
C++ 高性能 Unicode 文本文件 I/O 例程
4.76/5 (25投票s)
令人惊讶的是,C++ 运行时库和 Win32 Platform SDK 都没有提供读取和写入 Unicode 文本文件的例程。本文提供了高性能的例程,用于读取所有类型的 Unicode 文件(UTF-16 和 UTF-8)以及 ANSI 文件。
引言
令人惊讶的是,C++ 运行时库和 Win32 Platform SDK 都没有提供读取和写入 Unicode 文本文件的例程,因此,当我需要这些例程时,我不得不自己编写。您选择使用这些例程而非 Internet 上或 CodeProject 上其他地方可以找到的例程,有三个原因:性能、性能和性能。还有便利性。您可以读取和写入 ANSI、UTF-8、UTF-16 小端序和 UTF-16 大端序文件,而无需更改代码。这些例程完全不依赖 MFC,因此您可以在任何 C++ 项目中使用它们。
究竟什么是 Unicode 文本文件?
Unicode 文本文件有三种格式:UTF-16 小端序、UTF-16 大端序和 UTF-8。不幸的是,还有三种不同的行分隔符约定:DOS/Windows (CRLF)、Unix (仅 LF) 和 Mac (仅 CR)。EZUTF 可以处理所有三种类型的文件编码(以及 ANSI 文件)和三种行分隔符中的两种。它无法读取 CR 分隔的文件(但可以写入)。
UTF-16 文件每个字符存储两个字节,因此存在小端序和大端序变体。小端序文件按最低有效字节在前的方式存储字符,而大端序文件则相反。可以通过检查文件开头是否存在一个两字节标记(称为 BOM)来区分文件类型,该标记在两种格式之间有所不同。小端序文件为 0xFF, 0xFE,而大端序文件则为——您猜对了——相反。
UTF-8 文件非常巧妙,因为它们可以编码整个 UTF-16 字符集,但如果只存储 ASCII 字符(即小于 128 的字符码),其大小会是 UTF-16 文件的一半。它们在不同系统之间也非常便携,这也是多语言网页在互联网上传播的方式,以防您好奇。UTF-8 文件将字符存储为 1、2、3 或 4 字节的序列,具体取决于字符码,ASCII 字符始终编码为 1 字节,所有拉丁字符(和其他西方字符)编码为 2 字节。另一方面,中文字符和日文字符编码为 3 字节,因此如果您存储大量这些字符,UTF-16 可能是更好的选择。幸运的是,UTF-8 文件不存在字节序问题,并且在 Windows 应用程序中从不使用 4 字节序列,因为它们编码的字符超出了 UTF-16 字符集(Windows 内部使用)。
UTF-8 文件还可以通过其始终以 0xEF, 0xBB, 0xBF 序列开头来识别,这与两种 UTF-16 编码使用的 BOM 不同。UTF-16 字符编码为 UTF-8 字节序列的过程并不特别复杂,在此 处 有更详细的描述。或者,您也可以查看代码,其中有一些注释。
最后,为了完整起见,ANSI 文件将每个字符存储为单个字节,因此只能表示 255 及以下的字符码。要正确理解 ANSI 文件,您必须知道写入时使用了哪个代码页,尽管许多软件 simply 假定使用 Windows-1252。
EZUTF 有什么作用?
EZUTF 提供了一组高性能例程,用于读取和写入上述所有类型的文本文件,而无需应用程序进行任何必要的转换。它还可以处理 DOS/Windows (CRLF) 和 Unix (LF) 行分隔符,但不能处理 Mac (仅 CR)。当文件以读取模式打开时,EZUTF 可以被指示读取 BOM(如果存在),从而推断出文件编码。或者,您可以强制 EZUTF 使用特定编码,以避免,例如,错误地将以 0xFF, 0xFE 开头的 ANSI 文件当作 UTF-16 文件(这将是灾难性的)。当文件以写入模式打开时,您会告知 EZUTF 您想要使用的编码和行分隔符,它将处理所有细节,包括在文件开头写入 BOM。
不提供“seek”功能,但 EZUTF 可以将数据追加到现有文件的末尾。在这种情况下,除非文件最初为空(或不存在),否则不会写入 BOM。
Using the Code
所有 `public` API 都封装在一个类中:`TextFile`。`TextFile` 对象可以打开和关闭,可以读取和/或写入行或单个字符。
读取文件
通常,您会这样打开一个文件进行读取
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_READ);
当文件以这种方式打开进行读取时,EZUTF 将读取文件中的 BOM 标记(如果存在),并从中推断出文件编码。如果您想知道是什么编码,可以在打开文件后使用以下方法:
// TF_TF_ANSI, TF_UTF16LE, TF_UTF16BE or TF_UTF8
int file_encoding = tf->GetFileEncoding ();
或者,如果您知道您正在打开一个 ANSI 文件,那么使用以下方法会更明智:
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_READ, TF_ANSI);
……这样可以避免错误地将文件解释为 Unicode 的风险。
要从文件中读取行,可以这样做:
TCHAR *line_buf = NULL;
int result;
while ((result = tf->ReadLine (NULL, &line_buf) >= 0)
// do something; the line just read from the file is in line_buf
free_block (line_buf);
请注意,在返回之前,任何行分隔符都会从行中被剥离,并且 `line_buf` 是从 `TextFile` 内部分配的,而不是由调用者分配。这是为了处理不同的行长度,而无需在每次调用时分配缓冲区。调用者必须将 `line_buf` 初始化为 `NULL`,并在完成后负责释放它(通过调用 `free_block()`)。如果您未能将 `line_buf` 初始化为 `NULL`,您的程序将遭到可怕的结局,如果您在完成后未能将其传递给 `free_block()`,您将面临内存泄漏。返回的 `line_buf` 指针在您将其传递给另一个 `TextFile` 例程(或释放它)之前一直有效。初始的 `NULL` 参数用于可选地返回 'data lost'(在 ANSI 构建中),其中需要在 `TextFile` 类内进行 Unicode 到 ANSI 的转换(请参阅 Platform SDK 文档中的 `WideCharToMultiByte`)。
写入文件
要打开一个文件进行写入,您必须指定您想要使用的编码,如下所示:
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_WRITE, TF_UTF8);
然后要写出一行,可以这样做:
int result = tf->WriteString (NULL, L"This is a string");
if (result >= 0)
result = tf->WriteChar (NULL, '\n');
当然,如果正在写入的行已经以换行符(`\n`)字符结尾,您可以跳过对 `WriteChar()` 的调用。初始的 `NULL` 参数用于可选地返回 'data lost'(在写入 ANSI 文件时),其中需要在 `TextFile` 类内进行 Unicode 到 ANSI 的转换(请参阅 Platform SDK 文档中的 `WideCharToMultiByte`)。
如果您像我一样是 `fprintf` 的粉丝,您可以通过以下方式写出格式化数据:
int n_bottles = 10;
int result = tf->FormatString
(NULL, L"There are %d green bottles, standing on the wall.\n", n_bottles);
请注意,我没有提供对流的支持,因为我不使用它们,但添加它们并不困难,如果有人愿意,我将很乐意将他们的更改合并到主源代码中。
读写 Unix 文件
读取文件时,会自动处理 Unix 风格(仅 LF)的行分隔符,即,您可以像往常一样打开文件,然后按照上述说明调用 `ReadLine()`。要使用 Unix 行分隔符写入文件,您可以这样做:
TextFile *tf = new textFile;
int result = tf->Open (L"MyFile.txt", TF_WRITE, TF_UTF8 | TF_UNIX);
写入 `\n` 字符将只向文件写入一个 LF,而不是 CRLF 序列。
错误处理和 HPSLib
所有 `TextFile` 方法都返回一个整数,如果发生错误,该整数将为负数。文件结束也返回一个负值 - `TF_EOF` - 因此请先测试这一点。要检索一个描述错误的 `string`,请调用 `GetLastErrorString()`。这与 `GetLastError()` 的工作方式类似,但返回一个指向(每个线程)内部缓冲区的指针,其中包含一个用户友好的错误消息(例如,“无法打开文件 xyz,错误 blah”)。返回的指针在您再次调用 `TextFile`(或在同一线程内调用 `SetLastErrorString()`)之前有效。或者,您可以像往常一样调用 `GetLastError()`,并以您选择的任何方式报告错误条件。
性能
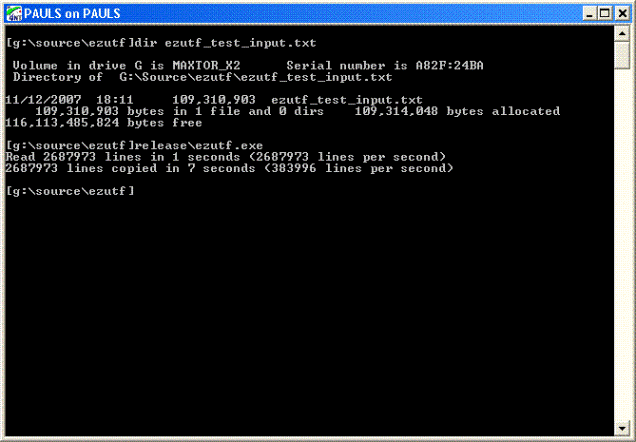
EZUTF 速度极快!如果您需要速度,这些例程就是为您准备的。在我的 AMD Athlon 64 3000+ 上,读取一个大小约 100MB / 2,500,000 行的 UTF-8 文件,一旦文件进入缓存,耗时不到一秒。复制同一文件大约需要 7 秒,与二进制复制所需时间差不多,尽管 CPU 开销要大得多。
相比之下,将同一文件加载到记事本需要大约 45 秒,加载到 Visual Studio 2005 需要 2-3 秒(这实际上相当不错;我印象深刻)。这些数字指的是发布版本 - 调试版本速度要慢得多。
HPSLib 和杂项
EZUTF 构建在一个内部库之上,该库被谦虚地命名为 *HPSLib*。我已经提供了一个该库的最小子集 - 在文件 `hpslib.cpp`、`hpsutils.h`、`hpslib.rc` 和 `hpslib.hr` 中 - 它们提供了 `TextFile` 类按设计运行所需的功能。您需要在任何使用 `TextFile` 类的项目中包含这些文件,或者您可以选择将 `hpslib.rc` 中的文本 `string`(只有 4 个)复制到您自己的 `*.rc` 文件中。
演示应用程序是一个控制台应用程序,它期望在当前目录中找到一个名为 `ezutf_test_input.txt` 的文件,并将其复制到 `ezutf_test_output.txt`。如果您想单步调试代码,请构建调试版本。
对于 C++ 新手来说,可能会对实现中使用的模板、虚函数和内联函数感兴趣。个人而言,我很少使用模板,但当您需要时,您就必须使用它。更多的方法可能应该是 `private`。
历史
- 2007 年 12 月:初始版本
- 2008 年 2 月:添加了一些 `const`
- 2008 年 3 月:修复了读取长行文件时出现的内存覆盖问题(抱歉——感谢 IanLo 发现问题)并增加了对 Unicode 代理对的支持。请注意,后者仅经过少量测试。
- 2008 年 8 月:现在可以在打开 `TF_READ` 访问的文件时,将文件编码(例如 `TF_UTF8`)传递给 `TextFile::Open`。EZUTF 仍将尝试读取 BOM,但不需要其存在。
- 2008 年 11 月:明确了下载 zip 文件中包含的源代码和项目文件适用于 Visual Studio 2005。