
性能比较 LINQ to SQL / ADO / C#
4.66/5 (19投票s)
本文旨在比较现有方法和随之发布的新方法
目录
- 引言
- 运行示例所需
- 开始之前,请阅读以下内容
- 代码解释
- 插入行 — ADO vs LINQ 使用存储过程
- 插入行 — ADO vs LINQ 不使用存储过程
- ADO vs. LINQ 从表中读取
- 读取 XML 文件 ADO vs. LINQ
- 访问对象(此处为数组)[传统 vs. c#3.0 vs. LINQ]
- 成果
- 插入行 — ADO vs LINQ 使用存储过程
- 插入行 — ADO vs. LINQ 不使用存储过程
- 从表中读取(ADO vs. LINQ)。5
- 读取 XML 文件 ADO vs. LINQ
- 访问对象(此处为数组)[传统 vs. c#3.0 vs. LINQ]
引言
你们中的许多人,包括我自己,都在关注 VS 2008 从其 beta 版本发布。我已经探索了一些 Silverlight 的特性;如这里所示。
从本文的角度来看,Microsoft 添加了泛型、查询运算符和 LINQ 支持。我一直想知道,当世界已经习惯了 ADO 编程,并且其对对象和 XML 都提供了支持(同样,C# 3.0 中使用泛型/聚合等)时,为什么还要添加 LINQ。这个问题促使了本文的诞生。本文旨在比较现有的方法与 C# 3.0 和 LINQ 发布的新的方法。由于比较的范围很大,我将把讨论限制在
- 使用 ADO.NET 和 LINQ 通过存储过程从 SQL Server 2005 读取数据的性能
- 使用 ADO.NET 和 LINQ 直接执行 SQL 语句从 SQL Server 2005 读取数据的性能
- 使用现有的 C# 方法与 LINQ 方法读取和操作 XML 文件的性能
- 使用传统编程、LINQ 和 C# 3.0 访问对象列表(本文中为数组)的性能
- 使用 ADO 和 LINQ 填充数据集,然后执行筛选操作,最后在筛选后进行求和的性能
在深入本文之前,我想指出,有许多方法可以以编程方式完成一项任务。我们已尽力编写最好的代码,尽管如此,为了使 LINQ 和 ADO 函数的编写更具可比性,还是引入了一些额外的行。由于代码是共享软件,您可以自由地对其进行改进和扩展。本文的基本测量单位是计算所使用的滴答数(System.StopWatch)。为了获得最佳性能值,每段性能代码都运行了 500 次。尽可能地添加了对象处置/垃圾回收的代码。本文中解释的所有代码均可下载。代码在需要的地方都进行了注释。最后,所有性能值都添加到了 Excel 文件Graphs.xls 中,并通过 Excel 图形进行可视化展示。
以下是运行函数 500 次的逻辑
- 创建数据集
- 启动 stopwatch()
- 运行测试函数(在 ActualFunction #region 下)
- 将滴答数添加到数据行
- 停止手表
- 将数据集输出到 XML,最后输出到Graph.xls
获取当前性能数据使用的配置如下
| 操作系统名称 | Microsoft(R) Windows(R) Server 2003, Ent Edition |
| 版本 | 5.2.3790 Service Pack 1 Build 3790 |
| 总物理内存 | 2,038.04 MB |
| 可用物理内存 | 872.52 MB |
| 总虚拟内存 | 2.85 GB |
| 页面文件空间 | 1.00 GB |
背景
运行示例所需
- VS 2008
- SQL Server 2005 已安装示例数据库(AdventureWorks)
- 在 Adventureworks 数据库上运行 InsertSP.sql 脚本,这将创建一个简单的存储过程,用于向 Sales.Customer 表插入值。
- 运行两个示例控制台应用程序后,它将为每个比较的 500 次传递生成以下 XML 文件,这些 XML 文件中的数据需要手动导入到Graphs.xls 文件中。
开始之前,请阅读以下内容
如果您不熟悉 LINQ、C# 3.0 的新特性,请阅读以下 URL
- LINQ 项目
- Visual C# 3.0x
- ADO.NET 无需介绍!
Using the Code
插入行 — ADO vs. LINQ 使用存储过程
用于 ADO 的函数是RetrieveUsingADO.sln 中的ADOInserting()。相同的 LINQ 对等函数是RetriveUsingLINQ.sln 中的LINQInserting()。
插入行 ADO vs LINQ 不使用存储过程
用于 ADO 的函数是RetrieveUsingADO.sln 中的ADOInsertingDirect()。相应的 LINQ 函数是RetriveUsingLINQ.sln 中的LINQInsertingDirect()。
ADO vs. LINQ 从表中读取
用于 ADO 的函数是RetrieveUsingADO.sln 中的ADOReading()。相应的 LINQ 函数是RetriveUsingLINQ.sln 中的LINQReading()。为了让函数执行更多任务,我添加了代码来在读取后添加第一列的所有值。
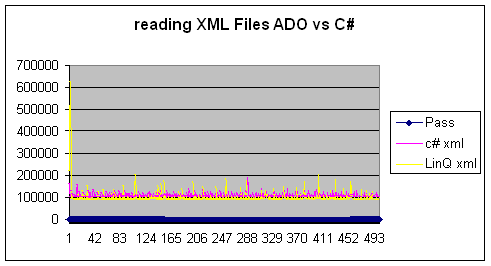
读取 XML 文件 ADO vs. LINQ
用于 ADO 的函数是RetrieveUsingADO.sln 中的xmlReading()。相应的 LINQ 函数是RetriveUsingLinQ.sln 中的LinQXmlRead()。这些函数首先读取一个 XML 文件,然后对其应用筛选(此处为值 > 250),然后添加第一列的所有值。
访问对象(此处为数组)[传统 vs. c#3.0 vs. LINQ]
LINQ 部分使用的函数是LinQObjects1(),传统 C# 部分使用的是csharpObjects1(),C# 3.0 部分使用的是LINQObjects2(),都在RetriveUsingLINQ.sln 中。
所有函数都首先创建一个整数数组,然后创建一个只包含偶数及其平方的第二个数组。函数中的最后一步是添加结果子集中的所有值。
使用 LINQ 和 ADO 填充数据集,然后执行筛选操作
LINQ 部分使用的函数是LINQQueryDataset(),ADO 部分使用的是ADODataSetQuery()。请注意,此类数据库操作资源密集,因为最小计数器值为 15 * 106。
关注点
我引用了中位数而不是平均值,以帮助减少异常值对图形的影响,因为在 Windows 操作系统中,始终有更多的进程在运行,图形中的尖峰不一定意味着代码有故障。
插入行 — ADO vs. LINQ 使用存储过程
- ADO 插入的中位数远高于 LINQ。在这种情况下,LINQ 获胜。
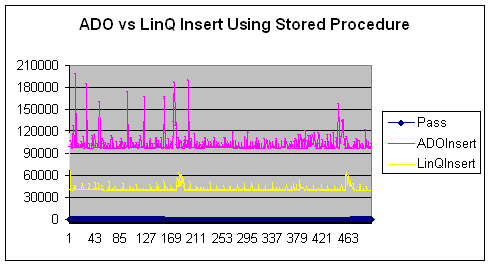
插入行 — ADO vs. LINQ 不使用存储过程
- ADO 的中位数高于 LINQ,这表明在这种情况下 LINQ 是赢家。
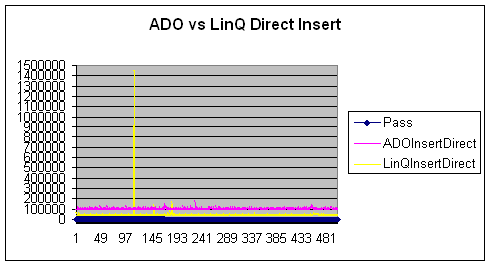
从表中读取(ADO vs. LINQ)
- 就从表中读取而言,LINQ 和 ADO 的中位数之间存在很大差异。ADO 在这里获胜,但这归因于 ADO.NET 在市场上的成熟度及其与 SQL Server 的紧密连接,或者是因为 LINQ(在我看来)通过创建 < IEnumerable> 接口和 LINQtoSQl dbml 设计器中每个绘制的对象而产生了开销。为了进一步改进,您应该尝试使用松散类型的数据集。
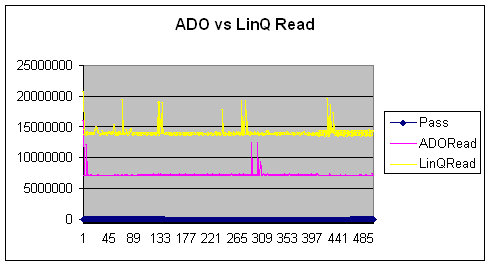
读取 XML 文件 ADO vs. LINQ
- 通过比较 C# 和 LINQ 的平均值,我们发现性能竞争非常激烈。只有 12304 滴答的微小差异,根据定义,1 秒约有 10 亿滴答。LINQ 在这里以微弱优势获胜。
访问对象(此处为数组)[传统 vs. c#3.0 vs. LINQ]
- 让我们从 LINQ Obj2 开始。在这里,添加仅偶数的平方的整个需求简化为一个语句,如下所示。最有趣的事实是,这个函数实际上不花费任何运行时间!所以 C# 3.0 语法在这里获胜。
double sum = nums.Aggregate(delegate(double Cursum, double curNum)
{
if (curNum % 2 == 0)
{
return (Cursum + (curNum * curNum));
} else
{
return (Cursum + 0);
}
});
LINQObj1,它在数组上运行 LINQ 风格的查询,如下所示。请注意,我们也可以写成temp%2 == 0,而不是 newFunction(temp),我只是想演示在 LINQ 查询的条件子句中使用函数。var getSquaresLessthen500 = from temp in nums where temp == newFunction(temp) select temp*temp;
csharpObjects1()所示。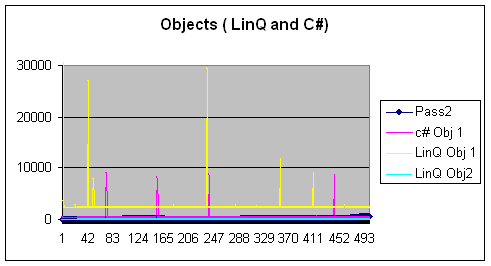
使用 LINQ 和 ADO 填充数据集,然后执行筛选操作
平均值之间存在很大差异。我认为在 LINQ 实现中,创建 DataRow 对象然后将其添加到表的那一行是性能瓶颈所在。ADO 实现在这里获胜。
table.LoadDataRow(new Object[] {
tempRec.CustomerID, tempRec.TerritoryID, tempRec.AccountNumber, tempRec.CustomerType,
tempRec.rowguid, tempRec.ModifiedDate}, true);

所以我的结论是 LINQ 并不是全面的赢家(正如预期的那样)。虽然插入操作在 LINQ 中更好,但读取操作在 ADO 中更优。XML 操作大体上相同(差异不大),对象访问基本上取决于使用的类型(尽管如此,聚合是一个很好的例子)。LINQ to datasets 相当昂贵;我建议使用 ADO 版本,并且只有在我们已经拥有数据集并希望进行查询时才使用 LINQ to objects。
为了进一步改进,我们应该尝试进行批量插入操作以及不同类型的读取(如整数读取、字符串读取、块数据读取和子字符串读取)。同样,很难根据我涵盖的有限场景得出结论。每个场景都有改进的空间,但由于我测量了所有操作的时间,这将在我们下次进行设计或架构时提供更好的见解。
附录
平均值和中位数
|
|
||||||||||
|
|
||||||||||
|
|
||||||||||
|
|
||||||||||
|
|
||||||||||
|
|||||||||||
|
|