
ATL 内部机制 第四部分
4.89/5 (26投票s)
继续 ATL 内部机制系列,
引言
到目前为止,我们还没有讨论任何关于汇编语言的内容。但是,如果我们真的想了解 ATL 内部的运作机制,那么就无法长期回避它。因为 ATL 使用了一些底层技术以及一些内联汇编语言,以使其尽可能的小巧和快速。我假设读者已经具备了汇编语言的基础知识,所以我将只专注于我的主题,而不尝试写另一篇汇编语言的教程。如果你对汇编语言的了解不够,我推荐你参考 Matt Pietrek 在 1998 年 2 月的 Microsoft System Journal 期刊上的文章“Under The Hood”,它为你提供了关于汇编语言的足够信息。
为了开始我们的旅程,请看这个简单的程序
程序 55
void fun(int, int) { } int main() { fun(5, 10); return 0; }现在用命令行编译器 cl.exe 编译它。使用 -FAs 开关进行编译。例如,如果这个程序名为 prog55,则这样编译:
Cl -FAs prog55.cpp
这将生成一个同名的文件,但扩展名为 .asm,其中包含以下程序的汇编语言代码。现在来看看生成的输出文件。让我们先讨论函数调用。调用这个函数的汇编代码如下:
push 10 ; 0000000aH
push 5
call ?fun@@YAXHH@Z ; fun
函数的参数是从右到左的顺序压入栈中,然后调用函数。但是函数的名称与我们给定的函数名略有不同。这是因为 C++ 编译器会修饰函数名以实现函数重载。让我们稍微修改一下程序,重载函数,以便查看代码的行为。
程序 56void fun(int, int) { } void fun(int, int, int) { } int main() { fun(5, 10); fun(5, 10, 15); return 0; }
现在调用这两个函数的汇编语言代码如下:
push 10 ; 0000000aH
push 5
call ?fun@@YAXHH@Z ; fun
push 15 ; 0000000fH
push 10 ; 0000000aH
push 5
call ?fun@@YAXHHH@Z ; fun
看看函数名,我们用相同的名称编写了两个函数,但编译器会自己修饰这些函数来实现函数重载。
如果你不想修饰函数名,可以使用 extern "C" 来声明函数。让我们看看程序中的一些小改动。
程序 57extern "C" void fun(int, int) { } int main() { fun(5, 10); return 0; }
这个函数的汇编语言代码是:
push 10 ; 0000000aH
push 5
call _fun
这意味着你现在不能用 C 链接来重载函数。请看下面的程序:
程序 58extern "C" void fun(int, int) { } extern "C" void fun(int, int, int) { } int main() { fun(5, 10); return 0; }
该程序会导致编译错误,因为 C 语言不支持函数重载,而你却试图创建两个同名的函数,并告诉编译器不要修饰它们的名称,即使用 C 语言链接而不是 C++ 链接。
现在来看看编译器为我们的“无操作”函数生成了什么代码。这是编译器为我们的函数生成的代码。
push ebp
mov ebp, esp
pop ebp
ret 0
在进一步深入细节之前,请看一下函数的最后一条语句,即 ret 0。为什么是 0?它能是其他值吗?正如我们所见,传递给函数的所有参数实际上都被压入了栈中。当你或编译器将某些东西压入栈时,寄存器会受到什么影响?请看下面的简单程序,以了解其行为。我使用了 `printf` 而不是 `cout`,以避免 `cout` 的开销。
程序 59#include <cstdio> int g_iTemp; int main() { fun(5, 10); _asm mov g_iTemp, esp printf("Before push %d\n", g_iTemp); _asm push eax _asm mov g_iTemp, esp printf("After push %d\n", g_iTemp); _asm pop eax return 0; }
该程序的输出是
Before push 1244980
After push 1244976
这个程序显示了 ESP 寄存器在压入一些值到栈中之前和之后的值。这清楚地表明,当你将某些东西压入栈时,栈在内存中会向下增长。
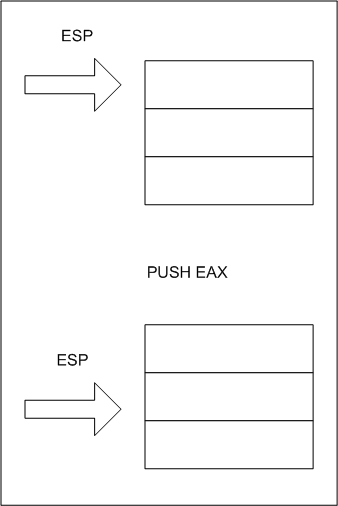
现在有一个问题,当我们向函数传递参数时,谁负责恢复栈指针?是函数本身还是函数的调用者?实际上,这两种情况都有可能,这也是标准调用约定和 C 调用约定之间的区别。请看调用函数之后的下一条语句。
push 10 ; 0000000aH
push 5
call _fun
add esp, 8
这里向函数传递了两个参数,所以将两个值压入栈后,栈指针会减去 8 字节。那么在这个程序中,设置栈指针的责任在于函数的调用者。这被称为 C 调用约定。在这种调用约定下,你可以传递可变数量的参数,因为调用者知道传递了多少参数,所以它可以自己设置栈指针。
但是,如果选择了标准调用约定,那么清理栈的责任就在被调用者身上。在这种情况下,不能向函数传递可变数量的参数,因为函数无法知道传递了多少参数,因此它无法适当地设置栈指针。
请看下面的程序,以了解标准调用约定的行为。
程序 60extern "C" void _stdcall fun(int, int) { } int main() { fun(5, 10); return 0; }
现在看看函数调用。
push 10 ; 0000000aH
push 5
call _fun@8
函数名旁的 @ 表明这是标准调用约定,8 表示压入栈中的字节数。因此,参数的数量可以通过将此数字除以 4 来计算。
这是我们“无操作”函数的代码。
push ebp
mov ebp, esp
pop ebp
ret 8
该函数在离开函数之前,通过 `ret 8` 指令自己设置栈指针。
现在我们来探索编译器为我们生成的代码。编译器插入这段代码是为了创建栈帧,以便它可以以标准方式访问参数和局部变量。栈帧是为函数保留的内存区域,用于存储关于参数、局部变量和返回地址的信息。当调用新函数时,栈帧总是被创建;当函数返回时,栈帧被销毁。在 8086 架构上,`EBP` 寄存器用于存储栈帧的地址,有时也称为栈指针。
因此,编译器首先保存前一个栈帧的地址,然后使用 `ESP` 的值创建新的栈帧。在函数返回之前,旧栈帧的值会被保留。
现在看看栈帧里有什么。栈帧在 `EBP` 的正向偏移量处包含所有参数,在 `EBP` 的负向偏移量处包含所有局部变量。
所以函数的返回地址存储在 `EBP`,前一个栈帧的值存储在 `EBP + 4`。现在看看这个例子,它有两个参数和三个局部变量。
程序 61extern "C" void fun(int a, int b) { int x = a; int y = b; int z = x + y; return; } int main() { fun(5, 10); return 0; }
现在看看编译器生成的函数代码。
push ebp
mov ebp, esp
sub esp, 12 ; 0000000cH
; int x = a;
mov eax, DWORD PTR _a$[ebp]
mov DWORD PTR _x$[ebp], eax
; int y = b;
mov ecx, DWORD PTR _b$[ebp]
mov DWORD PTR _y$[ebp], ecx
; int z = x + y;
mov edx, DWORD PTR _x$[ebp]
add edx, DWORD PTR _y$[ebp]
mov DWORD PTR _z$[ebp], edx
mov esp, ebp
pop ebp
ret 0
那么 _x、_y 等是什么?它们在函数定义之上定义,大致如下:
_a$ = 8
_b$ = 12
_x$ = -4
_y$ = -8
_z$ = -12
这意味着你可以这样理解这段代码:
; int x = a;
mov eax, DWORD PTR [ebp + 8]
mov DWORD PTR [ebp - 4], eax
; int y = b;
mov ecx, DWORD PTR [ebp + 12]
mov DWORD PTR [ebp - 8], ecx
; int z = x + y;
mov edx, DWORD PTR [ebp - 4]
add edx, DWORD PTR [ebp - 8]
mov DWORD PTR [ebp - 12], edx
这意味着参数 a 和 b 的地址分别是 `EBP + 8` 和 `EBP + 12`。变量 x、y 和 z 的值分别存储在内存地址 `EBP - 4`、`EBP - 8` 和 `EBP - 12` 处。
掌握了这些知识后,让我们来玩一个关于函数参数的游戏。看看这个简单的程序。
程序 62#include <cstdio> extern "C" int fun(int a, int b) { return a + b; } int main() { printf("%d\n", fun(4, 5)); return 0; }
这个程序的输出是符合预期的。输出是“9”。现在稍微修改一下程序。
程序 63#include <cstdio> extern "C" int fun(int a, int b) { _asm mov dword ptr[ebp+12], 15 _asm mov dword ptr[ebp+8], 14 return a + b; } int main() { printf("%d\n", fun(4, 5)); return 0; }
这个程序的输出是“29”。我们知道参数的地址,在这个程序中我们改变了参数的值。当我们相加那些变量时,相加的是新的值,即 15 和 14。
VC 有 `naked` 属性用于函数。如果你为任何函数指定 `naked` 属性,它就不会为该函数生成序言(prolog)和尾声(epilog)代码。那么什么是序言和尾声代码呢?Prolog 是一个英语单词,意思是“开头”,是的,它也是一种用于人工智能的编程语言的名称,但那种编程语言与编译器生成的 prolog 代码没有关系。这是编译器在函数调用开始时自动插入的代码,用于设置栈帧。看看程序 61 生成的汇编语言代码。在函数开头,编译器会自动插入以下代码来设置栈帧:
push ebp
mov ebp, esp
sub esp, 12 ; 0000000cH
这段代码称为序言代码。同样,在函数末尾插入的代码称为尾声代码。在同一个程序中,编译器生成的尾声代码是:
mov esp, ebp
pop ebp
ret 0
现在看看带有 `naked` 属性的函数:
程序 64extern "C" void _declspec(naked) fun() { _asm ret } int main() { fun(); return 0; }
编译器生成的函数 fun 的代码大致如下:
_asm ret
这意味着这个函数没有序言和尾声代码。事实上,`naked` 函数有规则,也就是说,你不能在 `naked` 函数中声明自动变量,因为编译器必须为你生成代码,而在 `naked` 函数中,编译器不会为你生成任何代码。实际上,你必须自己写 `ret` 语句,否则程序会崩溃。你甚至不能在 `naked` 函数中写 `return` 语句。为什么?因为当你从函数返回一个值时,编译器会将其值放入 `eax` 寄存器。所以这意味着编译器必须为你返回语句的代码。
程序 64#include <cstdio> extern "C" int sum(int a, int b) { return a + b; } int main() { int iRetVal; sum(3, 7); _asm mov iRetVal, eax printf("%d\n", iRetVal); return 0; }
这个程序的输出是“10”。这里我们没有直接使用函数的返回值,而是将 `eax` 的值复制到调用函数后立即声明的变量中。
现在我们把整个函数变成 `naked`,并加入序言和尾声代码,使其返回两个变量相加的值。
程序 65#include <cstdio> extern "C" int _declspec(naked) sum(int a, int b) { // prolog code _asm push ebp _asm mov ebp, esp // code for add two variables and return _asm mov eax, dword ptr [ebp + 8] _asm add eax, dword ptr [ebp + 12] // epilog code _asm pop ebp _asm ret } int main() { int iRetVal; sum(3, 7); _asm mov iRetVal, eax printf("%d\n", iRetVal); return 0; }
这个程序的输出是“10”,即两个参数 3 和 7 的和。
这个属性在 ATLBASE.H 文件中用于实现 `_QIThunk` 结构体的成员。当定义了 `_ATL_DEBUG_INTERFACES` 时,这个结构体用于调试 ATL 程序的引用计数。
我希望在下一篇文章中能探索 ATL 的更多神秘之处。