
创建您自己的 Googlebot
在本文中,我将解释如何创建一个类似于 Googlebot 的应用程序——它通过超链接查找和索引网站。
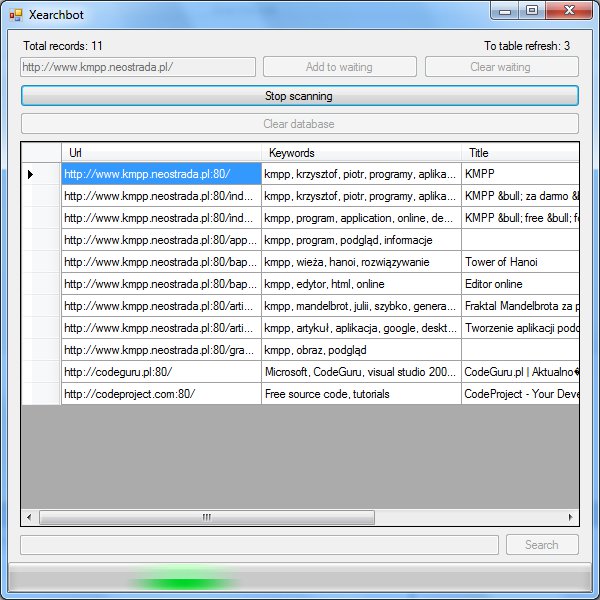
引言
Googlebot 通过超链接查找和索引网络。它仍然通过旧站点中的超链接访问新页面。我的搜索机器人(Xearchbot)可以查找站点并将其 URL、标题、关键字元标记和描述元标记存储在数据库中。将来,它将存储转换为纯文本的文档正文。我不计算 PageRank,因为它非常耗时。
在 Googlebot 下载页面之前,它会下载文件 robots.txt。此文件中包含有关机器人可以去哪里以及不能去哪里的信息。这是此文件内容的示例
# All bots can't go to folder "nobots":
User-Agent: *
Disallow: /nobots
# But, ExampleBot can go to all folders:
User-Agent: ExampleBot
Disallow:
# BadBot can't go to "nobadbot1" and "nobadbot2" folders:
Disallow: /nobadbot1
Disallow: /nobadbot2
阻止 Googlebot 的第二种方法是:Robots 元标记。其 name 属性为“robots”,content 属性的值由逗号分隔。有“index”或“noindex”(文档是否可以索引)和“follow”或“nofollow”(是否跟踪超链接)。对于索引文档和跟踪超链接,元标记如下所示
<meta name="Robots" content="index, follow" />
也支持阻止单个链接的跟踪——为此,其 rel="nofollow"。恶意软件机器人和防病毒软件机器人会忽略 robots.txt、元标记和 rel="nofollow"。我们的机器人将是一个正常的搜索机器人,并且必须允许所有以下阻止程序。
有一个名为 User-Agent 的 HTTP 头。在此头中,客户端应用程序(例如,Internet Explorer 或 Googlebot)将进行呈现。例如,IE6 的 User-Agent 如下所示
User-Agent: Mozilla/4.0 (Compatible; Windows NT 5.1; MSIE 6.0)
(compatible; MSIE 6.0; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
是的,Internet Explorer 的 HTTP 名称是 Mozilla... 这是 Googlebot 2.1 User-Agent 头
User-Agent: Googlebot/2.1 (+http://www.googlebot.com/bot.html)
括号中,加号字符后面的地址是有关机器人的信息。我们为我们的机器人在此头中放入类似的数据。
为了加快搜索机器人的速度,我们可以支持 GZIP 编码。我们可以添加值为“gzip”的 Accept-Encoding 头。有些网站允许 GZIP 编码,如果接受 gzip,它们会向我们发送压缩文档。如果内容已压缩,则服务器将在响应中添加值为“gzip”的 Content-Encoding 头。我们可以使用 System.IO.Compression.GZipStream 解压缩文档。
对于解析 robots.txt,我使用 string 函数(IndexOf、Substring...),对于解析 HTML,我使用正则表达式。在本文中,我们将使用 HttpWebRequest 和 HttpWebResponse 下载文件。最初,我考虑使用 WebClient,因为它更容易,但在该类中我们无法设置下载超时。
对于本文,需要 SQL Server(可以是 Express)和基本的 SQL 知识(DataSets 等)。
基础知识已讨论,现在让我们编写一个搜索机器人!
数据库
首先我们必须创建一个新的 Windows Forms 项目。现在添加一个名为 SearchbotData 的本地数据库并创建其名为 SearchbotDataSet 的 DataSet。向数据库添加表 Results
| 列名 | 数据类型 | 长度 | 允许空值 | 主键 | 身份 |
id_result |
int |
4 | 否 | 是 | 是 |
url_result |
nvarchar |
500 | 否 | 否 | 否 |
title_result |
nvarchar |
100 | 是 | 否 | 否 |
keywords_result |
nvarchar |
500 | 是 | 否 | 否 |
description_result |
nvarchar |
1000 | 是 | 否 | 否 |
在此表中,我们将存储结果。将此表添加到 SearchbotDataSet。
准备工作
首先,我们必须添加以下 using 语句
using System.Net;
using System.Collections.ObjectModel;
using System.IO;
using System.IO.Compression;
using System.Text.RegularExpressions;
站点将在 Collection 中等待索引
Collection<string> waiting = new Collection<string>(); // Here sites wait for indexing
在网络中,有数十亿个页面,而且它们的数量还在不断增加。我们的机器人永远无法完成索引。所以我们必须有一个变量来停止机器人
bool doscan; // Do scanning. If doscan is false then main bot function will exit.
机器人函数将在开始索引下一页之前检查此变量。让我们添加 Scan 方法 - 我们机器人引擎的主要功能。
/// <summary>
/// Scans the web.
/// </summary>
void Scan()
{
while (waiting.Count > 0 && doscan)
{
try
{
string url = waiting[0];
waiting.RemoveAt(0);
Uri _url = new Uri(url);
}
catch { }
}
}
索引页面的代码将在循环中。开始时,等待队列中必须至少有一个包含超链接的页面。当页面被解析后,它将从等待队列中删除,但找到的超链接将被添加——因此我们有了循环。Scan 函数可以通过例如 BackgroundWorker 在其他线程中运行。
解析 robots.txt
在我们开始索引任何网站之前,我们必须检查 robots.txt 文件。让我们编写一个用于解析此文件的类。
在我的机器人中,我将这个类命名为 RFX - Robots.txt For Xearch。
/// <summary>
/// Robots.txt For Xearch.
/// </summary>
class RFX
{
Collection<string> disallow = new Collection<string>();
string u, data;
/// <summary>
/// Parses robots.txt of site.
/// </summary>
/// <param name="url">Base url of site</param>
public RFX(string url)
{
try
{
u = url;
}
catch { }
}
}
url 参数是不带“/robots.txt”的地址。构造函数将下载并解析文件。因此,下载文件:首先创建请求。所有内容都必须在内部 try 语句中,因为会抛出 HTTP 错误。
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(u + "/robots.txt");
req.UserAgent = "Xearchbot/1.1 (+http://www.kmpp.neostrada.pl/xearch.htm)";
req.Timeout = 20000; // Maximal downloading time is 20 seconds.
现在获取响应及其 stream
HttpWebResponse res = (HttpWebResponse)req.GetResponse();
Stream s = res.GetResponseStream();
我们可以通过 StreamReader 从 s 读取所有数据。
StreamReader sr = new StreamReader(s);
data = sr.ReadToEnd();
下载结束时,我们必须关闭所有内容
sr.Close();
res.Close();
现在下载的 robots.txt 存储在 data 变量中,因此我们可以对其进行解析。编写用于解析单个代理部分的功能。
/// <summary>
/// Parses agent in robots.txt.
/// </summary>
/// <param name="agent">Agent name</param>
/// <returns>True if agent exists, false if don't exists.</returns>
bool parseAgent(string agent)
{
}
如果存在针对我们机器人的特定部分,则我们必须仅解析该部分,否则我们必须解析所有机器人的部分。因此将以下行添加到构造函数中。
// If it's section for Xearchbot then don't parse section for all bots.
if (!parseAgent("Xearchbot"))
parseAgent("*");
现在让我们编写 parseAgent 的代码。首先,我们必须找到指定用户代理部分的开头
int io = data.LastIndexOf("User-agent: " + agent); // Start of agent's section
if (io > -1)
{
int start = io + 12 + agent.Length;
return true;
}
else
return false;
如果该节存在,则最后返回 true,否则返回 false。现在我们必须找到结束。将其添加到 start 行之后。
int count = data.IndexOf("User-agent:", start); // End of agent's section
if (count == -1)
count = data.Length - start; // Section for agent is last
else
count -= start + 1; // end - start = count
现在我们有了带有解析命令的区域。我不会再延长了,添加这些行
while ((io = data.IndexOf("Disallow: /", start, count)) >= 0) // Finding disallows
{
count -= io + 10 - start; // Recalculating count
start = io + 10; // Moving start
string dis = data.Substring(io + 10); // The path
io = dis.IndexOf("\n");
if (io > -1)
dis = dis.Substring(0, io).Replace("\r", ""); // Cutting to line end
if (dis[dis.Length - 1] == '/')
dis = dis.Substring(0, dis.Length - 1); // Deleting "/" at the end of path.
disallow.Add(u + dis); // Adding disallow
}
这些行查找并解析 Disallow 语句。现在添加一个新方法来检查我们是否可以解析文档
/// <summary>
/// Checks we can allow the path.
/// </summary>
/// <param name="path">Path to check</param>
/// <returns>True if yes, false if no.</returns>
public bool Allow(string path)
{
foreach (string dis in disallow)
{
if (path.StartsWith(dis))
return false;
}
return true;
}
这将路径与每个不允许的路径进行比较。
现在回到主窗体类并添加机器人文件集合
Dictionary<string, RFX> robots = new Dictionary<string, RFX>(); // Parsed robots files
我们将在其中存储编译后的机器人文件。
检查 URL
我们的机器人将仅支持 HTTP 和 HTTPS 协议。因此,我们必须在 Scan 函数的 try 中检查 url 的方案
Uri _url = new Uri(url);
if (_url.Scheme.ToLower() == "http" || _url.Scheme.ToLower() == "https")
{
}
地址可以有不同的协议。为了消除歧义,让我们重新格式化 url
string bu = (_url.Scheme + "://" + _url.Host + ":" + _url.Port).ToLower();
url = bu + _url.AbsolutePath;
bu 变量是 RFX 的 baseUrl。现在每个协议都在路径中指定,默认协议 (80) 也是如此。
地址可以被索引,然后我们不应该第二次索引。因此,让我们向 ResultsTableAdapter 添加一个新查询(在将 Result 表添加到数据集时应创建它)。该查询将是 SELECT 类型,它返回一个单一值。它的代码
SELECT COUNT(url_result) FROM Results WHERE url_result = @url
将其命名为 CountOfUrls。它返回指定 URL 的计数。通过使用它,我们可以检查 URL 是否在数据库中。
在主窗体中,添加一个 resultsTableAdapter。如果要在 DataGrid 中显示结果并在扫描时刷新它,请使用 2 个表适配器 - 第一个用于显示,第二个用于 Scan 函数。所以我们必须检查 url 是否已索引
if (resultsTableAdapter2.CountOfUrls(url) == 0)
{
}
现在我们必须检查 robots.txt。我们已经为这些解析的文件声明了一个 Dictionary。如果我们有该站点的已解析 robots.txt,我们从 Dictionary 中获取它,否则我们必须解析 robots.txt 并将其添加到 Dictionary 中。
RFX rfx;
if (robots.ContainsKey(bu))
{
rfx = robots[bu];
}
else
{
rfx = new RFX(bu);
robots.Add(bu, rfx);
}
现在解析后的文件在 rfx 中,我们可以检查 URL
if (rfx.Allow(url))
{
}
url 已检查。我们现在可以继续解析文件。
下载文档
如何下载文档,您已经从“解析 robots.txt”部分了解到。这里更复杂,因为我们必须检查文档类型。
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.UserAgent = "Xearchbot/1.1 (+http://www.kmpp.neostrada.pl/xearch.htm)";
req.Timeout = 20000;
HttpWebResponse res = (HttpWebResponse)req.GetResponse();
有关文档类型的信息在 Content-Type 头中。此头的值的开头是文档的 MIME 类型。通常在 MIME 之后,还有其他信息,用分号分隔。所以解析 Content-Type 头
string ct = res.ContentType.ToLower();
int io = ct.IndexOf(";");
if (io != -1)
ct = ct.Substring(0, io);
HTML 文档的 MIME 类型是 text/html,XHTML 文档也可以是 text/html 或 application/xhtml+xml。因此,如果文档类型是 text/html 或 application/xhtml+xml,我们可以处理该文档。
if (ct == "text/html" || ct == "application/xhtml+xml")
{
}
res.Close();
最后,我们必须关闭响应。现在我们必须从文档中读取所有数据(当然将其放在 if 内部)
Stream s = res.GetResponseStream();
StreamReader sr = new StreamReader(s);
string d = sr.ReadToEnd();
sr.Close();
解析元标记
是时候解析文档了。对于解析 HTML 元素,我选择了正则表达式的方式。在 .NET 中,我们可以通过 System.Text.RegularExpressions.Regex 类使用它们。正则表达式是用于比较 string 的强大工具。我不会解释语法。为了查找和解析元标记,我设计了以下正则表达式
<meta(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*\/?>
正则表达式可以存储匹配字符串的某些部分。此正则表达式存储属性的名称和值。
因此在类中声明此正则表达式
/// <summary>
/// Regular expression for getting and parsing Meta tags.
/// </summary>
public Regex parseMeta = new Regex(@"<meta(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*\/?>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
这里有转义的引号字符。这个正则表达式有 Compiled 和 IgnoreCase 标志。我认为我不需要解释它们是什么意思。现在进入循环并声明这些变量
string title = "";
string keywords = "";
string description = "";
bool cIndex = true;
bool cFollow = true;
让我们解析元标签。使用正则表达式,这非常简单
MatchCollection mc = parseMeta.Matches(d);
mc 是找到的元标签的集合。现在我们必须处理所有元标签
foreach (Match m in mc)
{
}
在 m 中,我们找到了一个元标签。我们想读取属性。我们可以从 Groups 属性中获取捕获的名称和值。
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
在 names 中,我们有属性的名称,在 values 中,我们有相同顺序的属性值。如果元标签正确,则名称的数量等于值的数量
if (names.Count == values.Count)
{
}
现在让我们声明将包含元标记名称和内容的变量
string mName = "";
string mContent = "";
现在我们必须在 names 和 values 中找到 name 和 content 属性。
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "name")
mName = value.ToLower();
else if (name == "content")
mContent = value;
}
我们在 mName 中有元标记的名称,在 mContent 中有元标记的内容。我们的机器人将检查机器人元标记,但它也会存储关键字和描述元标记。所以解析它
switch (mName)
{
case "robots":
mContent = mContent.ToLower();
if (mContent.Trim().ToLower().IndexOf("noindex") != -1)
cIndex = false;
else if (mContent.IndexOf("index") != -1)
cIndex = true;
if (mContent.IndexOf("nofollow") != -1)
cFollow = false;
else if (mContent.IndexOf("follow") != -1)
cFollow = true;
break;
case "keywords":
keywords = mContent;
break;
case "description":
description = mContent;
break;
}
关键字和描述很简单——我们不需要解析它们。Robots 元标签更复杂,因为它控制着机器人,我们必须解析它。元标签解析完成。
解析超链接和基本标签
为了解析超链接,我创建了另一个正则表达式
<a(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*>
在 HTML 中,有一个标签用于更改所有链接的基本路径。我们必须在我们的机器人中实现这一点。有一个用于解析它的正则表达式
<base(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*\/?>
我们必须声明它
/// <summary>
/// Regular expression for getting and parsing A tags.
/// </summary>
public Regex parseA = new Regex(@"<a(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
/// <summary>
/// Regular expression for getting and parsing base tags.
/// </summary>
public Regex parseBase = new Regex(@"<base(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*\/?>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
让我们编写用于解析超链接并将其添加到等待队列的方法。
void follow(string d, Uri abs)
{
}
我们必须查找和解析标签
MatchCollection bases = parseBase.Matches(d);
mc = parseA.Matches(d);
foreach (Match m in mc)
{
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
if (names.Count == values.Count)
{
string href = "";
string rel = "";
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "href")
href = value;
else if (name == "rel")
rel = value;
}
}
}
我们必须检查 rel 属性。如果其值为 nofollow,则我们不需要将其添加到等待队列。如果 href 为空,则我们也不将 URL 添加到等待队列。href 可以是相对路径。因此我们必须将其与 abs 连接起来。
if (rel.IndexOf("nofollow") == -1 && href != "")
{
Uri lurl = new Uri(abs, href);
waiting.Add(lurl.ToString());
}
现在可以回到 Scan 方法。我们必须检查 cFollow 变量——我们在其中存储从机器人元标记中解析出的值。
if (cFollow)
{
}
让我们解析 base 标签
mc = parseBase.Matches(d);
Uri lastHref = _url;
for (int j = 0; j < mc.Count; j++)
{
Match m = mc[j];
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
if (names.Count == values.Count)
{
string href = "";
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "href")
href = value.ToLower();
}
}
}
超链接也可以在第一个 base 标签之前。因此,在循环之前,我们必须用默认的绝对路径(文档路径)解析超链接
string d2 = d;
if (mc.Count > 0)
d2.Substring(0, mc[0].Index);
follow(d2, _url);
现在让我们解析每个 base 标签的链接部分
d2 = d.Substring(m.Index);
if (j < mc.Count - 1)
d2.Substring(0, mc[j + 1].Index);
if (href != "")
lastHref = new Uri(href);
follow(d2, lastHref);
当 base 标签没有 href 属性时,我们使用最近一个 base 标签的 href。
解析标题并添加到数据库
现在是标题和将索引文档添加到数据库的时候了。我们必须检查 index。
if (cIndex)
{
}
现在我们必须声明用于解析标题的 regex
/// <summary>
/// Regular expression for getting title of HTML document.
/// </summary>
public Regex parseTitle = new Regex(@"<title(?:\s+(?:[a-zA-Z_\-]+)" +
"\s*\=\s*(?:[a-zA-Z_\-]+|\" + '"' + @"[^\" + '"' + @"]*\" + '"' +
@"))*\s*>([^<]*)</title>", RegexOptions.Compiled | RegexOptions.IgnoreCase);
所以让我们解析标题
mc = parseTitle.Matches(d);
if (mc.Count > 0)
{
Match m = mc[mc.Count - 1];
title = m.Groups[1].Captures[0].Value;
}
我们只考虑标题标签的最后一次出现。现在我们必须添加新的 SQL INSERT 命令,用于向表中添加一行。它的名称将是 InsertRow。这就是命令
INSERT INTO Results (url_result, title_result, keywords_result, description_result)
VALUES (@url, @title, @keywords, @description)
现在我们可以将结果添加到 Results 表中
resultsTableAdapter2.InsertRow(url, title.Trim(), keywords.Trim(), description.Trim());
这将在标题解析后添加。
GZIP 编码
我们可以使用 GZIP 编码来加快下载速度。有些网站支持此功能。
我们必须向请求添加 Accept-Encoding 头
req.Headers["Accept-Encoding"] = "gzip";
当我们获得 stream
Stream s = res.GetResponseStream();
...我们必须检查 stream 是否被 gzip 压缩,如果是,则解压缩
Stream s;
if (res.Headers["Content-Encoding"] != null)
{
if (res.Headers["Content-Encoding"].ToLower() == "gzip")
s = new GZipStream(res.GetResponseStream(), CompressionMode.Decompress);
else
s = res.GetResponseStream();
}
else
s = res.GetResponseStream();
您可以将其添加到 Scan 方法和 RFX 中。
机器人已完成!
结论
网络中有数十亿个页面,而且它们的数量还在不断增加。为了阻止机器人,我们可以使用 robots.txt 文件、robots 元标记和 rel="nofollow" 属性。恶意机器人将忽略这些阻止程序。为了加快下载速度,我们可以使用 GZIP 编码。正则表达式是解析 string 的强大工具。
历史
- 2011-08-20 - 首次发布
- 2011-08-22 - 更正,支持
base标签