整个区域。
- 另一种使用物体的轮廓或边缘。
以上所有方法都使用物体的轮廓来收集物体的特征。
算法要求。
我们需要的 OCR 算法必须满足以下要求:
- 它必须忠实地保留感兴趣的信息。
- 它必须允许紧凑存储和方便检索。
- 它必须促进所需的处理。
- 尺度不变性。
- 易于实现
因此,我们决定为此 OCR 实现链码。
也称为弗里曼链码。
弗里曼链码是纹理识别最好也是最简单的方法之一。
弗里曼于 1964 年设计了链码(此外,链码也是一种很好的图像编码方法,但在这里我们将其用作特征提取方法)。
尽管链码是一种紧凑的表示物体轮廓的方式,但在用作形状描述符时,它存在一些严重的缺点。
链码的缺点。
- 它仅适用于轮廓形状(在本例中意味着字符应以粗体输入)。
- 它对噪声非常敏感,因为误差是累积的。
- 链码的起始点、轮廓的方向和尺度都会影响链码。
因此,可用于匹配两个链的链相关方案也存在这些缺点。
注意:然而,缩放的缺点已被部分克服。
用于字符识别的弗里曼链码实现过程?
第一步如前所述是预处理。
本文将讨论的唯一预处理步骤是边缘检测或轮廓提取。
首先,什么是轮廓物体?
嗯,它意味着只有边缘的物体。
如何获得粗体字符对象的轮廓?
获取边缘的概念以相反的方式应用。
即,如果我们能检测到填充物并将其去除,剩下的就是边缘。
所以我们只需要找到填充物的独特属性并应用它。
填充属性。
- 所有八个周围的像素都是黑色的。
伪代码
Begin WHILE (! end of image) Search original image for black pixel If (the eight surrounding are black) Then This pixel is filling and we should remove it Go to next-pixel WHILEEND END
因此,通过在如下图像中实现上述代码。

第二步是特征提取过程(使用弗里曼链码)。
有许多实现链码的方法,它们都导向分割目标对象的思想。
因此,我们使用的是一种基于将对象分割成轨道和扇形,然后在每个扇形中应用链码以获取像素关系并将其保存在文件中的思想。
我们如何实现这种程度的分割对象并提取其特征向量?
实现轨道扇形分割对象并从中提取特征向量需要应用以下步骤:
- 获取质心 - 质量中心。
- 找到最长半径。
- 获取轨道步长。
- 使用轨道步长(基于预定义的轨道数量,即训练和测试必须使用相同数量的轨道)将对象虚拟地分割成轨道。
- 获取扇形步长。
- 使用扇形步长(基于预定义的扇形数量,即训练和测试必须使用相同数量的扇形)将这些虚拟轨道分割成相等的扇形。
- 找到相邻像素之间的关系。
- 将所有特征放在一起。
上述步骤将在后面更详细地讨论。
详细了解如何实现这种程度的轮廓对象分割。
1- 获取质心。
任何纹理(在本例中为字符)的质心由以下方程决定:
Xc=∑x/ ∑∑f(x, y) Yc= ∑y/ ∑∑f(x,y)
用英语来说,这意味着质心的 X 坐标是对象中所有像素的 x 坐标位置的总和。
除以对象的像素数。

所以上面图像的 Xc = (0+1+2+2+3)/5。
因此,质心的 Y 坐标是对象中所有像素的 y 坐标位置的总和除以对象的像素数。
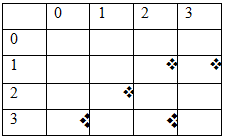
所以上面图像的 Yc = (3+2+2+2+1)/5。
因此,通过将上述规则应用于字符,我们得到:

2- 寻找最长半径。
要获得最长半径,我们必须计算质心(质量中心)与轮廓对象中的每个其他像素之间的距离,并找到最大长度,这将是最大半径。
如何获得两个像素之间的距离?
这要归功于毕达哥拉斯,他发明了毕达哥拉斯定理,它给出了任意两个点之间的距离,它陈述:
"任意两点之间的距离等于
Sqrt ((Xc-Xi)² + (Yc-Yi)²)"

3- 获取轨道步长。
什么是轨道步长?
轨道步长是任何两个相邻轨道之间的距离,将用于识别像素位置,即在哪个轨道中。
如何获得轨道步长?
轨道步长等于最大半径除以预定义的轨道数量,即(轨道步长 = 最大半径/轨道数)。
在本例中,我们使用的轨道数量是五个。
4- 使用轨道步长虚拟地将对象分割成轨道。
(基于预定义的轨道数量,即训练和测试必须使用相同数量的轨道)。
这样我们就可以确定一个像素位于哪个轨道中。
5- 获取扇形步长。
基于您决定的扇形数量。
(扇形步长 = 360/扇形数量)。
扇形步长将用于知道像素位于哪个扇形之下。
6- 使用扇形步长将这些虚拟轨道分割成相等的扇形。
(基于预定义的扇形数量,即训练和测试必须使用相同数量的扇形);
换句话说,使用扇形步长和轨道步长,我们可以确定像素位于哪个扇形和哪个轨道下。
详细了解如何确定一个像素位于哪个扇形。
首先,我们必须得到 Ө,这是像素与 x 轴之间的夹角。

Өi = tan⁻¹(y-Yc/x-Xc)
然后像素将位于扇形 = Ө/扇形步长。
7- 寻找像素关系。
寻找像素关系是特征提取步骤中最重要也是最简单的步骤,因为它在某种程度上描述了形状。
如何提取关系?
要提取像素之间的关系,我们遵循以下算法:
伪代码
Begin
For every pixel surrounding the target pixel
Moving clock-wise from north direction
If a pixel is, present surrounding the target pixel
Then
Store its position
Go to next target pixel
End if
Next
END
到目前为止,您应该能够确定任何像素位于哪个轨道和扇形中,以及它与其相邻像素的关系。通过
顺便说一句,这些是图像特征;
特征向量。
特征向量只是每个像素特征的集合,按轨道排序,即检查每个像素的位置并将其属性添加到特征向量中。例如,如果我们有两个像素位于扇形 1 和轨道 1,且关系相同为 4,那么在关系表中的单元格 4 中,位于 t1 和 s1 的像素将被增加两次,因为有两个像素具有此属性。

我们能够解决的弗里曼链码的缺点。
实际上,唯一解决的缺点是缩放问题,并且它是部分解决的(即仅向上缩放)。
如何克服链码的向上缩放缺点?
通过将特征向量除以对象中的像素数来解决,这样像素数(字符大小)对特征向量没有影响。
分类
分类是识别未知对象的过程。
有许多可用的分类器,例如:
- 神经网络
- 支持向量机。
- K-最近邻。
- 欧几里得距离。
本文我们讨论欧几里得距离,它是 KNN 的一种变体。
简单来说,欧几里得距离是计算关系之间的距离。
public double get_distence(cfeature_vector vec2)
{
double x=0,y=0,z=0,zf=0;
for (int i=0;i<6;i++)
{
for (int j=0;j<4;j++)
{
for (int k=0;k<8;k++)
{
x=current_features.tracks[i].sectors[j].relations[k];
y=vec2.tracks[i].sectors[j].relations[k];
z=x-y ;
z*=z;
zf+=z ;
}
}
}
return zf ;
}
识别结果和结论。
使用相同字体(Arial)的字符图像的识别率,向上缩放几乎 100% 正确。
然而,对于向下缩放,识别率非常差。
当我们用手写体测试我们的 OCR 时,有两个重要观察结果影响了识别率:
1. 人们倾向于使用与训练字体不同的字体。
2. 带有曲线的物体,如字符“C”、“O”和“Q”,尤其无法识别,也许是因为大多数人使用了非常糟糕的笔迹。
我们用于手写测试的数据来自两个不同的来源。
- 我们请人们使用画笔绘制字符,因此只有一两个人(包括我自己)真正做到了。
- 第二个来源是一张纸上的手写字母,我们有大约 7 个样本,包含 3 种不同的手写字母。
不同来源的正确率。
对于第一个来源,识别率达到了 75% 的峰值(在书写清晰的字母上),但在其他样本上,识别率约为 62%。
至于第二个来源,识别率比预期的要差,对于大多数样本约为 57%。
以下是测试过程中使用的一些样本。
以下是引擎最初训练的教学样本。

以下是通过扫描仪获取的手写样本。
