
SQL Express 中的数据同步
4.44/5 (21投票s)
SQL Express 中的数据同步
引言
SQL Server Express 版是一个免费的数据库管理系统(DBMS),但它不具备数据同步(DTS)功能。如今,大多数低预算的 Windows 应用程序项目都是使用 SQL Express 版开发的,当应用程序需要数据同步时,这一限制会阻碍用户进一步开发。本文提供了多种方法来解决这个问题。
方法一:使用 TableDiff 实用工具进行数据同步
我们可以使用 TableDiff 实用工具生成一个 Transact-SQL 脚本(包含 delete/insert/update 语句),用于修复目标服务器上的差异,使源表和目标表的数据趋于一致。由于该工具一次只能比较一个表,如果我们需要同步 N 个表,就需要在一个循环中调用它。在循环中,我们必须将生成的 Transact-SQL 脚本累积(即追加)到一个本地文件(例如 CompleteFixSQL.sql)中。循环结束后,我们就得到了一个完整的脚本文件,需要在目标服务器上执行。可以使用 sqlcmd 实用工具在目标服务器上运行该脚本文件(CompleteFixSQL.sql),从而使源表和目标表的数据趋于一致。
方法一的实现
我们使用以下 DOS 批处理文件实现了这个方法:
GenerateFixSQLScriptMain.bat:这个主 DOS shell 程序会遍历一个表列表(需要同步的表),并为每个表调用 GenerateFixSQLScriptSub.bat 来生成修复 SQL 脚本,然后将它们追加成一个单一的 CompleteFixSQL.sql 文件。
GenerateFixSQLScriptSub.bat:这个 DOS shell 程序会比较源表和目标表,并使用 TableDiff 实用工具生成修复 SQL 脚本文件。
Offline_Synchronization.bat:这个 DOS shell 程序会使用 SQLCMD 命令行实用工具运行由上述 GenerateFixSQLScriptMain.bat 生成的 CompleteFixSQL.sql 脚本。
Call_DTS.bat:这个 DOS shell 程序会调用 GenerateFixSQLScriptMain.bat 和 Offline_Synchronization.bat,分别用于生成脚本和执行数据同步。
将上述 zip 文件解压到一个文件夹中。根据您的设置修改 Call_DTS.bat 批处理文件(即,更改输入参数,如服务器名、数据库名、用户名、密码、以及需要同步的以逗号分隔的表列表)。然后在 DOS 提示符下执行它。
本文没有解释这些 DOS 批处理文件的程序流程,因为我们的主要目的是解释其他方法(方法二和方法三)。
方法一的缺点
TableDiff和sqlcmd实用工具都是需要从客户端应用程序代码中调用的外部应用程序。如果我们要同步 N 个表,TableDiff需要被调用 N 次,这会产生 I/O 开销。sqlcmd实用工具会按顺序逐一执行CompleteFixSQL脚本中包含的语句,如果目标端需要同步的数据量很大,这将是一个耗时的过程。TableDiff实用工具存在一些限制。它不会为 LOB 数据类型(如text、ntext和image)生成修复脚本文件。
方法二:使用连接(Join)机制进行数据同步
可以使用带有 SQL join 机制的存储过程(SP)来比较源表和目标表之间的差异,然后用源表数据同步目标表。为了使源表和目标表的数据趋于一致,需要:
- 找出需要从目标数据库表中删除的记录
- 找出需要插入到目标数据库表中的记录
- 找出需要在目标数据库表中更新的记录
随后,我们必须在目标数据库中,针对在上述步骤 1、2 和 3 中找到的记录,分别执行 delete、insert 和 update 语句。
步骤 1:从目标数据库表中删除的记录
- 选择那些在源数据库表中不存在,但在目标数据库表中存在的记录
- 然后从目标数据库表中删除它们
delete from
DestinationDB.dbo.TableName DestinationDBTable
where
not exists
(select
1
from
SourceDB.dbo.TableName SourceDBTable
where
SourceDBTable.PrimaryColumnName1 = DestinationDBTable.PrimaryColumnName1 and
SourceDBTable.PrimaryColumnName2 = DestinationDBTable.PrimaryColumnName2 and
...
SourceDBTable.PrimaryColumnNameN = DestinationDBTable.PrimaryColumnNameN
)
如果表包含 Identity 列,那么我们可以简单地使用该列而不是主键列作为 WHERE 子句中 join 条件。这将减少 join 条件的长度,特别是当表有复合主键和一个 Identity 列时。这也会提高 delete 语句的性能。
delete from
DestinationDB.dbo.TableName DestinationDBTable
where
not exists
(select
1
from
SourceDB.dbo.TableName SourceDBTable
where
SourceDBTable.IdentityColumn = DestinationDBTable.IdentityColumn
)
步骤 2:插入到目标数据库表中的记录
- 选择那些在源数据库表中存在,但在目标数据库表中不存在的记录。
- 然后将它们插入到目标数据库表中。
insert into
DestinationDB.dbo.TableName DestinationDBTable
(ColumnList)
select
SourceDBTable.Columnlist
from
SourceDB.dbo.TableName SourceDBTable
where
not exists
(select
1
from
DestinationDB.dbo.TableName DestinationDBTable
where
DestinationDBTable.PrimaryColumnName1 = SourceDBTable.PrimaryColumnName1 and
DestinationDBTable.PrimaryColumnName2 = SourceDBTable.PrimaryColumnName2 and
...
DestinationDBTable.PrimaryColumnNameN = SourceDBTable.PrimaryColumnNameN
)
数据类型为 TimeStamp 的列应从上述 insert 语句的列列表中排除,因为我们不能为 TimeStamp 列显式设置值。
如步骤 1 中所述,我们可以使用标识列而不是主键列,如下所示:
insert into
DestinationDB.dbo.TableName DestinationDBTable
(ColumnList)
select
SourceDBTable.Columnlist
from
SourceDB.dbo.TableName SourceDBTable
where
not exists
(select
1
from
DestinationDB.dbo.TableName DestinationDBTable
where
DestinationDBTable.IdentityColumn = SourceDBTable. IdentityColumn
)
如果表有标识列,那么上述 insert 语句必须被“set identity_insert on/off”包围,如下所示:
set identity_insert TableName On
... above insert statement
set identity_insert TableName off
步骤 3:在目标数据库表中更新的记录
- 选择源数据库表和目标数据库表中内容不同的记录。
- 然后用源数据库表的数据在目标数据库表中更新它们。
update
TableName
set
ColumnName1 = SourceDBTable.ColumnName1,
ColumnName2 = SourceDBTable.ColumnName2,
...
ColumnNameN = SourceDBTable.ColumnNameN
from
DestinationDB.dbo.TableName DestinationDBTable,
(
select
max(TableName) as TableName, columnlist
from
(
select
'SourceTableName' as TableName, columnlist
from
SourceTableName
union all
select
'DestinationiTableName' as TableName, columnlist
from
DestinationTableName
) AliasName
group by
columnlist
having
count(*) = 1
and max(TableName) = 'SourceTableName'
) SourceDBTable
where
SourceDBTable.PrimaryColumnName1 = DestinationDBTable.PrimaryColumnName1 and
SourceDBTable.PrimaryColumnName2 = DestinationDBTable.PrimaryColumnName2 and
...
SourceDBTable.PrimaryColumnNameN = DestinationDBTable.PrimaryColumnNameN
数据类型为 TimeStamp 的列应从上述 update 语句的 SET 子句中排除,因为我们不能为 TimeStamp 列显式设置值。
对于由上述语句的 UNION ALL 合并的查询,LOB 数据类型(Text、nText 和 Image)的列应转换为相应的大值数据类型[Varchar(max)、nVarchar(max) 和 varbinary(max)]。这是因为 UNION ALL 会触发排序机制,而该机制禁止 LOB 数据类型。
如步骤 1 和 2 中所述,我们可以在 update 语句的 WHERE 子句中使用标识列而不是主键列。
方法二的实现
上述核心逻辑是为给定的表列表一次同步一个表而实现的。对于每个目标表,它的记录将通过与关联的源表进行比较而被删除、插入和更新。只要表之间没有关系,即没有表被外键约束强制执行,这个逻辑就能正常工作。换句话说,这个逻辑不会对有外键引用的表执行数据同步(DTS)。为了解决这个问题,我们简单地在执行 DTS 之前禁用了所有要同步的表的外键约束。然后在 DTS 之后再重新启用它们。ALTER TABLE 语句的 NOCHECK/CHECK 子句可以很方便地实现这个解决方案。
附件中的 zip 文件 ‘Data Synchronization Stored Procedures and Views Part_II.zip’ 包含了以下视图和存储过程(SP)来实现 DTS:
v_DTS_ColumnInformationstp_DTS_GetCommaSeperatedColumnStringstp_DTS_GetIdentityOrPrimaryKeyColumnDetailsstp_DTS_SetDestinationColumnWithSourceColumnStringstp_DTS_DataSynchronizationv_DTS_ForeignKeystp_DTS_EnableDisableForeignKeyConstraint
v_DTS_ColumnInformation:此视图将用于填充列的详细信息,如数据类型、主键、非空约束、标识属性、列大小约束(字符数据类型的长度,数字数据类型的精度和刻度)。
stp_DTS_GetCommaSeperatedColumnString:此 SP 为给定表生成各种以逗号分隔的列字符串。
stp_DTS_GetIdentityOrPrimaryKeyColumnDetails:此 SP 为给定表的标识列或主键列生成各种字符串。
stp_DTS_SetDestinationColumnWithSourceColumnString:此 SP 为步骤 3 中描述的 update 语句生成 SET 子句。
stp_DTS_DataSynchronization:这是将用于将目标表与源表数据同步的主 SP。
v_DTS_ForeignKey:一个视图,用于检索表的外键详细信息(包括引用表和被引用表)。
stp_DTS_EnableDisableForeignKeyConstraint:一个存储过程,用于打开/关闭(即启用/禁用)给定表列表的所有外键约束。
上述所有过程中使用的参数的详细信息,都在每个 SP 的头部进行了描述。
方法二的优点
- 存储过程已经编译并存储在目标数据库中。客户端应用程序代码只需使用连接字符串调用此 SP。
- 表比较和同步将在单个查询中完成(
delete、insert和update各一个查询)。 - 记录以批量方式处理(删除、插入和更新)。
- 支持 LOB 数据类型。
方法三:使用连接机制进行数据同步,无需启用/禁用外键约束
方法三将详细阐述在方法二中发现的一些次要性能问题。同时,它提供了一个解决方案来修复这些问题并提高数据同步过程的性能。
问题一:存储过程重编译及其性能瓶颈:在数据同步(DTS)期间,记录将在目标数据库的指定表列表(在逗号分隔的表列表输入参数中指定)中被插入/删除/更新。这种记录操作是按顺序进行的,如果表之间通过外键(FK)相互引用,将会导致外键错误。这是因为,在向子表插入记录之前,必须先在其父表中插入相应的记录。同样,在从父表中删除记录之前,必须先从其子表中删除相应的记录。为了克服这个“鸡和蛋”的问题,在方法二的 DTS 版本中,我们在开始同步之前禁用了所有指定表的外键引用。然后在同步过程结束后再重新启用它们。
同步之后,如果执行一个存储过程(SP),并且该 SP 依赖于任何一个已同步的表,那么 SQL Server 优化器会强制该 SP 重新编译。这是因为在同步过程中,作为启用/禁用外键的一部分,依赖表的架构发生了变化。因此,在同步之后,所有依赖于已同步表的 SP 在执行前都会被强制重新编译。这种 SP 重编译会降低性能。
解决方案:避免 SP 重编译的解决方案是取消方法二 DTS 版本中引入的启用/禁用外键的机制。那么,我们如何克服因对具有外键约束的表进行记录操作而导致的外键错误呢?我们必须按照一个永远不会出现“鸡和蛋”场景的顺序重新排列给定的表。例如,我们有一个表列表 T7, T2, T1, T4, T5, T3 和 T6。它们之间的依赖关系如下:
| 子表 | 父表 |
| T7 | T1 |
| T1 | T5 |
| T5 | 无 |
| T2 | T1 |
| T3 | 无 |
| T6 | 无 |
| T4 | T3 |
我们必须根据给定的表列表的子-父关系构建一个层次树,如下所示:
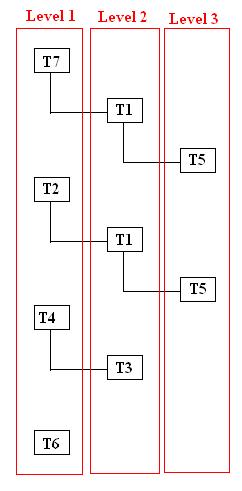
| 表格 | 子到父级别 |
| T7 | 1 |
| T2 | 1 |
| T6 | 1 |
| T4 | 1 |
| T1 | 2 |
| T3 | 2 |
| T5 | 3 |
我们现在可以按照上述层次树的升序(子到父级别)从表中删除记录,而记录将按降序插入到表中。更新可以按任何顺序进行。这将消除 DTS 过程中可能出现的外键冲突错误。
问题二:UNION ALL 和 GROUP BY 机制及其性能瓶颈:在之前的 DTS 方法二版本中,INSERT/DELETE 记录操作通过主键比较来处理,而 UPDATE 则通过 UNION ALL 机制处理。如果我们需要同步大量的记录,并且其中大部分需要 UPDATE,那么系统可能需要大量的内存空间来执行源/目标记录的 UNION ALL 操作。随后的对所有列的 GROUP BY 操作会使情况进一步恶化。这降低了 DTS 过程的性能。
解决方案:取代 UNION ALL 和 GROUP BY 机制的解决方案要求在每个(需要同步的)表中增加一个新列 TimeStamp,用于保存记录修改的日期和时间。虽然列名为“Time Stamp”,但它是一个常规的“DateTime”数据类型列,而不是“TimeStamp”数据类型。每当源数据库中的一条记录被修改时,相应记录的 TimeStamp 列必须用当前日期和时间进行更新。用户必须修改他们的应用程序代码/SP来执行此 TimeStamp 更新。在 DTS 期间,任何具有较早 TimeStamp(即日期时间)值的目标记录都将用其对应的源记录值进行更新。
然而,这个增强是可选的,用户仍然可以选择使用 UNION ALL 和 GROUP BY 机制。这是因为一些用户不想在他们现有的表中引入新的“Time Stamp”列,以避免代码重构。
方法三的实现
- 下载使用连接机制进行数据同步(无需启用/禁用外键约束) - 7.31 KB
- 下载修复 - 计算列错误 - 4.93 KB
- 下载 stp_DataSynchronizationWrapper - 778 B
附件中的 zip 文件 ‘Data Synchronization using Join mechanism without Enable Disable Foreign Key Constraints.zip’ 包含了以下最新的视图和存储过程(SP),用于实现增强版的数据同步:
v_DTS_ColumnInformation– 无变化stp_DTS_GetCommaSeperatedColumnString– 无变化stp_DTS_GetIdentityOrPrimaryKeyColumnDetails- 无变化stp_DTS_SetDestinationColumnWithSourceColumnString- 无变化stp_DTS_DataSynchronization– 已修改,详情请参见程序的修改历史v_DTS_ForeignKey– 无变化stp_DTS_EnableDisableForeignKeyConstraintfnTableHierarchy– 新增stp_DTS_ArrangeTablesInTheirOrderOfRelationships– 新增
fnTableHierarchy:对于给定的表,此函数使用递归 CTE(公用表表达式)机制,按“子到父”关系的顺序返回其所有依赖的表。
stp_DTS_ArrangeTablesInTheirOrderOfRelationships:此 SP 返回一个数据集,其中包含一个按指定顺序(子到父、父到子或无顺序)排列的表列表,该列表是为给定的逗号分隔的表列表而生成的。
结论
在本文中,我们看到了三种在 SQL Express 版数据库中执行数据同步的不同方法。其中,方法一的缺点最多。虽然方法二可以用于执行 DTS,但它有其自身的性能瓶颈。方法三解决了在方法二中发现的那些问题。然而,用户可以根据自己的需求选择方法二或方法三。
假设
- 源表和目标表的架构是相同的。
- 源数据源和目标数据源是不同的。
- 如果源服务器和目标服务器是远程连接的,目标服务器上有一个指向源服务器的链接服务器。
- 上面列出的所有 SP 和视图都存储并编译在目标数据库中。
- 主 SP
stp_DTS_DataSynchronization将在目标数据库上执行。 - 用户使用有效的参数调用主 SP
stp_DTS_DataSynchronization。
局限性
- 数据类型为
Timestamp的列已从数据同步中排除。
未来版本的特性
- 它将被扩展以提供数据同步过程的日志。这样用户就可以知道有多少条记录被删除/插入/更新,以及它们是什么。
提示:可以使用OUTPUT子句来实现此功能。
参考文献
- 在 SQL Server 中比较两个表的最短、最快、最简单的方法
UNION TableDiff实用工具 (http://technet.microsoft.com/en-us/library/ms162843.aspx)
致谢
我衷心感谢所有参与并在 Jeff 的 SQL Server 博客(http://weblogs.sqlteam.com/jeffs/archive/2004/11/10/2737.aspx) 中花费宝贵时间讨论表比较技术的专家。
- Jeff:感谢他提出的用于比较表的
UNION ALL方法 - Click:感谢他提出的用于比较表的
NOT EXISTS方法 - David L. Penton:感谢他对
NOT EXISTS方法中发现的问题的解释 - John:感谢他用单个
SELECT语句生成逗号分隔列表的强大代码 - Pinal Dave:感谢他用于在数据库中查找外键约束的脚本