
VTD-XML:面向未来的 XML 处理(第二部分)
4.60/5 (26投票s)
揭示 XML 处理的第一个问题,并解释为什么以文档为中心的 XML 处理是未来。
摘要
Code Project 的大多数读者都熟悉 .NET 环境中的各种 XML 解析器。本系列文章向 Code Project 社区介绍了一种新的 XML 处理模型,称为 VTD-XML。它在根本上克服了阻碍 SOA 和企业 XML 应用程序开发的许多棘手技术挑战,因此远远超出了传统模型。本系列的第一个部分演示了 VTD-XML 作为索引器和具有集成 XPath 的解析器的优势。第二部分展示了如何利用 VTD-XML 的剪切、编辑和修改功能,并介绍了“以文档为中心”的 XML 处理概念。本系列的第三部分将展示如何在 VTD-XML 的 C 版本中编写应用程序。
头号公敌:DOM 修改 XML 的问题
假设一个基于 DOM 的应用程序修改 XML 文档的特定文本节点,以下是完成该操作的必要步骤:
- 解码字符
- 通过拆分输入文档来创建字符串对象
- 分配节点对象以构建 DOM 树
- 导航到文本节点(手动或通过 XPath)
- 附加新的文本节点
- 编码字符
- 字节连接
- 垃圾回收节点和字符串对象
但是,如果您关注目标,我认为许多读者会意识到上述过程实际上没有意义。它实际上是荒谬的。DOM 处理在这些步骤中至少会产生以下三种往返开销:
- 每次解码字符时,最终都需要再次编码。
- 每次拆分文档以进行任何更改时,都需要将其重新组合(通过连接)。
- 每次分配一个对象(例如,字符串、节点等)时,它最终都会超出范围并被垃圾回收。
由于这些往返几乎将文档恢复到原始状态,因此它们只是浪费 CPU 周期和内存。请注意,人类使用文本编辑器可以更有效地修改文本节点。要编辑文本节点,只需用记事本打开文档,将光标移到文本节点,就地进行更改,然后保存!这次更新是“增量”的,意味着它不会触及文档的不相关部分。而且,如果我们人类可以像这样编辑 XML,为什么 XML 解析器不能呢?
对我而言,这个问题的答案揭示了当今软件开发中一些根深蒂固的技术问题。以下是我对此主题的一些观察:
- 它严重影响您的应用程序性能:当应用程序以只读方式处理 XML 时,基线性能由 XML 解析决定。如果应用程序同时读取和写入 XML 数据,则基线性能通常会减半(因为序列化和反序列化的性能相等)。
- 这是一个普遍但深入的问题:您是否曾想过,鉴于 XML 无处不在,为什么似乎没有人抱怨?一种看待方式是:因为事情一直都是这样,每个人似乎都习惯了。更糟糕的是,没有解决方案可以使问题显得明显。因此,我们最终会遇到一个普遍存在但出奇不明显且几乎无法逃脱的问题。
- 隐藏在面向对象的视角中:如果您生活在纯粹的面向对象世界中,冗余的反序列化/序列化过程——XML 处理的教科书式方法——确实是正确的事情。因此,这个问题再次被隐藏了。
值得注意的是,这个问题并非小事。在我看来,**它是当今企业 IT 中最大、最棘手aneous技术问题。** 考虑我在本系列第一部分中使用的 ESB(企业服务总线)示例。目前,在我看来,情况非常糟糕。由于 DOM 解析效率低下,这些 ESB 在只读情况下已经很慢,尤其是对于大型 XML 消息。如果所需的操作(例如策略执行)需要读写,那就雪上加霜了:无论更改多么微不足道,整个 XML 消息都需要重新序列化,从而迅速将整体性能降低到难以忍受的地步。
所以,我的问题是:我是唯一看到房间里的大象的人吗?
VTD-XML 如何改变局面
简单来说,VTD-XML 提供了一个如此出色的解决方案,以至于该问题**完全**消失了!
本系列文章的第一部分将 VTD-XML 介绍为一种内存高效、高性能的 XML 解析器,具有集成的索引和 XPath。VTD-XML 的几乎所有技术优势,或多或少都是非提取式解析的结果,这意味着原始 XML 文本被加载到内存中并被完整保留。然而,**VTD-XML 最重要的优势**——那些真正使其区别于其他 XML 处理模型的优势——**在于其在字节级别操作 XML 文档内容的能力**。以下是 VTD-XML 最新版本中提供的三组截然不同但又相关的功能。
- 增量 XML 修改器——您可以通过 `XMLModifier` 逐步修改 XML 文档,它定义了三种“修改”操作:“插入”新内容到文档的任何位置(即偏移量),“删除”内容(通过指定偏移量和长度),以及“替换”旧内容为新内容——这实际上是在同一位置进行删除和插入。要合成一个包含所有更改的新文档,您需要调用 `XMLModifier` 的 `output(...)` 方法。
- XML 切片器和拼接器——您可以使用一对整数(偏移量和长度)来寻址 XML 文本的段,因此您的应用程序可以从原始文档中切片该段并将其移动到同一文档或不同文档的另一个位置。`VTDNav` 类公开了两个方法来寻址元素片段:`getElementFragment()`,它返回一个 64 位整数,表示当前元素的偏移量和长度值,以及 `getElementFragmentNs()`(最新版本),它返回一个 `ElementFragmentNs` 对象,表示一个“命名空间补偿”的元素片段。最新版本还透明地支持转码,因此您可以在具有不同编码格式的文档之间进行剪切和粘贴。
- XML 编辑器——您可以使用 `VTDNav` 的 `overWrite(...)` 方法直接编辑 XML 文本的内存副本,前提是您要覆盖的原始令牌足够宽以容纳新的字节内容。
使用 VTD-XML 作为增量修改器来更新文本节点,您基本上是将 VTD 记录导航到正确的位置,插入更改,然后生成一个新文档——这与您使用记事本的方式完全相同。下面是一个使用 VTD-XML 更新文本节点的简单应用程序。
以下是更改前后的 XML 文档。
| old.xml | new.xml |
<root attr1='va'>
<b> text </b>
<c> test </c>
</root>
|
<root attr1='va' >
<b> new text </b>
<c> test </c>
</root>
|
using com.ximpleware;
namespace example1
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
if (!vg.parseFile("D:/codeProject/app2/example1/example1/old.xml", true))
return;
VTDNav vn = vg.getNav();
XMLModifier xm = new XMLModifier(vn);
if (vn.toElement(VTDNav.FIRST_CHILD))
{
int i = vn.getText();
if (i != -1)
xm.updateToken(i, " new text");
}
xm.output("D:/codeProject/app2/example1/example1/new.xml");
}
}
}
XML 处理:面向对象与面向文档
传统的 XML 处理模型(如 DOM、SAX 和各种对象数据绑定工具)围绕对象概念设计。XML 文本——仅仅是对象序列化的输出——被降级为二等公民。您的应用程序基于 DOM 节点、字符串和各种业务对象,但很少基于物理文档。如果您一直关注我的分析,就会发现这种面向对象的 XML 处理方法几乎没有意义,因为它从几乎所有方向都导致性能下降(可以在“二进制 XML 的性能问题”中找到对该主题的深入讨论)。对象创建和垃圾回收本身就占用大量内存和 CPU 资源,而且即使对原始文本进行最小的更改,应用程序也会产生重新序列化的成本。

什么是“面向文档”的 XML 处理?在非提取式解析中,XML 文本——持久数据格式——是一切的起点。无论是解析、XPath 求值、修改内容还是切片元素片段,默认情况下,您不再处理对象。只有当有意义时,您才会这样做。通常,您将文档纯粹视为语法,并以字节、字节数组、整数、偏移量、长度、片段和命名空间补偿片段来思考。此范例中的一等公民是 XML 文本。而且,如图 1 所示,XML 处理的面向对象的概念,如序列化和反序列化(或编组和解编组),通常被更面向文档的概念(如解析和组合)所取代,如果不是替换的话。您会发现,您的 XML 编程体验越来越简单。毫不奇怪,思考 XML 处理的更简单、更直观的方式也是最有效和最强大的(参见表 1,DOM 和 VTD-XML 的技术比较)。
| 面向对象的 XML 处理 (DOM) | 面向文档的 XML 处理 (VTD-XML) | |
| 解析 | 由于对象创建而速度慢 | 快得多(比 DOM 快 5-10 倍) |
| 内存使用 | 高(文档大小的 5-10 倍) | 低(文档大小的 1.3-1.5 倍) |
| 索引 | 否 | 是(消除了解析开销) |
| 修改 | 需要重新序列化 | 增量式 |
| 剪切、粘贴、拆分、拼接 | 否 | 是 |
SOA 的转折点
阅读了 Code Project 上许多精彩的文章后,在我看来,社区中的许多读者是职业生涯中忠实的、热情的面向对象方法论的实践者。但在我看来,面向对象可能并不总是适合这项工作的工具。从纯粹的面向对象角度处理 XML 时,序列化/反序列化问题变得不可见,这告诉我这种设计方法存在实际限制。在分布式计算领域,普遍的共识是对象在进程边界(例如,跨网络)上的分布不佳。从 90 年代初开始,分布式计算社区花了大约 10 年时间试图找出让分布式对象(即 CORBA)工作得像它们驻留在同一地址空间中的方法。但是,由于众多技术问题,这项努力最终被放弃了(有关更多阅读,请访问 CORBA 的兴衰)。其中一些问题包括紧耦合、僵化和窒息的复杂性。正是 CORBA 的痛苦教训引领我们走向 SOA,SOA 通过明确地将 XML 消息(线路上格式)暴露为服务的公共契约来实现松耦合和简单性。换句话说,在构建松耦合服务时,要考虑消息。
“面向文档”的 XML 处理如何融入并增强 SOA 的技术基础?简单来说,通过将 XML 视为文档(而不是对象的序列化),您不仅获得了松耦合和简单性,还获得了效率。通常,将 XML 看作对象没有意义。考虑一个聚合多个服务的 SOA 中介应用程序。它所做的几乎所有事情就是将多个文档的片段拼接在一起,组成一个更大的文档,然后将其向上推。对象在哪里发挥作用?再以服务分发点为例。情况恰恰相反:大型 XML 文档被分割成多个较小的文档,每个文档随后被转发给相应的接收者(下游服务)进行进一步处理。您是否看到了分配大量对象的必要性?随着越来越多的服务上线,您会发现复合服务/应用程序主要涉及本地化地切片、编辑、修改、拼接和拆分文档。传统的面向对象设计模式将不再适用。而且,一旦您跨越了面向对象的界限进入面向文档的世界,您就会发现问题和解决方案都变得显而易见。一切似乎都变得合理了。但是这样做可能并不容易:您首先需要有勇气拒绝随波逐流,去做周围没有人做的事情。Web 正在围绕 SOA 的概念发生深刻的变革。您通过正确地进行 SOA 所获得的经验,最终将是既有益又有价值的。
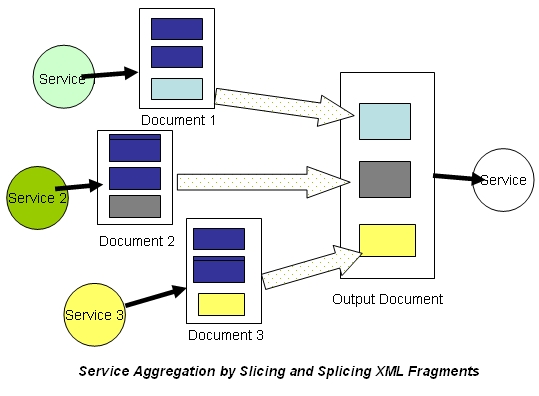
总之,为了让自己为即将到来的面向服务计算浪潮做好准备,现在可能是开始拥抱这种 XML 处理的“面向文档”视图的好时机。
代码示例
在本文的其余部分,我将向您展示如何使用 VTD-XML 的剪切、拆分、编辑和转码功能,以灵活高效的方式操作 XML 内容。为了理解代码的作用,每个示例都将应用程序的输入和输出并列。
删除属性和元素
| old.xml | new.xml |
<root attr1='va'>
<b> text </b>
<c> test </c>
</root>
|
<root
|
using com.ximpleware; namespace example2 { class Program { static void Main(string[] args) { VTDGen vg = new VTDGen(); if (!vg.parseFile("D:/codeProject/app2/example2/example2/old.xml", true)) return; VTDNav vn = vg.getNav(); XMLModifier xm = new XMLModifier(vn); int i = vn.getAttrVal("attr1"); if (i != -1) xm.removeAttribute(i - 1); if (vn.toElement(VTDNav.FIRST_CHILD)) { xm.remove(); } xm.output("D:/codeProject/app2/example2/example2/new.xml"); } } }
在文档之间剪切和粘贴命名空间补偿的元素片段
| old.xml | old2.xml | new.xml |
<a>
<b> text</b>
<c> text</c>
<d> text</d>
</a>
|
<?xml version='1.0'
encoding='utf-16le'?>
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
|
<a>
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
<b> text</b>
<root xmlns:bad='something'>
<ns:good xmlns:ns='' attr= 'val^'>
</ns:good>
<text> val_ </text>
</root>
<c> text</c>
<d> text</d>
</a>
|
using System;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example3
{
class Program
{
static void Main(string[] args)
{// test2 encoded in UTF-16LE format
VTDGen vg = new VTDGen();
if (vg.parseFile("D:/codeProject/app2/example3/example3/old2.xml",
true) == false)
return;
VTDNav vn = vg.getNav();
byte[] ba = null;
long l;
ba = vn.getXML().getBytes();
ElementFragmentNs efn = vn.getElementFragmentNs();
// test encoded in UTF-8
if (vg.parseFile("D:/codeProject/app2/example3/example3/old.xml",
false) == false)
return;
VTDNav vn2 = vg.getNav();
vn2.toElement(VTDNav.FIRST_CHILD);
XMLModifier xm = new XMLModifier(vn2);
// insert UTF-16-LE encoded elementFragmentNs into a UTF-8 encoded doc
xm.insertAfterElement(efn);
xm.insertBeforeElement(efn);
// transcoding is done underneath
xm.output("D:/codeProject/app2/example3/example3/new.xml");
}
}
}
重新排列元素片段
| input.xml | output.xml |
<root>
<a>text</a>
<b>text</b>
<c>text</c>
<a>text</a>
<b>text</b>
<c>text</c>
<a>text</a>
<b>text</b>
<c>text</c>
</root>
|
<root>
<a>text</a>
<a>text</a>
<a>text</a>
<b>text</b>
<b>text</b>
<b>text</b>
<c>text</c>
<c>text</c>
<c>text</c>
</root>
|
using System.IO;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example4
{
class Program
{
static void Main(string[] args)
{
AutoPilot ap1 = new AutoPilot();
AutoPilot ap2 = new AutoPilot();
AutoPilot ap3 = new AutoPilot();
ap1.selectXPath("/root/a");
ap2.selectXPath("/root/b");
ap3.selectXPath("/root/c");
byte[] ba1, ba2, ba3;
VTDGen vg = new VTDGen();
Encoding eg = System.Text.Encoding.GetEncoding("utf-8");
if (vg.parseFile("D:/codeProject/app2/example4/example4/input.xml", false))
{
VTDNav vn = vg.getNav();
ap1.bind(vn);
ap2.bind(vn);
ap3.bind(vn);
FileStream fos =
new FileStream("D:/codeProject/app2/example4/example4/new.xml",
System.IO.FileMode.OpenOrCreate);
ba1 = eg.GetBytes("" );
ba2 = eg.GetBytes("");
ba3 = eg.GetBytes("\r\n");
byte[] ba = vn.getXML().getBytes();
fos.Write(ba1, 0, ba1.Length);
while (ap1.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
// resetXPath is good if you want to reuse it
ap1.resetXPath();
while (ap2.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
ap2.resetXPath();
while (ap3.evalXPath() != -1)
{
long l = vn.getElementFragment();
int offset = (int)l;
int len = (int)(l >> 32);
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba, offset, len);
}
ap3.resetXPath();
fos.Write(ba3, 0, ba3.Length);
fos.Write(ba2, 0, ba2.Length);
}
}
}
}
编辑已索引的模板然后将其转储到文件中
| Input.vxl 的文本内容 | output.xml |
<!--an XML template, notice the attr val
and text are whitespaces -->
<a attr=' '>
<b> </b>
</a>
|
<!--an XML template, notice the attr val
and text are whitespaces -->
<a attr=' val '>
<b>text </b>
</a>
|
using System;
using System.Collections.Generic;
using System.Text;
using com.ximpleware;
namespace example6
{
class Program
{
static void Main(string[] args)
{
VTDGen vg = new VTDGen();
VTDNav vn = vg.loadIndex("D:/codeProject/app2/example6/example6/input.vxl");
int i = vn.getAttrVal("attr");
Encoding eg = System.Text.Encoding.GetEncoding("utf-8");
if (i != -1)
{
vn.overWrite(i,eg.GetBytes(" val"));
}
if (vn.toElement(VTDNav.FIRST_CHILD))
{
i = vn.getText();
vn.overWrite(i, eg.GetBytes("text"));
}
vn.dumpXML("D:/codeProject/app2/example6/example6/out.xml");
}
}
}
回顾和结论
我希望本文能够很好地向您说明 VTD-XML 如何根本性地解决了 DOM 和 SAX 的常见问题。在我看来,最简单的问题也是**最大的问题,不仅因为它影响了所有人,而且因为它如此深入以至于您已经习惯了。** 这就是 VTD-XML 再次脱颖而出的地方。无论是解析、索引、修改、剪切、拆分还是拼接 XML 文档,VTD-XML 在几乎所有可以想象的方面都表现出色,并在其他方面开辟了新天地。但是,要获得 VTD-XML 的全部好处,您首先需要走出面向对象思维的舒适区,并开始将 XML 视为文档。随着 IT 世界向面向服务的架构转型,我相信您会在许多方面发现,“面向文档”的 XML 处理方法自然而然地适用于设计和实现您的 SOA 基础设施。对我来说,这就是为什么 VTD-XML 是 XML 处理的未来,以及为什么最精彩的还在后面!
如果您访问过 VTD-XML 的项目站点,您可能已经注意到 VTD-XML 有一个 C 版本,它提供了与其 C# 对应版本完全相同的功能集。但是与 C# 不同,C 既不是面向对象的,也不是基于 VM 的。更糟糕的是,C 甚至不支持异常。因此,将 VTD-XML 从 C# 移植到 C 会带来有趣的挑战。在本系列的下一部分中,我将讨论如何克服这些挑战,以最大化代码重用并最小化移植工作。
相关文章
历史
- 2008 年 3 月 13 日 - 初次提交。
- 2008 年 4 月 5 日 - 添加了相关文章部分。