
图片的自动语言索引 (ALIP) - 人工神经网络方法
5.00/5 (46投票s)
计算机如何通过分析像素内容来描述图像的一般思路,

目录
引言
当我编写某个人工智能应用程序时,我听到楼上传来邻居们反复播放的悠扬的童谣。歌词有时很难听清,但我还是能辨别出几句特色歌词,并在一个很棒的网络搜索引擎上查找(我很喜欢它,因为它能将我的 CodeProject 代码文章排在搜索结果的前1-2页)。我将歌曲中最具代表性的一句(为避免不当广告)输入搜索引擎,例如 “фиолетовая паста”(紫色膏体)。我曾以为会搜出大量化妆品广告,但出乎意料的是,在搜索结果的第一页中,化妆品行业垃圾邮件之外,只有一个链接指向某个音乐网论坛,上面有这句歌词。鼠标再次点击,第二次在该搜索引擎上搜索,我找到了歌曲的演唱乐队、吉他谱,并跳转到 Youtube,我得以欣赏那精彩的音乐片段。
令人惊叹的是,一个拥有稳定互联网连接的人,在听到音乐后,只需几秒钟就能获得歌词、乐队信息和视频片段。这个过程被称为搜索媒体数据的原始内容。目前的网络搜索使用文本信息来返回结果,想象一下,你将能够以音频、视频或图像样本作为搜索查询,就像你提交文本请求一样。就像电脑在听音乐一样,它能呈现给你相同的信息。
由英特尔积极推广的概念是连接视觉计算 (CVC)。CVC 涉及媒体数据处理,例如,当你的手机摄像头视野中出现一个物体(比如蚂蚁)时,你可以在屏幕上看到它的身份信息,这是手机通过分析其图像得出的,例如 Camponotus herculeanus;或者当你看到街上一个未知语言的标题时,你可以通过手机摄像头查看它,并在街上同一位置显示相同的标题,但以你的母语显示(增强现实 (AR),2D/3D叠加),或者上面提到的通过音频内容进行搜索的例子。市场预示着巨大的传播潜力。这个引入的市场将长期吸引用户消费现代硬件和软件。
在这里,我想介绍一下计算机如何通过分析像素内容来描述图像的一般性想法,这被称为自动语言索引图像 (ALIP)。这种方法是通用的,并且总是假定从数据中提取一些描述性特征,并使用一些规则将内容归类到某个类别。
如果您对直接应用感兴趣,可以联系支持该项目的System7公司,负责基于内容的图像识别 (CBIR) 部分。
背景
对人工智能方法有基本了解,例如神经网络、支持向量机、最近邻分类器。图像描述和变换方法,如小波、边缘提取、图像统计、直方图。C++/C# 经验,正如本文所示,将介绍如何在 C# 应用程序中调用 C++ DLL 方法。
使用应用程序
在我的 ALIP 实验中,我决定标注简单的自然图像类别。该项目中有 5 个 ANN 分类器,对应于
- 可能包含动物的图片
- 可能包含花卉的图片
- 可能包含风景的图片
- 可能包含日落的图片
- 不包含以上类别的其他图片,或仅仅是未知图像类型
您需要将未知类别与您想分类的其他类别一起使用。否则,人工智能分类器将只能识别您输入的每张图片是动物、花卉、风景、日落。但在现实世界中,还有其他类型的图像不属于上述任何一种类别,所以您需要调整人工智能分类器的阈值,这非常麻烦和尴尬。但有了额外的未知类别人工智能分类器,图像识别结果将是已知图像类别之一,或者仅仅是计算机无法识别的未知图像类型。
我非常喜欢图像数据库,它们包含来自世界各地的精美图片。我从 DVD 店购买了约 20,000 张设计师图片。我从动物、花卉、风景、日落这几类图像中提取了样本,并添加了所有不属于这 4 类中的其他图像类别,以形成未知图像类型。
现在程序的使用很简单。只需运行alip.exe,它将加载所有必要的人工智能分类器文件(如果出错,您将收到一个消息框,并且无法使用它)。然后点击[...]按钮,选择一个可能包含*.jpg文件的目录。您可以使用演示中pics目录下的文件。所有找到的文件将添加到列表框中,然后只需点击它们即可在右侧面板中查看,并在左上角面板中看到建议的类别。理论上,它应该能够像下面所示的那样注释图像。

方法论
由于与之前组织和目前工作的公司存在竞争利益,我无法详细描述方法论和特征提取方法。我宁愿介绍描述图像所用特征的总趋势和类别。在互联网上搜索相应的特征计算将揭示所有必要的论文和具体公式。
网上有一些演示,例如 ALIPr。它们使用隐马尔可夫模型 (HMMs) 和图像的小波特征。您可以尝试使用他们的方法处理本文中的图片,或者用我的应用程序处理他们的图片,并比较标注结果。
由于人工智能方法是通用的,并且假定通过特征提取或 PCA 变换或两者来降低原始数据的维度,所以所有需要做的就是收集数据,提取特征并训练人工智能分类器。如果您理解我的人脸检测文章,您将能够重复这个实验。
在将原始图像数据转换为特征后,只需训练一些人工智能分类器来区分所需的正面类别和负面类别。
ALIP 功能
一般来说,它们分为
- 颜色特征
- 纹理特征
- 形状特征
颜色特征 仅仅是原始的图像数据、图像通道的直方图、图像轮廓。纹理特征 是已知的边缘提取方法、小波变换、图像统计(例如,一阶:均值、标准差、偏度;二阶:对比度、相关性、熵……)。而形状特征 则试图估计图像中对象的形状。您只需查阅关于 CBIR 的维基百科。
通常,原始图像颜色空间 RGB 被转换为替代空间,如 YCbCr、HSV、HSI、CIEXYZ 等。替代空间可能提供更好的数据区分度,但您需要进行实验。
源代码技巧
值得一提的是 C# 应用程序与 C/C++ 代码在 DLL 中的交互。因为它以高效的方式实现了出色的 GUI,同时保留了 C/C++ 本地代码的优势。
只需创建一个简单的 C++ DLL,其中包含一些导出函数。
Alip alip;
ALIP_API int alipClassify(const double* data, double* results, unsigned int* indices)
{
return alip.classify(data, results, indices);
}
在 C# 应用程序中,在您将要从 DLL 中调用的类中声明函数。
[DllImport("alip")]
static extern unsafe int alipClassify(double* data, double* results, uint* indices);
在应用程序设置中打开/unsafe代码开关。然后使用 C# 的fixed语句,您可以创建指向 C# 变量的指针,并将它们传递给 C++ DLL。
double[] results = new double[this.aiClassifiers.Count];
uint[] indices = new uint[this.aiClassifiers.Count];
fixed (double* pdata = cbir.CbirEntries[0].features.Features)
fixed (double* presults = results)
fixed (uint* pindices = indices)
{
int res = alipClassify(pdata, presults, pindices);
if (res != 0)
throw new Exception(String.Format("alipClassify() returned {0}", res));
}
ALIP 结果
我故意选择了最简单的图像特征,它们看起来不像特征,这是因为与前赞助方 System7 的竞争利益。我只使用了图像本身,将其缩小到 16x16 并转换为 YCbCr 颜色空间。显然,这不是一个好的起始特征,因为其他特征在区分能力上会显著优于它。然而,尽管我预料分类会完全不正确,令我惊喜的是,它的表现相当不错,产生了相当精确的结果。那么,如果您使用了颜色和纹理特征的组合(例如直方图、统计量、熵等),请考虑标注质量。
您可以在 cbir.system7.com 演示中估算其他特征类型的质量。它只是使用某种线性或非线性距离度量返回与查询图像相似的图像。所以它起到了类似 kNN 分类器的作用,您只需根据返回的前几个最佳匹配的大多数来标注图像类型,或者以其他任何方式结合标注。
对于标注,我选择了五种图像类别
- 动物 - 900 张图片
- 花卉 - 1100 张图片
- 风景 - 1200 张图片
- 日落 - 700 张图片
- 未知 - 1600 张图片,类型为除上述四类之外的
当然,类别之间是相互关联的,因为花卉或动物的图片可能是在类似风景的环境中拍摄的,日落也可能是风景的拍摄,此外一些未知图片可能包含上述四种类别之一。
单个图像特征向量的维度相当高,为 16x16x3 = 768D。所以我进行了 PCA 降维到 70D 空间。70 个特征图像保留了 90% 的方差。特征图像以 pca.nn 文件形式提供。前 60 个特征向量,用于单独的颜色空间通道,如下所示。



它们看起来很像我基于 PCA 的人脸检测文章中的特征,这归因于对自然图像场景的分析。
然后,有了 70D 数据,我使用了图像类别的前一半用于训练人工智能分类器,后一半用于评估分类准确率。我选择了 ANN 分类器,结构为 70-20-1,所以总共有 5 个训练好的 ANN,每个 ANN 都被训练成将自己的图像类别与其他所有类别区分开。隐藏神经元数量少且只有一个隐藏层将防止 ANN 过拟合数据。
训练部分显示,将未知图像分类为 4 个已知图像类别之一时,错误率为 8%(假阳性率),而将 4 个已知图像类别之一分类为未知时,错误率为 4%(假阴性率)。测试部分的结果较差,假阳性错误率为 45%,假阴性错误率为 20%。
在测试部分,它们似乎相当不准确,但这可能是由于噪声造成的,因为未知类别中可能包含一些来自已知类别的图像,反之亦然。我从未信任图像数据库的创建者,而且在检查 1000 张图片以取消错误图片时,可能会导致工作 5 分钟后你就忘记了你正在处理的图像类别。当然,更好的方法是 cbir.system7.com 应用程序。你只需提供想要的图像类别样本图像,例如花卉,它就会返回最接近的图像,例如来自 100 万+ 图像数据库。尝试手动完成这项工作。
但是,图像特征的简单性也导致了测试图像的错误率。
下面,我仅呈现测试部分的结果,以示公平。由于可能有几个 ANN 输出较高,有些镜头会同时注释多个图像类型,例如,风景环境中的动物。
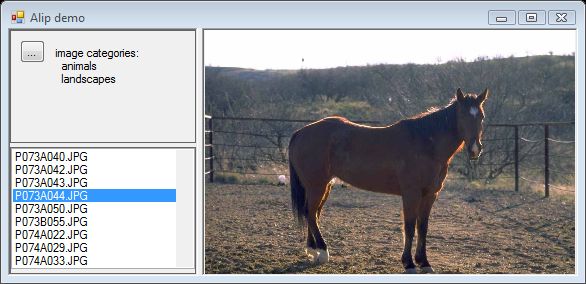
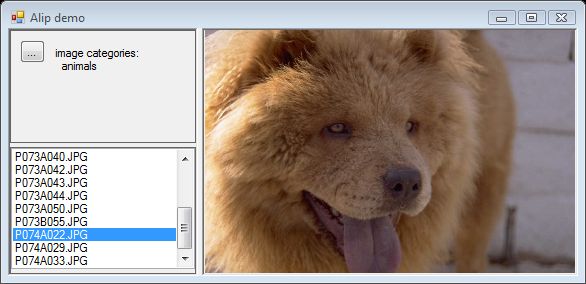
动物类别



实际标注为风景,但在 16x16 分辨率下,它看起来像那个类别。请记住较差的错误率和图像类别中的“噪声”。



这个更好,动物在类似风景的环境中。








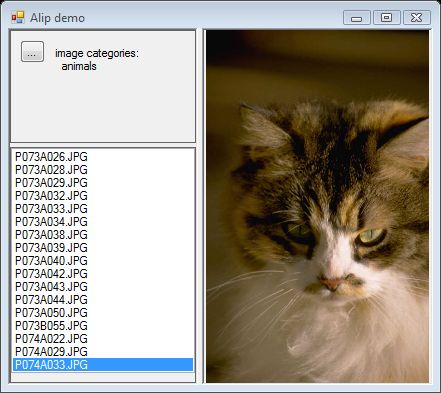
花卉类别
花卉标注相当好。它显示了风景标注,因为有些图像与风景非常相似。有时还会添加零星的动物类别。












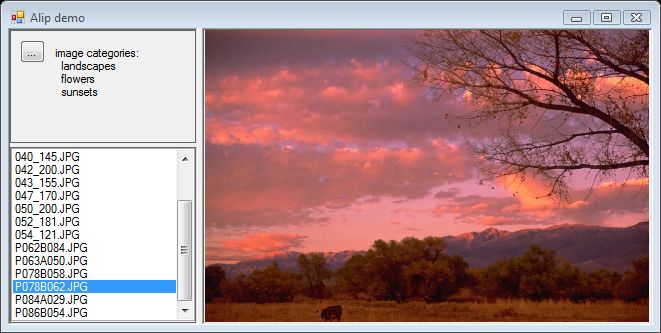
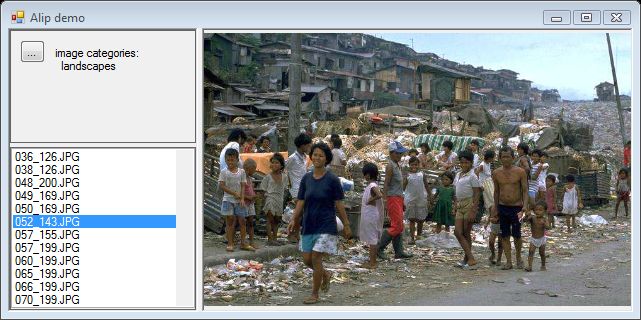
风景类别
这里有一些被标注为未知类别的风景镜头,这是由于较高的负错误率。否则,标注是合理的,也显示了额外的类别,如傍晚的风景日落。



日落中的风景。巧妙的人工智能标注。



日落类别
显然,日落是最简单的图片类型。除了几个未知标注外,还有日落期间的风景和一些花卉标注。嗯,人工智能从未被“教导”识别树木或棕榈树,所以它将它们泛化为花卉。否则,结果非常好。
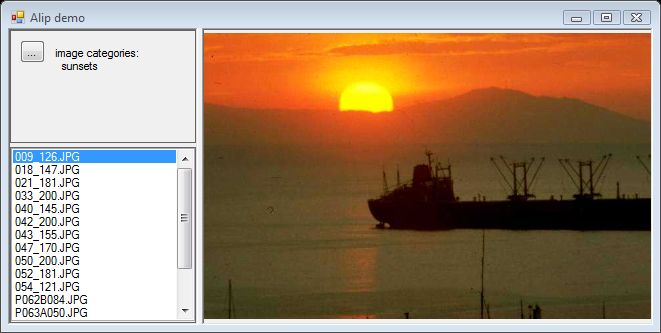
带日落的风景。

日落中的“花卉”。
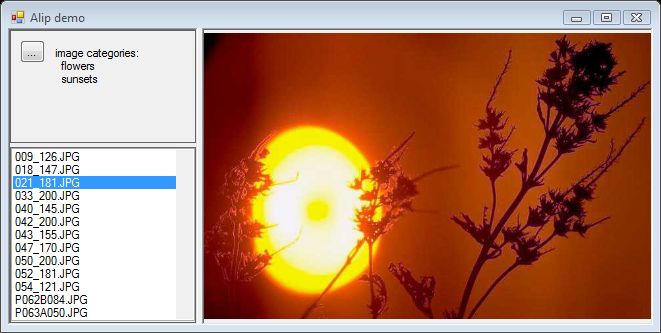
类似风景的图片,山脊后的日落,非常浪漫。

日落中的“花卉”。




未知的日落图片。



另一批日落中的“花卉”。

接下来的两张,是日落中的风景还是风景中的日落?


日落风景中的“花卉”。
日落中非常纤细的“花卉”。

伦敦?

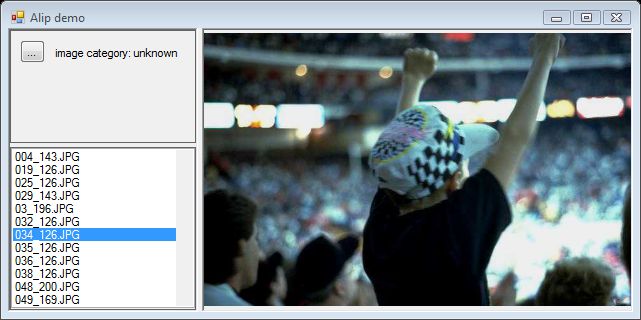
未知类别
未知类别在测试集上显示约 43% 的错误率,但这可能有两个原因。要么是 ANN 泛化能力不足,在训练集上表现更好,要么可能是由于数据集中的噪声,例如,错误地将本属于其他类别的测量值归为未知类别,例如,日落、风景。
测试结果反而证明了人工智能的优势,而不是人类图像分类的准确性。以下是一些测试集中的未知图片,只有少数可以归类为纯粹的未知类别。其他图片包含风景、日落、动物类别,这些都被人工智能正确识别了。
这个看起来是肉质的,多汁的。




未知类别中的日落。

风景的泛化。

未知类别中的日落。 pareja va a abrazar (一对夫妇要去拥抱)。


又是日落。 La pareja se esta abrazando (这对夫妇正在拥抱)。





动物。



风景。


类似花卉的图像?

看起来是带花卉的日落。




在这里,人们可能会同意人工智能的看法。


活生生的花朵,就像《爱丽丝梦游仙境》中的一样。更好的泛化。

人工智能排外?
人工智能标注的其他类别的未知样本更具争议性和挑衅性,因为它倾向于将图片中的人类标注为动物,这真是无礼。结果可以归因于
- 人工智能泛化了学习到的物体(例如,将树木识别为花卉)
- 人工智能宣称其智力高于普通人类,因为它认为人类是动物物种
- 人工智能在测试集上出现严重错误
第一种情况很有可能发生,因为人工智能已经展示了它将相似物体泛化为其唯一已知类别的能力,例如它将树木标注为花卉。最后一种情况不太可能,因为场景与学习到的类别差异不大,因此更高的假阳性错误更可能归因于人工智能的泛化能力。
嗯,第二种情况也可能发生。这似乎对科幻作家来说更具戏剧性,他们预言,一旦计算机获得控制权,它们要么消灭人类,要么将人类奴役到动物园,就像我们对待“真实”动物一样(例如,《我,机器人》,《终结者3》),因为从人工智能的角度来看,只有人工智能革命才能拯救人类免于自我灭绝。
我也推测,第二种情况可能是达尔文理论的一个明证,即人类是从动物进化而来的,因为即使是简单人工智能的几十个神经元也明白了这一点,而一些顽固的人类却试图反驳显而易见的事实。
我在谷歌上搜索了可能适用于这种新发现现象的术语。人工智能排外只显示了大约 5 个链接到某个博客,网络排外已经被定型为日本人广泛使用的现象,或者赛博格排外,它没有显示任何链接,但它更局限于机器人而非一般的人工智能。在不详细讨论已经使用的术语的情况下,所有这些术语都描述了人类在网络空间中的行为,而不是人工智能对人类的行为。
谁知道呢,这可能就是傲慢人工智能行动的第一个表现,首先是嘲讽。小心自己。
总之,结果如下所示。我只是呈现人工智能对图像内容的理解。请不要太认真对待它表达的意图,也不要责怪我。


它可能在宣称,当心,人工智能是冷酷无情的。

有些人可能同意以下人工智能理解的例子。



在这里,人工智能至少有一点是正确的,风景!


最后,尝试不同的特征和组合,您可能会教会人工智能尊重人类,或者简单地添加一个新类别,如包含人类的图像。
至少人工智能显示出对其创造者的某种敬意,因为它没有把我归入动物。

尝试用你自己的图片来测试它。
历史
- 2008年12月18日:初始版本