
Xbox Gamer Tag 阅读器
5.00/5 (1投票)
抓取任何公开的 Xbox Live 玩家标签,并以易于访问的方式提供标签/用户数据,方便格式化和操作。使用正则表达式进行解析。
引言
当我第一次了解到 Xbox Live 玩家卡时,我很快就开始思考如何在论坛、电子邮件等地方使用它。然而,当我想要将卡片无缝集成到自己的网站时,问题就开始了,基本的设计似乎总是不奏效。经过一番网络搜索,我失望地发现(免费的)API 不存在,允许我自定义它。当然,有一些网站提供了解决方案,但总是存在同样的基本问题——你被困在他们的设计中。
几年前,我编写了一个简单的 Python 脚本,它可以抓取基本的玩家卡 HTML 并将其重新组织成一个新的图像(网络上有一些这方面的例子)。最近,我一直在考虑再次将玩家卡数据集成到我的网站中,自定义图像可以奏效,但尝试使用图像库创建复杂的设计对于如此小巧的东西来说在编程上很麻烦。为什么它需要是图像?如果我想在我的网站的多个页面上显示一个用户的卡片数据,或者简单地将用户最近玩过的游戏显示在页面的一侧,而将他们的游戏分数显示在另一侧呢?为此,我需要原始数据来进行操作、保存和格式化。
解决方案
我想做几件事与我原来的 Python 脚本有所不同。首先是使用 PHP,我当前的 Web 主机不支持 Python,它正在逐渐融入 LAMP 堆栈,但从共享主机的角度来看,我认为它还没有完全到位。其次是采用一种不那么粗暴的方法来逐行解析文件,寻找特定的 HTML 并向前或向后移动n个字符。最后,我想尝试使用正则表达式,老实说,这在过去是我一直避免的,因为我总是记不住所有字符的意思 :-(。
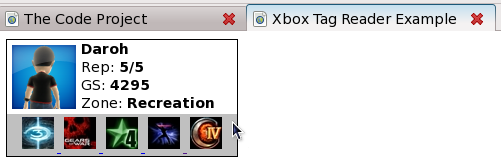
附加在此文章中是一个简单的 PHP 类和一个示例网页。该类根据玩家的标签/用户名下载给定玩家卡的 HTML 数据,并将数据解析为一组类属性,如声誉、游戏分数和最近玩过的游戏,以便于访问。我想让代码保持相对专注,并避免过度扩展以包含更复杂的功能,如缓存和连接错误处理(例如,如果 xbox.com 网站宕机该怎么办)。这在很大程度上是因为这是我的第一篇 CodeProject 文章,我想试探一下水温,部分原因是我想让该类作为基础,并希望任何额外的复杂性在我的应用程序的更高层次上提供,例如,用户对象类可以使用该类来引用玩家卡数据,如果其数据库记录为空或已过期。
Using the Code
该代码目前形式非常易于使用。只需创建一个类的实例,然后调用 `load()` 方法并传入有效的 Xbox Live 玩家标签/用户名。
require_once 'XboxTagReader.php';
$tag = new XboxTagReader();
$tag->load("Daroh");
...
就是这样。如果 `load()` 方法返回 `true`,则至少已成功读取用户的基本信息,然后可以通过调用类上的相应 `get` 方法来访问数据。
...
<a href="%22<?= $tag->getProfileURL() ?>%22">getProfileURL() ?>">
<img src="%22<?= $tag->getAvatarURL() ?>%22" style=""float:left;"
padding:5px">getAvatarURL() ?>" style="float:left; padding:5px" /> </a>
<?= $tag->getName(); ?>
...
上面的示例仅显示用户的头像/图标作为指向其在 xbox.com 上个人资料的链接以及他们的用户名。在演示项目中的 `index.php` 文件中提供了所有可用方法的示例。
关注点
当您提供玩家标签时,该类首先执行的操作之一是从 xbox.com 网站下载 HTML。PHP 使此操作非常简单,因为您只需提供主机的 URL/IP 地址(在本例中为 gamercard.xbox.com),然后读取其内容。通过 HTTP 读取网页时唯一的“技巧”是,在您使用 `GET` 请求请求其内容之前,文件将为空。这是您无需理解即可使用的事情之一。如果您有兴趣,我建议您了解套接字、文件指针和 HTTP 协议 `GET`、`POST` 请求。
/*
* Download the entire gamer card (html string) from the base host and path
*
* @return false on error or string response from base host and path
*/
private function download_card($gamerTag)
{
$fp = fsockopen(BASE_HOST, 80, $errno, $errstr, 30);
if (!$fp)
{
echo "$errstr ($errno)<br />\n";
return false;
}
else
{
// Build a HTTP GET request, this includes the path of the base host
// replace [GamerTag] in the path with the current gamer tag
$getRequest = "GET /".str_replace("[GamerTag]",
strtolower($gamerTag), BASE_PATH)." HTTP/1.1\r\n";
$getRequest .= "Host: ".BASE_HOST."\r\n";
$getRequest .= "Connection: Close\r\n\r\n";
fwrite($fp, $getRequest);
$response = "";
while (!feof($fp))
$response .= fgets($fp, 128);
fclose($fp);
// Remove space characters (space, new line, etc) from the response
return preg_replace('/\s+/', " ", $response);
}
}
首先,该函数使用 **fsockopen** 连接到我们的主机 (gamercard.xbox.com) 的 80 端口(标准 Web 端口),这将返回一个指向该主机的文件指针 ($fp)。可以将其视为我们与 Web 服务器的连接。
该函数执行的第二件事是使用 GET 请求请求我们的文件内容,这是一个格式化的字符串,我们将其“写入”到我们的文件指针中,并告诉主机我们想要它什么(例如,要获取.../users/index.html,我们将使用一个 `GET` 请求,如 `GET`/users/index.html)。
在有效的 `get` 请求之后,我们的文件将包含网页的 HTML,只需将文件读取到一个 `string` 中并关闭文件指针。该函数的最后一行对整个 `string` 使用了一个简单的 reg-ex查找和替换,以删除任何空格字符 (\s),如换行符、空格、制表符等。这相当粗暴,会删除所有空格,所以我们将其替换为一个空格,有效地修剪了文档内容。
一旦我们获得了卡片的 HTML,我们就需要能够将其转换为有意义的内容,提取我们想要的键值并丢弃其余部分。正如我在文章开头提到的,我想使用正则表达式来做到这一点,所以我采取的方法是标记化整个文档。这实际上意味着将长的 HTML `string` 分割成一个由更小的 `string` 组成的数组。查看源 HTML 后,我发现我们所需的所有值要么在 HTML 标签属性中,例如 `title="Halo 3"` 或 `src=".../halo_icon.gif"`,要么在标签本身内,例如 `Name Here`。我们永远不需要知道值来自哪个标签,所以我们可以忽略大部分 HTML 本身。
/*
* The meat of the class. Given a raw html response string from the gamer
* card use regex and string functions to tokenize into an array. The resulting
* array contains allot of rubbish but critically makes everything we need
* later easily available.
*
* @return array
*/
private function tokenize_card($rawData)
{
$tokens = array();
// Creates an array of $matches for all response data that
// lands between '>' and '<' characters OR
// between =" and " characters
// e.g. <span>GETS THIS</span> or title="GETS THIS"
preg_match_all('/>[^<(.*)]+<|="[^"]+"/', $rawData, $matches,
PREG_SET_ORDER);
foreach($matches as $match)
{
// Each match is returned as an array and includes its
// surrounding characters,
// remove them (<,>,=,") and save the token for return
$token = trim(preg_replace('/<|>|="|["]/', "", $match[0]));
if($token != '')
$tokens[] = $token;
}
return $tokens;
}
给定我们的 HTML 响应 `string`,该函数将其直接传递给 PHP 函数 preg_match_all,该函数根据 reg-ex 模式将我们的原始数据分割成一个 ` $match ` 数组,顺序与它们找到的顺序相同。如上所述,我们的数据可能存储在 HTML 中的有两种模式,正如你所料,我们的 reg-ex 模式也有两部分。第一部分获取 `>` 和 `<` 字符之间的任何数据。
>[^<(.*)]+<
之后是一个 OR 字符 **|**,然后是第二部分模式,告诉 `preg_match_all` 函数返回我们模式任一部分的每个匹配项。
="[^"]+"
一旦我们有了匹配项的数组,该函数就会简单地遍历它们,删除任何不需要的 HTML 字符和空格。如果清理后,我们的新标记不是空 `string`,我们就将其保存以供返回。通过这种方法处理我们的 HTML `string`,我们使得解析阶段(查找我们的实际数据)变得容易得多,例如,要获取用户的游戏分数,我们只需引用我们数组中的正确标记索引。
... $this->gamerscore = (int)$tokens[29]; ...
显然,如果 Xbox 提供的玩家标签 HTML 发生变化(尽管过去三年没有变化),该类就需要更新,但是,希望由于 HTML 的性质,标记函数不需要更新(值不太可能存储在其他地方)。为了尽量减少更改所需的任何更改,以防更改发生,所有标记到特定索引的引用都使用一个名为 `update_data()` 的函数。如果 HTML 发生变化,最可能的结果是数据会在我们的标记数组中移动,例如,将游戏分数从索引 29 更改为 30。
虽然这相当简单,但我不会建议尝试过度复杂化您的解析,因为很难说微软将来会对这些标签做什么。