
Vector:SQL UDT 的面向概念的方法
4.98/5 (28投票s)
UDT 编程的演练,主要关注数据库概念
目录
引言
您是否尝试在您最喜欢的开发者门户网站上搜索有关 SQL Server 用户定义类型 (UDT) 的内容? 大多数情况下,您最终会找到一些最终导致关于作者模型选择的争论,或者 UDT 是否能在软件开发中占有一席之地。 这些论证对经验丰富的开发人员来说是有益的,但对于初学者来说,它们可能会令人沮丧。 我曾经有过同样的经历,并且作为一个思想开放的人,我并不在意别人的说法,因为他们只会分散我专注于学习那些有潜力改变我们开发数据库应用方式的东西。
本文恰恰提供了我当初编写第一个 UDT 时所渴望的东西。 它从技术角度讨论 UDT,逐步指导您创建一个。 一路上,您将发现一些奇特的细节、不一致之处、晦涩的设置和解决方法。 文章还讨论了使用不同设置和 .NET 类型实现 UDT 的各种方法,并将它们进行比较,只是为了找出它们是否如普遍观念所认为的那样能在现实世界行为中得到体现。
本文采用了一种不太常规的方法,主要关注影响 UDT 结构和行为的概念,而不是实现它们的代码。 这使得文本比您典型的技术文章更冗长,所以注意力不集中的人,请注意。 对于那些乐于了解事物原因的人,请继续阅读!
什么是 UDT?
用户定义类型 (UDT) 是使用您喜欢的 .NET 语言创建的 SQL Server 数据类型。 它是您使用 SQL Server CLR 集成 (简称 SQL-CLR) 创建的工件之一。 也就是说,它是 SQL Server 最接近面向对象编程的东西。
模型
为了表达一种可能引起纯粹主义者不满的明确姿态,我们将对一个非标量实体进行建模,这个实体是——向量。向量是由大小和方向组成的量。我们将讨论限制在二维向量,它可以在笛卡尔坐标系中用两个点表示,其中一个点被理解为原点 (0,0)。因此,我们的向量同构于极坐标,从而也可以用来表示所述实体。方向的单位是弧度,以便于在 .NET 和 T-SQL 中进行操作。向量的例子有速度、加速度、力以及磁场。我将不再详细阐述向量,因为互联网上有很多关于它的好资料。对于那些需要回顾模型和此处应用的其它概念的人,这里有一些好的资源:
我们的向量是其现实世界对应物的简化模型。它很小,成员的实现也很简单。它不是工业级的;只包含足以说明 UDT 不同功能的成员。我们选择了一个简化的模型,以便能够专注于本文的主要目标,即展示如何创建 UDT,而不是如何选择正确的实体进行建模,更不用说完美化它了。
实现
安装
UDT 可以使用结构 (VB.NET 中的 structure) 或类来实现。 推荐使用 `struct`,因为它存储在堆栈上,通常速度更快。 作为一个基于集合的语言,SQL 可以在涉及大量行的事务中发挥这一优势。 它也比类实现需要更少的编码。 我们稍后通过非正式测试来了解这些理论声明是否属实。
本文中的代码使用 .NET 2.0,并针对 SQL Server 2005 和 2008 运行。 我尽可能避免使用 .NET Framework 后续版本的功能,以保持向后兼容性。 SQL Server 2008 中对 UDT 所做的更改非常细微,本文后面有一个专门的小节来介绍这些更改。
UDT,与 SQL-CLR 中的其他任何工件一样,通过 .NET 程序集集成到 SQL Server。 为此,您应该创建一个类库项目。 项目的唯一相关程序集是 `System`、`System.Data` 和 `System.Xml`,因此您可以删除 Visual Studio 默认导入的所有其他程序集。 下面展示了我们模型的初始实现:
Imports System
Namespace MathSqlObj
Public Structure Vector
Private _magnitude As Double
Private _direction As Double
Public Property Magnitude() As Double
Get
Return _magnitude
End Get
Set(ByVal value As Double)
_magnitude = value
End Set
End Property
Public Property Direction() As Single
Get
Return _direction
End Get
Set(ByVal value As Single)
_direction = value
End Set
End Property
End Structure
End Namespace
using System;
namespace MathSqlObj
{
public struct Vector
{
double _magnitude;
float _direction;
public double Magnitude
{
get { return _magnitude; }
set { _magnitude = value; }
}
public float Direction
{
set { _direction = value; }
get { return _direction; }
}
}
}
为了将我们的结构转换为 UDT,我们需要用 `Microsoft.SqlServer.Server` 命名空间中的 `SqlUserDefinedTypeAttribute` 来修饰它。 这告诉编译器我们的类型可以集成到 SQL Server 中作为 UDT。 它有一个必需的参数,指定 UDT 使用的序列化格式。 目前指定 `Format.Native`。 我们稍后会详细介绍。
Imports System
Imports Microsoft.SqlServer.Server
Namespace MathSqlObj
<SqlUserDefinedType(Format.Native)>
Public Class Vector
' Rest of the codes here...
using System;
using Microsoft.SqlServer.Server;
namespace MathSqlObj
{
[SqlUserDefinedType(Format.Native)]
public struct Vector : INullable
{
// Rest of the codes here
我们第一次接触了 UDT 编程中的属性,并且在此提醒您;请准备好应对即将到来的大量属性! UDT 涉及大量的声明式编程,以定义其在 SQL Server 中的一些行为。
伴随着首次修饰,我们的结构应该实现四个成员才能成为一个完整的 UDT。 我们将逐一添加它们,同时探索数据库和 SQL 的概念,这些概念需要它们。
初始化和赋值
在使用 UDT 之前,您必须通过为其字段赋值来初始化它。 这不像原生 SQL 类型那样简单,因为 SQL 没有构造函数和属性初始化器的概念,它们允许您分离每个字段的值。 在 UDT 中赋值,同时坚持使用标准 SQL 语法,唯一的方法是将所有值放入一大块字符串中,如下所示:

幕后发生的事情是 SQL Server 调用一个工厂函数 `Parse`,该函数接受一个表示 SQL 中输入的字符串参数。 它负责拆分输入字符串,将其转换为所需的类型,并最终将其赋值给字段。 当然,您应该提供这方面的逻辑。 您还必须提供一个分隔符,以方便拆分。 代码的大部分内容涉及格式验证,字段越多,您的工作就会越繁琐。 如果您想展示您的 RegEx 技能,这里就是合适的地方!
如果您读过很多关于验证是 UDT 最重要优势的内容,我很抱歉这篇文章让您失望了。 对我来说,知道将这些验证放在哪里就足够了。 逻辑完全取决于您。 因此,对于我们的 UDT,我们只假设所有输入都是正确的。
Public Shared Function Parse(ByVal input As SqlString) As Vector
' Happy Path! No validation!
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
Return v
End Function
static public Vector Parse(SqlString input)
{
// Happy Path! No validation!
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
return v;
}
参数的 `SqlString` 类型是强制的。 它允许使用 SQL 关键字 `NULL`,它实际上不是一个字符串,而是一种 UDT 可以假设的状态。
![]()
`SqlString` 只是 `System.Data.SqlTypes` 命名空间中许多 .NET 类型包装器之一。 它的主要目的是为 .NET 数据类型提供 NULL 状态;使其与其 SQL Server 对应物同构。 例如,`SqlDouble` 与 SQL Server `double` 数据类型同构。 这些包装器类型也可以在 UDT 中使用,但我们为字段选择了原生类型,因为模型要求如此。
我们所说的 null 状态仅与 SQL 相关,并且不同于 .NET 中的 null。 当我们处理其他必需成员时,我们将详细讨论这一点。
显示
UDT 应该能够以某种格式显示自身作为一个独立实体,使用其所有字段的值。 您可以在 `ToString` 函数中指定此格式。(是的,这是 `System.Object` 中无处不在的成员,每个类型都应该重写它。) 它的实现很简单。 只需确保您遵循良好的 UDT 设计,确保其返回值可由 `Parse` 轻松消费,就像这样:

这就是我们的向量通过其简单的 `ToString` 实现所达到的效果:
Public Overrides Function ToString() As String
Return String.Format("{0},{1}", Magnitude, Direction)
End Function
public override string ToString()
{
return string.Format("{0},{1}", Magnitude, Direction);
}
Null (空值)
在初始化部分,我提到我们的 UDT 应该能够假设一个未知的状态,称为 `null`。 这与我们在传统编程中对 `null` 的普遍看法不同,后者是对空内存的引用。 `null` 状态及其逻辑分别由 `Null` 和 `IsNull` 属性实现。 如果未正确实现,SQL Server 可能会将您的 UDT 解释为 `null`,而实际上并非如此。 这是因为 `null` 实际上是您的 UDT 的一个实例,SQL Server 将其理解为未知。 SQL Server 使用静态只读属性 `Null` 来获取此实例。(从现在开始,我将把 UDT `null` 称为 SQL-null,而将传统编程中的无效内存引用简单地称为 `null`。)
如果 `Null` 和 `Parse` 都返回我们的 UDT 的有效实例,SQL Server 将如何知道哪个是 SQL-null? 它只需检查只读属性 `IsNull`。 此成员是对 `System.Data.SqlTypes.INullable` 接口的隐式实现。 此接口实现为我们的 UDT 提供了 SQL-`null` 状态,就像 `Parse` 的 `SqlString` 参数一样。
有两种方法可以实现 UDT 的 SQL-nullability 逻辑。 第一种方法评估您字段的值,第二种方法使用一个简单的标志字段。 如果第一种方法需要 SQL-`null`,那么字段的值应该是在模型上下文中不可接受的。 假设您有一个 UDT,其中包含一个 `mass` 字段。 普遍接受质量永远不会为负。 在 UDT 中,此字段的负值可以表示 SQL-`null`
Private _mass As Double
Public Shared ReadOnly Property Null() As SimpleUdt
Get
Dim u As New SimpleUdt()
u._mass = -1 'This is the flag
Return u
End Get
End Property
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
Get
' If this instance is from Null property,
' the next line must be true
Return (_mass < 0)
End Get
End Property
double _mass;
static public SimpleUdt Null
{
get
{
SimpleUdt u = new SimpleUdt();
u._mass = -1.0 // This is the flag
return v;
}
}
public bool IsNull
{
get
{
// If this instance is from Null property,
// the next line must be true
return (_mass < 0.0;)
}
}
我个人更喜欢第二种方法,因为它简洁并且促进了代码的自我文档化。 这些也可能是它在 Visual Studio 中成为默认实现的原因。 在我们的 UDT 中,在 `Null` 属性返回该值之前,它是一个简单的标志。 以下是我们 UDT 的 SQL-nullability 和 `null` 实现:
Private _isNull As Boolean ' Will be initialized to False
Public Shared ReadOnly Property Null() As Vector
Get
Dim v As New Vector()
v._isNull = True ' Here's our flag
Return v
End Get
End Property
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
Get
Return _isNull
End Get
End Property
bool _isNull; // Will be initialized to false
static public Vector Null
{
get
{
Vector v = new Vector();
v._isNull = true; // Here's our flag
return v;
}
}
public bool IsNull
{
get { return _isNull; }
}
序列化
UDT 对象与您通常的 .NET 对象不同,因为它直接保存在磁盘上并直接从磁盘检索。 您的 UDT 和磁盘之间没有其他层来为您处理保存和检索。 这些保存和检索对象的进程分别称为二进制序列化和二进制反序列化。 其余文本可能将两者都简单地称为序列化。
如果您的字段类型易于序列化,那么 UDT 中序列化的实现是隐式的。 这些类型在编程术语中称为可比特。 它们不需要在 .NET 中进行特殊处理,因为它们的表示方式与非托管代码相同。 不需要额外的代码,我们所要做的就是告诉 SQL Server 它可以处理序列化。 我们已经在图 2 中完成了这个操作。我们的 UDT 满足原始序列化的所有条件,因此现在可以使用了。到目前为止,它应该具有以下成员:

如果至少有一个字段不可比特,那么我们必须指定 `Format.UserDefined` 作为序列化格式并手动实现序列化。 后者通过提供 `Microsoft.SqlServer.Server.IBinarySerialize` 接口的实现来完成。 此接口有两个成员,恰当地命名为 `Read` 和 `Write`。 您使用 `BinaryWriter` 参数来持久化您字段的值,使用 `BinaryReader` 来检索并将它们分配回去。 您的写入顺序应与您的读取顺序相同。 实现范围从最简单的读/写到超复杂的字节操作。 后者超出了本文的范围。
假设我们决定为我们的幅度获得最高的精度。 这正是 `System.Decimal` 的工作,SQL Server 无法序列化该类型。 手动二进制序列化仍然很简单:
' These are the fields
' we need to serialize/deserialize
Private _magnitude As Decimal
Private _direction As Single
Private _isNull As Boolean
Public Sub Write(ByVal w As System.IO.BinaryWriter) _
Implements IBinarySerialize.Write
w.Write(IsNull)
' No point of serializing
' the other fields if the UDT is SQL-NULL
If Not IsNull Then
w.Write(Magnitude)
w.Write(Direction)
End If
End Sub
Public Sub Read(ByVal r As System.IO.BinaryReader) _
Implements IBinarySerialize.Read
' Note the order
_isNull = r.ReadBoolean()
' We do the same check as that
' in the Write
If Not IsNull Then
Magnitude = r.ReadDecimal()
Direction = r.ReadSingle()
End If
End Sub
// These are the fields
// we need to serialize
decimal _magnitude;
float _direction;
bool _isNull;
void IBinarySerialize.Write(System.IO.BinaryWriter w)
{
w.Write(IsNull);
// No point of serializing
// the other fields if the UDT is SQL-NULL
if (!IsNull)
{
w.Write(Magnitude);
w.Write(Direction);
}
}
void IBinarySerialize.Read(System.IO.BinaryReader r)
{
// Note the order
_isNull = r.ReadBoolean();
// We do the same check as that
// in the Write
if (!IsNull)
{
Magnitude = r.ReadDecimal();
Direction = r.ReadSingle();
}
}
编目
我们的向量现在正式成为一个 UDT。 我们将把程序集复制到 SQL Server 并从中提取 UDT。 在 SQL Server 中创建对象的这个过程称为编目,因为您恰好使您的对象在 SQL Server 的目录视图中可见。 您应该构建类库,并将程序集复制到所需的位置。 如果您尚未启用 SQL-CLR 集成,可以执行以下语句:

编目您的 UDT 的第一步是使用 `CREATE ASSEMBLY` 命令将程序集复制到数据库。 您指定程序集的路径以及数据库中应出现的名称。 您的数据库和程序集的位置可能与我的不同,因此请相应地进行更改。 在下面的命令中,我们仅使用程序集名称作为其在数据库中的逻辑名称:

通过 `CREATE TYPE` 命令来实现我们的 UDT 的编目。 您的类型的完全限定名称,此时格式为 <数据库中的程序集名称>.[<原始程序集中的命名空间>.<原始程序集中的类型名称>]。 我们用“[]”括起命名空间和类型,因为目前 SQL-CLR 不支持命名空间。

您可以通过查询相应的目录视图来验证我们的程序集和 UDT:

当您对 UDT 的函数和某些属性参数进行修改时,`ALTER ASSEMBLY` 命令非常有用。 这可以节省您一步,因为您不再需要重新编目您的 UDT。 语法与其 `CREATE` 对应项非常相似。

如果您重命名、添加、删除成员,或对 UDT 的序列化产生影响的更改,则可能无法使用 `ALTER ASSEMBLY` 命令。 您必须重新编目所有内容。 这意味着删除程序集依赖树中的所有对象,然后重复之前的步骤。 您将在后续的 UDT 修改中使用以下命令:

我刚才提供的命令是我们需求的最紧凑变体。 请参阅 Microsoft 文档以获得有关它们的全面讨论。
试运行
现在是时候看看我们的 UDT 如何运作了。 我们将检查在执行一些最常见的 SQL 语句时内部发生了什么。 我们可以发现新东西并学到更多关于创建 UDT 的知识。 请记住,这是一个“快乐测试”;我们必须始终提供正确的输入,否则将会引发异常。
让我们首先声明我们 UDT 的一个变量,然后显示它。 果然,下面的语句打印“NULL”,因为我们还没有初始化它。
![]()
如果我们先初始化它再选择它,我们会得到一些乱码。

这一系列奇怪的字符实际上是向量的十六进制表示。 在那个十六进制中,包含着您的幅度和方向。 为了获得有意义的显示,我们需要调用 `ToString` 函数:

在我看来,如果 SQL Server 在我们省略 `ToString` 时在后台调用 `ToString`,那么与 T-SQL 的集成将会更加无缝。 这种行为将与使用 `Parse` 进行初始化相一致。
在继续之前,请注意您的 UDT 的成员是区分大小写的,下面的语句将说明这一点:

显示属性不需要调用 `ToString`,除非该类型是 UDT。 非 UDT 属性可以直接映射到某些 SQL 原生类型,因此 SQL Server 显示它们没有问题。

为了证明我们的 UDT 遵循了良好的设计,`Parse` 应该能够毫无问题地处理 `ToString`:

现在我们可以创建一个带有 `Vector` 列的表,并插入或更新行:

相等和排序
SQL 中无处不在的等于运算符“=”默认情况下与 UDT 不兼容,使用它会导致错误。

作为一名 .NET 开发者,您首先想到的可能是运算符重载。 不幸的是,SQL-CLR 尚不支持运算符重载。 好消息是,启用 UDT 中的此相等运算符支持非常简单。 我们只需告诉 SQL Server 在比较时使用字段的持久化二进制数据。 我们通过将 `SqlUserDefinedTypeAttribute` 的 `IsByteOrdered` 属性设置为 true 来做到这一点。 请注意,如果您的 UDT 是类,则会涉及额外的工作。 我们稍后会讨论这个问题。
`IsByteOrdered` 设置意味着 SQL Server 按照幅度、方向、然后是可空性进行比较。 这符合我们的需求,因为它已经符合向量相等性的语义。
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native, _
IsByteOrdered:=True)> _
Public Structure Vector
Implements INullable
' SQL Server compares magnitude first,
' followed by direction, then isNull
Private _magnitude As Double
Private _direction As Single
Private _isNull As Boolean
' Rest of the codes here...
[SqlUserDefinedType(Format.Native, IsByteOrdered=true)]
public struct Vector : INullable
{
// SQL Server compares magnitude first,
// followed by direction, then isNull
double _magnitude;
float _direction;
bool _isNull;
// Rest of the codes here
新的修饰是 UDT 的一项重大更改,因此不允许简单修改。 您必须重新编目所有内容。 重新编目后,执行最后一个命令应该没问题。

否定的等于运算符“!=”也作为逻辑结果实现:

甚至其余的相等运算符,尽管它们在 `Vector` 的上下文中没有意义:

如果 SQL Server 可以比较我们的向量,那么它肯定也可以对它们进行排序。 同样,排序 `Vector` 没有意义,但这里是:

此时,UDT 已准备好承担其他角色,例如主键、外键和索引键。 您确实可以创建这些带有 UDT 的约束,但这并不意味着您应该这样做。 UDT 不仅是违反基本关系原则的明显行为,而且 UDT 并非为此目的而构建,并且这种实现的性能损失可能非常严重。 这是一个以 UDT 作为主键的表:

验证
您是否注意到我们在图 4 中对 `Parse` 的实现有些奇怪? 该代码始终返回非 SQL-`null`,但如果我们为 UDT 赋值 `null`,它的行为则符合预期。

我们可以推断,当 `NULL` 被赋值为值时,SQL Server 可能会绕过 `Parse`。 这可能是因为显式调用 `Parse` 是另一回事 (在 T-SQL 中调用 UDT 的静态函数使用 `::` 作用域限定符)。

唯一可以得出的结论是,当我们在使用 `NULL` 关键字而不是调用 `Parse` 时,SQL Server 以某种方式标记了我们 UDT 所占用的内存为 SQL-`null`。 这次它直接处理二进制数据,而不是 `string`。 错误消息告诉我们无法使用参数的值,因为它是一个 SQL-`null`。 异常是在我们尝试拆分输入时抛出的。
显式调用 `Parse` 不是给 UDT 赋值的首选方法。 我只是为了说明这一点而展示的。 如果您仍然想谨慎行事,可以通过确保不拆分 SQL-`null` 参数来避免此异常,如下面的代码块所示:
Public Shared Function Parse(ByVal input As SqlString) As Vector
' We return null if SqlString NULL is entered
If input.IsNull Then
Return Null
End If
' Happy Path! No validation!
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
Return v
End Function
static public Vector Parse(SqlString input)
{
// We return null if SqlString NULL is entered
if (input.IsNull)
return Null;
// Happy Path! No validation!
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
return v;
}
这次,上面的语句应该可以正常工作:

这种不寻常的重载是为了提高性能。 绕过 `Parse` 意味着 SQL Server 可以像处理非 UDT 类型一样,实现处理 SQL-null 的原生方式。 这也意味着我们可以为 UDT 分配非字符串字面量来初始化它:

这可能会令人恐惧。 我们现在有类似令人讨厌的“SQL 注入”攻击的东西。 在这种情况下,这是直接的二进制反序列化攻击。 只要其二进制数据可以转换为 UDT 类型,就可以输入任意数据。 如果出现错误,或者如果出现 SQL-`null`,您就会走运;否则,它可能会破坏您的程序。 下一组语句表明,插入 12 字节 (幅度 8 字节,方向 4 字节) 的二进制数据可以避免 SQL-`null` 和 NAN (非数字),同时仍然确保产生垃圾数据。 注意,二进制数据的长度是我们将字段的长度加起来的总长度:`double`=8 + `float`=4 + `Boolean`=1 = 13。

SQL Server 提供了一种安全机制来防止这种规避,它通过一个函数来实现,该函数在执行外部二进制反序列化时被调用。 您在 `SqlUserDefinedTypeAttribute` 的 `ValidationMethodName` 属性中指定此项。 此函数应该是无参数的,并返回一个 `Boolean`,指示输入是否有效。 因此,为了说明起见,我们简化模型,只接受正幅度和介于 0 和 2PI 之间的方向。 我们的验证函数将是:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True, ValidationMethodName:="ValidateInput")> _
Public Structure Vector
Implements INullable
Private Function ValidateInput() As Boolean
Dim minDirection As Single = 0.0F
Dim maxDirection As Single = CSng((2 * Math.PI))
Return (Magnitude >= 0) AndAlso _
(Direction >= minDirection AndAlso Direction <= maxDirection)
End Function
'Rest of the codes here...
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
,IsByteOrdered=true, ValidationMethodName="ValidateInput")]
public struct Vector : INullable
{
private bool ValidateInput()
{
float minDirection = 0f;
float maxDirection = (float)(2D * Math.PI);
return (Magnitude >= 0D) &&
(Direction >= minDirection && Direction <= maxDirection);
}
// Rest of the codes here...
真实的向量没有这些限制。 负幅度意味着向量实际上指向相反的方向。 我们的模型强制用户反转方向,而不是提供负幅度。 小于 0 或大于 2PI 的方向也是允许的,但可以转换为介于 0 和 2PI 之间的等效值。 我们稍后将提供一个合适的辅助函数来实现这一点。 在验证函数到位后,这些来自任意字符串字面量的无意义值这次将被捕获:

也可以在 `Parse` 中应用验证,但我们需要将逻辑转移到另一个静态函数。 二进制反序列化的验证函数仅将任务委托给新静态函数,如下所示:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True, ValidationMethodName:="ValidateInput")> _
Public Structure Vector
Implements INullable
Private Function ValidateInput() As Boolean
Return Vector.Validate(Me)
End Function
Private Shared Function Validate(ByVal v As Vector) As Boolean
Dim minDirection As Single = 0.0F
Dim maxDirection As Single = CSng((2 * Math.PI))
Return (v.Magnitude >= 0) AndAlso _
(v.Direction >= minDirection AndAlso v.Direction <= maxDirection)
End Function
Public Shared Function Parse(ByVal input As SqlString) As Vector
' We return null if SqlString NULL is entered
If input.IsNull Then Return Null
' Happy Path! No validation!
Dim inputParts As String() = input.Value.Split(","c)
Dim v As New Vector()
v.Magnitude = Double.Parse(inputParts(0))
v.Direction = Single.Parse(inputParts(1))
If Not Validate(v) Then
Throw New ArgumentException("Magnitude must be positive " & _
"and direction must be between 0 and 2PI.")
Return v
End Function
' Rest of the codes here...
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
, IsByteOrdered = true, ValidationMethodName = "ValidateInput")]
public struct Vector : INullable
{
private bool ValidateInput()
{
return Vector.Validate(this);
}
private static bool Validate(Vector v)
{
float minDirection = 0f;
float maxDirection = (float)(2D * Math.PI);
return (v.Magnitude >= 0D) &&
(v.Direction >= minDirection && v.Direction <= maxDirection);
}
static public Vector Parse(SqlString input)
{
if (input.IsNull)
return Null;
// Happy Path! No validation!
string[] inputParts = input.Value.Split(',');
Vector v = new Vector();
v.Magnitude = double.Parse(inputParts[0]);
v.Direction = float.Parse(inputParts[1]);
if (!Validate(v))
throw new ArgumentException("Magnitude must be positive " +
" and direction must be between 0 and 2PI.");
return v;
}
// Rest of the codes here...
使用这些代码,有效的字面量也会被处理:

在生产环境中,来自任意字面量的恶意二进制反序列化几乎不可能发生,除非您的系统已经容易受到其他常规攻击方式的攻击,例如 SQL 注入。 防止此类攻击是前端应用程序和安全基础设施的主要责任。 但是,为了尊重墨菲定律,只需确保在 UDT 中有验证函数即可。
使用属性和函数更新
在讨论 UDT 初始化和赋值时,我们已经看到过 UDT 在 `Update` 语句中的用法。 它更多地是“替换”,因为我们只是创建 UDT 的另一个实例并将其赋值给列。 这会不必要地更新所有字段,而这并非我们总是想要的。 有时,我们只想更新一个属性。 属性 `Magnitude` 和 `Direction` 的类型分别映射到 SQL 类型 `double` 和 `float`。 这使得它们可以直接在 SQL 中更新。(有关 CLR 到 SQL 类型映射的完整列表,请参阅 Microsoft 文档。)

出于某种未知原因,有效输入的字符串字面量也是可能的。 看!

虽然这会导致无效字面量(如‘Hello there’)出错,但我仍然觉得这很不必要。 在本文的上一版本中,我曾希望此功能能在 SQL Server 2008 中被移除。 不幸的是,它仍然存在。
SQL Server 不允许在单个 `UPDATE` 语句中更新两个列。 尝试这样做会返回一个错误:

这可能是由于数据库引擎的内部机制,或其他关系原则,但我不太关心。 如果需要同时更改两个或多个字段,这可能表明存在一个函数。 此函数利用封装,隐藏更新字段的复杂性,同时使我们的 UDT 自我文档化。 我们可以应用此函数来表示向量的一些常见操作。 让我们用这些函数来增强我们的向量,从标量乘法开始。 标量乘法不过是将幅度乘以一个常数因子。 我们可以用一个不太学术的名称 Scale 来表示。 如果因子为负,则表示方向偏移 180 度或 2PI。
<SqlUserDefinedType(Format.Native, ValidationMethodName:="ValidateInput" _
,IsByteOrdered:="True"> _
Public Structure Vector
Implements INullable
Public Sub Scale(ByVal factor As Double)
If factor < 0 Then
' Preserving PI precision
Dim dir As Double = Direction
If dir > Math.PI Then
dir -= Math.PI
Else
dir += Math.PI
End If
' We might lose precision with coersion
' but at least we've minimized it
Direction = CSng(dir)
' We don't have to represent negative magnitude
' because it's the same as reversing direction
factor *= -1
End If
Magnitude *= factor
End Sub
' Rest of the codes here...
[SqlUserDefinedType(Format.Native, ValidationMethodName = "ValidateInput"
,IsByteOrdered = true)]
public struct Vector : INullable
{
[SqlMethod(IsMutator=true)]
public void Scale(double factor)
{
if (factor < 0)
{
// Preserving PI precision
double direction = Direction;
if (direction > Math.PI)
direction -= Math.PI;
else
direction += Math.PI;
// We might lose precision with coersion
// but at least we've minimized it
Direction = (float)direction;
// We don't have to represent negative magnitude
// because it's the same as reversing direction
factor *= -1;
}
Magnitude *= factor;
}
// Rest of the codes here...
但是,如果您执行此操作,您将收到一个错误:

发生的情况是 SQL Server 无法将成员识别为变异函数。 在编程术语中,变异函数是改变对象状态的函数。 改变是指至少一个字段的值发生了变化。 在没有属性构造的语言中,变异函数等同于 setter 函数。 因此,SQL Server 默认将属性视为变异函数是完全合理的。 您可以通过 `SqlMethodAttribute` 的 `IsMutator` 属性来更改此设置。 SQL-CLR 甚至超越了默认设置,因为 `IsMutator` 对属性似乎没有影响。 您应该尝试下面的代码,亲眼看看。
Public Property Magnitude() As Double
Get
Return _magnitude
End Get
' No effect
<SqlMethod(IsMutator:=False)> _
Set(ByVal value As Double)
_magnitude = value
End Set
End Property
public double Magnitude
{
get { return _magnitude; }
// No effect
[SqlMethod(IsMutator=false)]
set
{
_magnitude = value;
}
}
我们的 `Scale` 运算符,作为一个函数,不享有 `Magnitude` 所拥有的特权。 我们需要显式设置属性中的标志:
<SqlMethod(IsMustator:=True)>
Public Sub Scale(ByVal factor As Double)
' Rest of the codes here...
[SqlMethod(IsMutator=true)]
public double Scale(double factor)
{
// Rest of the codes here...
在良好的 OOP 设计中,变异函数通常是返回 void 的公共实例函数。 即使是您的属性 set 函数也转换为这样的函数。 SQL Server 通过将变异函数的调用限制在 `UPDATE` 和 `SET` 语句中来确保您遵循这一点。 如果您不将 `void` 函数标记为变异函数,您就授权 SQL Server 在 `SELECT` 或 `PRINT` 语句中调用该函数。 结果出错是因为 `SELECT` 和 `PRINT` 期望由 UDT 函数返回的参数值。
另一方面,非变异函数或访问器将值返回给调用者。 SQL Server 将访问器调用限制在 `SELECT` 和 `PRINT` 语句中。 将访问器标记为变异函数是完全合法的,但这样做会使其无效。 SQL Server 无法使用返回值,因为该属性排除了 `SELECT` 和 `PRINT`。 您可以使用 `UPDATE` 和 `SET`,但它们毫无用处,因为它们不会改变函数的返回值。 下表总结了 SQL 语句对 `IsMutator` 属性的依赖关系:

我们添加了一个访问器来返回指向相反方向的向量。 您可以省略修饰,因为默认值已经是 false。
' False is also the default
<SqlMethod(IsMutator:=False)> _
Public Function GetReversed() As Vector
Dim reversed As Vector = Me
reversed.Scale(-1)
Return reversed
End Function
// False is also the default
[SqlMethod(IsMutator=false)]
public Vector GetReversed()
{
Vector reversed = this;
reversed.Scale(-1);
return reversed;
}
在将我们的 `Scale` 函数标记为变异函数后,最后一个使用它的 SQL 语句现在可以正常运行:

新访问器也一样:

我们将模型中的其他向量运算添加为静态函数。 这使我们能够同时在显示和更新 UDT 时使用它们。 如果我们选择实例实现,则需要创建一个等效的静态函数,如果我们只想显示结果。 由于 SQL-CLR 不支持函数重载,我们将不得不使用一个不同名称的函数——一点都不优雅! 我们添加了一个辅助类,它将所有小于 0 或大于 2PI 的方向转换为有效值,因为中间运算符可能会产生超出该范围的值。
Public Shared Function Add(ByVal lhs As Vector, ByVal rhs As Vector) As Vector
Dim xOfMagnitude As Double = (Math.Cos(CDbl(lhs.Direction)) * lhs.Magnitude) _
+ (Math.Cos(CDbl(rhs.Direction)) * rhs.Magnitude)
Dim yOfMagnitude As Double = (Math.Sin(CDbl(lhs.Direction)) * lhs.Magnitude) _
+ (Math.Sin(CDbl(rhs.Direction)) * rhs.Magnitude)
Dim resultant As New Vector()
resultant.Magnitude = Math.Sqrt((xOfMagnitude * xOfMagnitude) _
+ (yOfMagnitude * yOfMagnitude))
resultant.Direction = ToFirstRevPositive( _
CSng(Math.Atan2(yOfMagnitude, xOfMagnitude)))
Return resultant
End Function
Public Shared Function Subtract(ByVal lhs As Vector, ByVal rhs As Vector) As Vector
rhs.Scale(-1)
Return Add(lhs, rhs)
End Function
Private Shared Function ToFirstRevPositive(ByVal angleInRadian As Single) As Single
Dim negative As Boolean = angleInRadian < 0.0F
Dim oneRev As Single = CSng((2 * Math.PI))
If negative Then angleInRadian *= (-1.0F)
Dim angleFirstRev As Single = angleInRadian Mod oneRev
Dim angleFirstRevPositive As Single = If(negative, _
oneRev - angleFirstRev, angleFirstRev)
Return angleFirstRevPositive
End Function
public static Vector Add(Vector lhs, Vector rhs)
{
double xOfMagnitude = (Math.Cos((double)lhs.Direction) * lhs.Magnitude)
+ (Math.Cos((double)rhs.Direction) * rhs.Magnitude);
double yOfMagnitude = (Math.Sin((double)lhs.Direction) * lhs.Magnitude)
+ (Math.Sin((double)rhs.Direction) * rhs.Magnitude);
Vector resultant = new Vector();
resultant.Magnitude = Math.Sqrt((xOfMagnitude * xOfMagnitude)
+ (yOfMagnitude * yOfMagnitude));
resultant.Direction = ToFirstRevPositive(
(float)Math.Atan2(yOfMagnitude, xOfMagnitude));
return resultant;
}
public static Vector Subtract(Vector lhs, Vector rhs)
{
rhs.Scale(-1.0D);
return Add(lhs, rhs);
}
static float ToFirstRevPositive(float angleInRadian)
{
bool negative = angleInRadian < 0f;
float oneRev = (float)(2.0 * Math.PI);
if (negative)
angleInRadian *= (-1f);
float angleFirstRev = angleInRadian % oneRev;
float angleFirstRevPositive = negative ?
oneRev - angleFirstRev : angleFirstRev;
return angleFirstRevPositive;
}
我们在两个幅度相等的向量上测试这些运算符:一个角度是 45 度,另一个是 135 度。 `static` 函数的作用域限定符是 `::`,这在图 34 中首次显示。请再次注意,我们的向量 UDT 只接受以弧度表示的角度,并且我们答案的精度取决于我们输入的精度。

函数重载和运算符重载仍然不是 SQL Server 2008 的一部分,但它们将来会是一个很好的补充。 对于向量这样的数学实体,运算符重载是必须的,因为可重载的 CLR 运算符已经具有固定且定义明确的语义。 鉴于 UDT 目前的不足之处,仍然无法编写 100% SQL 独立的 .NET 结构或类。 许多情况下,UDT 并不是现有库的简单移植。 它主要是为 SQL Server 而创建的。
在结束本节之前,我还想指出 SQL Server 不支持 out 和 ref 参数。 您的代码会编译,但在 SQL 中调用该函数会返回这个模糊的消息:
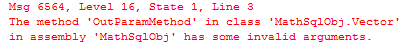
再次初始化
我们上一个测试中的赋值语句效率不高。 我们将方向初始化为 0,稍后又用另一个值更改它。 我们这样做是因为我们想使用 `PI()` 变量,但由于默认 UDT 初始化只接受字符串字面量,我们被迫为方向赋值一个虚拟值。 我们可以通过另一个工厂函数来纠正这一点,这次是带有正确类型的参数。 使用各自类型的值来初始化字段比使用容易出错的字符串要自然得多。 从现在开始,我们将更频繁地使用此函数:
Public Shared Function CreateVector(ByVal magnitude As Double _
, ByVal direction As Single) As Vector
Dim v As New Vector()
v.Magnitude = magnitude
v.Direction = direction
Return v
End Function
static public Vector CreateVector(double magnitude, float direction)
{
Vector v = new Vector();
v.Magnitude = magnitude;
v.Direction = direction;
return v;
}
这个新的工厂函数甚至让之前的 SQL 语句变得更短:

访问 SQL-Null UDT
此时,我们已经看到了 UDT 的所有成员如何工作,除了 `IsNull`。 我们已经知道 SQL Server 在反序列化后在内部使用它来确定实例是否为 SQL-null。 如果是这样,那么在 SQL 中使用它应该很简单,对吧? 错误。 看看这些语句:

检查我们 UDT 的属性可以解释为什么删除没有如预期那样发生。

这种奇特的行为是由于 SQL Server 默认会绕过对 SQL-`null` UDT 成员的调用。 这是一种提高性能的技术。 SQL Server 可以节省处理能力,因为它不必反序列化 UDT 的字段。 它只需要窥视内存足够长的时间来确定 UDT 是否被标记为 SQL-null。
在一个 SQL-`null` UDT 中,从其他成员(除了 `IsNull`)获取 `null` 是完全符合逻辑的。 `IsNull` 返回 SQL-`null` 具有误导性。 一个未受过训练的 SQL 开发人员可能会将此属性用作 `WHERE` 子句中的谓词,从而导致细微的错误。 为避免此问题,您可以告诉 SQL Server 调用 SQL-`null` UDT 的成员,方法是将 `SqlMethodAttribute` 的 `InvokeIfReceiverIsNull` 属性设置为 true。 这告诉 SQL Server,如果 UDT 是 SQL-`null`,它仍然必须反序列化它,以便能够调用该成员。
' No adornment here
Public ReadOnly Property IsNull() As Boolean Implements INullable.IsNull
' Adornment here
<SqlMethod(InvokeIfReceiverIsNull:=True)> _
Get
Return _isNull
End Get
End Property
// No adornment here
public bool IsNull
{
// Adornment here
[SqlMethod(InvokeIfReceiverIsNull=true)]
get { return _isNull; }
}
这次您将得到您期望的 `DELETE` 结果:

请注意,这会产生不必要的处理。 Microsoft 建议您使用 SQL 的现有方法,即使用 `IS NULL` 谓词运算符来测试可空性。 这也会给您正确的结果,但无需反序列化 UDT 字段,从而提供显著的性能提升。
我进行了一项非正式性能测试,比较了 `IsNull` 和 `IS NULL` 构造在具有 33% SQL-`null` 的 1000 万行表上的性能。 脚本和示例输出如下:
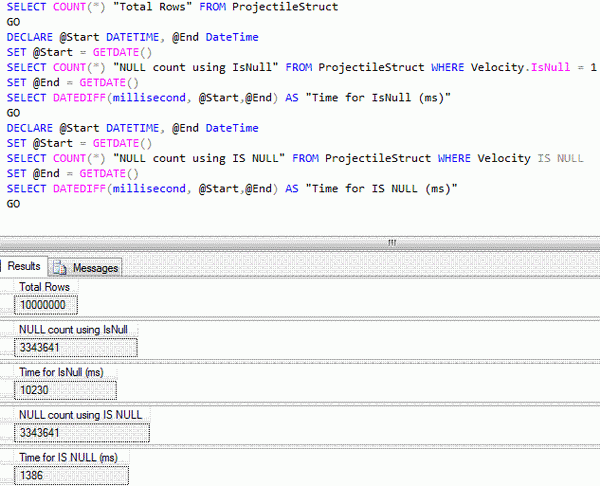
我的机器上有很多进程可能会影响脚本的执行,所以我进行了 10 次迭代以得出更具决定性的结果。 当然,迭代次数越多,结果就越具决定性,但我没有时间和资源来设置一个干净的测试环境。 现在您知道为什么我称它们为“非正式”测试了。
如以下图表所示,十次迭代产生了 `IS NULL` 比其 UDT 对应物快 6 倍的一致值:

虽然 `IsNull` 的负面影响在行数很少的情况下可能微不足道,但在基于集合的操作中最好避免使用它,因为您永远不知道表何时以及以多快的速度增长。 对于非基于集合的操作,如 `IF` 语句中的条件,使用它通常是安全的。
SQL-Null 参数
在我们还记得 SQL-`null` 的时候,让我们来处理另一个与之相关的行为。 这次不是 UDT 是 SQL-`null`,而是传递给其函数的参数。 与 `IsNull` 的情况一样,SQL Server 处理 SQL-`null` 参数时会同时考虑性能和语义。 这种行为由 `SqlMethodAttribute` 的 `OnNullCall` 属性控制。 当然,只有当参数是 SQL-nullable 时,此属性的用途才能完全实现。
将 `OnCallNull` 保留为默认值 true 会告诉 SQL Server,即使至少一个参数是 `null`,也要调用函数。 这似乎很荒谬,因为它暗示性能不是此属性的主要动机。 在本节结束时,我们将找出其背后的原理。
让我们通过添加一个 `AddVector` 的变异函数,并将 `OnNullCall` 设置为 false,来开始对这个新属性的探索:
<SqlMethod(IsMutator:=True _
, OnNullCall:=False)> _
Public Sub AddVector(ByVal v As Vector)
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
[SqlMethod(IsMutator=true
,OnNullCall=false)]
public void AddVector(Vector v)
{
this = Vector.Add(this, v);
}
如果我们向此函数传递一个 `null` 参数,我们会收到一条模糊的错误消息:
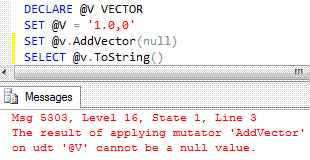
我们知道,通常情况下,涉及 SQL-`null` 的 SQL 操作会返回 SQL-`null`。 SQL Server 认为,通过将您的函数标记为变异函数,您将使用 SQL-`null` 参数进行涉及您字段的操作。 理论上,这反过来可能导致您的 UDT 变为 SQL-`null` 或您的字段处于不一致状态。 这正是之前消息的含义。
SQL Server 通过将变异函数的 `OnNullCall` 限制为仅 `true` 来防止您的 UDT 被意外渲染为 SQL-`null`。 由于您字段中的值至关重要,SQL Server 希望您采取适当的措施,而不是立即将 UDT 渲染为 SQL-null。 您可以选择退出函数或抛出异常。 如果您想将 UDT 渲染为 SQL-`null`,可以通过将 `nullability` 标志字段设置为 true 来实现。 SQL Server 强制规定,设置数据为 `null` 应通过显式 `null` 赋值完成,如图 5 所示,而不是作为 UDT 作为操作数的运算效果。 我们通过将 `OnNullCall` 设置为 true 并处理 SQL-`null` 参数来修复我们的代码:
<SqlMethod(IsMutator:=True, OnNullCall:=True)> _
Public Sub AddVector(ByVal v As Vector)
If v.IsNull Then
Return
End If
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
[SqlMethod(IsMutator = true, OnNullCall = true)]
public void AddVector(Vector v)
{
if (v.IsNull)
return;
this = Vector.Add(this, v);
}
之前的语句现在应该可以成功执行:
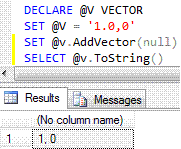
即使忽略了 SQL-nullability,字段的值对于特定操作也可能是有效的。 我们的向量 UDT 就是这种情况,其中零幅度的 SQL-`null` 值是一种特殊的向量——零向量。 零向量也是一个加法单位元,这意味着将其加到非零向量上只会得到相同的非零向量。 加法确实发生了,但由于结果与非零向量操作数相同,我们留下了错误的印象。 您可以通过运行相同的语句,但这次是在不返回参数是 SQL-`null` 的函数上进行验证。 我们甚至可以通过更改 `Null` 属性的 get 函数中的字段值来进一步验证。
<SqlMethod(IsMutator:=True _
, OnNullCall:=True)> _
Public Sub AddVector(ByVal v As Vector)
' We don't care if it's SQL-Null
Dim resultant As Vector = Me
resultant = Vector.Add(Me, v)
Magnitude = resultant.Magnitude
Direction = resultant.Direction
End Sub
Public Shared ReadOnly Property Null() As Vector
Get
Dim v As New Vector()
v._isNull = True
v.Magnitude = 15 ' We change the default intentionally
v.Direction = CSng(Math.PI)
Return v
End Get
End Property
[SqlMethod(IsMutator=true
, OnNullCall=true)]
public void AddVector(Vector v)
{
// We don't care if it's SQL-Null
this = Vector.Add(this, v);
}
static public Vector Null
{
get
{
Vector v = new Vector();
v._isNull = true;
v.Magnitude = 15.0; // We change the default intentionally
v.Direction = (float)Math.PI;
return v;
}
}
之前的语句这次将产生不同的结果,这清楚地表明加法确实发生了:

在开发过程中,您必须仔细检查所有变异函数,以查看所有 `null` 参数是否都已显式处理。 忽略它们不会返回错误,这可能会让您相信 SQL Server 会为您处理返回当前实例的工作。 该操作实际上是使用 SQL-`null` 参数执行的,并且成功了,因为 .NET 没有 SQL-`null` 的概念;SQL-`null` 对象仍然是一个有效的 .NET 对象!
访问器是另一回事。 SQL Server 允许将其 `OnNullCall` 设置为 `false`,因为您的 UDT 不会受到该操作的影响。 而且,由于几乎所有涉及 SQL-`null` 的操作都会产生 SQL-`null`,SQL Server 可以安全地立即返回 SQL-`null`。 如果有特殊情况,您仍然可以设置 `OnNullCall` 为 `true` 并相应地处理 SQL-`null` 参数。
我进行了另一次 10 次迭代的测试,以找出将 `OnNullCall` 设置为 `false` 可以带来多少性能优势。 在此测试中,我创建了我们向量 UDT 的两个变体,每个变体都有一个具有 SQL 可空参数的 `GetScaled` 访问器。 允许调用此方法的变体的 `GetScaled` 的实现如下所示:
<SqlMethod(OnNullCall:=True)> _
Public Function GetScaled(ByVal factor As SqlDouble) As Vector
If factor.IsNull Then _
Return Vector.Null
Dim v As New Vector()
v = Me
v.Scale(factor.Value)
Return v
End Function
[SqlMethod(OnNullCall = true)]
public Vector GetScaled(SqlDouble factor)
{
if (factor.IsNull)
return Vector.Null;
Vector v = new Vector();
v = this;
v.Scale(factor.Value);
return v;
}
测试模拟了将 `GetScaled` 从两个变体返回的 SQL-`null` 值插入到两个虚拟表中。 下面显示了脚本和示例结果:

我的机器上可能有一些进程导致了其中一次迭代中的异常峰值,但仍然清楚地表明绕过函数调用确实带来了性能优势。 我的机器获得了 21% 的性能优势,如下所示:

`OnNullCall` 设置先于 SQL Server 对函数参数执行的其他验证检查。 如果您的访问器的参数是非 SQL-nullable 的,即使您提供 `null` 值,SQL Server 也不会返回错误,因为该检查已被 `OnNullCall` 设置抑制。 为了说明这一点,让我们创建 `Scale` 的另一个访问器变体,但与图 70 不同,我们保留了非 SQL-nullable 参数,这对于本讨论至关重要。
' You may remove this later
Public Function ScaleAccessor(ByVal factor As Double) As Vector
Dim scaled As Vector = Me
scaled.Scale(factor)
Return scaled
End Function
// You may remove this later
public Vector ScaleAccessor(double factor)
{
Vector scaled = this;
scaled.Scale(factor);
return scaled;
}
如我之前所说,将此函数上的 `OnNullCall` 设置为 `true` 没有意义,因为您永远不允许提供 SQL-`null`。 SQL Server 无法将函数的参数转换为 SQL-null,您会收到类似这样的错误:

不要被这条消息愚弄。 将我们的参数转换为 out 或 ref 也没有用,如图 55 所示。 为避免此错误,请将 `OnNullCall` 设置为 false。 SQL Server 根本不会检查参数是否为 SQL-nullable。 因为它不再调用函数,所以没有意义。
此时很清楚,`OnNullCall` 非常依赖于 `IsMutator`。 我们将通过另一个总结这种依赖关系的表来结束本次讨论。 该表显示了 SQL Server 在默认 `OnNullCall` 设置方面为何有所不同,性能是一个重要的考虑因素。 我们可以推断,这只是 SQL Server 遵循基本数据库概念及其对您数据安全性的考量的自然结果。

更多关于索引
图 26 显示了通过 UDT 属性中的一个简单标志,使我们的 UDT 准备好进行索引是多么容易。 当时甚至不是我们的意图,只是告诉 SQL Server 如何比较两个 UDT 的一个简单副作用。 然而,在生产环境中,您会发现自己比 UDT 更频繁地为函数(属性 get 也是函数)编制索引,因为它们通常是标量的。 但与 UDT 外部的标量不同,标量函数默认情况下不是为索引准备的,如下所示:

消息说 SQL Server 要求函数必须是确定性的。 如果一个函数对于给定的输入只有一个可能的输出,那么它就是确定性的。 换句话说,没有两个输入会产生相同的输出。 例如,方程 `x+1` 是确定性的,因为它为每个 `x` 值产生一个唯一的值。 另一方面,`x^2` (x 的平方) 不是确定性的,因为它可能从两个数字产生相同的输出;例如 +2 和 -2。 在数学中,确定性方程实际上被称为函数。 不要将其与我们在编程上下文中的用法混淆。
SQL Server 无法确定函数是否为确定性的。 您需要通过使用 `SqlMethodAttribute` 的 `IsDeterministic` 属性来告诉它。 显然,我们候选的属性是合格的,因为它除了暴露我们的字段之外什么也不做。
Public Property Magnitude() As Double
<SqlMethod(IsDeterministic:=True)> _
Get
Return _double
End Get
' Rest of the codes here...
public double Magnitude
{
[SqlMethod(IsDeterministic=true)]
get
{
return _double;
}
// Rest of the codes here...
SQL Server 现在可以满足我们的要求:

为了了解我们的索引如何工作,我们执行两个查询,第一个查询利用了聚集索引。 执行计划显示,在第一个查询中,我们获得了显著的性能提升,因为 SQL Server 不需要再执行排序。

在继续之前,让我们简要看一下创建索引的语句。 该语句指出,从 UDT 属性创建索引涉及将该属性的值保存在派生列上。 这通过关键字 `PERSISTED` 实现,该关键字还意味着该列打算被索引。
您仍然可以通过告诉 SQL Server 在生成返回值时没有涉及浮点运算来提高属性或函数索引的性能。 您应该向 SQL Server 保证结果是精确的。 不幸的是,我们的任何属性都不能保证精确。 如果幅度是精确的,我们可以设置 `SqlMethodAttribute` 属性的 `IsPrecise` 属性,如下所示:
Public Property Magnitude() As Double
<SqlMethod(IsDeterministic:=True, IsPrecise:=True)> _
Get
Return _double
End Get
' Rest of the codes here...
public double Magnitude
{
[SqlMethod(IsDeterministic=true, IsPrecise=true)]
get
{
return _double;
}
// Rest of the codes here...
精度考虑
当处理浮点值时,后来会发现无处不在的等于“=”运算符可能不可靠。 这是因为两个值完全相同的可能性非常小。 有效数字的数量可能因一个输入而异,并且在中间计算中引入了一定程度的不精确性。 我们的 UDT 非常容易受到这种异常的影响,因为用于比较的所有字段都是浮点类型。 下一组语句模拟了两个本应相等但由于输入表示方式不同而结果不相等的向量之间的相等性测试异常。 第二个向量接受方向的近似值,这导致了非常微小但显著的差异。

如果我们有合理的有效数字数量,我们可以容忍两个操作数之间存在一定差异。 如果差异在此范围内,我们仍然认为它们相等。 它通常非常小且对模型无影响。 我们可以称这个范围值为我们的容差范围。 我们用另一个成员来增强我们的 UDT 以适应这一点:
Public Shared Function ApproxEquals(ByVal lhs As Vector, _
ByVal rhs As Vector, ByVal marginOfTolernace As Double) As Boolean
Dim diffMagnitude As Double = Math.Abs(lhs.Magnitude - rhs.Magnitude)
Dim diffDirection As Double = Math.Abs(CDbl((lhs.Direction - rhs.Direction)))
Return (diffDirection < marginOfTolernace) AndAlso _
(diffMagnitude < marginOfTolernace)
End Function
public static bool ApproxEquals(Vector lhs, Vector rhs, double marginOfTolerance)
{
double diffMagnitude = Math.Abs(lhs.Magnitude - rhs.Magnitude);
double diffDirection = Math.Abs((double)(lhs.Direction - rhs.Direction));
return (diffDirection < marginOfTolerance) &&
(diffMagnitude < marginOfTolerance);
}
您可以通过将两个操作数四舍五入到特定的小数位数来获得类似的结果。 在这种情况下,参数是要四舍五入到的小数位数。 我喜欢第一种方法,因为它集中在有问题的数值上。 通过显示两个向量方向之间的差异,我们可以轻松地锁定到该值。

这确实是一个非常微小的数量,但足以破坏您的查询。 新增的运算符可以解决这个问题:

建议为字节排序的 UDT 提供近似相等运算符。 这为您提供了灵活的解决方法,以应对处理浮点值时潜在的相等性异常。 一些开发人员选择在 `Equals` 重写中实现这一点,以使 UDT 更紧凑。 这种方法有两个缺点。 首先,它稀释了“equals”的真正含义。 由于其名称,它很容易被解释为绝对相等运算符。 其次,它不允许您灵活地调整容差范围。 只需更改边距值就需要修改代码。
此时,我们的 UDT 已完成,您应该能够正常使用它了。 下面的插图显示了其成员的概述。 您可以使用从谷歌搜索“向量计算器”找到的一些网站来验证其功能。 请记住,您不会得到完全相同的结果,因为这些计算器可能涉及近似。

类 UDT
类实现是 UDT 讨论中被忽视的一个方面。 大多数时候,开发人员固执地认为值类型(如结构)在性能方面具有固有的优势。 我们将找出这是否是避免类实现的原因。
在本节中,我们还将探讨类这种引用类型所带来的实现考虑。 我们将在创建一个类版本的 `struct` UDT 时逐一进行讨论。 首先,您需要将 `struct` UDT 的所有代码复制并粘贴到一个名为 `CVector` 的类中。
变量赋值修改
在继续之前,值得一提的一个怪癖是,在 SQL-CLR 中,将实例赋值给变量总是会创建一个新实例,无论 UDT 是实现为类还是结构。 这与我们对类实现的通常理解不同,在类实现中,赋值只是将变量指向实例。 仍然建议将特定于结构实现的任何内容相应地更改,以维护 UDT 在 SQL Server 之外的预期行为。 这意味着更改 `GetReversed` 的实现,使其创建一个新实例而不是将新变量指向当前实例。 我们的代码尚未编译,因为我们还没有定义构造函数。
<SqlMethod(IsMutator:=False)> _
Public Function GetReversed() As Vector
Dim reversed As New Vector(Magnitude, Direction)
reversed.Scale(-1)
Return reversed
End Function
[SqlMethod(IsMutator=false)]
public Vector GetReversed()
{
Vector reversed = new Vector(Magnitude, Direction);
reversed.Scale(-1.0);
return reversed;
}
访问修饰符修改
下一组修改与我们访问字段的方式有关。 如果您查看图 9,我们会直接访问字段,即使它是 `private` 的。 类严格遵守访问修饰符,这不再被允许。 我们将编写构造函数来满足此需求。
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True)> _
Public Class CVector
Implements INullable
Public Sub New()
Me.New(0, 0.0F, False)
End Sub
Public Sub New(ByVal magnitude As Double, ByVal direction As Single)
Me.New(magnitude, direction, False)
End Sub
Private Sub New(ByVal magnitude As Double, _
ByVal direction As Single, ByVal isNull As Boolean)
_direction = direction
_magnitude = magnitude
_isNull = isNull
End Sub
Public Shared Function Parse(ByVal input As SqlString) As CVector
Dim inputParts As String() = input.Value.Split(","c)
Dim magnitude As Double = Double.Parse(inputParts(0))
Dim direction As Single = Single.Parse(inputParts(1))
Dim v As New CVector(magnitude, direction)
Return v
End Function
Public Shared ReadOnly Property Null() As Vector
Get
Return New CVector(0, 0.0F, True)
End Get
End Property
' Rest of the codes here...
[SqlUserDefinedType(Format.Native
, IsByteOrdered = true)]
public class CVector : INullable
{
public CVector() : this(0D, 0F, false) {}
public CVector(double magnitude, float direction)
: this(magnitude, direction, false) {}
private CVector(double magnitude, float direction, bool isNull)
{
_direction = direction;
_magnitude = magnitude;
_isNull = isNull;
}
public static CVector Parse(SqlString input)
{
string[] inputParts = input.Value.Split(',');
double magnitude = double.Parse(inputParts[0]);
double direction = float.Parse(inputParts[1]);
CVector v = new CVector(magnitude, direction);
return v;
}
public static CVector Null
{
get { return new CVector(0, 0.0F, true); }
}
// Rest of the codes here...
这些构造函数的 `private` 重载仅用于设置 SQL-nullability 字段。 它之所以是 `private`,是为了防止在 SQL 之外设置 SQL-nullability,因为它没有意义。 默认重载被添加以验证原始调用结构构造函数的行。 `public` 和 `private` 运算符分别由 `Parse` 和 `Null` 函数使用。
内存问题
我们的类 UDT 可以无误地编译,但如果您将其编目,您将收到以下错误:

很明显,这是又一个缺少属性的情况。 不用费心使用老式的 Intellisense 来查找现有属性中的属性,因为这个属性是晦涩难懂的。 如果您编写了大量的互操作代码,那么您一定遇到过 `System.Runtime.InteropServices` 命名空间中的 `StructLayoutAttribute`,这正是我们所需要的。 它仅适用于传递给非托管代码的类或 `struct` 类型。 这正是 SQL Server 在持久化我们的类时处理二进制序列化时所发生的情况。 该属性有一个 `Value` 属性,其类型为 `LayoutKind`。 这告诉非托管代码类成员如何在内存中布局。 `LayoutKind.Sequential` 表示我们的类 UDT 的字段应按照我们声明它们的顺序排列在内存中。 `struct` 类型具有隐式的 `LayoutKind.Sequential` 修饰,这是优先于类的一个好原因。 按照 SQL Server 的要求,我们的代码如下:
<SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native _
, IsByteOrdered:=True)> _
<StructLayout(LayoutKind.Sequential)> _
Public Class CVector
Implements INullable
' SQL Server compares magnitude first,
' followed by direction, then IsNull
Private _magnitude As Double
Private _direction As Single
Private _isNull As Boolean
' Rest of the codes here...
[SqlUserDefinedType(Microsoft.SqlServer.Server.Format.Native
, IsByteOrdered = true)]
[StructLayout(LayoutKind.Sequential)]
public class CVector : INullable
{
// SQL Server compares magnitude first,
// followed by direction, then IsNull
double _magnitude;
float _direction;
bool _isNull;
// Rest of the codes here...
现在应该可以成功进行编目了,您的类 UDT 也已准备就绪。 没有比将其与其 `struct` 对应项进行正面比较更好的方法了,所以我又进行了一次测试。 这次,我还包括了用户定义格式的类 UDT。 测试脚本模拟了 UDT 的每种序列化格式的三个表的插入和删除。 这两个事务是连续的,但我决定分开显示结果以求清晰。 下面是用于用户定义格式的类 UDT 的表的脚本片段:

插入测试的结果基本符合我们的预期。 `struct` 和 `struct`-wannabe 类之间的差异非常微小,`struct` 仅获得了 1.1% 的优势。 另一方面,用户定义格式的手动二进制序列化导致其比 `struct`-wannabe 慢 32%。

如果插入结果基本符合预期,那么删除就是一个惊喜。 下面的图表根本没有显示任何趋势。 我清楚地意识到我机器上的一些其他进程影响了结果,但我不明白为什么相邻的插入似乎不受影响。 另一个大惊喜是用户定义格式的类在优势幅度分别为 4.5% 和 8.9% 的情况下,优于原生结构和类,尽管幅度不大,但仍值得思考。 我不是 SQL Server 或 CLR 内部专家,所以我无法为您提供清晰的解释。

根据结果来看,性能的关键在于序列化,而不是我们大多数人可能假设的实现类型。我们刚刚看到,通过将类的 UDT 序列化设置为本机,其性能几乎与本机 struct 相当。同样,用户定义的格式化 struct 的性能应该与用户定义的格式化类没有区别。但是,如果有一件事会让您回避使用类,那就是它比 `struct` 同类项需要更多的代码。
其他 UDT 特性
大小
如果您的 UDT 是用户定义的,SQL Server 无法知道存储它需要多少空间。您必须在 `SqlUserDefinedTypeAttribute` 的 `MaxByteSize` 属性中指定最大可能的字节大小。SQL Server 2005 的最大值为 8000,但在 SQL Server 2008 中取消了此限制。我稍后会详细说明。
我们通过创建 `struct` UDT 的用户定义格式化版本来演示 `MaxByteSize` 的用法。我们添加了一个名为 `Unit` 的 `string` 类型属性,它接受“`rad`”(弧度)和“`deg`”(度)值。您还应该像图 11 中一样添加 `IBinarySerialize` 的实现,并对其他成员进行必要的修改。下面的代码片段显示了新 UDT 的装饰。
<SqlUserDefined(Format.UserDefined, IsByteOrdered:=True _
, ValidationMethodName:="ValidateInput", MaxByteSize:=17)> _
Public Structure Vector
Implements INullable
Implements IBinarySerialize
Private _unit As String
' Rest of the codes here...
[SqlUserDefinedType(Format.UserDefined, IsByteOrdered=true
, ValidationMethodName="ValidateInput", MaxByteSize=17)]
public struct Vector : INullable, IBinarySerialize
{
string _unit;
// Rest of the codes here...
17 字节的最大值是通过将我们字段所需的所有字节相加得出的。我们已经有 13 个字节,额外的 4 个字节是输入的最大字符数:`string` 的 3 个字节加上字符串序列化的 1 字节开销。如果您打算支持非美国 ASCII 字符,则应增加大小。
如果您希望此属性成为 UDT 的一部分,可以向该属性添加验证例程。我们当前的实现只接受不超过 3 个字符的任何文字。超出此数量,SQL Server 将在序列化时耗尽内存,如下所示:

长度
另一个与用户定义格式化 UDT 相关的 `SqlUserDefinedAttribute` 属性是 `IsFixedLength`。在我看来,这个标志具有误导性,因为它指定您是否希望 SQL Server 为您 UDT 的所有实例分配最大字节大小。这是可选的,默认为 `true`。如果设置为其他值,SQL Server 只会为实例的值分配实际需要的字节。这里的决定通常受开发人员对性能和磁盘空间的考虑影响。固定长度的 UDT 在查询中通常更快,而可变长度的 UDT 则更节省空间。与标量(例如 `char` 与 `varchar`、`binary` 与 `varbinary` 等)一样,UDT 也适用类似的优缺点。
值表示
SQL-CLR 允许您通过 `SqlFacetAttribute` 控制函数和属性返回值特性。此属性具有对应于非托管类型和 `System.Data.SqlTypes` 命名空间中类型的不同特性的属性。您可以在 Microsoft 文档中找到支持的数据类型及其支持的属性的列表。我们的 UDT 不包含任何受支持的数据类型,但我们仍然可以通过更改幅度类型为 decimal 来演示。请注意,这对您现有的代码有广泛的影响。下面的代码片段显示了属性在属性上的装饰。
<SqlUserDefinedType(Format.UserDefined, IsFixedLength:=False _
, MaxByteSize:=8000)> _
Public Structure Vector
Implements INullable
Implements IBinarySerialize
Private _magnitude As Decimal
<SqlFacet(Precision:=15, Scale:=8)> _
Public Property Magnitude() As Decimal
Get
Return _magnitude
End Get
' Rest of the codes here...
[SqlUserDefinedType(Format.UserDefined, IsFixedLength=false
,MaxByteSize=8000)]
public struct Vector : INullable, IBinarySerialize
{
decimal _magnitude
[SqlFacet(Precision=15, Scale=8)]
public decimal Magnitude
{
get
{
return _magnitude;
}
// Rest of the codes here...
在上面的代码中,`Precision` 是总位数,而 `Scale` 是小数点右边的位数。我们使用图 54 中的值来演示装饰的效果。请注意,在下面的语句中,我们调用属性而不是 `ToString`,因为 `SqlFacetAttribute` 在 UDT 内部无效。如果您将下面的结果与图 54 进行比较,您会发现 SQL Server 确实按照指定对幅度进行了四舍五入。

对于属性来说,`SqlFacetAttribute` 的放置具有误导性。它暗示该属性同时包含输入和输出。这可能会让您认为它具有验证功能,而实际上,它只处理表示规范。我们可以通过输入不符合我们装饰规范的值来确认这一点,并看到它仍然会成功。

对我而言,`SqlFacetAttribute` 在 UDT 中的作用有限。我甚至避免使用我们刚刚演示的属性,因为如果装饰了 UDT 属性的属性用于中间计算,它们可能会导致精度损失。
`SqlFacetAttribute` 的其余属性是 SQL Server 在基于被装饰成员定义数据库对象时可以使用的信息。这在 UDT 中很少见,但在其他 CLR 工件(如托管过程、函数和用户定义聚合)中很常见。我们不再探讨它们。
SQL Server 2008 变更
考虑到 UDT 的使用稀少以及 Microsoft 自己的 UDT(如空间数据类型)的发布,UDT 在 SQL Server 2008 中只得到一项增强也就不足为奇了。正如我刚才提到的,UDT 不再限于 8000 字节。这可能只是在开发空间数据类型时的事后想法,而空间数据类型本身就是 UDT,但这总比没有好。然而,当我第一次应用此功能时,我感到很困惑。文档具有误导性。如果您需要大于 8000 字节的 UDT,您只能在 `SqlUserDefinedAttribute.MaxSize` 属性中设置值为 `-1`。指定大于 8000 的值会导致目录错误。
关于异常
您可能已经注意到,我们没有深入探讨异常。更糟的是,我们甚至没有进行任何异常处理!我曾指出 `Parse` 方法将包含大量的验证,当然也包括异常处理程序,但为了简洁起见,我完全省略了它们。此外,UDT 已经位于应用程序的核心,在异常处理程序中,您可以做的最好的事情就是重新抛出异常,并附带一个友好的消息。在特定于您的领域的情况下,您可能需要以不同的方式处理异常。至于其他未处理的异常,请不要担心;有人会在某个地方为您捕获它们。底线是,UDT 异常处理没有其他考虑因素。.NET 编程中的最佳实践也适用于此。
枚举的插曲
在我早期进行 UDT 实验时,我曾认为枚举只是一种命名的数字类型,在 UDT 中使用它应该没有问题。我当时进行的测试表明,事实并非如此。在原生格式 UDT 中,SQL Server 要求您像我们的原生类 UDT 一样,为枚举添加 `LayoutKind.Sequential` 装饰。这是不可能的,因为 `StructLayoutAttribute` 不能应用于枚举。而在用户定义格式中,您的代码可以编译,但 SQL Server 无法识别该类型。您将收到类似如下的消息:
![]()
曾经,为 UDT 提供枚举支持的想法对我很具吸引力。枚举通过其类型安全特性有助于最小化错误,同时提高 SQL 的可读性。后来我意识到这要求太高了,因为它实际上相当于实现一个全新的 SQL-CLR 对象。如果实现,它可能会使查找(名称-值)表过时,并引发另一轮争论;我们已经受够了。
摘要
用户定义类型 (UDT) 可能是 SQL-CLR 工件中最重要的一种。没有其他工件对 SQL Server 的影响像 UDT 那样广泛而深远。UDT 通过引入“对象”和属性等概念,在 SQL Server 超越其关系基础的演变中发挥了重要作用。此外,还需要新的 T-SQL 功能来与 UDT 进行交互。
不幸的是,UDT 也是 SQL-CLR 对象中最复杂的。它的实现是一种语言,但它的结构、特性和行为由另一种语言定义。这种双重性质使得我们必须稍微偏离对一些常见编程概念的传统理解;这可以归因于 UDT 的晦涩性质。更复杂的是,为了实现 UDT 的预期行为,需要大量的声明式编程。
UDT 可以使用类或结构 .NET 构造来实现。关于结构等值类型在处理大量事务时比引用类型具有性能优势的普遍观念不适用于 UDT。性能决定因素不是类型,而是 UDT 中使用的序列化格式。本机序列化比用户定义序列化更快。如果回避类有一个充分的理由,那就是它比结构实现更冗长。
也许,UDT 的最大优势尚未实现。通过允许我们存储几乎任何结构的data,它可以为全新的应用程序奠定基础。微软似乎正朝着这个方向发展,UDT 最终获得重视只是时间问题。
参考文献
- MSDN Library
- Apress Professional SQL Server Assemblies by Robin Dewson and Julian Skinner
- Microsoft SQL Server 2005 Stored Procedure Programming in T-SQL and .NET by Dejan Sunderi
历史
- 2008 年 8 月 23 日 - 初稿
- 包含 SQL Server 2008 的更改